通过此前的文章,我们已经掌握了两大框架。在逆向工程的工具链中,它们各司其职:
Unicorn (大脑) :负责跑代码。它模拟 CPU 的状态流转与内存交互。
[原创]深入浅出 Unicorn 框架学习
Capstone (眼睛) :负责看代码。它将枯燥的机器码翻译成人类可读的汇编语言。
[原创]深入浅出 Capstone 框架学习
然而,仅有“大脑”和“眼睛”是不够的。当我们想要修改程序的逻辑(例如 Patch 掉反调试检查、注入 Shellcode)时,我们需要——Keystone (双手) 。
Keystone 是一个轻量级、多平台、多架构的汇编框架。它的作用与 Capstone 正好相反:Capstone 将机器码转为汇编,而 Keystone 将汇编代码编译回机器码。
在 Python 脚本中,我们主要使用以下两个类:
Ks (Keystone Engine)
这是汇编引擎的主入口。你需要实例化它来创建一个汇编器对象。
KsError (Exception)
异常处理类。当你的汇编代码有语法错误(如拼写错误、操作数不匹配)时,Keystone 会抛出此异常。
Keystone 的常量命名规范与 Unicorn/Capstone 保持高度一致,只需将前缀 UC_ 或 CS_ 换成 KS_ 即可。
常用组合对照表:
对于 x86 架构,汇编语言有不同的格式。Keystone 允许通过 KS_OPT_SYNTAX 选项来切换语法风格。
KS_OPT_SYNTAX_INTEL (默认):Intel 语法。
KS_OPT_SYNTAX_ATT:AT&T 语法。
KS_OPT_SYNTAX_NASM:NASM 语法。
设置方法:
在将 Keystone 集成到 Unicorn 之前,我们先单独运行它,体验一下如何将一句汇编代码翻译成机器码。
目标
将汇编指令 "xor rax, rax; inc rax" 编译为 x64 机器码。
示例代码:
运行结果:
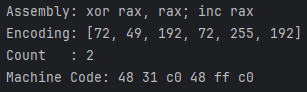
ks.asm() 方法的返回值是一个元组 (encoding, count) :
encoding (list[int]) :
count (int) :
需求:
在逆向分析中,我们经常遇到反调试指令(如 RDTSC、CPUID)或者不需要执行的垃圾代码。
假设在地址 0x400000 处有一条复杂的指令(例如 XOR EAX, EAX,长度 2 字节),我们希望将其“抹去”,替换为 NOP(空指令),让 CPU 什么都不做直接滑过去。
示例代码:
运行结果:
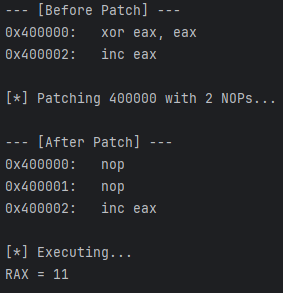
需求:
在破解 CrackMe 或去除混淆时,我们经常遇到关键的分支跳转,例如 TEST EAX, EAX; JZ 0xTarget。如果验证失败,程序会跳转到错误处理分支。
我们的目标是:强制将 JZ(条件跳转)修改为 JMP(无条件跳转),确保程序始终走向我们预期的路径,从而绕过校验。
核心挑战 (JIT 陷阱) :
Unicorn 使用 JIT(即时编译)技术。如果在 UC_HOOK_CODE 回调中动态修改当前指令的内存,CPU 实际上已经完成了该指令的取指和解码,Patch 仅对下一次执行有效。
因此,对于确定的逻辑修改,最佳实践是在模拟启动前 (Pre-Patch) 就完成内存修改。
示例代码:
运行结果:
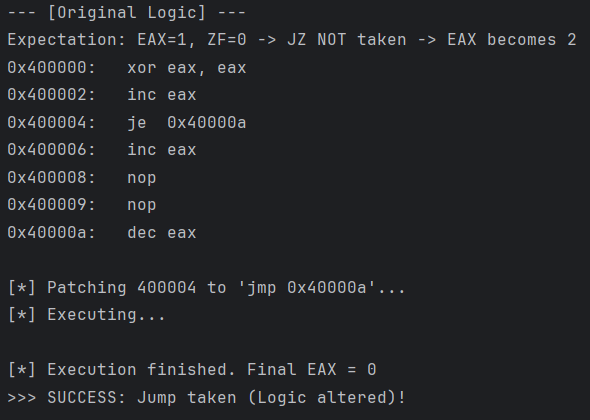
通过这种方式,我们成功地利用 Keystone 改变了程序的控制流,让它按照我们的意愿执行了跳转逻辑。
需求:
有时我们需要在程序的空白区域(Cave)注入一段全新的逻辑,比如打印调试信息、Dump 内存数据等。
我们需要在内存 0x500000 处写入一段 Shellcode,调用 Linux 的 write 系统调用打印 "HACKED",然后控制 CPU 跳转执行。
示例代码:
运行结果:
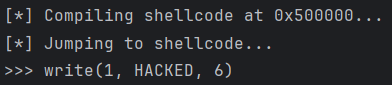
通过 Keystone,我们无需手动拼凑机器码,直接用汇编语言就实现了复杂的代码注入功能。
在基础用法之外,Keystone 还提供了一些高级特性来应对特定的编译需求,比如切换汇编风格、处理相对地址计算以及解析符号标签。
对于 x86 架构,汇编语言存在多种格式。Keystone 默认使用逆向工程中最通用的 Intel 语法,但也完美支持 Linux/GDB 风格的 AT&T 语法 以及更严格的 NASM 语法。
支持的语法常量:
KS_OPT_SYNTAX_INTEL (默认):Intel 语法。
KS_OPT_SYNTAX_ATT:AT&T 语法。
KS_OPT_SYNTAX_NASM:NASM 语法。
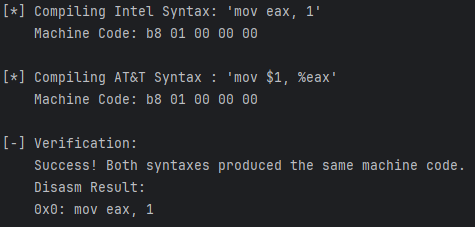
下面的代码展示了如何切换语法,并验证两种写法的编译结果是否一致。
运行结果:
在编写汇编代码时,使用标签(Label)跳转是人类的本能,例如 jmp loop_start。然而,Keystone 是一个轻量级编译器,在 Python 绑定中默认并不支持复杂的符号解析回调(Symbol Resolver Callback)。
Pythonic 解决方案:利用 Python 强大的字符串格式化功能(f-string),在将代码送入 Keystone 编译之前,手动完成符号的“链接”工作。
示例:
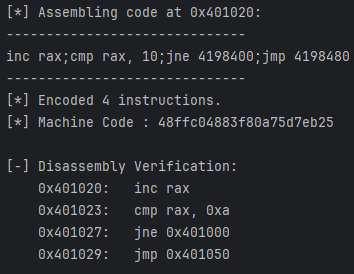
假设我们需要在地址 0x401020 处编写一段逻辑,其中包含跳转到 0x401000 和 0x401050 的指令。
运行结果:
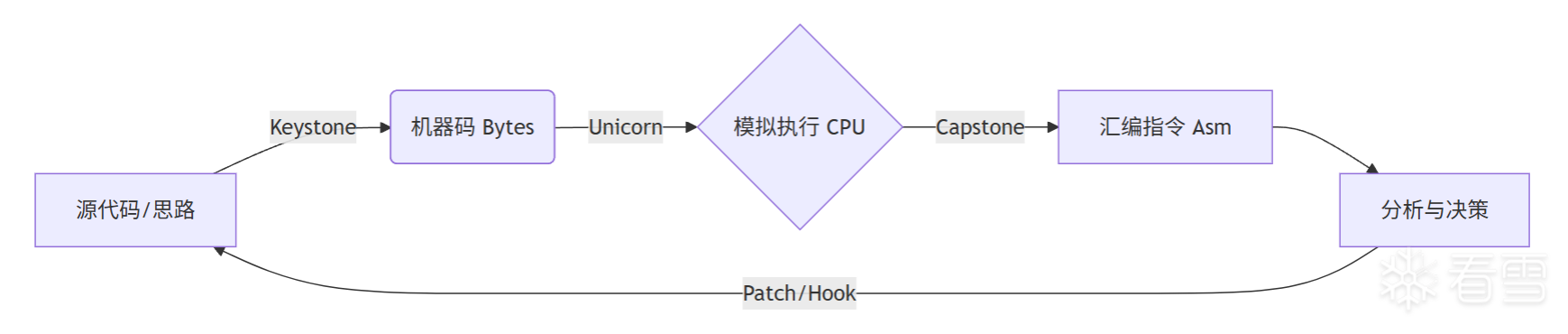
至此,我们已经学完了二进制分析与逆向工程的“三剑客”。
这三个框架各司其职,共同构成了一个完整的操控闭环:
协作流程图:
pip install keystone-engine
pip install keystone-engine
| 目标环境 |
Unicorn |
Capstone |
Keystone |
| x86 (32位) |
UC_ARCH_X86,UC_MODE_32 |
CS_ARCH_X86,CS_MODE_32 |
KS_ARCH_X86 ,KS_MODE_32 |
| x64 (64位) |
UC_ARCH_X86,UC_MODE_64 |
CS_ARCH_X86,CS_MODE_64 |
KS_ARCH_X86 ,KS_MODE_64 |
| ARM (32位) |
UC_ARCH_ARM,UC_MODE_ARM |
CS_ARCH_ARM,CS_MODE_ARM |
KS_ARCH_ARM ,KS_MODE_ARM |
| ARM Thumb |
UC_ARCH_ARM,UC_MODE_THUMB |
CS_ARCH_ARM,CS_MODE_THUMB |
KS_ARCH_ARM ,KS_MODE_THUMB |
ks = Ks(KS_ARCH_X86, KS_MODE_64)
ks.syntax = KS_OPT_SYNTAX_ATT
ks = Ks(KS_ARCH_X86, KS_MODE_64)
ks.syntax = KS_OPT_SYNTAX_ATT
from keystone import *
ASSEMBLY = "xor rax, rax; inc rax"
try:
ks = Ks(KS_ARCH_X86, KS_MODE_64)
encoding, count = ks.asm(ASSEMBLY)
print(f"Assembly: {ASSEMBLY}")
print(f"Encoding: {encoding}")
print(f"Count : {count}")
machine_code = bytes(encoding)
print("Machine Code: ",end="")
for i in range(len(machine_code)):
print(f"{machine_code[i]:02x}", end=" ")
print()
except KsError as e:
print(f"ERROR: {e}")
from keystone import *
ASSEMBLY = "xor rax, rax; inc rax"
try:
ks = Ks(KS_ARCH_X86, KS_MODE_64)
encoding, count = ks.asm(ASSEMBLY)
print(f"Assembly: {ASSEMBLY}")
print(f"Encoding: {encoding}")
print(f"Count : {count}")
machine_code = bytes(encoding)
print("Machine Code: ",end="")
for i in range(len(machine_code)):
print(f"{machine_code[i]:02x}", end=" ")
print()
except KsError as e:
print(f"ERROR: {e}")
from unicorn import *
from unicorn.x86_const import *
from keystone import *
from capstone import *
mu = Uc(UC_ARCH_X86, UC_MODE_64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
cs = Cs(CS_ARCH_X86, CS_MODE_64)
ADDRESS = 0x400000
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ADDRESS, MEM_SIZE)
ORIGINAL_CODE = b"\x31\xc0\xff\xc0"
mu.mem_write(ADDRESS, ORIGINAL_CODE)
print("--- [Before Patch] ---")
for insn in cs.disasm(mu.mem_read(ADDRESS, 4), ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
TARGET_ADDR = 0x400000
PATCH_LEN = 2
print(f"\n[*] Patching {TARGET_ADDR:x} with {PATCH_LEN} NOPs...")
encoding, _ = ks.asm("nop; " * PATCH_LEN)
mu.mem_write(TARGET_ADDR, bytes(encoding))
print("\n--- [After Patch] ---")
patched_code = mu.mem_read(ADDRESS, 4)
for insn in cs.disasm(patched_code, ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
print("\n[*] Executing...")
mu.reg_write(UC_X86_REG_RAX, 10)
mu.emu_start(ADDRESS, ADDRESS + 4)
print(f"RAX = {mu.reg_read(UC_X86_REG_RAX)}")
from unicorn import *
from unicorn.x86_const import *
from keystone import *
from capstone import *
mu = Uc(UC_ARCH_X86, UC_MODE_64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
cs = Cs(CS_ARCH_X86, CS_MODE_64)
ADDRESS = 0x400000
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ADDRESS, MEM_SIZE)
ORIGINAL_CODE = b"\x31\xc0\xff\xc0"
mu.mem_write(ADDRESS, ORIGINAL_CODE)
print("--- [Before Patch] ---")
for insn in cs.disasm(mu.mem_read(ADDRESS, 4), ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
TARGET_ADDR = 0x400000
PATCH_LEN = 2
print(f"\n[*] Patching {TARGET_ADDR:x} with {PATCH_LEN} NOPs...")
encoding, _ = ks.asm("nop; " * PATCH_LEN)
mu.mem_write(TARGET_ADDR, bytes(encoding))
print("\n--- [After Patch] ---")
patched_code = mu.mem_read(ADDRESS, 4)
for insn in cs.disasm(patched_code, ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
print("\n[*] Executing...")
mu.reg_write(UC_X86_REG_RAX, 10)
mu.emu_start(ADDRESS, ADDRESS + 4)
print(f"RAX = {mu.reg_read(UC_X86_REG_RAX)}")
from unicorn import *
from unicorn.x86_const import *
from keystone import *
from capstone import *
mu = Uc(UC_ARCH_X86, UC_MODE_64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
cs = Cs(CS_ARCH_X86, CS_MODE_64)
ADDRESS = 0x400000
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ADDRESS, MEM_SIZE)
CODE_ASM =
code_bytes, _ = ks.asm(CODE_ASM, ADDRESS)
mu.mem_write(ADDRESS, bytes(code_bytes))
print("--- [Original Logic] ---")
print("Expectation: EAX=1, ZF=0 -> JZ NOT taken -> EAX becomes 2")
for insn in cs.disasm(bytes(code_bytes), ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
KEY_JUMP_ADDR = 0x400004
PATCH_ASM = "jmp 0x40000a"
print(f"\n[*] Patching {KEY_JUMP_ADDR:x} to '{PATCH_ASM}'...")
patch_code, _ = ks.asm(PATCH_ASM, KEY_JUMP_ADDR)
mu.mem_write(KEY_JUMP_ADDR, bytes(patch_code))
print("[*] Executing...")
try:
mu.emu_start(ADDRESS, ADDRESS + len(code_bytes))
except UcError as e:
print(e)
final_eax = mu.reg_read(UC_X86_REG_EAX)
print(f"\n[*] Execution finished. Final EAX = {final_eax}")
if final_eax == 0:
print(">>> SUCCESS: Jump taken (Logic altered)!")
else:
print(">>> FAILED: Jump not taken.")
from unicorn import *
from unicorn.x86_const import *
from keystone import *
from capstone import *
mu = Uc(UC_ARCH_X86, UC_MODE_64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
cs = Cs(CS_ARCH_X86, CS_MODE_64)
ADDRESS = 0x400000
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ADDRESS, MEM_SIZE)
CODE_ASM =
code_bytes, _ = ks.asm(CODE_ASM, ADDRESS)
mu.mem_write(ADDRESS, bytes(code_bytes))
print("--- [Original Logic] ---")
print("Expectation: EAX=1, ZF=0 -> JZ NOT taken -> EAX becomes 2")
for insn in cs.disasm(bytes(code_bytes), ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
KEY_JUMP_ADDR = 0x400004
PATCH_ASM = "jmp 0x40000a"
print(f"\n[*] Patching {KEY_JUMP_ADDR:x} to '{PATCH_ASM}'...")
patch_code, _ = ks.asm(PATCH_ASM, KEY_JUMP_ADDR)
mu.mem_write(KEY_JUMP_ADDR, bytes(patch_code))
print("[*] Executing...")
try:
mu.emu_start(ADDRESS, ADDRESS + len(code_bytes))
except UcError as e:
print(e)
final_eax = mu.reg_read(UC_X86_REG_EAX)
print(f"\n[*] Execution finished. Final EAX = {final_eax}")
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。






