-
-
[原创] AI 时代逆向工程基建:从 GUI 到 API 的思考
-
发表于: 2026-3-14 00:58 2484
-

以算法助手 MCP 为例
一、引言: AI 时代我们需要什么样的逆向基建
毕业接触 Android 安全的第一天, 用 Frida 脚本成功修改函数的返回值,看着 APP 按自己的意志运行,兴奋得半夜 3 点还没睡着觉.
但随着逆向做得越来越多, 事情变味了.
每次拿到一个新的 App, 又要重新找入口、写 Hook、拼参数、看日志 … 心里烦躁居多: "又特么要写遍 Hook?”
于是开始 "封装", 写 Frida 模板、Python 脚本, XPosed 模块.
但很快又发现: 需求总是定制化, 而自己的封装往往过度设计, 最后还是得乖乖回去手写脚本, 然后发现很多工具函数又得手动复制一遍.
中间的复制粘贴得有十几次, 感觉全是重复性工作, 有些枯燥.
用我高中数学老师的话来说, 这不 "美".
那在 AI 时代, 什么是 "美" 的逆向工程?
目前我觉得, 要做的重复性工作越少, 就越美. 越能让我偷懒, 就越美.
随着大模型 (Cursor, Claude, Codex) 的普及, AI 辅助静态代码分析已经成为常态. 前几天看到 frida-mcp, 意识到 AI 现在也可以动态分析了.
我当前工作也总会有点小外挂分析需求, 什么卡密校验绕过, 加密链路分析之类的活, 最常用的 APP 就是军哥的算法助手 Pro, 什么过弹窗, 允许截屏, 增强 Reqable 抓包, 文件读写监控, 常用的密码算法 hook 之类, 还能自己选择 hook 哪些类, 比写 XPosed 脚本方便多了.
但果然没干几次我的 "牛夫人感应" 就又出现了.
每次都得选择 hook 哪个 App, 手动增加要 Hook 的方法, 重启进程, 查看日志, 有时候我还得给 frida 脚本放到 /sdcard/ 并打开文件管理器选择载入, 怎么又特么得点一遍? 弄了半小时, 得到了一堆还是需要我自己分析的日志.
要不让 AI 点?
试一下会发现, 就算是 Opus4.6, 每点击一下它也得想想下一步做什么, 点几个页面他得想 10 次, 看它操作比我自己手点还慢, 再一想这还要花我 Token, 就开始生闷气了.
岂止是不美, 简直是有点丑陋.
事实上, GUI 本身是为人类设计的, 但对 AI 来说, 文本命令天然匹配 LLM 的输入格式, 可自由串联成复杂工作流, API 和 CLI 才是面向 agent 的.
昨天也看到了 CLI-Anything, 是基于开源代码, 将所有的开源软件功能暴露出 CLI 接口, 让 agent 可以更好的使用.
这是针对开源项目的, 闭源还得有逆向的环节.
因此, 这篇是给我自己工作的提效探索开个头: 面向 AI 的逆向 GUI 工具利用.
我想做的, 就是把这些面向人类的 GUI 软件, 通过逆向分析剥离出可以直接被大模型调用的 API. 已经做过的事, 就别再反复手点了.
二、方法论:从 GUI 到 API 的 3 个通用切入点
当你拿到一个只能通过 UI 点击的 APP,想要把它变成脚本或 AI 可以自动控制的接口时,先不要去想“按键精灵”或 UI 自动化测试 (那太人类了)
可以期待作者提供接口, 也可以先尝试自己探索探索, 通常有以下 3 个通用的切入点:
1. 寻找持久化落盘点
UI 的每次点击,最终必然对应着某处数据的修改
思路: 监控 /data/data/pkg/shared_prefs、databases, 以及外部存储 /sdcard/Android/data/pkg/files. 只要找到配置文件 (XML/JSON/DB) , 可尝试用脚本修改文件, 就能绕过 UI.
2. 寻找跨进程通信 (IPC) 接口
如果配置不在常规文件里,或者修改文件后不生效,说明存在内存缓存或跨进程通信。
思路: 反编译工具 APK, 重点排查 AndroidManifest.xml 中的 provider、receiver、service (特别是 exported=true 的组件) . 很多工具的 UI 和后台服务是通过这些 Android 标准机制通信的.
3. 寻找命令行 (CLI)
有些工具为了方便高级用户或自身调试,会暗藏命令行接口。
思路: 检查工具的二进制文件、安装脚本, 或者在反编译代码中搜索 Runtime.getRuntime().exec、su -c 等关键字, 寻找隐藏的 shell 命令.
三、实战解剖:算法助手 MCP
几个阶段性目标:
- 在 LSPosed 勾选算法助手生效的应用
- 在算法助手 UI 里勾选生效的应用
- 针对单个应用的配置读取, 写入, 生效 (包括常见的选项如哈希算法的 hook, 自定义方法的 hook 等)
- 针对单个应用的 frida 脚本写入和应用
- 日志的提取, 结构化和查询
都尽量改造成 CLI, 让 agent 可以直接使用.
1. 持久化落盘点:先确认包级配置, 再追 AppSwitch
实验时,LSPosed 里勾选的是:
系统框架com.reqable.androidcom.example.app
算法助手自己 UI 里勾选的是:com.lerist.fakelocationcom.example.app
开始找, 先看算法助手自己的常见目录:
/data/user/0/com.junge.algorithmAidePro/shared_prefs/data/user/0/com.junge.algorithmAidePro/files/sdcard/Android/data/com.junge.algorithmAidePro/files/config/data/adb/lspd/config
很快可以确认一件事:目标包的 Hook 配置 确实在外置目录里
路径是:/sdcard/Android/data/com.junge.algorithmAidePro/files/config/<targetPackage>.json
但这只是配置, 算法助手 UI 那份 "应用勾选状态 (AppSwitch)" 并没有直接出现在应用私有目录里.shared_prefs下看到的是几个.sp文件, 看起来像配置, 但直接搜包名没有命中.
这里最容易犯的错误, 就是默认认为 "找不到明文包名 = 没有本地持久化" .
实际不然, 既然文件层面找不到, 我们就转向代码层面 (寻找阻力最小路径)
2. IPC 接口:Provider 暴露了关键读校验面
把 base.apk 拉下来后,重点不是全量看代码,而是找配置读写路径。
反编译后很快能抓到几个关键点:
ConfigReader.getInstanceByAlgorithmAidePro(String str)ConfigProviderandroid:authorities="algorithmAidePro"xposedsharedprefs=true
其中最关键的是 ConfigProvider. 它直接暴露了两个查询维度:
projection=configprojection=AppSwitch
# 查询 AppSwitch
adb shell content query --uri content://algorithmAidePro/com.example.app --projection AppSwitch
# 写入 AppSwitch
adb shell content insert --uri content://algorithmAidePro/com.example.app --bind AppSwitch:s:true
先拿 Provider 当读校验面, 再反推真实落点
AppSwitch 的主落点:AppSwitch.json 不是 Provider
到这里出现了一个反常现象:
- Provider 能读到
AppSwitch - 但
/data/user/0/com.junge.algorithmAidePro/shared_prefs/AppSwitch.xml并不存在
说明不是这个文件, 使用 AppSwitch 关键词找到了实际落点
/data/system/junge/AppSwitch.json
直接读取内容会得到一份包名到布尔值的映射,例如:
{
"com.example.app": true,
"com.lerist.fakelocation": true,
}
当前版本和这台设备上,算法助手 UI 的应用勾选状态主仓库已经和 AlgorithmServer 里的常量对上了:
APP_SWITCH = AppSwitch.jsonBASE_DIR = /data/system/junge/
3. CLI 接管 LSPosed 作用域: LSPosed_mod
LSPosed 的作用域是另一份配置, 不在算法助手目录里.
真实位置在:
/data/adb/lspd/config/modules_config.db
/data/adb/lspd/config/modules_config.db-wal
通过主库、WAL 和备份库的字符串命中, 可以确认这个 db 里存的是 LSPosed 的模块生效信息.
但直接改 sqlite3 不太优雅, 所以后面直接转向 LSPosed_mod 提供的 CLI.
先确认环境:
- 设备存在
/data/adb/lspd/bin/cli, CLI 需要 root 权限 - 需要在 LSPosed Manager 里开启
Enable CLI
su -c /data/adb/lspd/bin/cli scope set -a com.junge.algorithmAidePro com.qiyi.video/0
四、继续探索:日志源, Hook DSL 与动态分析闭环
1. 日志源定位:如何一步步收敛到 SQLite
/sdcard/Android/media/<targetPackage>/database/algorithmAidePro.db
第一轮:先从 UI 的 "保存所有日志" 反推
一开始最自然的思路, 是围绕日志页面里的 "保存所有日志" 做自动化.
这条路后来确认过两个事实:
- UI 按钮最终会走到
ThreadSaveLogList -> ConfigReader.createLogFile(null) - 导出的文本文件会落到:
/sdcard/Android/data/com.junge.algorithmAidePro/files/Log/<yyyy-MM-dd_HH_mm_ss>.log
第一轮里, 借用已有的经验, 先沿 "已验证路径" 查找:
- 已经验证过的
content://algorithmAidePro/... - 已经落到外置目录的日志或配置文件
第一,content://algorithmAidePro/...能稳定读到: projection=configprojection=AppSwitch
但没看到任何 "导出日志" 相关 projection, 也没看到稳定可用的insert/update/call写入口.
第二, Frida 日志这条链路是独立成立的.
/sdcard/Android/data/com.junge.algorithmAidePro/files/files/fridaLog.html
这个能直接拉, 但它只对应 Frida 脚本日志, 不是原生 hook 日志.
而且 fridaLog.html 的确存在, 但它偏向 UI/导出面, 不一定是最底层运行时写入面. 后面继续实机推进时, com.example.app 又看到了一个更直接的文件:
/sdcard/Android/media/com.example.app/database/frida.log
这个文件会直接记录 Frida 运行时日志, 做 smoke test 比 fridaLog.html 更直接.
第二轮:开始怀疑 UI 文本导出不是最优目标
到这里警觉了, "保存所有日志" 本身就是一个面向人看的导出动作. 它本质上是:
- 从内部真实数据源读数据
- 再拼成文本
- 最后才写到
files/Log/*.log
继续研究 "怎么替代按钮点击" , 应该是走远了, 且绕不过那个触发 UI 动作.
更该问的是: "日志页面展示的数据, 最原始的存储到底在哪?"
思路从 "模拟 UI 导出" 变成了 "直接找日志源" .
第三轮:从私有目录和系统侧配置继续反查
接下来先排了几处看起来最像“会放日志”的地方:
/data/user/0/com.junge.algorithmAidePro/files/data/user/0/com.junge.algorithmAidePro/databases/data/system/junge/
/data/system/junge/ 里面确实东西很多,而且看起来很像“算法助手系统侧仓库”:
AppSwitch.jsonlogList.jsoncom.example.app/config.jsoncom.example.app/script_data.json
但再往里看就会发现,这里主要是:
- 开关状态
- hook 配置
- script 配置
不是日志明细本身.
以 com.example.app/config.json 为例,里面已经能直接看到:
hookListprintLogenableScript
但这里后来踩了一个很典型的坑。
一开始很容易顺着笔记继续默认:
files/config/<pkg>.json是当前生效配置enableScript在这份 JSON 里- 那改外部脚本文件内容再重启,应该就会生效
第一句是对的,后两句不完整。
后面实机和反编译一起对账后,边界变成了:
files/config/<pkg>.json决定当前“选中了哪个脚本名”- 实际执行的脚本内容,落在
/data/system/junge/<pkg>/frida/<script>.js - 脚本列表元数据,落在
/data/system/junge/<pkg>/script_data.json
以 com.example.app 为例,当前能直接对上的就是:
/data/system/junge/com.example.app/config.json/data/system/junge/com.example.app/script_data.json/data/system/junge/com.example.app/frida/bezierzhixian.jsenableScript管的是脚本选择, 不是脚本内容本身.
这时候已经能排掉几类常见误判了:
/data/system/junge/更偏向配置仓库, 不是日志明细仓库files/Log/*.log更偏向导出结果, 不是长期主存储- 真日志源更可能是目标包维度的独立库
按这个思路继续往下找, Android/media/<pkg>/database 这条线就变得很顺了. 想想也是, 对这类“一套宿主管多个目标”的形态, 配置统一放宿主侧, 日志按目标包落地, 本来就很合理.
第四轮:开始按数据库名全局反查
既然 UI 页面背后大概率是结构化数据,就应该反过来找数据库,而不是继续盯着文本文件。
转折点不在代码, 而在设备全局搜索:
/data/media/0/Android/media/com.example.app/database/algorithmAidePro.db
这个路径一出现,很多事情就串起来了:
- 路径按目标包分目录,符合“每个目标 App 单独存日志”的直觉
- 名字直接叫
algorithmAidePro.db,和产品本身高度相关 - 它不在 UI 导出目录,而在目标 App 的外置媒体目录
这时候就不应该再猜了,直接拉下来开 SQLite。
第五轮:验证这个库是不是日志源
把库拉下来后,看 sqlite_master,结果非常干净:
table|LOG_DATA_V2|LOG_DATA_V2
table|android_metadata|android_metadata
table|sqlite_sequence|sqlite_sequence
表结构也直接指向日志用途:
CREATE TABLE IF NOT EXISTS "LOG_DATA_V2" (
"_id" INTEGER PRIMARY KEY AUTOINCREMENT,
"GROUP" INTEGER NOT NULL,
"TYPE" INTEGER NOT NULL,
"OBJ_NAME" TEXT,
"CLASS_NAME" TEXT,
"LOG_NAME" TEXT,
"TIME" INTEGER NOT NULL,
"IS_READ" INTEGER NOT NULL,
"LOG_DETAILS_RAW" BLOB,
"CALL_STACK" TEXT
);
到这里基本已经坐实了:
- 这不是 UI 导出文件
- 这是日志页面背后的原始结构化仓库
再继续查最近几条:
com.example.app.MainActivity | unregisterPluginTestReceiver()com.example.app.MainActivity | onDestroy()com.example.app.MainActivity | lambda$setupTestButtons$3$com-example-app-MainActivity()
而且当前设备上行数是实打实的:
124
做到这里, 结论就很清楚了.
最初设想是:
- 想办法不用 UI 点击“保存所有日志”
- 让 app 生成一个
.log - 再
adb pull
而现在找到的路径是: - 直接
adb pull /sdcard/Android/media/<pkg>/database/algorithmAidePro.db - 用
sqlite3/ GUI 工具直接查询
后者明显更适合后续 MCP 化:
结构化
可筛选
可排序
可增量导出
可直接转 TSV / CSV / JSON
UI 文本导出链路已经逆出来了,但它不是最优自动化目标
content://algorithmAidePro/...仍然是可靠读校验面,不是日志导出面Frida 日志仍然独立落在
fridaLog.html原生 hook 日志已经找到更好的非 UI 主路径:
Android/media/<pkg>/database/algorithmAidePro.db
这轮跑通的小闭环不是“自动触发 UI 保存日志”, 而是“直接通过 CLI 导出结构化 hook 日志数据库并用 SQL 查询”.
示例:
adb pull /sdcard/Android/media/com.example.app/database/algorithmAidePro.db .
sqlite3 algorithmAidePro.db 'select count(*) from LOG_DATA_V2;'
sqlite3 -header -column algorithmAidePro.db "
select
_id,
\"GROUP\",
TYPE,
ifnull(OBJ_NAME,'') as obj_name,
ifnull(CLASS_NAME,'') as class_name,
ifnull(LOG_NAME,'') as log_name,
TIME,
length(LOG_DETAILS_RAW) as raw_len
from LOG_DATA_V2
order by TIME desc
limit 10;
"
方法提示 1:Provider 是极强的验证面
只要目标自己暴露了 Provider,就不要只做静态分析
因为 Provider 能直接回答:
- 这个键有没有
- 当前值是什么
- 业务代码到底读的是哪一份配置
这比靠猜文件格式效率高得多。
方法提示 2:Xposed 模块要特别警惕 /data/misc/.../prefs
很多人会一直盯着:
/data/user/0/<pkg>/shared_prefs
但带xposedsharedprefs的模块,配置可能根本不落在应用私有目录,而是 Xposed 可共享读取的位置
2. MCP 化拆解:先把三层状态分开
如果后面要把算法助手做成一个通用 Java Hook MCP,动作至少要拆成三层:
- 写目标包 Hook 配置
- 落点:
/sdcard/Android/data/com.junge.algorithmAidePro/files/config/<targetPackage>.json
- 落点:
- 打开算法助手 UI 勾选
- 当前主持久化落点:
/data/system/junge/AppSwitch.json - 校验要拆成两层:
- 存储层回读
AppSwitch.json - 运行期层回读
logList.json - Provider 层回读
projection=AppSwitch(仅作参考)
- 存储层回读
- 当前主持久化落点:
- 同步 LSPosed 作用域
- 优先接口:
/data/adb/lspd/bin/cli - 落盘位置:
/data/adb/lspd/config/modules_config.db
- 优先接口:
这三层不拆开,后面做 CLI 和 MCP 很容易把状态混在一起。
这次主要拆开的就是:
- 算法助手自身配置
- 算法助手 UI 的应用启用状态
- LSPosed 作用域配置
3. 实机验证:包级 JSON
当所有默认开关都打开时,实机里这份包级 JSON 大致会长这样:
{
"ApplicationSwitch": true,
"ExceptionSwitch": true,
"SharedPreferencesPutSwitch": true,
"activitySwitch": true,
"assetsSwitch": true,
"cameraHookSwitch": true,
"checkRootSwitch": true,
"cipherSwitch": true,
"closeDialogSwitch": true,
"dialogKeyword": "注册码,机器码,激活码",
"dialogSwitch": true,
"digestSwitch": true,
"exitSwitch": true,
"fileDeleteSwitch": true,
"fileSwitch": true,
"fileWriteSwitch": true,
"getSharedPreferencesSwitch": true,
"hiddenVpnSwitch": true,
"hiddenWifiProxySwitch": true,
"hiddenXposedSwitch": true,
"justTrustMePlushSwitch": true,
"logSwitch": true,
"macSwitch": true,
"onClickSwitch": true,
"reqableSwitch": true,
"reqableSwitch_native": true,
"screenSwitch": true,
"shellSwitch": true,
"signSwitch": true,
"sqliteDeleteSwitch": true,
"sqliteExecSQLSwitch": true,
"sqliteInsertSwitch": true,
"sqliteOpenSwitch": true,
"sqliteQuerySwitch": true,
"sqliteUpdateSwitch": true,
"textViewSwitch": true,
"webCryptSwitch": true,
"webViewDebugSwitch": true,
"webViewLoadUrlSwitch": true
}
验证 1:projection=config 不是 config.xml 说了算
一开始很容易觉得:
AppSwitch.json管 UI 勾选config.xml管功能配置files/config/<pkg>.json只是导出副本
但实机验证下来,至少对projection=config不是这样。
做了两组对照实验:
pkg.json.digestSwitch=true,config.xml.digestSwitch=falseadb shell content query --uri content://algorithmAidePro/com.example.app --projection config- 返回
digestSwitch=true
pkg.json.digestSwitch=false,config.xml.digestSwitch=false- 同样查询
- 返回
digestSwitch=false
这已经足够说明:
/sdcard/Android/data/com.junge.algorithmAidePro/files/config/<pkg>.json
才是 projection=config 的主控制源,优先级高于:
/data/misc/<uuid>/prefs/com.junge.algorithmAidePro/config.xml
所以按字段改目标包配置时,直接改包级 JSON 就行,不用碰 config.xml。
验证 2:Root 也不等于无条件可写
这台机器上 su 的上下文是:
uid=0(root) gid=0(root) context=u:r:magisk:s0
SELinux 仍然是 Enforcing。而且:
setenforce 0会直接失败- shell 重定向覆盖
config.xml会报Permission denied
这说明“有 root”不代表“随便哪条写法都能写成功”。尤其是带/data/misc/.../prefs的路径,要考虑magisk su的上下文限制,不能靠想当然。
验证 3:纯文件覆盖的推荐 CLI 顺序
如果目标是“不要点 UI,只靠命令行改成功”,当前最稳定的闭环已经收敛成下面这 4 步:
force-stop算法助手- 覆盖包级 JSON
- 启动算法助手
- 用 Provider 回读校验
命令顺序如下:
adb shell am force-stop com.junge.algorithmAidePro
adb push com.example.app.json /data/local/tmp/com.example.app.json
adb shell su -c 'cp /data/local/tmp/com.example.app.json /sdcard/Android/data/com.junge.algorithmAidePro/files/config/com.example.app.json'
adb shell monkey -p com.junge.algorithmAidePro -c android.intent.category.LAUNCHER 1
adb shell content query --uri content://algorithmAidePro/com.example.app --projection config
4. 自定义 Hook 导出:已经能看清原生 DSL 的轮廓
这次顺手把“算法助手里手工快速添加的自定义 hook 方法”也导出看了一眼。
以 com.example.app 为例,设备上能看到两份同内容文件:
/sdcard/Android/data/com.junge.algorithmAidePro/files/config/com.example.app.json/sdcard/Android/data/com.junge.algorithmAidePro/files/exportConfig/com.example.app.json
config/<pkg>.json是当前生效配置exportConfig/<pkg>.json是导出快照- 导出文件本身就是算法助手当前认可的原生配置语法,不需要先自己猜 schema
com.example.app 当前导出的核心内容大致如下:
{
"enableScript": "bezierzhixian.js",
"hookList": [
{
"argsValues": [],
"className": "com.example.app.DemoTarget",
"constructor": true,
"description": "来自快速添加的Hook",
"enable": true,
"intercept": false,
"methodName": "<init>",
"parameterSign": "",
"printLog": true,
"results": ""
},
{
"argsValues": [],
"className": "com.example.app.DemoTarget",
"constructor": false,
"description": "来自快速添加的Hook",
"enable": true,
"intercept": false,
"methodName": "a",
"parameterSign": "Landroid/content/Context;",
"printLog": true,
"results": ""
}
]
}
结构 1:自定义 Hook 不只是一个方法名列表
每条 hookList 至少包含:
classNamemethodNameconstructorparameterSignenableprintLoginterceptresultsargsValues
结构 2:参数签名不是 Java 写法, 而是描述符写法
例如:
Landroid/content/Context;Ljava/lang/String;Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/reflect/Method;[Ljava/lang/Object;
这类写法更接近 JNI / Smali 描述符,不是 Java 源码签名。
结构 3:构造函数是单独编码的
这次导出里,构造函数同时具备两个特征:
constructor=truemethodName="<init>"
后面如果要抽 DSL,constructor 和 <init> 最好别让调用方重复写。
结构 4:enableScript 说明脚本和 hookList 可以并存
这份 JSON 不只是 hookList,还包含:
"enableScript": "bezierzhixian.js"
并且这次设备上也确实找到了对应脚本文件。
也就是说,结构化 Hook 和额外脚本本来就能并存。
5. Frida 自动化:上层应抽象成统一 Hook DSL
后面不应该只盯着“把算法助手 JSON 原样搬来搬去”,而应该往更高一层抽象:
- 上层统一描述“我要观察哪个类/哪个方法/是否拦截/是否替换参数/是否挂额外脚本”
- 中间层根据目标后端,分别编译成:
- 算法助手
hookList - 算法助手
enableScript - Frida 脚本
- 算法助手
- 底层再负责把产物落到:
files/config/<pkg>.jsonfiles/exportConfig/<pkg>.json- 或 Frida 对应的运行入口
- 算法助手原生 hook
- 附加脚本
- Frida 脚本
这三种东西后面完全可以统一进一个更高阶的 Hook DSL.
6. Frida 实机验证:这轮踩过的 5 个坑
坑 1:不要把 enableScript 误当成脚本内容落点
实测里先改了:
/sdcard/Android/data/com.junge.algorithmAidePro/files/config/com.example.app.json/sdcard/bezierzhixian.js
然后重启算法助手去验证。
这个动作本身不算错, 但它只能证明 "脚本名选择生效" , 不能证明 "运行时读到的是这份外部脚本内容".
原因是:
- 内部执行副本还在
/data/system/junge/com.example.app/frida/bezierzhixian.js - 它的修改时间还停在更早的日期
- 所以外部脚本内容变了,内部缓存没变,运行结果自然不会跟着变
坑 2:不要默认 su -c 一定已经切到 root
这台设备上一个很隐蔽的问题是:
adb shell su -c '...'
有时候实际上仍在 shell 身份跑。
直到显式改成:
adb shell 'su 0 sh -c "...'"
才拿到 uid=0(root),并成功覆盖 /data/system/junge/com.example.app/frida/bezierzhixian.js。
否则很容易误以为“目录有缓存”或者“文件不可写”,实际只是 root 没真的切成功。
坑 3:先验证“脚本确实被执行”, 再纠结 Hook 点
后面直接改了真实执行脚本之后,com.example.app 对应目录下的:
/sdcard/Android/media/com.example.app/database/frida.log
已经能看到我们主动写入的:
[smoke-probe] script loaded pid=...
- 实际执行脚本路径已经找对
- 修改真实脚本再重启的链路已经成立
这之后如果 onCreate、onResume、showMessage 这类 hook 没看到,不应再回头怀疑“脚本没生效”,而应该优先怀疑:
- 注入时机晚于目标方法
- 方法签名/重载不对
- 选择的验证点不够硬
后面要解决的就不是“脚本存哪”, 而是“选什么 hook 点才一定会触发”。
坑 4:这轮最终成立的最短路径
对现有算法助手而言,当前更可靠的 Frida 改脚本闭环是:
force-stop com.junge.algorithmAidePro- 直接改
/data/system/junge/<pkg>/frida/<script>.js - 启动算法助手
- 等待几秒,给它完成注入准备时间
- 启动目标 App
- 先看
/sdcard/Android/media/<pkg>/database/frida.log - 确认脚本已执行后,再迭代 hook 点
这条链已经够短, 也适合后面继续做 CLI/MCP.
坑 5:onResume 不是不能用, 前提是 Hook 点要选得更硬, 时序也要对
前面一度会怀疑:
MainActivity.onResume()这类点到底会不会触发
单独盯某个 Activity 自己声明的方法,确实可能踩到两个问题:
- 方法本身不是目标类直接声明
- 算法助手注入完成时,目标方法已经跑过去了
这轮后面换了个更稳的 smoke hook:
- 直接 hook
android.app.Activity.onResume() - 再按类名前缀筛掉,只打印
com.example.app*
然后按下面时序跑:
- 先启动算法助手
- 等几秒
- 再启动
com.example.app
最后 frida.log 里就稳定拿到了:
com.example.app.DemoCamera2Activitycom.example.app.MainActivity
的 onResume 日志。
现在在 algorithmaide-mcp 里,Frida 这条链已经额外做了一层受控适配:脚本写入时统一预置 __aaLog / __aaLogHit 结构化 logger,并强制要求脚本按契约打点。读取侧则按真机实际格式解包 frida.log 外层 {"type":"log","payload":"..."} envelope,再回收到统一查询视图里。
- smoke hook 应优先选系统层、一定存在、且偏晚触发的方法
- 算法助手先启动并等待几秒,这个时序在实机上确实会影响是否能稳定 hook 上
7. 目标再往前推一步:它已经在逼近 Java 层动态分析逆向
上面这套东西如果再往前推一步, 已经是在做一个可重复迭代的动态分析闭环:
- 先从人工经验或静态分析里拿到候选类、候选方法、疑似参数点
- 自动生成算法助手原生 hook、附加脚本或 Frida 脚本
- 跑一轮目标流程
- 把运行日志抽出来
- 统一格式化成结构化事件
- 再根据日志决定下一轮该 hook 什么、该拦截什么、该追加什么脚本
- 更新配置继续重跑
这里核心在于“日志格式统一”。
因为不管接的是:
- 算法助手原生日志
enableScript对应的附加脚本日志- 外部 Frida 项目的行内日志
最后都不能停留在“原始文本打印”这一层。
更合适的是把它们都收敛成统一事件结构,例如:
- 时间
- 来源后端
- 目标类
- 目标方法
- 参数
- 返回值
- 调用栈
- 标签
- 原始文本
8. 为什么它天然应该和 jadx-ai-mcp 协同
如果只靠动态侧自己盲打,效率会很差。
所以它和 jadx-ai-mcp 很适合协同:
jadx-ai-mcp提供静态分析结果- 例如关键类
- 关键方法
- 可疑调用链
- 值得观察的参数传播点
- 动态 Hook MCP 根据这些静态线索生成一轮最小 hook/script 配置
- 运行后把日志结构化
- 再把结构化结果回给上层分析,继续收敛候选点
jadx-ai-mcp偏静态分析前端- 这个项目偏动态执行后端
五、工程化落地:构建 algorithmaide-mcp
有了这些底层 API, 接下来就是把它们封装成大模型能直接调用的 MCP Tool.algorithmaide-mcp 的架构被有意设计为分层结构
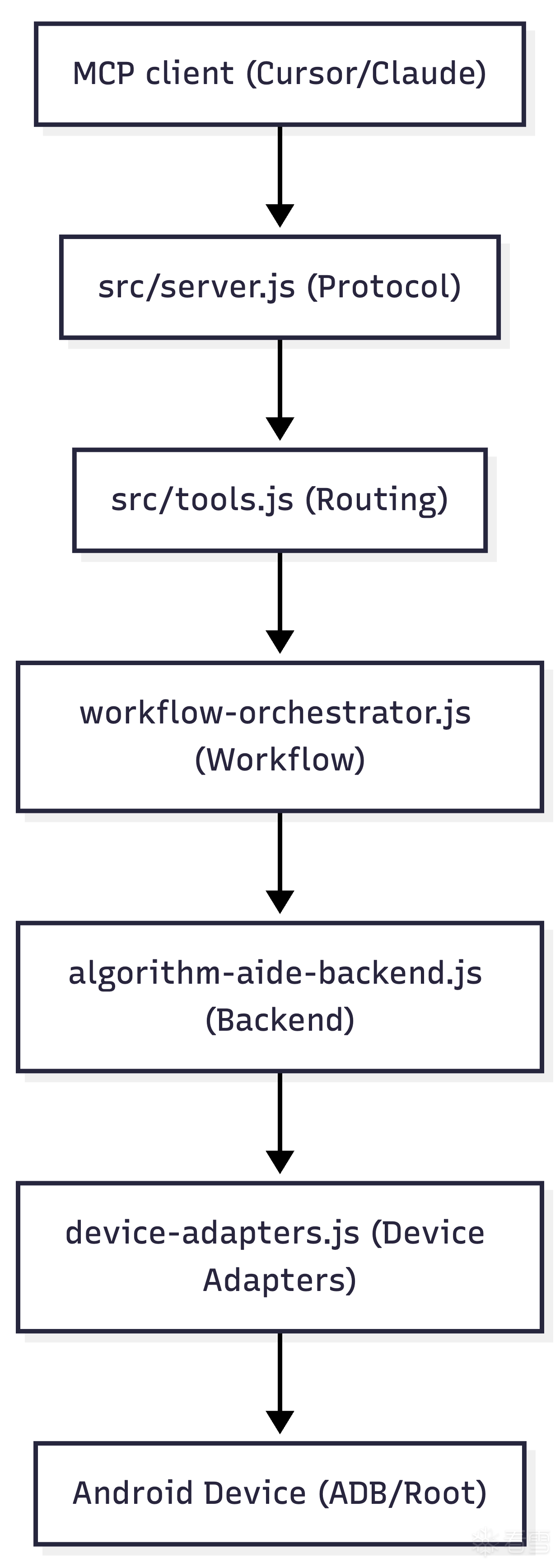
我们把这些底层动作, 例如包级 JSON 写入, AppSwitch 同步校验, LSPosed scope CLI 接管, 封装成了类似 apply_algorithm_aide_config 这样的高级工具.
现在, 你只需要对 Cursor 说一句: "帮我用算法助手 Hook com.example.app, 开启网络抓包和加解密打印", AI 就会自动调用 MCP, 在真机上完成所有的配置、强杀应用、重启并抓取日志.
当然, 写 SKILL.md 时候加上 "不确定的时候, 先用 jadx-ai-mcp 自己分析下" 会更好.
项目开源地址:
algorithmaide-mcp
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|




