# 缘起
最近在开发某款 APP 的功能扩展时,我使用 Frida 编写了大量逻辑,但不想再逐行翻译成 Xposed 代码。于是决定将 Frida 直接固化到 APP 中。
最初尝试使用 frida-gadget,但在 Android 16 上遇到问题:脚本完全不执行,也没有任何错误提示,只好放弃。
在网上搜索后,没有找到便捷的持久化方案,于是决定自己动手实现。
我的目标是:只需运行一行命令,就能自动打包出 Xposed 模块、已固化 Frida 脚本的 APP 包,以及可注入运行 Frida 脚本的 .so 和 .dll 文件。
最终,这个目标顺利实现了。如果你只是想打包 Frida 脚本,而不关心具体原理,可以直接使用以下工具:
354K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6K6N6r3c8Q4x3X3c8E0K9h3y4J5L8$3u0D9L8$3y4C8i4K6u0r3k6Y4u0A6M7r3q4U0K9#2)9J5c8R3`.`.
# 自编译 Frida
既然要自己动手,自然要做得尽善尽美。一方面需要掩盖 Frida 的某些特征,另一方面也要尽量减小体积。此外,我还希望将脚本直接嵌入二进制文件中,而不是作为独立文件存在。于是,我开始研究如何自行编译 Frida,类似于实现一个自定义的 frida-gadget。
首先,我们来看一下 Frida 的代码架构:
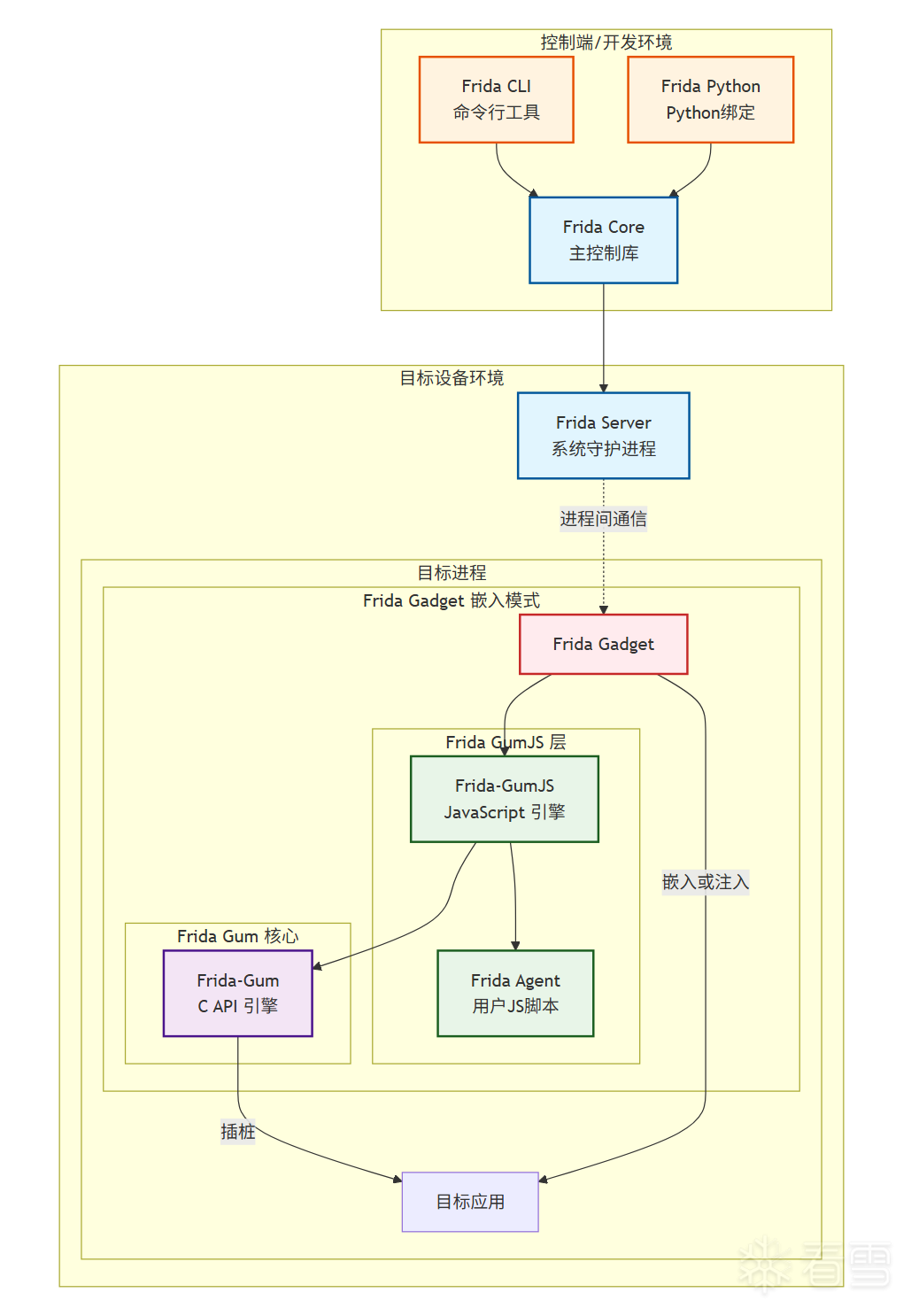
(注:此为简化示意图。实际上,frida-inject 和 frida-server 注入的是 frida-agent,但整体结构类似。)
可以看到,Frida Gadget 实际上是通过调用 Frida-GumJS 来执行我们的脚本。因此,我们也可以编写一个程序,调用 Frida-GumJS 来执行脚本。为了实现这一点,首先需要编译出 Frida-GumJS 库。
Frida-GumJS 通常包含两个引擎:V8 和 QuickJS。V8 执行效率高,但体积较大;QuickJS 体积较小。为了减小最终生成的二进制文件体积,我关闭了 V8 和内置的 Database,并参考 Florida 的 CI 流程,编写了一个 GitHub CI 来编译 Frida-GumJS:
7e4K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6r3M7X3W2d9k6h3u0#2K9h3I4V1i4K6u0r3k6Y4u0A6M7r3q4U0K9#2)9J5k6r3W2F1K9X3g2U0N6l9`.`.
接着,我创建了一个 xmake 项目,首先实现调用 GumJS 执行脚本的功能:
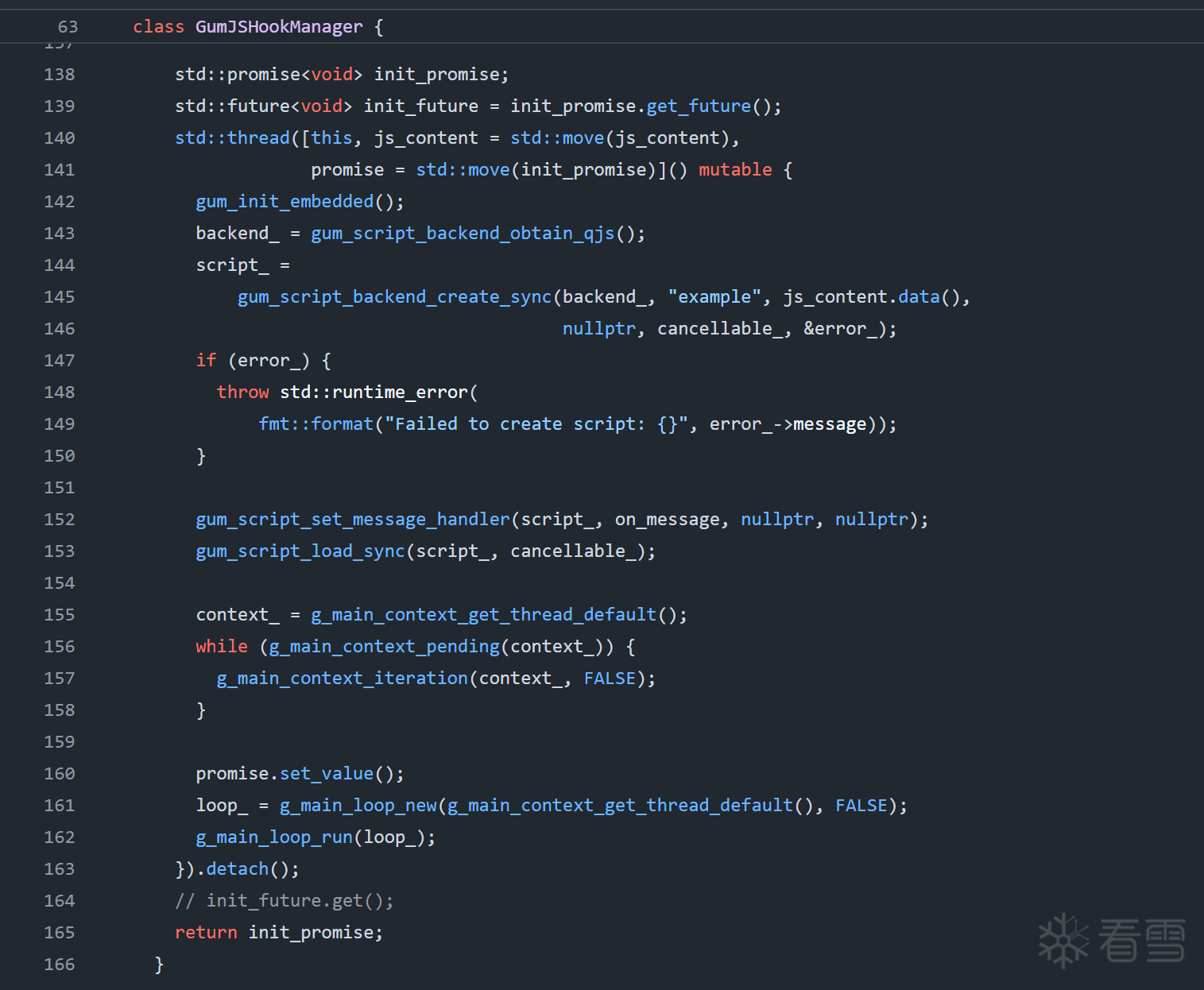
为了便于后续嵌入 JS 脚本,我设计了一个带有特定 Magic 标记的结构体:
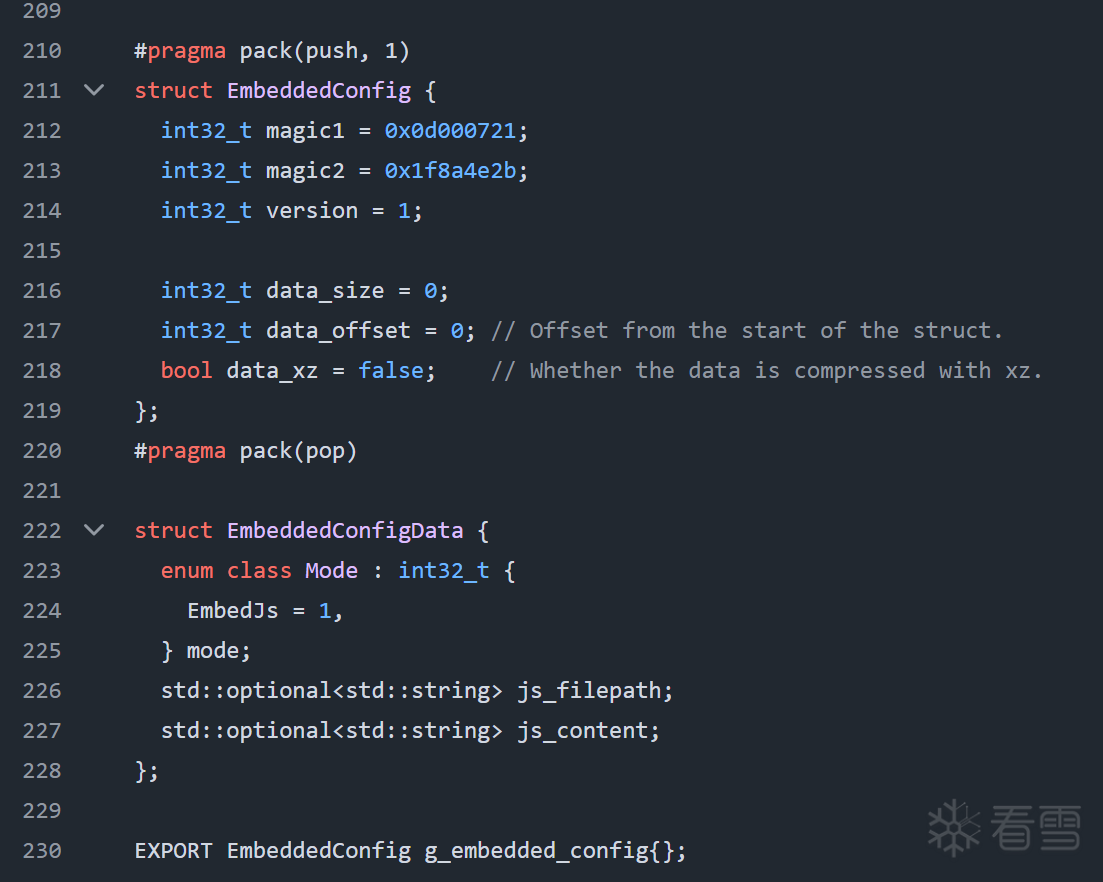
这样,在生成 .so 文件时,就可以通过扫描 Magic 标记找到这个配置结构,然后通过设置 data_size 和 data_offset 来指定脚本数据在二进制文件中的存储位置。
接下来,我们需要编写一个 CLI 工具,将脚本数据嵌入到二进制文件中。这里我选择了使用 Rust 来实现。
# 将数据嵌入二进制文件
## ELF 文件编辑
ELF 文件的主要结构包括 Section 和 Segment,其中数据通过 Segment 映射到内存中。我们只需新建一个 Segment,将脚本数据放入其中,并确保其加载到内存中。然后,计算出该数据映射的虚拟地址与 g_embedded_config 虚拟地址之间的偏移量,这样我们自制的 frida-gadget 就能正确加载数据了。
听起来很简单,我们来实现一下:
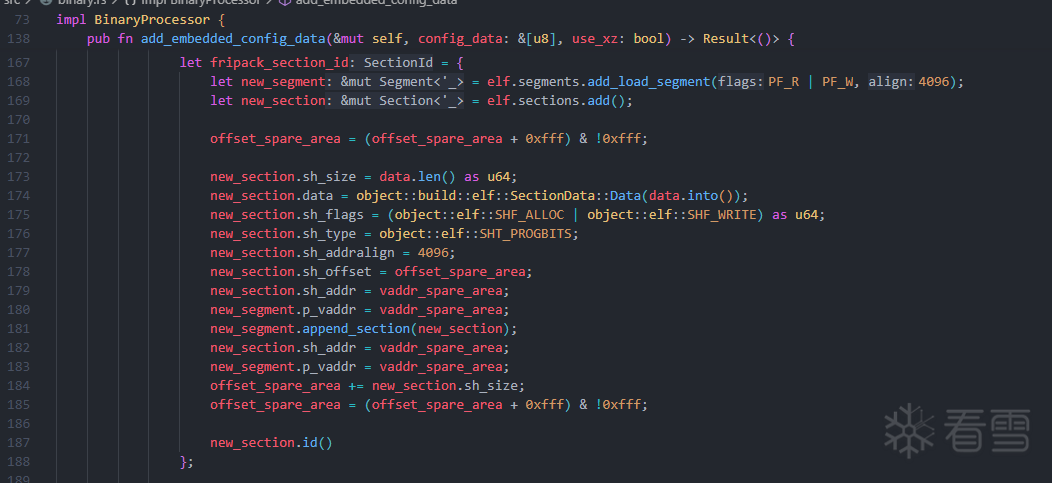
需要特别注意:对于需要加载到内存中的 Segment(PT_LOAD),其 vaddr 必须按 4K 或 16K 对齐,否则 dl 可能不会正确映射,且不会报错。
同时,由于新增了 Segment 和 Section,我们还需要扩展 ELF 文件头的大小:
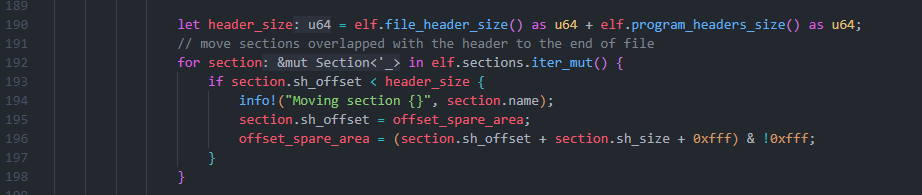
运行后却发现报错:.note sh_offset at 0x270, must be larger than 0x28a。这是怎么回事?原来是因为新增的 Segment 和 Section 导致 ELF 头变大,与原有的部分 Section 发生了重叠。我们需要将这些重叠的 Section 在文件中的数据及其 p_offset 移动到文件末尾:
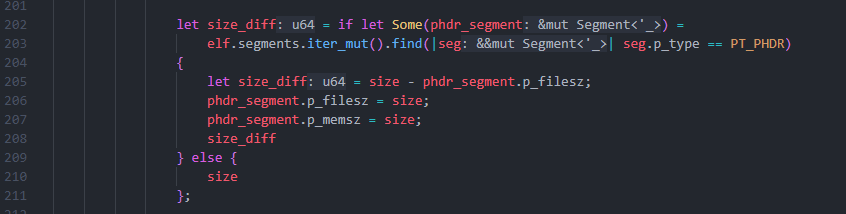
再次运行,这次没有报错了。但将文件放到手机中加载时,又出现了新错误:PT_PHDR segment is not covered by a PT_LOAD segment。这个问题比较奇怪,网上资料也很少。我猜测 PT_PHDR Segment 本身不会被映射到内存中,它需要一个 PT_LOAD Segment 来帮助加载。于是,我们找到覆盖 PT_PHDR Segment 的那个 Segment,并将其扩展的大小同步到 PT_PHDR Segment:

[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。






