* 本文由 AI 阅读 OBPO 代码后撰写
OLLVM 的控制流平坦化(Control Flow Flattening,下称 CFF)大概是前几年移动安全领域遇到最多的代码混淆方案。它的原理不复杂:把函数里所有基本块拆散,塞进一个由状态变量驱动的 switch-loop 结构里,让原本的顺序执行和分支跳转全部变成"修改状态变量 → 回到分发器 → 跳到下一个 Case"。效果也很直接——反编译器输出一个巨大的 while-switch,控制流图变成一朵以分发器为圆心的菊花图,原始的程序逻辑被彻底打散。
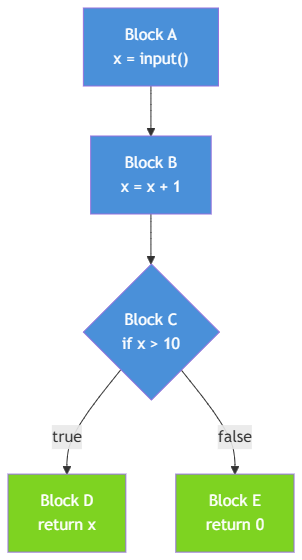
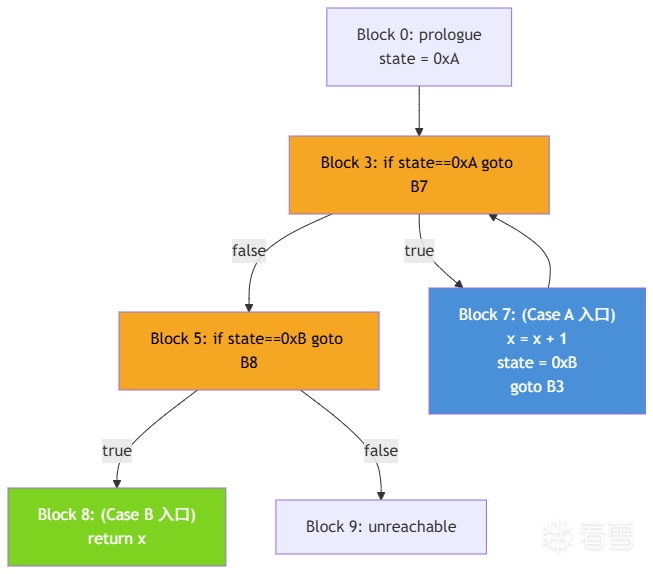
假设原始函数的控制流是这样的:
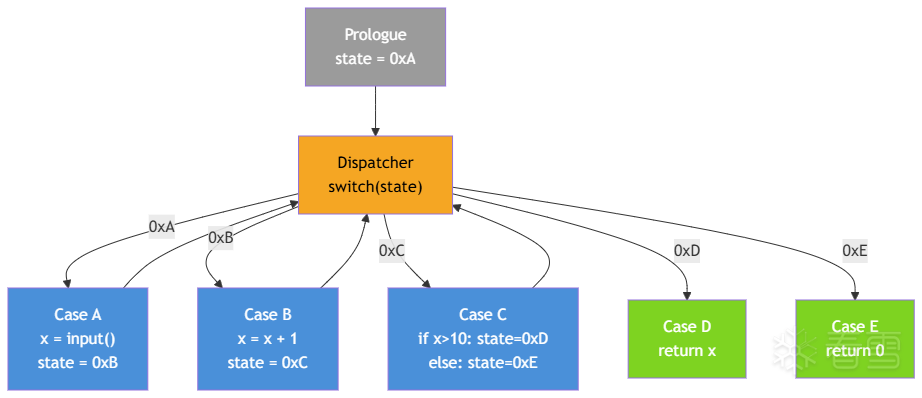
经过 CFF 混淆后,变成了这样:
所有块的原始连接关系全部消失,取而代之的是每个块都从 Dispatcher 出发、再跳回 Dispatcher 的星形拓扑。
对于分析者而言,手动恢复一两个函数并不困难,但当目标里有几百个被平坦化的函数时,自动化就成了刚需。obpo 就是为此而生的工具,它工作在 IDA Hex-Rays 的 Microcode 中间表示上,通过分析和修改 Microcode 的控制流图(CFG),让反编译器自己输出正确的伪代码。
本文将介绍 obpo 内部的处理思路与实现方法。由于 obpo-core 并未开源,文中以阐述原理和设计思路为主。
在二进制层面做反混淆通常有两种路径:直接 patch 二进制指令,或者修改反编译器的中间表示。
patch 二进制的好处是直观,但问题也很多:不同架构的指令集差异巨大,需要处理指令编码、对齐、重定位等细节,还要考虑分支距离溢出等工程问题。
Hex-Rays 的 Microcode 是一种统一的中间表示,不管底层是 ARM、x86 还是 MIPS,到了 Microcode 层面都是同一套指令集和 CFG 结构。在这里做修改有几个好处:
跨架构 ,一套逻辑适配所有 IDA 支持的处理器。
直接影响反编译结果 ,修改 Microcode CFG 后,Hex-Rays 的后续优化 pass 和类型推断会自然地基于修正后的 CFG 继续工作,最终输出干净的伪代码。
不污染二进制文件本身 ,所有修改都发生在内存中的中间表示上。
obpo 选择在 MMAT_GLBOPT1(全局优化阶段)的 Microcode 上工作。这个阶段足够成熟——常量传播和简单的死代码消除已经完成,能减少很多混淆引入的噪声;同时又不至于太晚,CFG 结构还保持着与原始控制流的对应关系。在整个 Hex-Rays 的处理流水线中,obpo 的介入位置大致如下:
在介绍具体步骤之前,先定义几个贯穿全文的概念。
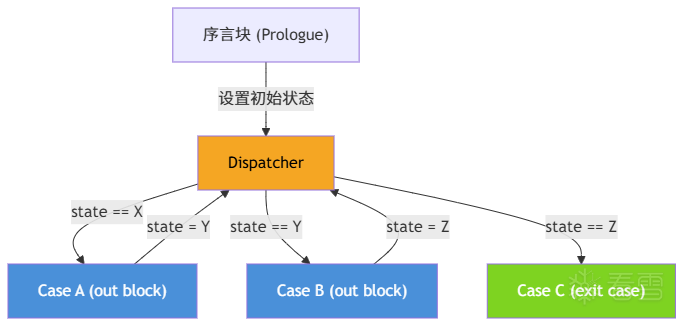
一个被 CFF 混淆的函数,其 Microcode CFG 可以被划分为三个部分:
Dispatcher 是平坦化的核心——由一组基本块构成的分发网络。它读取状态变量,进行比较或计算,然后通过一系列条件跳转把控制流导向不同的 Case。一个典型的 Dispatcher 可能只是一个 switch 的展开形式(一连串 if-else),也可能是多层嵌套的比较树。
Dispatcher 内部的指令可以分为两类:
计算指令(Calculation) :对状态变量进行赋值、运算。
分发指令(Dispatch) :消费状态变量值的条件跳转。
Case 是原始程序的一个基本块(或一段连续的基本块),是真正承载业务逻辑的部分。在混淆后的 CFG 中,Case 从 Dispatcher 的某个出口被跳入,执行完自己的逻辑后,会修改状态变量的值,然后跳回 Dispatcher,由 Dispatcher 决定下一步去哪个 Case。
一个 Case 可能很简单(只有一条赋值语句),也可能包含复杂的控制流(内部的 if-else、循环等)。所以 Case 有自己的入口和出口——入口是从 Dispatcher 跳入的第一个块,出口是最终跳回 Dispatcher 的那个块。
在 obpo 的术语中:
Out Block :Case 的入口块,即 Dispatcher 的"出口"。它是 Dispatcher 的后继,但它不支配任何 dispatch block——换句话说,它是控制流真正离开 Dispatcher 内部判断逻辑的地方。
Exit Case :那些不会再跳回 Dispatcher 的 Case(比如函数的 return)。
如果把上面的结构画出来,核心问题就很清楚了:
混淆后的 CFG 里,Case A 执行完之后并不是直接跳到 Case B,而是把状态变量改成 Y,跳回 Dispatcher,Dispatcher 再根据 state == Y 跳到 Case B。我们要做的就是把中间绕了一圈 Dispatcher 的间接跳转,还原成 Case A → Case B 的直接跳转 。
这个"Case A 的出口,经过 Dispatcher,到达 Case B 的入口"的一条完整路径,就是一个 Flow 。准确地说,一个 Flow 记录了:
从哪个 Case 出发( start_block)
在哪个位置跳入 Dispatcher( edge:从 edge.src 跳到 edge.dest)
经过哪个 Dispatcher 入口( dispatch_block)
最终到达哪个 Case 入口( dest_block,即目标 Out Block)
以及这条路径上完整的执行轨迹(emulation trace)
