从 x64dbg 的机器码反查 IDA / Ghidra:精准定位 C 语言伪代码的方法
关于使用基地址(ImageBase / rebase)的定位方式
可以通过 统一基地址(ImageBase / rebase) 的方式,直接在 x64dbg 与 IDA / Ghidra 之间进行地址对齐,从而实现快速跳转定位。
常见做法包括:
- 在 x64dbg 中查看模块的运行时基地址
- 在 IDA / Ghidra 中将对应模块的 ImageBase 设置为相同的基地址
- 此时调试器中的 RIP / EIP 地址,通常可以直接映射到反汇编或反编译视图中
这种方式在以下条件下效果较好:
- 程序无壳或已完整脱壳
- 运行时代码与文件中代码一一对应
- 模块未被手动映射,代码未在内存中动态生成
- 地址空间布局相对稳定
在满足上述条件的情况下,基地址对齐是一种高效的定位手段,可以快速完成从动态调试到静态分析的跳转。
本文介绍的 基于机器码(Opcode / Byte Sequence)的定位方法,则更多用于以下场景:
- 运行时代码与文件代码不完全一致
- 需要在不同工具之间进行稳定、可复现的定位
- 希望在不依赖地址假设的情况下,确认指令的真实来源
两种方式各有适用场景,实际分析中可以根据程序状态和分析阶段灵活选择。
在实际逆向分析中,经常会遇到这样一种非常常见、也非常让人头疼的情况:
- 在 x64dbg 中已经调试到关键逻辑
- 能看到关键的 汇编指令
- 但 汇编代码难以直接理解整体逻辑
- 希望跳转到 IDA / Ghidra 的 C 语言伪代码 来理解程序行为
问题是:
如何把 x64dbg 中的某一条汇编,精准定位到 IDA / Ghidra 中对应的反编译代码?
本文介绍一种 稳定、精准、实战中非常常用的方法:
通过机器码(Opcode)在 IDA / Ghidra 中反查对应的反编译位置
一、问题场景说明
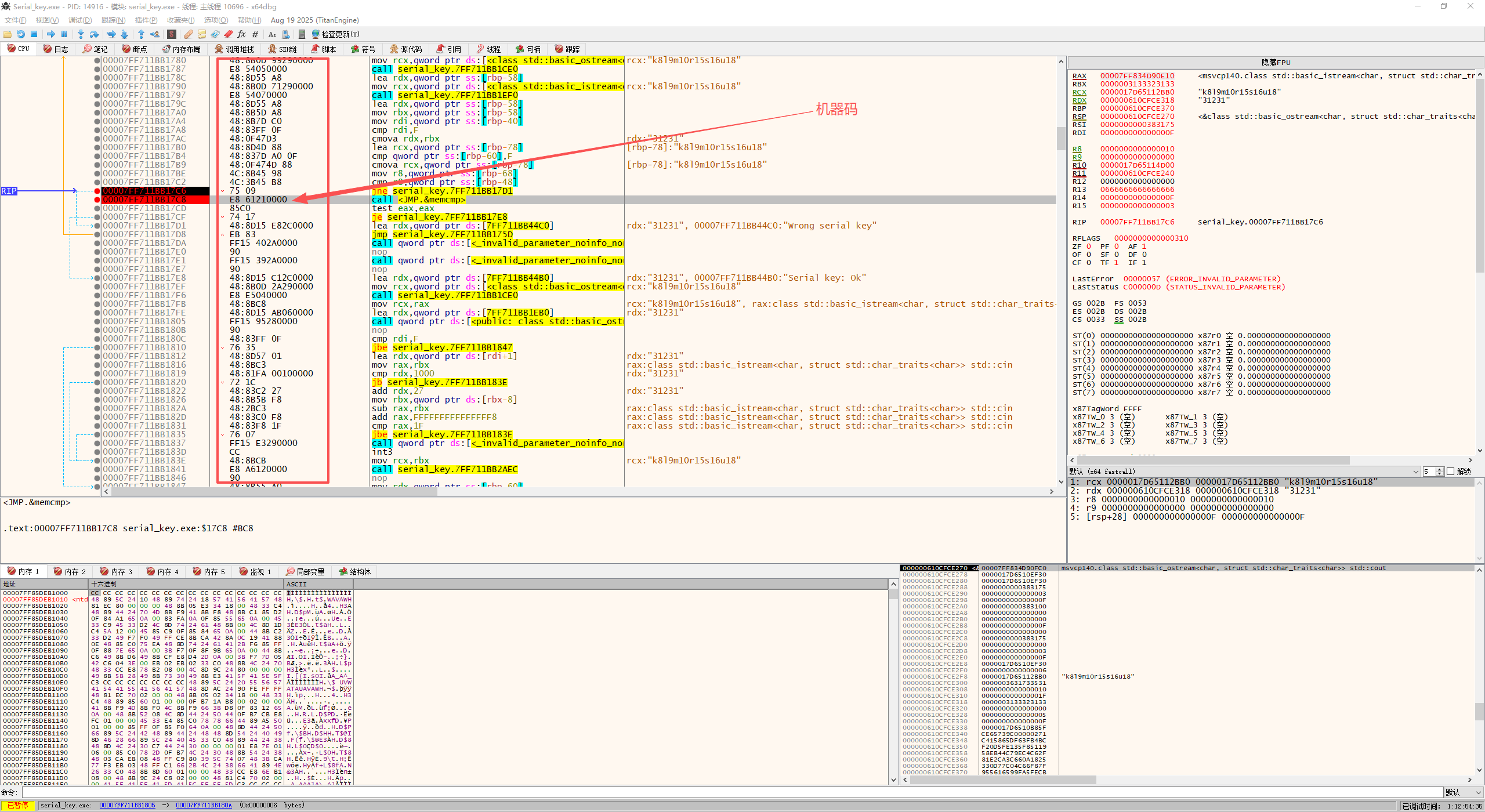
在 x64dbg 中调试程序时,定位到如下关键指令:
1 | 00007FF711BB17C8 | E8 61 21 00 00 | call <JMP.&memcmp>
|
这是一个对 memcmp 的调用。
但问题在于:
- x64dbg 里看到的是 汇编
