[原创] 从零开始手写 x86 反汇编引擎:硬编码解析与架构设计全纪录 源码地址:ccaK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6Z5j5h3&6V1M7$3S2A6L8X3g2Q4x3V1k6o6L8%4u0W2i4K6u0V1P5o6R3$3i4K6u0V1c8r3W2K6j5i4y4K6k6h3#2T1L8r3g2J5
前言 学习逆向工程一段时间后,我们往往会遇到一个瓶颈:虽然会熟练使用 OD、x64dbg、IDA 等各种强大的反汇编与调试软件,但对底层的**指令硬编码(Opcode)**往往只停留在“认得几个常见前缀和指令”的表面层次。
为了真正打通任督二脉,夯实逆向基本功,最好的方式莫过于亲自翻阅 Intel 白皮书(Intel® 64 and IA-32 Architectures Software Developer Manuals),从零手写一个 x86 反汇编引擎 。
本项目正是在这样的初衷下诞生的。为了方便学习且符合人类直觉,本引擎大量完全按照 Intel 白皮书的表格结构来查表并填充数据 。在这篇分享中,我将毫无保留地分享我用 C 语言实现这款轻量级 x86 反汇编引擎(Disassembler)的架构设计、核心逻辑、FPU 浮点解析,以及踩过的各种硬编码解析的坑。希望对正在学习硬编码或者想要自己动手写轮子的朋友有所启发!
一、 引擎核心特点预览 在动手写代码之前,我们需要明确目标。本项目的反汇编引擎做到了以下几点:
纯 C 语言编写 :不依赖任何第三方复杂库,代码极度精简、纯粹,方便跨平台移植或直接嵌入 PE 工具、内核驱动中。严格贴合 Intel 白皮书的表驱动架构(Table-Driven) :通过精心设计的一维和多维数组表来处理庞杂的 x86 指令集,彻底摆脱杂乱的 if-else。完整的指令生命周期解析 :支持 Prefix -> Opcode -> ModR/M -> SIB -> Displacement -> Immediate 的标准 x86 解析流程。精细的 FPU 与 Group 指令支持 :针对 0xD8~0xDF 的浮点指令族,以及 0x80、0x83 等“组指令”进行了细致的分发处理。支持指令格式化 :将内存字节流完美还原并格式化为标准 Intel 汇编语法。
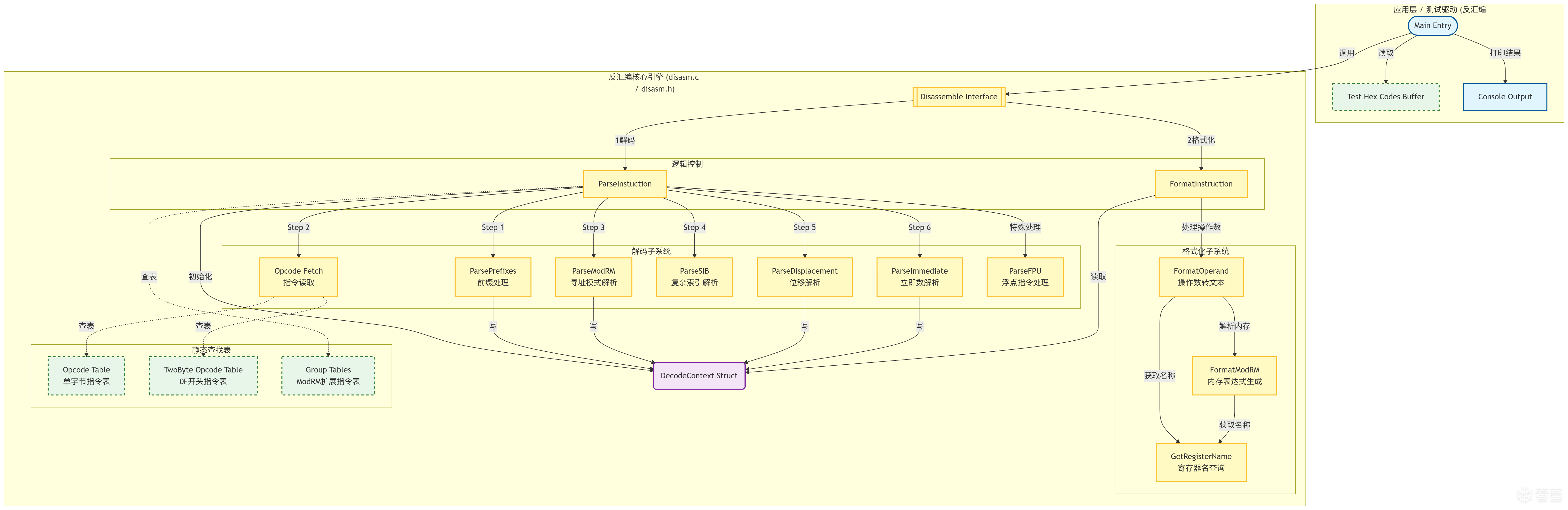
二、 整体架构与数据结构设计
1. 操作数类型抽象 (OperandType) 在 x86 中,一个操作数可能是寄存器、立即数、内存寻址、端口、FPU 堆栈等等。我们在 disasm.h 中定义了一个庞大的枚举 OperandType,正是对应了 Intel 手册中对操作数的代号描述:
1
2
3
4
5
6
7
8
9
10
11
typedef enum {
NONE = 0,
Gb, Gw, Gv, Gz,
Eb, Ew, Ev,
Ib, Iw, Iz, Iv,
Jb, Jz,
M, Mv,
OP_AL, OP_rAX,
M_F32, M_F64,
} OperandType;
2. 指令表设计:引擎的心脏 (OpcodeEntry) 想要摆脱无限的 switch-case,我们采用硬编码查表法。定义了 256 大小的结构体数组(针对单字节指令)。每读取一个字节的 Opcode,不仅能拿到它的助记符,还能准确拿到它所需的后续结构和操作数类型:
1
2
3
4
5
6
7
typedef struct {
const char* mnemonic;
bool is_prefix;
bool has_modrm;
OperandType op1, op2, op3;
GroupEntry* group_table;
} OpcodeEntry;
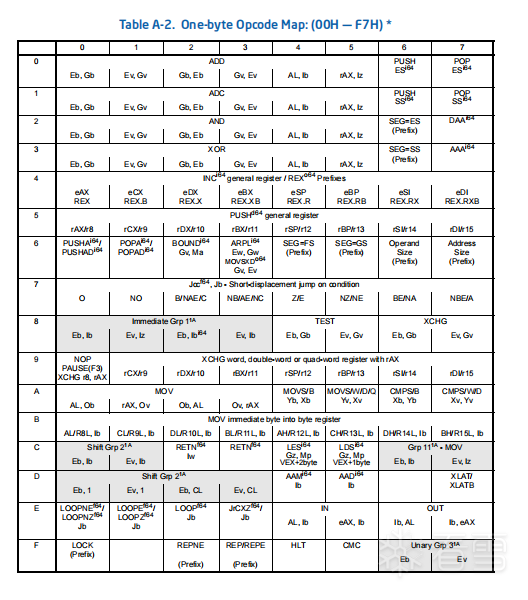
三、 教你如何查阅 Intel 白皮书填表 为了让解析符合直觉,我们的 opcode_table 数据结构是彻头彻尾地照着 Intel 手册附录 A 的 One-byte Opcode Map (Table A-2) 来填写的!
打开 Opcode Map 表,这是一个按照高低半字节划分的二维网格(行代表高 4 位,列代表低 4 位)。以表中第一行(行为 0)为例,你可以清晰看到 ADD 指令的分布:
第 0 列(Opcode 0x00):表格内写着 ADD,下方填写的参数是 Eb, Gb。
第 1 列(Opcode 0x01):表格内写着 ADD,下方填写的参数是 Ev, Gv。
第 4 列(Opcode 0x04):表格内写着 ADD,下方填写的参数是 AL, Ib。Eb, Gv, Ib 等),正是我们在前一节 OperandType 枚举中原汁原味定义好的符号!
