-
-
[原创]PE分析小工具开发流水账
-
发表于: 2025-11-11 17:40 1139
-

此次修改于2026/6/12,将原帖PE分析小工具开发流水账(一)修改为原PE分析小工具开发流水账(一)(二)合并版本,内容未变。
原帖PE分析小工具开发流水账(一)内容:
最近想开发一个可以查看PE文件各字段值的小工具,虽然GitHub上肯定能找到很多这样的很厉害的工具,很多现代工具也集成了这样的功能,但我其实只是想作为学习项目来开发一个这样的小工具。
1.项目目标
内核:C++
界面:使用平台API
基本功能:解析一个PE文件的各个字段,并在文件被混淆、加壳等异常情况时成功报错。
扩展功能:处理特定壳处理过的PE文件,不是那种很复杂的,就比如UPX这种压缩壳啊,或者其他的一些简单壳。
2.当前设计思路
这是我初步设计的一个工作图:
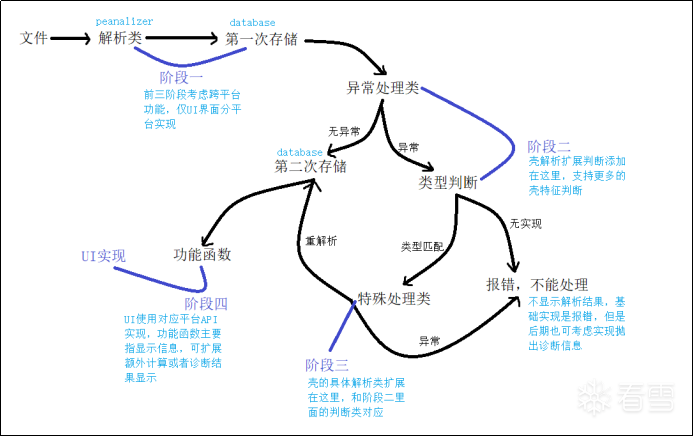
3.一些问题
问题一:PE文件分析时上下文依赖的难拆分与可维护性冲突问题
刚开始只设计了三个解析阶段,也就是读取——分析——输出的一个简单流程。但这里会产生一个超级大类,虽然上下文非常容易读取,但此时变得十分难以维护和扩展。于是就设计了现在的这个框架,将原本的分析工作分成了三个阶段,在第一个阶段中完成全文件的初步解析,并储存上文依赖字段,第二个阶段完成扩展壳特征分析,第三个阶段为添加壳的字段解析功能。这时二三阶段属于扩展,可以轻松添加与删除,虽然仍不是完全独立的,需要依赖一阶段存储的关键字段。且数据处理单独建立了一个类,存储输出的匹配结果和诊断信息。
问题二:如何处理字段映射的格式转换以及正确性
这里我的设计思路是依赖于加载器关键字段作为标杆。什么样的文件是PE文件?PE文件本质上就是一种格式,假设一个混淆过PE文件被修改了1%,比如只改了MZ头,它不能运行,但是我可以说他是一个被修改被混淆过的PE文件。但一个标准的PE文件被修改了99%,我可以说它已经不是PE文件了。而PE文件,或者说恶意软件,它们希望的结果必然是执行,以上面说的修改MZ头为例,其实这种修改并没有什么意义,只是我说的一种极端情况而已,因为一旦MZ头被修改,它一定会在加载器那里报错,变成不可执行的文件。所以说加壳啊,混淆啊,本质上都不会修改哪些加载器依赖的字段,所以我可以大概率的信任这些字段,信任的字段不仅包括信任值,也包括偏移,如果加载器有机会找到那些值,我也可以,所以在第一阶段的处理中,我就是逐字节按顺序提取那些关键字段,至于其他字段,他们是后面阶段要处理的事情。
问题三:极端情况
如问题二中的假设那样,一个文件仅仅被修改了MZ头,这时工具直接报错看起来好笨,因此我认为也不能完全信任加载器依赖字段。所以这时需要尽可能的诊断更多的依赖字段,我设定的标准是,如果一半以上的依赖字段出现问题,基本上就可以判断这里不是一个有效的PE文件,分析它并没有什么价值,可以直接报错了。但对于某些值来说,是强烈关联的,必然machine值与magic值,如果magic值被恶意篡改,我也许需要进行反推和预分析,我目前开发到这里,出现了滚雪球一样的需求延申,这里也是需要平衡的地方。像magic值,会关系到后面按照什么结构来进行后续分析,所以这也是不得不解决的一个问题。
问题四:简洁性设计
PE文件中存在不止一处的字段关联性,比如上面提到的machine与magic字段关联,还存在比如实际偏移和值规定偏移的区别。还有比如节区数的规定和实际节区数,虽然正常解析会忽略那些多出来的节区,但是在代码执行中任何的空隙都能够指定指针进行跳转执行,所以这些是必须考虑的。我认为如果每次遇到一个这样的问题就全文解析一遍会非常浪费时间,因此怎么设计的简洁很重要,目前我没有想到怎么尽可能少次的读取和分析文件,未来想到的话会继续在流水账里面分享。
好多问题……如果有一天我真能做完,我就最终把它开源。
原帖PE分析小工具开发流水账(二)内容:
最近随便看了一下其他类似工具的处理,我修改了一个程序的MZ头然后把它放到不管是CFF Explorer也好还是PEview也好,感觉都是采用的保守式分析。众所周知,MZ签名在最开头,当MZ签名被修改后,后面就不进行分析了,但是依然还是合法文件,而不是直接报错不是可执行文件不能分析。然后又试了一下改magic字段看看咋样,也是只分析到前面一些字段,后面保守式仅显示十六进制数据。
emmm,之所以想看看其他工具怎么处理,就是因为开发其实也遇到一点问题,就是在极端情况下假设一些关键字段被修改(虽然其实现实中可能没什么意义),但还是要考虑一些奇奇怪怪的情况。下面还是梳理一下最近又遇到的一些问题。
问题一:可选头分析的依赖问题
可选头之所以叫可选头我想就是因为它是分类讨论的,大概有32位、64位还有ROM架构的这个问题。目前我想先不考虑ROM架构,只做一个最小可执行版的。但是加载一个文件时怎么知道选择哪个结构呢,或者说,我在静态分析时怎么知道我要按照哪个结构分析呢。magic字段是最有说服力的,但是也不排除它的错误,归根结底就是,不能因为一个关键字段的修改而放弃后续的分析。但是其实这个架构问题,并不仅仅只是涉及到这一个字段,像是machine值啊,在合法情况下也要和这个东西匹配。所以我想留一个启发式分析的空给这种反推式分析结构。但是当多个字段出现错配时,这种分析方式也无能为力。所以就引发了下一个问题。
问题二:联合检验和反推式验证平衡点
除了在可选头中出现这种联合性检验问题,还有就是节区头的检验问题。一个健壮的解析器大概是不能仅仅依赖于关键字段的,比如NumberOfSections这样的字段。现实的恶意软件中,可能出现跳转执行这样的情况吧,万一后面还有节区咋办。然后我现在想的就是自己检验这个节区是不是节区,但是怎么检验呢,大概是根据里面字段的合法性检验。首先一个问题就是数量,我想的就是每40个字节一读取,然后看看它是不是,但是万一哪个什么奇怪的文件它搞个1000个节区咋搞,虽然它的NumberOfSections可能只写了几个。然后我设定了一个最大值128,如果它真搞1000个那这也解析不了,就报错算了。可现实就是某些壳啊什么的本来就不会改的所有值都合法,比如Name字段啊搞一点奇奇怪怪的值进去。既然知道现实中这个情况,那又怎么保证检验的成功性呢,可能需要置信度来判断吧,这个还在解决中。
问题三:节区属性判断(Characteristic字段处理)问题
关于属性问题,其实作为解析工具重点肯定不是放在像加载器一样搞清楚它到底是什么属性,但是对于某些节区,比如text段不应该有可执行属性还是需要诊断的。除了常见值,Characteristic字段问题就在于它有很多组合,按位计算,出现常见值容易解决,但是非常见值应该怎么处理。就类似于一个莫名其妙的值,可能被解析为可执行,怎么判断呢,这个部分也在设计中。目前想到的是分析以下几个关键属性。
struct section_imformation {
bool mem_execute_ = false; // 内存可执行
bool mem_read_ = false; // 内存可读
bool mem_write_ = false; // 内存可写
bool mem_shared_ = false; // 内存共享
bool cnt_code_ = false; // 包含可执行代码
bool cnt_initialized_data_ = false; // 包含已初始化数据
bool cnt_uninitialized_data_ = false; // 零初始化
……
}----------------------------------------分割线 以下内容为2026/2/27更新
最近发现之前的结构太乱了,所以把诊断的中文输出全部以固定格式存储起来了。过去设计的数据结构大概是,一个结构体记录每一块区域的内容,分类成偏移、错误信息、普通信息这一类的东西,然后直接以字符串形式存储。现在诊断部分差不多能把头部关键的地方诊断了,想加个界面先做个最小可执行的程序,但是在加界面时第一个问题就是编码问题,以字符串存储占位置不说还很麻烦。在修改中,新的设计想法是,把原本的一句话拆成几个内容,以模板形式存储,少量字符串也以英文形式存起来,这样在未来加界面时不仅可以直接根据整个结构来进行翻译,而且还将导出功能变成了可能。可以做到界面和程序本体分离。下面就是我想到的新结构。
namespace Core {
// 分析对象
enum class Object : uint8_t {
SIGNATURE, // 签名
FIELD, // 字段本身
ADDRESS_IN_FIELD, // 根据字段计算出的地址(适用于简单情况)
STRUCTURE, // 结构
IMFORMATION_IN_FIELD, // 字段所示的信息
STRUCTURE_ADDRESS // 结构地址(适用于复杂情况)
};
// 严重程度
enum class Severity : uint8_t {
INFO_LOW, // 普通信息
SUSPICIOUS, // 可疑
WARNING_MED, // 警告
ERROR_HIGH // 错误
};
// 包含诊断信息
enum class DiagCategory : uint8_t {
/* 签名(SIGNATURE)、字段本身(FIELD) */
VALUE_MISMATCH, // 【{severity}】{description} -> {field_name}字段异常,期望/阈值/参考值:{expected},实际值:{actual}
INVALID_VALUE, // 【{severity}】{description} -> {field_name}字段值无效,实际值:{actual}
/* 根据字段计算出的地址(ADDRESS_IN_FIELD) */
EXCURSION_ANOMALY, // 【{severity}】{description} -> {field_name}所示地址异常,值:0x{address}
ADDRESS_OUT_OF_RANGE, // 【{severity}】{description} -> {field_name}地址超过文件/内存范围,值:0x{address}
/* 结构(STRUCTURE) */
ABNORMAL_LENGTH, // 【{severity}】{description}长度异常,实际长度:{actual}字节
STRUCTURE_MISSING, // 【{severity}】{description}区域缺失
/* 字段所示的信息(IMFORMATION_IN_FIELD) */
DETAILED_INFORMATION, // 【{severity}】{description} -> {field_name}:{info1}
/* 结构地址(STRUCTURE_ADDRESS) */
REGULAR_ISSUE, // 【{severity}】{description}{info1}
INDEXED_ISSUE, // 【{severity}】{description}[{index}]{info1}
/* 其他问题 */
RELATIONSHIP_ISSUE, // 【{severity}】{description} -> {field_name}与{compared_description} -> {compared_field_name}:{info1}
ADDITIONAL_INFORMATION // {info2}
};
// 对象诊断结果所在背景以及包含的诊断信息
struct Diagnostic {
Object object; // 诊断对象
Severity severity; // 严重程度
DiagCategory category; // 诊断类别(用哪种模板)
/* 提示信息 */
std::string info1; // 提示信息1
std::string info2; // 提示信息2
/* 基础参数 */
std::string field_name; // 字段名,如"PE Signature"
std::string description; // 结构名,如"File Header"
uint64_t offset; // 文件偏移位置
/* 字段值问题 */
uint64_t expected_value; // 期望值/阈值/参考值,如"0x00004550"
uint64_t actual_value; // 实际值,如"0x12345678"
/* 地址问题 */
uint64_t address; // 地址值,如"0x00400000"
/* 其他信息 */
uint64_t index; // 索引,如节区头索引0、1、2...
std::string compared_field_name; // 相关字段名,如"SizeOfHeaders"
std::string compared_description; // 相关结构名,如"Optional Header"
};
}----------------------------------------分割线 以下内容为2026/3/4更新
改结构的时候又发现一个问题,之前一直想做到权责分离,分析类只管分析,数据类只管数据,本来是流水线式直接带过去了,每一步分析类把数据传入数据类,也就是数据类只进不出,只在每一步中进行迭代,最终获得输出。至于读取前文问题,之前在分析大类里面弄了一个共享结构,到现在发现根本不够用,搞得越来越大,还不得不从数据类里面找信息,所以或许应该把共享类删掉?然后不搞分离了?目前还没有删掉,因为删掉要改的东西有点多,先这样放着算了。
----------------------------------------分割线 以下内容为2026/3/19更新
我要爆炸了!!!现在只先让它显示了前一小部分,刚开始显示一堆莫名其妙的东西,debug了半天发现是文件没找到路径,不能处理中文路径,吓死我,还以为哪个指针有问题。结果换了个英文路径还行能用了,结果说啥,DOS Stub算了个什么东西,长度都不够。这现在做的东西,还一堆东西没显示出来。里面似乎还有除零问题。
----------------------------------------分割线 以下内容为2026/6/8更新
我的项目开源了。
073K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6o6j5h3I4H3j5i4u0J5L8%4c8Q4x3V1k6b7c8g2)9J5k6q4m8S2M7Y4y4A6L8X3N6f1L8$3!0D9
欢迎讨论交流。
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
赞赏
|
|
|---|---|
|
|
|




