-
-
[原创]Ghidra反编译器的设计与实现(2)
-
发表于: 2026-3-16 19:37 1558
-

前文介绍了Ghidra反编译器的调试环境搭建,相信看到上篇文章的读者都已经把环境搭建起来了,当然要是没有搭建起来也是可以看本篇文章的,不过少了些动手的乐趣,让我们开始吧。
本文会介绍
Ghidra如何实现反汇编?
中间代码PCode如何生成?
C语言的If语句如何生成?
Ghidra如何实现反汇编?
本文以一个最小exe文件来分析反编译器的流程,IDA载入该exe文件,可以看到在0x140000300的程序开头处是一条比较语句,Ghidra如何处理这条指令呢?
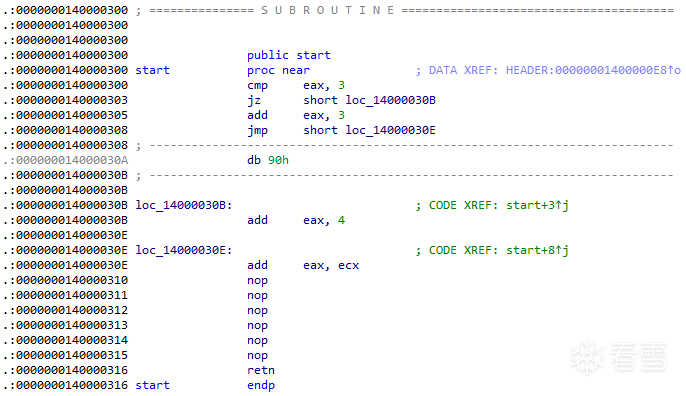
打开安装有Ghidra的Ubuntu虚拟机,
用VS Code远程打开Ghidra/Features/Decompiler/src/decompile/cpp目录,
F5开始调试。
首先载入要分析的exe文件,指令是
load file /mnt/hgfs/prj/test/tt3.exe
在sleigh.cc文件
ParserContext *pos = obtainContext(baseaddr, ParserContext::pcode);
下好断点,然后执行
load addr 0x140000300
不出意外程序会停在下好的断点处。
进入这个函数,可以看到
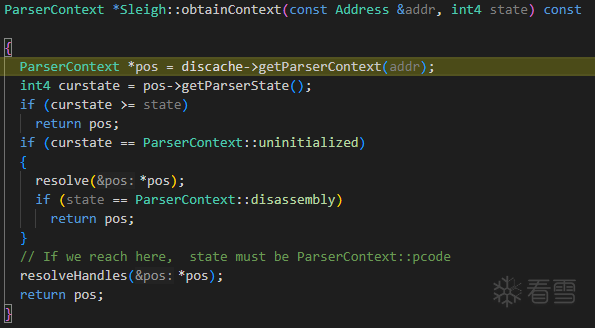
首先需要分析的是resolve()函数,这个函数完成的是反汇编工作。
在resolve()函数中首先的重点是
ct = root->resolve(walker)
resolve(walker)函数内部执行了很复杂的匹配工作,主要根据cmp eax,3的机器码83 F8 03得到ct,这个匹配很复杂,好在我们可以直接忽略这个函数,不影响我们的分析。
得到ct后会根据特定脚本文件的内容建立内存中的树状结构,这牵涉到Ghidra反汇编器的基本机制。
在Ghidra\Processors\x86\data\languages文件夹下有一个脚本文件ia.sinc,这个文件是x86_64架构cpu指令集的描述文件,之所以是这个文件会被采用是因为我们载入的exe是这个指令集。
对于比较语句“cmp eax,3”首先会对应到ia.sinc的3062行
:CMP rm32,simm8_32 is vexMode=0 & opsize=1 & byte=0x83; rm32 & reg_opcode=7 ...; simm8_32 { local temp:4 = rm32; subflags(temp,simm8_32); local diff = temp - simm8_32; resultflags(diff);}这个脚本首先是
CMP rm32,simm8_32
这代表这这条指令的构成方式,在resolve()函数接下来的程序执行中会解析这个脚本文件,首先得到rm32的信息,这在ia.sinc的1487行
rm32: Rmr32 is mod=3 & Rmr32 { export Rmr32; }rm32又依赖Rmr32,程序继续分析脚本文件会引用ia.sinc的848行内容
Rmr32: r32 is rexBprefix=0 & r32 { export r32; }至此“cmp eax,3”的第一个操作数确定下来了。接下来程序分析第二个操作数simm8_32,这会引用ia.sinc的924行
simm8_32: simm8 is simm8 { export *[const]:4 simm8; }这样“cmp eax,3”这条指令就被转换为了内存中的数状结构以便接下来的程序继续处理。反汇编结构就分析到这,接下来是resolveHandles()函数,这个函数中会继续分析“cmp eax,3”汇编语句机器码83 F8 03的后两个字节,对汇编比较熟悉的朋友知道F8字节用于确定cmp指令的第一个操作数是哪个寄存器,在ia.sinc的3062行首先可以看到
byte=0x83
刚好“cmp eax,3”的机器码的第一个字节是0x83,所以“cmp eax,3”确实会绑定到ia.sinc的3062行。继续看脚本的3062行,接下来是
rm32 & reg_opcode=7
搜索ia.sinc可以在536行可以看见
reg_opcode = (3,5)
这代表这reg_opcode表示一个字节中的3,4,5三个比特位。由于
reg_opcode=7
所以比较指令“cmp eax,3”的第二字节只能表示为:xx111xxx,x表示不定。
继续查看上面的这条
rm32: Rmr32 is mod=3 & Rmr32 { export Rmr32; }其中mod为3,而mod在ia.sinc的535行
mod = (6,7)
mod为3就表示一个字节中的第6,7比特位全为1,所以比较指令“cmp eax,3”的第二字节只能表示为:11111xxx,x表示不定。
现在只差最低位的三个比特没有确定了,继续看上面的这条
Rmr32: r32 is rexBprefix=0 & r32 { export r32; }这条中的r32在ia.sinc的560行
r32 = (0,2)
这代表r32是一个字节中的最低3位。比较指令“cmp eax,3”中的不同寄存器就被编码为不同的这3个比特,由于只有3个比特所以最多可以表示8个不同的寄存器。看ia.sinc的690行
attach variables [ r32 reg32 base index ] [ EAX ECX EDX EBX ESP EBP ESI EDI ];
这就确定了r32的值对应的寄存器,对于“cmp eax,3”,由于是寄存器eax,所以比特位为000,比较指令的第二字节为11111000,刚好是0xF8。
分析完了“cmp eax,3”的机器码83 F8 03的第二个字节,resolveHandles()函数接下来会将exe文件中的0x140000300处的第三个字节03提取出来,以便后用。
Ghidra反汇编的总结:
Ghidra通过编写自己内部定义的脚本语言文件来实现机器码到汇编语言的转换,ia.sinc就是按照这个脚本语言规则编写的CPU指令集描述,要想自己扩展反编译对不同CPU指令集的支持,就需要自己去编写脚本语言文件。Ghidra会将编写的脚本语言文件读入后编码,然后将编码后的文件输出为后缀名为sla的文件,在Ghidra反编译器初始化过程中会读入对应CPU指令集的sla文件,然后解码sla文件的内容生成内存结构。在反汇编阶段,其实主要就是用exe文件的机器码去Ghidra中查询得到对应的内存结构,再做进一步处理。
脚本语言除了能够实现机器码到汇编语言的转换,还可以进一步实现汇编语言到PCode的转换,不管是哪种CPU的机器码,Ghidra都会根据对应脚本文件将机器码转换为PCode,这可以认为是反编译器的前端,反编译之后的动作全部都围绕PCode进行,通过这样的方式,Ghidra实现了对多种CPU指令集的支持。
脚本语言的解析
在编写完脚本语言后,Ghidra会调用相应程序去解析脚本语言文件,这些解析代码不是直接用C++写的,而是用工具生成的,脚本语言的词法分析阶段是在slghscan.I中描述的,语法解析阶段实在slghparse.y文件中描述的。在make编译阶段,slghscan.I和slghparse.y都会被工具处理为可编译的C++文件,工具为bison/flex。
PCode的生成
还是以“cmp eax,3”为例来介绍PCode的相关内容
:CMP rm32,simm8_32 is vexMode=0 & opsize=1 & byte=0x83; rm32 & reg_opcode=7 ...; simm8_32 { local temp:4 = rm32; subflags(temp,simm8_32); local diff = temp - simm8_32; resultflags(diff);}在大括号内部就是这条比较指令会转换为哪条PCode的描述。
在执行完前面我们所下断点处的代码处后会继续往下执行,来到PCode的处理函数。
builder.build(walker.getConstructor()->getTempl(), -1); pcode_cache.resolveRelatives(); pcode_cache.emit(baseaddr, &emit);
首先
walker.getConstructor()
这条指令就会取出前面辛辛苦苦resolve得到的ct,然后调用了它的getTempl()函数,这个模板就是解析脚本文件所得到的PCode的模板。
接下来进入build函数中,主要看它的dump()函数,该函数在一个for循环中,会将解析得到的PCode一一处理。
首先dump()函数处理的PCode是CPUI_COPY指令,我们结合脚本语言中的描述来看看到底有没有这条PCode
local temp:4 = rm32
可见“cmp eax,3”脚本语言中大括号的第一个部分的确有复制的行为,所以这样脚本语言中的内容就被处理了。
接下来继续调试,dump()函数处理的PCode是CPUI_INT_LESS,接着看大括号内部的语句
subflags(temp,simm8_32);
在ia.sinc的2164行
macro subflags(op1,op2) {
CF = op1 < op2;
OF = sborrow(op1,op2);
}看到了吗,首先的确是在做比较操作,而且是小于的比较,这正好是PCode的CPUI_INT_LESS中的LESS。
继续调试,dump()函数处理的PCode是CPUI_INT_SBORROW,一眼可见这是正确的。
继续调试,dump()函数处理的PCode是CPUI_INT_SUB,
local diff = temp - simm8_32;
可见的确是在做减法。
继续调试,dump()函数处理的PCode是CPUI_INT_SLESS
resultflags(diff)
在ia.sinc的2142行
macro resultflags(result) {
SF = result s< 0;
ZF = result == 0;
PF = ((popcount(result & 0xff) & 1:1) == 0);
# AF not implemented
}可见,首先是比较。
继续调试,dump()函数处理的PCode是CPUI_INT_EQUAL,这是等于判断,也对的上。
继续调试,dump()函数处理的PCode是CPUI_INT_AND,这是与操作,对应的是&。
继续调试,dump()函数处理的PCode是CPUI_POPCOUNT。
继续调试,dump()函数处理的PCode是CPUI_INT_AND,这是与操作,对应的是&。
继续调试,dump()函数处理的PCode是CPUI_INT_EQUAL,转换结束。
这样一条“cmp eax,3”汇编就被转换为多条PCode了。
在dump()函数中,还会将前面的resolveHandles()函数中提取的信息,如“cmp eax,3”中的3利用起来。
接下来是
pcode_cache.emit(baseaddr, &emit);
这个函数中会将生成的PCode做进一步封装。PCode被封装到PcodeOp类型对象中,同时“cmp eax,3”中的3被封装到Varnode类型对象中,并将Varnode设置为PcodeOp类型对象的输入。这样一条扁平的“cmp eax,3”就被表示为立体的内存结构了。
If语句的生成
介绍了基本的反汇编和PCode生成,我们就有基础了,所以再来介绍一条If语句是如何生成的。
本文的tt3.exe被设计为一条If语句的结构。一条If语句结构如下:
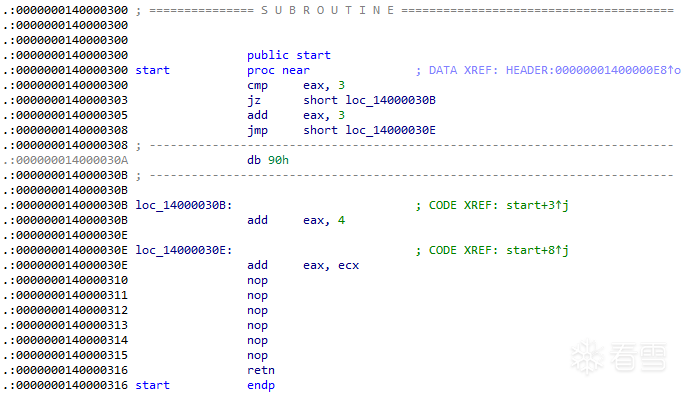
首先是判断语句cmp,比较eax和3,如果eax为3,则z标志位为1,jz跳转实现,将eax+4赋值给eax,执行14000030E代码,如果eax不为3,z标志位不为1,将eax+3赋值给eax,然后跳转执行14000030E代码。
下面分析Ghidra如何处理这段机器码。
首先是前面分析过的反汇编和生成PCode阶段,这部分就不重复分析了,重点分析
void FlowInfo::generateBlocks(void)
该函数内主要是以下3个函数
collectEdges(); splitBasic(); connectBasic();
首先看collectEdges()函数,该函数会根据PCode中的跳转相关指令,生成边,边的开始是一条PCode,边的另一边是一条目标PCode,对于tt3.exe的代码会生成4条边,如下图所示:
接下来是关键函数splitBasic()函数
这个函数完成将一个整体PCode分散为多个小的基本块,如上图所示,会被分为4个基本块,如何分块的很快就会提到。
然后是connectBasic()函数,该函数将分块之后的基本块通过边连接起来。
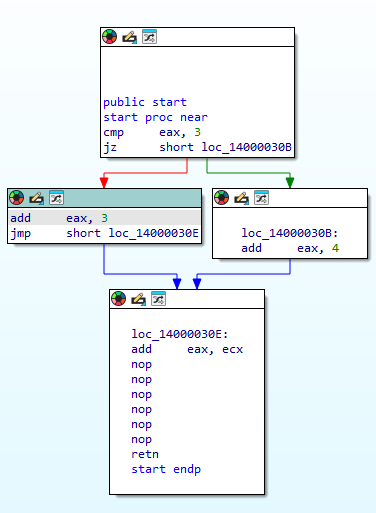
下面重点介绍基本块是如何分割出来的。
首先是cmp指令,该指令在一个基本块中,然后是jz指令,该指令的目的地址被标记为一个基本块的起始地址,然后jz指令的下一条指令也会被标记为一个基本块的起始地址。这样就有了第一个基本块。
继续处理,“add eax,3”,由于被jz指令标记了,所以会生成第二个基本块,接下来是jmp指令,该指令和“add eax,3”在一个基本块中。由于是jmp指令,所以该指令的目的地址被标记为一个基本块的起始地址,然后jmp指令的下一条指令也会被标记为一个基本块的起始地址。
