题目与初赛一样,都是godot
题目附件:
ps:一些部分其实写的不太详细,后面有机会再补充吧,赛中使用了codex加速解题,wp中给的顺序非实际做题顺序,做题时没有处理反调试,因为10s的kill时间足够frida输出信息了,反调试是最后去了混淆再处理的,因此下面使用frida分析的动态调代码都会触发反调试,但是信息正常输出,在反调试章节给出了最终处理反调试的frida代码,和一些其它现象。
去混淆部分写的特别乱,主要当时写wp的时候还是有点懵,有空再整理
这一部分其实跟初赛一样,甚至简化了
首先找脚本加密 key,与初赛相同,Godot 4.5 用 AES-256 CFB 加密 .gdc 文件,key 存在libgodot_android.so 的 .data段中
沿用初赛脚本做熵扫描,在段中找连续 32 字节高熵区域(前后被零填充包围)。
key在0x4002f18
与初赛相同,用初赛的解密脚本报错了,检查了一下发现,GEQ = GDSC ^ {0x00, 0x01, 0x02, 0x03},是标准的CFB-128,没有XOR,微调了下初赛的脚本
运行脚本发现提取出来的
是类似的乱码,猜测是被混淆了,因为之前在华为杯看到过类似的题可能是改了opcode的映射?
通过对比初赛和决赛 .gdc 文件结构发现
初赛Godot 4.5 格式:
决赛:
用新格式解析,AI搓一个脚本
输出trigger1,示例
有点乱,然后研究了libgodotengine.so发现,不仅改格式,果然重排了 token 类型 ID。完整 token 表从 libgodot_android.so 提取在 0x3ec2548 找到 100 项的 _ZN17GDScriptTokenizer5Token8get_nameEv字符串指针表。
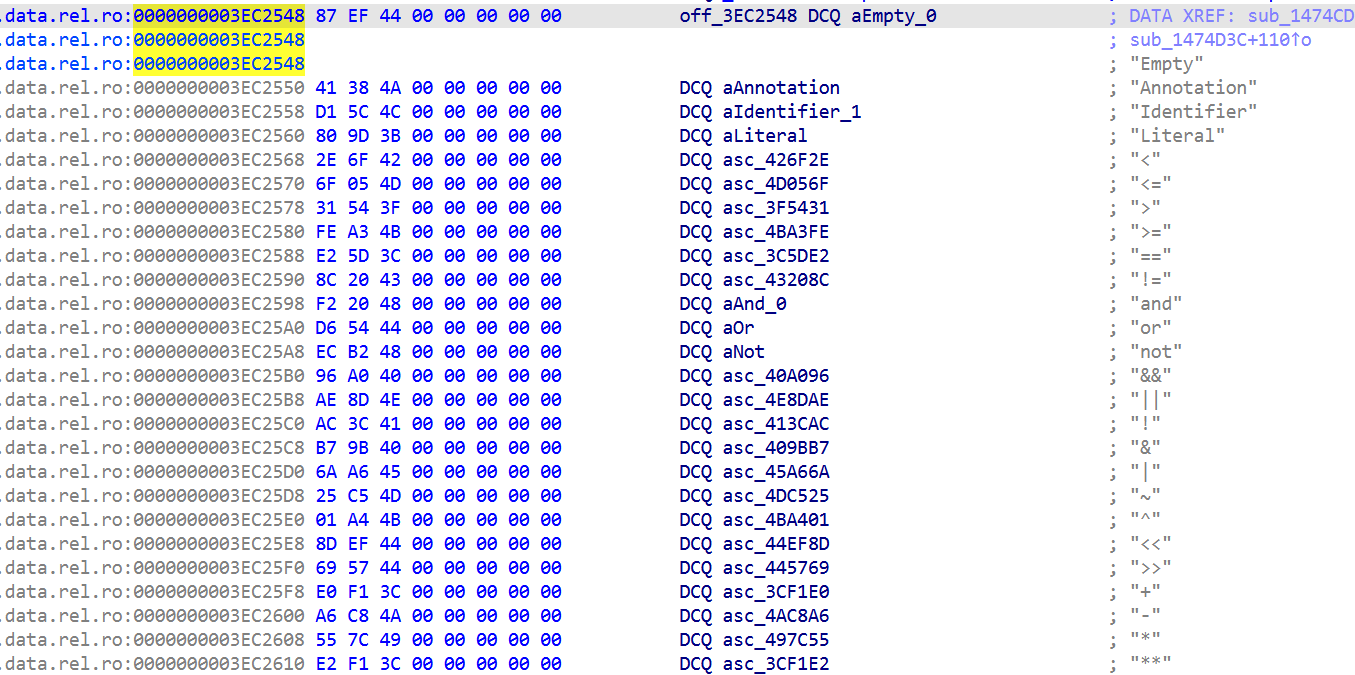
AI解释了下说
依旧搓个脚本
生成的trigger起码能看了
让AI综合两版进行总结整理下
这其实是最后做的当时
Trigger里的Tick一开始以为是part3 最后发现是反调试扎堆的地方
工作原理博客,不久前才稍微复习了ollvm,用上了刚好,其实原理差不多,虽然混淆每次不一样,如果不理解请先了解ollvm对抗
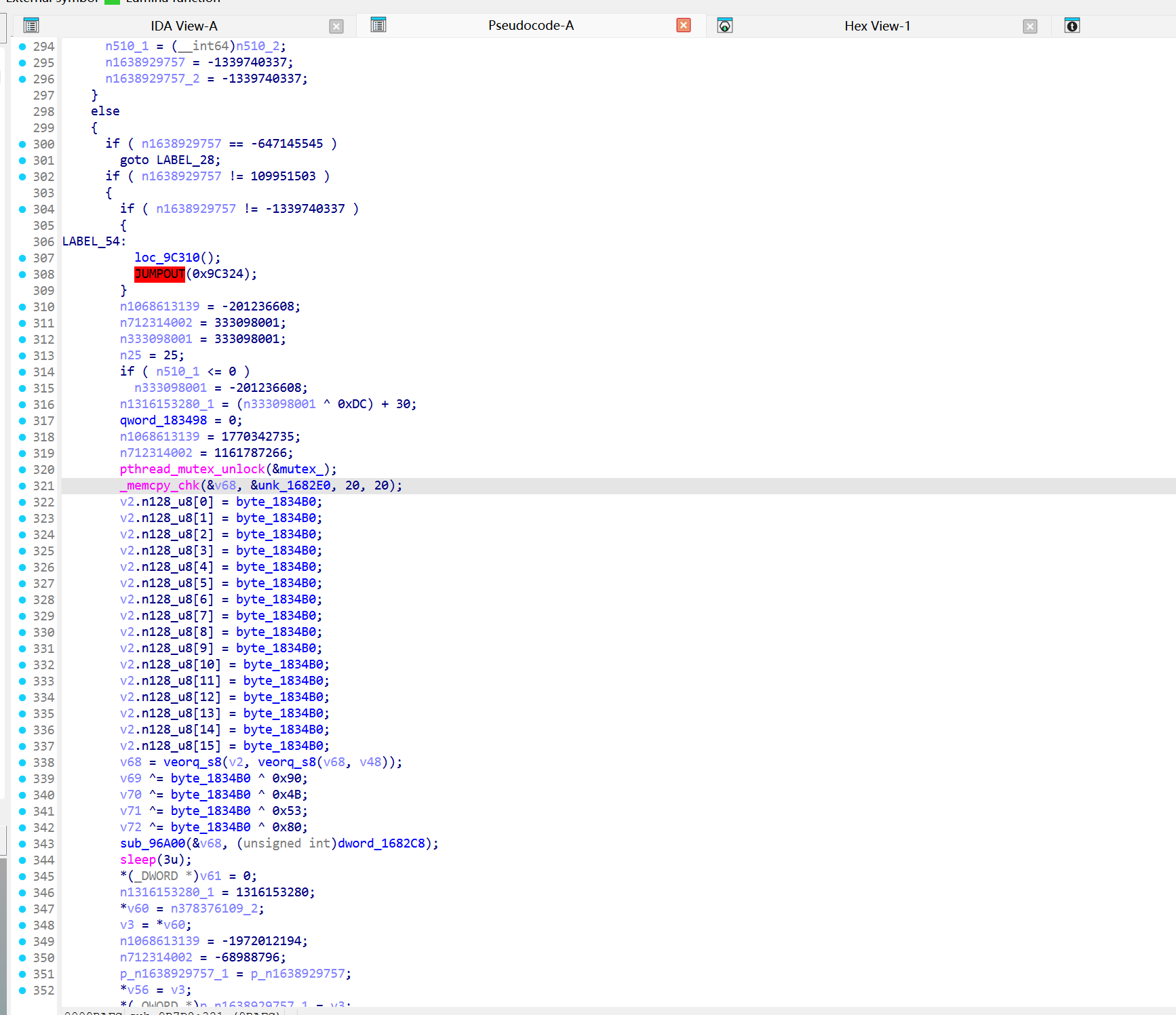
跟踪到0x9AD68 ,这一块结合codex进行分析
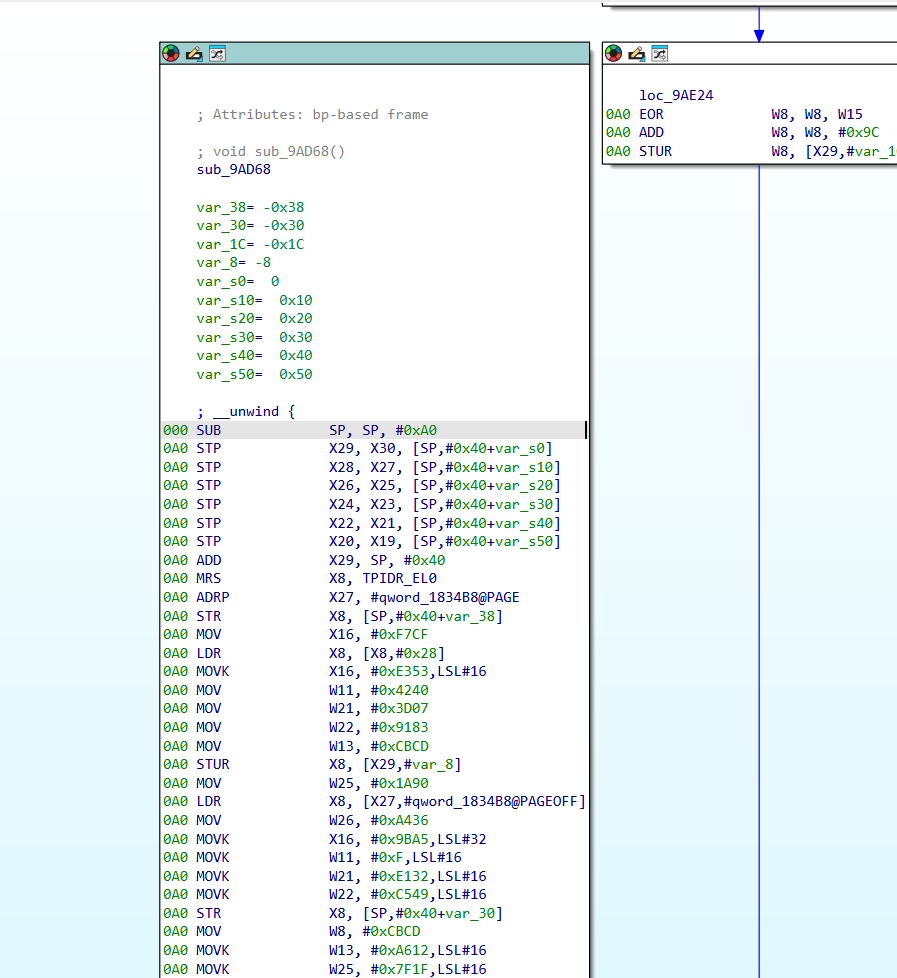
0x9AD68 - 0x9ADB0很明显是个序言
在分配栈空间和初始化魔数
比如
0x9AD94 - 0x9AE10在进行一些常量设置,结合后面分析得出大概是这样的
核心的分发逻辑在0x9AE30 - 0x9AE6C
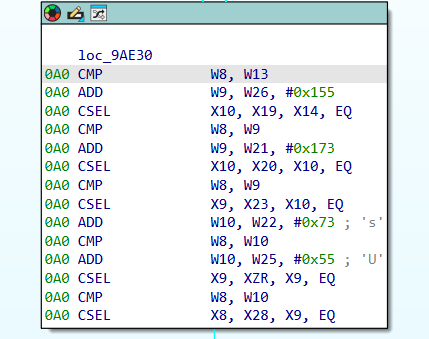
0x9AE1C - 0x9AE2C进行状态迁移转换
Entry 0 (0x9AE14) : slow-path
把返回地址向后推 0x30 字节,RET 后 CPU 跳到进入 Tick 时 LR 值 + 0x30 的位置。但 Tick 进入时 LR = 0x9AEFC(BLR llabs 的下一条,被保存在寄存器未被改过),推 0x30 , 跳到 0x9AF2C,那是 Tick 自己函数体内部。
LR用来保存函数返回值,跳转到某个寄存器里保存的地址,并把返回地址保存到 LR/X30
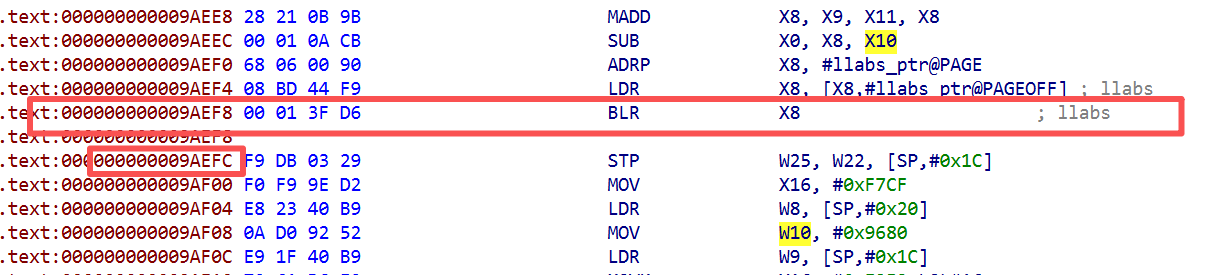
回到 0x9AF2C 后代码继续执行 entry 5 的后半段,再次 B 到 dispatcher,第二次分发时 W8 不再匹配任何 valid state,落到默认 entry 7。
以下分了几个entry,下面要穿起来理解但理解某个entry可能不太好理解
Entry 1 (0x9AF44) : baseline 初始化判定
首次 Tick:baseline==0 ,选 entry 2 写 baseline
非首次:baseline!=0,选 entry 5 检查 10 秒
Entry 2 (0x9AE88): 初始化 baseline
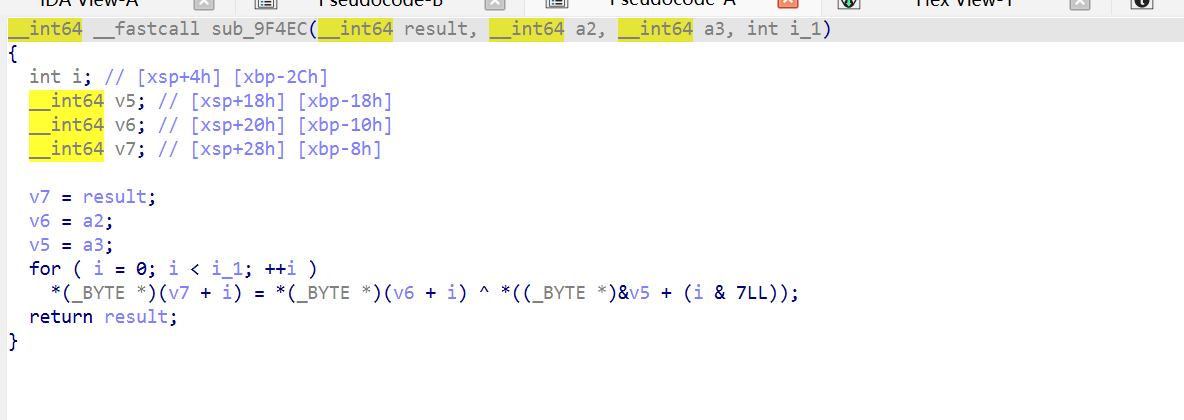
这是唯一写 qword_1834B8 的地方(在 Tick 内部)。只在首次调用 Tick 时执行。
这段是 Tick 反调试的初始化 baseline 时间戳分支(首次运行时建立基准时间)
Entry 5 (0x9AEBC) : 10 秒 diff 判定 核心反调试
常量:
Entry 4 (0x9AF60) : 正常 epilogue(fast path 出口)
标准 epilogue stack canary 验证。fast path 出口是这里(指的是没被调试过)。
Entry 7 (0x9AE70) trap
loc_9AE68 实际是 dispatcher 最后两条指令的机器码(LDR X8, [X24, X8] + BR X8):
合起来读0xD61F0100F8686B08。
这是 ARM64 指令字节被当成数据地址读取,BLR X1 跳到不存在的内存 , MEM_INVALID 导致 SIGSEGV。OLLVM 的骚操作 , 用自己的指令字节做陷阱指针。
正常运行流程:
本质是一个反向心跳机制: 反调试线程每 3s 证明还活着,如果证明中断 ,Tick 自毁。
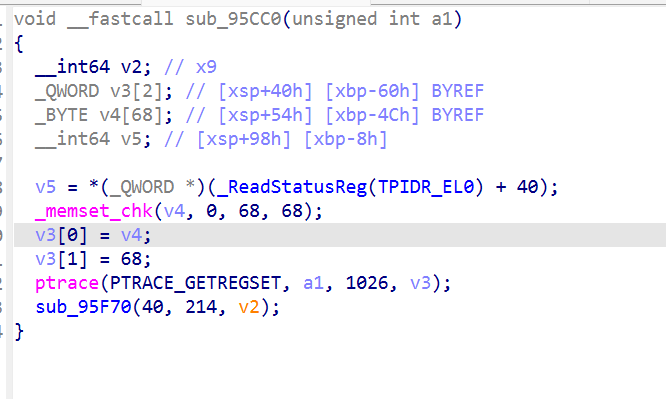
内联 SVC 的反 hook 细节
Tick 里 clock_gettime 不走 libc,而是 inline SVC
Frida Interceptor.attach(libc.so, "clock_gettime") 完全拦不到。要拦这个 SVC 必须用 Stalker 级别指令扫描,开销大。
发现了 OLLVM 标准结构,实际工作只在 entry block 里。dispatcher 纯粹是混淆。
先找 dispatcher 边界 + jump table 基址
工作原理博客,不久前才稍微复习了ollvm,用上了刚好
简单学习ollvm混淆&polyre例题解析 | Matriy's blog
angr符号执行对抗ollvm - Qmeimei's Blog | 探索一切,攻破一切
既然是OLLVM CFF ,我们需要找dispatcher,OLLVM CFF 把它变成巨型 switch
每个 basic block 变成一个 entry
例1:
例2:
所以可以得到一个通用流程
用 Unicorn-style 模拟 dispatcher,建立 state到 entry 映射,拿博客里的改就行
这里手动找了序言,放进去了,后面有自动化的版本这里只为了验证
输出:
魔数对应如上
其中的prologue_static_regs 怎么填?看 prologue 里的 MOV W19, ...; MOVK W19, #..., LSL #16 序列,把每个寄存器最终的值算出来。手动算或用:
trace cold-start 链
知道 state到entry 后,从 prologue 的 INITIAL_STATE 开始 trace,就是之前的流程
XOR_K 和 ADD_K 在 dispatcher 入口,比如 sub_97B6C 是 EOR W8, W8, #0x8D; ADD W8, W8, #0x8F。
遇到 CSEL 的 entry, 它依赖一个全局 byte(如 byte_183518 = 反调试 flag)。Cold start 时这些 byte 全 0,所以总是走false 分支。trace 一遍 cold-path 即可。这个我的博客里也提到怎么处理
Patch dispatcher 短路成线性
每个 entry 末尾的 B 0x97C24/97C28 替换成 B <下一个 entry>。选一边
prologue 末尾的 B → dispatcher 也要改成 B → 第一个 entry 的 work 入口(跳过 dispatcher 整个 CSEL chain)。
最后重建函数边界:
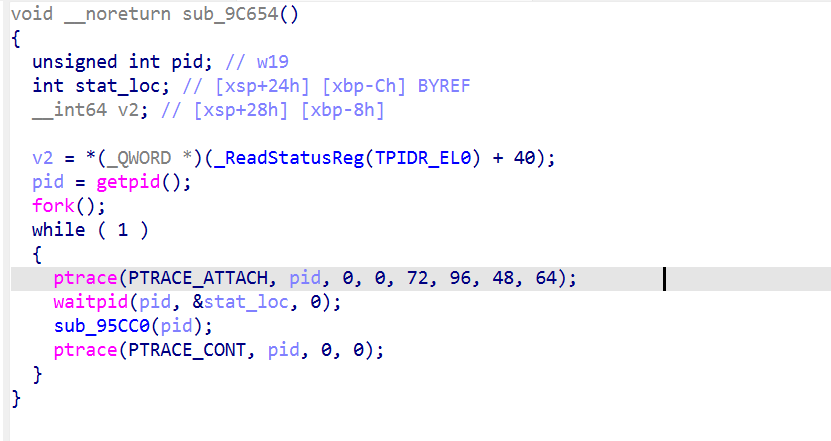
完整代码:
初始状态分析:
用 ollvm_cff_solver 解出的 21 个 (state→entry) 映射:
Cold-start 链:
11 个 patch:
执行后 F5 出 伪代码,17 个工作调用可见,揭示了完整的Godot注册逻辑。
效果
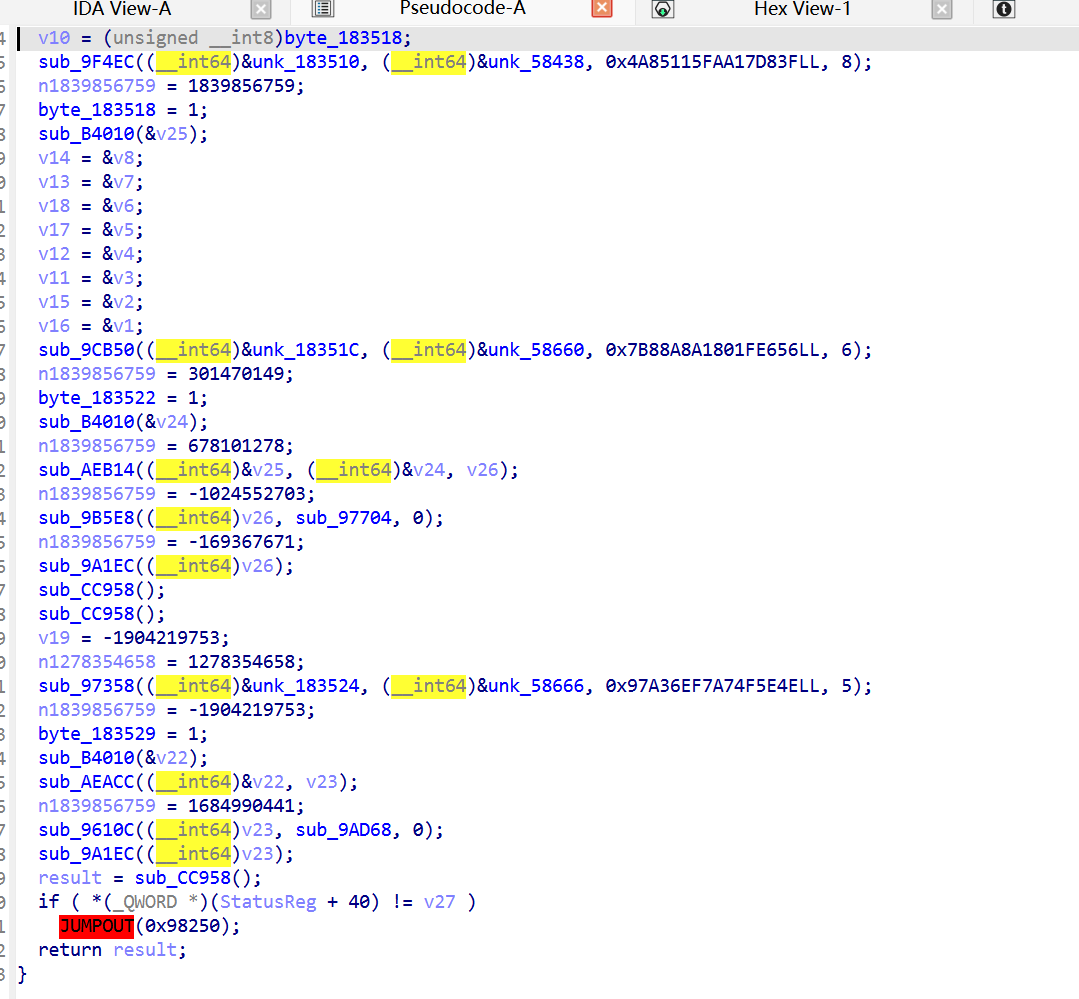
这是用 OLLVM CFF patch 方法对付 Tick 函数 (sub_9AD68) 的脚本。逻辑跟之前的同款,只是针对 Tick
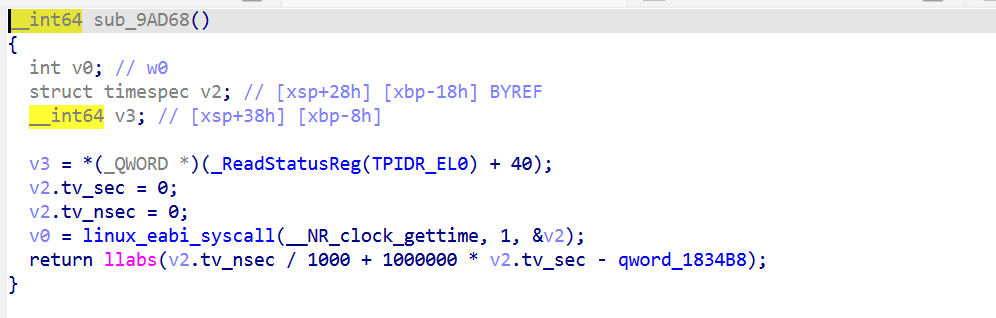
可以看到清晰的代码
ps:最后观察了一波主要分两种混淆这里 一种是写死的跳转 一种是条件跳转,这里只是分析,其实还是手动patch,让AI分析
这个是个更复杂的OLLVM(OLLVM CFF + 运行时状态机),依赖 mprotect sub_9AD3C 返回值+ byte-compare loop
因此思路是用Unicorn 跑出真实 cold-path + 静态 patch 完全线性化
为什么需要 Unicorn?
前面的OLLVM 的 CFF 是可静态 trace 的:
区别是 state 来源是静态常量还是运行时数据
ADR+BLR:正常函数调用常写成 BL 目标地址,但 OLLVM/混淆器可能先用ADR 把目标地址算到寄存器里,再用 BLR 寄存器调用。这样会把一个直接调用伪装成间接调用
怎么看出 next_state 来自运行时:
syscall 返回值决定下一个 state
再比如
这些都是运行时探测,静态没法预测。所以必须 Unicorn 跑,看实际命中哪些 entry。
写个 grep 工具扫整个函数,这种 BLR CMP CSEL B 的三连就是运行时状态转移
用之前的CFFSolver可以初步探测一下
这 17 条映射告诉我们 dispatcher 能跳到哪些地方,但不告诉你它实际跳了哪条。要拿真实链必须 Unicorn 跑(CSEL 依赖运行时探测结果)。
其实就是:
比如next_state {0xfbe35076, 0x698549b1},取决于 W0W0 取决于 mprotect / openat 的真实返回值, 内核行为/文件系统状态决定,编译期/静态分析无法预测 ,我们无法预测,之前的Tick 我们是手动分析和选择了一个分支,但是这里全是
用 Unicorn trace 实际执行
让AI搓一个脚本,准备好got表,然后模拟执行
这脚本把 sub_9B7D8 的所有 syscall 替换成永远成功的 stub,让 Unicorn 实际跑一遍。CSEL 拿到 stub 返回的 0 永远走 cold-path(无调试), 记录 PC 命中 entry 的顺序 ,得到真实链
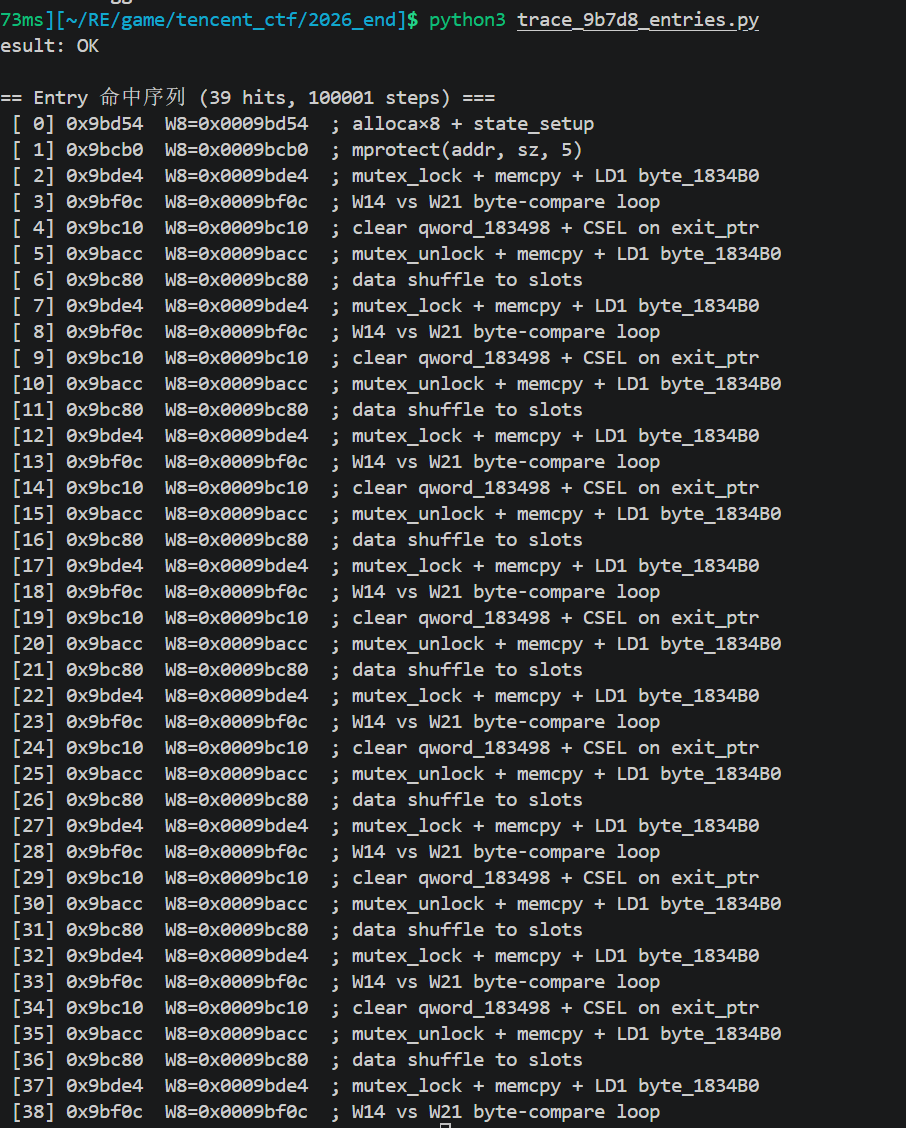
Phase 1: 0x9BD54 → 0x9BCB0
Phase 2 (loop): 0x9BDE4 → 0x9BF0C → 0x9BC10 → 0x9BACC → 0x9BC80 → 回 0x9BDE4
找每个 entry 的 dispatcher 出口
不是所有 entry 都直接跳回 0x9B93C/934/938。有些经过中转:
发现多个 entry 共用 dispatcher 尾巴。如果 patch 共用尾巴,会破坏多个 entry。所以必须 patch 每个 entry 自己的汇入点,不要碰共用尾巴。
效果
完整伪代码
这里自己想写一个批量去混淆的脚本失败了,想想也对,腾讯在用的混淆怎么可能这么轻松给去了,于是用unicorn和手动分析去找patch列表
重新分析下,因为中间被搞懵了,后面的patch列表都是unicorn+手动分析得到的
原理性部分
来自个人博客
简单学习ollvm混淆&polyre例题解析 | Matriy's blog和angr符号执行对抗ollvm - Qmeimei's Blog | 探索一切,攻破一切
把OLLVM处理过的反调试函数还原为 F5 可读的线性 C 代码。之前解完发现还有几处混淆漏了,上面的代码好像不是非常通用,经过分析发现
OLLVM CFF 主要有两种派发器实现,底层目的相同(隐藏控制流),但具体形态不同,去混淆策略也不同。
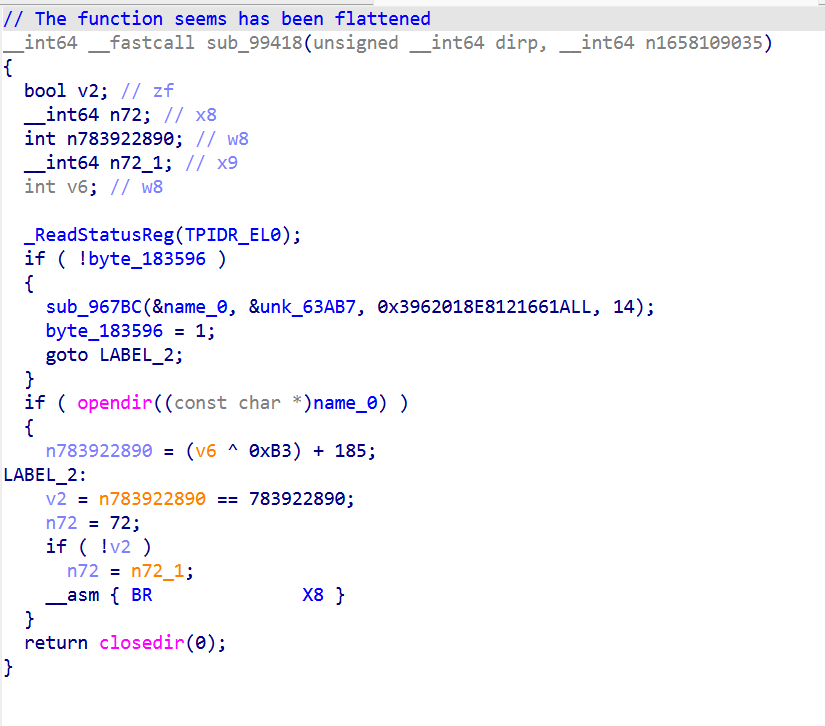
第一种: jump-table 表驱动(Tick / sub_9B7D8 / sub_9C654 / sub_9AF98 / sub_99418)
每个 entry 末尾:
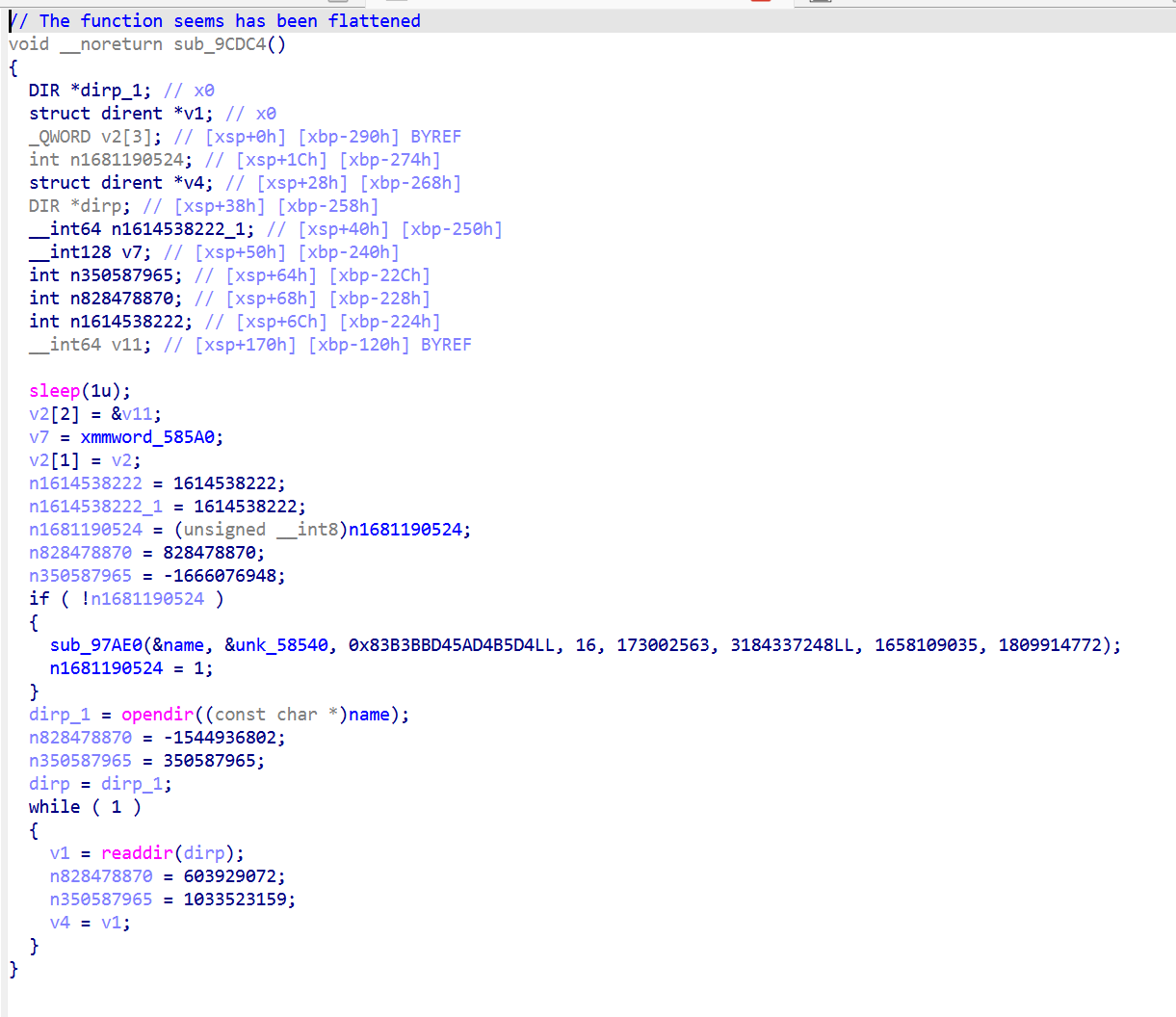
第二种: chained-conditional 链式条件(sub_9CDC4)
用一堆按大小组织的CMP + 条件跳转来查找当前 state 对应的真实基本块
可以看这篇文章:f80K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6K6P5h3&6@1K9r3g2K6K9i4y4Q4x3X3g2@1L8#2)9J5c8U0t1H3x3U0q4Q4x3V1j5H3x3#2)9J5c8U0l9K6i4K6u0r3k6X3I4S2N6s2c8W2L8X3W2F1k6#2)9#2k6X3c8W2N6r3g2U0N6r3W2G2L8W2)9J5k6h3S2@1L8h3H3`.
之前的CFF slover解不开这种
每个 entry 末尾:
特征是CMP + B.cond 长链(无 BR Xn),通常配二分搜索。
派发器附近找 BR Xn:
BR Xn 和 B label 的根本区别跳转目标是从寄存器还是指令本身硬编码的,之前讲过
第一种
关于这一种,[原创] 2026腾讯游戏安全技术竞赛-安卓决赛VM分析与还原-Android安全-看雪安全社区|专业技术交流与安全研究论坛,这个师傅有更好的处理方法。
我的是线性化 patch思路这个师傅是修 tab/jpt 表(修 jump_table 使索引连续)
之前实现的是ollvm_cff_solver是第一种,派发器是 state → entry_addr的查表函数,但里面混杂了 OLLVM 制造的死代码。直接 F5 看是一坨 CSEL,看不出到底有几个 entry。解法符号执行派发器,给 state 一个具体值,模拟跑派发器到 BR X8,记下最终的 X8(就是jump table 偏移)。然后从 jump table 拿 entry 地址。
派发器里的 CMP W8, W?中的 W? 都是候选 state 值。扫描派发器,把所有进入 W? 寄存器的常量(MOVZ + MOVK 解算后)当作候选。
找派发器边界:从序言之后第一个 CMP W8, Wn 开始 (dispatcher_start),到 BR X8 之后 (dispatcher_end)。
找 jump table:派发器里 ADR Xn, off_XXXX 的 off_XXXX。
抄 prologue 的静态寄存器值:所有 MOV/MOVK 串解算成 32-bit。
调 solve_all()
第二种
NZCV 是ARM64 的 4 个条件标志位,每条 B.cond 都靠它决定跳不跳
如NZCV = 0x60000000 二进制 = 0110 0000 ... N=0, Z=1, C=1, V=0。
思路是用Unicorn 模拟 CPU 执行函数
二叉树遍历,第二种的派发器是二分搜索树,内部节点是 B.LE/GT 把范围切成两半,叶子是B.EQ跳到 entry。
因此可以BFS / DFS 整棵树,遇到 B.EQ 收集叶子 (state_to_entry),遇到B.LE/GT/NE把目标 push 到工作队列继续走。
下面的可能比较难理解,这里不展开了,有空补充,而且比赛的时候只是分析了,实际上还是让AI分析控制流手动patch的
目标仍是建立某个 state 值到 对应的真实基本块入口
每遇到一个条件跳转,就把目标地址加入 work,之后继续遍历
state mutation
每次 entry 末尾都把期望 next state 的 pre-mutation 值写进 STATE_SLOT,然后 B 回 mutation 头,让派发器算出真正的 next state。
dispatcher 入口加 XOR+ADD 加工成真 state,是 OLLVM 编译期插的混淆,dispatcher 的门口固定的一小段代码,详细可以看
求next_state发现有这样的东西,需要把状态还原回去:
尝试写个自动脚本自己去混淆结果,自动找第一种混淆的entries然后填入用unicorn模拟,自动化的得到patch_list,对于第二种需要收找entries
模块 1:auto_extract_entries() :静态找 entries,扫 [func_lo, func_hi) 找 LDR Xt,[Xn,Xm]+BR Xt 配对
模块 2:CFGTracer : Unicorn 动态 trace, 输出转移列表 [(src_entry, branch_pc, target, NZCV, kind), ...]
模块 3:gen_patches() :根据traces的输出转 PATCHES
一般很多个转移可能是dispatcher
以sub_9c654为例,python xxx sub9c654
输出
manual review needed代表需要人工确认,加上这一条的效果如下
相比下面的手动patch识别其实还有差距,因此废弃了这个方案
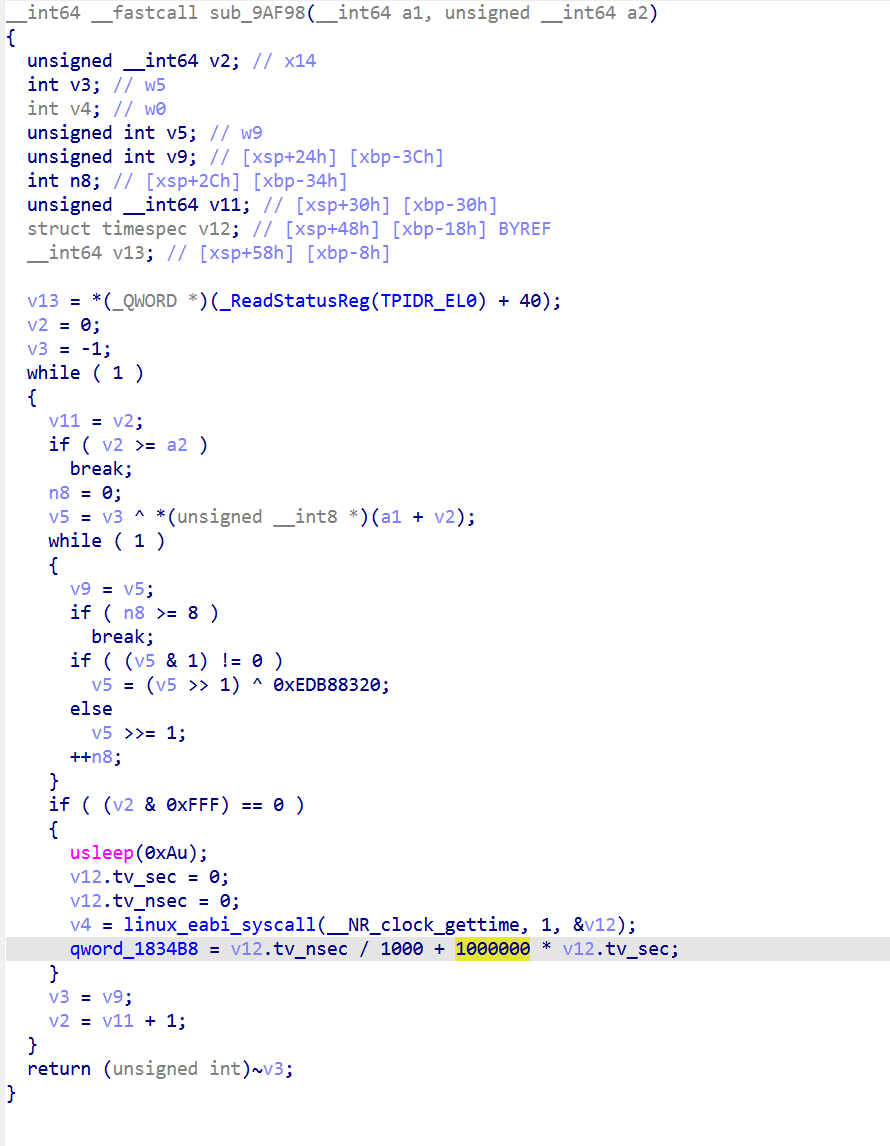

