-
-
苹果FairPlay中发现的混淆技术分析
-
发表于: 2025-10-20 16:45 5103
-

苹果FairPlay中发现的混淆技术分析
以下是对文章《Analysis of Obfuscation Found in Apple FairPlay》的翻译,原文来自 [5e1K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6F1K9h3y4G2L8r3!0Q4x3X3g2V1k6i4k6Q4x3V1k6W2L8W2)9J5c8X3u0D9L8$3N6Q4x3V1k6X3j5h3W2J5M7r3I4S2P5g2)9J5k6r3q4H3M7r3I4W2i4K6u0V1L8$3u0X3N6i4y4U0j5i4c8A6L8$3&6Q4x3V1k6Q4y4f1b7`.
希望对你有用
苹果FairPlay中发现的混淆技术分析
FairPlay是苹果公司开发的一套用于数字版权管理(DRM,Digital Rights Management)的算法集合。FairPlay目前用于管理iOS设备上应用安装过程中的解密操作。众所周知,苹果通过App Store分发的所有应用程序都采用IPA文件格式。IPA文件格式包含加密信息,这些信息由操作系统用于安装应用程序。FairPlay负责确保解密密钥和整个解密过程的安全,以防止未经授权的用户解密IPA文件内容并分享应用程序(尤其是付费应用)的代码。
本文将总结我在分析运行FairPlay的macOS用户空间守护进程时发现的一些静态保护措施。所有信息均基于文章发布时的最新情况,分析的二进制文件提取自macOS 13.5.1。
警告:本文仅提供对FairPlay及其混淆技术的入门级概述,概述其总体结构和概念,但有意避免深入探讨苹果的实际实现细节(以及如何破解这些技术),这可能是为了避免收到苹果公司的停止函或法律诉讼。
DRM系统与苹果应用的保护
保护数字形式的知识产权一直是分发版权材料的公司的重要目标。如何在分发内容的同时防止用户复制、查看、编辑和重新分发?当前大多数系统使用DRM技术。简而言之,DRM系统的工作原理如下:它们接收一个不可读的秘密输入(例如电影、图片或算法的原始文件),处理这些信息,并输出原始内容。整个过程尽量隐藏获取原始信息的方法。DRM系统最常用于观看受版权保护的内容:用户与服务提供商签订合同,服务商承诺发送用户请求的信息(电影、电视剧、书籍)。为防止内容被复制(合同规定只有一位授权用户可以查看),信息必须以不可复制或导出的方式访问。
从苹果的视角来看,假设我们想通过App Store下载一款付费应用或新游戏。我们完成交易后,设备会收到一个独立的安装包,准备安装。从技术角度看,如果没有保护措施,用户可以将应用安装包复制并分享给其他人。结果如何?苹果和开发者将因此损失收入,因为复制的安装包是免费的。由于IPA文件格式本质上是一个独立的容器,如果没有技术措施,应用程序共享将无法阻止。这正是FairPlay™技术的用武之地。
如何保护IPA文件中的信息?显然,我们需要以某种方式隐藏档案内容;这样,即使攻击者从iPhone中提取IPA文件,也无法访问内容。信息只能由负责安装应用程序的系统进程读取。下一个问题是:如何隐藏内容?这开启了一个复杂的技术领域。最简单且成本较低的方法之一是使用密钥加密信息。通过调用decrypt(content, key),信息即可恢复为可读状态。
然而,密钥的选择并非简单问题。在安装过程中,信息最终需要被解密,即恢复为可读状态。能否为所有售出的iPhone设置一个静态密钥?显然不行。静态(即硬编码)密钥会带来诸多问题:攻击者只需找到一个密钥,就能解密所有App Store创建的档案。一旦密钥暴露,破解的安装包将迅速在网络上传播。一种看似可行的方法是按设备分配不同的密钥(例如,iPhone 12使用一个密钥,iPhone 13使用另一个),利用硬件特性。但这种方法也不可行,因为密钥可能在多个设备间共享。
实际的解决方案是生成“动态”密钥,即根据安装设备、支付应用的Apple账户以及交易期间交换的元数据(以防止伪造)生成密钥。苹果在收到App Store的新请求时对IPA文件内容进行加密,使用与Apple账户关联的公钥加密。设备接收档案后,解压缩并使用设备内的私钥解密二进制文件。
解密发生的点是一个重要的集中化节点,可能被攻击者用来尝试解密IPA文件。如果攻击者能够弄清楚如何从设备和关联账户生成私钥,苹果的保护系统将立即失效。为了应对伪造风险,苹果在设备中加入了一些机制,向云服务(App Store、iCloud、Apple Signing)证明数据包确实来自苹果设备,而非模拟设备。然而,由于技术限制,无法100%证明“我不是模拟设备,请给我二进制文件,我是[myaccount@icloud.com]”。
静态分析与混淆技术
FairPlay是苹果在知识产权保护方面的核心技术之一。苹果开发了多项专利来描述和保护这项技术,例如美国专利US8934624B2(将数字内容单位的权利与下载分离)和欧洲专利ES2373131T3(使用解密密钥安全分发内容)。保护解密过程的工作方式是另一组“反逆向工程”技术的核心目标,这些技术被称为软件混淆。
我们知道,在分析软件的多种技术中,静态分析是一种无需执行程序即可深入调查软件特定部分的方法。静态分析的主要技术是逆向工程,通过从原始二进制代码推断信息来重建原始代码。
原始二进制文件主要包含两类信息:数据和指令。通过一系列步骤,工具如Ghidra、IDA或Binary Ninja可以重建大部分原始源代码。虽然重建不完美,但软件分析师能够推断出软件的许多语义:它如何工作、调用哪些方法、使用操作系统的哪些信息等。
通过逆向工程,可以较为精确地推导出FairPlay用于解密内容的算法。通过分析数据,可能推断出密钥的构造方式,经过足够努力,攻击者可能开发出解密工具。这对苹果及其投资者来说是个问题。保护指令和数据的解决方案是应用混淆技术,使逆向工程分析更加困难。
混淆技术属于计算机科学中的软件安全学科,旨在保护程序中的代码和信息。混淆的应用包括:保护知识产权、增加逆向工程难度以防止发现漏洞、缓解漏洞利用。这些技术应用于程序的语法(即原始指令),隐藏原始语义。操作原始代码非常复杂,需要坚实的基础以避免副作用。
在接下来的段落中,我们将看到FairPlay如何隐藏指令和数据。这些技术是否真正有效?我们将在文章末尾尝试回答这个问题。需要注意的是,混淆和代码保护技术必须在每次发布时更新,因为没有永久的保护方案。通过混淆,我们可以复杂化逆向工程的尝试,但无法完全阻止二进制文件的分析。
fairplayd守护进程
在接下来的段落中,我们将详细分析苹果操作系统家族中的用户空间守护进程。FairPlay不仅限于iOS移动平台:macOS也使用FairPlay通过安全通道传输受保护的数字内容(电影、电视剧等)。这一子技术称为FairPlay Streaming,通过加密内容分发版权内容。有关其工作原理的高层次概述可参考《FairPlay Streaming Overview》。
我们希望了解FairPlay在macOS中的使用情况,并检查其算法是否通过混淆技术得到保护。我们发现,FairPlay的管理主要由位于/System/Library/PrivateFrameworks文件夹中的CoreFP.Framework(核心FairPlay框架)负责。私人框架是一组专用于macOS特定功能的库,被视为私有,仅对苹果应用程序有效。
CoreFP.Framework目前被Safari和AMPLibraryAgent等应用和守护进程使用。提示:如果想知道某个私有框架的当前使用情况,可以运行命令lsof | grep -i [name_framework],其中name_framework是框架库的名称。结果将显示打开该私有框架的活跃进程列表。在这里,我们关注AMPLibraryAgent。AMPLibraryAgent是一个用户空间守护进程,用于管理用户的媒体(TV.app和Music.app)。它充当苹果服务器发送的加密内容与通过TV.app和Music.app交互的解密内容之间的中间进程。
fairplayd是由AMPLibraryAgent调用的守护进程,实际负责解密内容。我们开始分析CoreFP.Framework文件夹的内容。尽管私有框架存储在动态缓存dyld中,但CoreFP.Framework的二进制文件无需用户对动态缓存进行特殊操作即可访问。在CoreFP中,我们找到CoreFP和fairplayd。CoreFP是系统进程使用的库,而fairplayd是用户空间守护进程。用户空间守护进程使用内核组件FairPlayIOKit。
我们提取fairplayd的x86_64版本,并通过命令lipo -extract x86_64 fairplayd ~/fairplayd保存到指定文件夹。fairplayd文件是一个标准的Mach-O可执行文件,头部没有特别值得注意的字段。我们将其导入逆向工程工具(可选择Ghidra、IDA、Binary Ninja或Hopper)。本文使用IDA以方便说明,但需注意在其他工具中导入二进制文件时要格外小心(原因将在文章末尾解释)。我们让IDA解析二进制文件中的信息(通过段解析、反汇编、反编译)。

默认情况下,IDA打开二进制文件并定位到主符号_main,即fairplayd守护进程的入口点。我们立即感受到混淆的威力,很快发现整个二进制文件都经过精心设计以混淆所有指令。反编译器的输出进一步证实了这一点,以下是一个简短片段:
1 2 3 4 5 6 7 8 9 10 | v298 = &v297;v297 = (((unsigned int) v298 & 0x52491520 | (2 * (_DWORD) v298) & 0x80120A40) ^ 0x40090520) + ((-1704077140 - ((unsigned int) v298 & 0x8924A850)) & 0x8924A854) + ((((unsigned int) v298 & 0x24924288) + 689062540) & 0x24924288 | (2 * (_DWORD) v298) & 0x506D9510);v302 = 62;((void (__fastcall *)(__int64, _QWORD, _QWORD, _QWORD))((char *) *(&off_1002B0BF0 + (unsigned int)(unsigned __int8)((unsigned __int8) v298 ^ byte_100237430[byte_1002AEEF0[(unsigned __int8) v298] ^ 0x3A]) + 944) - 790860942))(31LL, 0LL, 0LL, 0LL);LODWORD(v303) = 1312628203 * ((unsigned int) &v303 ^ 0x4EBE92AB) + 8;((void (__fastcall *)(unsigned __int64 *))((char *) *(&off_1002B0BF0 + (unsigned int)(unsigned __int8)(byte_100237330[byte_1002AEDF0[(unsigned __int8) &v297] ^ 0x18] ^ (unsigned __int8) &v297) + 532) - 1051853286))(&v303);LODWORD(v303) = 2064956458 - 1106503637 * (((unsigned int) &v303 - 2 * ((unsigned int) &v303 & 0x6F01D10) + 116399381) ^ 0x92F4EBC6);sub_10015D450(&v303);v21 = HIDWORD(v303);v22 = (HIDWORD(v303) == 1923298241) | 2; |
惊慌失措! 面对这样的代码,分析师的选择不多:要么放弃逆向工程,要么深入调查。大多数应用混淆技术的开发者希望分析师选择放弃。如果分析应用行为过于复杂,逆向工程就不值得。然而,混淆必须足够完善,否则可能出现重大失误。本文将尝试通过简单查看原始代码来识别一些常见的混淆模式。接下来的段落将介绍一些混淆技术及其实现方式。
在继续之前,需要说明不同的混淆技术根据保护的资源而有所不同。正如我们稍后将看到的,不同混淆技术的成本不同:不透明谓词技术的成本与控制流平坦化完全不同。让我们开始吧!
提示:在存在指令和数据混淆的情况下,尽量少使用反编译器视图。反编译器通过分析机器指令的放置方式和操作的数据推断高级信息。由于大多数指令旨在复杂化反编译结果,放弃反编译器视图通常是明智的选择。
混合布尔算术表达式
我们讨论的第一个混淆技术是使用混合算术(加、减、乘、除)和布尔(逻辑运算)运算符进行数据混淆。这种技术用于隐藏程序中的特定数值常量。常量可能代表加密算法中的值(“无中生有数字”),也可能是字符串、内存地址等。如果在解密过程中,加密算法执行简单加法,可以通过复杂化算术表达式来隐藏。
混合布尔算术表达式的例子包括:
1 | v298 & 0x52491520 | (2 * (_DWORD) v298) & 0x80120A40) ^ 0x40090520) + ((-1704077140 - (v298 & 0x8924A850)) & 0x8924A854) + (((v298 & 0x24924288) + 689062540) & 0x24924288 | (2 * v298) & 0x506D9510) |
我在之前的文章中已介绍如何通过应用变换规则创建这些表达式。苹果采用相同的过程:从代码中提取一个常量,使用算术运算符重写常量,然后继续应用变换规则。已有表达式后,继续应用变换规则,但只有部分变换规则适用,因为它们不能改变原始表达式的语义。最终,表达式被翻译回机器语言并重新插入二进制文件。
在fairplayd中,数值常量通常表示从一个基本块跳转到另一个基本块的地址。这些地址指向其他基本块或调用其他库方法的存根。我们将在控制流混淆部分详细讨论。
我们发现两种基于布尔表达式的混淆类型,取决于使用的汇编指令。经典的布尔表达式混淆示例为:
1 | *(_BYTE *)(a1 + v2) = -13 * (-71 * (59 * *(_BYTE *)(a1 + v2) - 107) + 71 * (v2 & 0xF ^ 0x9C)) - 111; |
这在汇编中翻译为:
cdqe movzx ecx, byte ptr [rdi+rax] imul ecx, 0x3B add cl, 0x95 movzx ecx, cl imul ecx, 0xB9 mov edx, eax and edx, 0x0F xor edx, 0x9C imul edx, 0x47 add edx, ecx imul ecx, edx, 0x0D add cl, 0x91 mov [rdi+rax], cl
这些汇编指令在Intel x86_64指令集中较为常见,通过一些框架(如Msynth)可以简化表达式。这些指令属于SISD(单一指令单一数据):单个表达式作用于单一数据(例如,cl与0x95的加法对其他寄存器无副作用)。
另一种逻辑算术表达式涉及Intel x86_64指令集中的MMX子系统,属于SIMD(单一指令多数据)指令,允许单一指令操作多个数据。例如,以下基本块:
movdqu xmm0, xmmword ptr [rdi+rdx] pmovzxbw xmm3, xmm0 punpckhbw xmm0, xmm0 movdqa xmm1, cs:xmmword_100216450 pmullw xmm0, xmm1 pand xmm0, xmm6 pmullw xmm3, xmm1 pand xmm3, xmm6 packuswb xmm3, xmm0 paddb xmm3, cs:xmmword_100216470 pshufd xmm0, xmm3, 0EEh pmovzxbd xmm8, xmm0 pshufd xmm0, xmm3, 0FFh pmovzxbd xmm13, xmm0 pshufd xmm0, xmm3, 55h ; 'U' pmovzxbd xmm9, xmm0 pmovzxbd xmm10, xmm3 movdqa xmm0, cs:xmmword_100216600 pmulld xmm10, xmm0 pmulld xmm9, xmm0 pmulld xmm13, xmm0 pmulld xmm8, xmm0 movdqa xmm0, xmm14 movdqa xmm4, cs:xmmword_100216480 pand xmm0, xmm4
这些操作难以翻译成高级代码,因为它们依赖于架构,且一条指令可能转换为多条高级指令(例如,paddb允许128位加法)。IDA通过定义类似mmu_addb(xmm3, xmmword_100216470)的函数解决此问题,但我们无法知道其内部细节。
设想:SIMD计算为基于MBA表达式的混淆提供了机会:能否利用矩阵计算/并行技术混淆常量?可以并行计算一系列MBA表达式以得出常量结果。这将降低复杂表达式的开销,并依赖Apple Silicon架构,增加模拟计算的难度。潜在问题包括:寻找可并行执行的方程、检查如何与并行核心交互(通过软件抽象?)、验证表达式语义。
在fairplayd二进制文件中,混合布尔算术表达式混淆被广泛使用。函数sub_1001F5D32是包含最多布尔算术表达式的函数。目前,简化布尔算术表达式的方法主要依赖符号执行和Z3等证明求解器验证混淆表达式与合成表达式的语义。
当前最佳工具是HexRays开发的goomba,集成于IDA Pro和IDA Teams 8.3版本。Tim Blazytko开发的Msynth框架也是优秀替代品。尽管MBA混淆是复杂化表达式的有效方法,但已有多种工具可以解决和重写这些表达式。
不透明谓词
不透明谓词是另一种成本较低的混淆技术,通过引入恒真或恒假条件,使反编译器探索无用的指令块。这些条件包括直接或间接跳转到永不执行的基本块,仅增加函数分析的复杂性。
假设有以下源代码:
1 2 3 4 | int sum(int a, int b){ int result = a + b + c; return result;} |
为保护结果部分,可以重写代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | int sum(int a, int b){ int result = a + b; if(a == 0 && a == 1 && a - 4 >= 55 && (a * 4 - 36 * 0xff - 0xc) < 2){ result += 1 * 4 << 2 - 0x5c; } else if (a == 5 && a != 5){ if(b > 4 && b < 4 && b != 4 && 352610 == 122){ result += 50 * 0xf5 * 352610; result += decrypt(key); } } else { return result + decrypt(key); }} |
反编译器难以重建原始检查,因此会遗漏恒真或恒假检查。不透明谓词的防御效果与if检查的复杂度和比较语句前的代数算术语句的不可读性成正比。if中的代码是死代码,即永不执行的代码;但在反编译时,无法区分可执行代码和死代码。不透明谓词因此为二进制分析增加“混淆”程度。
函数sub_100005FC0是典型例子:在经典序言后,有一个函数调用和两个执行分支。跳转条件由test al, 2指令提供,高级语言等价于if (al % 4 == 0),即如果寄存器al存储的数字能被4整除,则继续执行,否则跳转到loc_10000505F。test指令对寄存器al和立即数0x2执行AND操作,等价于检查al % 4的余数。
通过函数的图树视图,可以看到条件下的基本块非常大。
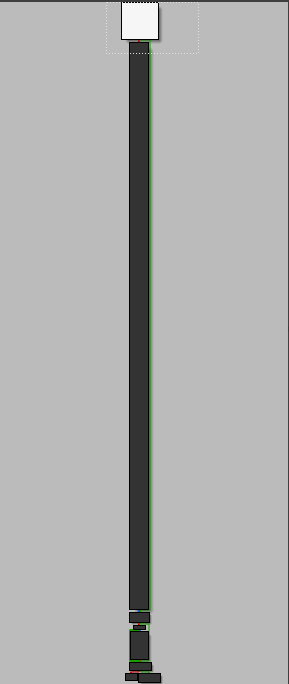
直观上,大基本块可能是处理的核心部分。如果程序未被混淆,这种假设合理。然而,苹果开发者通过复杂化指令挑战自动二进制分析工具。在本例中,条件al % 4 == 0的TRUE分支是一个明显的不透明谓词示例。检查该基本块,可以发现大量无用汇编操作。
我们需要问:这个基本块是否对计算无用?条件al % 4 == 0是否恒真或恒假?混淆的目的是防止推断条件的恒定性。确实,我们无法预测指令是否始终产生固定结果。
我们可以通过检查TRUE条件下的下一个基本块(即FALSE分支,jnz loc_100005F2F跳转到loc_100005F2F)来验证。检查大基本块是否有效的方法是查看其数据与其他基本块的依赖关系。
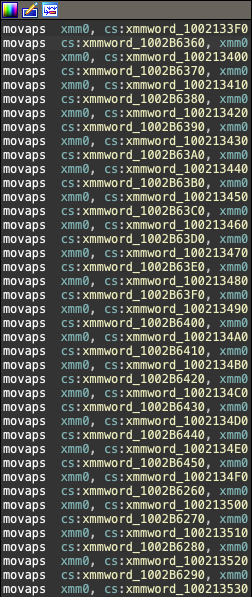
在本例中,TRUE基本块加载了xmmword_1002B6460的地址,该地址在“可疑”基本块中被重写。
FALSE条件基本块
在可疑基本块中,xmmword_1002B6460被另一个内存位置的信息重写。验证指令间的复杂依赖关系很困难!但在本例中,检查依赖较为简单,重要代码翻译如下:
1 2 3 4 5 6 7 8 9 10 11 12 | xmmword_1002B5460 = 0x0EC0C7C941423B0F77D59F9E25CFAC016;xmmword_1002142F0 = 0x6432B8A1D491C1746754EB00EF0F9478;// 序言[... 省略 ...]if (al % 4 == 0){ // 死代码 xmmword_1002B5460 = xmmword_1002142F0;}memcpy(v6, &xmmword_1002B5460, 0x1000);// 结尾 |
xmmword_1002B5460的值取决于if条件。然而,即使存在不确定性,不透明谓词的混淆效果不强:只有两种可能性,我们可以并行传播更改(验证TRUE或FALSE分支的效果)。其他问题包括:
- 如何确定大基本块的汇编代码是“死代码”?指令显示覆盖了其他数据,但这些数据从未使用。引用分析未显示其他程序使用这些数据的可能性,但我们不能完全信任二进制分析工具。
- 如何确保
xmmword_1002142F0未被其他函数覆盖?使用XREF工具检查未发现读/写xmmword_1002142F0的其他程序。但XREF依赖自动分析工具,初始解析遗漏的信息可能导致分析错误。 - 如何确定
al % 4 == 0条件不总是满足?除非发明水晶球,否则无法回答。我们关注的是分析数据以了解“可疑”基本块的效果。通过分析后续基本块并传播更改,可以推断更多数据。
回答“sub_100005FC0实际做什么?”的问题,只需查看memcpy函数调用后的基本块。函数签名是sub_100005FC0(int64 a1, int a2):
1 2 3 4 5 6 7 8 | for ( i = 0; i != a2; ++i ){ v4 = i + 15; if ( i >= 0 ) v4 = i; *(_BYTE *)(a1 + i) = -13 * v6[256 * (__int64)(int)(i - (v4 & 0xFFFFFFF0)) + (unsigned __int8)(59 * *(_BYTE *)(a1 + i) - 107)] - 111;} |
sub_100005FC0迭代v6缓冲区以解混淆xmmword_1002B5460的内容。最昂贵的指令是需要解混淆的MBA表达式。请参阅MBA部分了解如何解混淆和重写表达式。如果指针有问题,可重写为:
1 | a1[i] = -13 * v6[256 * (i - (v4 & 0xFFFFFFF0)) + 59 * a1[i] - 107] - 111; |
此混淆措施效果不佳,允许恢复大部分原始信息。fairplayd程序中包含许多类似的“无用”不透明谓词。苹果引入的不透明谓词未造成太大困扰:优秀分析师能够区分死分支和不可执行指令。苹果需改进不透明谓词构造,使基本块更复杂。
设想:为增强混淆效果,需使每个基本块更复杂(例如复杂化控制流)。控制流平坦化部分展示了一个使反编译器工作更困难的例子。
移动栈
在继续讨论之前,我们继续分析sub_100005FC0函数,查看test al, 0x2语句前的序言。
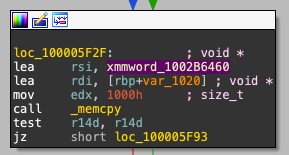
是否注意到异常?分析后发现,苹果应用了另一种保护fairplayd的混淆技术:微妙地移动栈(向上或向下,取决于栈构建方式)。为何程序要移动栈?
所有指令分析软件都提供“栈分析”,用于恢复栈和局部变量的组成。正确推断栈组成对理解控制流和函数调用至关重要。在本例中,IDA报告错误sp-analysis failed,无法跟踪栈指针的修改。IDA未意识到移动栈是为了混淆分析。通过指令mov eax, 1010h和sub rsp, rax,IDA误认为存在一个大小为0x1010字节的局部缓冲区var_1020。这只是IDA无法重建原始栈的众多例子之一。
另一个例子是函数sub_10000F620,其栈参数占用0x2CE7AB73字节(约753MB)。如此大的栈参数不可能存在:macOS栈最大为65520KB,超此值会报错。753MB值来自不可达基本块中的sub esp, 0x2CE7AB73指令,属于死代码。但IDA无法识别此值过大,拒绝反编译函数。苹果通过单一指令为反编译设置了重大障碍。
修复此情况是否困难?对初学者来说,是的。对有经验的逆向工程学生来说,不是。IDA允许分析师修改推断信息,通过重新定义栈可忽略753MB变量。另一种方法是将某路径标记为死代码(选择字节并通过“Undefine”选项不定义)。移动栈指针时,我们并非真正影响代码可读性,而是在利用分析工具的局限性。Markus Gaasedelen的文章《Dangers of the Decompiler》总结了一些混淆IDA分析的技术。
控制流平坦化
控制流平坦化是fairplayd二进制文件中发现的另一种混淆技术,也是苹果在代码保护中最强大的技术。控制流描述程序随时间演变的指令流:调用哪些函数、检查的跳转类型(条件或无条件)、基本块间的连接、执行移动的条件等信息均从控制流推导。
高级控制流指令包括if、if else、if else if else、switch、do while、for等。这些条件在Intel机器语言中转换为cmp、test、jmp指令。高级控制流由“逻辑”指令决定,而低级控制流通过更改下一指令地址(跳转)实现。
控制流可推导基本块连接,进行过程内分析,重建程序执行流,恢复循环等信息以翻译为伪C代码。
为展示控制流平坦化的威力,分析函数sub_10003FE60。在IDA中选择该函数,右键选择树视图,了解基本块连接、依赖关系和执行分支。通常,树视图有助于预测反编译器的伪代码。
控制流平坦化的目标是通过条件和无条件跳转展平控制流。该技术由Chenxi Wang在其博士论文《A Security Architecture for Survivability Mechanisms》中提出。通常,程序控制流呈垂直发展,如下图:

IDA垂直控制流
应用控制流平坦化后,程序图被“水平化”,如下图:

IDA控制流平坦化后
基本块被拉到同一水平,图呈水平扩展。极端情况下,控制流平坦化构造虚假基本块,混淆反编译器,如下图:

IDA极端垂直控制流
控制流平坦化可通过简单switch实现。假设有函数:
1 2 3 4 5 6 7 8 9 10 11 | int sum(int a, int b){ int s = 4; int c; if ( a > 500 ){ c = 2; } else { c = 0; } int result = s + a + b + c; return result;} |
控制流图如下:
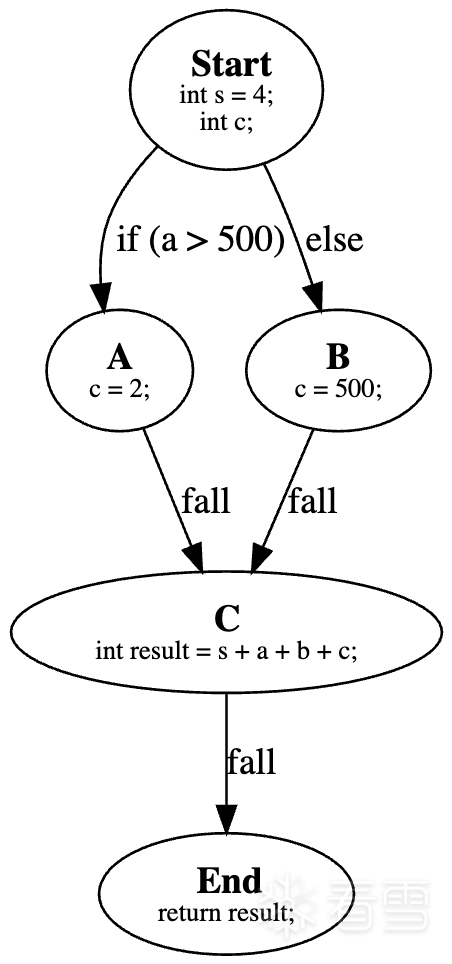
控制流图
我们希望将垂直图展平!使用switch指令将执行分为多个分支,创建水平排列的基本块。通过辅助变量state存储当前状态,类似有限状态机。变换步骤如下:
- 创建“开始”块:初始化
state变量和switch中使用的变量。可将声明移到switch分支,但需注意局部变量副作用。 - 创建分发器:包含
while和switch语句,避免分支跳出到函数最后语句。 - 移动基本块:为新状态选择编号,插入代码并更改
state指向下一基本块。可细分大基本块或添加永不执行的指令。 - 变换检查:通过证明求解器和数学方程检查函数可终止,确保原始语义不变。
应用控制流平坦化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | int sum(int a, int b){ int state = 0; int s, c, result; while(1){ switch(state){ case 2: if (a > 500){ state = 4; } else { state = -1; } break; case 0: s = 4; state = 2; break; case -1: c = 0; state = 5; break; case 5: result = s + a + b + c; case 0x54292639: return result; case 4: c = 2; state = 5; break; } } return -542926392;} |
结果控制流图如下:

控制流图
注意事项:
- 图未包含
while指令以避免过多箭头。break后从state评估恢复执行。 basic block A和B区分a > 500的控制流。状态号为随机标签。- 攻击者可通过跟踪
state预测执行流。使用MBA表达式和别名可混淆state值,添加无用块或动态构造switch。 state从未赋值为0x54292639。通过省略break,从状态5顺序执行到0x54292639(“C Magic”)。禁用编译器优化以保留图。
编译包含sum_1(混淆)和sum_2(原始)的程序,sum_2反编译正确:
1 2 3 4 5 6 7 8 | __int64 __fastcall sum_2(int a1, int a2){ int v3; // [rsp+4h] [rbp-10h] if ( a1 <= 500 ) v3 = 0; else v3 = 2; return (unsigned int)(v3 + a2 + a1 + 4);} |
控制流图与手动构建一致。而sum_1反编译为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | __int64 __fastcall sum_1(int a1, int a2){ int v3; // [rsp+8h] [rbp-14h] int v4; // [rsp+Ch] [rbp-10h] int i; // [rsp+10h] [rbp-Ch] for ( i = 0; ; i = 5 ){ while ( 1 ){ while ( 1 ){ while ( i == -1 ){ v3 = 0; i = 5; } if ( i ) break; v4 = 4; i = 2; } if ( i != 2 ) break; if ( a1 <= 500 ) i = -1; else i = 4; } if ( i != 4 ) break; v3 = 2; } return (unsigned int)(v3 + a2 + a1 + v4);} |
IDA反编译器被混淆,生成三个嵌套while(1)循环。尽管结果不完全正确,程序仍可运行,攻击者可能恢复逻辑。这是弱混淆的典型例子:攻击者难以重建原始控制流,但初始逻辑可能被恢复。结合不透明谓词、常量变换和MBA表达式可增加复杂性。
在fairplayd中,控制流平坦化广泛用于混淆执行流。打开函数sub_10003FE60,反编译器识别高级switch结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | switch ( (v7 == 0) + v2 ){ case 0: JUMPOUT(0x100035E2CLL); case 1: JUMPOUT(0x10004359ELL); case 2: JUMPOUT(0x10005BECDLL); case 3: v46 = v3; v45 = a1; v8 = v2 ^ 6u; v9 = v8 - 5; v10 = ((_DWORD)v8 - 5) | 2u; ....} |
但switch中的指令无意义,因为苹果开发者重度混淆了状态变量v2和v7。反编译器通过跳转表识别switch,跳转表存储分支地址。苹果为某些函数动态重建跳转表,分配内存空间存储地址,使用MBA表达式计算。由于静态分析限制,无法精确确定地址,破坏了IDA和分析师恢复程序逻辑的能力。
地址构造的典型例子在基本块末尾:
lea r12, jpt_10003FF12 movsxd rax, ds:(jpt_10003FF12 - 100218890h)[r12+rax*4] lea rcx, loc_10005A140 add rcx, rax mov r14, [rbp+var_58] jmp rcx
控制流平坦化结合不透明谓词和MBA表达式是fairplayd混淆的关键。
是否可能进一步混淆?
本文尝试识别fairplayd中的常见混淆模式。一些措施有效,复杂化了逆向工程,尤其是控制流平坦化,破坏了恢复程序结构的可能性。攻击者面临动态跳转表、不可恢复的switch和动态生成代码。
其他混淆技术(如不透明谓词)在理论上有效,但通过检查基本块可区分原始和混淆代码。
是否存在完美的混淆技术?不可能。由于数字内容管理的限制,信息最终必须可见和解混淆。工具与混淆技术将持续演化。苹果可能通过“虚拟化”技术增强混淆,编写专用解释器和指令集体系结构执行解密操作。目前fairplayd未使用此技术,但switch分支和动态代码生成迹象预示其可能性。
如有批评、建议或评论,请发送至seekbytes@protonmail.com (原文作者)。错误或不准确的报告始终欢迎。
脚注:
- “安装包”指包含可执行文件、资源和签名元数据的IPA包。
- 苹果已使用GID Key(256位AES密钥)加密/解密固件,部分用于生成iCloud账户密钥验证App Store购买。
- 指令
mov eax, 1010h和sub rsp, rax未受sub_100008B80调用影响,该函数仅加载栈金丝雀。 - 感谢Tim Blazytko的演讲《Revealing the secrets in binaries using code detection strategies》,通过块长度和控制流图排列加速了二进制分析。
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。