接下来是“add eax,4”,由于这个地址被jz指令标记为一个基本块的起始地址,所以我们有了第三个基本块。
接下来是“add eax,ecx”,由于这个地址被jmp指令标记为一个基本块的起始地址,所以我们有了第四个基本块。
现在只剩下最后一步了,识别基本块之间的拓扑结构并生成If语句。
在CollapseStructur::ruleBlockIfElse()函数中下好断点,在命令行中执行
decompile
不出意外,程序被断下来了。
bool CollapseStructure::ruleBlockIfElse(FlowBlock *bl)
{
FlowBlock *tc, *fc, *outblock;
if (bl->sizeOut() != 2)
return false; // Must be binary condition
if (bl->isSwitchOut())
return false;
if (!bl->isDecisionOut(0))
return false;
if (!bl->isDecisionOut(1))
return false;
tc = bl->getTrueOut();
fc = bl->getFalseOut();
if (tc->sizeIn() != 1)
return false; // Nothing else must hit true clause
if (fc->sizeIn() != 1)
return false; // Nothing else must hit false clause
if (tc->sizeOut() != 1)
return false; // Only one exit from clause
if (fc->sizeOut() != 1)
return false; // Only one exit from clause
outblock = tc->getOut(0);
if (outblock == bl)
return false; // No loops
if (outblock != fc->getOut(0))
return false; // Clauses must exit to same place
if (tc->isSwitchOut())
return false;
if (fc->isSwitchOut())
return false;
if (tc->isGotoOut(0))
return false;
if (fc->isGotoOut(0))
return false;
graph.newBlockIfElse(bl, tc, fc);
return true;
}这个函数就是生成If语句的地方。
参数bl表示语句块,语句块结构参考上面的截图。
bl->sizeOut() != 2
表示该结构的入口点必须有两个出口,对于我们的exe文件的代码,这是满足的。
tc = bl->getTrueOut(); fc = bl->getFalseOut();
获取两个出口,一个为jz条件为真的出口,一个为jz条件为假的出口。
tc->sizeIn() != 1
条件为真的块必须只有一个入口。
fc->sizeIn() != 1
条件为假的块必须只有一个入口。
tc->sizeOut() != 1
条件为真的块必须只有一个出口。
fc->sizeOut() != 1
条件为假的块必须只有一个出口。
outblock = tc->getOut(0); if (outblock == bl) return false; // No loops if (outblock != fc->getOut(0))
条件为真的出口块必须等于条件为假的出口块。
这些判断条件就是为了确定这张图的拓扑结构
这样If的结构就被识别出来了。所以下面生成了If语句块。
graph.newBlockIfElse(bl, tc, fc);
有了语句块,最后打印出来就生成了If语句,打印函数为:
PrrintC::emitBlockIf
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|

- [原创]Windows内核之exe文件section 1318
- [原创]Windows内核之载入exe文件 1399
- [原创]Windows内核之鼠标处理 1593
- [原创]让Qiling框架支持结构化异常(SEH) 9591
- [原创]Ghidra反编译器的设计与实现(2) 1557