在我们的引擎中,相当于直接将这张表“翻译”并抄下来,转化为 C 代码:
1
2
3
4
5
6
7
8
9
10
11
const OpcodeEntry opcode_table[256] = {
[0x00] = {"ADD", 0, HAS_MODRM, Eb, Gb, NONE, NULL},
[0x01] = {"ADD", 0, HAS_MODRM, Ev, Gv, NONE, NULL},
[0x04] = {"ADD", 0, 0, OP_AL, Ib, NONE, NULL},
};
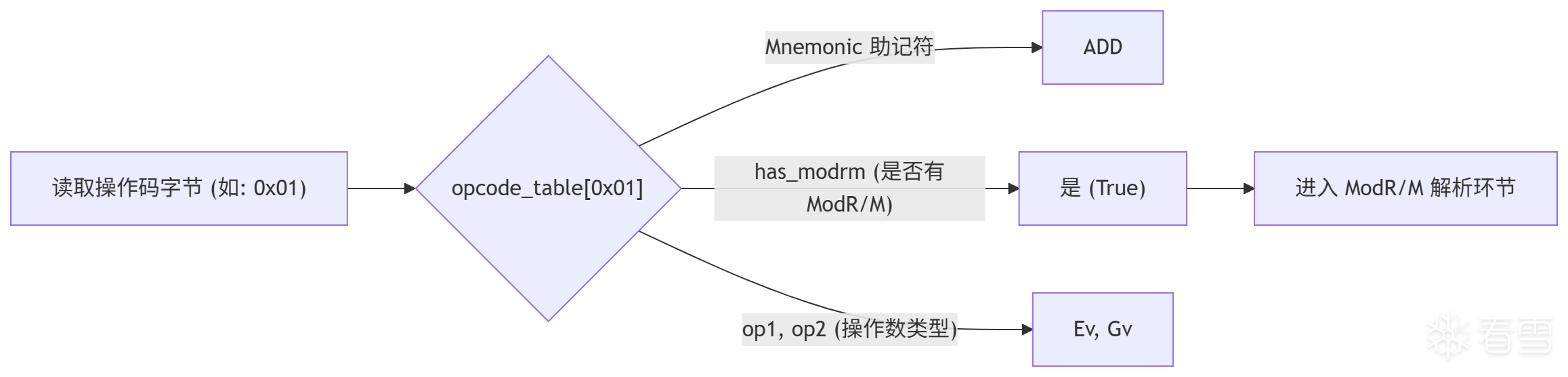
你看,这样的表格映射是否极其符合直觉?查表的过程如下图所示:
graph LR
A["读取操作码字节 (如: 0x01)"] --> B{"opcode_table[0x01]"}
B -->|"Mnemonic 助记符"| C["ADD"]
B -->|"has_modrm (是否有ModR/M)"| D["是 (True)"]
B -->|"op1, op2 (操作数类型)"| E["Ev, Gv"]
D --> F["进入 ModR/M 解析环节"]
E --> G["根据寻址模式确定具体操作数"]
四、 x86 深度解析流水线 (The Pipeline)与核心函数 有了数据结构,解码函数其实就是一条流水线:
graph TD
A["原始字节流"] --> B("1. 解析前缀 (ParsePrefixes)")
B --> C("2. 读取操作码 (Opcode)")
C --> D{"是否为双字节拓展 (0x0F)?"}
D -- "是" --> E("查找双字节指令表")
D -- "否" --> F("查找单字节指令表")
E --> G{"是否包含 ModR/M?"}
F --> G
G -- "是" --> H("3. 解析 ModR/M 字节")
H --> I{"是否包含 SIB?"}
I -- "是" --> J("4. 解析 SIB (ParseSIB)")
I -- "否" --> K("5. 解析偏移 (ParseDisplacement)")
J --> K
G -- "否" --> L("5. 解析偏移 (ParseDisplacement)")
K --> L
L --> M("6. 解析立即数 (ParseImmediate)")
M --> N["格式化输出汇编字符串 (FormatInstruction)"]
核心 API 函数一览 为了保持架构的纯粹性,所有的逻辑被拆分为了几个职责分明的核心函数:
int Disassemble(uint8_t* buffer, uint32_t eip, DecodeContext* out_ctx):顶层暴露给外界的接口,传入机器码字节流和当前 EIP,传出完全解析并格式化好的结构体,并返回该条指令占用的总字节数。int ParseInstuction(...):核心的解码流水线引擎(也就是实现上面流程图的主轴)。负责按照顺序依次调用 ParsePrefixes、查找 Opcode、分发处理 SIB 及 Immediate 等逻辑。void ParseModRM/ParseSIB/ParseDisplacement/ParseImmediate:四剑客,在解码流水线中针对性地剥离数据填充到上下文中。void FormatInstruction/FormatOperand:专门做“苦力活”的打印函数,将解析出来的硬核二进制状态如(Mod=0, Reg=2, disp=0x10 等),优雅地转化为类似 DWORD PTR FS:[EAX+ECX*4-0x10] 的性感字符串。
重点坑位:ModR/M 与 SIB 寻址迷宫 ModR/M 规定了操作符的寻址方式:
Mod (2 bit):决定寻址模式(寄存器、无偏移内存、8位偏移、32位偏移)。Reg (3 bit):通常代表一个寄存器(比如加法里的目标寄存器),但在 Group 指令中,它代表Opcode 的扩展 !R/M (3 bit):决定基址寄存器。如果 R/M = 4 且 Mod != 3,说明后面还紧跟着一个 SIB 字节 !
解析代码极具位运算的美感:
1
2
3
4
5
6
7
8
9
10
11
12
void ParseModRM(DecodeContext* ctx) {
uint8_t b = ctx->buffer[ctx->pos++];
ctx->modrm = b;
ctx->mod = (b >> 6) & 0x03;
ctx->reg = (b >> 3) & 0x07;
ctx->rm = b & 0x07;
if (ctx->mod != 3 && ctx->rm == 4) {
ctx->has_sib = true;
}
}
紧接着解析 SIB(Scale, Index, Base) 。这里有深坑:如果 Index == 4,实际上代表没有 Index(因为 ESP 不能做变址);如果 Base == 5 且 Mod == 0,代表没有寄存器基址,只有一个单纯的 32位 Displacement!
Group 扩展指令组 遇到 0x80、0x81 这一类指令时,单纯查 opcode_table 你只能得到它是算术底层组,根本不知道它是 ADD 还是 SUB。秘密藏在刚才提到的 ModR/M 的 Reg 字段 里!group_tables 二维数组,如果 opcode_table[0x80] 指向了 group_tables[0],我们立刻取出刚解析的 ctx->reg 进行二次查表。这种二级表映射极其优雅地解决了 x86 操作码拥挤度过高的问题。
五、 硬核揭秘:FPU 浮点数指令解析 很多人手写计算器或反汇编器时,都会在 FPU 指令前止步。x87 浮点指令集中分布在 0xD8 ~ 0xDF 这个区间。
FPU 的恶心之处在于,同一个 Opcode(例如 0xD8),如果你后面跟的 ModR/M 字节的 Mod 字段是不是 3,它的含义完全不同!
如果 Mod != 3,说明是内存寻址,操作数通常是一个 32位/64位 内存浮点数。
如果 Mod == 3,说明是 FPU 寄存器寻址,它变成了对寄存器堆栈 ST(0), ST(i) 的操作。
在我们的引擎中,我专门编写了 ParseFPU 分发器来进行精准狙击:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
void ParseFPU(DecodeContext* ctx) {
uint8_t op = ctx->opcode;
uint8_t mod = ctx->mod;
uint8_t reg = ctx->reg;
uint8_t rm = ctx->rm;
switch (op) {
case 0xD8:
if (mod != 3) {
ctx->entry.op1 = M_F32;
switch (reg) {
case 0: ctx->entry.mnemonic = "FADD"; break;
case 1: ctx->entry.mnemonic = "FMUL"; break;
}
} else {
ctx->entry.op1 = OP_ST0;
ctx->entry.op2 = OP_STi;
switch (reg) {
case 0: ctx->entry.mnemonic = "FADD"; break;
case 1: ctx->entry.mnemonic = "FMUL"; break;
}
}
break;
}
}
通过分离 mod == 3 与否的状态空间,并在结构体内植入 M_F32/M_F64 以及 OP_STi 的动态代号标识,FPU 最复杂的寄存器堆栈与内存寻址就被瞬间磨平。
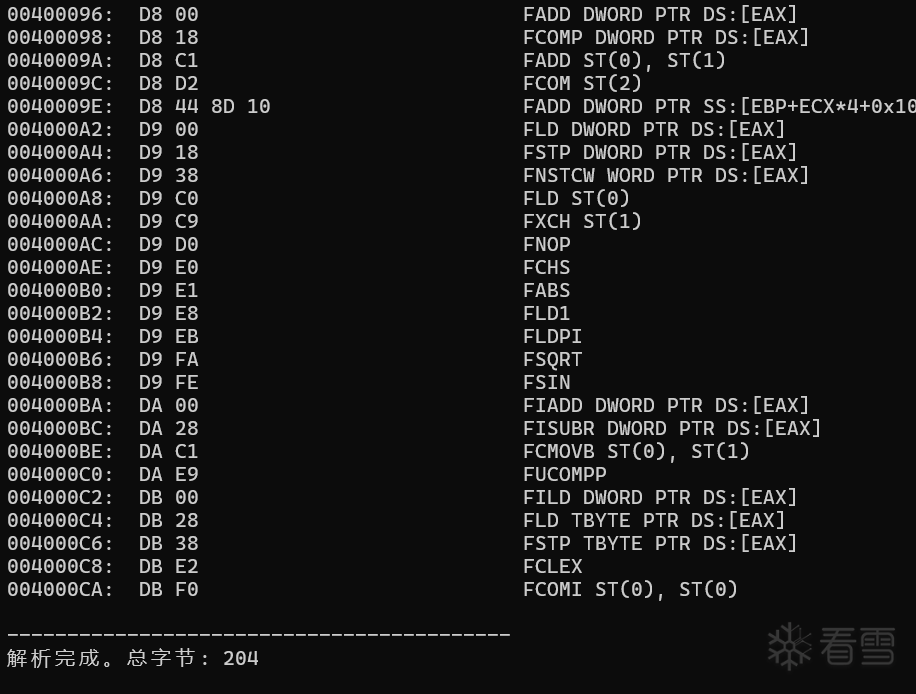
六、 测试通过与效果展示 千行代码见真章,造好轮子当然要下地跑一跑。在 main 函数的测试驱动中,我设计了两种不同的测试模式 :
1. 终极边缘用例大考场(硬编码数组单元测试) 我精心构造了一个 test_hex_codes 数组,里面硬编码了涵盖各种极端边缘情况的机器码,包括花式 0x66 前缀、段寄存器覆盖、极品 SIB 寻址组合和冷门的 FPU 浮点运算,专门用于打乱状态机的严苛测试考验。
2. 结合自有 PE 解析库实战拉练(硬核实盘反汇编) 不仅能玩小打小闹,它还被我集成了早前手写的 PE 格式解析工具 (PETools.c) 。只需要提供一个 exe 目标路径(比如 windbg.exe),引擎便会:
自动读取 PE 文件结构并映射到内存中的 ImageBuffer;
遍历节表(Section Headers)精准定位含有 IMAGE_SCN_CNT_CODE 属性的代码段(如 .text);
找出 VirtualAddress 后,无缝开始对真实被编译出来的二进制机器码进行地毯式的连续解析输出!
(目前为了方便演示各种坑位,这里放出来的是第一种测试模式下终端输出的效果)
跑起来的输出令人感到极致顺滑:
所有的字节流被完美还原出了对应的硬编码及正确的汇编指令结构,包含段寄存器覆盖、正确的内存寻径解析,以及复杂的浮点 FPU 指令。
3. 反汇编覆盖率与性能考量(得与失) 经过大量的真实 EXE 解包与测试,我们发现:对于大部分常规 x86 程序,本引擎的支持覆盖范围已经基本接近了 OllyDbg 等成熟调试器的呈现效果 。只要不是极为偏门且较新的 SIMD 扩展指令,经典 x86 指令全家桶它都能精准拿捏。
但是,既然是造轮子,就必须讲究得失的权衡。 为零基础学习者服务,逻辑极致清晰,且完全符合人类直觉 ”的设计初心,我在代码编写时主动牺牲了蛮多运行效率 。
为了代码易懂,内部多次进行了复杂结构体的拷贝传递与 snprintf 高频次字符串格式化拼接。
绝大多数解码判定都使用了结构体成员的显式赋值(如 has_modrm = true)和普通分支,并没有特意使用极客思维的位运算、状态树压缩表(像是商业反汇编引擎那样)来压榨极限性能。
因此,如果你想要用它去完成千万行级别汇编代码的极速静态扫描,它的效率会有明显瓶颈。但作为初级阶段逆向硬编码的教科书级实战项目 ,它舍弃的这点效率换来的是“零门槛的可读性”。一旦你读懂了它,想在此基础上优化性能便只是个人的工程问题罢了。
七、 结语与悬念预告 亲手搓一个能解析上千种 x86 组合的反汇编引擎是一段硬核的修行。FF 15 后面的 15,它的二进制刚好拆分成 Mod=0, Reg=2(CALL扩展), RM=5。原来花指令里植入的垃圾数据,是为了利用解析器的状态机缺陷。通过严格研读 Intel 白皮书,表驱动设计真的是编程之神。
这是结束吗?不,这只是个开始。
读懂了汇编,那能不能执行 汇编?Opcode、op1、op2,那我干脆再往前迈一步——自己写一套 CPU 寄存器上下文环境,给这套引擎再加上一套执行流!
没错,在完全手撕完这个解析器后,我又硬核爆肝,在上面套了一层壳,写出了一个 属于自己的纯 C 语言 x86 汇编虚拟解释器(x86 Virtual CPU Emulator) ,不仅能单步调试,还能模拟堆栈调用!
如果这篇反汇编引擎的文章大家觉得有帮助,反馈热烈的话,下一篇我将开源并为大家全面解析那个“x86 汇编虚拟解释器”的实现原理!
感谢阅读,欢迎看雪的各位大佬批评指正和留言交流! 逆向的浪漫,正是亲手撕开黑盒建立掌控感的过程,不是吗?
(本文为看雪论坛专属发文,记录于逆向学习初级班·硬编码阶段。代码纯C手搓,请大家多多指教!)
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-3-1 01:39
被XIAOQUAN777编辑
,原因: