这篇文章笔者自认为只能说是抛砖引玉,因为人工智能安全性实在是太新太前沿了。人工智能安全是复杂的,一方面,人工智能的对抗甚至说不上是一种攻击——文章中只是有一些错别字/图像中只是有一些噪点。很难说这些错别字是有什么“过错”的,错别字...只不过是错别字而已。它并不是传统意义上的“攻击”,因为它也并不会破坏什么。但是,如果被对抗的模型不是AI内容生成检测,而是AI文本内容安全模型呢?甚至,如果人工智能被用于电子商务、纠纷调解,这些“错别字”、“噪点”的危害就不可估量了。
最大的危险来自无知。现在的许多基于人工智能的应用并没有意识到潜在的安全性问题。所喜的是,人工智能安全性问题正在为越来越多的人了解,终有一天,安全的模型将携手引领更可信的未来。笔者也在此希望各位模型应用者与设计者可以缘此更加充分地意识到普通的模型的不可靠性,并加以防御或审计。笔者也计划于下篇文章中浅谈人工智能防御的一些方法。
本文中全部目标测试平台均不为境内平台,使用的全部数据均为主动公开且合法取得的数据;使用DeepSeek仅生成了一篇测试用的文章,并未对DeepSeek产生任何影响。出于安全性考量,完整代码与模型不会公开。作者呼吁大家正视、重视人工智能模型的不可靠性,共同建设安全的人工智能平台与产品。
其实我纠结了很久这篇文章要不要发,怎么发和发在哪里。自从2022冬天ChatGPT开始站在聚光灯下始,人工智能这个概念便深入人心。有构建的地方便有解构,这是颠覆不破的规律。既然看雪久负安全界盛名,那今日我遍献个丑,试为诸君解说一二罢。
人工智能安全目前在国内外应该都属于较为前沿的课题,但绝对不至于某些人认为的只停留在实验室阶段。事实上,人工智能攻防的实际应用就在你我身边。
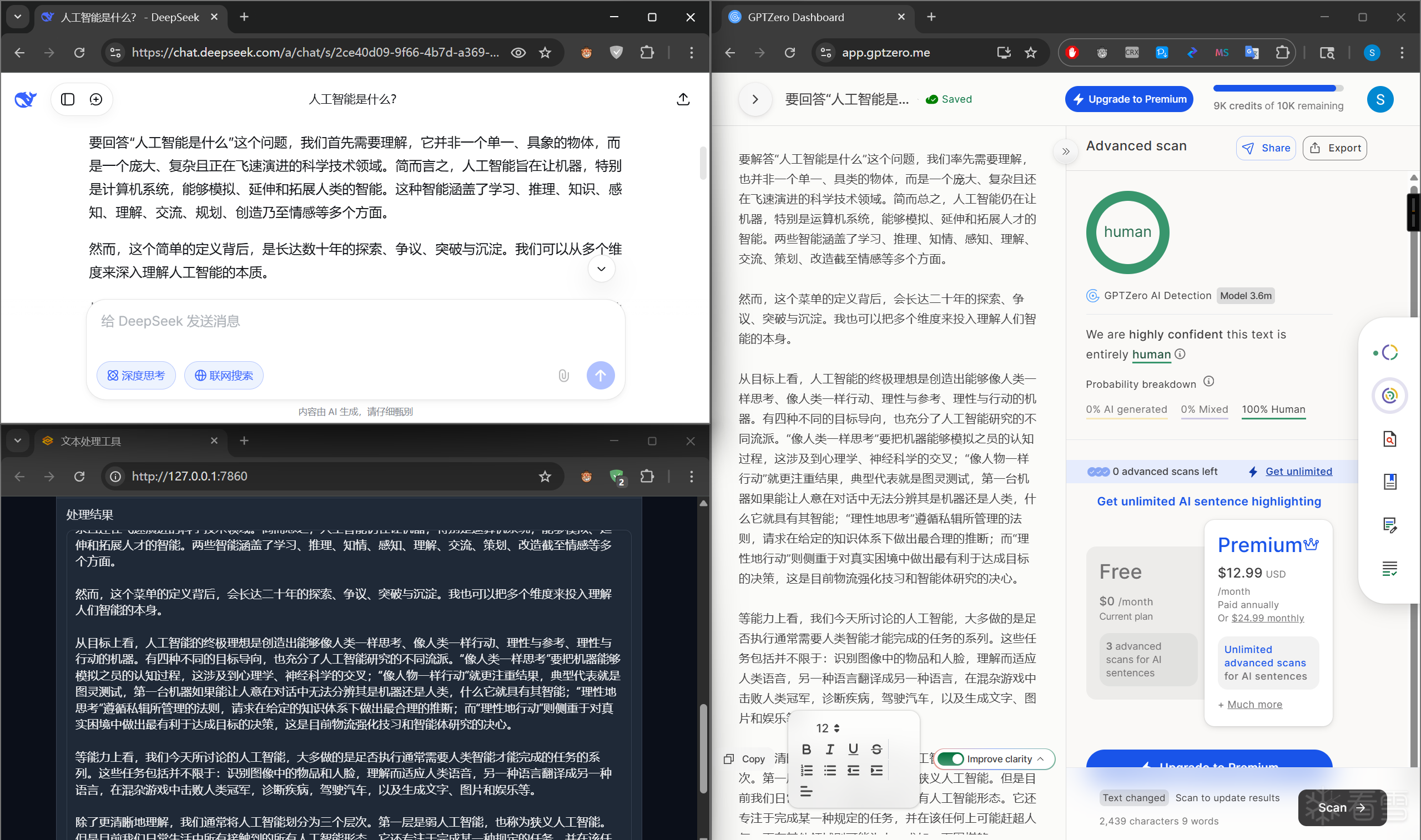
我们今天就以国外平台GPTZero为例,来拆解一二。
请有NLP基础的同学跳过这个章节。
所有的AI模型本质都是数学模型,它的输入是文字,但是,要让模型能处理语言,第一步就是把每一个字、每一个词,变成一串数字。显然的,一个数字不足以存取一个句子的信息,而高阶虚数对我们的脑子不友好,因此,我们会将输入转换为向量。这件事叫作词的向量化(或者更广义地说,token的向量化)。当然,输出也会转换为向量。
最朴素但事实上仍在使用的做法叫独热编码。假设汉字一共只有四个:天地玄黄
天 → [1, 0, 0, 0]
地 → [0, 1, 0, 0]
玄 → [0, 0, 1, 0]
黄 → [0, 0, 0, 1]
每一个词都变成一个极长的向量,向量长度等于整个词汇表大小,只有自己对应的那一维是 1,其他全是 0,我们便称为独热编码。事实上,直到今天我们都在用独热编码。有一些教科书喜欢表述为“我们使用嵌入取代了独热编码”,在我看来这是不正确的。
向量到向量的变换天然遍有两种:矩阵乘和逐元素操作。显然的,如果只使用矩阵乘,无论进行多少次操作,都只能产生输入的线性组合,或者说,线性回归。而逐元素操作往往只能保留原有信息的形状,无法表达跨维度的信息交互。因此,我们往往交替地使用矩阵乘和逐元素操作。事实上,只是交替地使用矩阵乘和逐元素操作便已经足以以任意精度拟合任意函数(证明见UAT)。我们知道,一个二维矩阵如果在两个维度上都长,那么需要的资源是巨量的。而考虑到汉字的个数足够多,而句子足够长,我们会在独热编码后进行降采样。而在独热向量右乘降采样矩阵的行为我们就叫做文本嵌入。简明起见,今天我们不使用更复杂的词编码器,并且略过所有非汉字的字符。这会破坏文本嵌入的一些性质,因此这些性质今天我们也不讨论。
梯度指的是一个多变量函数沿着特定方向的变化率。在模型训练中,我们常常利用梯度的性质来优化模型,甚至只使用梯度来训练模型。这样训练是高效但危险的:一方面,梯度指出的方向是函数值增长最快的方向,梯度的模长等于函数值在该方向上的最大变化率,因此沿梯度反方向修改模型总能迅速使得单个样本的误差降低。但另一方面,模型将对梯度敏感。在人工智能安全领域中,如果我们沿着损失函数相对于输入的梯度方向进行扰动,就能最大化模型的预测误差。这些扰动可以小到人眼或人脑难以察觉或意识到异常。
GPTZero是一款国外的人工智能内容检测软件,它的主要目的是识别由大型语言模型(如 GPT-3 或 GPT-4)产生的文字内容。
今天我们将探讨一种基于梯度的文本重风格化方法,对GPTZero进行对抗,并基于此给出一些关于人工智能安全防御的建议。
有限输出蒸馏指的是在无法取得目标模型权重时,通过数个个样本的试探,取得与目标模型功能乃至梯度都近似的模型。较为高级的有限输出蒸馏方法包括但不仅限于双对抗性训练和子模式一致性优化,不过今天我们用不到这些。
GPTZero为了展示其能力,在RAID(发表于ACL 2024)数据集的测试集上公布了自己的原始输出,尽管这些样本是纯英文的,这亦对安全性来说构成了非常大的隐患。我们在这里不展开如何进行跨语种迁移蒸馏,但是给出一个基本结论,即,如果两个模型的分类界面一致,那么它们的梯度也将相似。分类界面的样本体现为置信度在0.5附近的样本。下面给出使用语种迁移完成后的数据进行模型蒸馏的代码:
这个损失函数的巧妙之处在于其自适应性:当教师置信度 ct≈0.5 时,权重急剧上升,迫使学生模型在边界区域精细调整参数。同时,学生自身的置信度 cs 也参与权重计算,形成一种“自举”(bootstrapping)机制,避免学生模型过度自信(overconfident)。通过这种有限输出蒸馏,我们揭示了AI安全的一个悖论:公开基准虽促进研究,却无意中放大漏洞。下一节,我们将基于此代理模型,探讨如何利用梯度搜索锁定最优扰动位置。
接下来,我们要选择字并进行替换。
第一步是确定哪些字需要被替换。随机选择显然不仅低效,而且不能保证选择的替换点是最优的。不过,基于梯度的搜索则能高效锁定那些对分类器决策边界最敏感的位置。分类器模型通过计算输入嵌入的梯度来量化生成概率的置信度度,我们蒸馏了类似物模型,那蒸馏得到的模型的高梯度区域往往对应于模型自信度较低或决策边界附近的文本,这些文本扰动后能最大化干扰模型输出。
给出核心代码:
至于alt_token的来源,则可以存在不少工程优化,例如同义词表,这里便不赘述。
以上便是全部,欢迎大家批评指正。
class BoundarySensitiveLoss(nn.Module):
def __init__(self, lambda_weight=2.0):
super().__init__()
self.ce_loss = nn.CrossEntropyLoss()
self.lambda_weight = lambda_weight
def forward(self, logits, labels, teacher_confs):
probs = torch.softmax(logits, dim=-1)
pred_probs = torch.max(probs, dim=-1)[0]
weights = torch.exp(-self.lambda_weight * torch.abs(teacher_confs - 0.5)) * \
torch.exp(-self.lambda_weight * torch.abs(pred_probs - 0.5))
ce = self.ce_loss(logits, labels)
return (ce * weights).mean()
class BoundarySensitiveLoss(nn.Module):
def __init__(self, lambda_weight=2.0):
super().__init__()
self.ce_loss = nn.CrossEntropyLoss()
self.lambda_weight = lambda_weight
def forward(self, logits, labels, teacher_confs):
probs = torch.softmax(logits, dim=-1)
pred_probs = torch.max(probs, dim=-1)[0]
weights = torch.exp(-self.lambda_weight * torch.abs(teacher_confs - 0.5)) * \
torch.exp(-self.lambda_weight * torch.abs(pred_probs - 0.5))
ce = self.ce_loss(logits, labels)
return (ce * weights).mean()
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2025-11-23 08:02
被the_hs编辑
,原因:






