本文定位为抛砖引玉,分享一系列实验性质思路、代码实现方法,并非一整套体系化、成熟化的商业对抗方案。
文中涉及的内容,均基于自建靶场环境下的模拟分析与验证,仅用于技术研究和交流。若文中有表述不够准确、理解不到位,或存在笔误、疏漏之处,也欢迎各位朋友在评论区指正。
文中涉及到的教学代码也已整理并完整开源到GitHub,欢迎各位朋友交流、指正。
在内核对抗、游戏安全方面,驱动隐藏总是一个津津乐道的话题。最早的驱动隐藏为断链隐藏驱动,一个标准流程加载的驱动将自身DriverObject从系统模块链表中摘除,再通过各种DKOM手法,使得PCHunter一类的ARK工具也无法在驱动列表中找到相关信息。
在2019年,GitHub上一个名为kdmapper的开源项目,该项目利用了存在安全缺陷的驱动,可以绕过DSE,直接在内核态中分配内存、拉伸PE镜像、解析导入等等操作,最后调用驱动入口点,实现把未签名的内核驱动手动映射进内核。这就是自己实现了一套ImageLoader,不走系统正常加载流程,根本不会创建正常的DRIVER_OBJECT,从隐蔽性角度来优于早期的断链隐藏驱动。
kdmapper刚开源那段时间,游戏安全简直就是一场无序的乱战,各路开发者利用kdmapper的能力随意将驱动程序映射到内核态实现提权,绕过游戏保护,当时大多数反作弊(AC)厂商都没有很完善的检测方案。早期检测方案是向可疑线程发送APC,在APC回调中采集堆栈信息,后来演进到注册NMI回调。
在笔者印象中,所谓无痕驱动一词被广泛提及,大概是在PUBG爆火的那几年,当时大量的灰产、外挂在宣传时都声称自己所谓的无痕化驱动。
在2025年,随着某国产摸金搜打撤游戏的爆火,某些社区论坛出现帖子,公然宣传、售卖所谓的无痕化商业驱动,这些商业驱动大多声称"可以稳定xxx反作弊保护",提供的功能无非是:读写内存、注入、模拟键鼠...
笔者对于无痕驱动一词的理解是:不存在绝对意义上的无痕化驱动,只要其加载、驻留在内存中,一定会留下痕迹。只是人为地将这些特征隐藏、抹除,从而抬高分析成本,使得短时间内绕过了安全审查。
重映射方式加载驱动
1.1 重映射加载驱动原理
1.2 重映射加载驱动的重定位问题
1.3 重映射加载驱动的通讯问题
劫持系统调用指针实现通讯
2.1 劫持系统调用指针原理
2.2 IDA脚本搜索内核模块中所有的CFG调用
2.3 筛选可利用的CFG点
2.4 符合要求的CFG点分析
2.5 利用特征码定位CFG点
2.6 兼容Win10~Win11多系统版本驱动通讯
2.7 修复通讯回调寻址问题
2.8 替换CFG函数指针
2.9 多系统通讯测试
2.10 小结
检测PoolBigPageTable内存痕迹(Win11 25H2)
3.1 MmAllocateContiguousMemory分析
3.2 MiAllocateContiguousMemory分析
3.3 ExInsertPoolTag分析
3.4 ExpAddTagForBigPages分析
3.5 调用链、参数分析
3.6 PoolBigPageTable对象中成员结构
3.7 利用PoolBigPageTable检测匿名内存分配行为可行性分析
3.8 利用特征码定位PoolBigPageTable表
3.9 遍历PoolBigPageTable中的成员
3.10 检测敏感内存分配行为
3.11 对抗PoolBigPageTable内存扫描
扫描内核态下所有可执行内存
4.1 扫描内核态下PTE
4.2 Win11 25H2环境下测试
4.3 通过扫描可执行内核页面检测Shellcode驱动
4.4 小结
利用编译器特征扫描"无痕"驱动
5.1 利用导入表特征检测原理
5.2 测试结果
5.3 剥离导入表Stub特征
5.4 延迟导入API
扫描被劫持的系统调用指针
6.1 扫描 ntoskrnl 中的CFG间接调用点
6.2 定位当前内核中的__guard_dispatch_icall
6.3 扫描内核模块代码中所有对__guard_dispatch_icall的调用
6.4 还原数据指针槽位
6.5 过滤正常CFG点
6.6 扫描、检测测试
6.7 绕过常规的指针扫描
Github开源仓库地址
结束语
常见的手动映射加载驱动方式往往分为两层,外层驱动仅作为Loader(使用未被AC厂商拉黑的签名),内层驱动(无签名)负责实现各种功能,以Shellcode、无模块镜像的形式驻留 / 运行在内核态(Ring 0)中。根据笔者接触到的一些样本来看,常规的Loader驱动工作流程往往分为以下几步:
本文会介绍一种取巧的思路:先让当前驱动按系统正常流程被加载一次,等内核加载器把镜像映射、重定位、导入解析等工作全部完成后,在 DriverEntry 阶段将自身重新映射到另一块匿名内核内存中继续执行,原始的DriverEntry 主动返回STATUS_UNSUCCESSFUL。此时我们的重映射驱动不再依赖原始的DRIVER_OBJECT和模块加载记录。
重映射并没有像传统手动映射那样,从头实现一整套 PE Loader。当 DriverEntry 被调用时,DrvObj->DriverStart 指向的已经不是磁盘上的原始PE文件,而是系统完成装载后的运行时镜像。所以我们在重映射时,很多初始化结果天然被继承下来了,例如PE已经被拉伸、IAT导入表中的函数地址已经被系统处理好。
我们将驱动自身直接重映射到一块新的匿名内核内存中,此时Shellcode驱动还不能直接运行,原因在于新旧镜像的基址(ImageBase)不同,镜像内部凡是依赖固定基址的绝对地址项,都需要根据新的地址重新修正。修正流程、部分关键代码如下:
当重定位修正完成后,这份新镜像在执行层面就已经具备了独立运行的基础。此时再结合后续的特征剥离操作,例如抹除PE头,以及让原始 DriverEntry 主动返回失败,就可以把真正的执行逻辑切换到这段匿名内存中。
笔者这些年接触、分析过诸多灰产驱动样本,这些驱动样本往往是提供一系列绕过AC保护、实现提权的功能,处于内核态的驱动程序大部分时间都是被动地接收来自应用层(Ring 3)程序的命令,解析命令后执行不同的动作。这一行为笔者笼统地概括为驱动通讯,常见的驱动通讯方式有:IO通讯、注册表回调通讯、MiniFilter通讯端口、共享内存通讯、本机Socket通讯等等。 本文提及的重映射加载驱动方式,本质上算是一种特殊的手动映射加载驱动。由于没有标准流程中的系统创建的DRIVER_OBJECT,所以常规的IO通讯、注册表回调、Filter端口通讯都会注册失败,必须寻找一条不依赖设备对象、同时又能被用户态正常触发的替代入口。
下一章节会介绍一种另类、相对隐蔽(指常规的ARK工具找不到痕迹)的驱动通讯方式。
在本文靶场中,劫持思路是基于CFG(Control Flow Guard,控制流保护)相关的特性,CFG 的设计目标,是对间接调用、间接跳转这类控制流转移行为进行约束和校验。内核运行时,会在特定分支上通过间接函数指针进入特定的处理逻辑,通过劫持这个间接函数指针,为重映射驱动提供了一条可被利用的隐藏通讯通道。
关于PG(PatchGuard)问题:有别于修改SSDT、IDT表项本身,这里真正劫持、改写的是某条系统调用内部会间接访问的函数指针或回调槽位,笔者测试时最长40h内无任何蓝屏状况。
如图2-1 IDA反汇编所示,就是一条可被利用CFG劫持点:
其反汇编大多可以总结为如下格式:
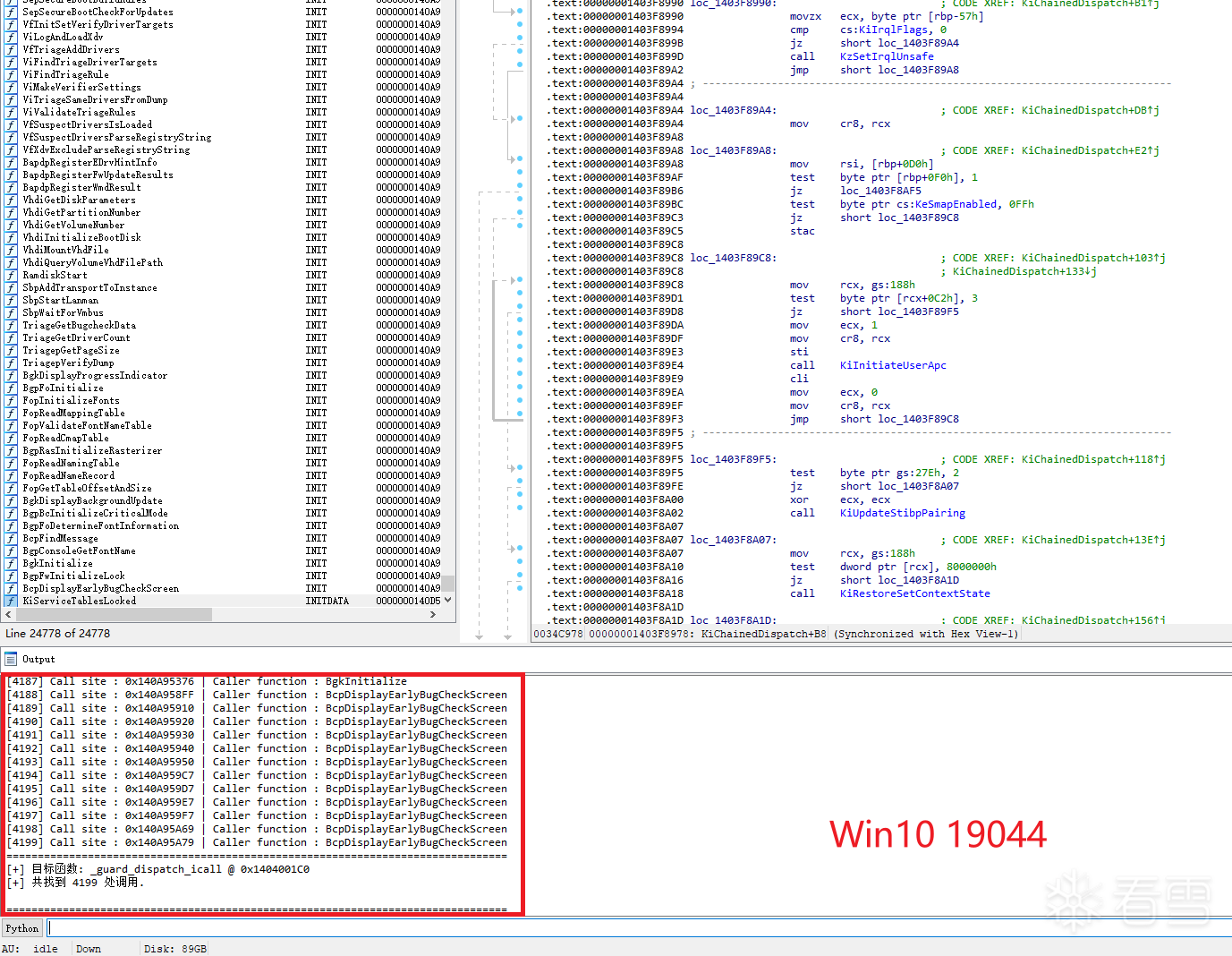
内核中存在着大量的CFG间接调用,依赖手动分析明显不现实,所以这里我们使用Python编写用于IDA的脚本文件,自动化的方式减轻我们的重复劳动,运行效果如图2-2所示:
从IDA脚本执行结果来看,内核中这类通过 CFG 保护的间接调用点非常多,但绝大多数位置并不具备实际研究价值。原因很简单:很多间接调用只出现在初始化路径、错误处理分支、一次性回调、或者只能由内核内部状态机触发的逻辑中,既不稳定,R3应用程序也无法发起调用。对于当前场景而言,真正值得重点关注的应该是那些恰好位于用户态可触发系统调用链上的间接分发点。
这类CFG点需要具备以下几个共同特征:
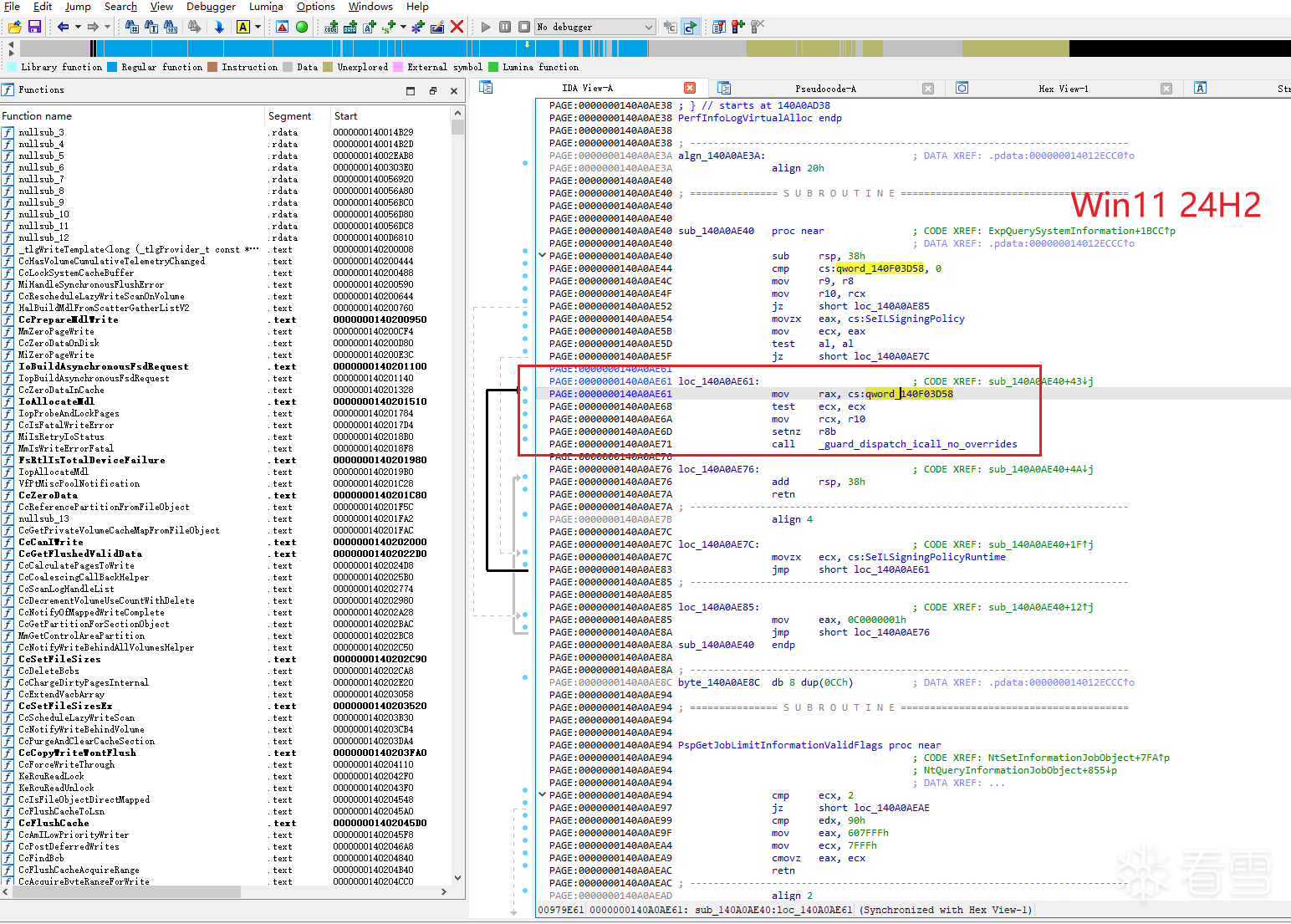
经过笔者分析Win11 24H2版本的内核文件后,分析出一个符合我们要求的CFG点,如图2-4-1所示:
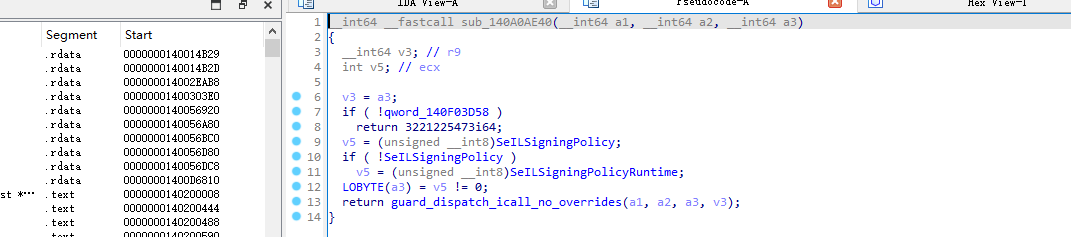
笔者首先关注到的函数为 sub_140A0AE40,从反编译结果来看,这个函数本身的逻辑非常简单:先检查一个全局函数指针是否为空,随后读取 SeILSigningPolicy / SeILSigningPolicyRuntime 相关状态,整理出一个布尔值,最后通过 guard_dispatch_icall_no_overrides 发起一次受CFG保护的间接调用。
也就是说,sub_140A0AE40 本质上只是一个非常薄的Wrapper,真正决定执行流走向的并不是它自身,而是全局变量 qword_140F03D58 所保存的目标函数。
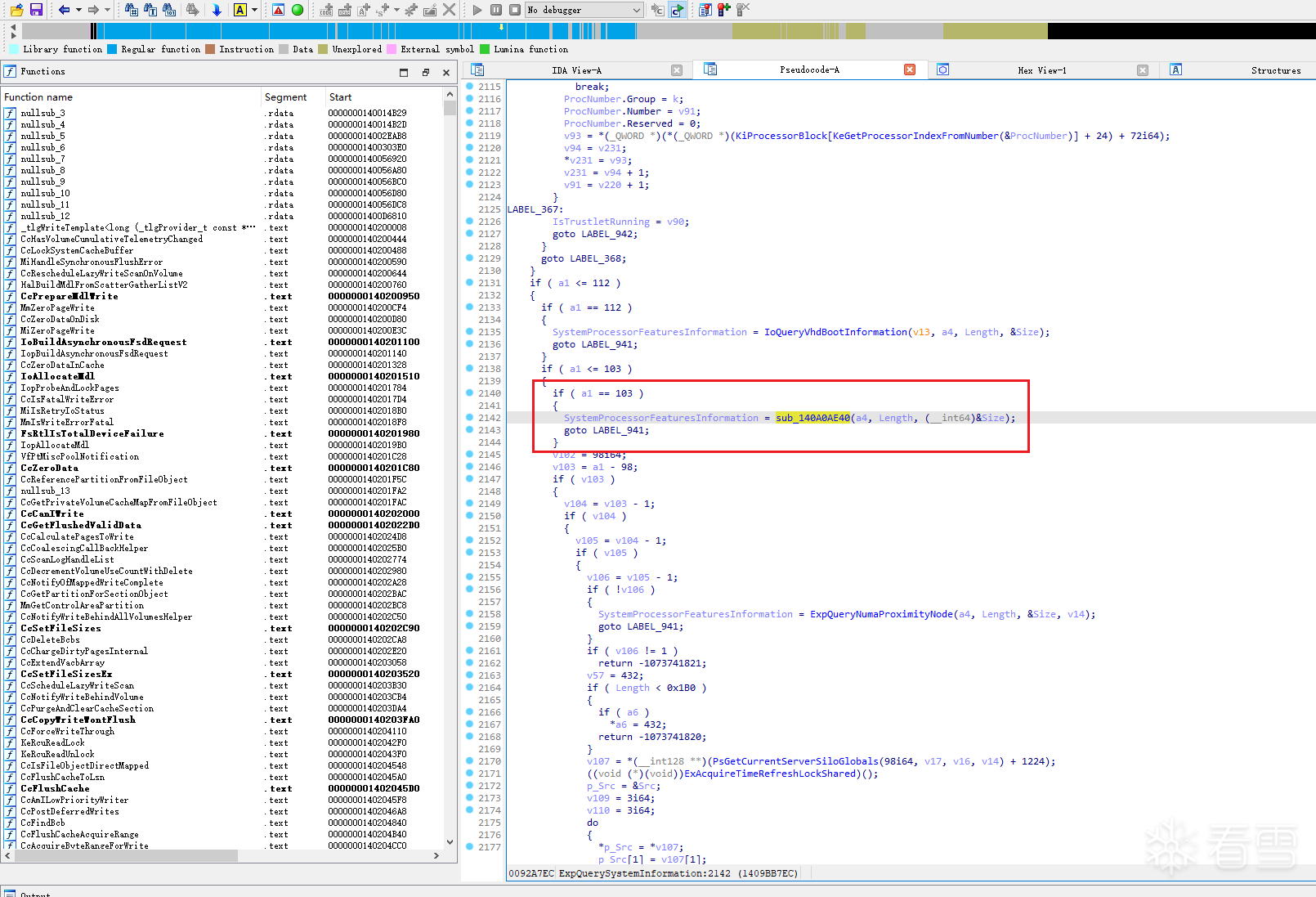
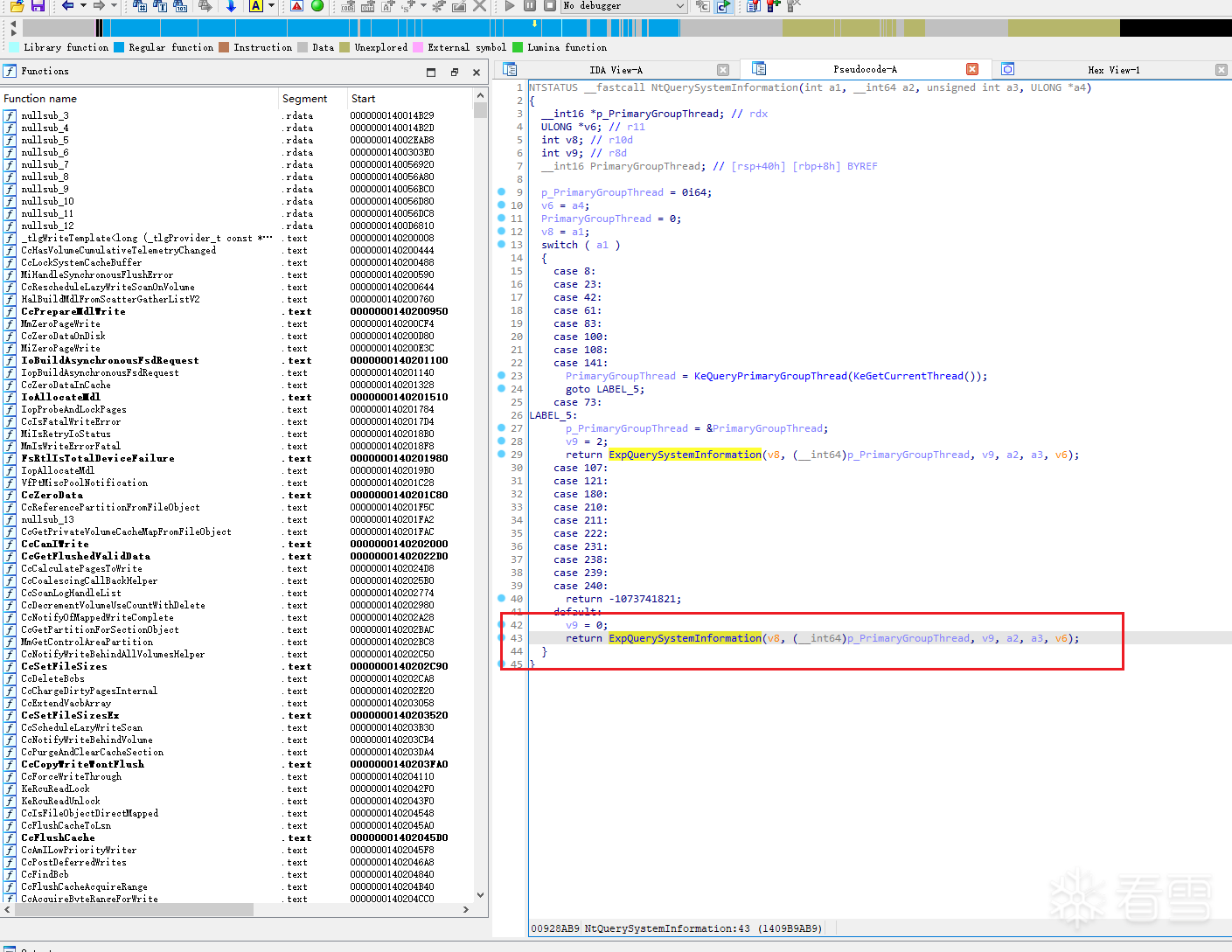
接下来继续查看 sub_140A0AE40 的交叉引用,可以发现它并不是一个孤立存在的内部函数,而是由 ExpQuerySystemInformation 在特定分支中调用。当 SystemInformationClass == 103 时,ExpQuerySystemInformation 会执行如下逻辑,如图2-4-2所示
由以下代码可知,到了 sub_140A0AE40 这一层,来自 Ring 3 的缓冲区地址 缓冲区长度 几乎原样保留、传递下来了。
再继续向上追,就能回到最外层的系统调用入口 NtQuerySystemInformation,从反编译结果来看,103 这个分支并不属于那些需要特殊线程上下文处理的情况,因此它最终会走默认路径,如图2-4-3所示:
至此,这条调用链已经可以完整串联起来:
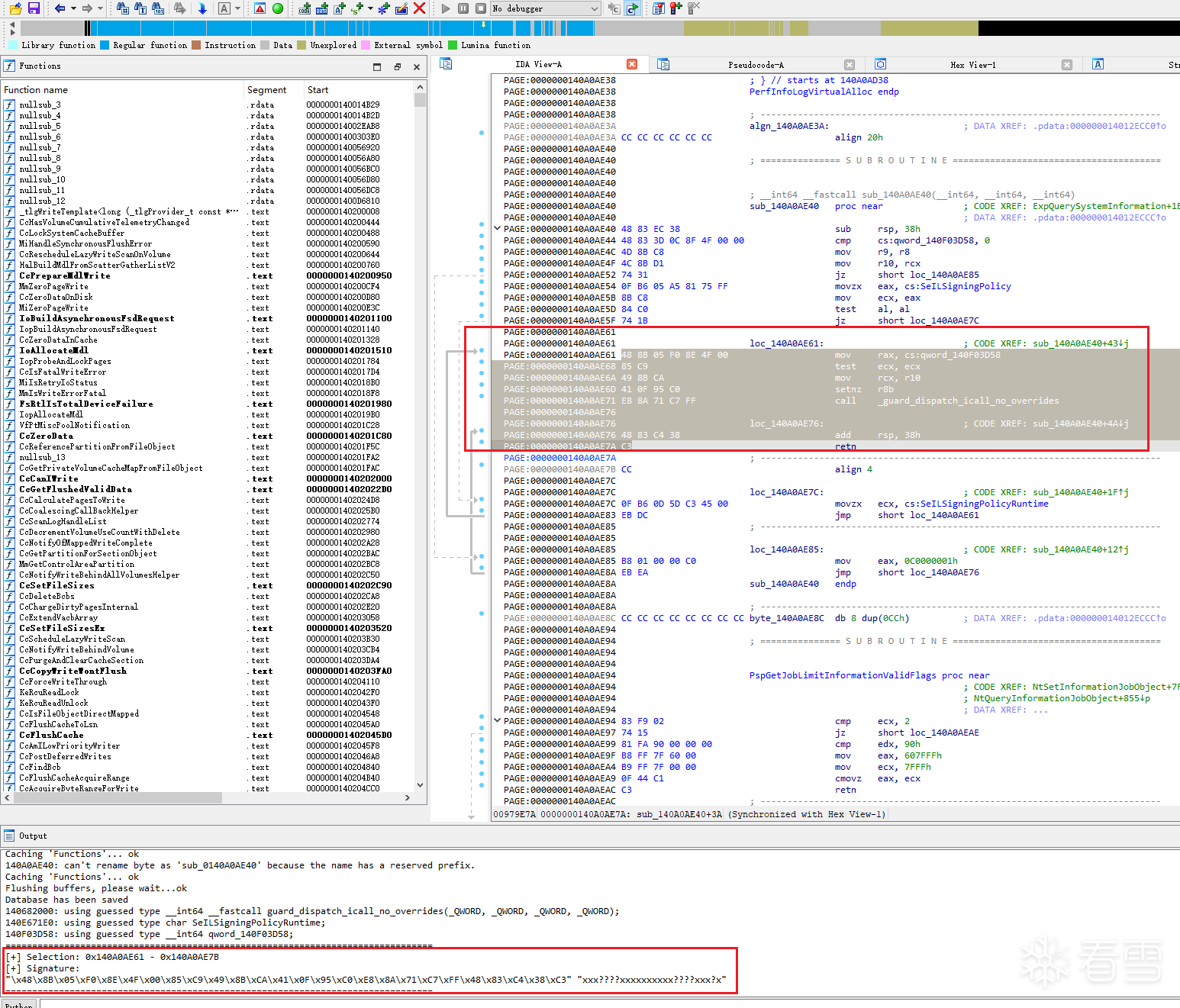
在前文中,笔者已经通过逆向分析确认了一条符合要求的 CFG 调用链。但在实际研究中,仅靠手工在 IDA 里逐层点交叉引用并不高效,尤其是在需要适配多个系统版本、反复验证目标点是否发生偏移时,更需要一种相对稳定、可重复的定位方法。出于这个目的,笔者选择使用 IDA 脚本辅助提取目标代码片段的上下文特征,再结合模式匹配的方式,在不同版本内核中快速确认该 CFG 点是否仍然存在,IDA脚本运行效果如图所示:
我们提取好特征码后,就可以在驱动运行时动态搜索特征码,定位到CFG点,部分关键代码如下:
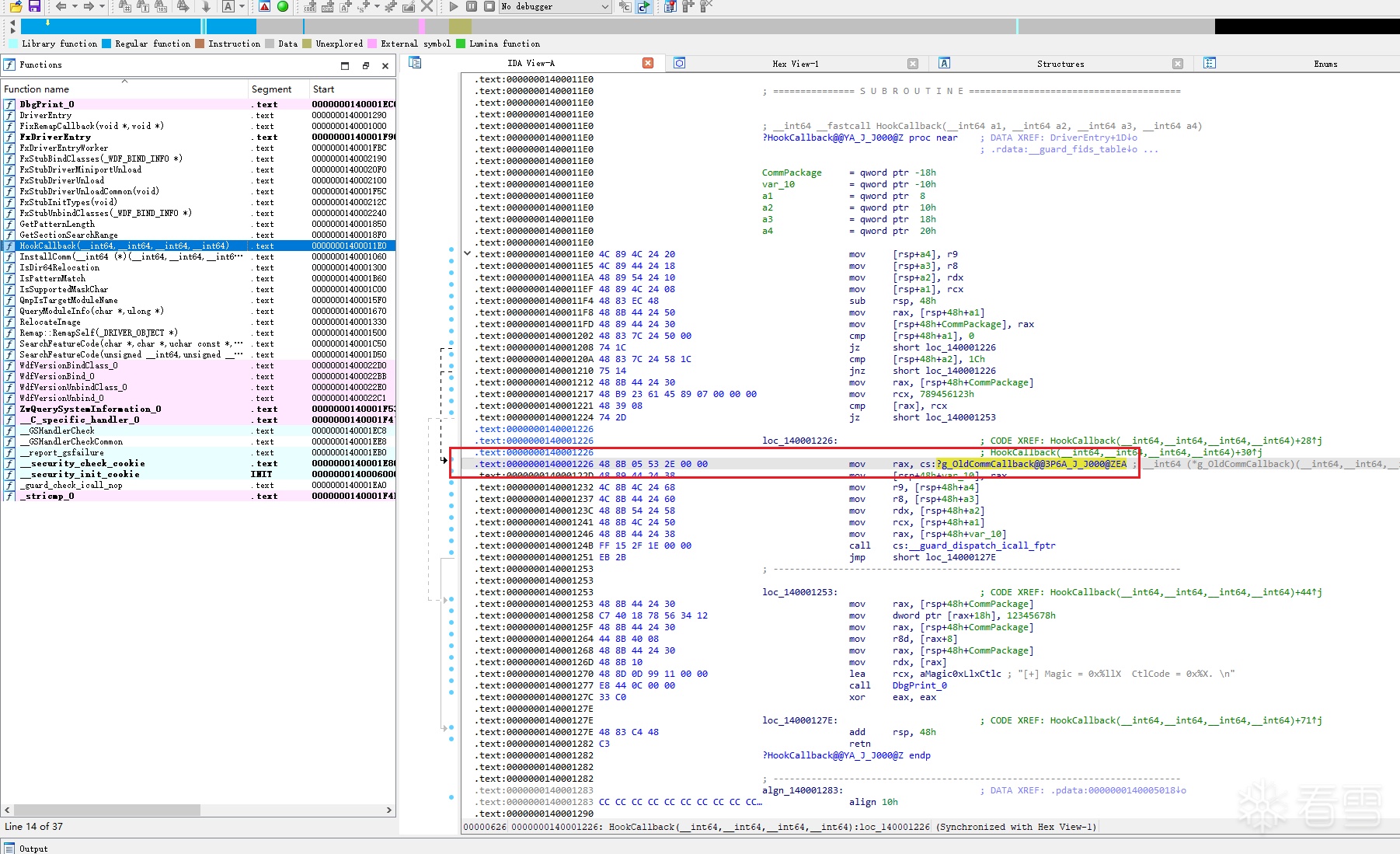
笔者编写的驱动通讯回调代码如下所示,需要修复全局变量的寻址问题:
使用IDA反汇编我们的靶场驱动,其中的HookCallback函数需要修复的地方,如图所示:
修复代码如下所示:
到了这一步,我们就可以替换CFG中的回调指针了,代码如下所示:
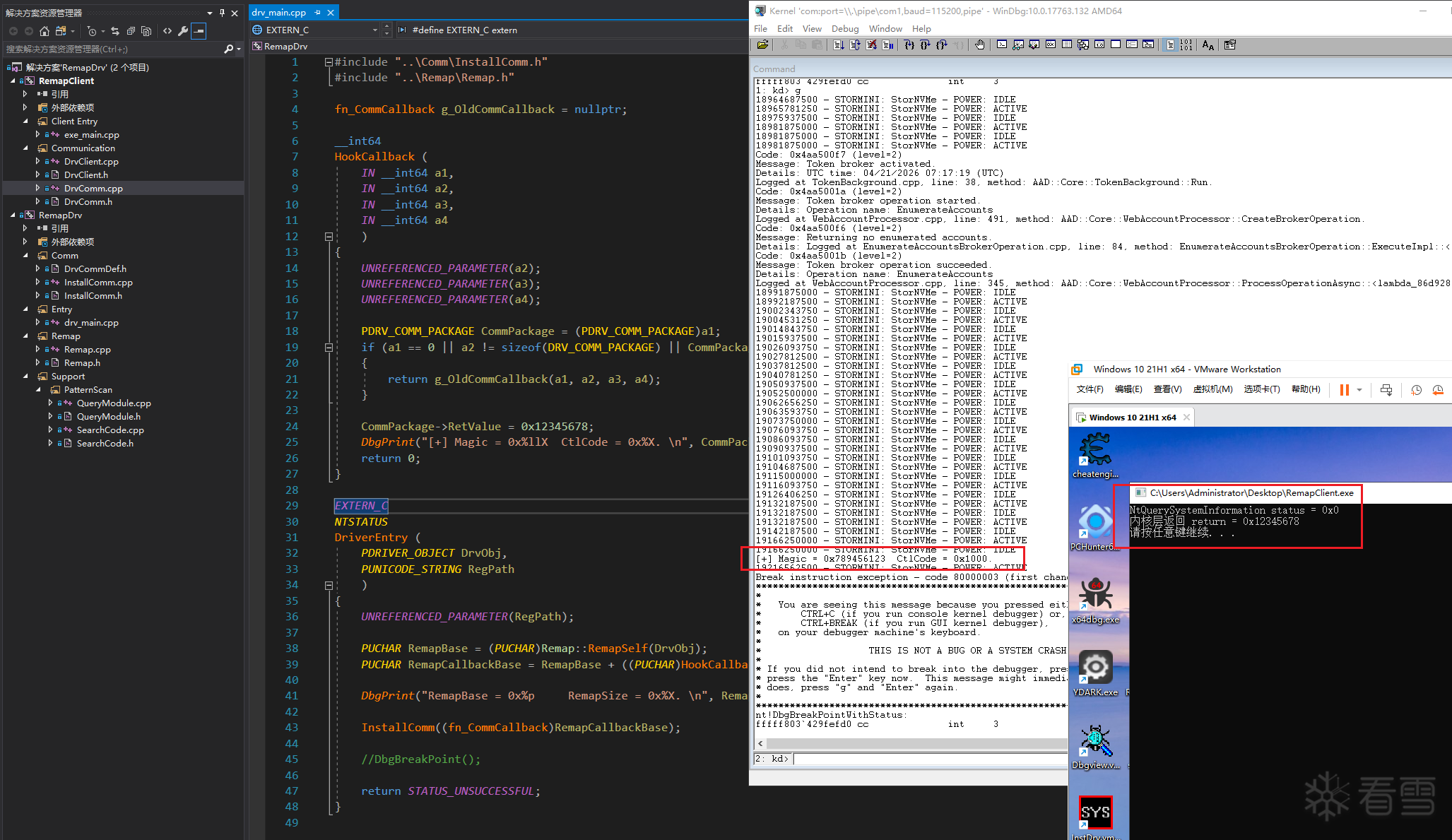
至此我们的劫持CFG通讯方式算是完成了,剩下的就是由Ring 3应用程序主动发起NtQuerySystemInformation调用,让我们的Shellcode靶场驱动接管调用流程,关键代码如下所示:
笔者针对多系统版本做了特征码提取,理论上可适配 Win10 19041 及之后的 Win10/Win11 版本。
驱动通讯测试结果如图所示,分别测试Win10 19044、Win11 25H2:
至此,一个用于实验与分析的所谓"无痕"驱动框架就基本构造完成了。当然,当前靶场驱动仍然保留了不少明显特征尚未处理,例如注册表、文件以及 PiDDBCacheTable 等相关痕迹。但这些内容并不属于本文的讨论重点。
本文阶段性目标,是构造一份以 Shellcode 形式驻留于内核中的驱动样本,作为后续分析与检测的模拟靶场。从成果来看,当前驱动已经具备了重映射加载与隐蔽通讯的基本能力,足以支撑后续章节的实验与分析。
接下来的内容中,笔者将从多个角度出发,对这类所谓"无痕"驱动进行剖析,展示如何一步步检测其残留特征。
在检测这类 Shellcode 驱动时,一个很自然的切入点就是内核内存分配痕迹。因为无论是手动映射驱动,还是本文这种重映射后的匿名驱动,想要在内核中长期驻留,都必须先拿到一块新的可用内存。以本靶场中使用的 MmAllocateContiguousMemory 为例进行逆向分析。
先看最外层的 MmAllocateContiguousMemory。从 Win11 25H2 的反编译结果来看,它本身只是一个较薄的Wrapper。函数首先将调用者传入的 NumberOfBytes 保存到局部变量 v4 中,然后把 HighestAcceptableAddress 右移 12 位,转换成页帧号上限(PFN Upper Bound)。随后,它调用内部的 MiAllocateContiguousMemory:
进入 MiAllocateContiguousMemory 后,内存管理器首先读取 *a1,并根据是否页对齐计算本次实际需要的页数:
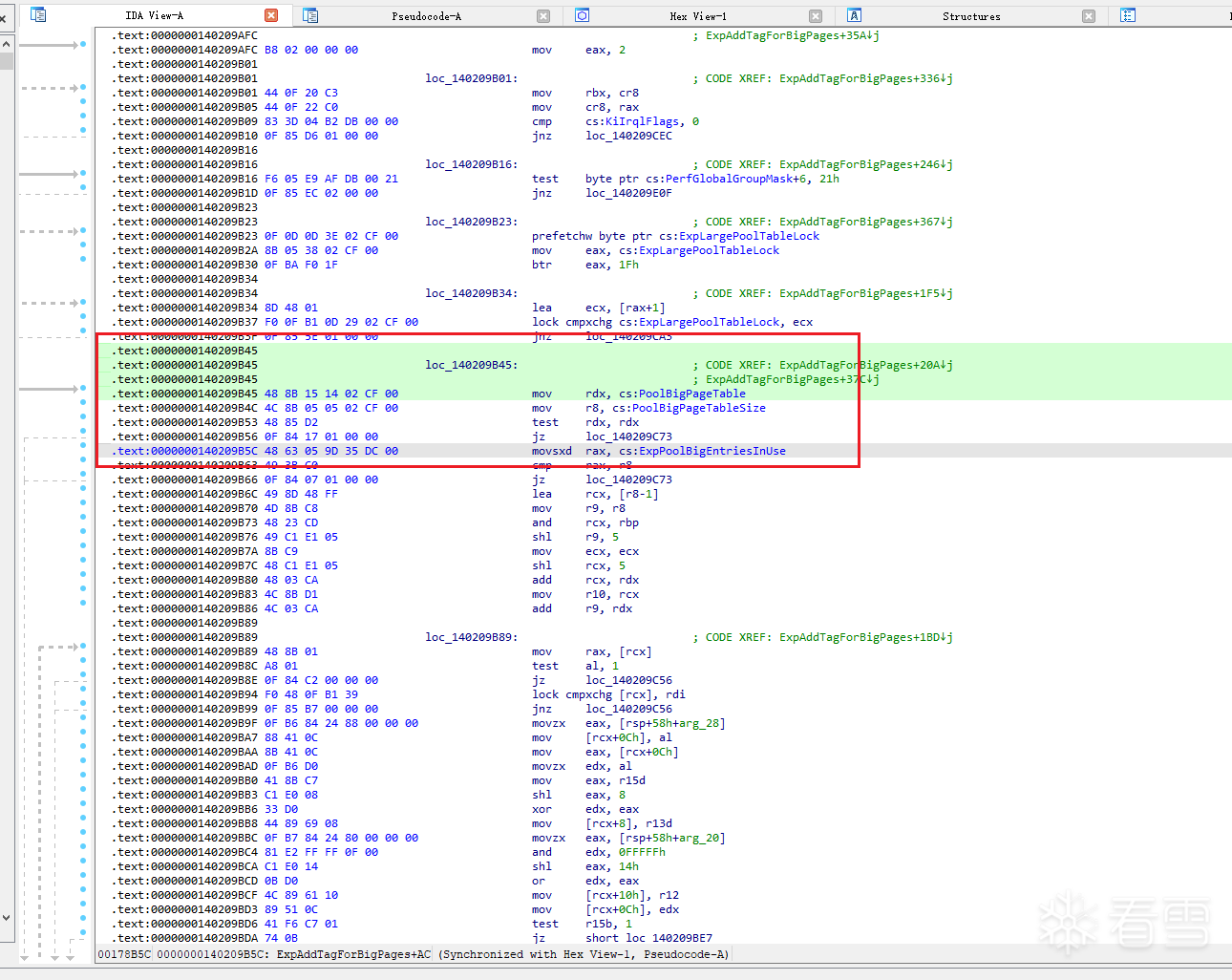
也就是说,v17 就是最终需要分配的页数,后续真正参与记录的大小也是 v17 << 12,而不是最初用户请求的原始字节数。随后,函数会在指定物理范围内搜索连续物理页,并在成功找到后调用 MiMapContiguousMemory 把这段物理内存映射成内核虚拟地址,紧接着调用ExInsertPoolTag,这条调用链已经把2个最关键的信息凑齐了:
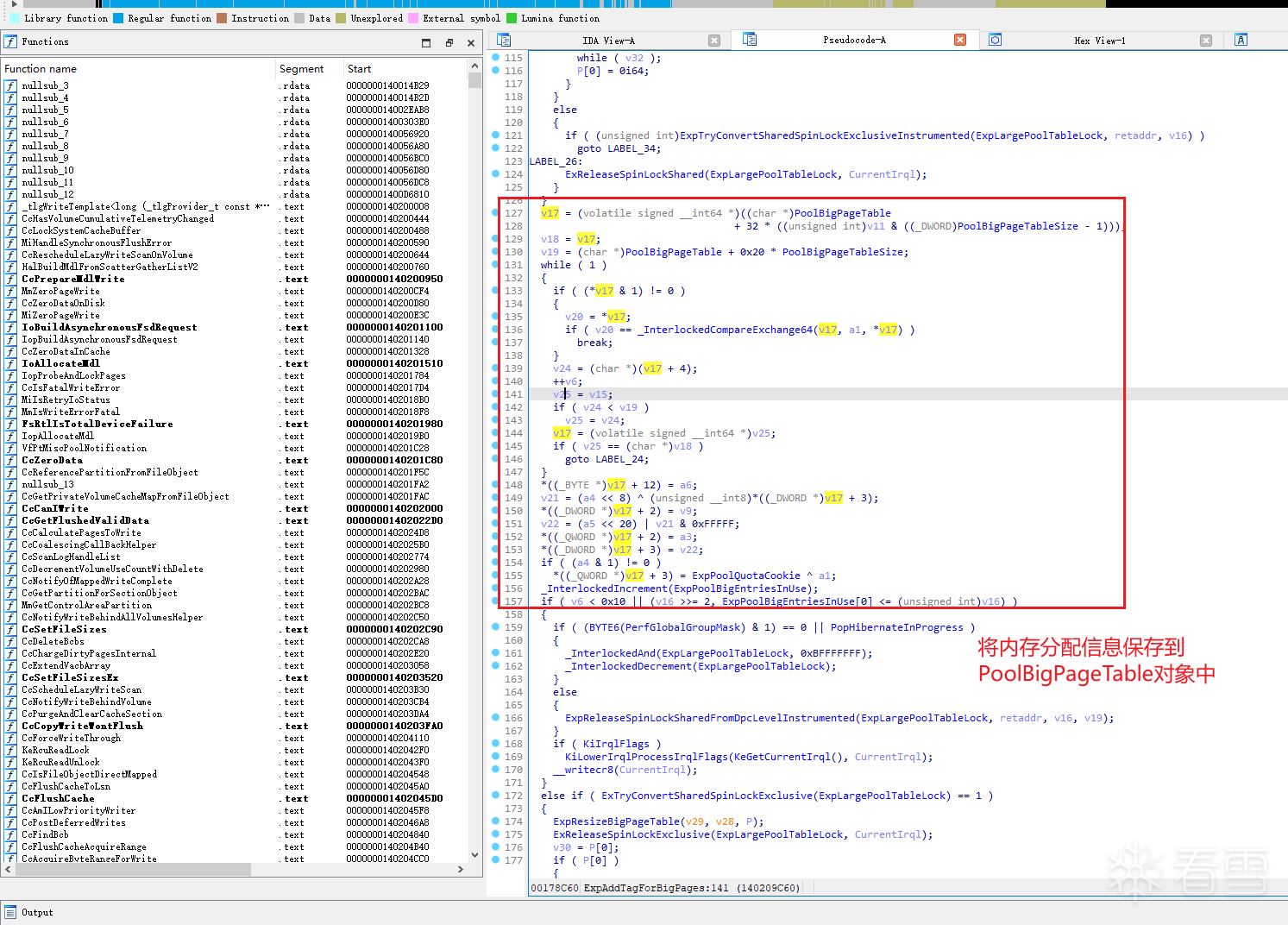
ExInsertPoolTag 会先把传入的大小再次按页对齐,随后调用核心函数ExpAddTagForBigPages,如图所示:
可以把 ExpAddTagForBigPages 的2个关键参数理解为:
目前可以知道分配出来的内存信息,都会保存到PoolBigPageTable对象中,并且在Win11 25H2下,其中的对象结构可以表示为如下:
在Win10系统下,PoolBigPageInfo可以表示为如下结构:
经过笔者分析发现,内核中大部分常用的内存分配函数,最终都会将分配到的内存信息保存到PoolBigPageTable对象中,所以利用该系统特性,我们就可以遍历PoolBigPageTable中所有的条目,找出敏感的匿名内存分配行为。
PoolBigPageTable,关键代码如下所示:
使用特征码搜索到PoolBigPageTable对象后,遍历其中所有已分配内存信息,关键代码如下所示:
测试系统版本为Win11 25H2,测试流程为:
关于这一部分,笔者仅提供2种思路,暂不提供实现源码:
每次分配内存前,临时Hook ExpAddTagForBigPages函数,不让其将本次的内存分配信息保存到PoolBigPageTable
手动遍历PoolBigPageTable中所有成员,将敏感的内存分配信息清除
带来的缺陷:
释放内存前需要将抹除的信息还原,因为内核在释放内存时也会查找一次PoolBigPageTable对象,查找失败会触发BugCheck
除了前文提到的 PoolBigPageTable 这类"内存分配记录"思路外,另一种更直接、也更粗暴的检测方式,就是直接遍历内核态下所有虚拟地址对应的页表项(PTE)。
其核心思想很简单:既然所谓的 Shellcode 驱动最终总要以代码页的形式驻留在内核地址空间中,那么无论它是否存在标准的 DRIVER_OBJECT,也无论它是否已经抹除了 PE 头,只要它仍然需要执行,就必然对应着一段可执行的内核虚拟内存。因此,我们完全可以绕过模块链表、对象管理器等高层结构,直接从页表层面对整个内核地址空间做一次暴力扫描。
首先读取当前CPU的 CR3 寄存器,取得当前地址空间使用的顶级页表物理基址。随后通过 MmGetVirtualForPhysical 将 PML4 对应的物理页映射成内核虚拟地址,并从这里开始逐级遍历 PML4 -> PDPT -> PD -> PT 四级页表结构。
关于其中的每一级PTE,可以使用如下结构进行描述:
由于x64下内核地址通常位于高地址空间,因此这里没有从 PML4[0] 开始全量遍历,而是直接枚举 PML4[256] ~ PML4[511] 这部分条目,把扫描范围收敛到内核态虚拟地址区间。遍历过程中,只保留满足 Present = 1 且 NoExecute = 0 的页表项,也就是当前真实存在、并且具备执行权限的页面;其余不可执行页、未映射页则直接跳过。
对于命中的可执行页,再结合是否属于已知模块映像范围进行一次过滤,就可以把大量正常内核模块代码排除掉,把关注点集中到那些不属于任何已加载模块、但却具备执行权限的匿名内存区域上。对于手动映射驱动、重映射驱动这类 Shellcode 驱动而言,这类区域往往就是后续重点分析的对象。
如下为关键部分代码:
在Win11 25H2环境下测试,顺利枚举出所有的可执行内存页面信息,如图所示:
这里的测试流程同PoolBigPageTable,先扫描一次PTE列表、加载靶场驱动、再扫描一次PTE列表,此时前后新增的可执行PTE条目大概率就是Shellcode驱动所在的内存范围,如图所示顺利扫描到靶场驱动所在Pool内存范围:
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-4-25 15:14
被__Shinn编辑
,原因:















 利用特征码定位
利用特征码定位