- 汇编参数来源、条件判断、上下文关系并不直观
- 想知道它在 C 语言中对应的是哪一段逻辑
这时最自然的想法是:
在 IDA 或 Ghidra 中找到这条指令对应的 C 伪代码
二、核心思路(非常重要)
❌ 不要用「汇编文本」去对齐反编译器
✅ 而是使用:机器码(Opcode)
原因:
- 汇编文本在不同工具中:
- 但机器码是唯一稳定、不变的标识
- IDA / Ghidra / x64dbg 底层都是基于机器码分析
机器码 = 跨工具通用的定位锚点
三、从 x64dbg → IDA:通过机器码定位 C 伪代码
1️⃣ 在 x64dbg 中获取机器码
目标指令:
1 | 00007FF711BB17C8 | E8 61 21 00 00 | call <JMP.&memcmp>
|
对应的完整机器码为:
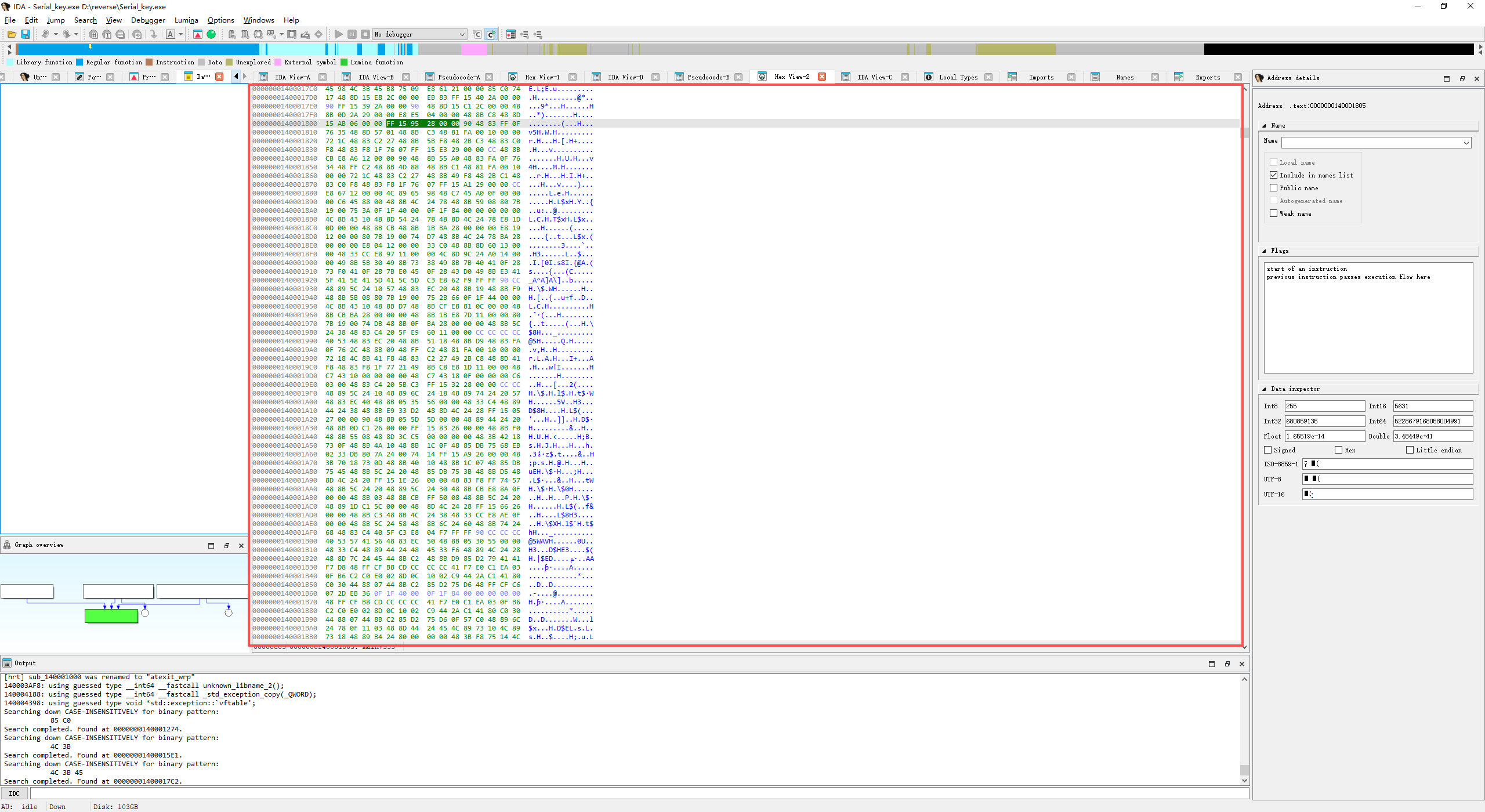
2️⃣ 在 IDA 中打开 Hex View
菜单路径:
1 | View → Open subviews → Hex dump
|
在弹出的窗口中,双击 Hex dump 或选中后点击 OK。
此时会出现类似:
3️⃣ 使用机器码搜索(Alt + B)
在 IDA 中按下:
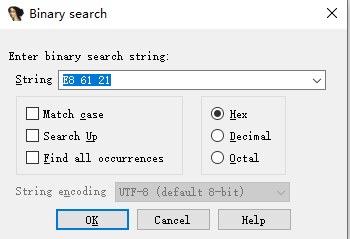
在弹出的搜索窗口中:
- 搜索类型:Binary
- 输入机器码(每两位一个字节,通常使用空格分隔):
⚠ 重要说明(容易踩坑):
- 输入时 是否带空格并不是本质区别
- 最终一定要以 IDA 显示的
Byte Sequence 解析结果为准
- 只要
Byte Sequence 显示的字节序列与 x64dbg 中看到的机器码一致:
那么搜索结果就是正确的
不要纠结输入格式,解析结果才是唯一标准
点击 OK 开始搜索。
4️⃣ 跳转到反汇编 / 伪代码位置
搜索成功后,IDA 会直接跳转到匹配位置。

此时你可以:
- 查看反汇编窗口
- 按下 Tab 键切换到伪代码视图(Hex-Rays)
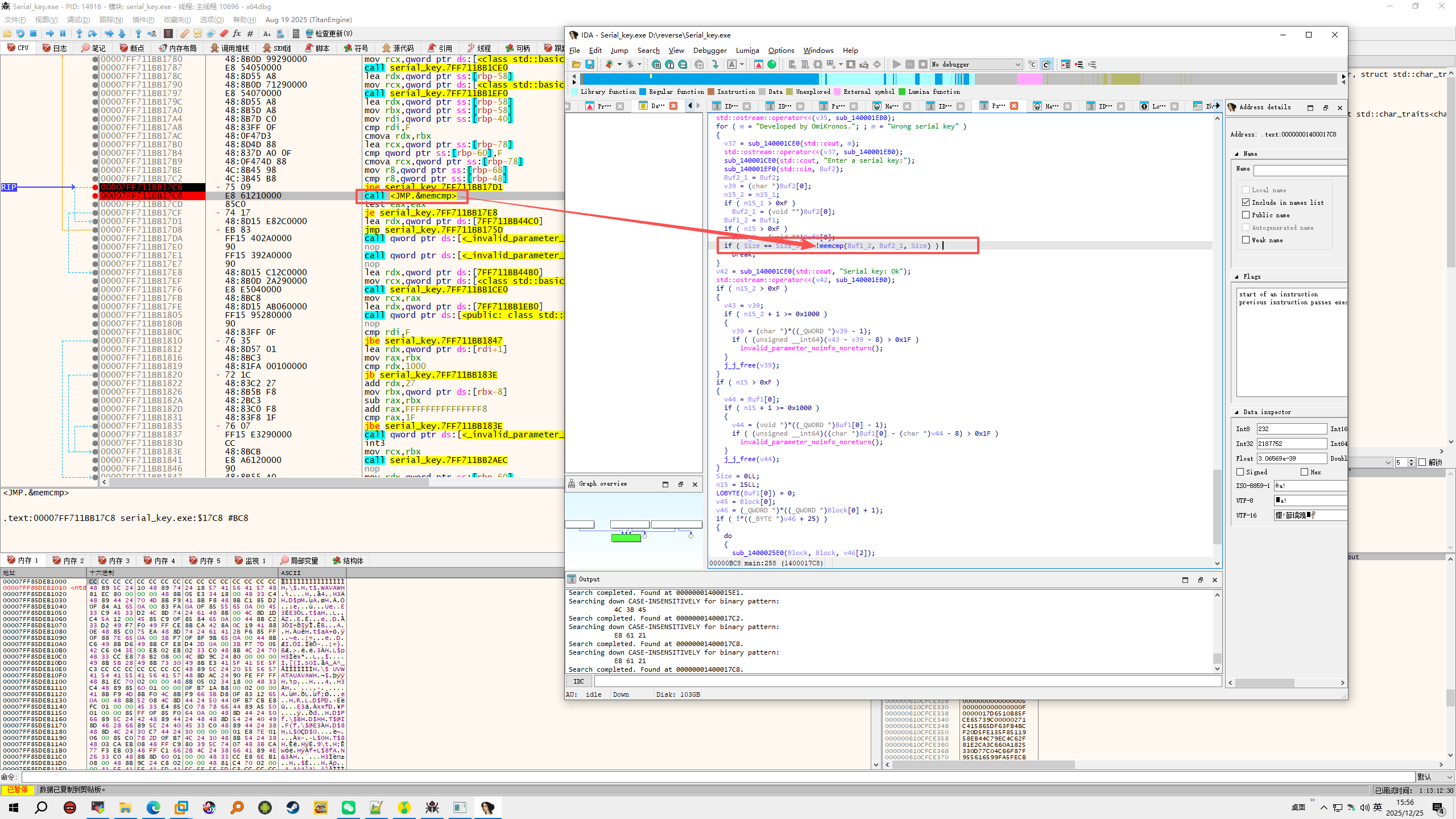
你会看到类似如下的 C 语言逻辑:
1 2 3 4 | if ( memcmp(a1, a2, v3) == 0 )
{
...
}
|
至此,x64dbg 中的汇编已经成功映射到 IDA 的 C 语言逻辑
四、从 x64dbg → Ghidra:通过机器码定位 C 代码
Ghidra 的思路完全一致,但操作细节略有不同。
1️⃣ 打开内存搜索窗口
菜单路径:
会打开 Search Memory 搜索窗口。
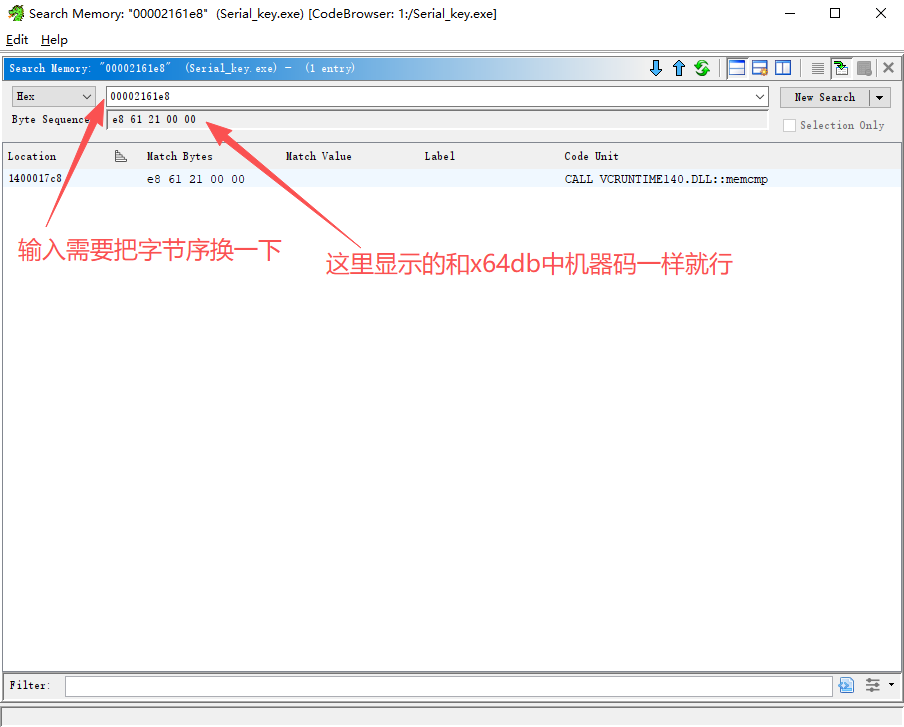
2️⃣ 输入机器码(⚠ 以 Byte Sequence 为准)
仍然是这条指令:
在 Ghidra 中:
- 输入时 不能包含空格
- 使用连续的十六进制字节序列:
输入完成后,下方会显示 Byte Sequence。
⚠ 关键点:
- 输入格式只是手段
- 最终必须确认 Byte Sequence 与 x64dbg 中的机器码顺序、字节完全一致
- Byte Sequence 才是 Ghidra 实际用于搜索的内容
确认无误后,点击 Search 或 New Search。
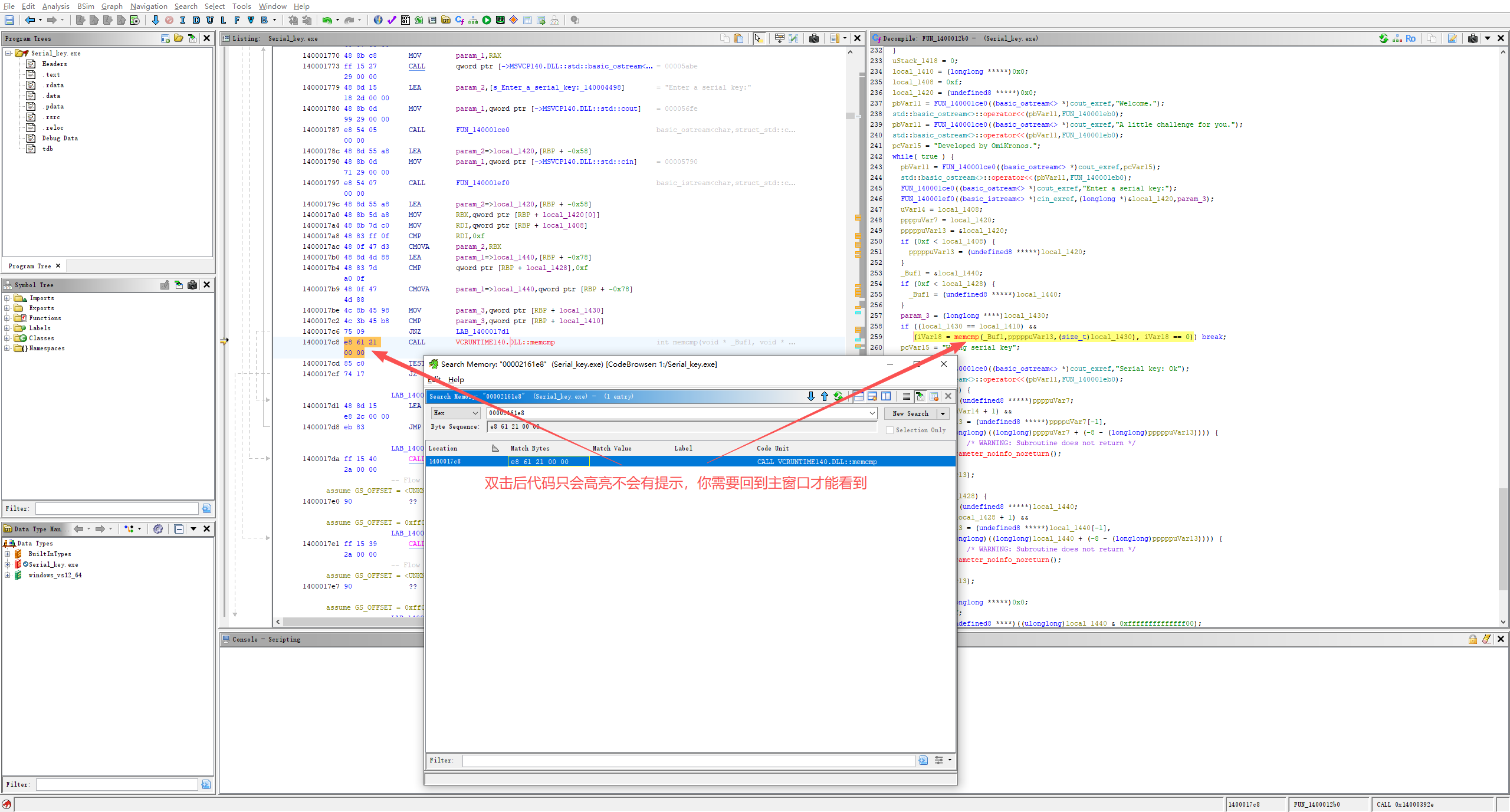
3️⃣ 跳转并查看反编译代码
搜索结果列表中会出现匹配项,例如:
1 2 | Location Match Bytes Code Unit
1400017c8 e8 61 21 00 00 CALL VCRUNTIME140.DLL::memcmp
|
双击该条目即可跳转。
随后打开 Decompile 窗口,就能看到对应的 C 语言代码,并且该调用位置会被高亮。
⚠ 注意:
- Ghidra 不会弹窗提示“这是你要找的代码”
- 如果搜索结果有多个,需要你结合上下文自行判断
五、反向操作:从 IDA / Ghidra → x64dbg
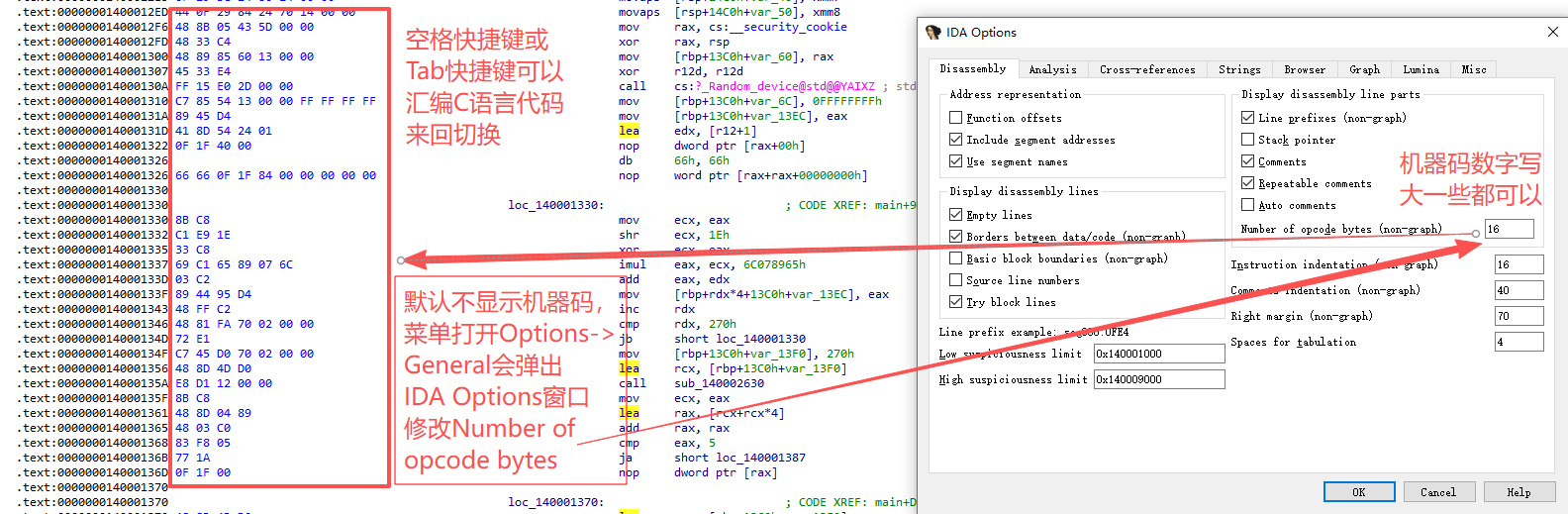
如果你的起点是:
- IDA / Ghidra 中的 C 伪代码
- 想反查到 x64dbg 中进行动态调试
IDA 中开启机器码显示
IDA 默认不显示机器码,可以在:
1 | Options → General → 勾选显示 opcode bytes
|
或者直接使用:
六、总结(实战建议)
✔ 不要试图“肉眼对齐汇编”
✔ 机器码才是跨工具的唯一稳定标识
✔ 输入格式不重要,Byte Sequence 才是最终裁判
推荐工作流:
1 2 3 4 5 6 7 8 9 | x64dbg 定位关键逻辑
↓
复制机器码(Opcode)
↓
IDA / Ghidra 搜索(确认 Byte Sequence)
↓
查看 C 伪代码
↓
理解逻辑 / 还原算法
|
这套方法在分析壳、反调试、关键校验、核心算法定位中都非常实用。
已整理为 Markdown(MD)格式,可直接粘贴使用:
反汇编器
在不同逆向工具(x64dbg / IDA / Ghidra)之间进行定位时,真正稳定的并不是“看起来最高级”的那一层,而是所有反汇编器都必须遵守的共同基础。
各层级稳定性对比
| 层级 |
稳定性 |
| C 伪代码 |
❌ 不稳定 |
| 汇编文本 |
⚠️ 半稳定 |
| 地址(基地址) |
⚠️ 依赖环境 |
| 机器码(Opcode) |
✅ 稳定 |
机器码 = 跨工具通用的定位锚点
无论是 x64dbg、IDA 还是 Ghidra,它们在显示层面可以各不相同,但底层分析的对象始终是同一份 Byte Sequence。
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2026-1-6 19:47
被我是jet编辑
,原因: 补充内容