整个 obpo 的工作,就是找到所有的 Flow,然后根据 Flow 把 CFG 缝回去。
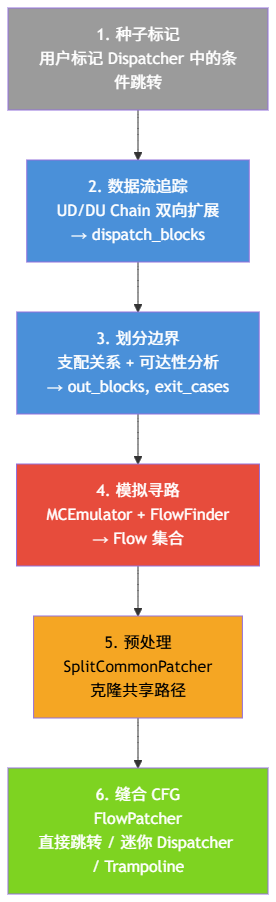
下面这张图概括了 obpo 的完整处理流程:
要恢复控制流,第一步是搞清楚哪些块是 Dispatcher 的一部分,哪些块是 Case 的一部分。
obpo 需要用户标记至少一个 Dispatcher 中的条件跳转指令作为种子。这个标记不需要特别精确——只要是 Dispatcher 中任意一个条件跳转块即可。用户可以标记多个。
拿到种子之后,从它所在的块中提取出尾部的条件跳转指令,作为分析的起点。
仅凭一个种子是不够的——Dispatcher 通常由多个块组成,我们需要找到所有参与分发逻辑的块。方法是利用状态变量的数据流关系,从种子出发,双向扩展。
首先,obpo 自己实现了一套基于块级别的 UD/DU Chain(Use-Definition / Definition-Use Chain)。为什么不直接用 IDA 自带的数据流分析?因为这里需要的是一个轻量的、能以"变量在哪个块被定义/使用"为粒度进行查询的链,而不是 IDA 内部用于优化的完整数据流信息。自实现的 DataFlowChains 在整个 MBA 上做一次前向传播,就能得到所有块之间的变量定义-使用关系。
有了 UD/DU Chain,从种子开始做交替的双向追踪:
反向追踪 :从种子指令出发,沿着 UD Chain 向上查找——这条条件跳转用到了哪个变量?这个变量是在哪里被赋值的?赋值指令又用到了哪些变量?一路追上去,就能找到所有参与状态变量计算的指令(Calculation Instructions)。
正向追踪 :从找到的计算指令出发,沿着 DU Chain 向下查找——这个计算结果被谁使用了?如果使用者是一个条件跳转指令,那它就是一个新的分发指令(Dispatch Instruction)。
这两个方向的追踪交替进行,直到不再有新的指令被发现。这是一个类似不动点的迭代过程,伪代码大致如下:
追踪结束后,所有 Dispatch Instruction 所在的块构成 dispatch_blocks 集合。
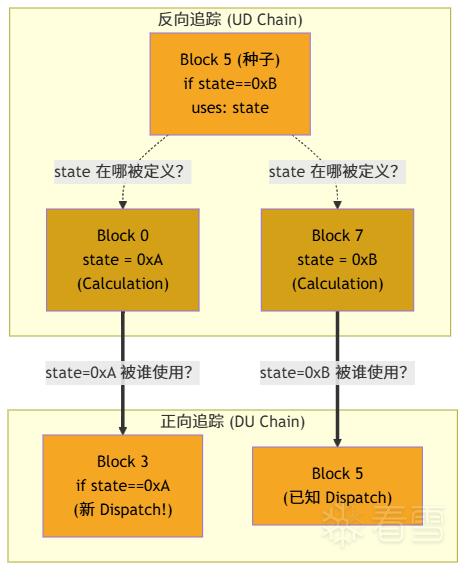
假设一个平坦化函数的 Microcode CFG 如下,Block 5 被标记为种子:
从 Block 5 的条件跳转 if state==0xB 开始,数据流追踪的过程如下:
反向追踪找到了 Block 0 和 Block 7 中的计算指令,正向追踪从这两个计算指令出发,发现 Block 3 的条件跳转也是分发指令。不再有新的发现,迭代结束。
最终得到:
Calculation Instructions:Block 0 的 state = 0xA,Block 7 的 state = 0xB
Dispatch Instructions:Block 3 的 if state==0xA,Block 5 的 if state==0xB
Dispatch Blocks:{3, 5}
找到了 Dispatcher 的所有块之后,下一步是把 CFG 中的其他块进行分类。在这个过程中,支配树(Dominator Tree)分析扮演了核心角色。
补充一个图论概念:
A 支配 B (A dominates B):意味着在 CFG 中,从起点到达 B 的每一条可能路径,都 必须 经过 A。
反过来就是:B 的支配者中包含了 A 。
Dispatch Entry 是整个分发网络的唯一入口点。在所有 dispatch blocks 中,如果有一个块支配了其他所有的 dispatch block ,那它就是 Entry。直觉上,所有回跳到 Dispatcher 的路径,都必须在这个块汇合。
Prologue 是函数开头、在第一次进入 Dispatcher 之前对状态变量进行初始化的块。判断方法:对于包含计算指令(calculation block)的块,如果它的支配者集合中没有任何 dispatch block ,说明到达它根本不需要经过分发逻辑,它自然处于整个分发网络“上方”的序言部分。
Out Block 的检测从 Dispatcher 的所有后继块出发,向外扩展:
取 dispatch blocks 的所有后继块作为候选。
如果候选块是一个不包含任何指令、只有一条跳转指令的空跳块(simple goto),且它能到达 dispatch blocks,则跳过它,并把它的后继加入候选。(这主要是为了剔除编译器或混淆器生成的一些无意义中转块,直达真正的业务入口)。
关键判断 :检查候选块 是否支配了任何一个 dispatch block (即该块的被支配节点集合与 dispatch_blocks 的交集是否为空)。
如果不为空:说明候选块是去往后续 dispatch block 的必经之路(或者它本身就是 dispatch block),它依然在 Dispatcher 的分发网络内部,跳过。
如果为空:说明通过它之后,控制流彻底离开了当前分发节点的控制,这就找到了真正的 Out Block ——Dispatcher 的出口,也就是 Case 的入口。
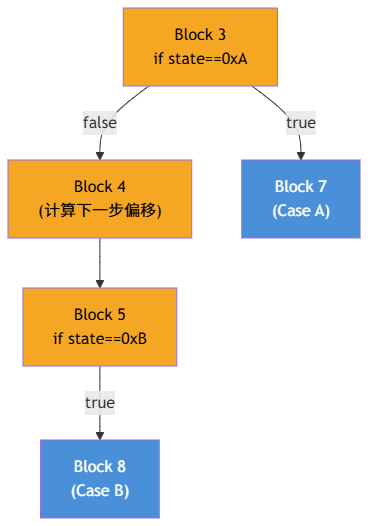
为了直观理解第 3 点,考虑一个多层 if-else 展开的 Dispatcher 内部结构:
在这里,Block 4 和 Block 7 都是 Dispatch Block 3 的后继。那 Block 4 为什么不是 Case 入口(Out Block)呢?因为 Block 4 支配了 Block 5 (到达 Block 5 必须经过 Block 4),而 Block 5 显然是属于分发逻辑的 dispatch block。这说明 Block 4 依然在分发网络的内部骨架上。相反,Block 7 和 Block 8 没有支配任何 dispatch block,所以它们才是真正的 Out Block。
最后,在找出的 Out Block 中,如果一个块无法再到达任何 dispatch block(即不会再跳回 Dispatcher),它就被标记为 Exit Case ,通常对应着函数的 return 或异常退出块。
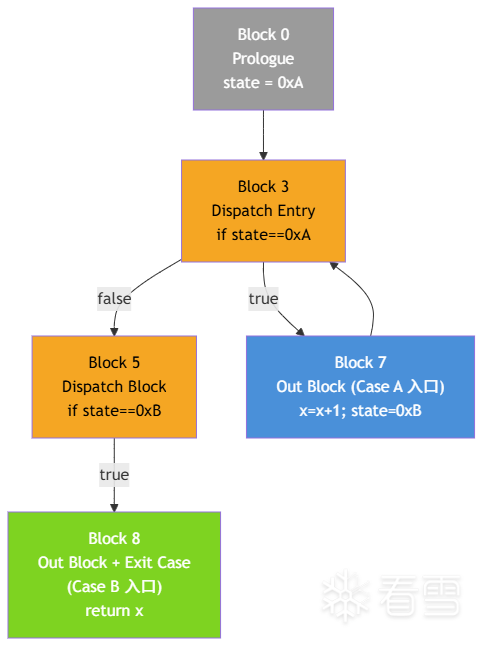
沿用前面的贯穿示例,分析完成后,CFG 中的每个块都被分配到了明确的区域:
| 分类 | 块 | 判定依据 |
|------|-----|----------|
| Prologue | Block 0 | 其支配者集合中没有任何 dispatch block |
| Dispatch Entry | Block 3 | 支配了集合中所有的 dispatch blocks |
| Dispatch Block | Block 5 | 包含 dispatch instruction |
| Out Block | Block 7 | Dispatcher 的后继,且不支配 任何 dispatch block |
| Out Block + Exit Case | Block 8 | 不支配任何 dispatch block,且无法到达 Dispatcher |
到这里,CFG 被清晰地划分成了三个区域:Prologue、Dispatcher、Cases。接下来的任务是弄清楚 Case 之间真正的执行顺序。
这是整个方案中最关键的一步:确定每个 Case 执行完之后,真正应该跳转到哪个 Case。
一个 Case 执行完毕后会把状态变量设置成某个值,然后跳回 Dispatcher。Dispatcher 根据这个值做一系列条件判断,最终跳到下一个 Case。如果我们能"模拟执行"这个过程——从 Case 的出口开始,带着 Case 设置的状态变量值,走一遍 Dispatcher 的条件跳转链,看它最终会落到哪个 Out Block——那我们就知道了这个 Case 的真正后继。
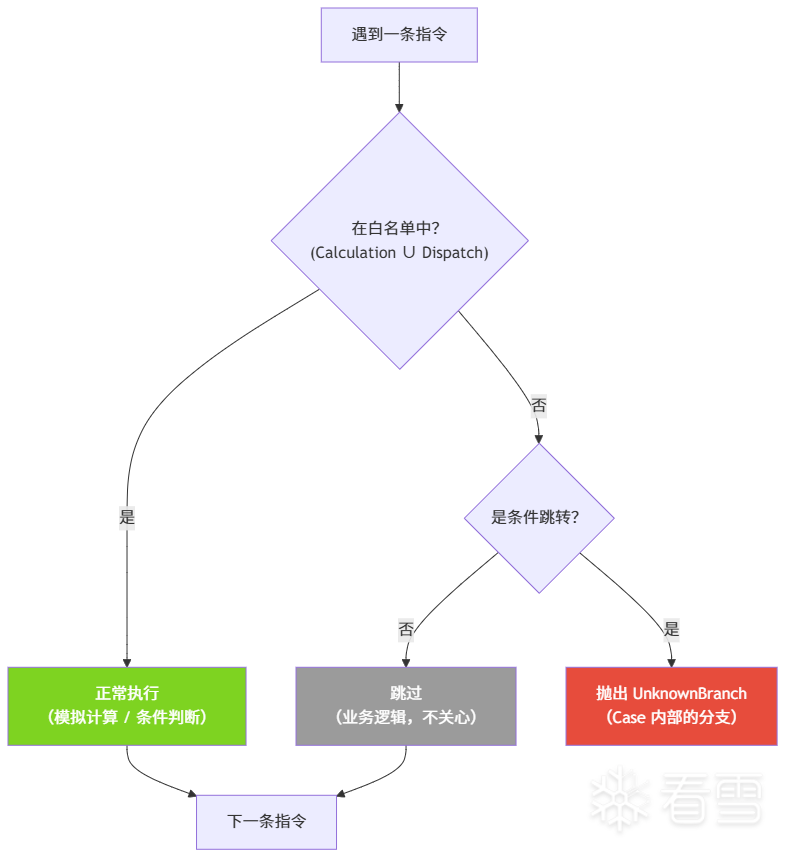
obpo 实现了一个轻量的 Microcode 解释器(MCEmulator)来完成这个模拟。它不是一个通用的完整模拟器——它只关心与 Dispatcher 相关的指令。
具体来说,MCEmulator 维护了两个简单的空间:寄存器空间和内存空间。它的执行策略是:
这个策略让模拟器专注于状态变量的传播和 Dispatcher 的判断逻辑,忽略所有不相关的计算。因为 CFF 混淆的本质就是把状态变量计算和条件分发叠加在原始逻辑上,只要我们能准确地模拟这些叠加的部分,就能还原出真实跳转。
FlowFinder 用模拟器从每个可能的起点出发,寻找它的目标 Out Block,产出 Flow。
首先尝试一种"探索式"的方法:从 Prologue 的入口开始,用一个空的模拟器执行。模拟器走过 Prologue(在这里,Prologue 中对状态变量的初始赋值会被执行),然后进入 Dispatcher,经过一系列条件跳转,最终到达第一个 Out Block——假设是 Case A。
到达 Case A 之后,模拟器继续从 Case A 开始执行。Case A 内部的业务逻辑被跳过,但 Case A 末尾对状态变量的赋值会被执行。然后模拟器跳回 Dispatcher,经过条件判断,到达下一个 Out Block——比如 Case B。
这样一路"探索"下去,每经过一次"Case → Dispatcher → 下一个 Case"的过程,就产生一个 Flow。
在这个过程中,如果遇到 Case 内部的分支逻辑怎么办?
其实无论是探索式寻路还是后续的补全模式,底层的单次寻路都由 EmuPathFinder 执行,它自身就具备处理内部 if-else 的分叉能力。
当模拟器在某个非 Dispatcher 的条件跳转处遇到 UnknownBranch 时(即 Case 内部的 if-else),EmuPathFinder 会在内部就地分叉:对这个条件跳转的每个后继分支,复制一份当前的模拟器状态,分别继续模拟,看看每条路各自通向哪个 Out Block。
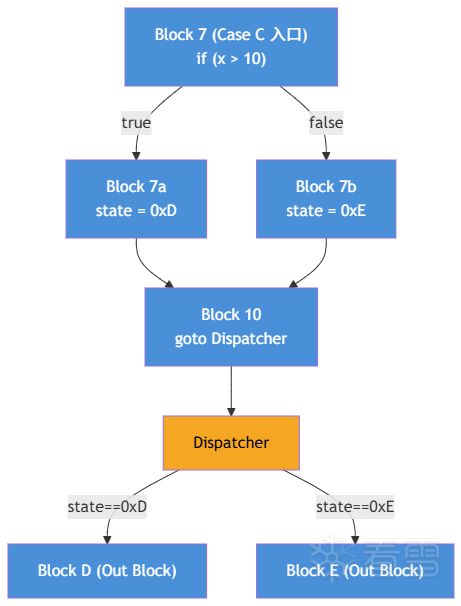
考虑一个包含内部分支的 Case:
模拟器执行到 Block 7 的 if (x > 10) 时,这不是 Dispatcher 的条件跳转(不在白名单中),于是抛出 UnknownBranch。EmuPathFinder 将当前模拟器状态复制两份,分别从 true 和 false 分支继续执行:
分支 1 (true):经过 Block 7a → state = 0xD → Block 10 → Dispatcher → 到达 Block D。产出 Flow: (10 → Dispatcher) → D
分支 2 (false):经过 Block 7b → state = 0xE → Block 10 → Dispatcher → 到达 Block E。产出 Flow: (10 → Dispatcher) → E
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2026-3-16 12:58
被葫芦娃编辑
,原因: