本文的目标是分析 OLLVM 核心混淆技术——虚假控制流(BCF)和控制流平坦化(FLA/CFF),并提供多种可复现的去混淆实战方法,这些方法并非万能的,有些如随机控制流、指令替换、常量替换等混淆还是无法去除,后续需要继续研究分析。
感谢 oacia、九天 666、 乐子人 等作者的文章。
只针对的 Android 端的混淆特征以及混淆原理的学习,如有错误欢迎指正。
如侵权可联系修正删除。
在深入实战之前,我们必须彻底理解这两种混淆的“魔术”究竟是什么。
BCF 的核心思想是 “制造干扰”。它通过插入永远不会被执行(或功能上无意义)的代码块,并使用复杂的、静态分析难以解析的“不透明谓词”(Opaque Predicate)来引导跳转,从而污染(Pollute)程序的控制流图(CFG)。
基本形态:
一个原始的基本块 A 会被分裂成至少两个块(例如 A_pre 和 A_post)。
干扰引入:
在 A_pre 和 A_post 之间,BCF 会插入一个或多个“虚假”的基本块(B_bogus)。
不透明谓词 (Opaque Predicate):
A_pre 的结尾会有一个条件跳转。这个跳转的条件是一个“不透明谓词”——它是一个在运行时 结果恒定(始终为真或始终为假),但静态分析器(如 IDA Pro)难以或无法 在不运行代码的情况下确定其结果的表达式。
混淆效果:
原理图
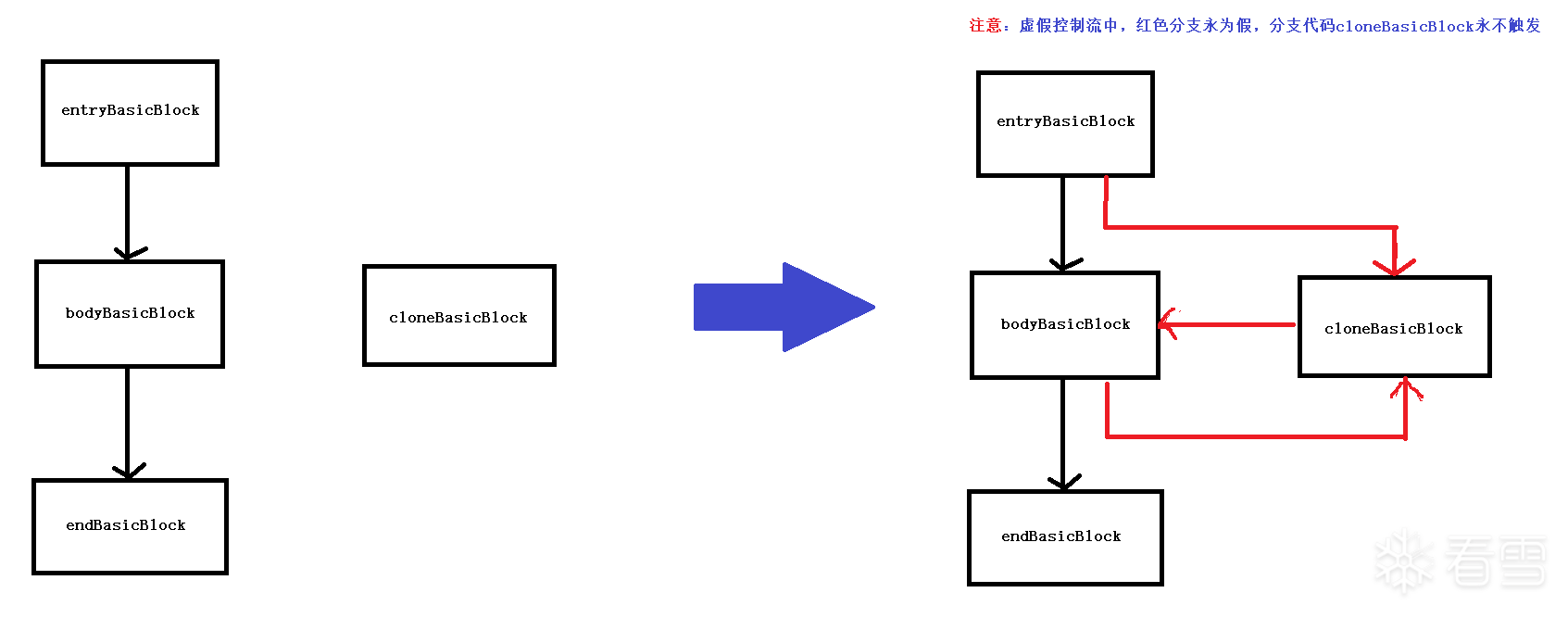
BCF 的关键: 识别并“拆除”那个恒为真/假的“不透明谓词”,nop 恒为假的虚假块,让 CFG“塌陷”回真实路径。
如果说 BCF 是“制造干扰”,那么 FLA(或 CFF)就是一种 “摧毁结构” 的混淆。它彻底颠覆了函数正常的执行流图(CFG),将其“拍扁”(Flatten),所有真实的代码块都变成由一个中央调度器(Dispatcher)来“发牌”和“调度”的“子程序”。
基本思想:
FLA 会摧毁函数内所有的“直接跳转”(如 BB_1 结束时直接跳到 BB_2)。取而代之的是,它引入一个“状态变量”(State Variable),并建立一个巨大的、循环的“分发器”(Dispatcher)。
平坦化流程 512K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Z5k6i4S2Q4x3X3c8J5j5i4W2K6i4K6u0W2j5$3!0E0i4K6u0r3j5X3I4G2k6#2)9J5c8X3S2W2P5q4)9J5k6s2u0S2P5i4y4Q4x3X3c8E0K9h3y4J5L8$3y4G2k6r3g2Q4x3X3c8S2M7r3W2Q4x3X3c8$3M7#2)9J5k6r3!0T1k6Y4g2K6j5$3q4@1K9h3&6Y4i4K6u0V1j5$3!0E0M7r3W2D9k6i4t1`.
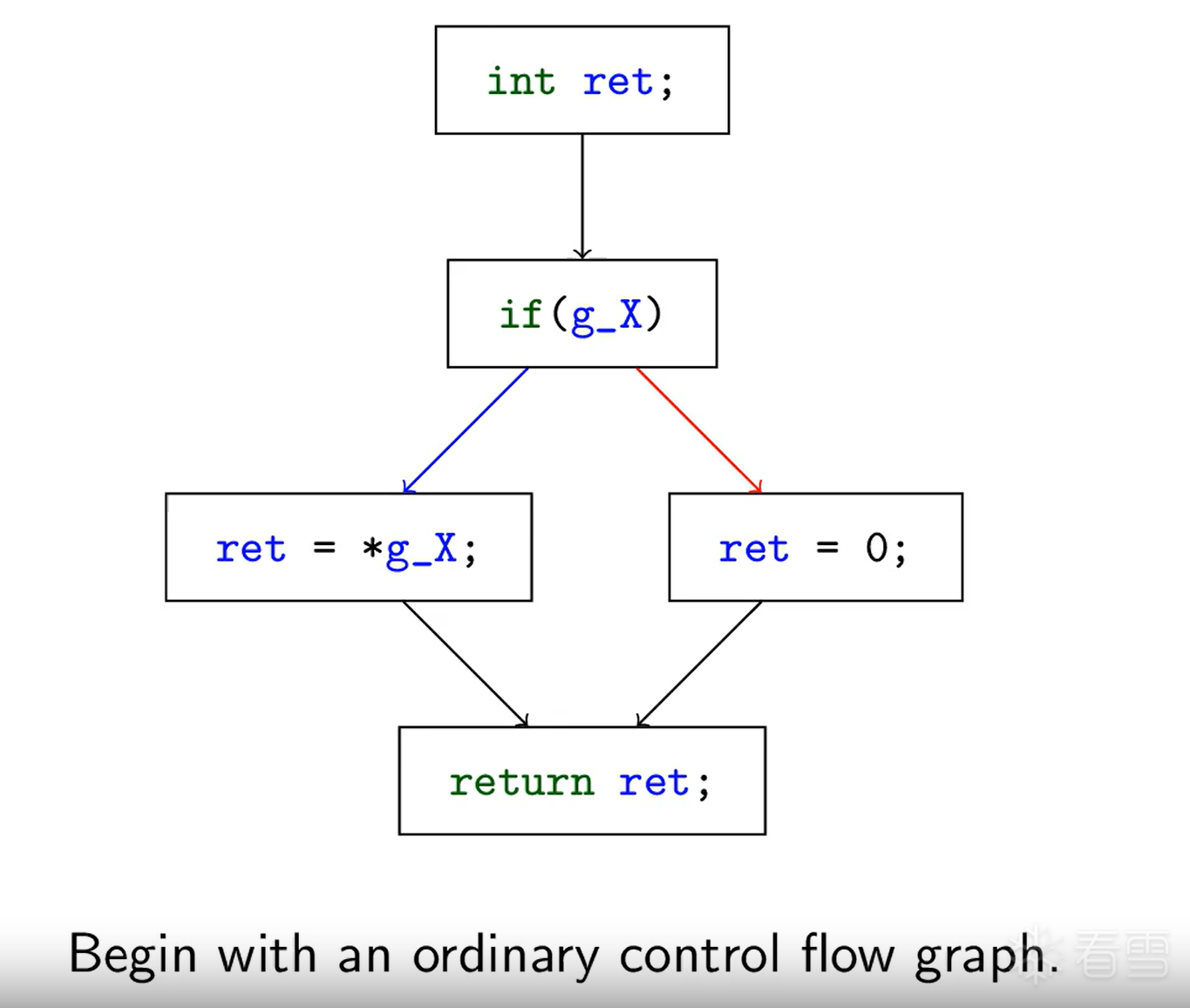
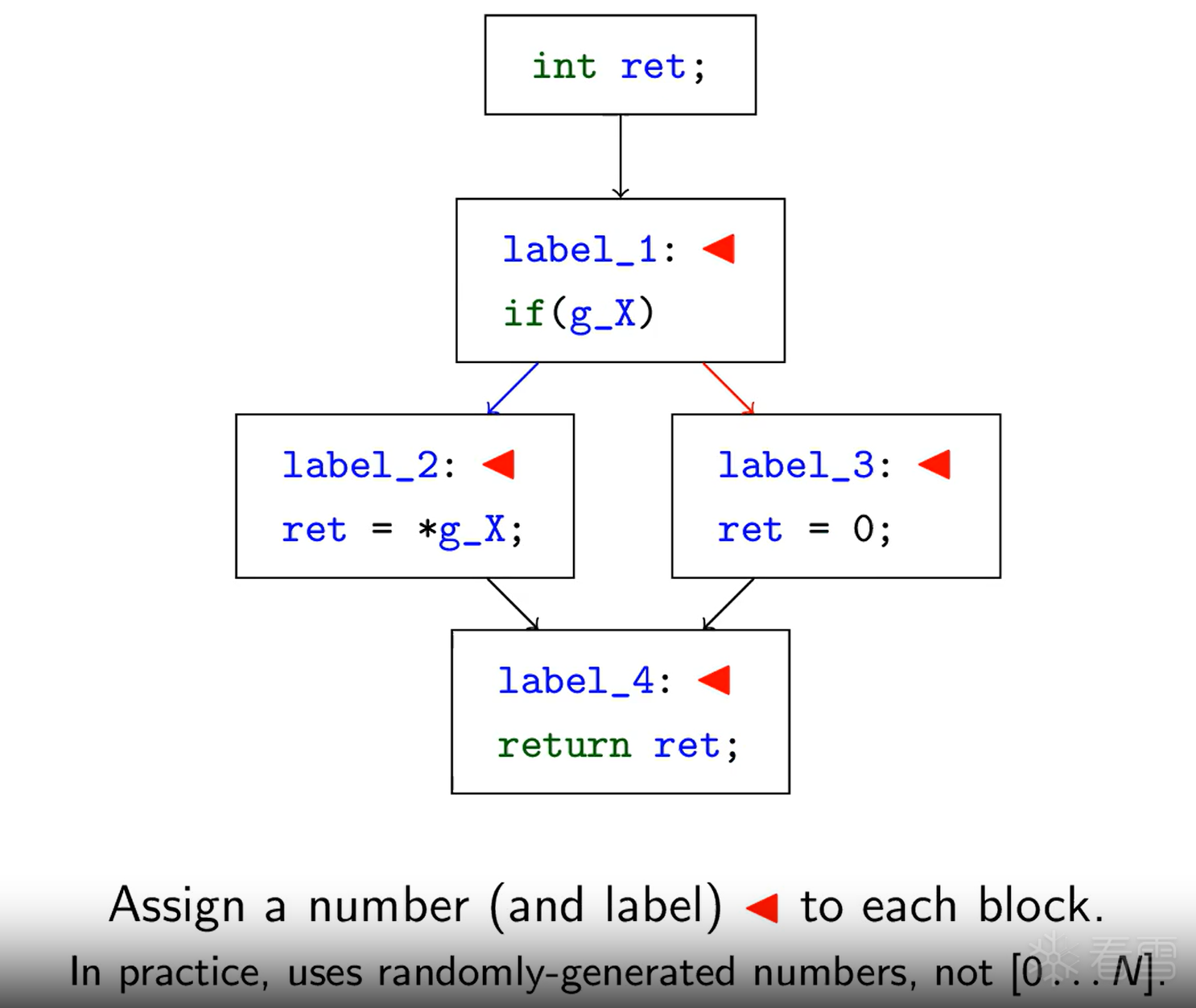
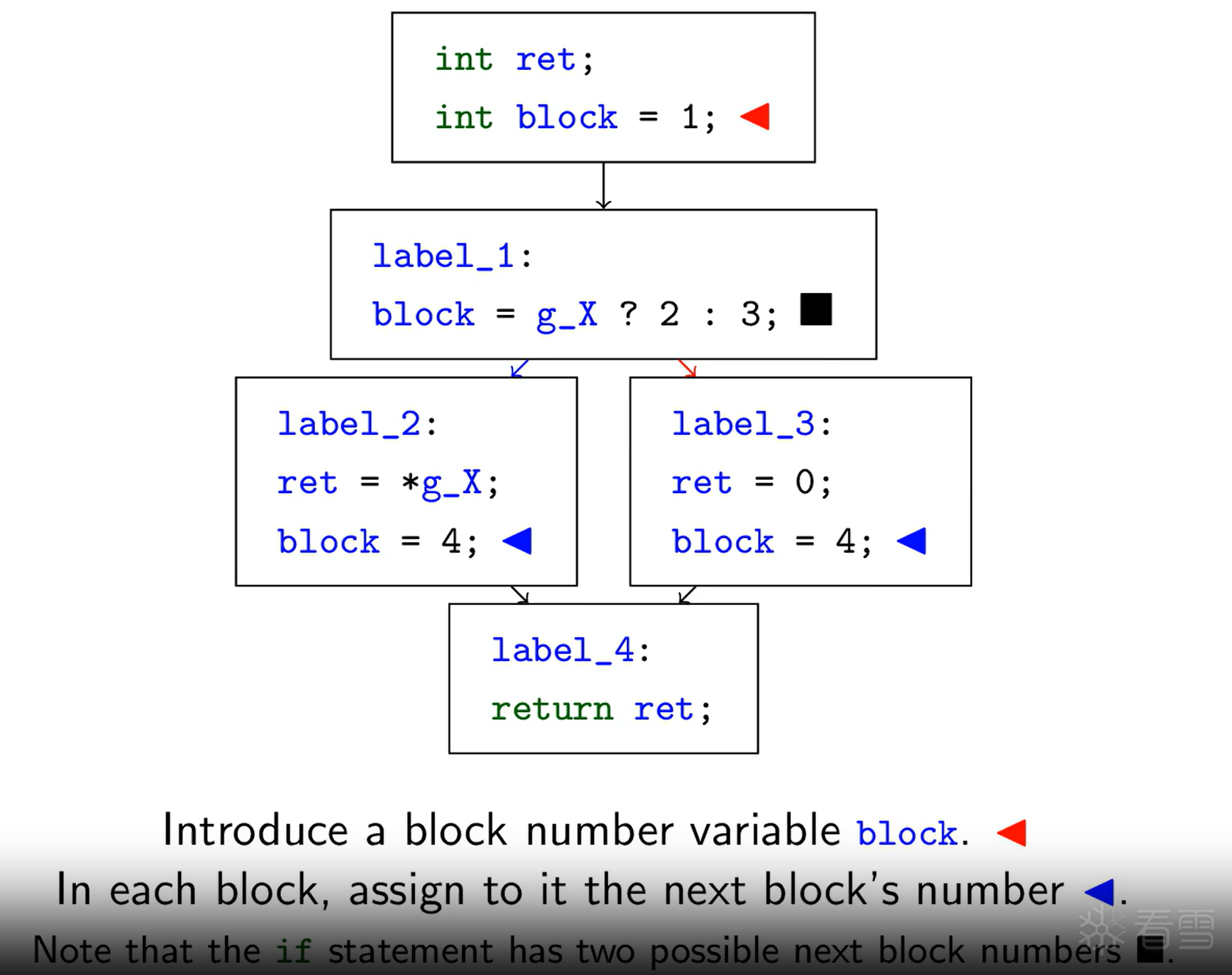
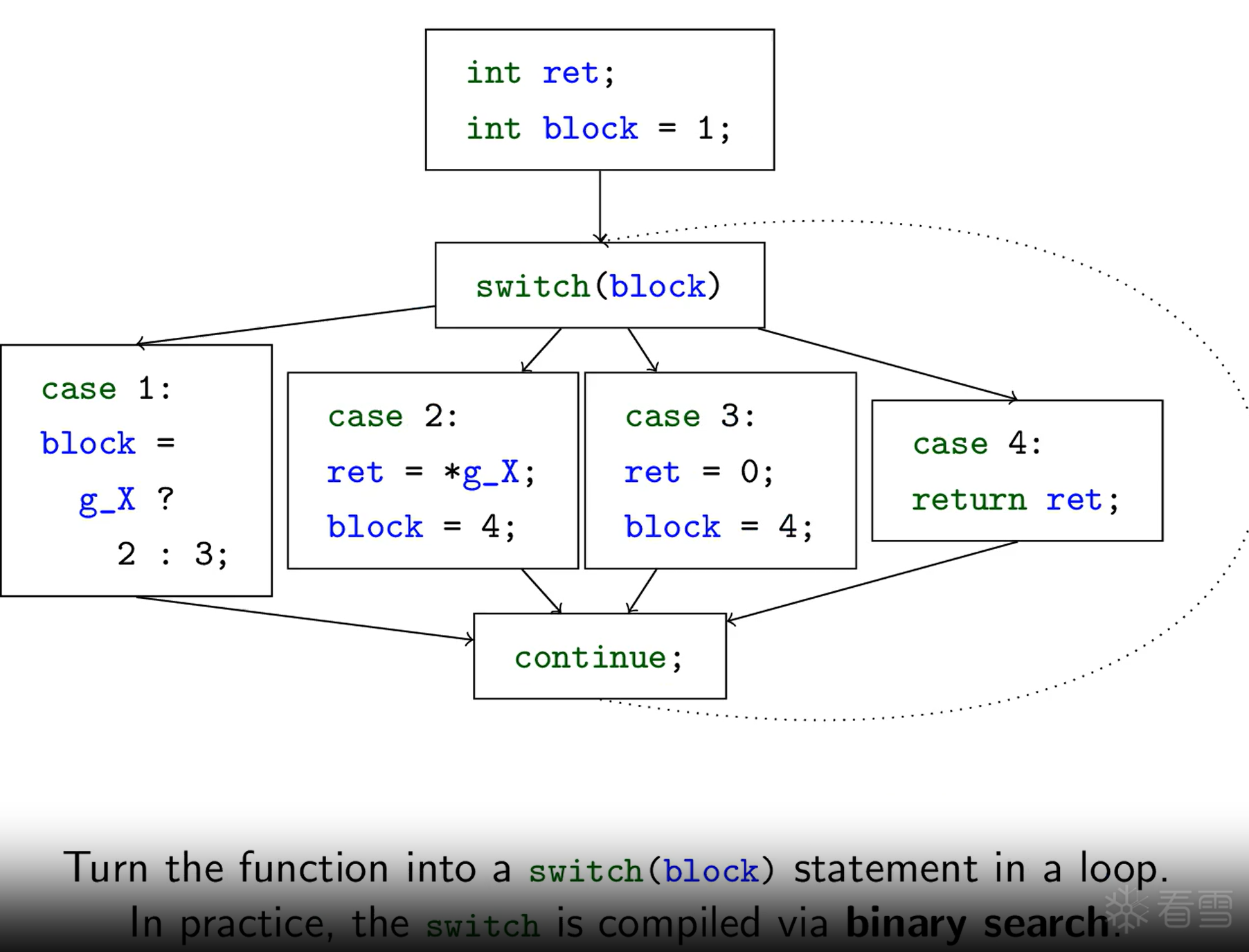
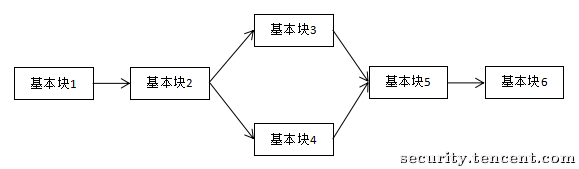
正常的执行流程
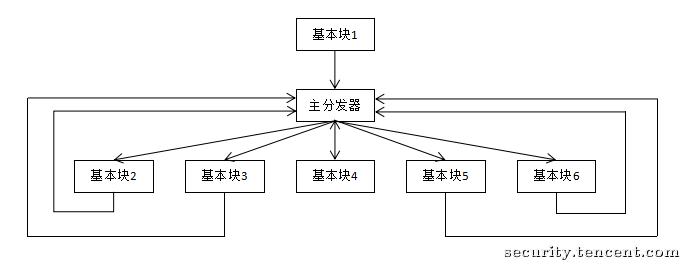
经过控制流平坦化后的执行流程
控制流平坦化后的 CFG:
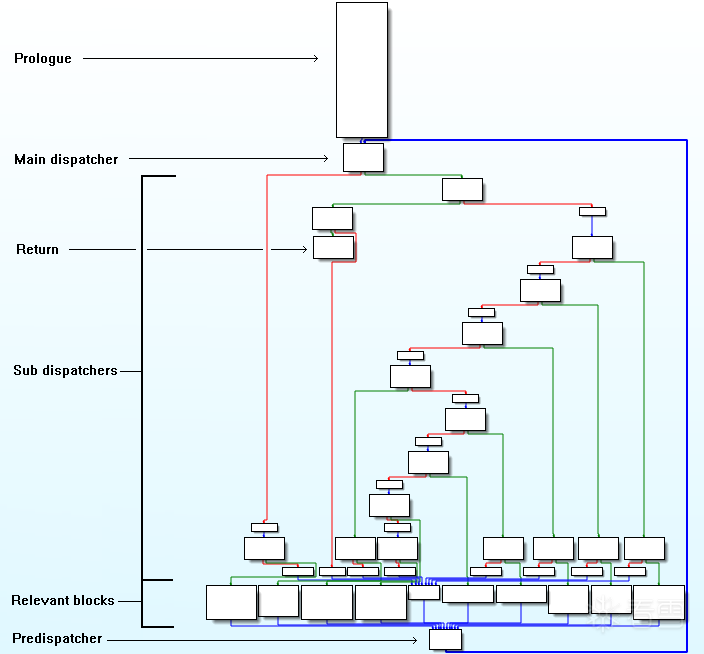
核心组件:
序言 (Prologue):
这是函数的入口块。它的主要作用是初始化“状态变量”,将其设置为第一个“真实块”的 ID。
主分发器 (Main Dispatcher):
这是 FLA 的心脏,通常是一个巨大的 while(true) 循环。这个循环的主体是一个 switch 语句(或等效的 if-else 链),它根据“状态变量”的当前值来决定下一步要跳向何处。这就是图中的“Hub-and-Spoke”(集线器-辐条)模型的“集线器”。
真实块 (Relevant Blocks):
这些是程序原始的基本块(BB),它们包含了函数真正的业务逻辑。在图中,它们被“拍扁”并排列在最底层。它们现在是完全“隔离”的“岛屿”,互相之间没有任何直接的 CFG 连接。
预处理块 (Predispatcher) / 状态更新:
这是 FLA 的关键所在。 当一个“真实块”执行完毕后,它 不会 跳转到下一个“真实块”。相反,它会跳转到一个(或多个)“预处理块”。这个块的 唯一目的 就是 修改“状态变量”的值,将其设置为下一个 应该 执行的“真实块”的 ID。
如图所示,所有“真实块”的执行(蓝线)都将汇聚到“预处理块”,该块完成状态更新后,再 无条件地跳回“主分发器”,形成一个闭环。
子分发器 (Sub-Dispatcher) (高级变种):
正如下图所示,FLA 可以被嵌套和复杂化。“主分发器”可能不会直接跳转到“真实块”,而是跳转到一个“子分发器”。这个“子分发器”可能包含另一层 switch 或复杂的条件判断,进一步混淆状态和目标块之间的关系,然后再跳转到“真实块”。
Return:
返回块
执行流程(控制流平坦化后的 CFG):
混淆效果:
FLA 的关键: 找到那个“状态变量”,并静态或动态地分析出“状态转移图”(State Transition Graph),即 case 1 之后 state 会变成几?case 2 之后呢?找到所有的“真实块”和执行流程,从而重建原始的 CFG。
分析平台:
脚本与自动化:
符号执行/约束求解(可选高级方法):
angr: 强大的二进制分析和符号执行框架。(<span style="color:#CC0000;">python 3.10 版本 pip install angr-management</span>)
z3-solver: 微软的 SMT 约束求解器。
建议安装 Z3 以便使用 D-810 的几个功能:
目标样本:
示例为:455K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6G2j5h3y4A6j5g2)9J5k6h3c8W2N6W2)9J5c8X3!0D9L8s2k6E0i4K6u0V1M7%4c8#2k6s2W2Q4x3V1j5`. 中的 ollvm_bcf-fla-sub.zip 的 test-bcf 二进制文件
参考:https://bbs.kanxue.com/thread-266005.htm (内包含示例)
注意:需要安装<span style="color:#CC0000;">python 3.10 版本 </span>
工具与思路:
angr 之所以能“去除”这种虚假控制流,是因为它使用了 符号执行 (Symbolic Execution),而这种混淆技术的核心——不透明谓词 (Opaque Predicate)——在强大的符号执行引擎面前是无效的。
angr 的核心是 符号执行引擎 和一个 约束求解器 (SMT Solver, 如 Z3)。
当 angr 遇到这个混淆代码时,它会这样做:
angr 通过其强大的求解器,在数学上证明了 哪些路径是“虚假”的(永远不会执行),哪些是“真实”的(永远会执行)。
当您要求 angr 生成控制流图(CFG)时,它只会显示它找到的 唯一真实执行路径。这个过程就等同于“去除”了所有由不透明谓词制造的虚假 goto 和虚假 while 循环,将所有被拆分的真实代码块重新按正确的顺序拼接了起来。
Angr 脚本实现:
重建 CFG:
根据 angr 的“可达”路径(sat states),重建一个干净的 CFG。
对比图(示例为:ollvm_bcf-fla-sub.zip 中的 test-bcf)
参考:73bK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6U0M7e0j5%4y4o6x3#2x3o6f1J5z5g2)9J5c8X3c8W2k6X3I4S2N6l9`.`.
备注:运行比较慢,需要等待一段时间,但效果和之前一样
参考:690K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6G2j5h3y4A6j5g2)9J5k6h3c8W2N6W2)9J5c8X3!0D9L8s2k6E0i4K6u0V1M7%4c8#2k6s2W2Q4x3V1j5`.
核心原理:
最大风险:
编写 IDAPython 脚本:
它先用 patch_dword 修改了底层的原始字节。
然后用 update_segm 保存了段权限。
最后用 del_items 和 create_dword 摧毁了所有旧的分析缓存,迫使 IDA 基于新的字节和新的权限从头开始分析。
Patch 与效果演示:
.bss 段手动修改流程
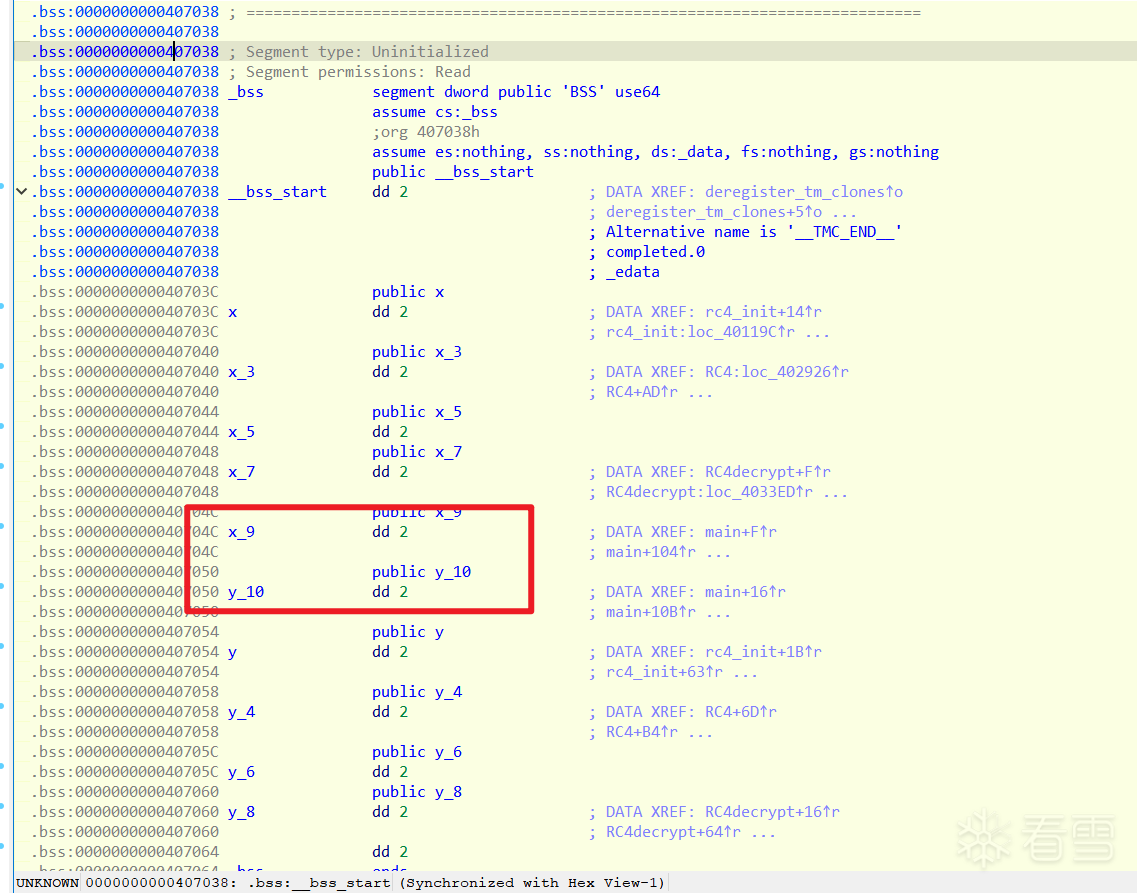

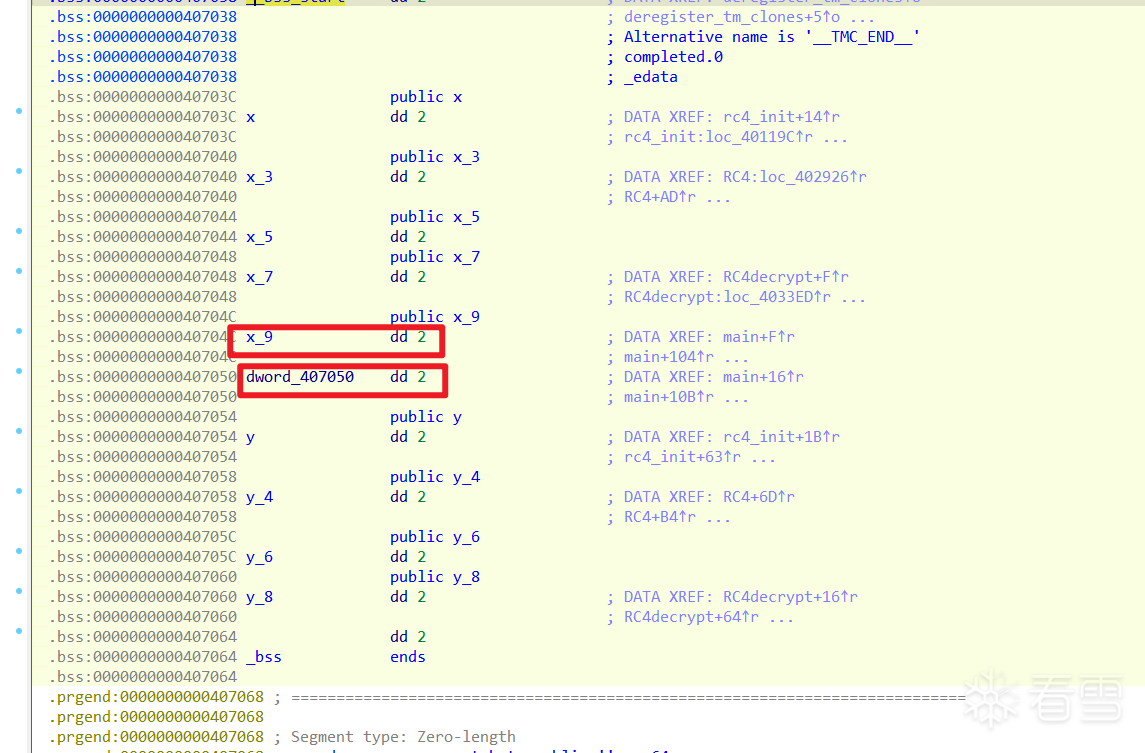
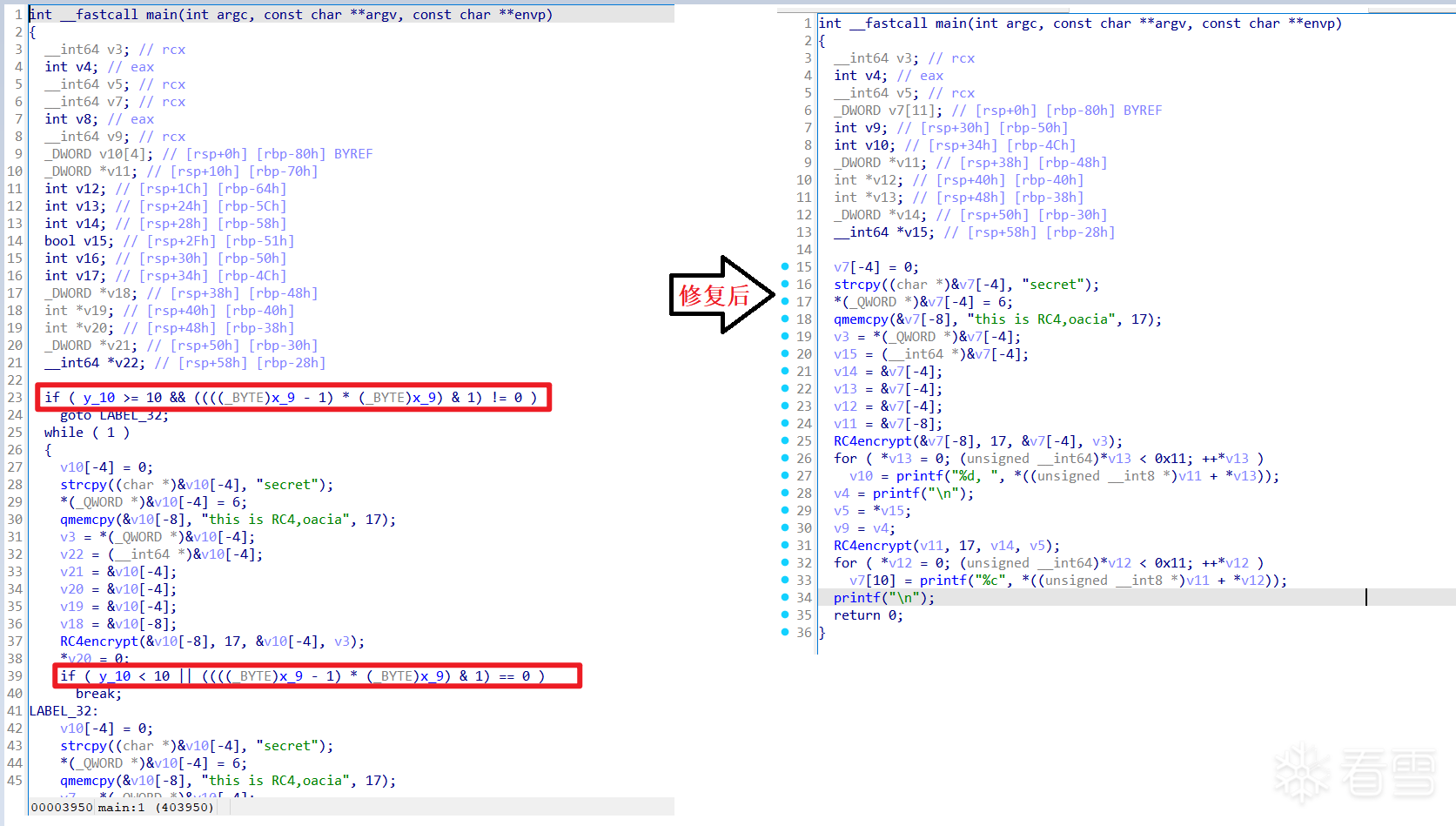
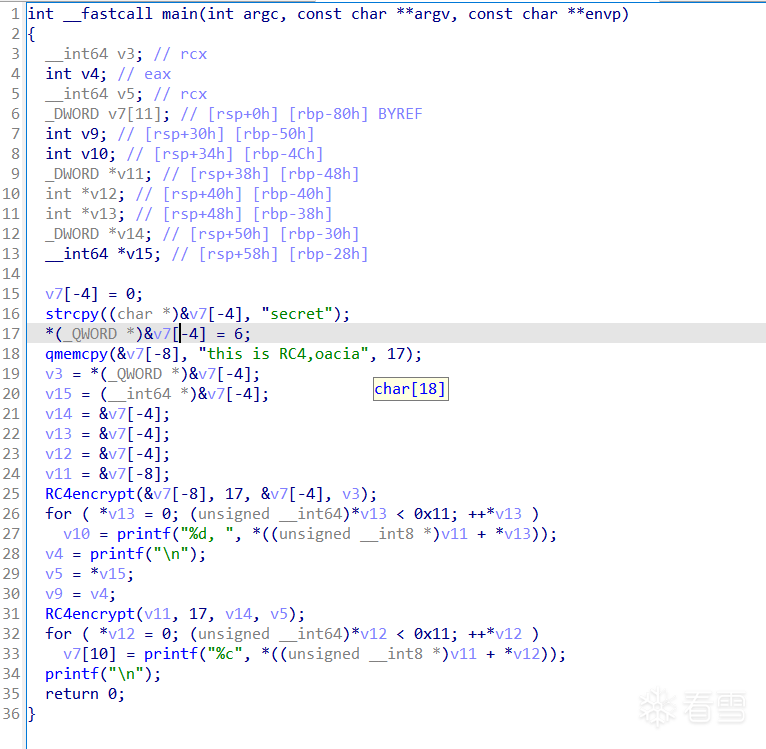
CFG 恢复原状,以及 F5 伪代码变得简洁可读。
参考:4b0K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6G2j5h3y4A6j5g2)9J5k6h3c8W2N6W2)9J5c8X3!0D9L8s2k6E0i4K6u0V1M7%4c8#2k6s2W2Q4x3V1j5`.
原理:
我们之前的脚本(方法三)是“修改数据”:它把 .bss 段的数据改成常量 2,然后设为只读,依赖 IDA 的分析引擎 去自动“算”出 if(2 >= 10) 为假。
而 这个脚本是“修改代码”:它不修改 .bss 段的数据,而是 直接修改所有“读取”这些数据的代码。
最大风险:
ida python 脚本:
[FLA 的恢复通常比 BCF 更复杂,核心是找到状态转移关系。]
示例:https://bbs.kanxue.com/thread-286151.htm 附件作为样本
标准和非标准 fla 区分:
非标准 fla 的循环头地址和汇聚块的地址是相等的
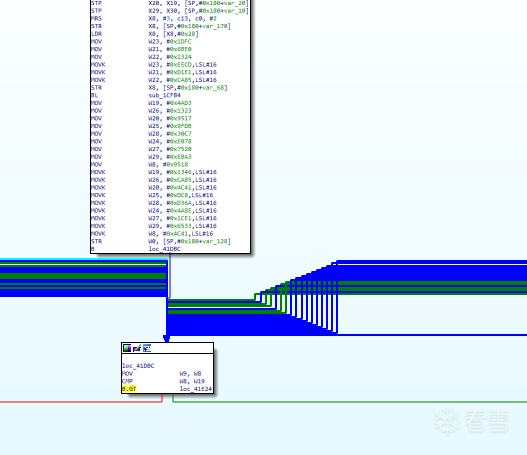
标准 fla 的循环头地址和汇聚块的地址是不相等的,其循环头的前驱只有两个基本块, 一个是序言块, 一个是汇聚块。
插件功能展示
示例:https://bbs.kanxue.com/thread-286151.htm 附件的 init_proc() 函数作为样本
思路:
CFG 示例
idapython 脚本:
对样本中的 init_proc() 去混淆

示例:https://bbs.kanxue.com/thread-286151.htm 附件中的 sub_41D08() 函数作为样本
思路:
CFG 示例
idapython 脚本:
对样本中的 sub_41D08() 去混淆(TODO :但是测试发现,对一些样本还原效果不理想,后续需研究)
示例 1:https://bbs.kanxue.com/thread-277428-1.htm 评论区中经过去除 br x9 后的 JNI_OnLoad() 函数作为样本
示例 2:https://bbs.kanxue.com/thread-286151.htm 附件的 init_proc() 函数,
附件示例:作为 <span style="color:#FF0000; font-weight:bold;">本文 unidbg 的去混淆复现</span>的样本
首先下载 unidbg-0.9.8,并进行测试,测试通过如下
先看一下 main 函数
后续逐个分析 main 函数中的子函数作用
(1)然后通过 Unidbg 模板加载 so,一定先跑起来!!!!
(2)主动调用目标函数,目的是触发 hook
(3)跑起来后,通过 unidbg hook 目标函数,打印指令执行流,试验是否有指令流产生
(4)同上 hook(此处可与之前的 hook 合并在一个函数中):通过 unidbg hook 主动调用的函数,将其以对象 InsAndCtx 存储在栈容器 instructions 中,内部利用 do_processflt 函数进行处理
(5)关键处理 do_processflt 函数
所以我们可以按照以下算法对控制流平坦化进行还原:
同时,我们在主分发器处 hook 指令,记录每次经过主分发器时的索引寄存器的值为索引值顺序。
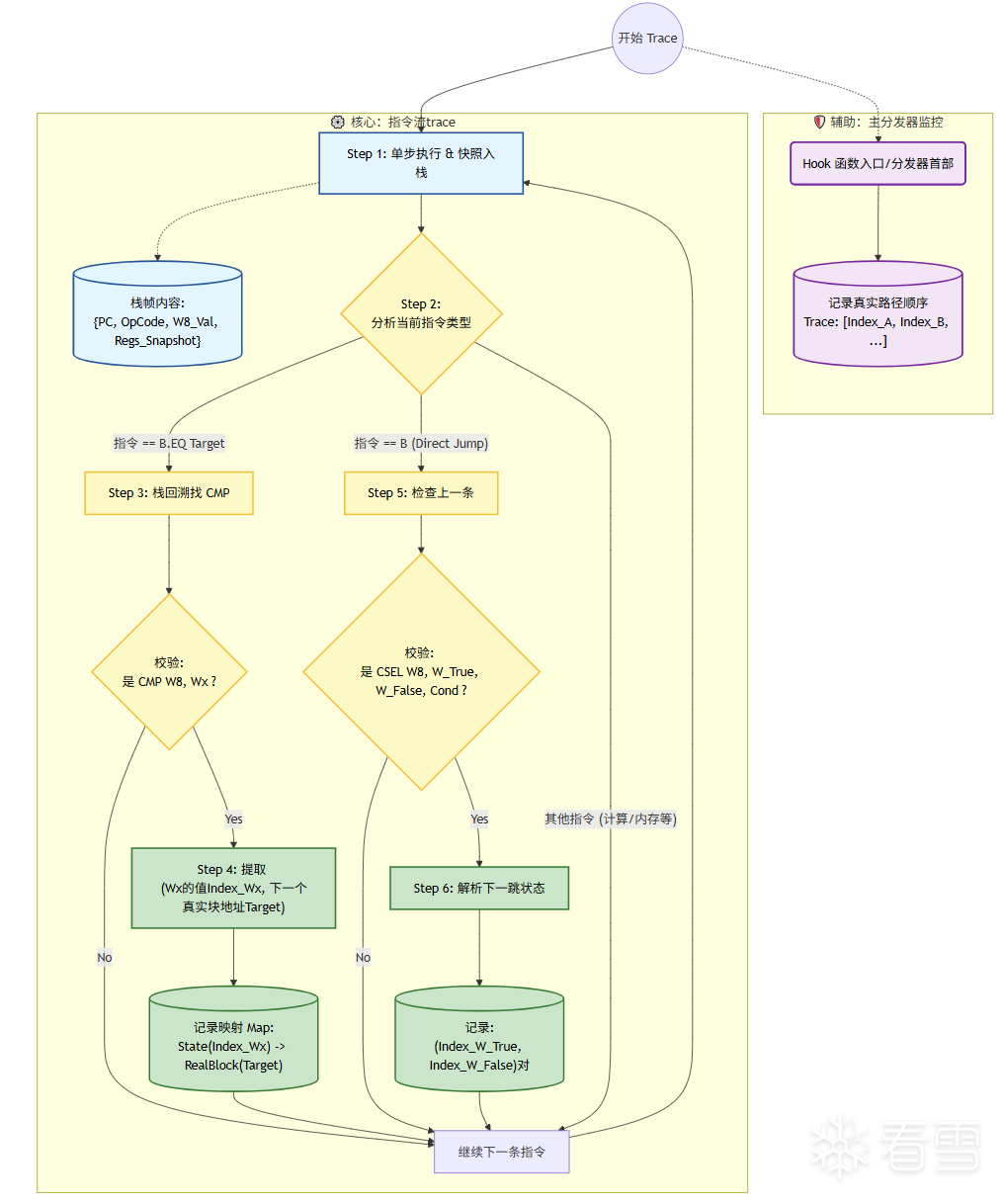
(6)do_processflt 处理之后,先打印和处理各个索引值和真实块信息
<span style="color:#FF00FF; font-weight:bold;">问:有的一分支,trace时发现,程序原有逻辑没有经过,为什么要处理?</span>
答:一个 app 的不同动作对 if 的不同分支都可能触发,那么我们根据程序运行的主要逻辑,找到另一个分支真实块,这样代码还原时,才不会缺省。
如果不处理会出现类似如下报错:
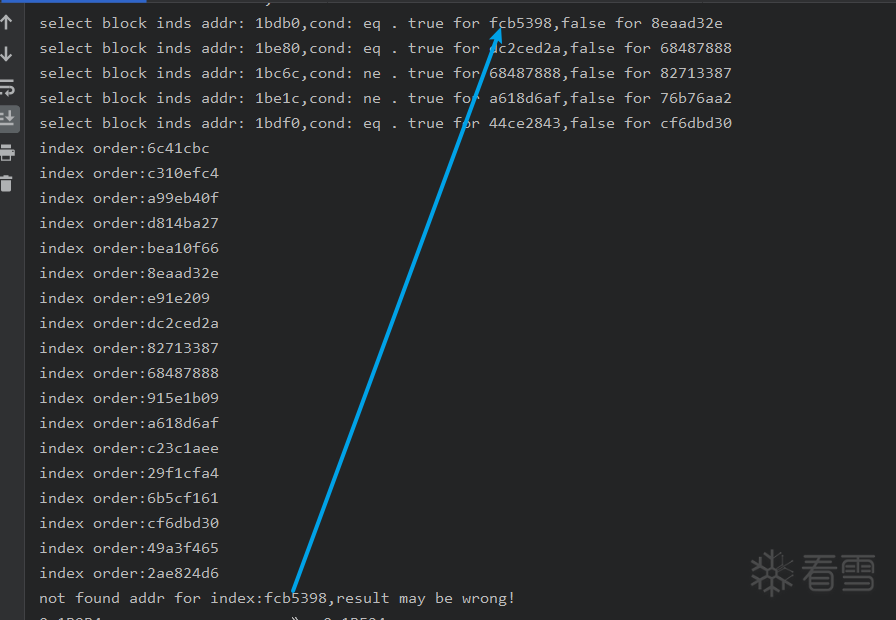
<span style="font-weight:bold; color:#FF0000;">那么如何寻找呢?</span>
情况一(<span style="font-weight:bold; color:#FF0000;">B.NE</span>):0x76B76AA2-> 0x1BB14,<span style="color:#0000FF;">B.NE寻找下一层跳到非主分发器上的分支地址0x1BB14</span>,可得 tbs.add(new TrueBlock(0x76b76aa2L,0x1bb14));
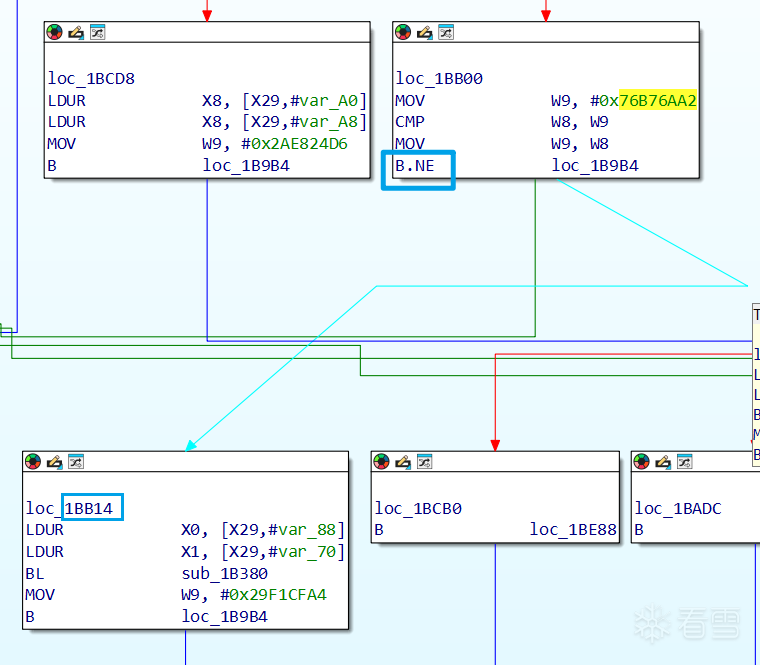
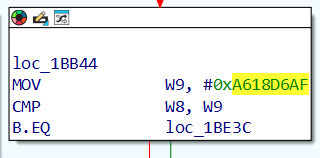
情况二(<span style="color:#FF0000; font-weight:bold;">B.EQ</span>):0xA618D6AF-> 0x1BE3C,<span style="color:#0000FF;">B.EQ寻找紧跟后面的地址0x1BE3C(大多数代码会自动处理好)</span>, 可得 true block index a618d6af,addr 1be3c
除了 CSEL(if-else)分支要处理,如果后续有报错,那么必须要根据 trace 流,手动加入【欠缺的索引值,对应的后续真实块地址】如下第二部分
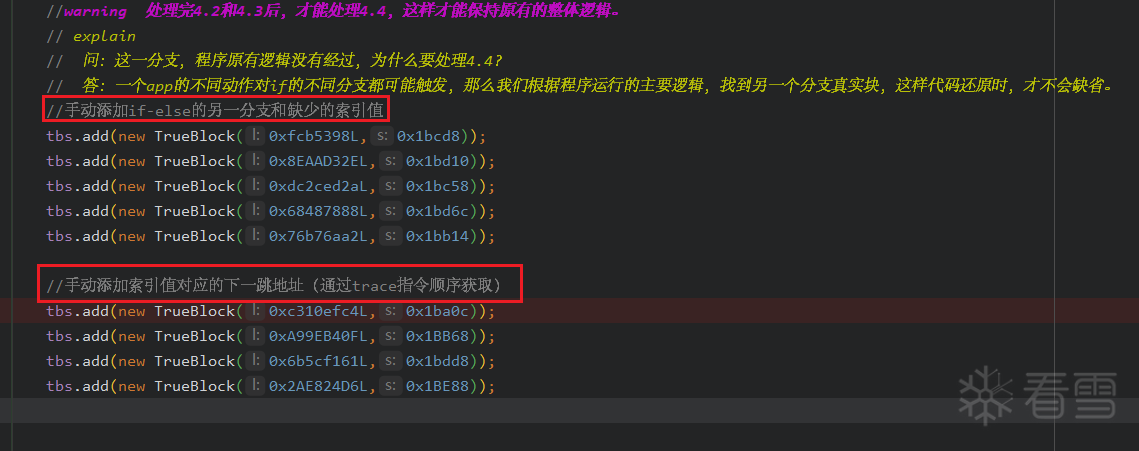
(7)patch 连接真实块
<span style="font-weight:bold; color:#FF0000;">手动处理</span>:对真实块最后为【B 主分发器地址 dispatcher】 的指令处进行 patch
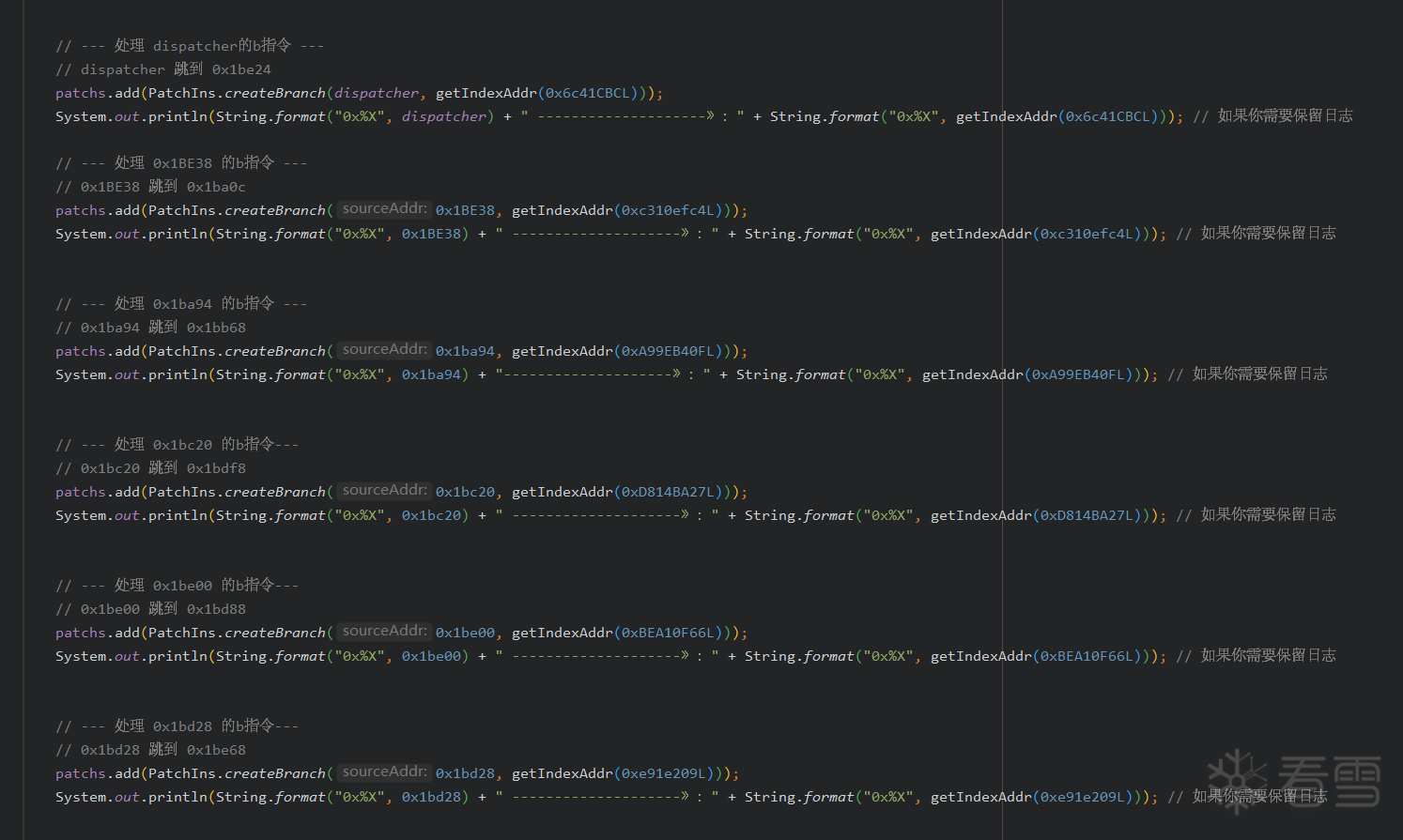
<span style="color:#FF0000; font-weight:bold;">特殊处理部分</span>:即对【b.lt dispatcher】的指令进行 patch

需要手动分析
有一部分没有还原成功,导致最外层还有一个 while 循环,以及部分真实块没有反编译出来(dclose 函数没有反编译出来),还需要细致化分析处理
此作为分析示例,但是没有完全达到 D810 的效果,但是大多数已经满足,可以以此了解去混淆思路,从而预防 D810 等插件去混淆
样本较简单,只作为学习
基于 ida pro 分析的伪代码,交给大模型分析,效果还不错!
BCF: 侧重于制造“噪音”,恢复关键是“去噪”(识别不透明谓词)。
FLA: 侧重于“重构”,恢复关键是“重建”(找到状态转移)。
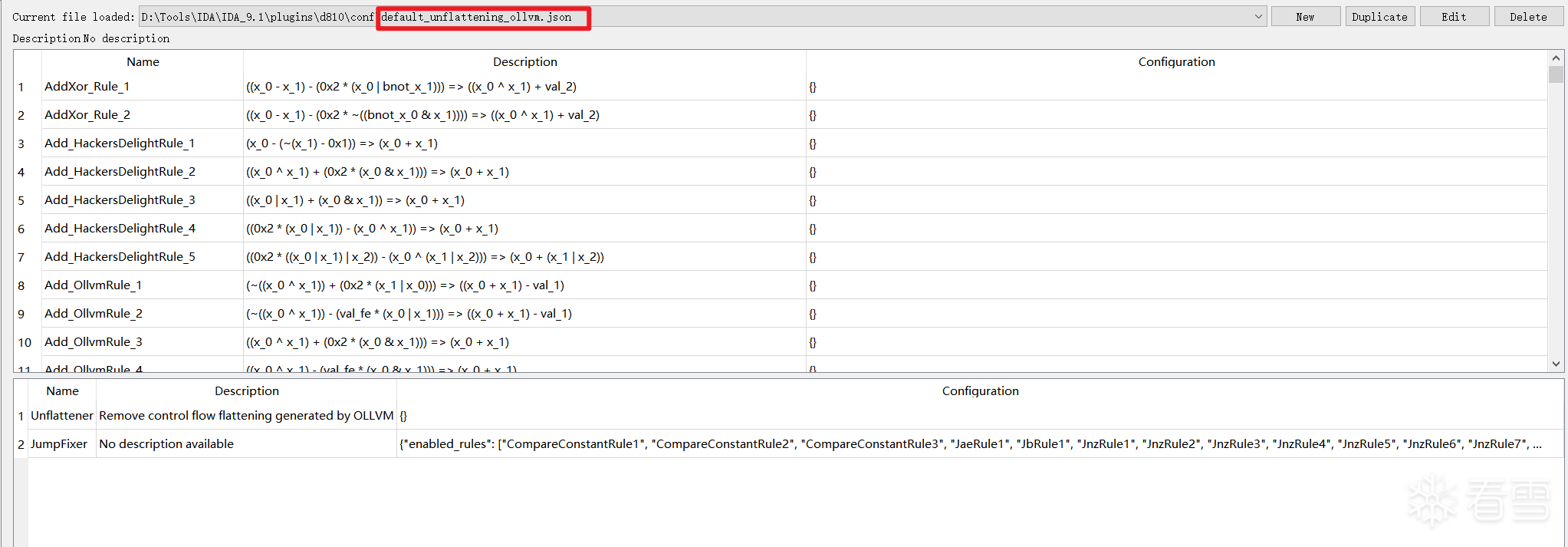
D810 插件需要仔细研究,了解其去混淆原理
2025-11-24 ——针对 fla 中的方法四的TODO(附件已更新)
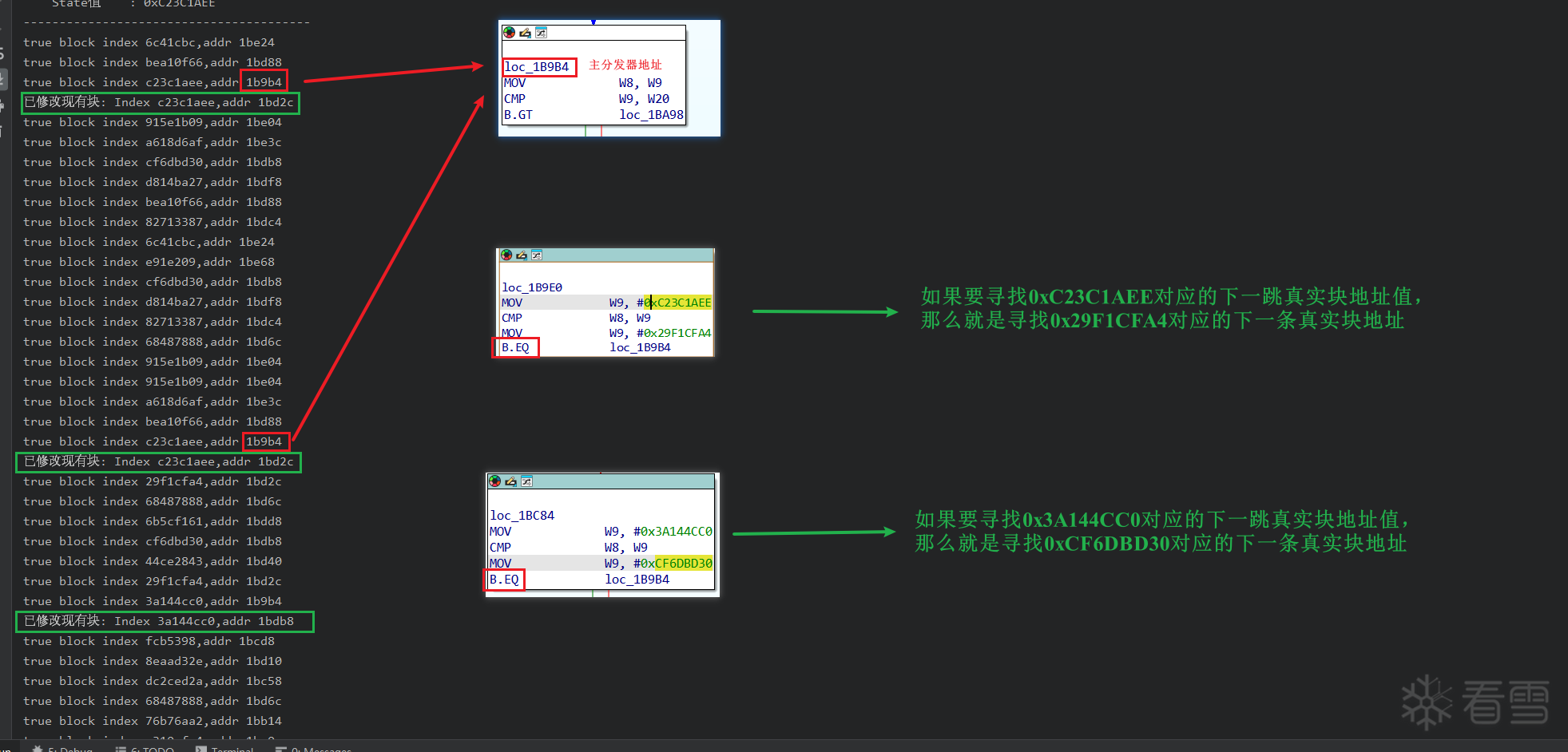
最外层还有一个 while 循环原因找到了:序言块最后一个 b 指令应该直接跳转到第一个真实块,而不是主分发器
部分真实块没有反编译出来原因(dclose 函数没有反编译出来):在打印索引对应的真实块中发现,<span style="color:#FF0000;">在寻找 b.eq 对应的跳转地址时,有些索引对应的下一个真实块地址是主分发器</span>,这肯定是不对的,因此需要修改其对应的下一跳真正的真实块地址
如果存在下面的情况时,就需要手动修复(每个样本此处可能有所变化)

手动修复后日志信息如下:
将大多数手动 patch 转成自动 patch,减少出错几率
python -m pip install z3-solver
python -m pip install z3-solver
python-m pip install angr-management
python-m pip install angr-management
python debogus.py [-h] [-f FILE] [-s START]
python debogus.py [-h] [-f FILE] [-s START]
import angr
from angrmanagement.utils.graph import to_supergraph
import argparse
import logging
import os
def patch_nops(block):
offset = block.addr - proj.loader.main_object.mapped_base
binfile[offset : offset + block.size] = b'\x90' * block.size
print('Patch nop at block %#x' % block.addr)
def get_cfg(func_addr):
cfg = proj.analyses.CFGFast(normalize=True, force_complete_scan=False)
function_cfg = cfg.functions.get(func_addr).transition_graph
super_cfg = to_supergraph(function_cfg)
return super_cfg
def deobfu_func(func_addr):
blocks = set()
cfg = get_cfg(func_addr)
for node in cfg.nodes:
blocks.add(node.addr)
print([hex(b) for b in blocks])
state = proj.factory.blank_state(addr=func_addr)
simgr = proj.factory.simgr(state)
while len(simgr.active):
for active in simgr.active:
blocks.discard(active.addr)
block = proj.factory.block(active.addr)
for insn in block.capstone.insns:
if insn.mnemonic == 'call':
next_func_addr = int(insn.op_str, 16)
proj.hook(next_func_addr, angr.SIM_PROCEDURES["stubs"]["ReturnUnconstrained"](), replace=True)
print('Hook [%s\t%s] at %#x' % (insn.mnemonic, insn.op_str, insn.address))
simgr.step()
for block_addr in blocks:
patch_nops(proj.factory.block(block_addr))
if __name__ == '__main__':
logging.getLogger('cle').setLevel(logging.ERROR)
logging.getLogger('angr').setLevel(logging.ERROR)
parser = argparse.ArgumentParser()
parser.add_argument('-f', '--file', required=True, help='File to deobfuscate')
parser.add_argument('-s', '--start', type=lambda x : int(x, 0), help='Starting address of target function')
args = parser.parse_args()
proj = angr.Project(args.file, load_options={"auto_load_libs": False})
start = args.start
if start == None:
main = proj.loader.find_symbol('main')
if main == None:
parser.error('Can\'t find the main function, please provide argument -s/--start')
start = main.rebased_addr
with open(args.file, 'rb') as file:
binfile = bytearray(file.read())
deobfu_func(func_addr=start)
fname, ext = os.path.splitext(args.file)
with open(fname + '_recovered' + ext, 'wb') as file:
file.write(binfile)
print('Deobfuscation success!')
import angr
from angrmanagement.utils.graph import to_supergraph
import argparse
import logging
import os
def patch_nops(block):
offset = block.addr - proj.loader.main_object.mapped_base
binfile[offset : offset + block.size] = b'\x90' * block.size
print('Patch nop at block %#x' % block.addr)
def get_cfg(func_addr):
cfg = proj.analyses.CFGFast(normalize=True, force_complete_scan=False)
function_cfg = cfg.functions.get(func_addr).transition_graph
super_cfg = to_supergraph(function_cfg)
return super_cfg
def deobfu_func(func_addr):
blocks = set()
cfg = get_cfg(func_addr)
for node in cfg.nodes:
blocks.add(node.addr)
print([hex(b) for b in blocks])
state = proj.factory.blank_state(addr=func_addr)
simgr = proj.factory.simgr(state)
while len(simgr.active):
for active in simgr.active:
blocks.discard(active.addr)
block = proj.factory.block(active.addr)
for insn in block.capstone.insns:
if insn.mnemonic == 'call':
next_func_addr = int(insn.op_str, 16)
proj.hook(next_func_addr, angr.SIM_PROCEDURES["stubs"]["ReturnUnconstrained"](), replace=True)
print('Hook [%s\t%s] at %#x' % (insn.mnemonic, insn.op_str, insn.address))
simgr.step()
for block_addr in blocks:
patch_nops(proj.factory.block(block_addr))
if __name__ == '__main__':
logging.getLogger('cle').setLevel(logging.ERROR)
logging.getLogger('angr').setLevel(logging.ERROR)
parser = argparse.ArgumentParser()
parser.add_argument('-f', '--file', required=True, help='File to deobfuscate')
parser.add_argument('-s', '--start', type=lambda x : int(x, 0), help='Starting address of target function')
args = parser.parse_args()
proj = angr.Project(args.file, load_options={"auto_load_libs": False})
start = args.start
if start == None:
main = proj.loader.find_symbol('main')
if main == None:
parser.error('Can\'t find the main function, please provide argument -s/--start')
start = main.rebased_addr
with open(args.file, 'rb') as file:
binfile = bytearray(file.read())
deobfu_func(func_addr=start)
fname, ext = os.path.splitext(args.file)
with open(fname + '_recovered' + ext, 'wb') as file:
file.write(binfile)
print('Deobfuscation success!')
import ida_segment
import ida_bytes
import ida_auto
print("--- Starting BSS segment patch script ---")
seg = ida_segment.get_segm_by_name('.bss')
if not seg:
print("Error: .bss segment not found.")
else:
print(f"Found .bss at [0x{seg.start_ea:X} - 0x{seg.end_ea:X}]")
print("Patching all dwords in .bss to 2...")
patched_count = 0
for ea in range(seg.start_ea, seg.end_ea, 4):
ida_bytes.patch_dword(ea, 2)
patched_count += 1
print(f"Patched {patched_count} dwords.")
print("Setting segment permissions to Read-Only (R--)...")
seg.perm = 0b100
ida_segment.update_segm(seg)
print("Segment permissions updated in the database.")
print("Forcing re-analysis of all items in .bss...")
for ea in range(seg.start_ea, seg.end_ea, 4):
ida_bytes.del_items(ea, ida_bytes.DELIT_SIMPLE, 4)
ida_bytes.create_dword(ea, 4)
print("--- Script finished successfully! ---")
print(">>> ACTION REQUIRED: Go to your function's pseudocode and press F5 to refresh!")
print(">>> If F5 is not enough, go to assembly, press 'U' on the function, then 'P', then F5.")
import ida_segment
import ida_bytes
import ida_auto
print("--- Starting BSS segment patch script ---")
seg = ida_segment.get_segm_by_name('.bss')
if not seg:
print("Error: .bss segment not found.")
else:
print(f"Found .bss at [0x{seg.start_ea:X} - 0x{seg.end_ea:X}]")
print("Patching all dwords in .bss to 2...")
patched_count = 0
for ea in range(seg.start_ea, seg.end_ea, 4):
ida_bytes.patch_dword(ea, 2)
patched_count += 1
print(f"Patched {patched_count} dwords.")
print("Setting segment permissions to Read-Only (R--)...")
seg.perm = 0b100
ida_segment.update_segm(seg)
print("Segment permissions updated in the database.")
print("Forcing re-analysis of all items in .bss...")
for ea in range(seg.start_ea, seg.end_ea, 4):
ida_bytes.del_items(ea, ida_bytes.DELIT_SIMPLE, 4)
ida_bytes.create_dword(ea, 4)
print("--- Script finished successfully! ---")
print(">>> ACTION REQUIRED: Go to your function's pseudocode and press F5 to refresh!")
print(">>> If F5 is not enough, go to assembly, press 'U' on the function, then 'P', then F5.")
import ida_xref
import ida_idaapi
import ida_segment
from ida_bytes import get_bytes, patch_bytes
def do_patch(ea):
if get_bytes(ea, 1) == b"\x8B":
reg_code = (ord(get_bytes(ea + 1, 1)) & 0b00111000) >> 3
new_opcode = (0xB8 + reg_code).to_bytes(1, 'little')
new_immediate = b'\x00\x00\x00\x00'
padding = b'\x90'
new_instruction_bytes = new_opcode + new_immediate + padding
patch_bytes(ea, new_instruction_bytes)
else:
print(f'Error: Instruction at 0x{ea:X} is not 0x8B, skipping.')
print("--- Starting BCF Patch Script (Code Modification) ---")
seg = ida_segment.get_segm_by_name('.bss')
start = seg.start_ea
end = seg.end_ea
if not seg:
print("Error: .bss segment not found. Exiting script.")
else:
print(f"Scanning .bss segment [0x{start:X} - 0x{end:X}]...")
for addr in range(start, end, 4):
ref = ida_xref.get_first_dref_to(addr)
print(f"--- Processing refs to 0x{addr:X} ---")
while(ref != ida_idaapi.BADADDR):
print(f' Found reference at 0x{ref:X}. Patching...')
do_patch(ref)
ref = ida_xref.get_next_dref_to(addr, ref)
print(f"--- Finished processing 0x{addr:X} ---")
print("--- Script finished successfully! ---")
print(">>> ACTION REQUIRED: Go to your function's assembly view.")
print(">>> Press 'U' (Undefine), then 'P' (Create Function).")
print(">>> Finally, press F5 to see the deobfuscated pseudocode.")
import ida_xref
import ida_idaapi
import ida_segment
from ida_bytes import get_bytes, patch_bytes
def do_patch(ea):
if get_bytes(ea, 1) == b"\x8B":
reg_code = (ord(get_bytes(ea + 1, 1)) & 0b00111000) >> 3
new_opcode = (0xB8 + reg_code).to_bytes(1, 'little')
new_immediate = b'\x00\x00\x00\x00'
padding = b'\x90'
new_instruction_bytes = new_opcode + new_immediate + padding
patch_bytes(ea, new_instruction_bytes)
else:
print(f'Error: Instruction at 0x{ea:X} is not 0x8B, skipping.')
print("--- Starting BCF Patch Script (Code Modification) ---")
seg = ida_segment.get_segm_by_name('.bss')
start = seg.start_ea
end = seg.end_ea
if not seg:
print("Error: .bss segment not found. Exiting script.")
else:
print(f"Scanning .bss segment [0x{start:X} - 0x{end:X}]...")
for addr in range(start, end, 4):
ref = ida_xref.get_first_dref_to(addr)
print(f"--- Processing refs to 0x{addr:X} ---")
while(ref != ida_idaapi.BADADDR):
print(f' Found reference at 0x{ref:X}. Patching...')
do_patch(ref)
ref = ida_xref.get_next_dref_to(addr, ref)
print(f"--- Finished processing 0x{addr:X} ---")
print("--- Script finished successfully! ---")
print(">>> ACTION REQUIRED: Go to your function's assembly view.")
print(">>> Press 'U' (Undefine), then 'P' (Create Function).")
print(">>> Finally, press F5 to see the deobfuscated pseudocode.")
angr 9.2.102
import idaapi
import idautils
import idc
import keystone
ks = keystone.Ks(keystone.KS_ARCH_ARM64, keystone.KS_MODE_LITTLE_ENDIAN)
def print_block_insts(block):
ea = block.start_ea
while ea < block.end_ea:
print(hex(ea), ":", idc.GetDisasm(ea))
ea = idc.next_head(ea)
def getPredBlockIndex(block):
preds_list = list(block.preds())
preds_len = len(preds_list)
if preds_len > 1:
print(hex(block.start_ea), " 前驱数量-->", preds_len)
return None
elif preds_len == 0:
print(hex(block.start_ea)," 没有前驱块")
return None
pred = preds_list[0]
print("前驱块指令:")
print_block_insts(pred)
end_addr = pred.end_ea
last_ins_ea = idc.prev_head(end_addr)
mnem = idc.print_insn_mnem(last_ins_ea)
if mnem == 'B.EQ' or mnem == "B.NE":
CMP_ea = idc.prev_head(last_ins_ea)
mnem = idc.print_insn_mnem(CMP_ea)
CMP_1 = idc.print_operand(CMP_ea,1)
if mnem == 'CMP':
MOV_ea = idc.prev_head(CMP_ea)
mnem = idc.print_insn_mnem(MOV_ea)
if mnem == 'MOV':
index = idc.get_operand_value(MOV_ea, 1)
return hex(index)
else:
if CMP_1 == "W26":
return hex(0xA9D4543B)
elif CMP_1 == "W24":
return hex(0xE4DBC33F)
return None
def findLoopEntryBlockAllPreds(loop_end_ea):
block = getBlockByAddress(loop_end_ea)
for pred in block.preds():
ea = idc.prev_head(pred.end_ea)
print("主分发器前驱基本块:", hex(ea), idc.GetDisasm(ea))
def getBlockLink(func_ea,loop_end_ea):
state_map = {}
func = idaapi.get_func(func_ea)
blocks = idaapi.FlowChart(func)
for block in blocks:
block_start_ea = block.start_ea
block_end_ea = block.end_ea
next_states = []
if block_start_ea == 0x43058:
next_states.append(hex(0x665797A5))
next_states.append(None)
state_map[hex(block_start_ea)] = next_states
continue
last_ins_addr = idc.prev_head(block_end_ea)
mnem = idc.print_insn_mnem(last_ins_addr)
op_0 = idc.get_operand_value(last_ins_addr, 0)
if mnem == "B" and op_0 == loop_end_ea:
ins = idc.prev_head(last_ins_addr)
mnem = idc.print_insn_mnem(ins)
if mnem == "MOV":
mov_1 = idc.get_operand_value(ins,1)
next_states.append(hex(mov_1))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
if mnem == "MOVK":
MOVK_0 = idc.print_operand(ins, 0)
MOVK_1 = idc.get_operand_value(ins,1)
mov_0 = ""
mov_1 = 0
for ea in idautils.Heads(block_start_ea, block_end_ea):
mnem = idc.print_insn_mnem(ea)
if mnem == "MOV":
mov_0 = idc.print_operand(ea,0)
if MOVK_0 == mov_0:
mov_1 = idc.get_operand_value(ea,1)
break
if MOVK_0 == mov_0:
if idc.GetDisasm(ins).find("LSL#16") != -1:
index = (MOVK_1 << 16) | mov_1
next_states.append(hex(index))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
else:
print("未匹配算术移位:",hex(block_start_ea))
if mnem == "CSEL":
print("CSEL:",hex(block_start_ea))
if block_start_ea == 0x43168:
next_states.append(hex(0x4E30550D))
next_states.append(hex(0xBEE4A4C9))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x431d8:
next_states.append(hex(0xA9D4543B))
next_states.append(hex(0xC7AC1F5F))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x433d8:
next_states.append(hex(0xF5C370CA))
next_states.append(hex(0x667521E4))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x43420:
next_states.append(hex(0xE4DBC33F))
next_states.append(hex(0x667521E4))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x434ac:
next_states.append(hex(0xBD9FBBA))
next_states.append(hex(0x5338AB80))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x434cc:
next_states.append(hex(0x146E0C87))
next_states.append(hex(0x1B166FED))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
if mnem == "MOV" and block_end_ea == loop_end_ea:
mov_1 = idc.get_operand_value(last_ins_addr,1)
next_states.append(hex(mov_1))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
if mnem == "RET":
while (1):
preds = block.preds()
preds_list = list(preds)
block = preds_list[0]
pred_ea = block.start_ea
mnem = idc.print_insn_mnem(pred_ea)
if mnem == "MOV":
MOV_ea = pred_ea
pred_ea = idc.next_head(pred_ea)
mnem = idc.print_insn_mnem(pred_ea)
if mnem == "CMP":
pred_ea = idc.next_head(pred_ea)
mnem = idc.print_insn_mnem(pred_ea)
if mnem == "B.NE":
mov_1 = idc.get_operand_value(MOV_ea, 1)
next_states.append(None)
next_states.append(hex(mov_1))
break
if next_states:
state_map[hex(block_start_ea)] = next_states
print(state_map)
return state_map
def getSuccBlockAddrFromMap(state_map,index):
for key in state_map:
block_ea = int(key,16)
targets = state_map[key]
if len(targets) == 2:
pred = targets[1]
if index == pred:
return hex(block_ea)
if len(targets) == 3:
pred = targets[2]
if index == pred:
return hex(block_ea)
return None
def verifyBlockLink(state_map,fun_start,ret_block_ea,next_states):
value = state_map[fun_start]
next_states.append(fun_start)
if len(value) == 3:
for i in range(2):
tmp = next_states.copy()
index = value[i]
addr = getSuccBlockAddrFromMap(state_map, index)
if addr == None:
print("array3 无法找到后继块:",tmp,index)
return None
if addr == ret_block_ea:
tmp.append(addr)
print(tmp)
else:
verifyBlockLink(state_map,addr,ret_block_ea,tmp)
elif len(value) == 2:
index = value[0]
addr = getSuccBlockAddrFromMap(state_map, index)
if addr == None:
print("array2 无法找到后继块:", next_states, hex(index))
return None
if addr == ret_block_ea:
next_states.append(addr)
print(next_states)
else:
verifyBlockLink(state_map, addr, ret_block_ea, next_states)
def findRETBlock(func_ea):
func = idaapi.get_func(func_ea)
blocks = idaapi.FlowChart(func)
for block in blocks:
block_end_ea = block.end_ea
last_ins_ea = idc.prev_head(block_end_ea)
mnem = idc.print_insn_mnem(last_ins_ea)
if mnem == "RET":
return block
def verifyLinkMain(state_map,fun_start):
next_states = []
ret_block = findRETBlock(fun_start)
ret_block_ea = ret_block.start_ea
verifyBlockLink(state_map, hex(fun_start), hex(ret_block_ea), next_states)
def getBlockByAddress(ea):
func = idaapi.get_func(ea)
if not func:
print(f"地址 {hex(ea)} 不在任何函数中")
return None
blocks = idaapi.FlowChart(func)
for block in blocks:
if block.start_ea <= ea < block.end_ea:
return block
print(f"地址 {hex(ea)} 未找到对应的块")
return None
def patchBranch(src_addr, dest_addr,op_value = 0):
CSEL_ea = idc.prev_head(src_addr)
CSEL_3 = idc.print_operand(CSEL_ea,3)
if op_value == 1:
if CSEL_3 == "EQ":
encoding, count = ks.asm(f'b.eq {dest_addr}', CSEL_ea)
if CSEL_3 == "NE":
encoding, count = ks.asm(f'b.ne {dest_addr}', CSEL_ea)
if CSEL_3 == "GT":
encoding, count = ks.asm(f'b.gt {dest_addr}', CSEL_ea)
src_addr = CSEL_ea
else:
encoding, count = ks.asm(f'b {dest_addr}', src_addr)
if not count:
print('ks.asm err')
else:
for i in range(4):
idc.patch_byte(src_addr + i, encoding[i])
def rebuildControlFlow(state_map):
for block in state_map:
block_ea = int(block,16)
value = state_map[block]
endEa = getBlockByAddress(block_ea).end_ea
last_insn_ea = idc.prev_head(endEa)
if idc.print_insn_mnem(last_insn_ea) == "B":
if len(value) == 2:
succ_index = value[0]
if succ_index == None:
continue
jmp_addr = getSuccBlockAddrFromMap(state_map,succ_index)
patchBranch(last_insn_ea, jmp_addr)
elif len(value) == 3:
succ_0 = value[0]
jmp_addr_0 = getSuccBlockAddrFromMap(state_map, succ_0)
patchBranch(last_insn_ea, jmp_addr_0,1)
succ_1 = value[1]
jmp_addr_1 = getSuccBlockAddrFromMap(state_map, succ_1)
patchBranch(last_insn_ea, jmp_addr_1)
if idc.print_insn_mnem(last_insn_ea) == "MOV":
succ_index = value[0]
jmp_addr = getSuccBlockAddrFromMap(state_map, succ_index)
patchBranch(last_insn_ea, jmp_addr)
def findDispatchers(func_start,num = 10):
func = idaapi.get_func(func_start)
blocks = idaapi.FlowChart(func)
pachers = []
for block in blocks:
preds = block.preds()
preds_list = list(preds)
if len(preds_list) > num:
pachers.append(block)
return pachers
def deObfuscatorFla():
print("===============START===================")
fn = 0x43058
patchers = findDispatchers(fn)
print("patchers:",len(patchers))
if len(patchers) == 0:
print("未找到主分发器")
return
for disPatcherBlock in patchers:
print("主分发器地址:", hex(disPatcherBlock.start_ea))
stamp = getBlockLink(fn, disPatcherBlock.start_ea)
verifyLinkMain(stamp,fn)
rebuildControlFlow(stamp)
print("===============END===================")
deObfuscatorFla()
import idaapi
import idautils
import idc
import keystone
ks = keystone.Ks(keystone.KS_ARCH_ARM64, keystone.KS_MODE_LITTLE_ENDIAN)
def print_block_insts(block):
ea = block.start_ea
while ea < block.end_ea:
print(hex(ea), ":", idc.GetDisasm(ea))
ea = idc.next_head(ea)
def getPredBlockIndex(block):
preds_list = list(block.preds())
preds_len = len(preds_list)
if preds_len > 1:
print(hex(block.start_ea), " 前驱数量-->", preds_len)
return None
elif preds_len == 0:
print(hex(block.start_ea)," 没有前驱块")
return None
pred = preds_list[0]
print("前驱块指令:")
print_block_insts(pred)
end_addr = pred.end_ea
last_ins_ea = idc.prev_head(end_addr)
mnem = idc.print_insn_mnem(last_ins_ea)
if mnem == 'B.EQ' or mnem == "B.NE":
CMP_ea = idc.prev_head(last_ins_ea)
mnem = idc.print_insn_mnem(CMP_ea)
CMP_1 = idc.print_operand(CMP_ea,1)
if mnem == 'CMP':
MOV_ea = idc.prev_head(CMP_ea)
mnem = idc.print_insn_mnem(MOV_ea)
if mnem == 'MOV':
index = idc.get_operand_value(MOV_ea, 1)
return hex(index)
else:
if CMP_1 == "W26":
return hex(0xA9D4543B)
elif CMP_1 == "W24":
return hex(0xE4DBC33F)
return None
def findLoopEntryBlockAllPreds(loop_end_ea):
block = getBlockByAddress(loop_end_ea)
for pred in block.preds():
ea = idc.prev_head(pred.end_ea)
print("主分发器前驱基本块:", hex(ea), idc.GetDisasm(ea))
def getBlockLink(func_ea,loop_end_ea):
state_map = {}
func = idaapi.get_func(func_ea)
blocks = idaapi.FlowChart(func)
for block in blocks:
block_start_ea = block.start_ea
block_end_ea = block.end_ea
next_states = []
if block_start_ea == 0x43058:
next_states.append(hex(0x665797A5))
next_states.append(None)
state_map[hex(block_start_ea)] = next_states
continue
last_ins_addr = idc.prev_head(block_end_ea)
mnem = idc.print_insn_mnem(last_ins_addr)
op_0 = idc.get_operand_value(last_ins_addr, 0)
if mnem == "B" and op_0 == loop_end_ea:
ins = idc.prev_head(last_ins_addr)
mnem = idc.print_insn_mnem(ins)
if mnem == "MOV":
mov_1 = idc.get_operand_value(ins,1)
next_states.append(hex(mov_1))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
if mnem == "MOVK":
MOVK_0 = idc.print_operand(ins, 0)
MOVK_1 = idc.get_operand_value(ins,1)
mov_0 = ""
mov_1 = 0
for ea in idautils.Heads(block_start_ea, block_end_ea):
mnem = idc.print_insn_mnem(ea)
if mnem == "MOV":
mov_0 = idc.print_operand(ea,0)
if MOVK_0 == mov_0:
mov_1 = idc.get_operand_value(ea,1)
break
if MOVK_0 == mov_0:
if idc.GetDisasm(ins).find("LSL#16") != -1:
index = (MOVK_1 << 16) | mov_1
next_states.append(hex(index))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
else:
print("未匹配算术移位:",hex(block_start_ea))
if mnem == "CSEL":
print("CSEL:",hex(block_start_ea))
if block_start_ea == 0x43168:
next_states.append(hex(0x4E30550D))
next_states.append(hex(0xBEE4A4C9))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x431d8:
next_states.append(hex(0xA9D4543B))
next_states.append(hex(0xC7AC1F5F))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x433d8:
next_states.append(hex(0xF5C370CA))
next_states.append(hex(0x667521E4))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x43420:
next_states.append(hex(0xE4DBC33F))
next_states.append(hex(0x667521E4))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x434ac:
next_states.append(hex(0xBD9FBBA))
next_states.append(hex(0x5338AB80))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
elif block_start_ea == 0x434cc:
next_states.append(hex(0x146E0C87))
next_states.append(hex(0x1B166FED))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
if mnem == "MOV" and block_end_ea == loop_end_ea:
mov_1 = idc.get_operand_value(last_ins_addr,1)
next_states.append(hex(mov_1))
pred_index = getPredBlockIndex(block)
next_states.append(pred_index)
if mnem == "RET":
while (1):
preds = block.preds()
preds_list = list(preds)
block = preds_list[0]
pred_ea = block.start_ea
mnem = idc.print_insn_mnem(pred_ea)
if mnem == "MOV":
MOV_ea = pred_ea
pred_ea = idc.next_head(pred_ea)
mnem = idc.print_insn_mnem(pred_ea)
if mnem == "CMP":
pred_ea = idc.next_head(pred_ea)
mnem = idc.print_insn_mnem(pred_ea)
if mnem == "B.NE":
mov_1 = idc.get_operand_value(MOV_ea, 1)
next_states.append(None)
next_states.append(hex(mov_1))
break
if next_states:
state_map[hex(block_start_ea)] = next_states
print(state_map)
return state_map
def getSuccBlockAddrFromMap(state_map,index):
for key in state_map:
block_ea = int(key,16)
targets = state_map[key]
if len(targets) == 2:
pred = targets[1]
if index == pred:
return hex(block_ea)
if len(targets) == 3:
pred = targets[2]
if index == pred:
return hex(block_ea)
return None
def verifyBlockLink(state_map,fun_start,ret_block_ea,next_states):
value = state_map[fun_start]
next_states.append(fun_start)
if len(value) == 3:
for i in range(2):
tmp = next_states.copy()
index = value[i]
addr = getSuccBlockAddrFromMap(state_map, index)
if addr == None:
print("array3 无法找到后继块:",tmp,index)
return None
if addr == ret_block_ea:
tmp.append(addr)
print(tmp)
else:
verifyBlockLink(state_map,addr,ret_block_ea,tmp)
elif len(value) == 2:
index = value[0]
addr = getSuccBlockAddrFromMap(state_map, index)
if addr == None:
print("array2 无法找到后继块:", next_states, hex(index))
return None
if addr == ret_block_ea:
next_states.append(addr)
print(next_states)
else:
verifyBlockLink(state_map, addr, ret_block_ea, next_states)
def findRETBlock(func_ea):
func = idaapi.get_func(func_ea)
blocks = idaapi.FlowChart(func)
for block in blocks:
block_end_ea = block.end_ea
last_ins_ea = idc.prev_head(block_end_ea)
mnem = idc.print_insn_mnem(last_ins_ea)
if mnem == "RET":
return block
def verifyLinkMain(state_map,fun_start):
next_states = []
ret_block = findRETBlock(fun_start)
ret_block_ea = ret_block.start_ea
verifyBlockLink(state_map, hex(fun_start), hex(ret_block_ea), next_states)
def getBlockByAddress(ea):
func = idaapi.get_func(ea)
if not func:
print(f"地址 {hex(ea)} 不在任何函数中")
return None
blocks = idaapi.FlowChart(func)
for block in blocks:
if block.start_ea <= ea < block.end_ea:
return block
print(f"地址 {hex(ea)} 未找到对应的块")
return None
def patchBranch(src_addr, dest_addr,op_value = 0):
CSEL_ea = idc.prev_head(src_addr)
CSEL_3 = idc.print_operand(CSEL_ea,3)
if op_value == 1:
if CSEL_3 == "EQ":
encoding, count = ks.asm(f'b.eq {dest_addr}', CSEL_ea)
if CSEL_3 == "NE":
encoding, count = ks.asm(f'b.ne {dest_addr}', CSEL_ea)
if CSEL_3 == "GT":
encoding, count = ks.asm(f'b.gt {dest_addr}', CSEL_ea)
src_addr = CSEL_ea
else:
encoding, count = ks.asm(f'b {dest_addr}', src_addr)
if not count:
print('ks.asm err')
else:
for i in range(4):
idc.patch_byte(src_addr + i, encoding[i])
def rebuildControlFlow(state_map):
for block in state_map:
block_ea = int(block,16)
value = state_map[block]
endEa = getBlockByAddress(block_ea).end_ea
last_insn_ea = idc.prev_head(endEa)
if idc.print_insn_mnem(last_insn_ea) == "B":
if len(value) == 2:
succ_index = value[0]
if succ_index == None:
continue
jmp_addr = getSuccBlockAddrFromMap(state_map,succ_index)
patchBranch(last_insn_ea, jmp_addr)
elif len(value) == 3:
succ_0 = value[0]
jmp_addr_0 = getSuccBlockAddrFromMap(state_map, succ_0)
patchBranch(last_insn_ea, jmp_addr_0,1)
succ_1 = value[1]
jmp_addr_1 = getSuccBlockAddrFromMap(state_map, succ_1)
patchBranch(last_insn_ea, jmp_addr_1)
if idc.print_insn_mnem(last_insn_ea) == "MOV":
succ_index = value[0]
jmp_addr = getSuccBlockAddrFromMap(state_map, succ_index)
patchBranch(last_insn_ea, jmp_addr)
def findDispatchers(func_start,num = 10):
func = idaapi.get_func(func_start)
blocks = idaapi.FlowChart(func)
pachers = []
for block in blocks:
preds = block.preds()
preds_list = list(preds)
if len(preds_list) > num:
pachers.append(block)
return pachers
def deObfuscatorFla():
print("===============START===================")
fn = 0x43058
patchers = findDispatchers(fn)
print("patchers:",len(patchers))
if len(patchers) == 0:
print("未找到主分发器")
return
for disPatcherBlock in patchers:
print("主分发器地址:", hex(disPatcherBlock.start_ea))
stamp = getBlockLink(fn, disPatcherBlock.start_ea)
verifyLinkMain(stamp,fn)
rebuildControlFlow(stamp)
print("===============END===================")
deObfuscatorFla()
from collections import deque
import ida_funcs
import idaapi
import idc
def get_block_by_address(ea):
func = idaapi.get_func(ea)
blocks = idaapi.FlowChart(func)
for block in blocks:
if block.start_ea <= ea < block.end_ea:
return block
return None
def find_loop_heads(func):
loop_heads = set()
queue = deque()
block = get_block_by_address(func)
queue.append((block, []))
while len(queue) > 0:
cur_block, path = queue.popleft()
if cur_block.start_ea in path:
loop_heads.add(cur_block.start_ea)
continue
path = path + [cur_block.start_ea]
queue.extend((succ, path) for succ in cur_block.succs())
all_loop_heads = list(loop_heads)
all_loop_heads.sort()
return all_loop_heads
def find_converge_addr(loop_head_addr):
converge_addr = None
block = get_block_by_address(loop_head_addr)
preds = block.preds()
pred_list = list(preds)
if len(pred_list) == 2:
for pred in pred_list:
tmp_list = list(pred.preds())
if len(tmp_list) > 1:
converge_addr = pred.start_ea
else:
converge_addr = loop_head_addr
return converge_addr
def get_basic_block_size(bb):
return bb.end_ea - bb.start_ea
def add_block_color(ea):
block = get_block_by_address(ea)
curr_addr = block.start_ea
while curr_addr < block.end_ea:
idc.set_color(curr_addr, idc.CIC_ITEM, 0xffcc33)
curr_addr = idc.next_head(curr_addr)
def del_func_color(curr_addr):
end_ea = idc.find_func_end(curr_addr)
while curr_addr < end_ea:
idc.set_color(curr_addr, idc.CIC_ITEM, 0xffffffff)
curr_addr = idc.next_head(curr_addr)
def find_ret_block_addr(blocks):
for block in blocks:
succs = block.succs()
succs_list = list(succs)
end_ea = block.end_ea
last_ins_ea = idc.prev_head(end_ea)
mnem = idc.print_insn_mnem(last_ins_ea)
if len(succs_list) == 0:
if mnem == "RET":
ori_ret_block = block
while True:
tmp_block = block.preds()
pred_list = list(tmp_block)
if len(pred_list) == 1:
block = pred_list[0]
if get_basic_block_size(block) == 4:
continue
else:
break
else:
break
block2 = block
num = 0
i = 0
while True:
i += 1
succs_block = block2.succs()
for succ in succs_block:
child_succs = succ.succs()
succ_list = list(child_succs)
if len(succ_list) != 0:
block2 = succ
num += 1
if num > 2:
block = ori_ret_block
break
if i > 2:
break
return block.start_ea
def find_all_real_block(func_ea):
blocks = idaapi.FlowChart(idaapi.get_func(func_ea))
loop_heads = find_loop_heads(func_ea)
print(f"循环头数量:{len(loop_heads)}----{[hex(loop_head) for loop_head in loop_heads]}")
all_real_block = []
for loop_head_addr in loop_heads:
loop_head_block = get_block_by_address(loop_head_addr)
loop_head_preds = list(loop_head_block.preds())
loop_head_preds_addr = [loop_head_pred.start_ea for loop_head_pred in loop_head_preds]
converge_addr = find_converge_addr(loop_head_addr)
real_blocks = []
if loop_head_addr != converge_addr:
loop_head_preds_addr.remove(converge_addr)
real_blocks.extend(loop_head_preds_addr)
converge_block = get_block_by_address(converge_addr)
list_preds = list(converge_block.preds())
for pred_block in list_preds:
end_ea = pred_block.end_ea
last_ins_ea = idc.prev_head(end_ea)
mnem = idc.print_insn_mnem(last_ins_ea)
size = get_basic_block_size(pred_block)
if size > 4 and "B." not in mnem:
start_ea = pred_block.start_ea
mnem = idc.print_insn_mnem(start_ea)
if mnem == "CSEL":
csel_preds = pred_block.preds()
for csel_pred in csel_preds:
real_blocks.append(csel_pred.start_ea)
else:
real_blocks.append(pred_block.start_ea)
real_blocks.sort()
all_real_block.append(real_blocks)
print("子循环头:", [hex(child_block_ea) for child_block_ea in real_blocks])
ret_addr = find_ret_block_addr(blocks)
all_real_block.append(ret_addr)
print("all_real_block:", all_real_block)
all_real_block_list = []
for real_blocks in all_real_block:
if isinstance(real_blocks, list):
all_real_block_list.extend(real_blocks)
else:
all_real_block_list.append(real_blocks)
for real_block_ea in all_real_block_list:
add_block_color(real_block_ea)
print("\n所有真实块获取完成")
print("===========INT===============")
print(all_real_block_list)
print("===========HEX===============")
print(f"数量:{len(all_real_block_list)}")
print([hex(real_block_ea) for real_block_ea in all_real_block_list], "\n")
all_child_prologue_addr = all_real_block.copy()
all_child_prologue_addr.remove(ret_addr)
all_child_prologue_addr.remove(all_child_prologue_addr[0])
print("所有子序言块相关的真实块地址:", all_child_prologue_addr)
all_child_prologue_last_ins_ea = []
for child_prologue_array in all_child_prologue_addr:
child_prologue_addr = child_prologue_array[0]
child_prologue_block = get_block_by_address(child_prologue_addr)
child_prologue_end_ea = child_prologue_block.end_ea
child_prologue_last_ins_ea = idc.prev_head(child_prologue_end_ea)
all_child_prologue_last_ins_ea.append(child_prologue_last_ins_ea)
print("所有子序言块的最后一条指令的地址:", all_child_prologue_last_ins_ea)
return all_real_block_list, all_child_prologue_addr, all_child_prologue_last_ins_ea
import logging
import time
import angr
from tqdm import tqdm
logging.getLogger('angr').setLevel(logging.ERROR)
def capstone_decode_csel(insn):
operands = insn.op_str.replace(' ', '').split(',')
dst_reg = operands[0]
condition = operands[3]
reg1 = operands[1]
reg2 = operands[2]
return dst_reg, reg1, reg2, condition
def print_reg(state, reg_name):
value = state.regs.get(reg_name)
print(f"地址:{hex(state.addr)},寄存器:{reg_name},value:{value}")
def find_state_succ(proj, base, local_state, flag, real_blocks, real_block_addr, path):
ins = local_state.block().capstone.insns[0]
dst_reg, reg1, reg2, condition = capstone_decode_csel(ins)
val1 = local_state.regs.get(reg1)
val2 = local_state.regs.get(reg2)
sm = proj.factory.simgr(local_state)
sm.step(num_inst=1)
tmp_state = sm.active[0]
if flag:
setattr(tmp_state.regs, dst_reg, val1)
else:
setattr(tmp_state.regs, dst_reg, val2)
while len(sm.active):
for active_state in sm.active:
ins_offset = active_state.addr - base
if ins_offset in real_blocks:
value = path[real_block_addr]
if ins_offset not in value:
value.append(ins_offset)
return ins_offset
sm.step(num_inst=1)
def find_block_succ(proj, base, func_offset, state, real_block_addr, real_blocks, path):
msm = proj.factory.simgr(state)
while len(msm.active):
for active_state in msm.active:
offset = active_state.addr - base
if offset == real_block_addr:
mstate = active_state.copy()
msm2 = proj.factory.simgr(mstate)
msm2.step(num_inst=1)
while len(msm2.active):
for mactive_state in msm2.active:
ins_offset = mactive_state.addr - base
if ins_offset in real_blocks:
msm2_len = len(msm2.active)
if msm2_len > 1:
tmp_addrs = []
for s in msm2.active:
moffset = s.addr - base
tmp_value = path[real_block_addr]
if moffset in real_blocks and moffset not in tmp_value:
tmp_addrs.append(moffset)
if len(tmp_addrs) > 1:
print("当前至少有两个路径同时执行到真实块:", [hex(tmp_addr) for tmp_addr in tmp_addrs])
ret_addr = real_blocks[len(real_blocks) - 1]
if ret_addr in tmp_addrs:
tmp_addrs.remove(ret_addr)
ins_offset = tmp_addrs[0]
print("两个路径同时执行到真实块最后取得:", hex(ins_offset))
value = path[real_block_addr]
if ins_offset not in value:
value.append(ins_offset)
print(f"无条件跳转块关系:{hex(real_block_addr)}-->{hex(ins_offset)}")
return
ins = mactive_state.block().capstone.insns[0]
if ins.mnemonic == 'csel':
state_true = mactive_state.copy()
state_true_succ_addr = find_state_succ(proj, base, state_true, True, real_blocks, real_block_addr, path)
state_false = mactive_state.copy()
state_false_succ_addr = find_state_succ(proj, base, state_false, False, real_blocks, real_block_addr, path)
if state_true_succ_addr is None or state_false_succ_addr is None:
print("csel错误指令地址:", hex(ins_offset))
print(f"csel后继有误:{hex(real_block_addr)}-->{hex(state_true_succ_addr) if state_true_succ_addr is not None else state_true_succ_addr},"
f"{hex(state_false_succ_addr) if state_false_succ_addr is not None else state_false_succ_addr}")
return "erro"
print(f"csel分支跳转块关系:{hex(real_block_addr)}-->{hex(state_true_succ_addr)},{hex(state_false_succ_addr)}")
return
msm2.step(num_inst=1)
return
msm.step(num_inst=1)
def angr_main(real_blocks, all_child_prologue_addr, all_child_prologue_last_ins_ea, func_offset, file_path):
proj = angr.Project(file_path, auto_load_libs=False)
base = proj.loader.min_addr
func_addr = base + func_offset
init_state = proj.factory.blank_state(addr=func_addr)
init_state.options.add(angr.options.CALLLESS)
path = {key: [] for key in real_blocks}
ret_addr = real_blocks[len(real_blocks) - 1]
first_block = proj.factory.block(func_addr)
first_block_insns = first_block.capstone.insns
first_block_last_ins = first_block_insns[len(first_block_insns) - 1]
for real_block_addr in tqdm(real_blocks):
if ret_addr == real_block_addr:
continue
prologue_block_addr = 0
child_prologue_last_ins_ea = 0
if len(all_child_prologue_addr) > 0:
for index, child_prologue_array in enumerate(all_child_prologue_addr):
if real_block_addr in child_prologue_array:
prologue_block_addr = child_prologue_array[0] + base
child_prologue_last_ins_ea = all_child_prologue_last_ins_ea[index]
state = init_state.copy()
print("正在寻找:", hex(real_block_addr))
def jump_to_address(state):
state.regs.pc = base + real_block_addr - 4
def jump_to_child_prologue_address(state):
state.regs.pc = prologue_block_addr - 4
if prologue_block_addr == 0:
if real_block_addr != func_offset:
proj.hook(first_block_last_ins.address, jump_to_address, first_block_last_ins.size)
else:
proj.hook(first_block_last_ins.address, jump_to_child_prologue_address, first_block_last_ins.size)
proj.hook(child_prologue_last_ins_ea, jump_to_address, 4)
ret = find_block_succ(proj, base, func_offset, state, real_block_addr, real_blocks, path)
if ret == "erro":
return
hex_dict = {
hex(key): [hex(value) for value in values]
for key, values in path.items()
}
print("真实块控制流:\n", hex_dict)
return hex_dict
from collections import deque
import idaapi
import idautils
import idc
import keystone
ks = keystone.Ks(keystone.KS_ARCH_ARM64, keystone.KS_MODE_LITTLE_ENDIAN)
def patch_ins_to_nop(ins):
size = idc.get_item_size(ins)
for i in range(size):
idc.patch_byte(ins + i, 0x90)
def get_block_by_address(ea):
func = idaapi.get_func(ea)
blocks = idaapi.FlowChart(func)
for block in blocks:
if block.start_ea <= ea < block.end_ea:
return block
return None
def patch_branch(patch_list):
for ea in patch_list:
values = patch_list[ea]
if len(values) == 0:
continue
block = get_block_by_address(int(ea, 16))
start_ea = block.start_ea
end_ea = block.end_ea
last_ins_ea = idc.prev_head(end_ea)
if len(values) == 2:
flag = False
for ins in idautils.Heads(start_ea, end_ea):
if idc.print_insn_mnem(ins) == "CSEL":
condition = idc.print_operand(ins, 3)
encoding, count = ks.asm(f'B.{condition} {values[0]}', ins)
encoding2, count2 = ks.asm(f'B {values[1]}', last_ins_ea)
for i in range(4):
idc.patch_byte(ins + i, encoding[i])
for i in range(4):
idc.patch_byte(last_ins_ea + i, encoding2[i])
flag = True
if not flag:
ins = idc.prev_head(last_ins_ea)
succs_list = list(block.succs())
csel_ea = succs_list[0].start_ea
condition = idc.print_operand(csel_ea, 3)
encoding, count = ks.asm(f'B.{condition} {values[0]}', ins)
encoding2, count2 = ks.asm(f'B {values[1]}', last_ins_ea)
try:
for i in range(4):
idc.patch_byte(ins + i, encoding[i])
for i in range(4):
idc.patch_byte(last_ins_ea + i, encoding2[i])
except:
print("except")
else:
encoding, count = ks.asm(f'B {values[0]}', last_ins_ea)
for i in range(4):
idc.patch_byte(last_ins_ea + i, encoding[i])
print("pach over!!!")
def find_all_useless_block(func_ea, real_blocks):
blocks = idaapi.FlowChart(idaapi.get_func(func_ea))
local_real_blocks = real_blocks.copy()
useless_blocks = []
ret_block_addr = local_real_blocks[len(local_real_blocks) - 1]
queue = deque()
ret_block = get_block_by_address(ret_block_addr)
queue.append(ret_block)
while len(queue) > 0:
cur_block = queue.popleft()
queue.extend(succ for succ in cur_block.succs())
ret_flag = False
for succ in cur_block.succs():
local_real_blocks.append(succ.start_ea)
end_ea = succ.end_ea
last_ins_ea = idc.prev_head(end_ea)
mnem = idc.print_insn_mnem(last_ins_ea)
if mnem == "RET":
ret_flag = True
if ret_flag:
break
for block in blocks:
start_ea = block.start_ea
if start_ea not in local_real_blocks:
useless_blocks.append(start_ea)
print("所有的无用块:", [hex(b) for b in useless_blocks])
return useless_blocks
def patch_useless_blocks(func_ea, real_blocks):
useless_blocks = find_all_useless_block(func_ea, real_blocks)
for useless_block_addr in useless_blocks:
block = get_block_by_address(useless_block_addr)
start_ea = block.start_ea
end_ea = block.end_ea
insns = idautils.Heads(start_ea, end_ea)
for ins in insns:
patch_ins_to_nop(ins)
print("无用块nop完成")
def main(func_ea):
file_path = idc.get_input_file_path()
all_real_block_list, all_child_prologue_addr, all_child_prologue_last_ins_ea = find_all_real_block(func_ea)
patch_list = angr_main(all_real_block_list, all_child_prologue_addr, all_child_prologue_last_ins_ea, func_ea, file_path)
patch_branch(patch_list)
main(0x41D08)
from collections import deque
import ida_funcs
import idaapi
import idc
def get_block_by_address(ea):
func = idaapi.get_func(ea)
blocks = idaapi.FlowChart(func)
for block in blocks:
if block.start_ea <= ea < block.end_ea:
return block
return None
def find_loop_heads(func):
loop_heads = set()
queue = deque()
block = get_block_by_address(func)
queue.append((block, []))
while len(queue) > 0:
cur_block, path = queue.popleft()
if cur_block.start_ea in path:
loop_heads.add(cur_block.start_ea)
continue
path = path + [cur_block.start_ea]
queue.extend((succ, path) for succ in cur_block.succs())
all_loop_heads = list(loop_heads)
all_loop_heads.sort()
return all_loop_heads
def find_converge_addr(loop_head_addr):
converge_addr = None
block = get_block_by_address(loop_head_addr)
preds = block.preds()
pred_list = list(preds)
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-1-22 09:22
被教教我吧~编辑
,原因: fix








