前一阵子去京东沙龙上做了一次 升级的猫鼠游戏:AI时代的移动攻与防的讲座,讲的主要内容就是在ai的时代,如何进行高效的安全开发和逆向工程。
主要核心就是,ai提高了每个人的效率,逆向工作者提高了自己逆向的效率,与此同时,安全开发者提高了自己开发的效率,攻防的本质不变,但是作为相关的工作者,我们要提高自己的核心能力,才能在这升级的对抗里稳住脚跟。
今天分享的是ai在逆向中的几个应用,和应用具体的操作办法。
并且分享如何获取到一些比较好用的ai资源,对一些模型的一些评测。


经验类知识我定义的就是 你从0到1逆向了一个完整的一个过程记录,在哪些地方遇到了哪些卡住的,如何去解决的
这一部分当然可以不出自于自己,论坛上有大把的教程,我的历史帖子你也可以作为输入
什么时候去使用?当你逆向一个新的app,你把目前的进度输入进去,可能遇到意外的惊喜。
可能遇到的问题就是,知识过多无法索引的问题,但是随着大模型的发展,cursor等工具都可以索引到了40-50w行,所以这个不是特别大的问题,尤其是augment的mcp索引引擎
能够索引几百万行
比如imyang大佬开源的多个脚本资源
我们可以给他clone下来,整理到一个文件夹,索引使用。
还有我们日常中写的一些功能性脚本,或者我们报了培训里面的课件,都可以作为整理输入。
有了这些索引输入,生成的脚本可以一键使用,没有幻觉。
别看他是一个代码工具,索引的效果非常好,也可以一键生成脚本。
415K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6D9j5h3u0J5K9h3&6Y4i4K6u0r3c8X3q4K6N6p5N6b7g2l9`.`.
具体搭建教程可以看他的readme 可以搭配线上的索引模型和问答模型,也可以自己本地部署,可以做成一个问答bot形式
知识库无非就是,一群markdown,使用输入一定语言,使用索引模型进行索引,然后把结果喂给问答模型,我们完全可以自建。
可以给大家一个教程作为搭配 9e5K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6*7K9s2g2S2L8X3I4S2L8W2)9J5k6i4A6Z5K9h3S2#2i4K6u0W2j5$3!0E0i4K6u0r3M7q4)9J5c8U0t1%4z5e0b7%4y4K6R3J5x3K6V1J5
假如我们觉得本地的索引模型难度比较高怎么办,那么就借用现成的。
e7fK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6&6k6i4g2^5N6h3q4F1i4K6u0r3b7h3y4W2i4K6u0V1e0h3y4H3i4K6u0V1e0X3!0V1k6b7`.`.
这个是逆向了augmentcode的索引,我们可以直接使用mcp协议调用索引引擎,是不是很酷,全世界最厉害的索引引擎给你助力。
如果后续大家有需求,我可以
自从MCP出来已经很久了,大家可能在平时用的不是特别多,在今年五月的时候,我做了一篇 https://bbs.kanxue.com/thread-286813.htm MCP的环境配置,其实里面讲的大部分都是偏基础的,随着发展,大部分mcp已经可以自己去识别你的电脑已经安装的工具,并且自动去配置。
但是我认为大家还是有必要懂的python环境的配置的,如果你想要开发一个你自己的MCP,这里是必不可少的一环。
我理解的MCP的概念: MCP就是自动向你的对话中自动添加上下文的工具,ai主动获取上下文的工具
比如你在索引你的知识库的时候,你使用了Ace-Mcp-Node,他会主动去索引好知识,输入回大模型
或者你在逆向so的时候,你使用了ida-pro-mcp,他会自动获取你要分析的函数的整个伪代码,输入回大模型,保持连贯性
由于逆向领域比较冷门,ai并没有得到有效的训练(但是frida脚本我感觉表现还可以)
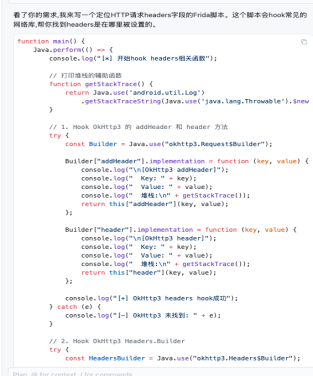
比如我们要解开java和native的混淆的时候,跑不掉要去写一些脚本,这时候困难就来了。
ai总是写一些不存在的api,自己胡编乱造,这不是智力问题,因为最新的Claude4.5opus也在乱写,这时候我们就需要一个有力的工具去帮他去开发了。
这里我推荐Context7这个MCP
178K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6U0L8$3&6@1k6i4S2@1y4#2)9J5k6h3y4G2L8g2)9J5c8Y4N6W2j5Y4y4A6N6r3g2K6i4K6u0r3j5i4m8A6i4K6g2X3j5X3W2F1j5i4u0&6i4K6g2X3L8X3W2F1K9X3p5`.
比如我们在写ninja的时候,就可以便捷配置了,具体配置教程可以参考我上面的ida-pro-mcp的教程,简单的更改即可
a45K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6E0L8$3c8W2L8r3y4G2L8Y4c8W2P5s2c8H3M7X3!0@1L8$3y4G2L8q4)9J5c8Y4y4W2M7Y4k6W2M7Y4y4Q4x3V1k6@1M7X3g2W2i4K6u0r3L8h3q4A6L8W2)9J5c8Y4y4J5j5#2)9J5c8Y4y4W2M7i4g2W2L8Y4c8A6j5h3I4@1K9r3W2F1K9$3W2F1k6H3`.`.
具体配置教程和上面一致
当你的ai思考深度不够,思考质量不足时候,他会命令ai多思考,以此获得更好的回答质量
jadx-gui
或者也可以使用jadx命令
然后导入cursor进行分析
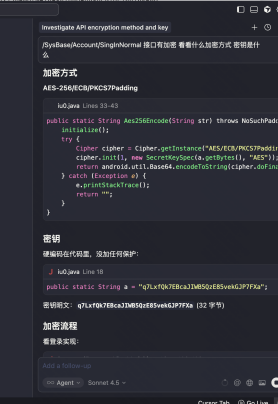
有著名的项目 jadx-mcp 可以参考之前的配置mcp的教程进行配置
146K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6*7K9h3&6B7j5g2)9J5k6r3y4G2k6r3g2J5i4K6u0r3K9X3q4V1P5q4)9J5k6r3q4A6i4K6u0V1L8h3y4H3
两者的区别是,jadx-ai-mcp可以使用交叉引用等功能,而作为文本导入cursor的代码就丧失了这个功能
但是cursor的速度快于mcp,所以推荐优先尝试cursor,然后转为配置jadx-ai-mcp
提出一个简单的小思路,以java的角度去分析,反编译后,使用java-parser 作为ast解析,写相关的反混淆的脚本,效率要比写jadx和jeb的脚本效率高很多
并且可以让ai自动去分析混淆的模式
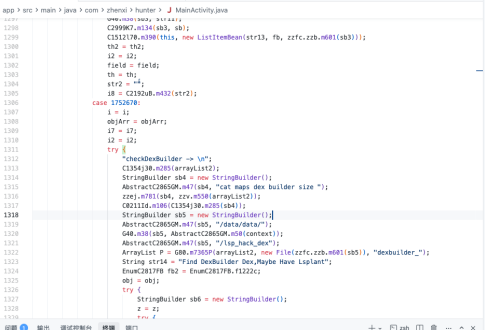
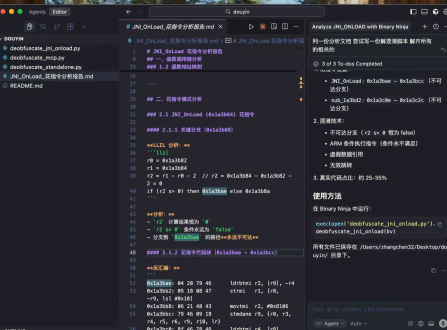
使用ida-pro-mcp 或者binary ninja mcp 看自己的习惯来使用
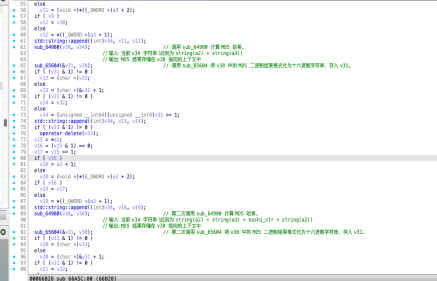
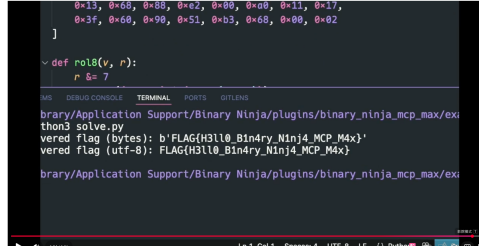
尽管你不懂花指令等概念,也可以让ai给你手把手教学,逐步去解决
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2026-3-14 11:26
被棕熊编辑
,原因: 修复图片









