-
-
[原创][讨论] 南极企鹅游戏安全2026-Android-初赛
-
发表于: 2026-4-14 15:39 6290
-



打开游戏,触发示例方块得到样例flag,目标是触发屋顶的方块,得到真正的flag,常规游玩、车是开不到那地方的。
所以第一个目标:传送车的坐标到触发块的坐标。
解包APK发现是Godot引擎制作的游戏,gdc脚本也被加密了,本身对godot不是很熟悉,不过既然是开源的就下载源码下来看看,同时上网搜索发现:Godot官方是支持用脚本加密的。
懒了: 847K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3f1#2x3Y4m8G2K9X3W2W2i4K6u0W2j5$3&6Q4x3V1k6@1K9s2u0W2j5h3c8Q4x3X3b7J5x3o6l9J5y4K6M7&6i4K6u0V1x3g2)9J5k6o6q4Q4x3X3g2Z5N6r3#2D9 ,直接照抄思路dump密钥(脚本末尾)
得到ce4df8753b59a5a39ade58ac07ef947a3da39f2af75e3284d51217c04d49a061 ,
尝试使用社区工具gdre_tools来解密显然是不行的,下载源码后发现脚本解密逻辑中的AES_MODE和游戏逆向出来的处理方式不太一样,要改掉那部分逻辑又得重新下个godot引擎编译很麻烦,干脆直接复用游戏内的解密逻辑,然后再用gdre_tools读取gdc脚本:
游戏引擎(libgodot_android.so)解密魔改部分:
解密脚本:
同时获取到了flag的获取逻辑:
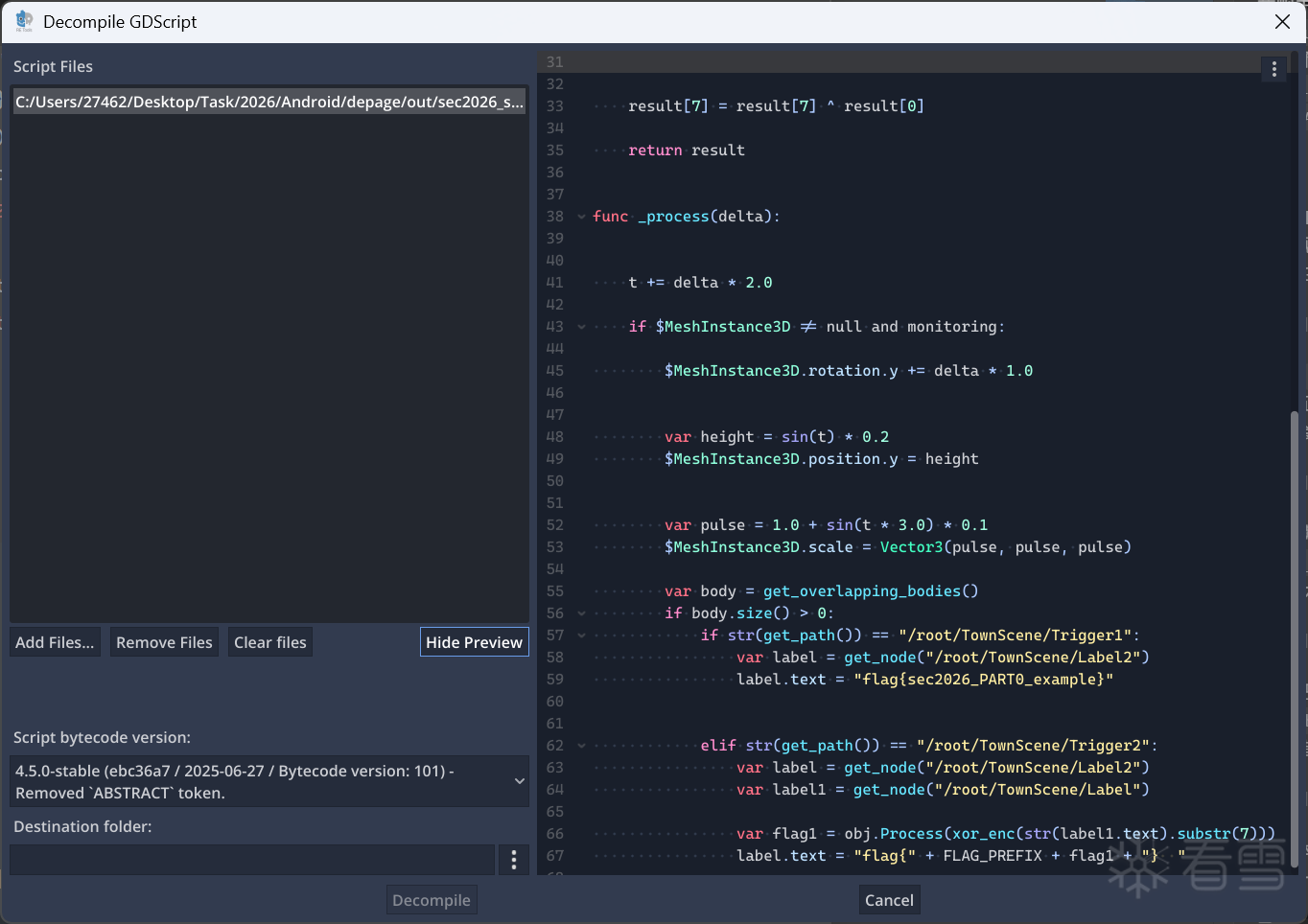
然后就是处理传送车的问题:反过来利用 Godot 自己的对象系统和场景系统,直接让游戏正常执行这段逻辑。
根据Unity开发经验猜测:Godot肯定也有某种find gameObject方法,找了一下 Godot 恰好给了这样做的条件。只要在 Frida 里拿到引擎内部的这些能力:
就可以像脚本层一样直接操纵场景节点。
这部分的实现对应脚本是frida_move_trigger_sec2026.js(太长放末尾了)。
核心思路远程调用引擎提供的接口
实在懒得搜坐标手动改,还是原生的办法通用性高一些。
如果只是改可见节点的位置,车不一定真的算“进入触发器”,因为场景里真正参与碰撞的是物理对象。也正因为这样,frida_move_trigger_sec2026.js 不是只改一次 transform 就结束了,而是同时做了两层同步:
IDA打开可以分析的函数不多:
主要是解压子程序,然后通过BR命令跳转到子程序去执行逻辑。
二环主要逻辑:
选择在00001764 通过Frida脚本动态dump(脚本见末尾)下来继续分析:
三环:
因为三环入口 0x1c48 会先自修改代码,静态分析已经啃不动了,看静态毫无头绪,Hook要打上还得抓时机控制、不然直接崩。想着应该可以用Stalker去追执行流说不定方便点,但由于页权限切换、还有自修改代码等原因、反正我是一个个线程去试了,没扒下来。一番静态压根找不到Process的链路,转向动态,从native层和游戏层之间的沟通入手:
根据解包的配置知道,libsec的在游戏中被调用的入口点是
而Godot GDExtension的标准API是:
在Godot游戏引擎要调用拓展的时候第一个传入的函数指针p_get_proc_address类似于引擎接口查询函数可以直接查到Godot 的注册接口地址classdb_register_extension_class_method 在注册拓展函数的时候,会交一个GDExtensionClassMethodInfo:
call_func注册了拓展函数的入口点,注册时可以拿到三环关键函数的地址:
对照dump下来的逻辑:
可以发现自修改改了不少,动态分析就省去了那部分分析逻辑,而因为执行函数的时候是通过method_userdata下发分发的,调用时又加上了userdate做了一层偏移,触发flag获取的逻辑后,可以得到Object.Process在三环内的真正地址:
结合静态来看,开始套娃:
此时已经可以根据运行的参数,计算出之后的调度链(大致会执行哪些函数都看一遍、结果发现是套娃),通过binary ninja继续跟,直到套娃:0x4ffd0 类似的分发函数,按照类似的思路去做:
重复这个操作下来两三次:0x4d7a8 -> 0x4ffd0 -> 0x4bd68 -> 0x4c8e4 -> 0x4e198 -> 0x4e548 -> 0x5bf18 -> 0x5b69c -> 0x5b5e0 -> 0x5b950。其中 0x5b818/0x5bcec 的 state dump 直接打出了 ChaCha20-like 常量、key、nonce,正式把整个处理逻辑给扒干净了,非常之搞笑。(脚本见末尾)
正好有运行时反汇编的操作,顺手就可以确定加密逻辑,并把flag推随机值的一起做了,验证之后是没问题的:(见样例源代码)
其实思路和2021还是2022的ACE保护差不多,都是游戏引擎侧对入口(global-meta.data、gdc)这种做加密,然后提高保护程序的分析难度,上混淆vmp、控制流平坦化什么的,这次赛题没有反调试、但是多环嵌套代码、自修改和动态跳转已经对Hook时机、方式有了一定的保护。同时三环的自修改写得也挺有意思,有外部分发、根据参数跳转执行的方式也对静态分析有了不小的挑战,同时动态分析时Frida的inlinehook是没法随意提前打上去拿各种信息的,stalker不知道为什么总是会崩。总之,很有意思!
解题优化思路:如果有动态trace多线程dump执行流的办法,其实这道题就变得非常简单了,用的frida脚本其实已经有了雏形,可能以后再继续研究看看有没有更好的办法去自动化吧。
打完决赛再放dump执行流的脚本,之后有时间可能改进一下做成工具,思路还是比较自信的,运行时dump听起来就很酷炫,这里多宣传一个个人写得zygisk工具:cb6K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6y4j5i4u0U0K9o6N6Q4x3X3c8U0L8$3c8W2i4K6u0r3h3Y4W2Y4K9i4y4C8d9h3&6B7k6h3y4@1i4@1g2r3i4@1u0o6i4K6S2o6i4@1f1$3i4K6R3@1i4K6W2r3i4@1f1#2i4K6R3#2i4@1t1@1i4@1f1^5i4@1t1$3i4@1p5K6i4@1f1%4i4K6W2m8i4K6R3@1i4@1f1#2i4@1p5@1i4@1p5%4i4@1f1@1i4@1u0p5i4@1q4o6i4@1f1#2i4K6S2r3i4@1q4r3i4@1f1@1i4@1u0n7i4@1p5#2i4@1f1%4i4K6W2o6i4K6S2n7i4@1f1%4i4K6W2o6i4K6S2n7i4@1g2r3i4@1u0o6i4K6S2o6i4@1f1#2i4K6R3H3i4K6W2r3i4@1f1&6i4K6R3&6i4@1t1@1i4@1f1^5i4@1q4q4i4@1u0m8i4@1f1#2i4K6W2p5i4K6W2n7i4@1f1#2i4K6R3$3i4K6R3#2i4@1f1#2i4@1p5@1i4@1p5%4i4@1f1@1i4@1u0p5i4@1q4o6i4@1f1%4i4K6W2m8i4K6R3@1i4@1f1$3i4K6R3K6i4@1t1K6i4@1f1$3i4@1t1K6i4K6V1#2i4@1g2r3i4@1u0o6i4K6W2m8M7$3g2U0j5$3!0E0j5i4m8Q4x3V1u0@1M7X3q4U0k6i4u0Q4c8e0g2Q4z5p5k6Q4b7f1k6Q4c8e0c8Q4b7V1u0Q4b7e0g2Q4c8e0g2Q4z5f1y4Q4b7e0S2Q4c8e0S2Q4b7V1k6Q4z5e0m8Q4c8e0S2Q4b7e0q4Q4z5p5y4Q4c8e0k6Q4z5e0N6Q4b7U0k6Q4c8e0k6Q4z5p5u0Q4b7e0k6Q4c8e0k6Q4z5o6S2Q4b7f1q4K6P5i4y4U0j5h3I4D9i4@1f1^5i4@1t1H3i4K6R3K6i4@1f1%4i4K6V1@1i4@1p5^5i4@1f1%4i4K6W2m8i4K6R3@1i4@1f1@1i4@1t1^5i4K6R3H3i4@1f1@1i4@1t1^5i4@1q4m8i4@1f1#2i4@1t1H3i4K6S2r3i4@1f1#2i4@1t1%4i4@1p5#2i4@1f1#2i4K6R3#2i4@1t1%4i4@1f1K6i4K6R3H3i4K6R3J5
见附件,逆向的加密算法:
#!/usr/bin/env python3
from __future__ import annotations
import argparse
import hashlib
import struct
from pathlib import Path
DEFAULT_INPUT = Path("lib/arm64-v8a/libsec2026.so")
DEFAULT_OUTPUT = Path("lib/arm64-v8a/libsec2026.payload.bin")
DEFAULT_MAP_SIZE_OFFSET = 0x69A60
DEFAULT_COMP_SIZE_OFFSET = 0x69A64
DEFAULT_BLOB_OFFSET = 0x69A6C
DEFAULT_ENTRY_OFFSET = 0x10
def parse_int(value: str) -> int:
return int(value, 0)
def read_u32_le(data: bytes, offset: int) -> int:
return struct.unpack_from("<I", data, offset)[0]
def to_signed32(value: int) -> int:
value &= 0xFFFFFFFF
return value - 0x1_0000_0000 if value & 0x80000000 else value
class Bitstream:
def __init__(self, data: bytes) -> None:
self.data = data
self.offset = 0
self.word = 0x80000000
def read_byte(self) -> int:
if self.offset >= len(self.data):
raise EOFError("read past compressed blob")
value = self.data[self.offset]
self.offset += 1
return value
def next_bit(self) -> int:
carry = 1 if (self.word & 0x80000000) else 0
self.word = (self.word << 1) & 0xFFFFFFFF
if self.word == 0:
if self.offset + 4 > len(self.data):
raise EOFError("reload past compressed blob")
reloaded = read_u32_le(self.data, self.offset)
self.offset += 4
total = reloaded + reloaded + carry
carry = 1 if total > 0xFFFFFFFF else 0
self.word = total & 0xFFFFFFFF
return carry
def decode_varlen(bitstream: Bitstream) -> int:
value = 1
while True:
value = ((value << 1) + bitstream.next_bit()) & 0xFFFFFFFF
if bitstream.next_bit():
return value
def unpack_payload(blob: bytes) -> bytes:
bitstream = Bitstream(blob)
out = bytearray()
last_offset = 0xFFFFFFFF
while True:
if bitstream.next_bit():
out.append(bitstream.read_byte())
continue
code = decode_varlen(bitstream)
if code >= 3:
offset_low = bitstream.read_byte()
last_offset = (~(offset_low | ((code - 3) << 8))) & 0xFFFFFFFF
if last_offset == 0:
break
length = bitstream.next_bit()
length = ((length << 1) + bitstream.next_bit()) & 0xFFFFFFFF
if length == 0:
length = (decode_varlen(bitstream) + 2) & 0xFFFFFFFF
if ((last_offset + 0xD00) >> 32) == 0:
length = (length + 1) & 0xFFFFFFFF
src = len(out) + to_signed32(last_offset)
if src < 0:
raise ValueError(f"invalid back-reference: src={src} offset={last_offset:#x}")
copies = length + 1
for _ in range(copies):
out.append(out[src])
src += 1
if bitstream.offset != len(blob):
raise ValueError(
f"decompression ended at 0x{bitstream.offset:x}, expected 0x{len(blob):x}"
)
return bytes(out)
def build_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(
description="Offline unpacker for the runtime-compressed payload in libsec2026.so."
)
parser.add_argument(
"input",
nargs="?",
type=Path,
default=DEFAULT_INPUT,
help=f"input shared object (default: {DEFAULT_INPUT})",
)
parser.add_argument(
"-o",
"--output",
type=Path,
default=DEFAULT_OUTPUT,
help=f"where to write the unpacked payload (default: {DEFAULT_OUTPUT})",
)
parser.add_argument(
"--map-size-offset",
type=parse_int,
default=DEFAULT_MAP_SIZE_OFFSET,
help=f"offset of the mapped-size dword (default: {DEFAULT_MAP_SIZE_OFFSET:#x})",
)
parser.add_argument(
"--comp-size-offset",
type=parse_int,
default=DEFAULT_COMP_SIZE_OFFSET,
help=f"offset of the compressed-size dword (default: {DEFAULT_COMP_SIZE_OFFSET:#x})",
)
parser.add_argument(
"--blob-offset",
type=parse_int,
default=DEFAULT_BLOB_OFFSET,
help=f"offset of the compressed blob (default: {DEFAULT_BLOB_OFFSET:#x})",
)
parser.add_argument(
"--entry-offset",
type=parse_int,
default=DEFAULT_ENTRY_OFFSET,
help=f"runtime branch target inside the unpacked payload (default: {DEFAULT_ENTRY_OFFSET:#x})",
)
parser.add_argument(
"--pad-to-map-size",
action="store_true",
help="pad the output file to the loader's mmap size",
)
return parser
def main() -> int:
args = build_parser().parse_args()
image = args.input.read_bytes()
map_size = read_u32_le(image, args.map_size_offset)
comp_size = read_u32_le(image, args.comp_size_offset)
blob = image[args.blob_offset : args.blob_offset + comp_size]
if len(blob) != comp_size:
raise ValueError("compressed blob extends past end of file")
payload = unpack_payload(blob)
if len(payload) > map_size:
raise ValueError(
f"payload is larger than mapped size: 0x{len(payload):x} > 0x{map_size:x}"
)
written = payload.ljust(map_size, b"\x00") if args.pad_to_map_size else payload
args.output.parent.mkdir(parents=True, exist_ok=True)
args.output.write_bytes(written)
sha256 = hashlib.sha256(payload).hexdigest()
print(f"input: {args.input}")
print(f"output: {args.output}")
print(f"map size: 0x{map_size:x}")
print(f"blob size: 0x{comp_size:x}")
print(f"payload size: 0x{len(payload):x}")
print(f"entry offset: 0x{args.entry_offset:x}")
print(f"entry file: {args.output}@0x{args.entry_offset:x}")
print(f"sha256: {sha256}")
if args.pad_to_map_size and len(written) != len(payload):
print(f"padded size: 0x{len(written):x}")
return 0
if __name__ == "__main__":
raise SystemExit(main())
00001450 // 二环装载器:根据 arg1
00001450 // 的自相对头字段计算重定位基址与下一环入口;把
00001450 // rebase + *(u32 *)(arg1 + 0xc) 处的内嵌 UPX
00001450 // 风格容器复制到临时映射并解包;遍历 arg3 +
00001450 // 0x40 开始的 0x38
00001450 // 字节描述符,逐段映射、修补并设置权限;如遇可执行尾段则通过
00001450 // memfd 构造 16 字节 RX 跳板;最后在 0x1778
00001450 // 跳入重定位后的下一环入口。
00001458 int64_t x19
00001458 int64_t var_e0 = x19
0000147c float128 v15
0000147c sub_1004(arg1, x19, v15) // 设置描述符号
00001484 // 计算重定位基址:arg1
00001484 // 头字段是自相对偏移,因此 base = arg1 - *(u32
00001484 // *)arg1。
0000148c double v9 = float.d(arg1 - zx.q(*arg1))
00001490 int32_t x1 = (*(arg1 + 8)).d
00001494 int64_t var_10 = *arg1
000014a4 // 定位内嵌的下一环压缩块:packed_blob = rebase_base
000014a4 // + *(u32 *)(arg1 + 0xc)。
000014a4 char* x19_2 = v9 i+ zx.q(arg1[3])
000014b4 // 定位重定位后的下一环入口:next_entry =
000014b4 // rebase_base + *(u32 *)(arg1 + 4)。
000014b4 double v10 = float.d(v9 i+ zx.q(arg1[1]))
000014b8 uint64_t x0_6 = zx.q(arg1.d - x19_2.d)
000014dc // mmap
000014dc // 申请 RW
000014dc // 临时映射,用来承接下一环的压缩容器。
000014dc char* x0_7 = sub_74()
000014f0 // 拷贝缓冲区
000014f0 // 把内嵌压缩块复制到临时映射中。
000014f0 sub_f48(x0_7, x19_2, x0_6)
000014fc uint64_t var_20 = zx.q(*(x0_7 + 0x18))
00001500 void* var_18 = arg3
0000150c uint64_t var_30 = zx.q(*(x0_7 + 0x1c)) + 0xc
00001510 void* var_28 = &x0_7[0x18]
0000151c // 初始化 / 推进 scratch+0x18 处的 UPX
0000151c // 风格块流解析器。
0000151c sub_1150(&var_30, &var_20)
00001520 // 执行起始地址
00001520 // 描述符表起点:arg3 + 0x40;每项大小 0x38 字节。
00001520 int64_t* x19_3 = arg3 + 0x40
00001530 // desc_end = desc_table + (*(u16 *)(arg3 + 0x38) *
00001530 // 0x38),准备遍历全部段描述符。
00001530 void* x23_1 = &x19_3[zx.q(*(arg3 + 0x38)) * 7]
00001530
00001538 if (x19_3 u< x23_1)
0000153c int32_t x24_1 = 0
00001540 int64_t x21_1 = 0
00001540
00001750 do // 修补映射的主逻辑
00001550 // 读取 desc->type_flags;只有 (type_flags &
00001550 // 0x2ffffffff) == 1 的项会按可装载段处理。
00001564 if ((*x19_3 & 0x2ffffffff) == 1)
00001568 if (x21_1 == 0)
0000156c // 首个可装载段会建立统一的
0000156c // load_bias:load_bias = rebase_base -
0000156c // desc->vaddr。
00001574 x21_1 = v9 i- x19_3[2]
00001574
00001578 // 计算当前段的逻辑末尾 desc->vaddr +
00001578 // desc->filesz,并从块流中取出下一个 0xc
00001578 // 字节块头。
00001580 int32_t x20_2 = (x19_3[2]).d + (x19_3[4]).d
00001584 var_30 = 0xc
00001594 int32_t var_50
00001594 sub_10f0(&var_30, &var_50, 0xc)
000015a0 var_28 -= 0xc
000015a8 int32_t var_4c
000015a8 var_30 = zx.q(var_4c)
000015ac int32_t x0_21 = var_50
000015b0 uint64_t x1_9 = zx.q(x0_21)
000015b4 // chunk_len =
000015b4 // hdr[0];记录本次要回填到当前段的块长度。
000015b4 var_20 = x1_9
000015c0 // 计算当前块的落点:dst = load_bias +
000015c0 // (desc->vaddr + desc->filesz - chunk_len)。
000015c0 int64_t x1_11 = zx.q(x20_2) - x1_9 + x21_1
000015c0
000015dc if (x19_3[1] + x19_3[4] u> zx.q(x1) || x24_1 != 0)
000015ec int32_t var_64_1
000015ec
000015ec if ((*(x19_3 + 4) & 1) == 0)
00001600 // 若 desc->flags.bit0
00001600 // 未置位,则走匿名 RW
00001600 // 映射路径(sub_f6c)。
00001604 sub_f6c(x0_21, x1_11, arg1.d)
00001608 var_64_1 = 0
000015ec else
000015f0 // 若 desc->flags.bit0 置位,则走
000015f0 // file-backed /
000015f0 // 对齐映射路径(sub_1374)。
000015f8 var_64_1 = sub_1374(x0_21, x1_11, arg1)
000015f8
0000160c // 保存当前 chunk_len /
0000160c // dst,随后推进块流到下一个块。
0000160c uint32_t x0_23 = var_20.d
00001620 sub_1150(&var_30, &var_20)
00001620
00001628 // 只有可执行 / file-backed
00001628 // 类型的段才会继续进入下面的跳板与最终权限处理逻辑。
0000162c if ((*(x19_3 + 4) & 1) != 0)
00001644 int32_t var_40_1 = 0xd4000001
00001650 int32_t var_3c_1 = 0xa9417be2
0000165c int32_t var_38_1 = 0xa8c207e0
00001668 int32_t var_34_1 = 0xd61f03c0
00001668
0000166c // 特殊分支:只处理 masked
0000166c // type_flags == 0x100000001
0000166c // 的描述符(可执行尾段 /
0000166c // 跳板场景)。
0000167c if ((*x19_3 & 0x1ffffffff) == 0x100000001)
00001680 // 计算尾部 slack = desc->memsz -
00001680 // desc->filesz;若满足页对齐约束,则为尾段构造
00001680 // RX 跳板。
0000169c if ((neg.d(x1_11.d + (x19_3[5]).d - (x19_3[4]).d)
0000169c & not.d(arg1.d)) u> 0xf)
0000169c jump(0x16a0)
0000169c
000016dc int64_t __saved_fp
000016dc // 通过 memfd_create -> write(16-byte
000016dc // veneer) -> mmap(PROT_RX)
000016dc // 生成临时可执行跳板,结果保存在
000016dc // x26。
000016dc sub_16e4(x19_3, x1_11, x21_1, 0xffffffffffff, x23_1, x24_1,
000016dc 0xc, arg2, x1, &__saved_fp, v9, v10)
000016e0 undefined
000016e0
0000172c // 调用 sub_12c4
0000172c // 完成当前段的收尾:设权限、刷
0000172c // I-cache,并按需要释放中间映射。
00001740 sub_12c4(x0_23, x1_11, x19_3, var_64_1, x21_1)
00001740
00001744 x24_1 += 1
000015dc else
000015e0 x24_1 += 1
000015e0
00001748 // 移动到下一个 0x38
00001748 // 字节描述符,继续装载循环。
00001748 x19_3 = &x19_3[7]
00001750 while (x23_1 u> x19_3)
00001750
00001764 // 释放之前为压缩容器申请的 scratch 映射。
00001764 sub_1c(x0_7, x0_6)
00001778 // 正式跳入下一环入口:blr next_entry(zx.q(*arg2),
00001778 // *(arg2 + 8), *(arg2 + 0x10))。
00001778 v10(zx.q(*arg2), *(arg2 + 8), *(arg2 + 0x10))
0000179c return 0
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!




