本文用于学习/复现 LLVM 混淆 的原理,并给出在 IDA 侧做“识别→模拟→还原”的实现思路。
(Hikari)
对应代码:
对每个 条件分支(BranchInst 且 isConditional()):
最终语义保持不变:仍然只会跳到 T 或 F,但目标地址不再直接出现在分支指令里,而是运行时解密得到。
IndirectBranch 把每个条件分支的每个 successor 基本块(TBB/FBB)转换为 BlockAddress 常量:
这类 BlockAddress 常量被当作“对象”,最终会进入 对象表(objects table):
在 Utils.cpp::createPageTable 里:
createPageTable(...) / enhancedPageTable(...) 会生成若干个 int32 数组(页表):
在 IndirectBranch.cpp 里:
BBKey 的布局在代码里是:
Utils.cpp::maskCipher(...) 定义了一组 index 变换(伪代码):
createPageTable(...) 会对每个对象的 index 做多轮 maskCipher,把结果写进 int32 page_table[]。
直观理解:
Utils.cpp::buildPageTableDecryptIR(const BuildDecryptArgs&) 是 “iCall / indbr / indirectgv” 共用的解密器。
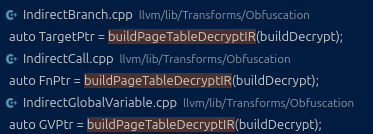
对 IndirectBranch 场景,BuildDecryptArgs 的关键字段是:
解密过程按“从最后一层到第一层”迭代(倒序遍历 page table 列表):
代码里用的不是显式 rotl/rotr 指令,而是 IR intrinsic:
这也是为什么落到 AArch64 机器码后,通常会看到 ROR 之类旋转指令。
byteSwap() 在 IR 里会变成 llvm.bswap.* intrinsic,落地到 AArch64 常见是 REV 系列。
对每个 conditional BranchInst BI:
关键点:
把上面的 IR 概念映射到机器码,通常会出现:

因此片段:
对应代码:
IndirectCall 的语义很简单:不再在 call 指令里直接出现被调函数地址,而是把它变成:

注意:它的“页表/解密器”与 -irobf-indbr 共用同一套 Utils.cpp::buildPageTableDecryptIR,所以这里不再重复解释解密链细节(ROR/REV/NEG/MVN/EOR/... 的来源见 indbr 章节)。
在 IndirectCall.cpp 中,会遍历模块里的 CallInst/CallBase:
初始化阶段会调用 createPageTable(...) / enhancedPageTable(...):
opt.level() > 0 时,页表可能是“函数级增强 + 模块级”的两级/多级(同 indbr)。
对每个 callsite:
与 indbr 很像,只是“最后一步”从 BR 变成 BLR:
因此在二进制里常见的 callsite 形态就是:
对应代码:
IndirectGlobalVariable(indgv)的目标是隐藏**全局变量/全局对象/全局常量(含字符串常量)**的真实地址与交叉引用关系:

核心语义不变:程序仍然访问同一个全局对象,但“地址来源”变成运行时计算。
在 IndirectGlobalVariable.cpp 中:
与 indbr/icall 一致:key 的高位作为 mask 驱动 maskCipher,低位作为扰动 key。
初始化阶段会调用 createPageTable(...) / enhancedPageTable(...) 生成两类全局结构:
当 opt.level() > 0 时,也可能出现“函数级增强页表 + 模块级页表”的组合(同 indbr/icall)。
对每个指令 Inst,如果它的 operand 直接/间接使用了目标 GV:
这一步是 indgv 的本质:它不改控制流,而是把“数据地址”改成“解密后指针”。
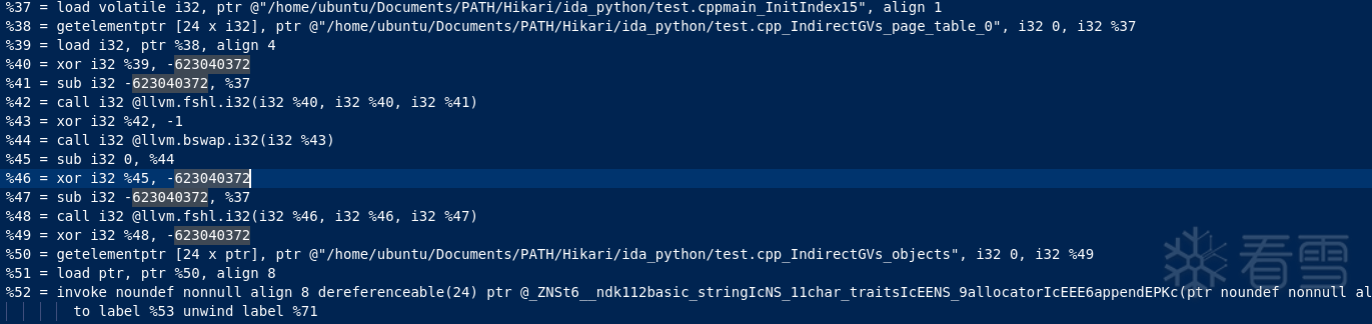
indgv 的核心就是:把“全局地址常量”变成“运行时解密得到的指针值”。它与 indbr/icall 复用同一套 page_table + maskCipher + buildPageTableDecryptIR,区别只在“解密结果的用途”——indgv 把结果当作数据指针继续参与数据流(传参/读写/GEP),而不是立刻 BR/BLR 改控制流。
indgv 的“页表解密链”与 indbr/icall 本质一致(同一套 buildPageTableDecryptIR),差别只在最后“解密结果”的用途:
因此在 AArch64 机器码中,常见形态仍然是:
区别在于:LDR Xdst, [Xobj, ...] 之后通常不会立刻 BR/BLR,而是把 Xdst:
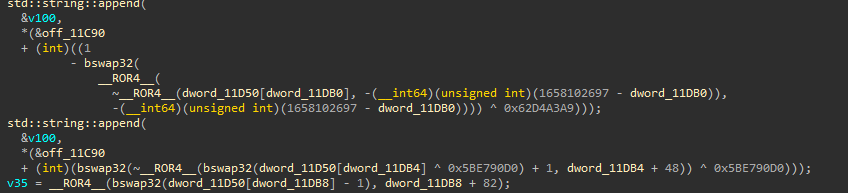
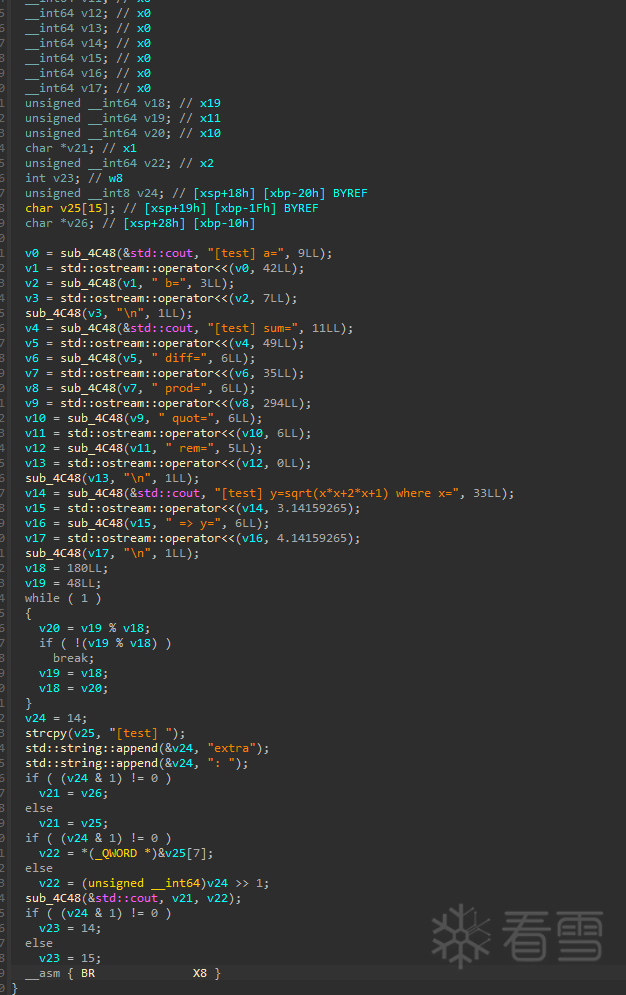
我们先看一下 main() 混淆后的伪代码效果(明显变短,控制流被“掐断”):
再看对应汇编,会发现关键位置最终落到 BR Xn 这种间接跳转,导致 IDA 很难像直跳那样把 CFG 还原出来:
这类现象和“简单花指令”(例如 BL sub; ADD X1, X0, #imm; BR X1)很像:本质都是 运行时计算目标地址再跳转。区别在于:
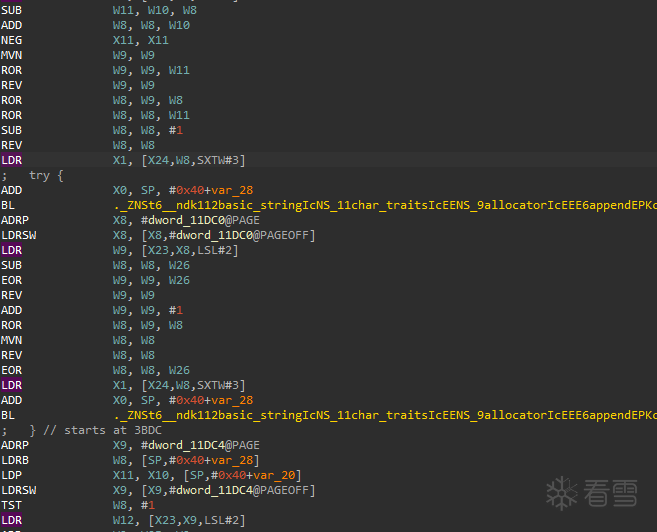
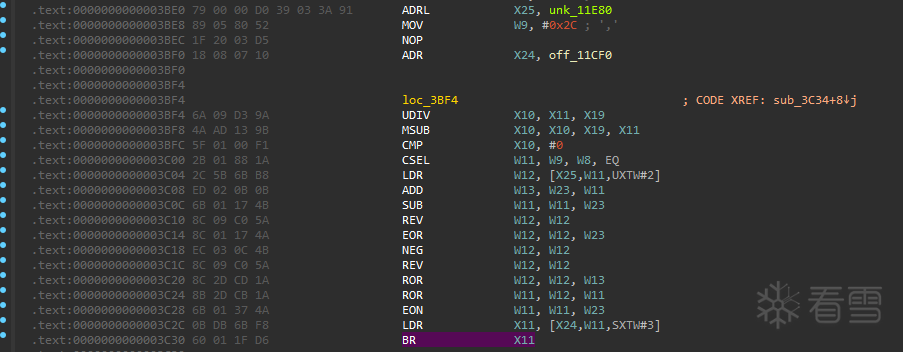
下面是一段典型的 indbr 机器码:
对应到段里最“关键”的 6 行就是:
观察寄存器“基址”来源:
因此可以把这段 indbr 理解为:
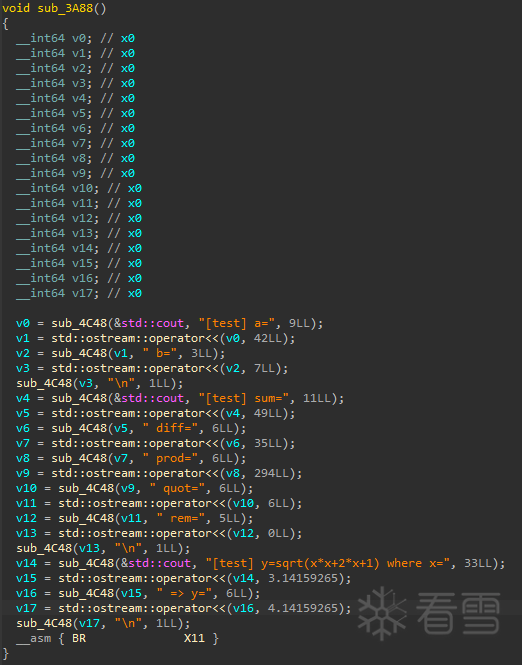
下面以 sub_3A88 片段为例,手动把 BR X11 的目标算出来。先把“只用于计算跳转目标”的指令摘出来(与前面打印逻辑无关):
说明:这里的 W23 是 key(由 MOV/MOVK 拼出来),其值为:
W23 = 0x95E0D26D
这里要强调一点:CSEL 让这段 indbr 逻辑具有两条可能路径:
两条路径后续“page dword 读取 + 变换链 + objects 查表”完全相同,但因为 输入 index 不同,最终会导向 不同的 BR 目标。下面分别把两条路径算出来。
因此(路径 B:W11=0x2E):
记这个 dword 为:
在样本里:unk_11E80+0xB8 = 0x11F38 的 4 字节是:B3 ED 8C 27(little-endian)。
因此本次 LDR 读到的 t0 = 0x278CEDB3。
路径 A(W11=0x2C)同理,只是读取的地址改为:
结合本样本的 tables(把后面算出来的结果反推回来可验证),这一项 dword 为:
从这一行开始,所有运算都在 32-bit 的 W 寄存器里进行(自动模 (2^{32})):
下面开始处理 W12:
到这里,我们得到了最终 index:
先算路径 B(W11=0x2E)。把上面链条的 t0=0x278CEDB3 代入,并使用:
可得到路径 B 的最终 index:
再算路径 A(W11=0x2C)。同样代入(此时:
)可得到路径 A 的最终 index:
因此 BR X11 的真实目标就是:
路径 B(else)我们已经算出 idx_final_else=9,所以:
贴的 objects 表:
off_11CF0 + 0x48 = 0x11D38 → DCQ loc_3C34
所以 路径 B 的 BR X11 最终跳转目标就是 0x3C34
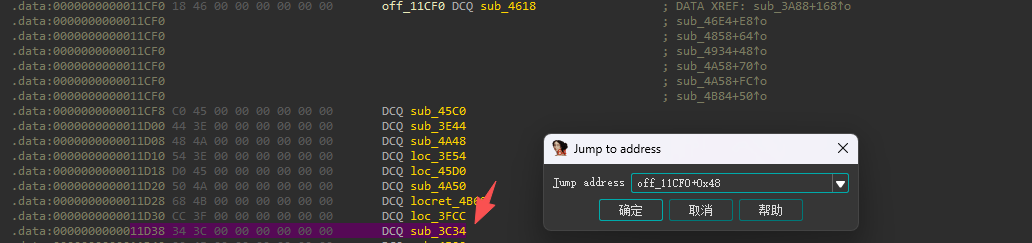
路径 A(EQ)我们已经算出 idx_final_eq=39。对应的表项偏移是:
39*8 = 0x138
off_11CF0 + 0x138 = 0x11E28 → DCQ loc_3C40
所以 路径 A 的 BR X11 最终跳转目标就是 0x3C40。
下一个间接跳转和 之前类似不在手动处理下面介绍自动处理方案
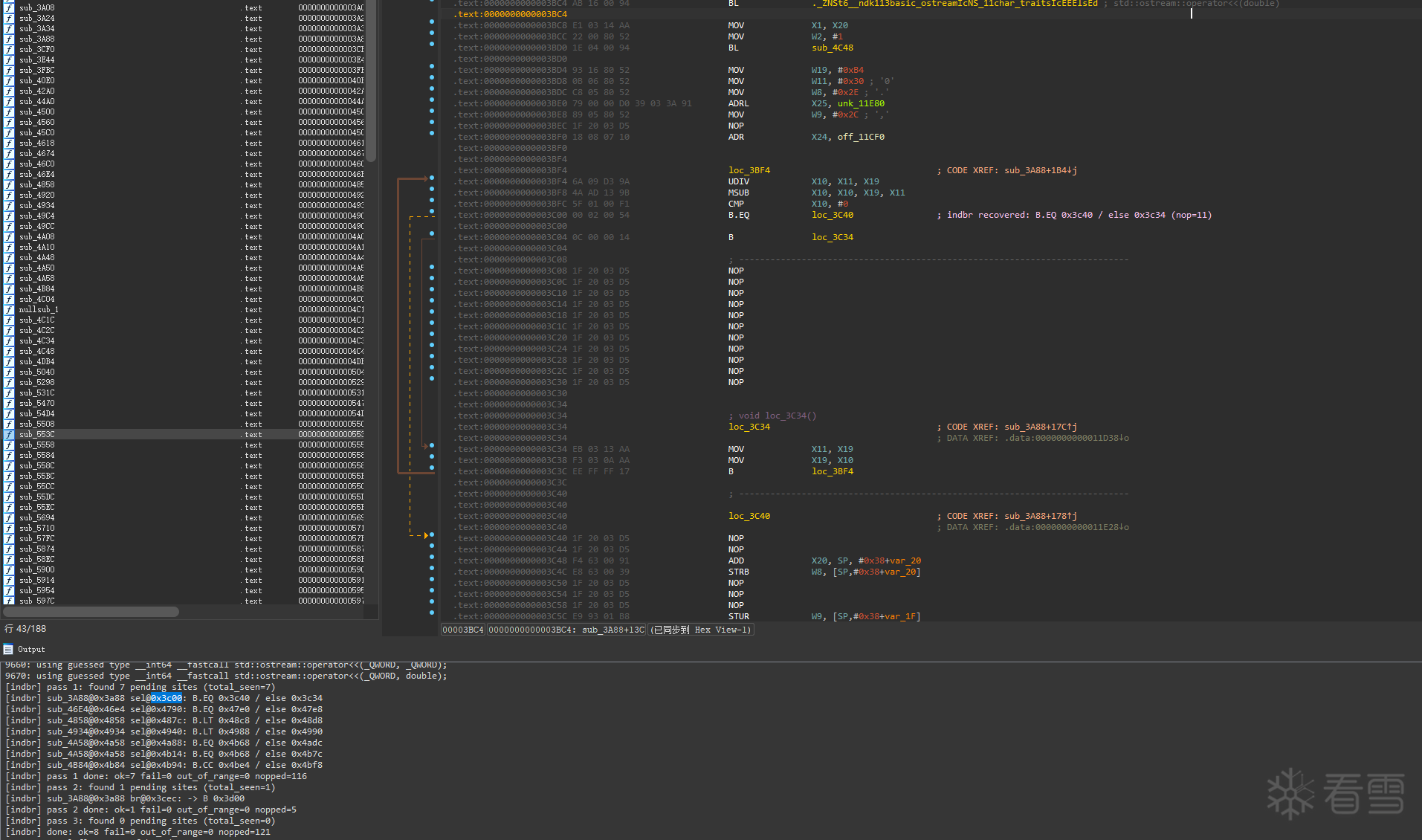
批量处理的第一步,不是先去“猜解密链长什么样”,而是先回答一个更现实的问题:我到底要从哪儿开始找这些 indbr?
最省事的入口其实就是 BR ——因为 indbr 最终一定会落地成一次间接跳转。
但如果“只扫 BR”,会遇到两个问题:
所以搜索思路要做一个抽象:从 BR 作为锚点出发,向上回溯它的喂值链,把“普通间接跳转”和“indbr 解密跳转”区分开。
具体来说,我们要求 BR 上面能回溯出两段非常有辨识度的喂值:
最后再加一道“强过滤”,基本就能把误判压下来:
回溯确认 Xobj/Xtbl 的基址寄存器,是通过 ADR/ADRP/ADRL 指向我们已知的表符号(例如 off_11CF0、unk_11E80)。
一句话总结这个匹配逻辑就是:
脚本输出每个 site 的关键信息:
对应的扫描脚本:ida_python/indbr_scan.py

定位到 site 之后,“算地址”其实就简单了:把那一小段解码链跑一遍,然后读 BR 用的目标寄存器。
这里不用硬抠每条指令的语义(REV/ROR/EOR/NEG/... 组合太多,JNI_OnLoad 和别的函数也可能不一样),更稳的做法是直接上 Unicorn:
如果遇到 CSEL/CSINC 这种“二选一”的 index(同一个 BR 有两个可能 target),也不需要真的去控制 flags:
我们可以先跑到 CSEL/CSINC 前,把它两路的 src 值 snapshot 出来,然后 强行把 dst 写成两种值,分别继续跑到 BR,就得到两条落点。
对应的计算脚本:indbr_calc_unicorn.py
输出形式大概是:

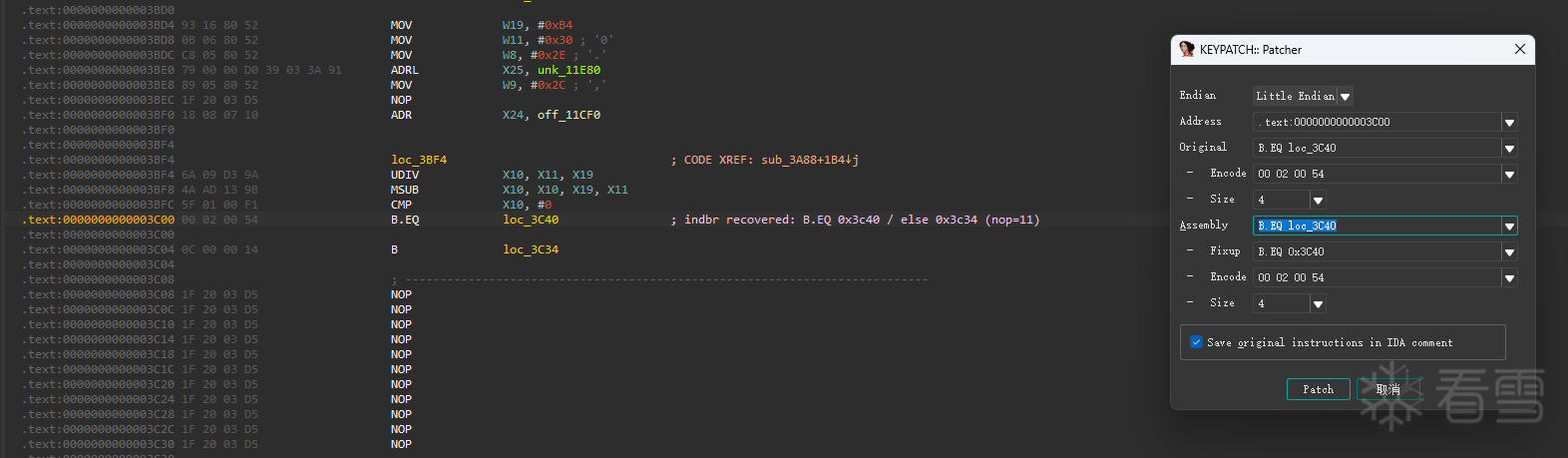
上一步我们已经能把每个 site 的落点算出来了,那么 patch 的目标也很朴素:把“间接跳转”改成“直接跳转”,让 Hex-Rays 和 CFG 立刻恢复正常。
这里分两类情况:
单目标(最常见):BR Xn 的 Xn 在当前路径下只有一个值直接把 BR Xn patch 成 B target,然后把 basic block 里那一串纯计算(REV/ROR/EOR/NEG/...)NOP 掉即可。
双目标(常见于 CSEL/CSINC 选择 index):同一个 site 在运行时可能跳两处这类如果只 patch BR,就会把它“固化”成单一路径,语义可能变掉。更稳的做法是:在 sel 那一条指令位置把两路直接写出来:
对应的 patch 脚本:ida_python/indbr_deobf_patch_unicorn.py
脚本内部做了三件事(对应脚本里最关键的几个开关也写在开头配置区):
提醒两点(很关键):
修复后的CFG和Hex-Rays:
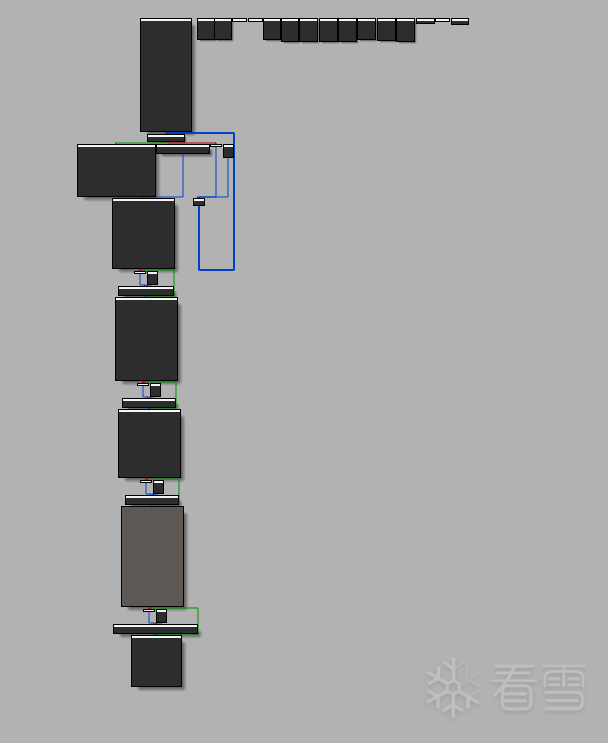
在 Hikari 里,indbr / icall / indgv 看起来是三个 pass,其实可以把它当成 “同一套解密链 + 三种不同用途”。
它们的共同点很直观:
所以 IDA 侧的套路也基本一样:先把站点定位出来,再用 Unicorn 把目标算出来,最后 patch 掉(把“间接”变“直接”)。
关于多层跳转其实就是“套娃”:算出来的 target 跳过去,发现那边还是一套同样的计算 + BR/BLR。
处理方式也别很简单:
龙哥
Hikari
最近闲着无聊建了一个吹水群,欢迎进群吹水

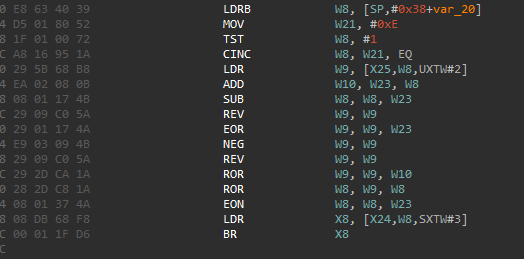
MOV W19, #0xB4
MOV W11, #0x30
MOV W8, #0x2E
ADRL X25, unk_11E80 ; page_table base (dword*)
MOV W9, #0x2C
ADR X24, off_11CF0 ; objects base (qword*)
UDIV X10, X11, X19
MSUB X10, X10, X19, X11
CMP X10, #0
CSEL W11, W9, W8, EQ ; pick 0x2C or 0x2E
LDR W12, [X25, W11, UXTW#2] ; w12 = page[w11]
ADD W13, W23, W11
SUB W11, W11, W23
REV W12, W12
EOR W12, W12, W23
NEG W12, W12
REV W12, W12
ROR W12, W12, W13
ROR W11, W12, W11
EON W11, W11, W23
LDR X11, [X24, W11, SXTW#3] ; x11 = objects[ signext(w11) ]
BR X11
MOV W19, #0xB4
MOV W11, #0x30
MOV W8, #0x2E
ADRL X25, unk_11E80 ; page_table base (dword*)
MOV W9, #0x2C
ADR X24, off_11CF0 ; objects base (qword*)
UDIV X10, X11, X19
MSUB X10, X10, X19, X11
CMP X10, #0
CSEL W11, W9, W8, EQ ; pick 0x2C or 0x2E
LDR W12, [X25, W11, UXTW#2] ; w12 = page[w11]
ADD W13, W23, W11
SUB W11, W11, W23
REV W12, W12
EOR W12, W12, W23
NEG W12, W12
REV W12, W12
ROR W12, W12, W13
ROR W11, W12, W11
EON W11, W11, W23
LDR X11, [X24, W11, SXTW#3] ; x11 = objects[ signext(w11) ]
BR X11
注意:它的“页表/解密器”与 -irobf-indbr 共用同一套 Utils.cpp::buildPageTableDecryptIR,所以这里不再重复解释解密链细节(ROR/REV/NEG/MVN/EOR/... 的来源见 indbr 章节)。
opt.level() > 0 时,页表可能是“函数级增强 + 模块级”的两级/多级(同 indbr)。
与 indbr/icall 一致:key 的高位作为 mask 驱动 maskCipher,低位作为扰动 key。
这一步是 indgv 的本质:它不改控制流,而是把“数据地址”改成“解密后指针”。
说明:这里的 W23 是 key(由 MOV/MOVK 拼出来),其值为:
W23 = 0x95E0D26D
在样本里:unk_11E80+0xB8 = 0x11F38 的 4 字节是:B3 ED 8C 27(little-endian)。
因此本次 LDR 读到的 t0 = 0x278CEDB3。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | MOV W19, #0xB4
MOV W11, #0x30
MOV W8, #0x2E
ADRL X25, unk_11E80 ; page_table base (dword*)
MOV W9, #0x2C
ADR X24, off_11CF0 ; objects base (qword*)
UDIV X10, X11, X19
MSUB X10, X10, X19, X11
CMP X10, #0
CSEL W11, W9, W8, EQ ; pick 0x2C or 0x2E
LDR W12, [X25, W11, UXTW#2] ; w12 = page[w11]
ADD W13, W23, W11
SUB W11, W11, W23
REV W12, W12
EOR W12, W12, W23
NEG W12, W12
REV W12, W12
ROR W12, W12, W13
ROR W11, W12, W11
EON W11, W11, W23
LDR X11, [X24, W11, SXTW#3] ; x11 = objects[ signext(w11) ]
BR X11
|
ida pro 7.7原理说明图文 混淆级别默认(3)
llvm/lib/Transforms/Obfuscation/IndirectBranch.cppllvm/lib/Transforms/Obfuscation/Utils.cpp(createPageTable / enhancedPageTable / buildPageTableDecryptIR)
- 原始 IR:
br i1 %cond, label %T, label %F
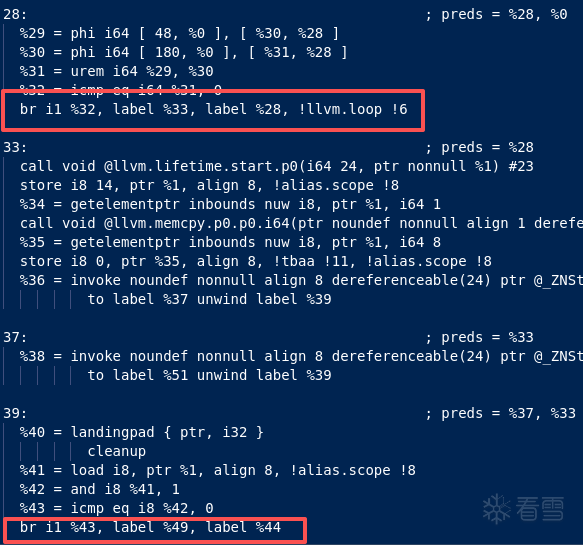
- 混淆后 IR:
- 先通过
select(SSA 形式)在 两个 successor 的索引之间选择一个 NextIndex
- 再通过“页表解密”把
NextIndex 变换成一个 指向目标基本块地址的指针
- 用
indirectbr i8* %TargetPtr, [label %T, label %F] 完成跳转
br i1 %cond, label %T, label %F
- 先通过
select(SSA 形式)在 两个 successor 的索引之间选择一个 NextIndex
- 再通过“页表解密”把
NextIndex 变换成一个 指向目标基本块地址的指针
- 用
indirectbr i8* %TargetPtr, [label %T, label %F] 完成跳转
auto BBAddr = BlockAddress::get(Successor);
createPageTableArgs.Objects = &BBAddrTargets;
- 生成一个全局数组
_objects,元素类型是指针(把 BlockAddress bitcast 成 i8*)
- 该数组就是“地址对象表”:
objects[index] = &BasicBlock
- 每一层页表把“输入 index”映射到“下一层 index”(或映射到最终对象)
opt.level() > 0 时,还会为“函数级”再生成一套增强页表(enhancedPageTable),形成 FuncPageTable + ModulePageTable 两级混淆


- 模块初始化阶段
NumberBasicBlock 为每个函数生成 BBKey = RandomEngine.get_uint64_t()
- 对同一函数内的所有
BlockAddress,使用同一个 BBKey 作为该函数的 key(BBKeys[BBAddr] = BBKey)
- 低 32 位:
ObjKey
- 高 32 位:
ObjMask
NEG:preIndex = -preIndexROTL/ROTR:依赖 (ObjKey ± newIndex) 的旋转BSWAP:字节交换NOT:按位取反XOR:与 ObjKey 异或
- “页表”不是简单的
index -> index 映射,而是把映射值做了可逆扰动(mask/key 驱动)
- 这些扰动在解密时会被逆向再做一遍,所以最终仍能还原出正确 index
NextIndexValue:来自 select(cond, TIndex, FIndex)LoadTy = i8*(无条件指针)ModulePageTable / FuncPageTable:页表数组列表(从外层到内层)ModuleKey / FuncKey:对应 key/mask
return load objects[NextIndex](类型为 LoadTy,在 indbr 里即 i8* 的 BlockAddress)
Intrinsic::fshl:等价“rotate left”Intrinsic::fshr:等价“rotate right”
- 无函数级增强时:
BBIndex[AddrTBB] / BBIndex[AddrFBB]
- 有增强时:
FuncBBIndex[...]
IndirectBrInst::Create(TargetPtr, 2)addDestination(TBB) / addDestination(FBB)
indirectbr 的目的地列表仍然显式包含 TBB/FBB,保证 IR 验证正确- 但实际选择哪个目标,被“隐藏”进
TargetPtr 的解密过程里
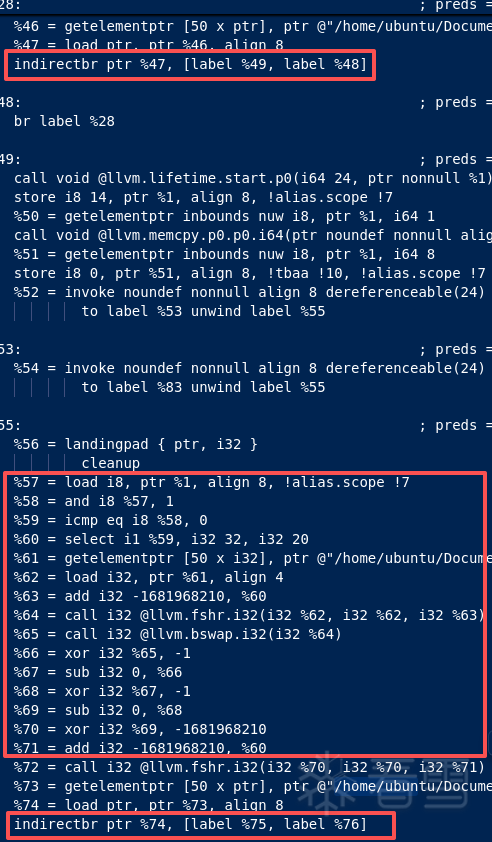
- Cond 选择:
select 落地为 CSEL / CSET 等
- 页表读取:
load page[index] 落地为 LDR Wt, [Xtbl, Xidx, LSL #2](dword 表)
- 变换链:
neg/not/xor/bswap/rot 落地为 NEG/MVN/EOR/REV/ROR/...
- 对象表读取:
load objects[index] 落地为 LDR Xn, [Xobj, Widx, SXTW #3](qword 指针表)
- 间接跳转:
indirectbr 落地为 BR Xn
CSEL W11, W9, W8, EQ:对应 select(cond, TIndex, FIndex)LDR W12, [X25, W11, UXTW#2]:对应读取某一层 dword page table- 后面
NEG/MVN/EOR/ROR/...:对应 buildPageTableDecryptIR 的 mask/key 驱动变换
LDR X11, [X24, W11, SXTW#3]:对应 objects[index] 取目标 BlockAddressBR X11:对应最终间接跳转
llvm/lib/Transforms/Obfuscation/IndirectCall.cppllvm/lib/Transforms/Obfuscation/Utils.cpp(createPageTable / enhancedPageTable / buildPageTableDecryptIR)
- 解析真实 callee:
getCalledFunction() 或 getCalledOperand()->stripPointerCasts()
- 把 callee 视为“对象”(Object)
- 为对象分配一个随机 64-bit key:
- 低 32 位:
ObjKey
- 高 32 位:
ObjMask
getCalledFunction() 或 getCalledOperand()->stripPointerCasts()
- 低 32 位:
ObjKey
- 高 32 位:
ObjMask
- Objects table:指针数组(元素是 callee 的函数指针)
- 命名形如:
<ModuleName>_IndirectCallee_objects
- Page table:dword 数组(元素是“被 maskCipher 多轮扰动后的 index”)
- 命名形如:
<ModuleName>_IndirectCallee_page_table_0(以及更多层/更多轮)
- 命名形如:
<ModuleName>_IndirectCallee_objects
- 命名形如:
<ModuleName>_IndirectCallee_page_table_0(以及更多层/更多轮)
- 构造
BuildDecryptArgs
- 调
buildPageTableDecryptIR(buildDecrypt) 得到 FnPtr
- 把原本
call @foo(...) 改成 call FnPtr(...)
- 页表读取:
LDR Wt, [Xtbl, Widx, (SXTW|UXTW|LSL)#2]
- 变换链:
NEG/MVN/EOR/REV/ROR/...(对应 maskCipher/buildPageTableDecryptIR)
- 对象表读取(函数指针):
LDR Xn, [Xobj, Widx, SXTW#3]
- 间接调用:
BLR Xn
LDR Xn, [objects, idx*8]BLR Xn
llvm/lib/Transforms/Obfuscation/IndirectGlobalVariable.cppllvm/lib/Transforms/Obfuscation/Utils.cpp(createPageTable / enhancedPageTable / buildPageTableDecryptIR)
- 混淆前:指令/IR operand 里直接出现
@Global(或能直接推到 @Global)
- 混淆后:先通过页表解密得到
GVPtr,后续用 GVPtr 参与 LDR/STR/传参/GEP/...
- pass 会遍历函数内指令的操作数(operand),收集其中的
GlobalVariable
- 并为每个目标
GV 分配一个随机 64-bit key:
- 低 32 位:
ObjKey
- 高 32 位:
ObjMask
- 低 32 位:
ObjKey
- 高 32 位:
ObjMask
- Objects table:指针数组
- Page table(s):
int32 数组(可能多层/多轮)
- 每个元素是“被 maskCipher 多轮扰动后的 index”
- 每个元素是“被 maskCipher 多轮扰动后的 index”
- 构造
BuildDecryptArgs:
NextIndex:该 GV 对应的 index(或函数级 index)LoadTy:GV->getType()(即“GV 指针类型”)ModulePageTable/FuncPageTable + ModuleKey/FuncKey
- 调用
buildPageTableDecryptIR(buildDecrypt) 得到一个 SSA 值 GVPtr
- 用
GVPtr 替换原本 operand 里的 GV
NextIndex:该 GV 对应的 index(或函数级 index)LoadTy:GV->getType()(即“GV 指针类型”)ModulePageTable/FuncPageTable + ModuleKey/FuncKey
indbr:解密结果当作基本块地址 → BRicall:解密结果当作函数指针 → BLRindgv:解密结果当作数据地址 → 后续 LDR/STR/传参/...
- 页表读取(dword):
LDR Wt, [Xtbl, W/X idx, *#2]
- 变换链:
NEG/MVN/EOR/REV/ROR/...
- 对象表读取(qword 指针):
LDR Xdst, [Xobj, Widx, *#3]
- 作为参数传给库函数(例如
std::string::append(ptr))
- 作为后续内存访问基址(
LDR/STR [Xdst, #imm])
- 作为
GEP / 指针运算的基址继续传播
- 简单花指令:目标常常是“当前 PC + 常量”,工具有时能直接算出
JUMPOUT(addr)
-irobf-indbr:目标来自 page table + objects table + 多轮可逆扰动,目标不再是简单的 PC-relative,工具更容易算不动
- index 选择:
CSEL W11, ...
- page table 读取:
LDR W12, [X25, W11, UXTW#2]
- 变换链:
REV/EOR/NEG/ROR/EON/...
- objects table 读取:
LDR X11, [X24, W11, SXTW#3]
- 最终跳转:
BR X11
LDR W12, [X25,W11,UXTW#2]:从 dword page_table 读取中间值... REV/EOR/NEG/ROR ...:对 index 做可逆扰动(来自 maskCipher / buildPageTableDecryptIR)LDR X11, [X24,W11,SXTW#3]:从 qword objects 取出真正目标地址(块地址)BR X11:完成间接跳转
X25:通常来自 ADRP/ADRL 指向一段连续的 dword 数组(page table)
- 在片段里:
ADRL X25, unk_11E80(页表基址)
X24:通常来自 ADR/ADRL 指向一段连续的 qword 指针数组(objects table)
- 在片段里:
ADR X24, off_11CF0(对象表基址)
- 在片段里:
ADRL X25, unk_11E80(页表基址)
- 在片段里:
ADR X24, off_11CF0(对象表基址)
MOV W19, #0xB4:W19 = 0xB4MOV W11, #0x30:W11 = 0x30UDIV X10, X11, X19:X10 = 0x30 / 0xB4 = 0MSUB X10, X10, X19, X11:X10 = X11 - (X10 * X19) = 0x30 - 0 = 0x30CMP X10, #0:比较 0x30 与 0,结果 不相等(Z=0)CSEL W11, W9, W8, EQ:
- 若
EQ(Z=1) 则取 W9=0x2C
- 否则取
W8=0x2E
- 因为本例
Z=0,所以 W11 = 0x2E
- 若
EQ(Z=1) 则取 W9=0x2C
- 否则取
W8=0x2E
- 因为本例
Z=0,所以 W11 = 0x2E
- 路径 A(EQ, Z=1):
W11 = 0x2C
- 路径 B(else, Z=0):
W11 = 0x2E
LDR W12, [X25, W11, UXTW#2]
UXTW#2 表示:把 W11 零扩展为 64 位后再乘 4- 也就是:
W12 = *(u32*)(X25 + (uint64)W11*4)
UXTW#2 表示:把 W11 零扩展为 64 位后再乘 4- 也就是:
W12 = *(u32*)(X25 + (uint64)W11*4)
X25 = &unk_11E80W11 = 0x2E- 读的是:
W12 = *(u32*)(unk_11E80 + 0x2E*4) = *(u32*)(unk_11E80 + 0xB8)
t0_eq = *(u32*)(unk_11E80 + 0x2C*4) = *(u32*)(unk_11E80 + 0xB0) = *(u32*)(0x11F30)
t0_eq = 0x26470047- little-endian 字节:
47 00 47 26
ADD W13, W23, W11
W13 = W23 + W11 = 0x95E0D26D + 0x2E = 0x95E0D29B
SUB W11, W11, W23
W11 = 0x2E - 0x95E0D26D = 0x6A1F2DC1(32-bit 回绕)
W13 = W23 + W11 = 0x95E0D26D + 0x2E = 0x95E0D29B
W11 = 0x2E - 0x95E0D26D = 0x6A1F2DC1(32-bit 回绕)
REV W12, W12
EOR W12, W12, W23
W12 = REV32(t0) ^ 0x95E0D26D
NEG W12, W12
REV W12, W12
ROR W12, W12, W13
- 旋转位数取低 5 bit:
sh1 = W13 & 31 = 0x95E0D29B & 31 = 0x1B
W12 = ROR32(W12, sh1)
ROR W11, W12, W11
- 旋转位数取低 5 bit:
sh2 = W11 & 31 = 0x6A1F2DC1 & 31 = 0x01
W11 = ROR32(W12, sh2)
EON W11, W11, W23
EON 语义:dst = src1 XOR NOT(src2)W11 = W11 ^ (~0x95E0D26D)(得到最终 index,32-bit)
W12 = REV32(t0) ^ 0x95E0D26D
- 旋转位数取低 5 bit:
sh1 = W13 & 31 = 0x95E0D29B & 31 = 0x1B
W12 = ROR32(W12, sh1)
- 旋转位数取低 5 bit:
sh2 = W11 & 31 = 0x6A1F2DC1 & 31 = 0x01
W11 = ROR32(W12, sh2)
EON 语义:dst = src1 XOR NOT(src2)W11 = W11 ^ (~0x95E0D26D)(得到最终 index,32-bit)
W23 = 0x95E0D26Dsh1 = (W23 + 0x2E) & 31 = 0x1Bsh2 = (0x2E - W23) & 31 = 0x01
t0 = t0_eq = 0x26470047sh1 = (W23 + 0x2C) & 31sh2 = (0x2C - W23) & 31
LDR X11, [X24, W11, SXTW#3]
SXTW#3 表示:把 W11 视为 有符号 32-bit,符号扩展到 64-bit 后再乘 8- 等价于:
X11 = *(u64*)(X24 + (int64)(int32)W11 * 8)
SXTW#3 表示:把 W11 视为 有符号 32-bit,符号扩展到 64-bit 后再乘 8- 等价于:
X11 = *(u64*)(X24 + (int64)(int32)W11 * 8)
target = *(u64*)(off_11CF0 + (int64)(int32)idx_final * 8)
target_else = *(u64*)(off_11CF0 + 9*8) = *(u64*)(off_11CF0 + 0x48)
off_11CF0 + 0x48 = 0x11D38 → DCQ loc_3C34
所以 路径 B 的 BR X11 最终跳转目标就是 0x3C34
路径 A(EQ)我们已经算出 idx_final_eq=39。对应的表项偏移是:
39*8 = 0x138
off_11CF0 + 0x138 = 0x11E28 → DCQ loc_3C40
- 误判很多:AArch64 里正常的
BR/BLR 也很多(虚表、函数指针、switch 跳表、异常处理……),只看 BR 分不清它是不是 indbr 的产物。
- 信息不够:
BR X11 本身只告诉你“跳到 X11”,并不告诉你 X11 是怎么来的;而 indbr 的关键恰恰在于“它是通过 page_table + objects 计算出来的”。
- objects 表取目标(qword):
LDR Xdst, [Xobj, W/X idx, (SXTW|UXTW|LSL)#3]
- page 表取中间值(dword):
LDR Wt, [Xtbl, W/X idx, (SXTW|UXTW|LSL)#2]
- 这说明
idx 来自一个“dword 数组”,并且后面会配合 REV/ROR/EOR/NEG/... 之类的变换链
- 这说明
idx 来自一个“dword 数组”,并且后面会配合 REV/ROR/EOR/NEG/... 之类的变换链
- 先用
BR 抓到“候选落点”(召回高)
- 再用 objects/page 两个表的回溯把“候选”收敛成 indbr
sel:可选的 CSEL/CSINC(定义 index 的 select 点,若能找到)page_ldr:page 表读取地址(LDR Wt, [Xtbl, ...])obj_ldr:objects 表读取地址(LDR Xn, [Xobj, ...])br:最终 BR Xn 地址
- 把
X0~X7(以及关心的参数寄存器)先按需要塞进去(不塞也行,默认 0)
- 最关键的是 把
objects/page_table 的基址寄存器直接 seed 成表地址
- 否则很可能跑不到正确的
LDR [Xobj, ...] / LDR [Xtbl, ...]
- 模拟范围尽量小:一般直接从
BR 所在 basic block 的起点跑到 BR 就够了
- 跑到
BR 前停下,读 site.br_reg(也就是 BR Xn 的 Xn)就是 target
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-1-14 18:46
被王麻子本人编辑
,原因: 补个码



 怎么有时间写帖子了
怎么有时间写帖子了