这里应该有个xor解密
肯定还有其它字符串被混淆了,查看这个混淆的特性
要做这件事得解决 3 个子问题: 1. 怎么找到所有解密函数(不止一个,可能 3 个 10 个 39 个不知道) 2. 怎么知道每个解密函数用的是哪种 XOR 算法(有简单 XOR 和加 index XOR 两种变体) 3. 怎么知道每次调用传的参数是什么(src 地址在哪、key 是多少、len 是几)
想法一:看形状不看字节,可以去看序言的形状对比一下正常业务代码还是有区别的
XOR decoder 干的事是这样:
寄存器编号、地址表达式、指令顺序细节可以变,但这 3 个动作必须出现,而且必须按 LDRB → EOR → STRB 这个顺序出现。 只要 LDRB → EOR → STRB 这 3 个都出现,就不管编译器怎么调,照样识别
想法二:分辨两种 XOR 变体 。 数 EOR 个数,有一种混淆多了一个xor i,但是忘记在哪看见的...,直接看汇编里 EOR 出现几次
想法三:解析每次调用的参数,写小型 CPU 模拟器
我们要在调到 BLR 时知道 X0/X1/X2/W3 是什么。这就要模拟 CPU 的寄存器。难点
跑出来:是
为什么是正向走不是反向找
一开始写的是反向找,从 BLR 往回扫,找最近一次设置 X0/X1/X2 的 MOV 指令。但是
也可以看到反调试的一些字符
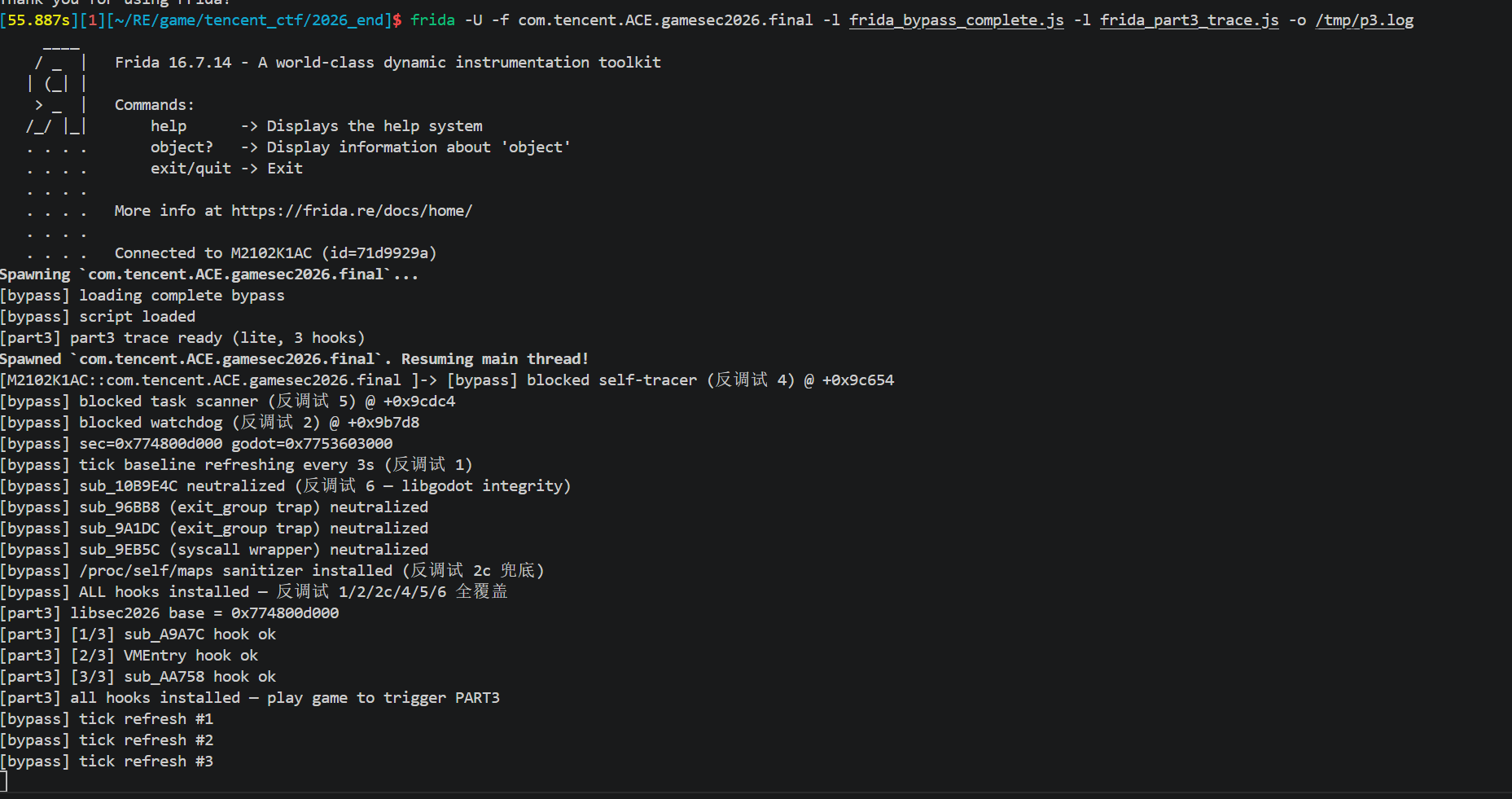
使用frida会出现花屏10s退出等现象,这里主要使用静态分析方法,可以使用一些trace方法比如stalker等,以下包括分析及对抗方法
游戏画面出现马赛克类似,看起来像 shader 损坏,仅在 Frida 实际 hook 时出现,但是起一个空的frida又是正常使用的,一开始以为是inline svc搞了什么东西,后面分析了一圈实在找不到了搜了一下godot机制
可能是如下的问题(我的设备是小米11pro android11,如有相同现象可以跟我讲,初赛也没碰到)
导致后面几个part去发生碰撞验证token和flag同时出现效果图的时候看不出来

解决方法
对frida去调godot会产生这种现象,难以解决,可替代的方法是直接编译一个二进制去执行,用NDK编译的外部二进制注入调试
二进制调试示例代码:
这是唯一写 qword_1834B8 的地方(在 Tick 内部)。只在首次调用 Tick 时执行。
下图为Tick分析章节去混淆后的代码,可以清晰地看到反调试
Entry 5 (0x9AEBC) : 10 秒 diff 判定 核心反调试
qword_1834B8在第一次 Tick 调用时被初始化为当前时间。
fast path 与 slow path 的差异
slow path 不是显式 abort(),而是故意构造的 garbage W8 值让二次 dispatch 落到没初始化的 entry 导致跳到 0xD61F0100F8686B08 (BR + invalid) → SIGSEGV。
正常 60fps 游戏每帧应在 16ms 内 tick 一次。两次 tick 间 10 秒 ,两次 tick 间 10 秒 就是大概率有人在干预。
最简单的就是pacth,0x9AE14改成普通 RET (c0 03 5f d6),k可以在二进制patch,但是打包不方便,可以使用运行时frida_patch逻辑每 3 秒把 baseline 改成当前时间,diff 永远 = 0 < 10s 永远 fast path,不会被kill(这里还包含了其它模块的代码)

当然还有其他方案,比如不用frida,直接编写纯C去调试
patch baseline 入口 ,0x9AE9C 加 LDR X12, [X27, #0x4B8] + 0x9AEB4 CBNZ X12 检查 ,保留 baseline 逻辑,只让 trap 不触发
Frida hook clock_gettime,拦截 __NR_clock_gettime 系统调用,需 Stalker,且开销大。
sub_9B7D8 里的 mprotect(addr, len, 5)调用0x9BCC4
函数图如上图所示
原理
如果 Frida 等工具用 inline hook 修改了 exit(修改字节码需要先把页设为 PROT_WRITE),那这页可能:
最简单的方案就是不要去inline hook exit(),一个个函数去hook 对应详细的反调试去分析
hook mprotect 强制返回 0,Interceptor.replace(mprotect, () => 0),这里为了演示我们主动去hook exit
方案就是
提前在 exit 上 GOT hook,走 PLT 而不是 inline,mprotect 也不会发现
这里直接看汇编,看反编译出来的代码有误导性,之前搞错了以为是在做什么签名什么的
这俩是通用 syscall(),把调用解码:
这是 inline syscall 的 procfs 扫描 ,用 SVC 直接系统调用,绕开 libc 的 openat,read防 Frida Interceptor.attach('openat'))。
watchdog 把 &v73 当 path 传给 openat,但 &v73 是栈上 16 字节缓冲区,由三层 XOR 解密:

/proc/self/maps,异或出来是这个,那其实逻辑就是
block sub_9B7D8 整体不启动
拦截 SVC 指令本身,Stalker 复杂方案
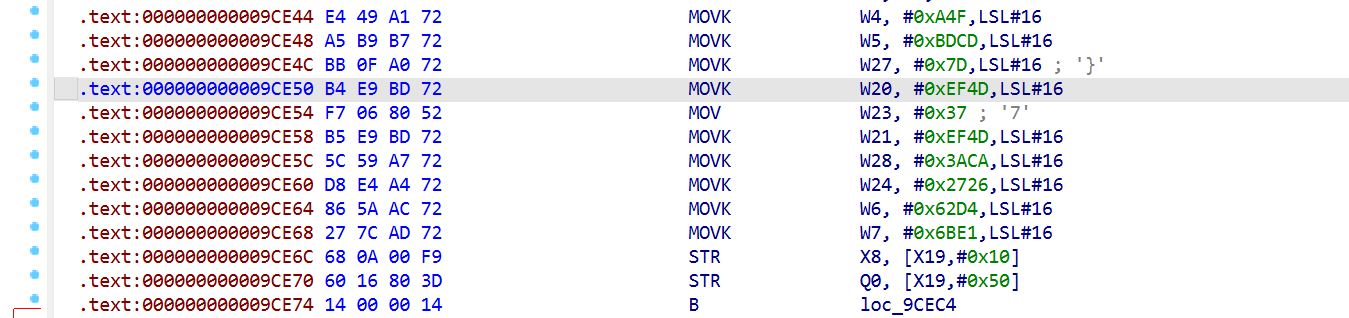
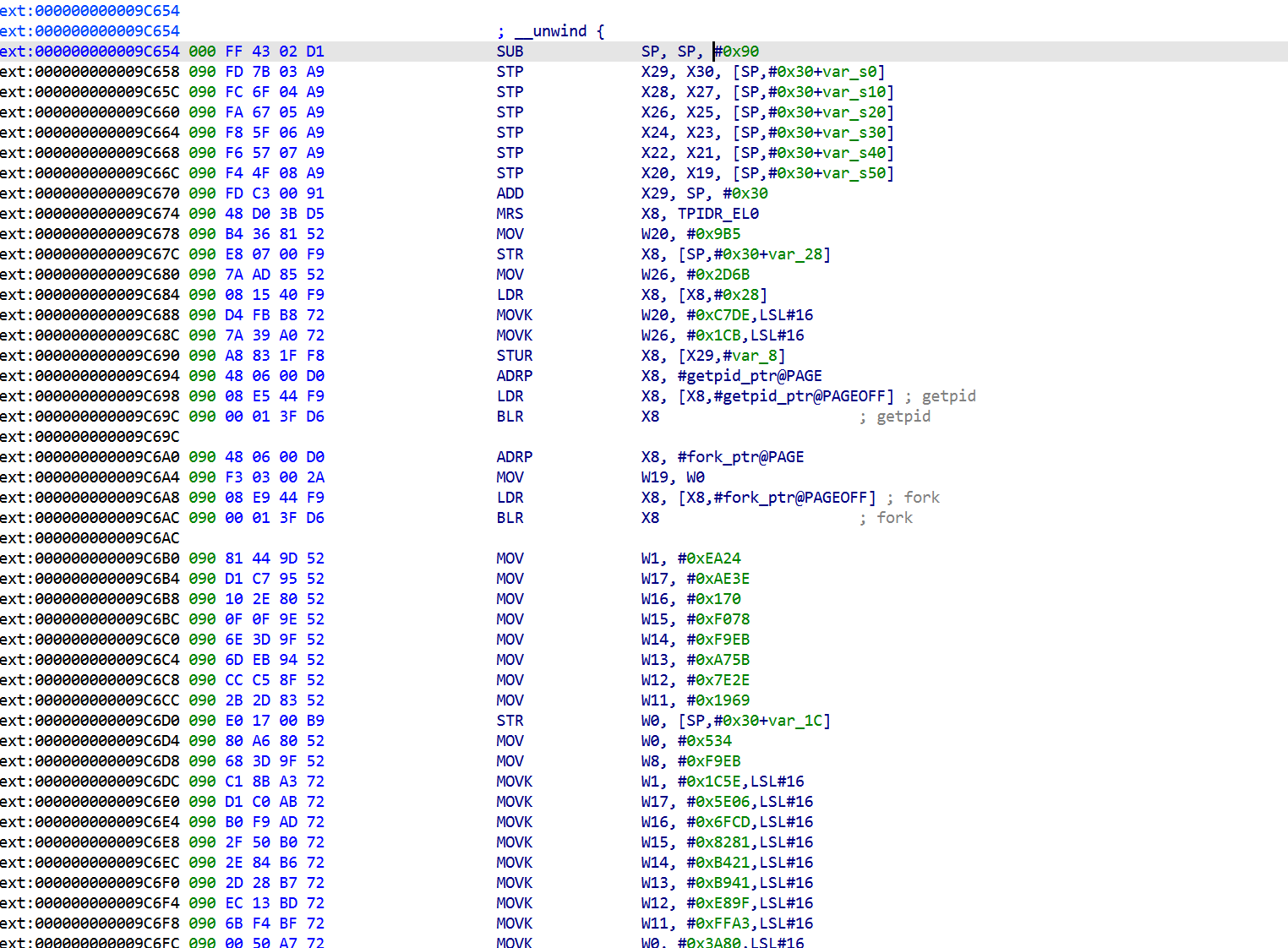
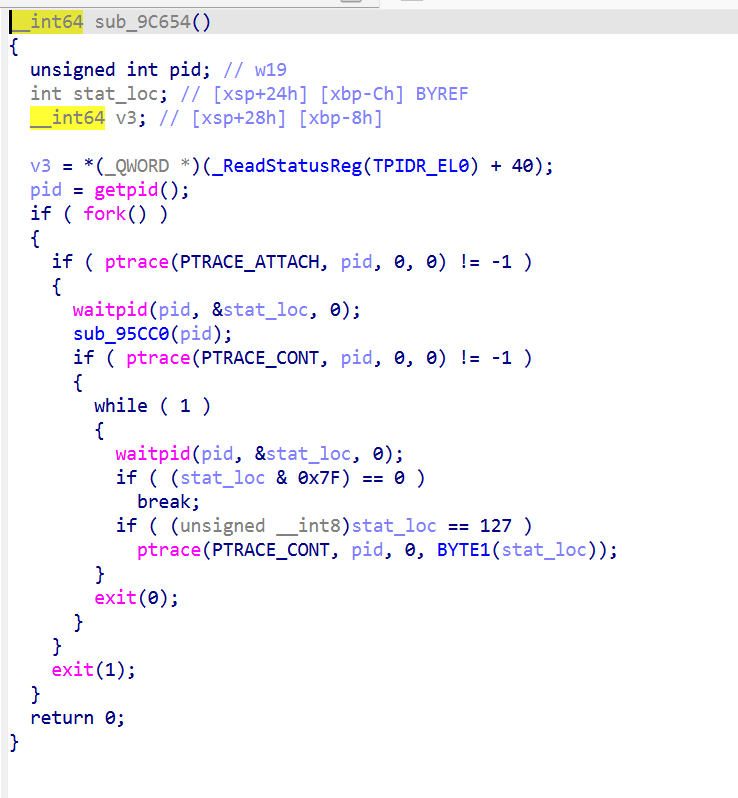
sub_9C654 (fork + ptrace self-tracer)
.init_array在库加载时会启动以下函数
其中
子进程的cmdline仍然是 com.tencent.ACE.gamesec2026.final(fork 后没 exec),所以 ps -A 能看到两个同名进程。
而Linux 一个 task 同一时刻只能有一个tracer。子进程占着 ,外部 Frida工具 attach 都返回 EPERM。
检测:
进程主动 attach 父进程。一旦 attach 成功,Linux 内核把这个父子关系记录到 /proc/31419/status 的 TracerPid 字段里
这也是为什么frida前期调试只能-f启动,不能-n去attach,因为-f时候新建进程,此时 .init_array 还没跑),以下包括两种绕过手段
child 用 exit() 走 _exit_group 终结整个进程组
这里还有个硬件断点,1026 = 0x402 = NT_ARM_HW_BREAK,是硬件断点寄存器组(ARM64 的 DBGBVRn_EL1/DBGBCRn_EL1。
把调试器设的硬件断点全擦了,hbreak 失效。
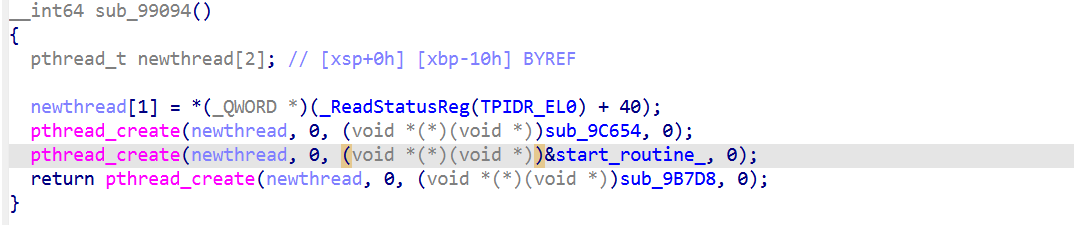
Frida:spawn 模式下 hook pthread_create,让 start_routine == sub_9C654 的调用直接 return(不创建子进程) ,Frida 在游戏跑 sub_99094 之前已经注入。我们 hook libc 的 pthread_create,或者直接使用-f
Method D:kill -9 $TRACER_PID,杀完 child 后,父进程不会因为失去 tracer 而自杀(它对自己的 tracer 是单向检测)
或者
直接命令行kill
单独 pthread 线程(由 sub_99094 创建),扫描/proc/self/task
后面继续分析下去还有混淆
还有个trap机制
不调 abort/exit/raise,而是把黑名单字符串本身当指针解引用 , SIGSEGV:
block pthread_create 创建 sub_9CDC4
hook opendir 对/proc/self/task返 NULL
/proc/self/fd 扫描 linjector 特征
被 sub_9CDC4 主循环每轮调用一次。这个其实跟反调试5是同一套线程
3 个新解密字符串(5 个解码器中第 4-6 号):
sub_99418 完整流程:
Frida agent 注入时,Frida-server 创建 /data/local/tmp/re.frida.server/linjector-helper-32之类的辅助进程并保持 fd 打开。注入完成后,目标进程的 /proc/self/fd/<N> 会有 symlink 指向这个 path ,strstr linjector就抓到了。
对抗方案和反调试5一致,同一套线程,最简单的方法就是把这块调用给block掉
判断逻辑在 sub_9AF98,后面还有一大片混淆
后面去了混淆如下
此外,sub_9AF98 不只有CRC,它还是 Tick baseline 的更新者
也就是说反调试的设计逻辑如下:
sub_9AF98是CRC其中
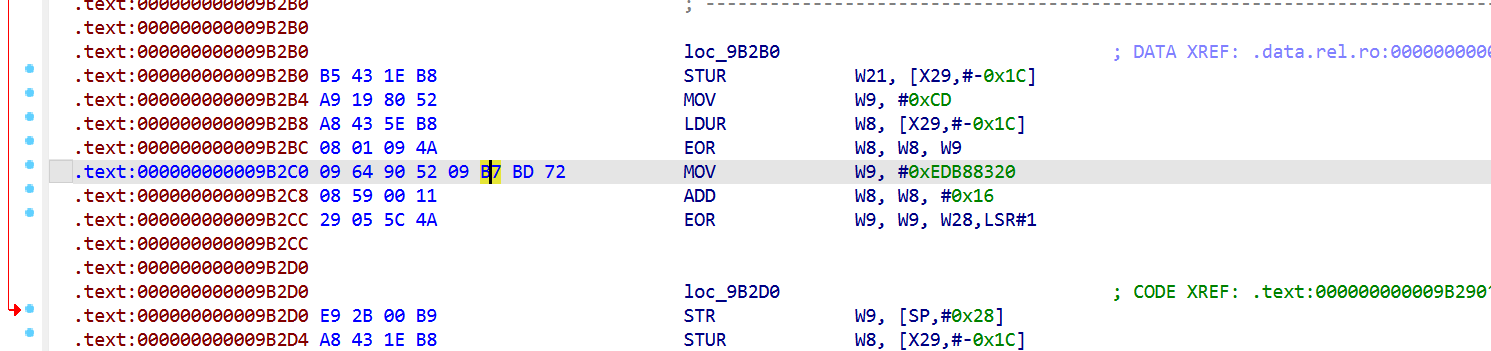
0xEDB88320 = bit_reverse(0x04C11DB7) 标准 CRC32实现逻辑。
加上其他 CRC32 特征:
sub_9AF98 同时做 heartbeat + verify, 形成 :
双重防御:
直接 block sub_9B7D8 watchdog,sub_96A00 不被调,整个流程不跑
sub_10BAB00 = Main::iteration (Godot 标准, 但作者在第一行插入了 sub_10B9E4C() 调用)
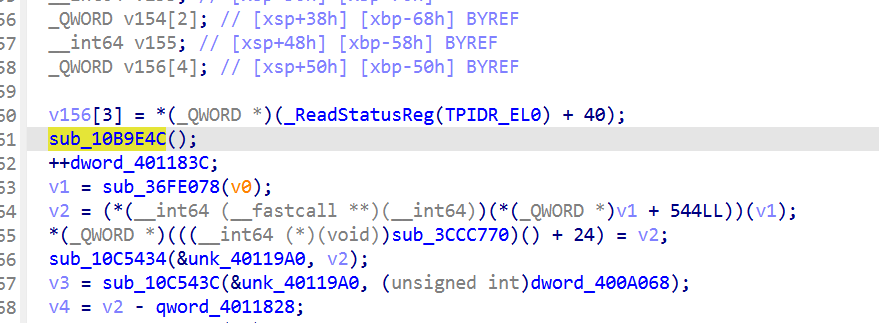
在libgodot_android.so中,被 Godot 标准 JNI 函数 Java_org_godotengine_godot_GodotLib_step 间接调用(每帧)。
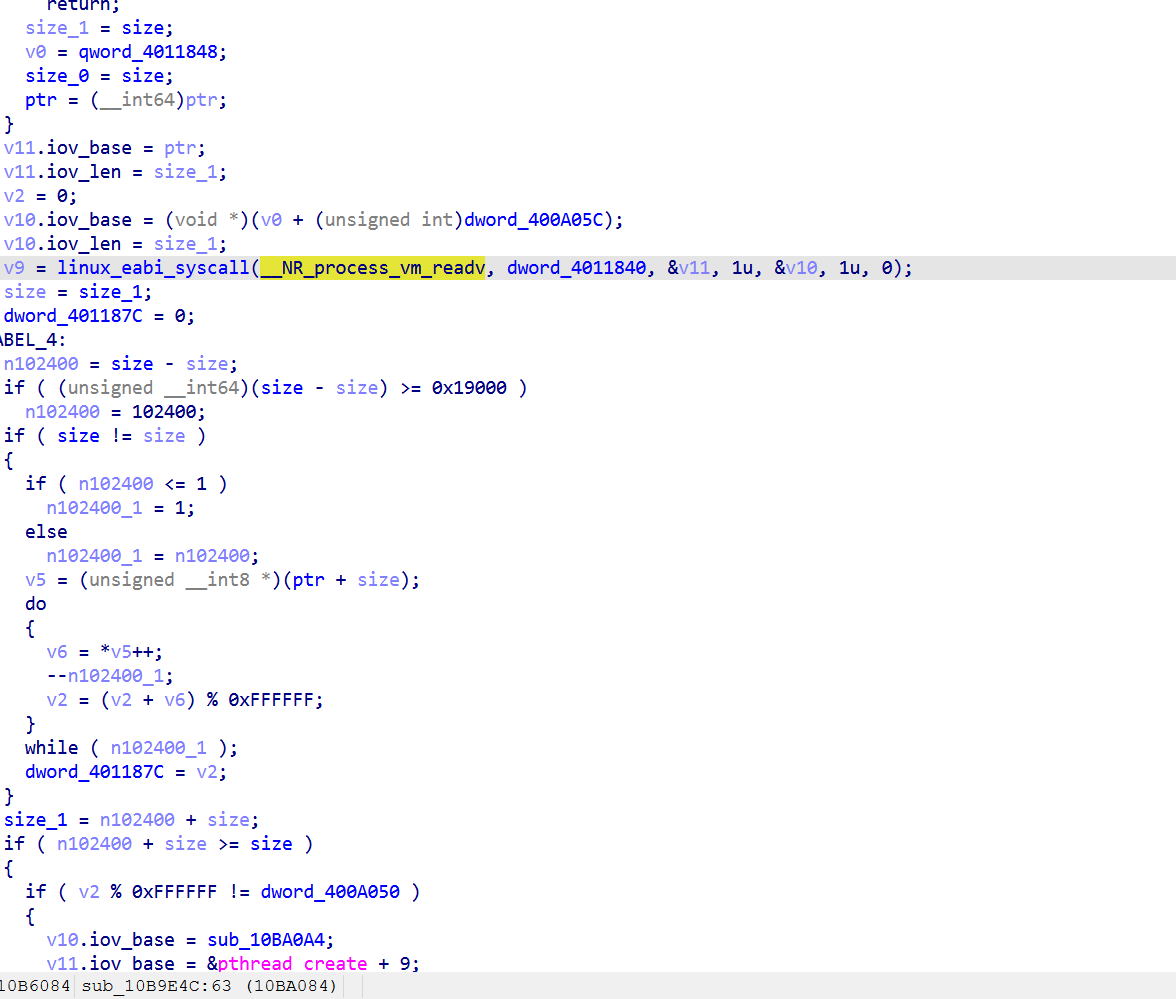
特点:
不依赖 dl_iterate_phdr,直接用 process_vm_readv读 /proc/self/mem
hash 是某种滚动求和
结果 mod 0xFFFFFF 跟 dword_400A050比
dword_400A050 是硬编码期望值
只在第一次调用 v27(s_7) 时执行(初始化qword_4011848)。之后 qword_4011848 非 0,跳过校验,不通过则会自毁

借 Godot 标准退出流程, logcat 看起来像用户主动关游戏
并且经过测试,貌似只有part3的时候会触发,查看伪代码返现这里的dword_400A054值是0xA9A7C针对的就是part3阶段的入口绝对地址。
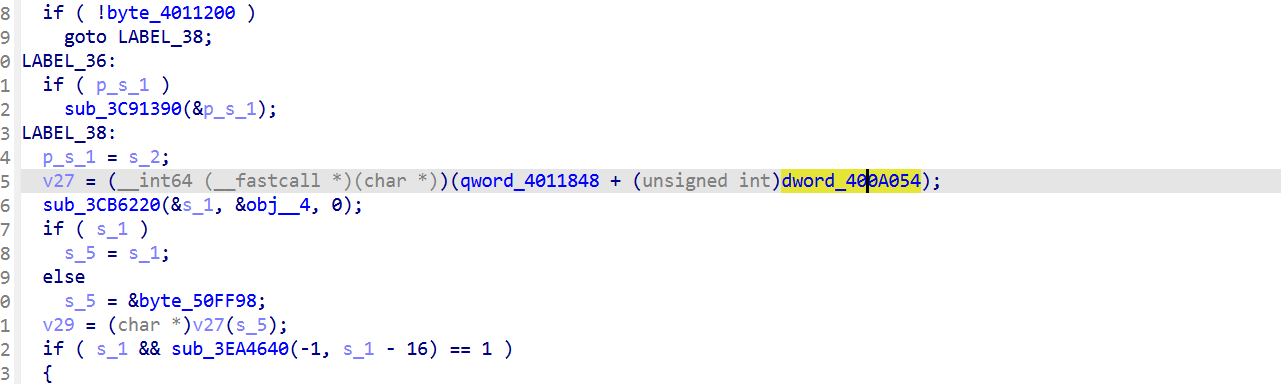
不要用Memory.patchCode 改 libgodot 字节
不然可以让校验函数立刻 return success,不计算
或者hook process_vm_readv,从干净副本读 ,启动时 dump libsec2026 .text 完整副本到自己 buffer,sub_10B9E4C 调 process_vm_readv 时把请求重定向到副本
下面这份代码是hookpart3时用的发现被kill使用了对应的反反调试,监控到触发了反调试,这里使用的是让校验函数立刻 return success这种方法,成功解决了这个反调试

sub_9AD3C是个 7 指令通用 SVC wrapper:


类似的还有sub_9CB30。libsec2026 内部所有敏感 syscall(ptrace, mprotect, openat, prctl等)都走这条,不经 libc。
使用方式(不起part3)
可以加part3的trace不崩
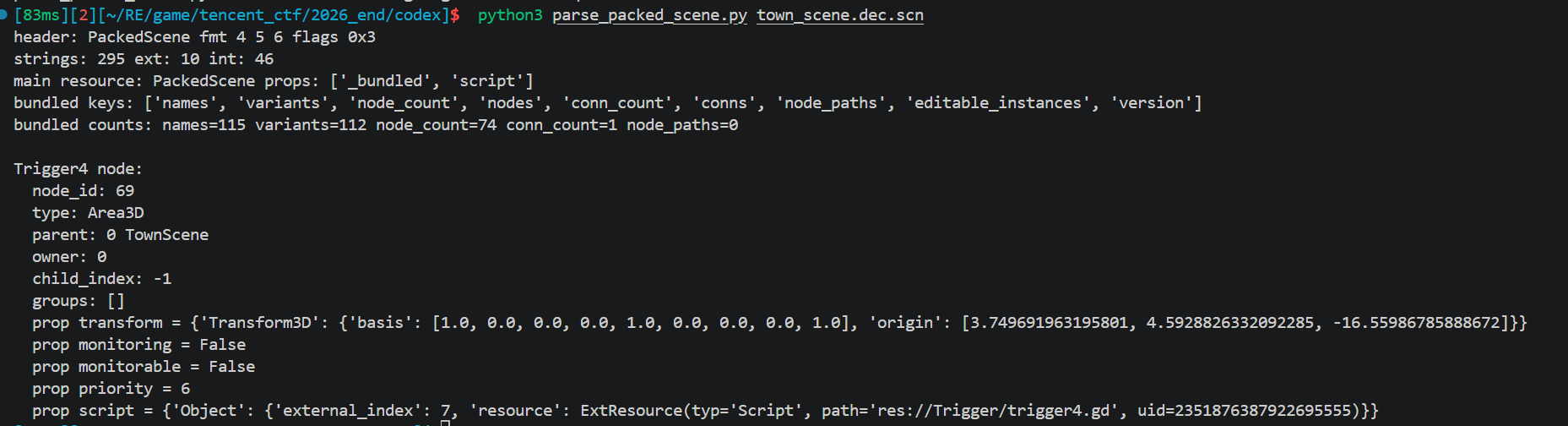
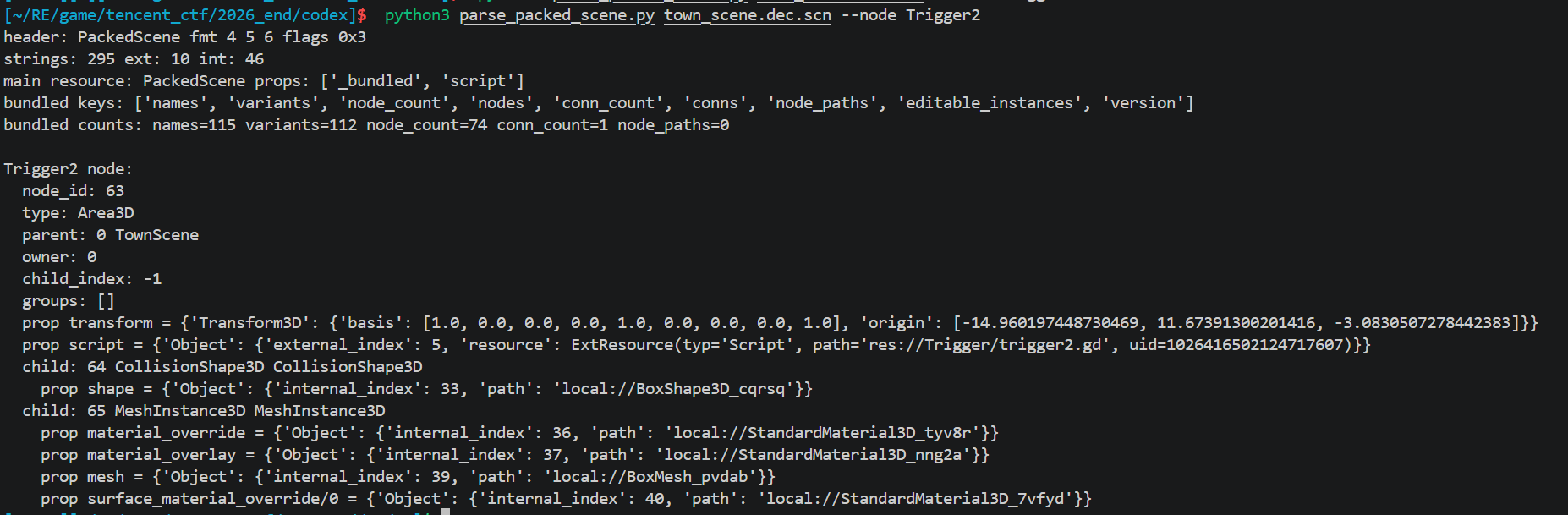
PackedScene 内部是 Godot 自己的二进制格式:
尝试在网上找一些开源工具直接解,但是没找到,解析后能直接拿到每个 Node3D 子类的 transform.origin。
阅读godot源码
godot/core/io/resource_format_binary.cpp at master · godotengine/godot
头格式,编码布局
godot/scene/resources/packed_scene.cpp at master · godotengine/godot
RSRC 头解析
文件起始固定 RSRC magic 后是定长头:
flags 里有几个位特别要注意,否则后面尺寸算错崩盘:
Variant 类型 ID 常量,parse_variant() 用一个枚举 ID 分发,需要的几个:
按上面 schema 全部解析完,对每个 Node3D 子类节点:
跑一遍 town_scene 就能把 4 个 Trigger 和 InstancePos 的世界坐标拉出来
需要先解密出来场景文件
然后
完整代码:
绿色方块,完全在 GDScript 内实现,是一个 8 轮 Feistel 密码:
大致为输入 token,拆为 L+ R,然后过 8轮 Feistel,Feistel的内部大概如下:
密钥用字符串拼接构造
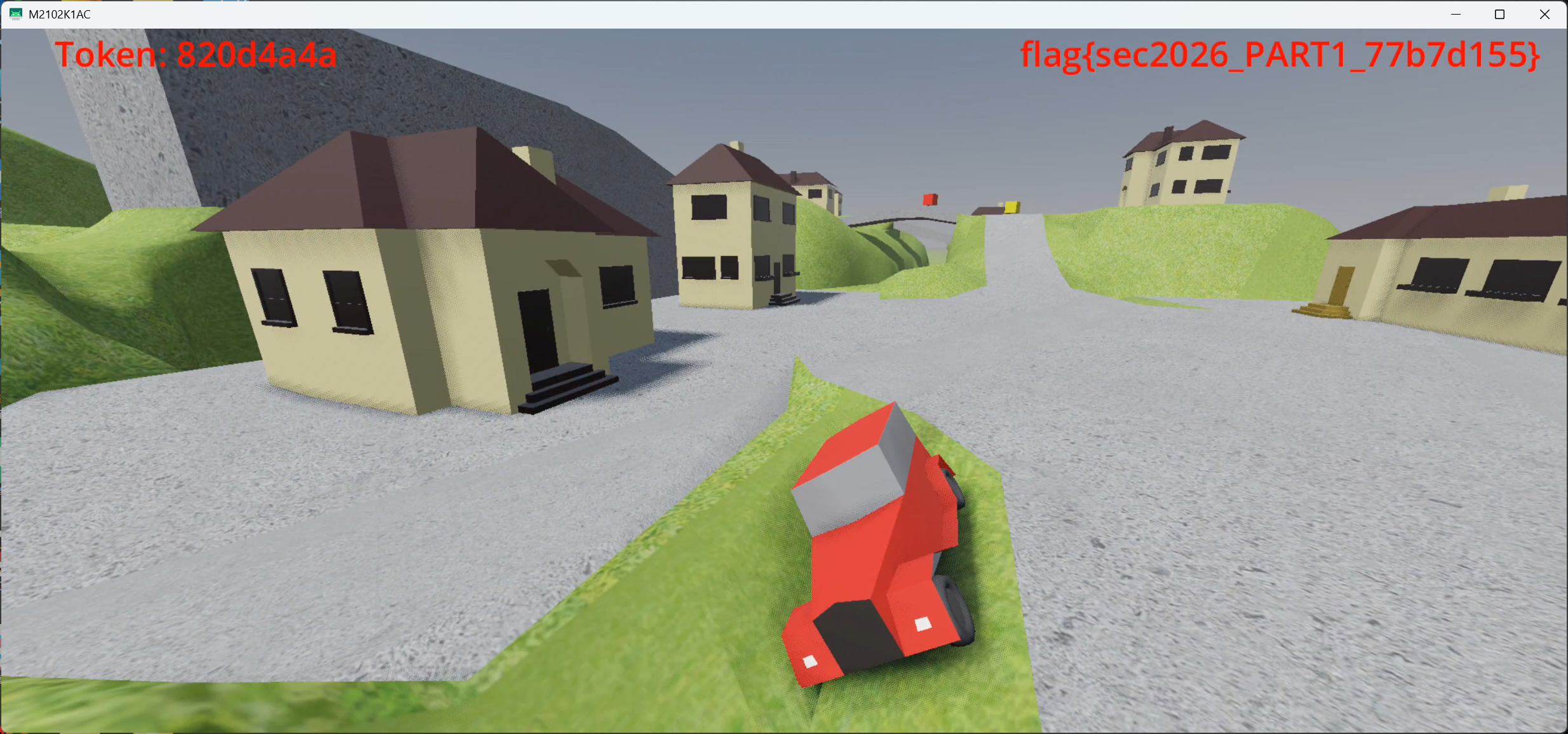
Sec2026_Godot
flag为flag{sec2026_PART1_<8 hex>}
根初赛类似,trigger都在房顶上,要想获得flag需要主动触发碰撞函数,由于之前用Frida hook会出现花屏,因此我们这使用纯C去进行绕过
有一种比较简单的方法是,其实大同小异:
把 Trigger2 挪到玩家车出生点 (8.0, 3.36405, -16.0)。挪靠 ptrace + 调 Godot setter,跟 trigger4_call.c 的范式一致。
链条上每一段都可以从外部直接 hook,越往下游越接近显示 flag,但对应的函数签名也越复杂(要构造 Godot 内部的数据结构)。trigger2_call 选的是最上游的挪车 ,因为只要传一个 12 字节 Vector3,最简单。
从外部进程用 pwrite(/proc/PID/mem, ...) 直接把 Trigger2 对象内存里那 12 字节 transform.origin 改成 (8, 3.36, -16),下一帧物理引擎就该看到 trigger2 在新位置了 ,跟玩家车重叠 ,触发碰撞
不能用纯字节写:Godot 4 PhysicsServer 是 push 模式,光改 Area3D 内 transform 字节不会同步给物理引擎,下一帧 area_overlap 仍按旧位置算。必须真调 setter,让它通过 _propagate_transform_changed → PhysicsServer::area_set_transform 的链路推送。
Godot 4 把 Node 层(场景树里的 Area3D 对象)和 Physics 层(PhysicsServer 内部的物理对象)完全分开存

两边各存一份 transform。PhysicsServer 不会主动去 Node 内存读最新值(pull 模式),而是等 Node 层主动调 PhysicsServer::area_set_transform 把新值推过来(push 模式)。 正常游戏流程是:
既然字节写不行,那就让 Godot 自己执行第 2-5 步,通过 ptrace 让游戏进程跳进 Node3D::set_global_position(Vector3) 函数入口,参数填 (8, 3.36, -16)。函数内部会按上面 5 步走完,PhysicsServer 自动同步。
需要确认这个函数的地址, Godot 中函数符号大部分被 strip 掉,所以
第一个 PT_LOAD 的 p_offset == p_vaddr == 0,所以 file offset == 库内 vaddr。set_global_position 字符串地址 = 0x4178ba
用Capstone 扫 ClassDB::bind_method 注册
Godot 4 的 Node3D::_bind_methods() 内每条 bind_method 编译为 8 条指令 pattern:
BL 的目标是按签名共享的工厂,真正的 method ptr 是它前 4 条指令的 ADR X0 加载值。
输出
Node3D::set_global_position 这个函数机器码,在 libgodot_android.so 里相对文件起始 0x254583c 字节的位置。
验证签名
把 set_global_position 函数前几条机器指令打印出来看,通过 prologue 用了哪些寄存器反推它的参数怎么传
从 ClassDB 注册点找到了 Node3D::set_global_position 0x254583c,但只知道地址,不知道调用约定
读 .so 文件 0x254583c 处的 128 字节,让 capstone 按 ARM64 反汇编,逐条打印直到第一个 RET。
ARM64 AAPCS 调用约定:函数被调用时 X0 是第 1 个参数,X1 是第 2 个,依此类推。X19/X20 是 callee-saved 寄存器。
函数一进来就把 X0 和 X1 备份到 X19/X20,说明 X0 和 X1 都是参数,且要在函数体里反复用到。
X20 是备份的 X1。函数把 X1 当指针用(ldr x8, [x20] = X20 指向的内存读 8 字节):
加起来正好 12 字节 = 3 个 float = 完整 Vector3。
拿到这些接下来就是去替换位置,我们在上一节已经知道几个坐标,我们需要先处理Trigger2的
观察内存发现4 个 Area3D 在堆上连续分配(间距 0xc00 字节)。每个 Area3D dump 时窗口要 < 0xc00 否则越界扫到下一个 area 的 transform,把它误判成自己的。用 0x800 窗口刚好
多次尝试发现 Trigger2 的 origin 字段在对象 +0x3a4。
ptrace-call 传 Vector3 引用(vs trigger4 的整数参数)
传整数 set_monitoring(area, 1),传 Vector3 引用需要先把 12 字节数据写到目标进程能读到的内存,再让 X1 指向它。
代码总流程大致是
后面两个都是类似的思路
编译:
使用方法直接push到手机上给权限执行即可
peek可以查看从外部读运行中游戏进程的指定内存地址,dump 字节出来
后面可以直接拿去验证算法真实性
编译:

原理和之前trigger2一样
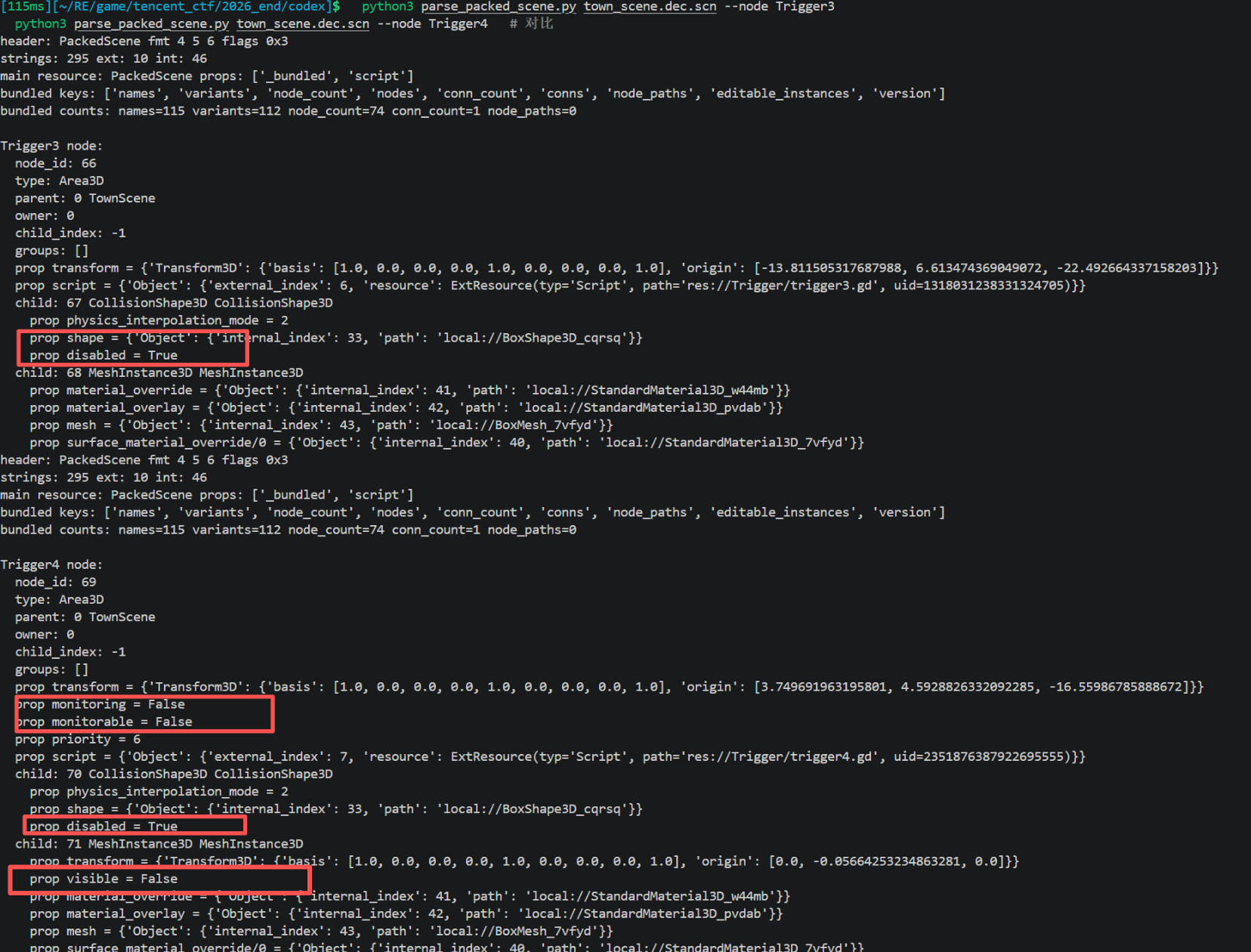
trigger2.gd 默认 monitoring=1 , collision enabled , visible,只是位置高车开不到
trigger3 的 GDScript 结构相同,但初始可能 monitoring=0 disabled=1 visible=0(红色方块可能未开启碰撞属性)
对比一下就知道了
可以试一下强制碰撞
其中set_monitoring(trigger3, true) , 让 area 监听碰撞
ptrace_call libgodot+0x25F94A4 (Area3D::set_monitoring), X0=trigger3, X1=1
Area3D 有两个开关:
monitoring=false 时 PhysicsServer 不会发 body_entered 信号,车进入 area 也没反应。这步把它打开。
注意 set_monitoring(true) 不只是改字段值,会调 PhysicsServer::area_set_monitor_callback 注册物理回调。
还有提携setter代码的定位
之前定位的一些关键逻辑 再libgodotengine.so里
完整代码:
后面可以直接拿去验证算法真实性
trigger3.gd 红色方块,可以看到调用 native Process(buf) 方法
两种解法,但是本质都是获取中间信息推动解密,算法识别
因为一开始先分析的process所以没绕过反调试,但是10s的空间足够我们进行一些调试,获取一些信息
libsec2026.so 在 entry_funcs注册 GDExtension,通过 classdb_register_extension_class_method把 Process 字符串绑定到某个 native 函数。
用 IDA 查找字符串 Process的引用,找到注册调用点。注册结构体第二个字段指向一个 MethodBindCustom vtable,vtable 里含 call 回调。
用 Frida hook classdb_register_extension_class_method打印参数,来找process对应的native函数
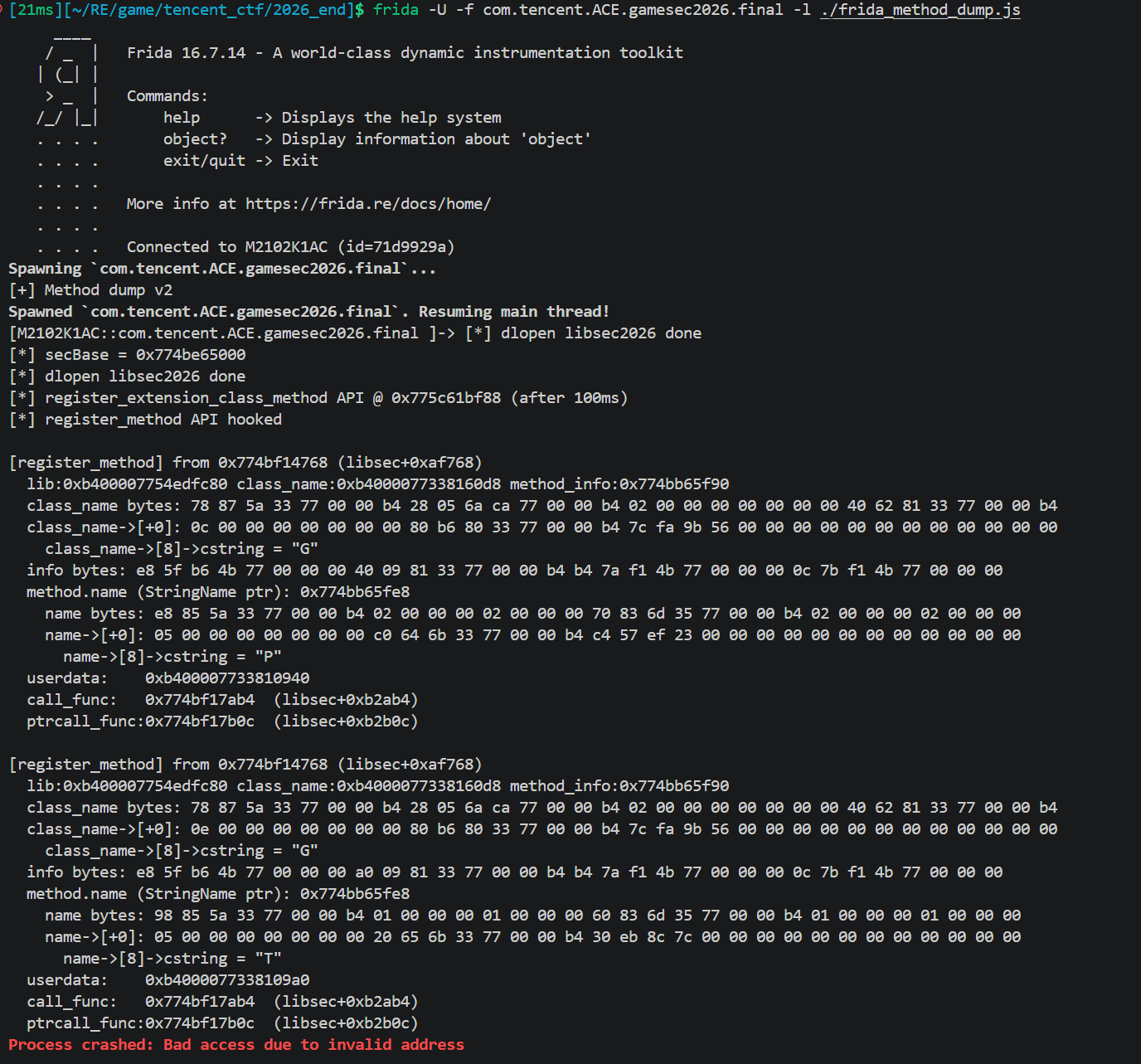
最主要的信息是
这意味着 Process 和 Tick 共用同一个分发函数 libsec+0xb2ab4
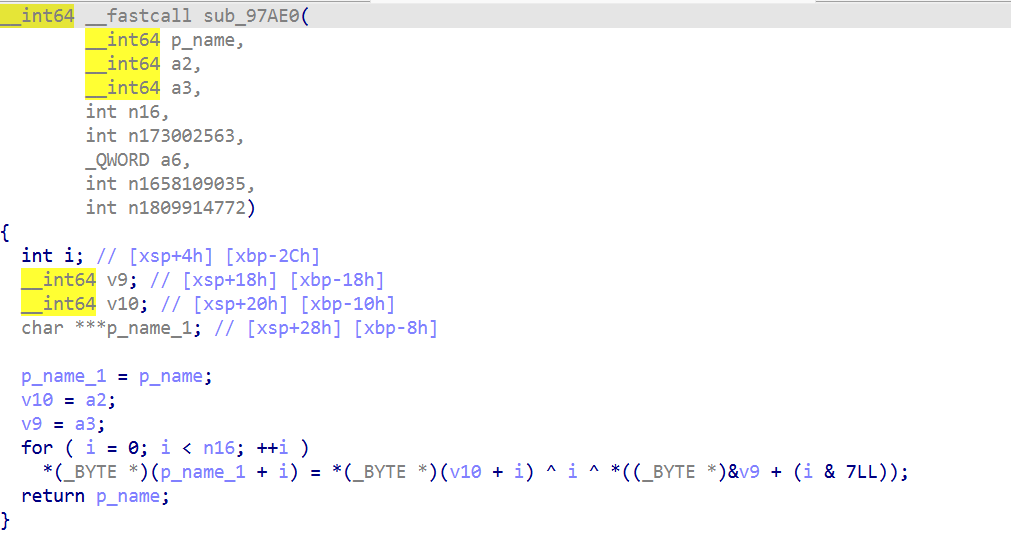
sub_97704内部只做 userdata 解包,真正算法在其调用的Sub_A936C,sub_A936C 又调用sub_A7900(key schedule) 和sub_A7194(cipher)。
同时也发现反调试的端倪
后续定位到sub_97704
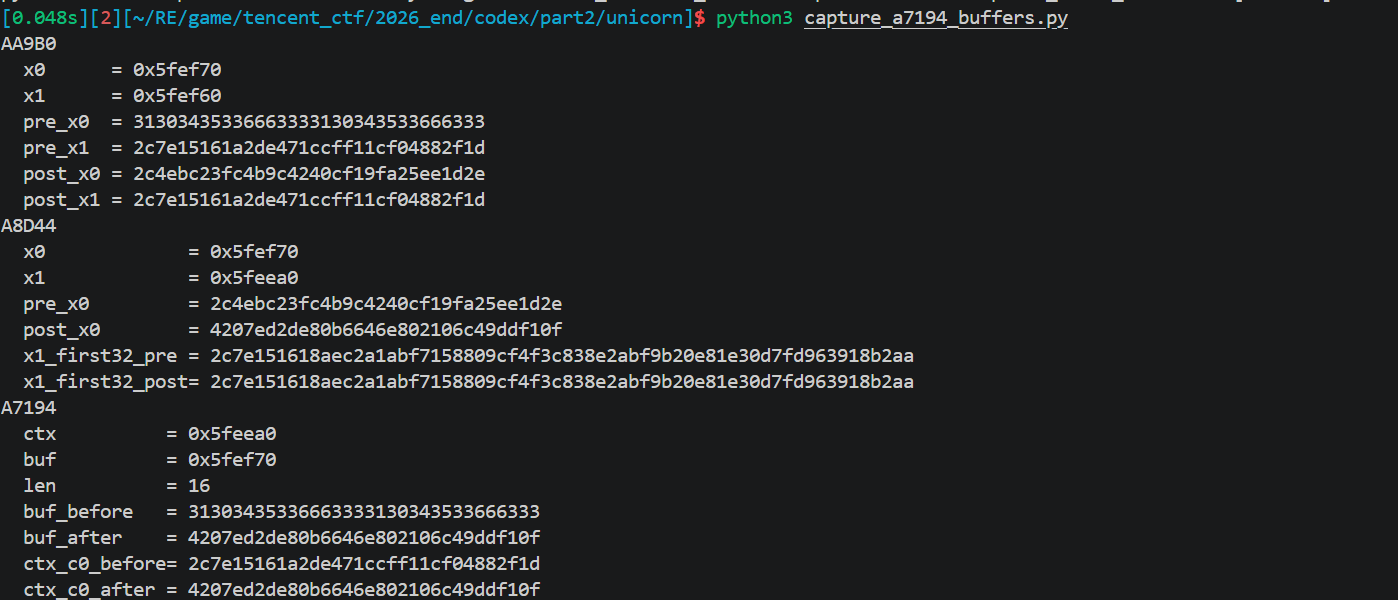
sub_A7194这里一F5就会崩溃
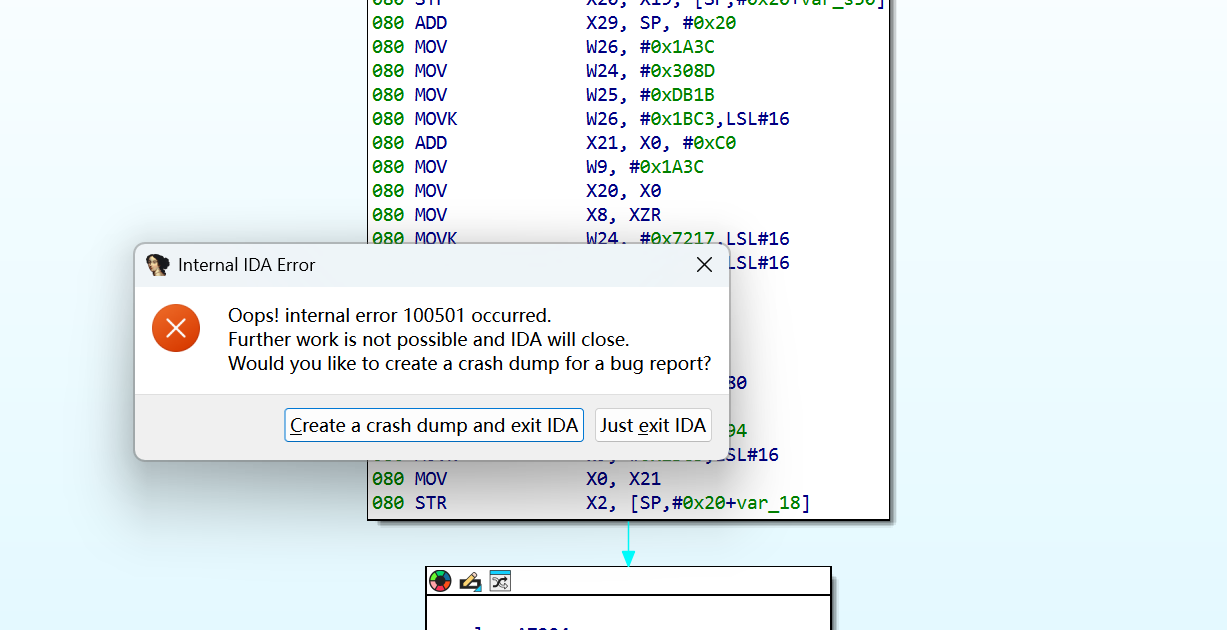
尽量从汇编分析
sub_A7194被 OLLVM 打散,IDA decompile 直接失败,disasm 看到 38 条 dispatcher 指令 + BR X9 间接跳。
做法:
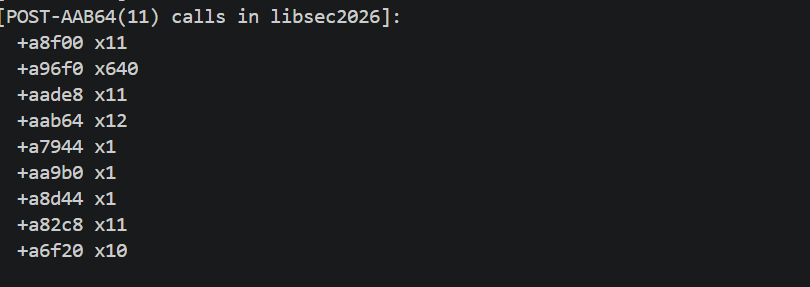
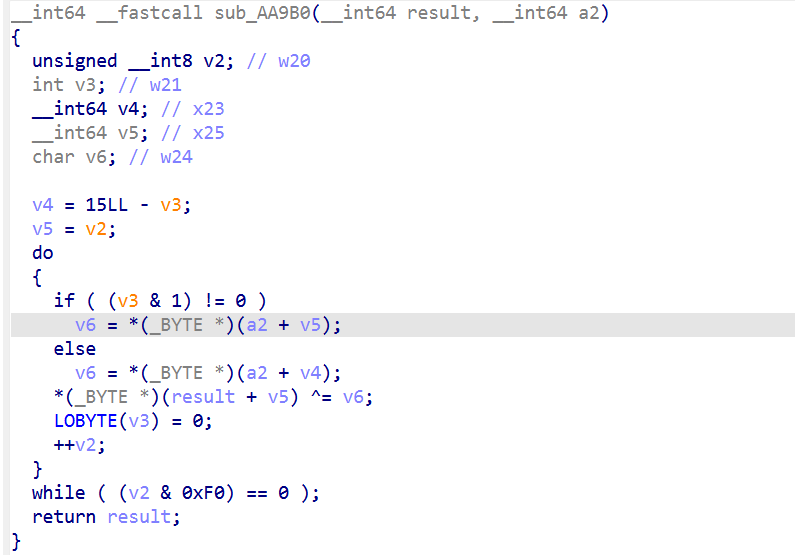
数 subfunction:在 IDA 里把sub_A7194全部直接 callees 列出来,发现几个反复被调用的函数:sub_A82C8, sub_A8F00, sub_AADE8, sub_A6F20, sub_AAB64, sub_AA9B0, sub_A7944, sub_A8D44。这有点像AES。
Frida Stalker call summary 统计实际调用次数。得到:
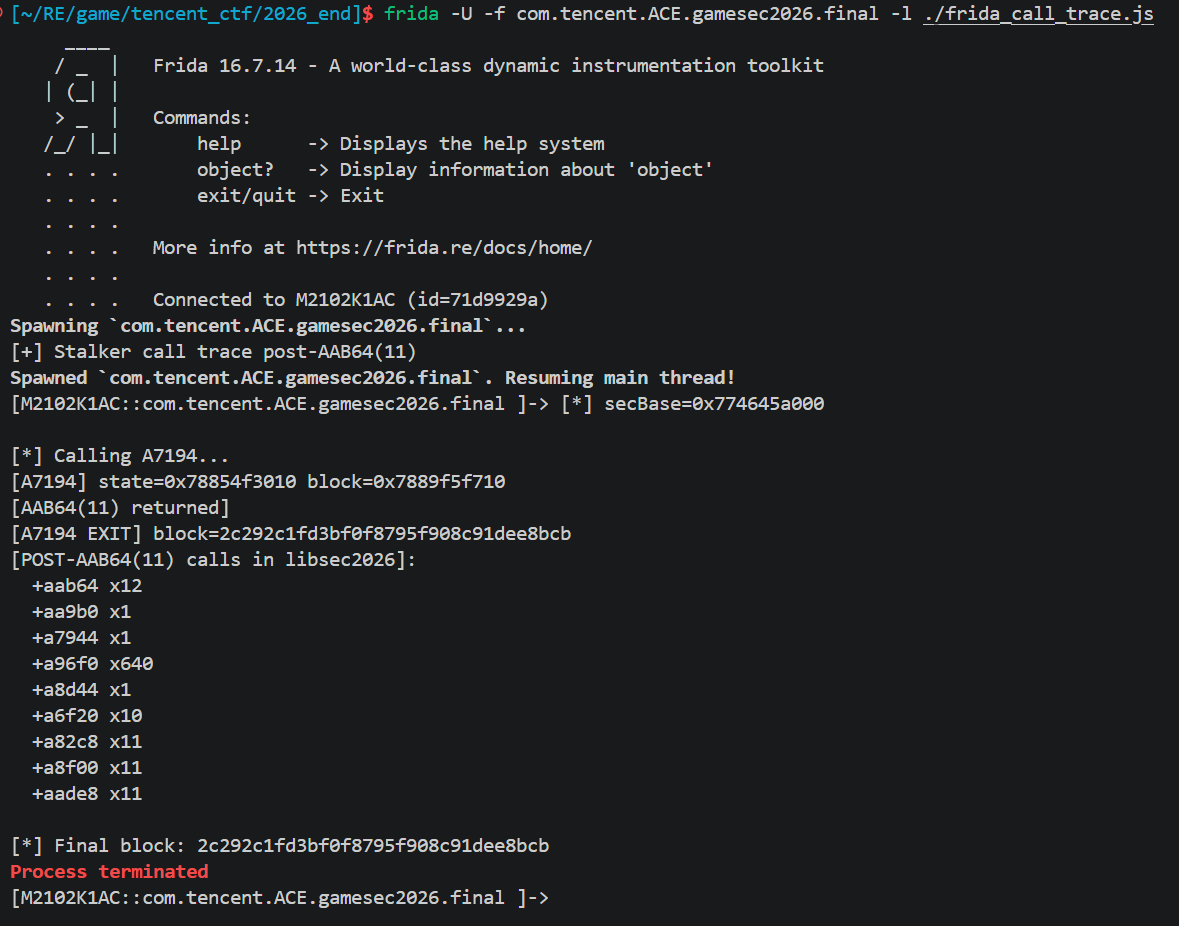
a96f0 x64 = 10 × 16 × 4,看着 a96f0 是 GF(2^8) 乘法(MixColumns 的 inner mul),a6f20是 MixColumns。11 轮 + 初始 round key + 最终轮无 MC,这就是 AES-128 的骨架(10 或 11 round,根据 Nk 变形)。
首先有这么多的块,如何定位块的逻辑?
可以用Stalker去追踪
也就是之前的
提取所有 S-box 和常量
SBOX_ENC
得到 256 字节的完整表。AES 标准是 0x63 ... 看出来非标准了。
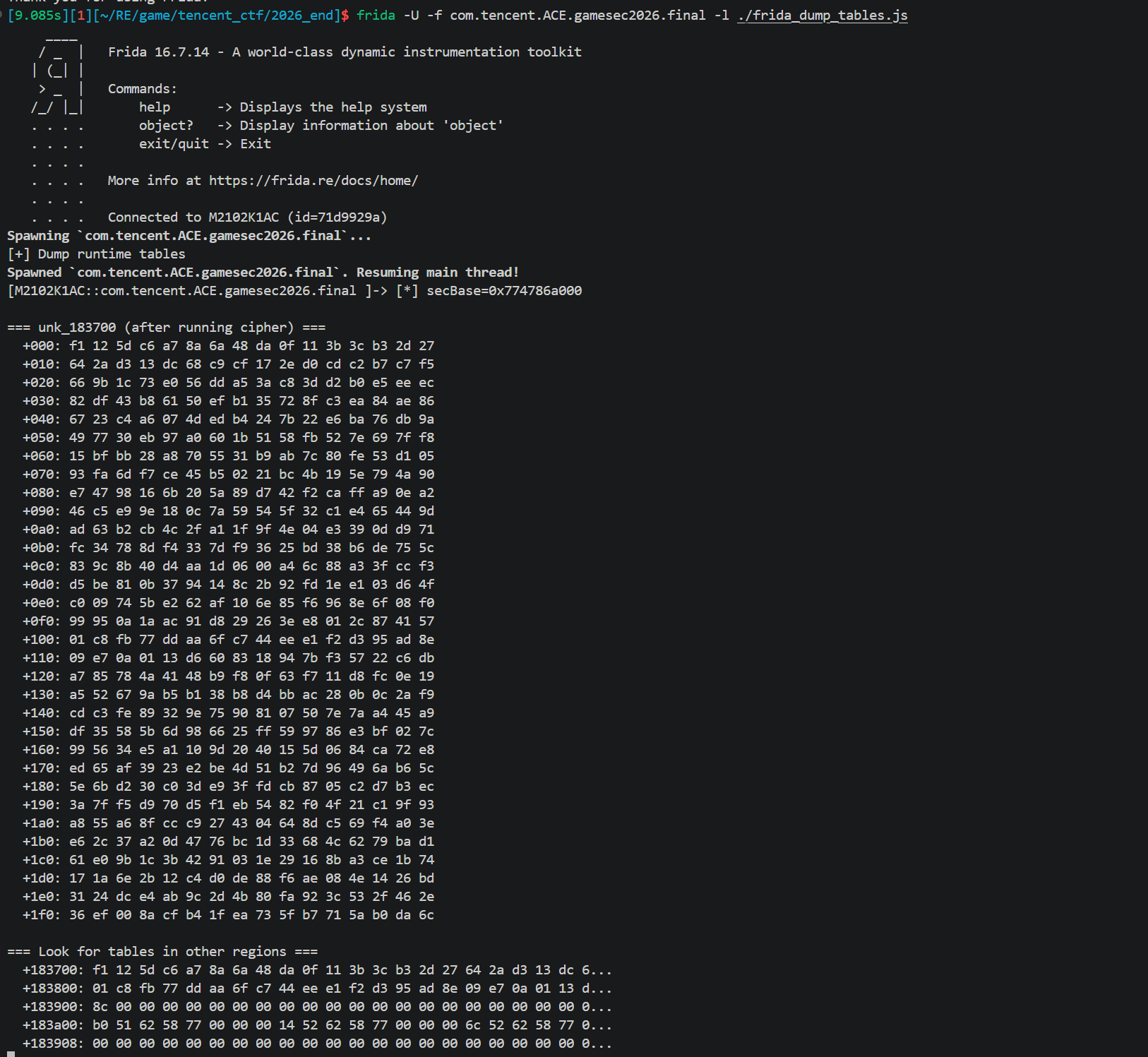
SBOX_KS和RCON也是类似做法
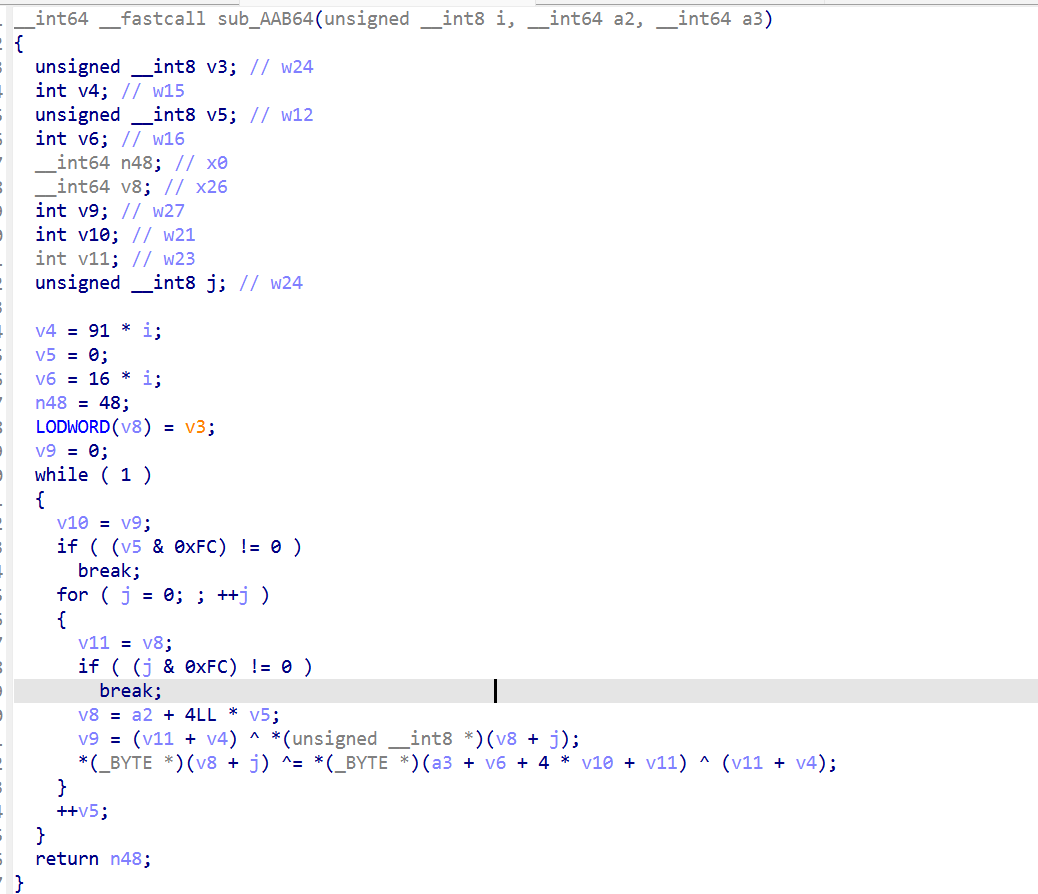
做法类似,但 SBOX_KS 与 SBOX_ENC是两张不同的表。通过跟踪 sub_A7DE8(key schedule 的 SubWord 子程)的内存读取定位表地址,dump 出 256 字节。
提取K_INIT
提取K1 K2
做了非常多的hook,有些没列出来,篇幅过长
AAB64 = AddRoundKey + pattern(round)
hook sub_AAB64(round, block, state):
实测每轮:eff_xor ^ rk = [base, base+1, base+2, base+3, base, ...],其中 base = (round * 0x5b) & 0xff。即:
这个 (r*0x5b + i%4) 的 pattern 是我手动试探得来的,先检查 eff_xor ^ rk 是否为 0(不是),再看是否只和 round 有关(是),最后拟合出 base 和 stride 都是简单线性函数。
A82C8 = SubBytes(直接 SBOX 查表)
跟之前的脚本类似做法:喂不同 block 观察 after。对 block = 0,1,2,...,255 喂进去看输出,直接得到 S-box 映射。验证 = SBOX_ENC(同一张表)。
A8F00 = rot90 + const XOR
通过基矢测试:喂 block = [1,0,0,0,...]、[0,1,0,0,...]、...,看每一位 → 输出的映射。发现是纯字节置换(线性,不混 bit)。进一步验证置换就是 4×4 矩阵按列主序的 90 度旋转:
再加一个 round 相关的 XOR 常量,就是 CONST_A8F00[r]。
AADE8 = ShiftRows
类似基矢测试得到字节置换。拟合出每行的 shift 量为 (0, 3, 1, 2)——row 0 不动,row 1 左移 3,row 2 左移 1,row 3 左移 2。不是标准 AES 的 (0,1,2,3)。
A6F20 = MixColumns(带非标准 poly)
通过基矢测试得到线性响应后,每列的 4 个输入对 4 个输出都有贡献(区分于 permute 的纯字节移动)。这意味着存在 GF 乘法。
拟合矩阵系数时,标准 GF(2^8) poly 0x1b 下解不出整系数。脚本暴力尝试 256 个 poly:对每个 poly,用矩阵反解看能否得到 0..255 范围内的小系数。最终 poly = 0x71 才给出干净的矩阵:
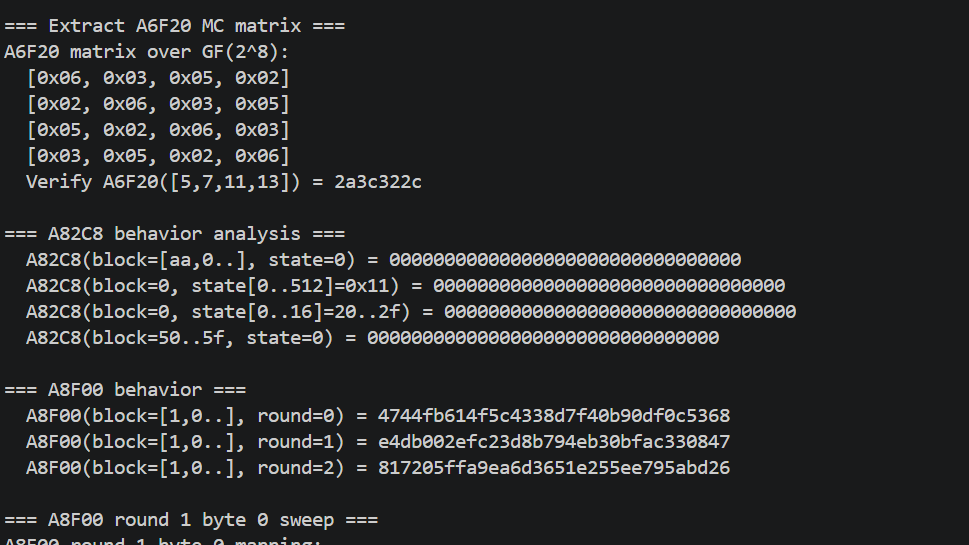
这与 Rcon 后 3 项用 0x71 翻倍的发现吻合,整套密码使用 poly 0x71。
AA9B0 = XOR permute_k2(K2)
类似 AAB64 的做法,hook sub_AA9B0(block, k2, size),观察不同 K2 值对 block 的影响。测试 K2=0、K2=单点 1,发现输出是 block XOR 一个置换过的 K2。置换规则:
密钥扩展 sub_A7900 (Key Schedule)
类似标准 AES-128 key schedule,但 SubWord 用 SBOX_KS,RotWord 方向反转(右旋 1 而非左旋 1),Rcon 用 [01,02,04,08,10,20,40,80,71,e2,5b]。
但是按照 Frida Stalker 观察到的调用顺序拼出完整算法。
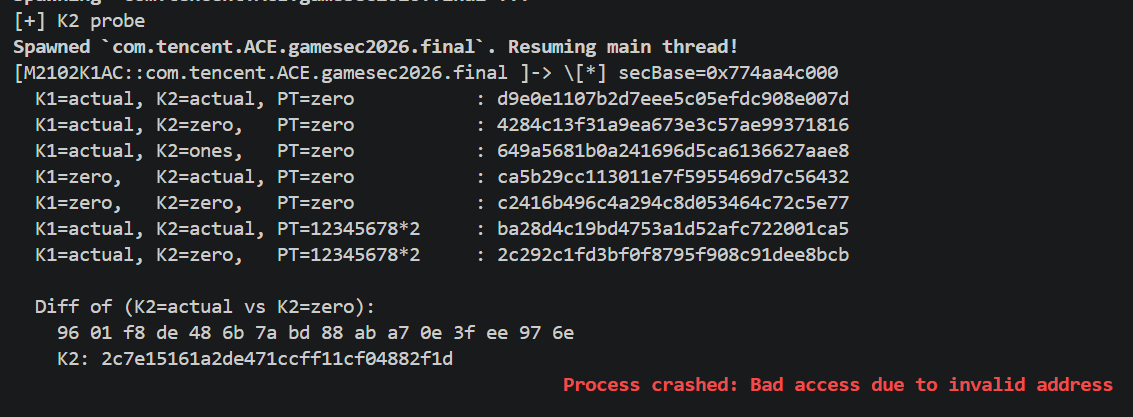
第一次验证失败:用 token 12345678,K2=0:
中间步骤到 AAB64(11) 为止逐步完全匹配,但 sub_A7194 返回后 block 又被改了**,可能还有其它逻辑**
确认修改发生的位置
脚本 hook AAB64(11) 的 onLeave、hook memcpy/__memcpy_chk/memmove
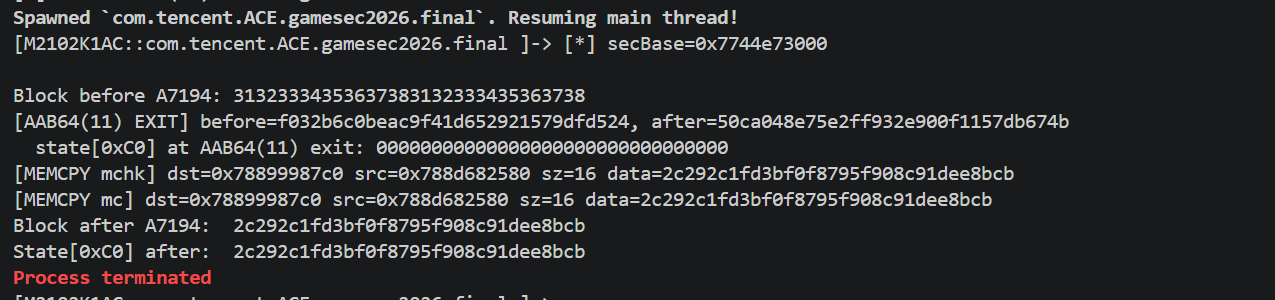
发现AAB64(11) 返回时 block = 50ca04...,但最后 memcpy 从 block 到 state+0xC0 的数据已经是 2c29.。说明在 AAB64(11) 返回到 memcpy 之间,block 被代码改写了。
验证 DIFF 是常量,4 个不同 token × 2 种 K2 值测试:
DIFF 恒为 7ce32891a65df014bb6907d84a35ec80
没有在代码里发现哪里做了手脚,但是通过diff得到是个定值
可能是通过运行时派生。
把这个diff作为最后的xor进去就得到了完整的算法
思想跟frida一样
定位到sub_97704后,有 一堆 flattening,题目做了很多懒初始化和跳表,可以写个unicorn
能看到执行了哪些函数统计执行次数

说明:
然后再抓AA9B0,A8D44,A7194,各 round 的中间状态
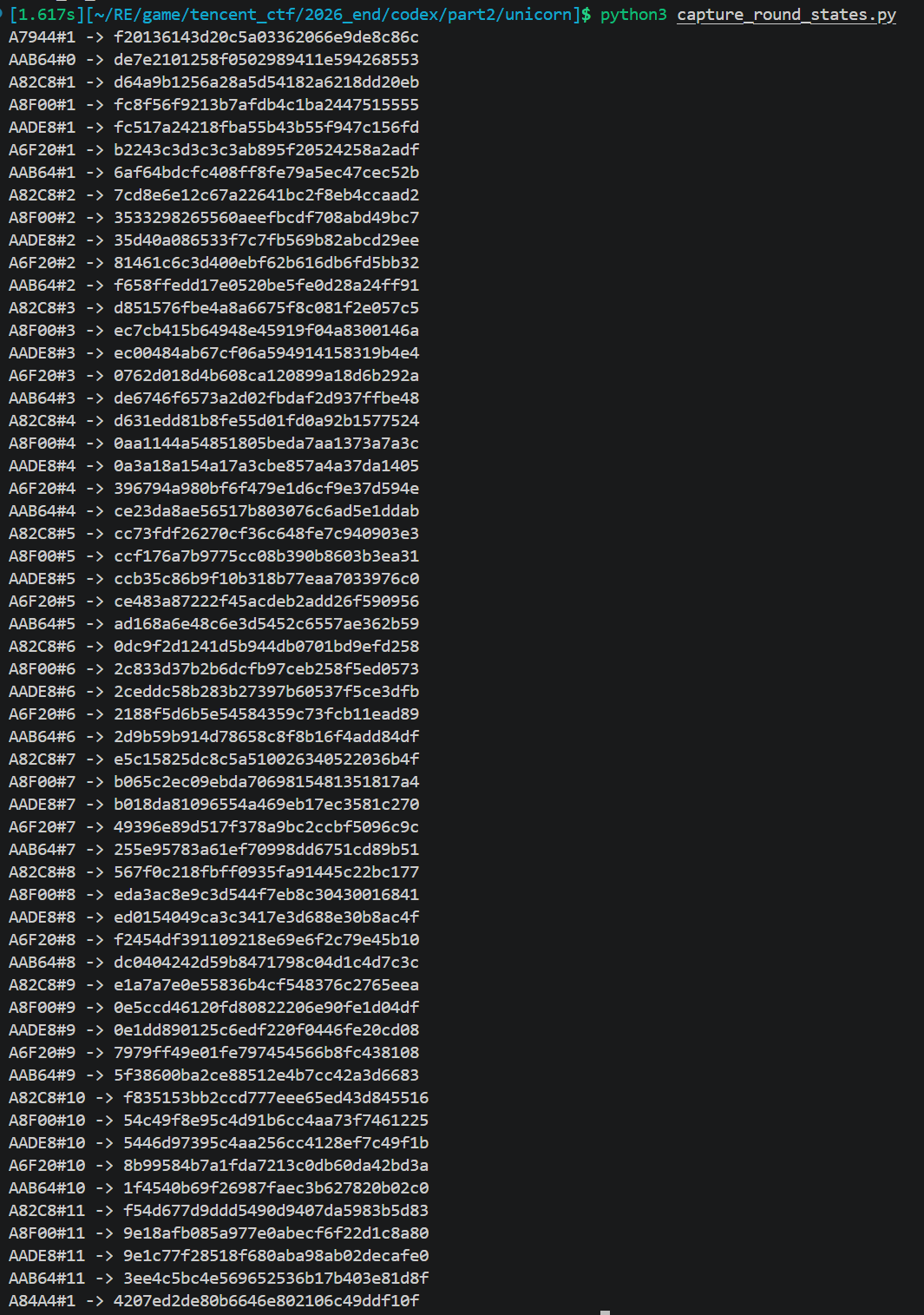
确认:
接着针对每一层分别识别:
A82C8
A8F00
AADE8通过输入 00..0f,确认为固定字节置换Perm2
A6F20,起初最难,先看它自身只像个 flattened dispatcher,再继续追它内部 helper A96F0,识别A96F0是 GF 乘法
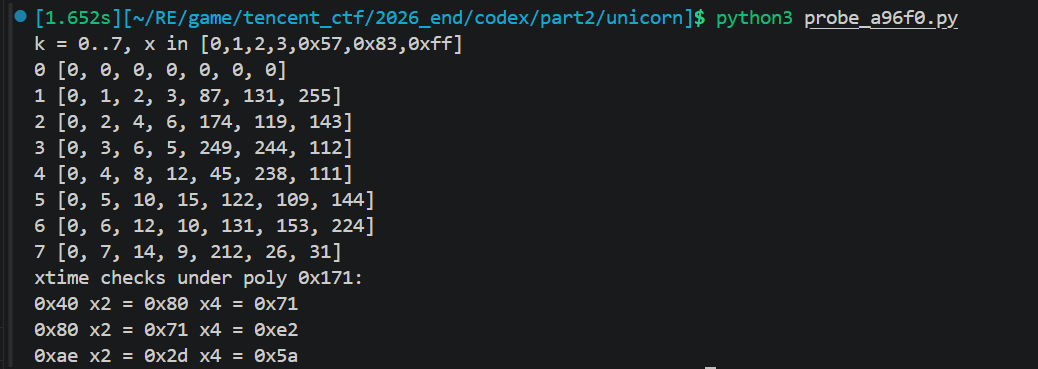
A96F0(x, k)的行为表明k=1是恒等,k=2/3/4/5/6/7 是 GF 上的常数乘法,约简多项式不是 AES 的 0x11b,而是 0x171
于是 A6F20 最终可以写成:
最后再抓:
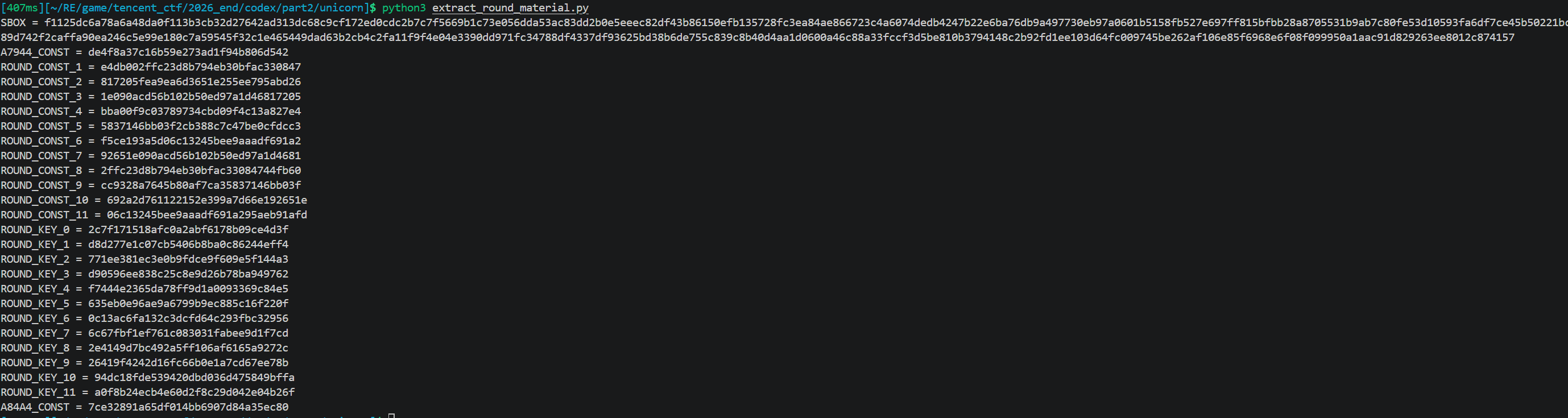
自此所有材料已经具备
Part2的最终 pure forward 已经可以写成:
其中:
中间还测了一些样例如
打印出一些patch必要信息,流程跟之前一样, 通用 OLLVM CFF 求解器:
经过多次调试写出去混淆脚本,主循环patch(相当于手动patch)
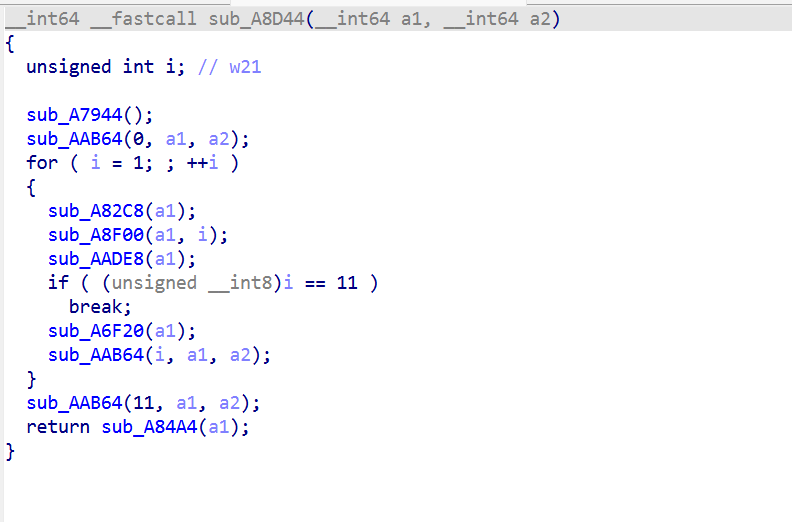
sbox处
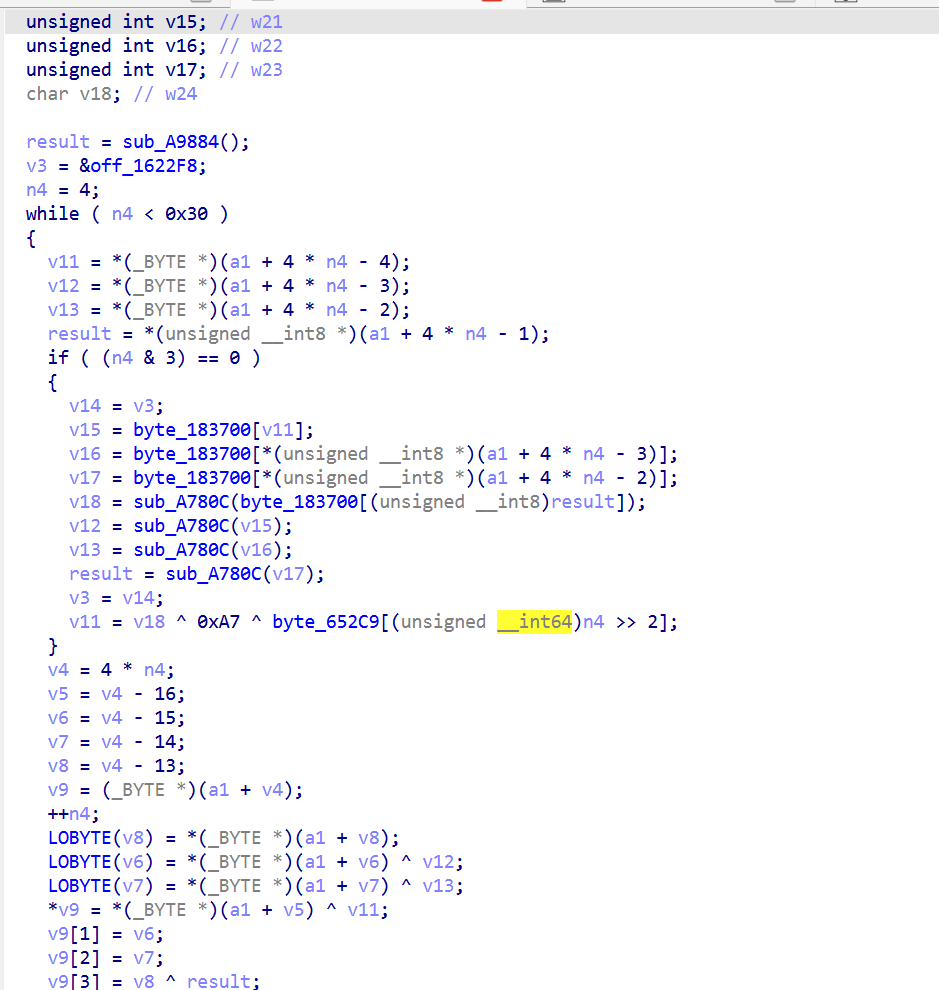
自此全部逻辑已获取
再三核实,三种方法的结果都对应下面的脚本

编译

跟之前一样思路,在前面我们已经可以看到了,下面那个visiable为false
4 层全关:
所以 trigger4_call 的任务就是一次性把这 4 层全部打开,然后因为 Trigger4 离出生点只有很近看起来是,车稍微动一下就自然碰撞,不需要挪位置(不像 trigger2/3 位置高不可达必须传送)。
所以可以ptrace + 调 Godot 4 个 setter 函数。
找 setter 函数偏移,需要的 4 个 setter + 1 个 getter
跟之前一样定位方法(capstone 扫描)对每个字符串做 ClassDB::bind_method 注册点查找:
ADRP + ADD指向字符串地址的代码点,在 ADRP 前 4 条指令找 ADR X0, <fn> 。 那就是 setter 的真实偏移。
5 个函数都是ARM64 标准调用约定:
识别 Trigger4 实例
trigger2/3 得靠世界坐标 fingerprint 区分 4 个 Area3D,trigger4 不用。
识别规则扫内存找 Area3D vptr 拿到 4 个实例,读每个实例 offset +0x578(monitoring 字段):
其实就是找唯一不可见的那个
AREA3D_MONITORING_OFFSET= 0x578,通过反汇编 Area3D::set_monitoring 函数体看到 STRB W1, [X0, #0x578] 反推。
ptrace-call 调 setter,通用 remote_call 框架
因为所有 setter 都是 X0, X1, ... 纯寄存器传参,一个通用函数覆盖所有调用:
force-zero 字节绕过 setter 早返回,这是 trigger4_call 特有的一个细节。Godot 4 的 setter 都有防抖:
如果 monitoring 当前值已经是 p_enable,setter 不会跑 PhysicsServer 注册。但我们希望无论当前值是什么,都强制重新注册一次(确保 PhysicsServer 状态和场景一致)。
因此可以调 setter 之前,用 pwrite64把字节预先清 0:
初次解谜时开车撞过 trigger4(导致 monitoring 已经变 1),再跑 trigger4_call 时没 force-zero 的话 setter 全部早返回、PhysicsServer 没重注册导致表面看调用成功但物理层没刷新。
完整流程
代码
编译

后面可以直接拿去验证算法真实性
主要有两个任务
因为一开始以为tick是part3绕了好久,一直没找到part3位置
入口定位从 GDScript 追到 sub_A9A7C,
直接搜flagd等字符串也搜不到,感觉libsec2026 不直接构造 flag 字符串,可能有某种收发机制,转向 libgodot 找collided_with发射点。
collided_with 是 trigger4.gd 通过 _w7 接收的信号名,但 trigger4.gd 自己根本没 _w7,证明这个信号由 native 发出。grep libgodot 字符串:
直接发现尾部函数尾部确实有:

但这只是发射机制,算法不在这里。算法藏在 arg的构造过程里
在F12搜索里没搜到,但是通过直接对整个文件过滤发现了相关字符串
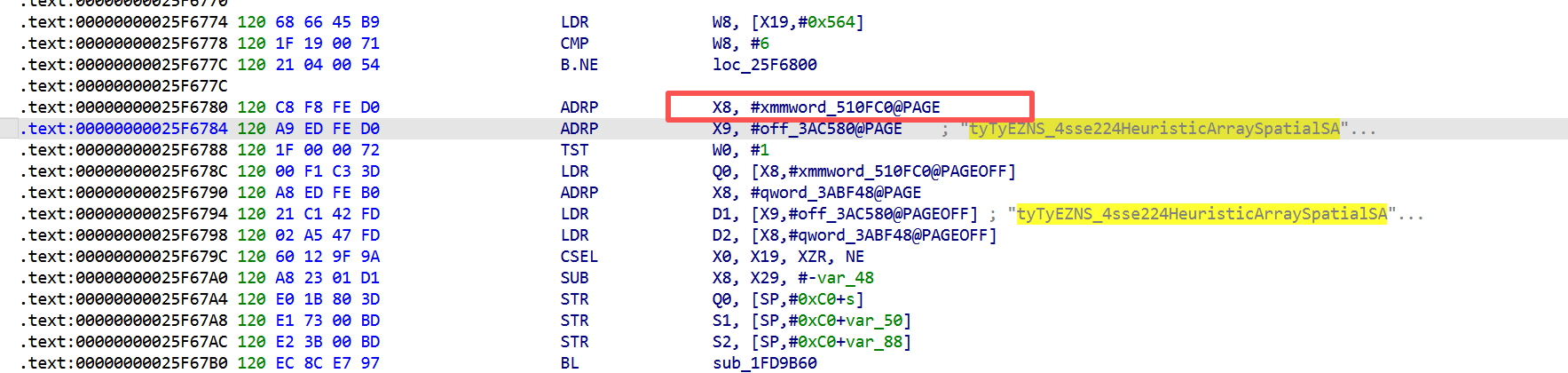

一眼顶真 flag
拼起来就是flag{sec2026_PART3_" + <hash> + }。中间的 <hash> 由 v27(s_7) 这个函数调用产出:

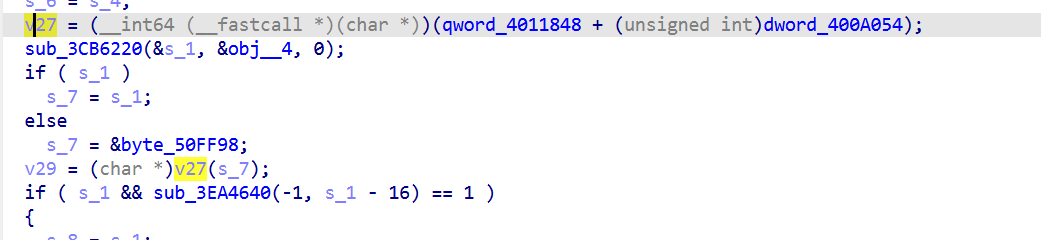
跟踪qword_4011848 :
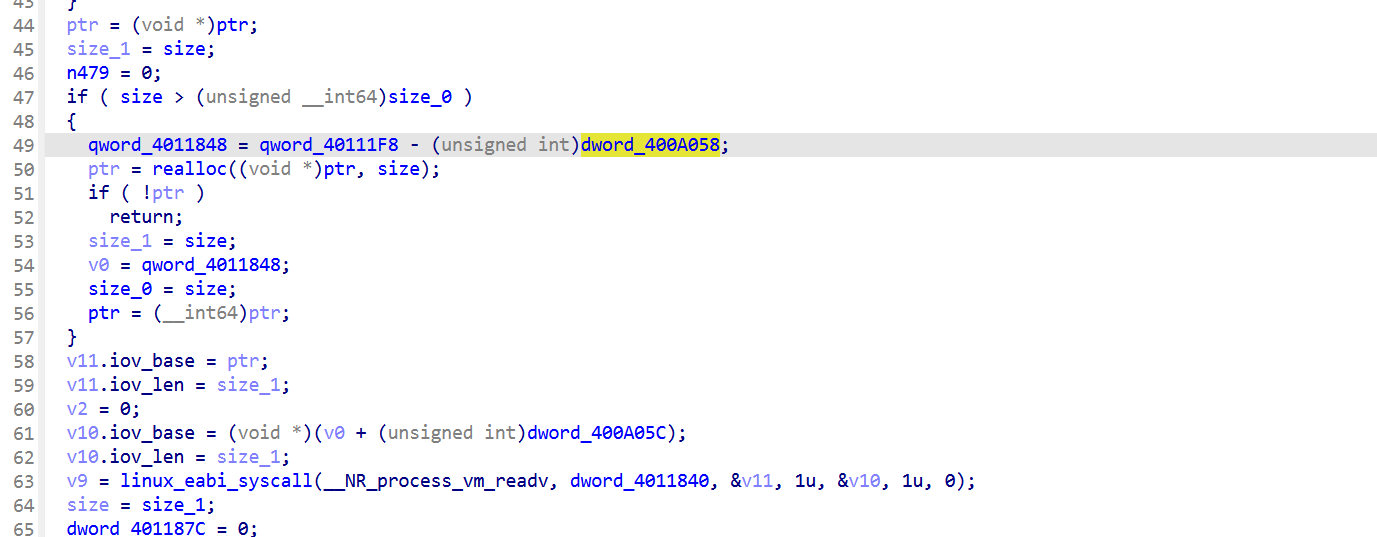
把 dword_400A054 = 0x000A9A7C 和 dword_400A058 = 0x000A4074代回去:
PART3 = libsec2026.so::sub_A9A7C(token_string)
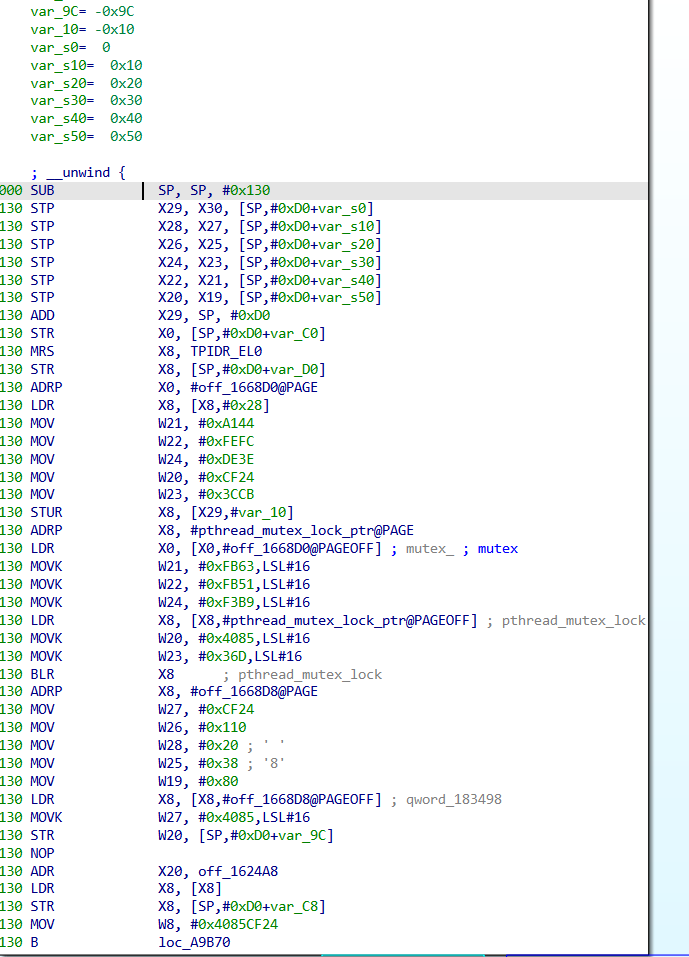
sub_A9A7C 是 OLLVM 扁平化 dispatcher,每个 state 跳到一个 handler,handler 自己又是 OLLVM 状态机。多层嵌套 OLLVM。直接读汇编基本不可行
观察sub_A9A7C的代码结构,dispatcher loop 形态像解释器,每次循环:
这是经典 VM 解释器模式。0x63D80 处发现 SBC0 magic + 5414 字节字节码,确认是 VM 程序段:
一般VM的处理思路就是动态trace,观察执行,观察它对内存做了什么。
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。








