间接跳转这个高级混淆,接触了unicorn,unidbg这种模拟执行脚本后,发现这种特别适合对抗反编译器无法分辨的一些混淆,本文记录学习过程以及以京麒2024的drillbeam为样本尝试去去除间接跳转。笔者的脚本能力确实有限,写的不好的地方大佬们勿喷(
如上的样本就是经典的间接跳转混淆,这种jmp eax,可以让反编译工具无法计算跳转的地址,导致反编译出错,这种混淆手段在vmp中也有体现,我们分别看看这个在ida和bn的效果
ida:
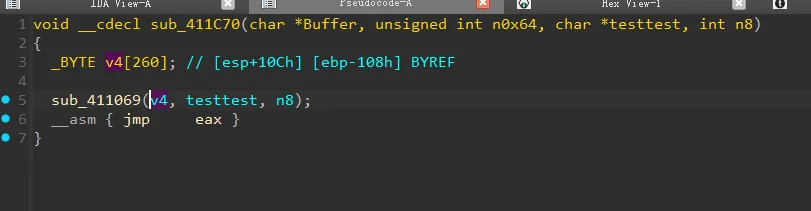
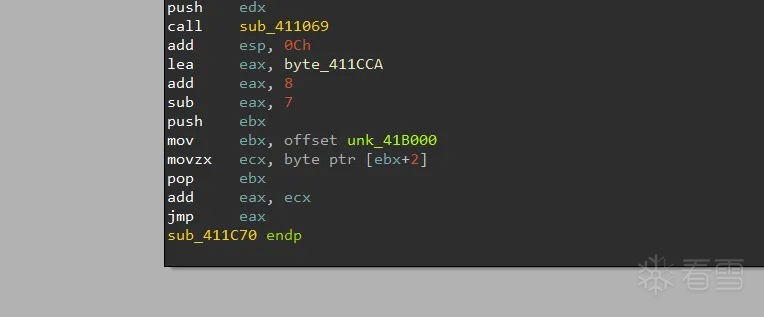
直接导致cfg丢失
bn:
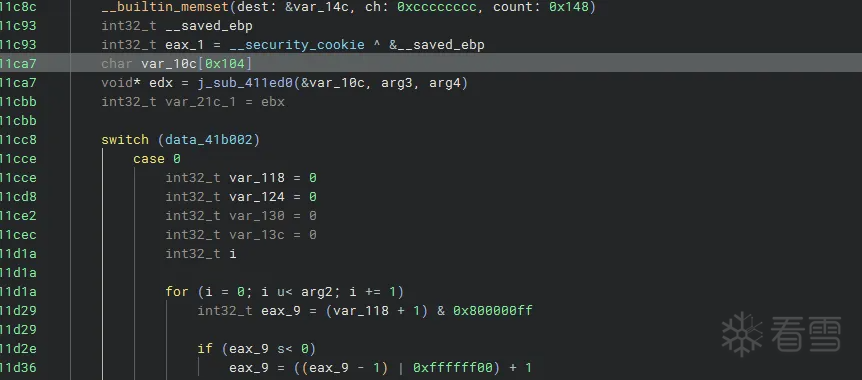
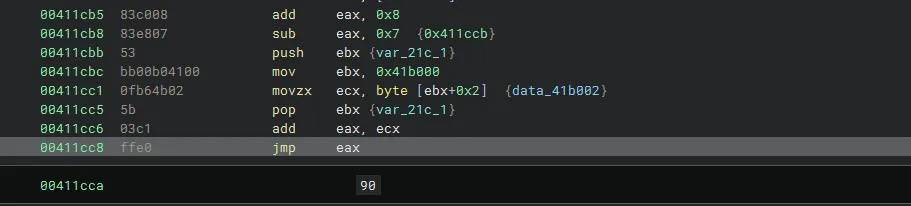
bn虽然能分析个大概,不过好像仍然有问题,这里粗暴的把查表的操作分析成了switch
不过有办法
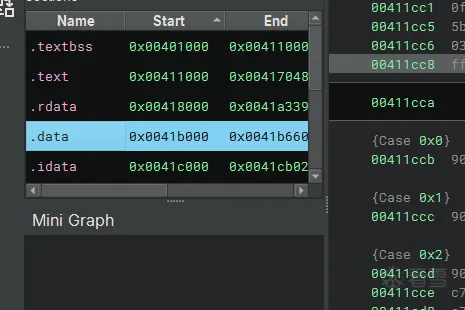
把data段改成只读
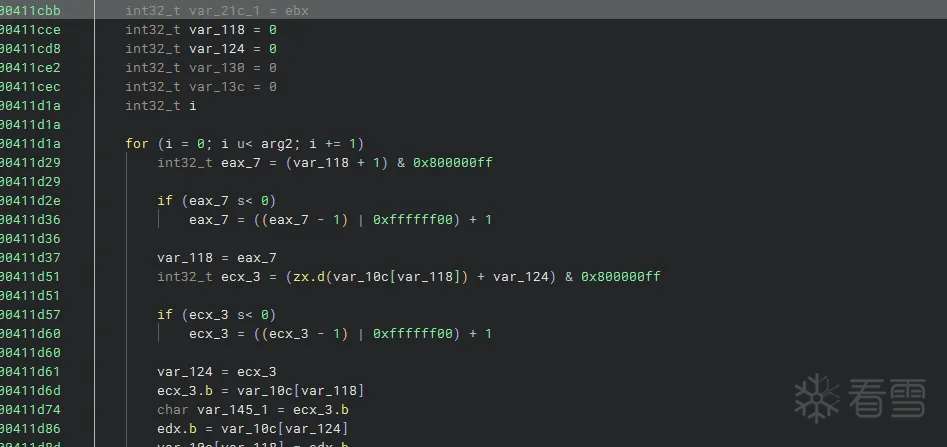
就可以正常分析了,因为计算地址存储在了data段(比如我这里的查表),反编译器不会去解析data段的数据,因为data段默认可写,导致被引用都的值被看作的是变量而非常量,阻止了常量传播,设置为可读的话,bn会去把data段看成常量,这也的话动态分析就可能解析出跳转的地址,但是这种方法并不高枕无忧,还是会存在问题
对于一般的ctf题的话,可能就只会存在一两种间接跳转的计算方式,这个时候我们就可以手动计算出然后写脚本简单去除就行,但是我们把情况放极端一点,如果一个程序充斥着几千种不重样的间接跳转,或者说ollvm里面还嵌套了间接跳转的话,挨个计算然后去除岂不是效率低
回到手动计算,总之就是计算,有没有自动化工具计算然后识别,然后去除,这不就满足了我们手动计算->ida脚本去除的完整过程了吗
这种一般就是模拟执行的过程,模拟执行的框架一般有unicorn unidbg qiling angr等等,我写unidbg要稍微多一点
这几种可以说是都在unicorn基础上成立的,为了更加理解这种去除思路,故用unicorn写一下,而且unicorn更适合跑指令

可以很好的模拟出结果
可是unicorn是纯裸的CPU,意味着我们如果暴力的把整个exe直接载入CPU的内存里,一般是运行不起来的,还需要对一些系统函数进行重定位的操作
我们先假设只有一个间接跳转,先试着模拟一下
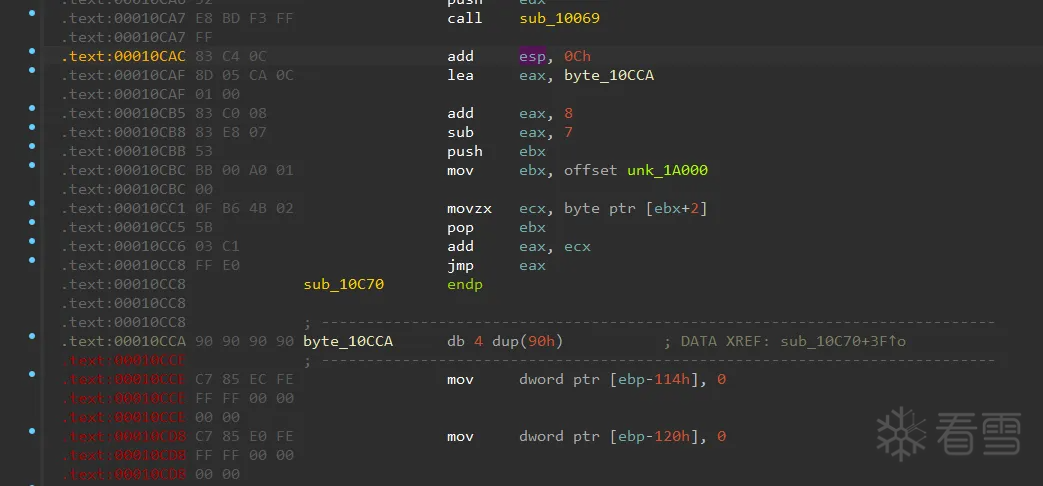
对于这种只有一个的话,我们的模拟手段就很简单的,因为我们已经找到了间接跳转的位置,所以自然可以找到需要模拟开始的地址以及结束地址,但是,这一路也不能直接裸调用,因为可以看到这里的查表操作是涉及到了读取数据段的东西了,我选择的是直接载入整个exe,然后单个开机模拟执行一段即可
模拟PE的话,跟我在模拟ELF是不一样的,ELF我模拟的时候,基地址设置0,然后模拟区间和ida看到的偏移一样即可,但是PE文件不一样,因为PE的RAW和RVA是按照节表换算的
这里是把栈映射进去,把这个映射进去也是模拟栈帧创建,局部变量等等,这里减少4是为了防止栈崩掉
方便我们看到是哪条指令崩掉了,快速查找或者看值
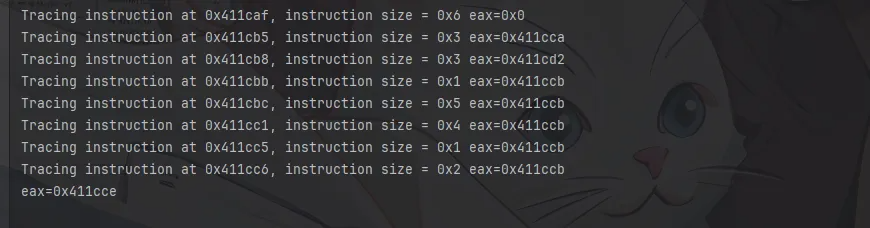
这样可以看到已经完成了模拟
现在我们可以加一点东西了,首先,需要知道何时去patch,这里我们可以用到反汇编引擎,去识别到jmp eax,然后直接改成jmp xxxx
这里涉及到了keystone和capstone,感觉只要是模拟执行都绕不过这两个东西
上面就是简单的修改,不过这种修改有个bug感觉,就是修改后的指令大小有一点怕覆盖下面如果有用的指令(当然这里不成立,因为下面四个字节都没用)
这里修好了,那如何去patch回文件呢
这里可以选择直接把unicorn的内存直接修改后复制到新文件
我们选择去把unicorn内存修改然后试着覆盖回程序
但是为了防止覆盖后面的指令,所以我们先设置一个可写区域
0x11CAF-0x11CC8其实都是可以随便修改的(根据间接跳转而不同)
对比一下
去除前
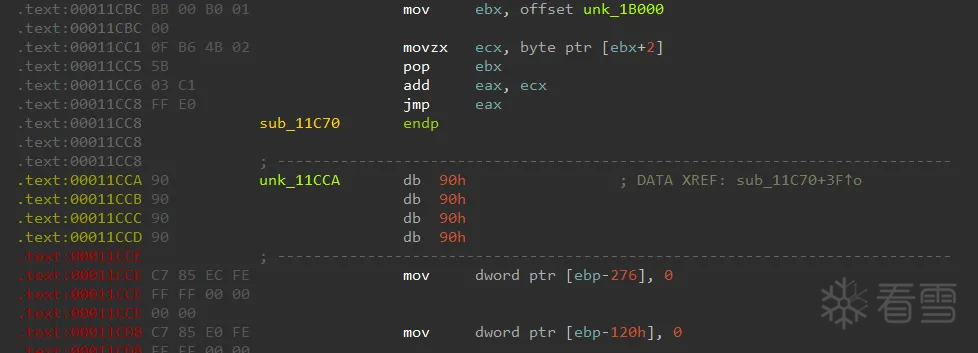
去除后
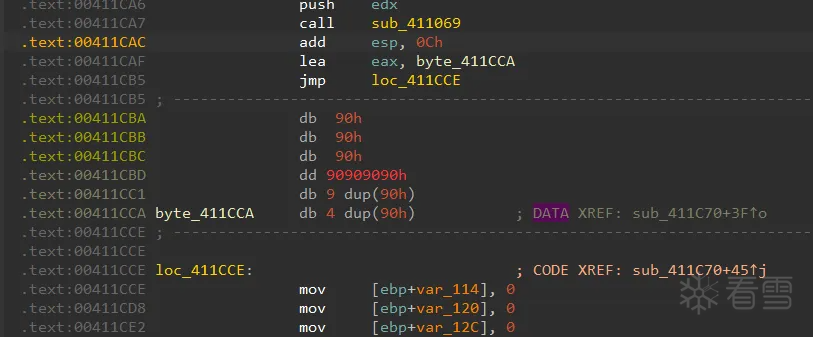
缺陷:以上只是简单的单个模拟,目的只是学习,缺陷也十分明显
第一是eax寄存器是固定的情况,当然可能会出现jmp ecx这种,如果为了更全面的考虑可以把所有通用寄存器都加入进去
第二是如果间接跳转存在条件判断的问题,例如arm的 CSEL和BR模式的话,也无能为力了
第三是回溯修改的区间被我固定了,如果遇到大小不一致的话,也很难去去除
这个题是间接跳转+ollvm混淆,导致解题难度比较大,赛中尝试的是去用trace到每一个函数,然后挨个看,找到了xxtea加密,结合d810去混淆勉强能看,不过init_array也有间接跳转,而且是存在修改delta的操作的
这里我看了一个师傅的unidbg脚本去间接跳转和去平坦化
https://bbs.kanxue.com/thread-277086.htm
学习一下并且尝试为这个题写一下
注:这里只讨论如何去除间接跳转,不讨论做这个题的过程
(含有检测模拟器的操作)

可以看到间接跳转数量多,而且是这种存在条件判断的,不能简单的去除,如果只是patch,cfg不会被修复
我们试一下unidbg而不是unicorn因为unidbg在模拟安卓层面可以让我们少走一些弯路
像unidbg这种模拟执行框架,属于是比较成熟的了,可以帮我们完成so的加载和解析
这里就是一些初始化的操作了,加载了模拟器,内存管理模块以及要调用的so模块,如果这里我们需要补充其他的so的加载,也只需要去加载一下就行了
注意把代码放在loadlibrary之前
这种trace手段的话,是有寄存器信息的,这里的setRedirect是设置重定向,把输出结果从默认的控制台保存到文本文件里面。
配合前面的init_array就可以成功调试init_array函数
这一类的间接跳转感觉都比较相似
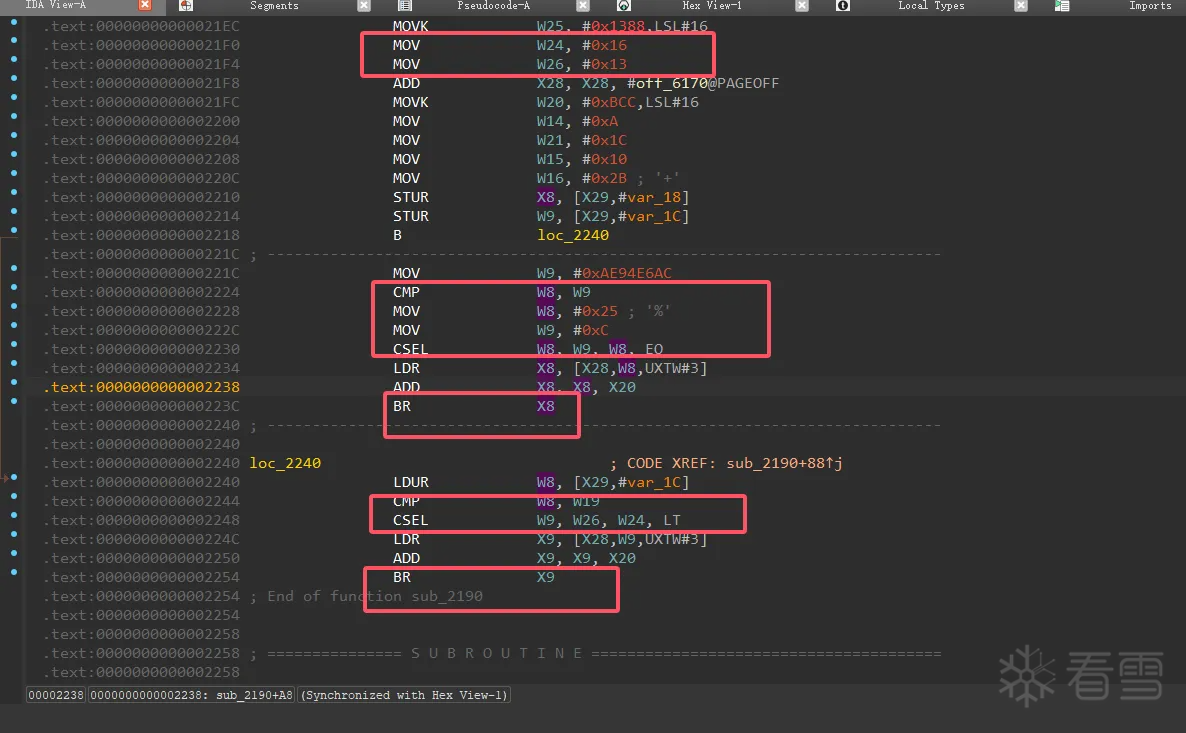
都是CMP CSEL的形式或者有
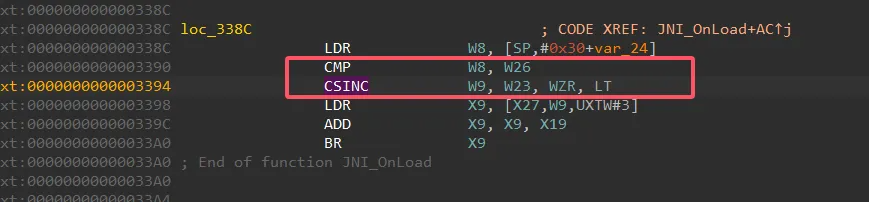
不过都是 比较,然后根据比较的结果选取值作为偏移,然后去查表加基址常量,然后br跳转
这种条件是不固定的话,我们就需要去计算不同情况下的跳转情况
我们发现程序的间接跳转可以说有很多种,比如cmp到br之间有CSEL LT 和CSEL EQ CSINC NE
以及cmp和br中间还有有用的逻辑,但凡多patch一点,就会导致程序进入死循环,作者应该是采用了LLVM的间接跳转去替换掉了一些条件跳转,所以去除难道比较大,而且兼容必须要好才行,因为cmp到br之间的长度也不固定,计算方式不一样
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2025-11-30 13:38
被zzzhangyu编辑
,原因: