-
-
[原创]Polaris-Obfuscator中IndirectCall简要分析+反混淆
-
发表于: 2026-3-20 13:50 12535
-

za233/Polaris-Obfuscator: Polaris: An LLVM-based obfuscator that protects software at various levels
这个obfuscation pass简单来说就是把直接调用改成间接调用。比如:
改成:
在我所测试用的例子里面,代码如下:
反编译出来就是:
在该Obfuscator的具体实现中(见src/llvm/lib/Transforms/Obfuscation/IndirectCall.cpp):
总结一下就是:
然后创建IR来构造以下公式:GV - random_value. 这个值也就是func_addr。不过由于这个地址是动态创建的,因此编译器会使用间接调用(e.g., call rax)来调用函数.
个人认为单独使用这个obfuscation pass并不能提供太强的保护。从上面Ghidra提供的例子都可以发现,在间接调用上都已经直接表明了会跳转到的真实函数。但是一但结合其他的obfuscation pass,尤其是MBA obfuscation,分析地址的过程就会变得复杂很多.
考虑到该obfuscation pass通常还会与更复杂的数据流混淆pass结合使用,比如MBA obfuscation,本人并不打算直接针对该pass的构造流程来进行deobfuscation。我的想法是,先提出一个更通用的去混淆方法(一个框架/workflow),进而实现通用性的deobfuscation方法.
我将这个问题建模为一个约束求解问题:在一个间接调用点I处,我们已知的信息是:call var。这里的var可以是一个寄存器(如call rax),也可以是一个内存地址(如call [0x114514]);但无论哪种情况,它都不是一个直接调用(即不是一个常量)。我们的目标是找出var的所有可能取值。如果这个间接调用是由类似上述obfuscation pass构造的,那么var的可能取值应该只有一个。我们可以将其形式化为一个更通用的约束收集与求解问题:
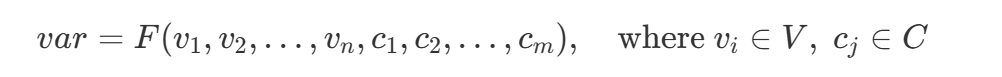
其中 VV 是所有参与构造 var 的变量集合,CC 是所有参与构造的常量集合。函数 FF 是对构造 var 的数据流的一般性表示。以上面的例子为例,FF 可以表示为`GV-MaskValue`.
所以说我们的目标其实很简单,就三个步骤:
这是我针对上述概念简单编写的一个working prototype,目前在IndirectCall+MBA Obfuscation的一个样本上通过了测试。
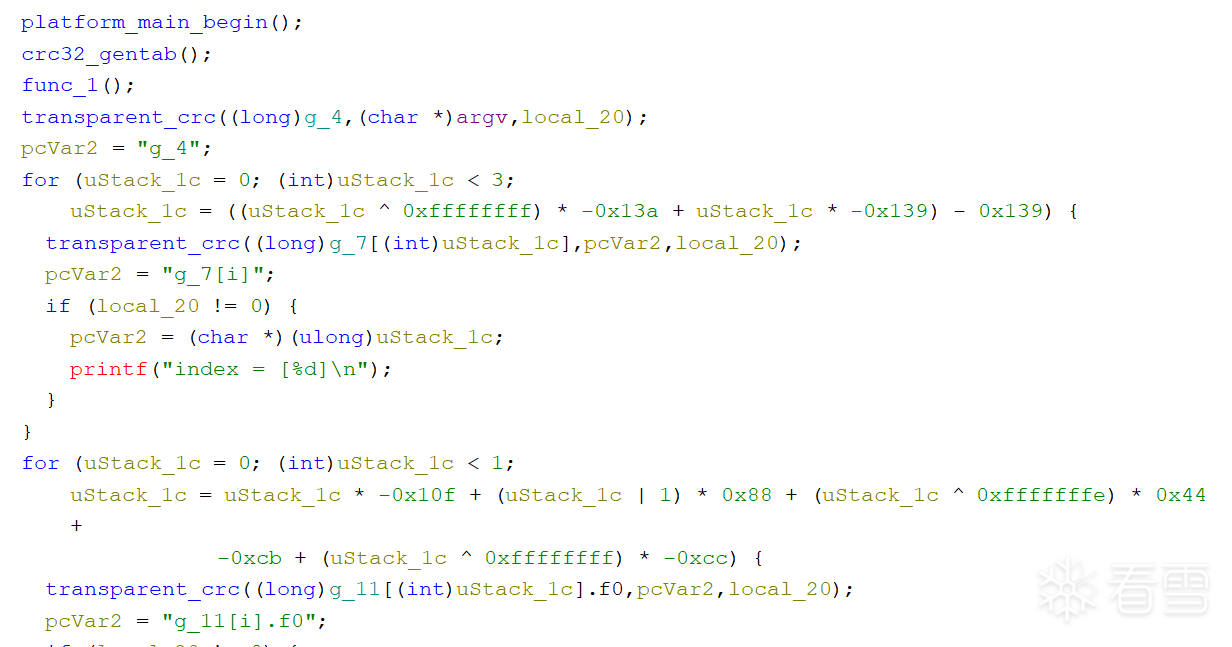
这是IndirectCall+MBA混淆后的:

patch后:
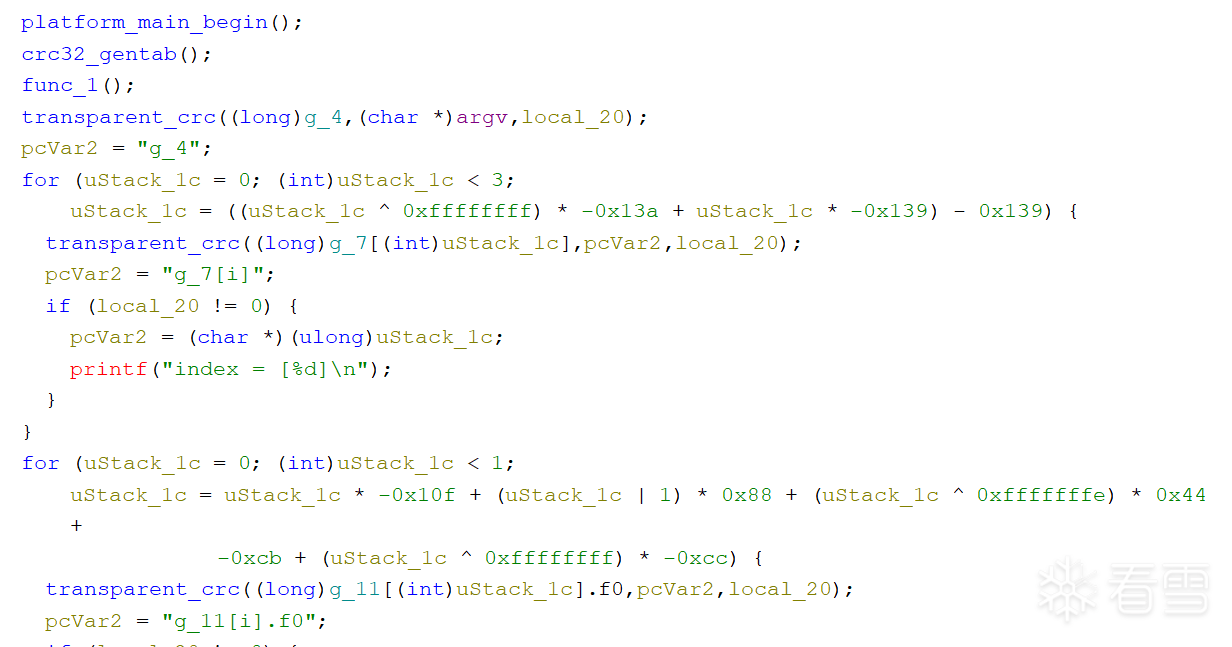
优化后:
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|




