先说结论:
1、同一个脚本,不需要修改,可以同时还原Windows的x86汇编和Android的arm64汇编。
2、同一个函数,基于汇编还原和基于Microcode还原做对比,后者的代码量是前者的一半。
再说问题:
[原创]OLLVM扁平化还原—新角度:状态机里面分享了基于状态机的思路对扁平化进行还原,还原的脚本是基于汇编直接读取解析。但是实战的情况会很复杂,因为汇编太过于底层,分析和还原起来很不方便。
问题1:多种情况
基于汇编容易遇到问题就是要兼容很多种情况。举一个最简单的例子:修改状态寄存器的值,就有两种情况:
问题2:限制很多
更麻烦的是进行还原的时候,要去修改原本的汇编,会遇到很多限制:
(1)容易处理的情况:
状态值有两种可能,最后也有跳转指令
这种可以直接修改最后两条汇编指令
实现了按条件跳到不同的基本块
(2)不好处理的情况:
状态值有两种可能,但是后面没有跳转指令,因为下一个基本块就是分发器
这种情况只有一条汇编指令能修改:CSEL W8, W14, W12, EQ,容纳不下两条跳转指令。非要按汇编修改的话,这里还可以在前面直接修改W11和W13,让最后两条指令空出来。
但要是CSEL后面没有多余的指令,就得去占用下一个基本块的空间了,要处理更多细节,很麻烦。
正因为在汇编上直接处理会带来很多麻烦,所以更舒服的处理方法是在汇编的更上层进行分析和还原。而 IDA 的 Hex-Rays 正好提供了比汇编更高级的中间表示(IR):微码(Microcode)。
1、正因为微码是一种中间表示,能把多种具体指令集表达成同一种抽象指令集,所以能够同一个还原脚本同时支持x86和arm64。
2、与此同时,汇编转化成微码之后,微码本身还可以进行多次的优化。这就意味着前面说得给寄存器赋值的两种情况,经过优化会自动变成同一种,脚本处理起来更便捷。
3、更重要的是,微码本身支持随意加减指令,甚至直接加减整个基本块,不需要考虑原有的空间限制,自由多了。
需要注意的是,微码的资料比较少,加上微码相关的API比较复杂,一开始写还原脚本还是挺费劲的,不过熟悉微码之后比基于汇编写脚本舒服多了。折腾了一周才理顺,一堆坑,后面会尽量写详细点。
关于微码的参考资料:
1、官网Hex-Rays API:6bdK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6H3P5i4c8Z5L8$3&6Q4x3X3g2V1L8$3y4K6i4K6u0W2K9r3g2^5i4K6u0V1M7X3q4&6M7#2)9J5k6h3y4G2L8b7`.`.
2、使用 IDA microcode进行ollvm 扁平化还原的详细资料:687K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Z5k6i4S2Q4x3X3c8J5j5i4W2K6i4K6u0W2j5$3!0E0i4K6u0r3j5X3I4G2k6#2)9J5c8X3S2W2P5q4)9J5k6s2u0S2P5i4y4Q4x3X3c8E0K9h3y4J5L8$3y4G2k6r3g2Q4x3X3c8S2M7r3W2Q4x3X3c8$3M7#2)9J5k6r3!0T1k6Y4g2K6j5$3q4@1K9h3&6Y4i4K6u0V1j5$3!0E0M7r3W2D9k6i4t1`.
一开始先看看汇编转化的微码长什么样,前面参考资料的作者写了一个IDA插件GitHub - RolfRolles/HexRaysDeob,用来直接查看微码:
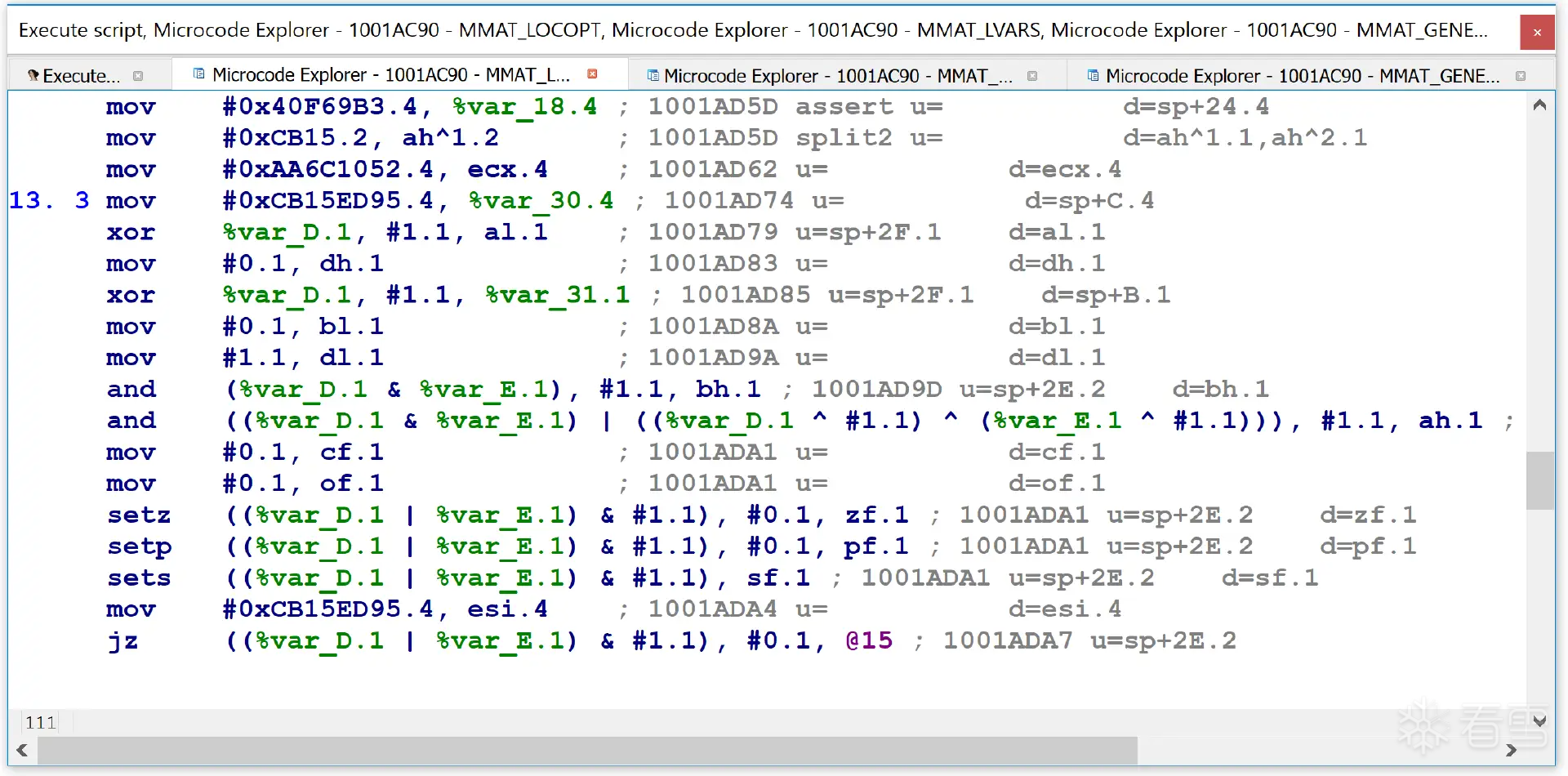
因为Hex-Rays的API有改动,这个插件需要自己修改编译才能用在IDA9.1上面。但用的时候发现有问题:这个插件比较简单,要对比汇编和微码比较麻烦;还有就是会莫名奇妙地崩溃。索性看了插件里面核心的源码,直接写一个IDA python脚本,导出微码后方便搜索比较。
导出微码的脚本如下:
复习一下[原创]OLLVM扁平化还原—新角度:状态机最后提到的,基于状态机的角度进行还原的关键步骤:
思路还是找到被跳转最多的基本块(前驱最多)。像之前基于汇编分析,需要自己统计所有跳转指令;而微码本身就已经统计好前驱和后继的信息,所以只需要找到前驱最多的基本块:
因为修改状态之后跳回分发器,所以只要找到跳转分发器的基本块,然后找到给寄存器赋值的指令,从里面得到状态寄存器:
找到改变状态值和找到状态寄存器的思路是一样。最舒服的是不用去管到底是直接修改还是按条件分叉状态修改。
汇编是按条件分叉赋值:
微码是生成两个基本块,里面都是直接赋值:
对应的找修改状态值的脚本就很简洁了:
找到命中状态值,第一反应是找到比较状态值的指令,结果发现优化后的微码,会和原本的汇编对不上。
降低微码的优化等级,是能和汇编一一对应,但又发现优化级别低的微码太啰嗦了,还不如直接分析汇编。这才意识到,汇编转微码的过程中,最原始的微码要比汇编更底层(为了兼容多种汇编架构);而高等级优化的微码确实能带来便捷,但也意味着可能和汇编无法一一对应。
一筹莫展的时候,突然发现微码一个特殊的功能:值范围(VALRANGES)。值范围具体来说就是进入基本块之前,条件变量对应的值可能是什么。这一点完美对上了状态机也是根据状态值进入真实基本块。根据这个功能,就可以很方便地找到命中状态的的基本块!
先举个简单的例子:
对应的可以写出命中状态值的脚本
扁平化的还原就简单了,匹配一下状态值,然后修改跳转。
需要注意的是:
1、修改或者新增goto指令,前驱和后继也要对应修改。
2、修改状态值的指令也要删掉,不然F5转伪代码会很难看
3、修改之后,要及时验证
最终效果和基于汇编还原是一样的53行:
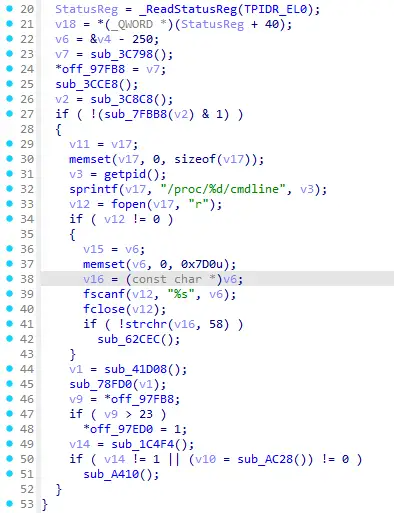
有意思的是,Android的so函数扁平化大多都是基于OLLVM。OLLVM是把源码变成中间表示(IR),然后加入分发器进行扁平化,最后再转化成汇编。
我们也可以用魔法打败魔法:先用IDA的Hex-Rays把汇编转成中间表示的Microcode,再对Microcode分析去掉分发器,最后还原得到一开始的源码。
此外,Android的so函数虚拟化保护(VMP)大多也是基于LLVM:转化成中间表示(IR)、加上虚拟机、最后生成汇编。同样的思路,借助Microcode去分析VMP之后的汇编,也能省事很多。
本质上,这是把底层的汇编抬升(Lift)成中间表示(IR)。让分析者从“面向机器的分析”提升为“面向语义的分析”。
MOV W8,
MOV W8,
MOVK W8,
loc_434CC
LDRB W8, [X19,#0x1F]
MOV W9, #0x1B166FED
CMP W8, #0
MOV W8, #0x146E0C87
CSEL W8, W8, W9, NE
B loc_43120
loc_434CC
LDRB W8, [X19,#0x1F]
MOV W9, #0x1B166FED
CMP W8, #0
MOV W8, #0x146E0C87
CSEL W8, W8, W9, NE
B loc_43120
B.<cond> true_block_begin_ea
B false_block_begin_ea
B.<cond> true_block_begin_ea
B false_block_begin_ea
loc_434CC
LDRB W8, [X19,#0x1F]
MOV W9, #0x1B166FED
CMP W8, #0
MOV W8, #0x146E0C87
B.NE loc_true
B loc_false
loc_434CC
LDRB W8, [X19,#0x1F]
MOV W9, #0x1B166FED
CMP W8, #0
MOV W8, #0x146E0C87
B.NE loc_true
B loc_false
loc_3EBE8
MOV W11, #0x290F
MOV W13, #0x9866
CSEL W8, W14, W12, EQ
MOVK W11, #0xA4C3,LSL#16
MOVK W13, #0x8A8,LSL#16
loc_3EBE8
MOV W11, #0x290F
MOV W13, #0x9866
CSEL W8, W14, W12, EQ
MOVK W11, #0xA4C3,LSL#16
MOVK W13, #0x8A8,LSL#16
loc_3EBE8
MOV W11, 0xA4C3290F
MOV W13, 0x08A89866
CSEL W8, W14, W12, EQ
B.EQ loc_true
B loc_false
loc_3EBE8
MOV W11, 0xA4C3290F
MOV W13, 0x08A89866
CSEL W8, W14, W12, EQ
B.EQ loc_true
B loc_false
x86
汇编:0xEC7CF mov edi, 2863E1C6h
微码:mov #0x2863E1C6.4, edi.4 ; EC7CF
arm64
汇编:0x4327C MOV W8, #0x5338AB80
微码:mov #0x5338AB80.4, w8.4 ; 4327C
x86
汇编:0xEC7CF mov edi, 2863E1C6h
微码:mov #0x2863E1C6.4, edi.4 ; EC7CF
arm64
汇编:0x4327C MOV W8, #0x5338AB80
微码:mov #0x5338AB80.4, w8.4 ; 4327C
# 原本的汇编赋值需要两条指令
0x430B0 MOV W8, #0x97A5
0x430D8 MOVK W8, #0x6657,LSL#16
0x430DC B loc_43120
# 转化成微码优化之后合并成一条指令
mov #0x665797A5.4, w8.4 ; 430D8
goto @3 ; 430DC
# 原本的汇编赋值需要两条指令
0x430B0 MOV W8, #0x97A5
0x430D8 MOVK W8, #0x6657,LSL#16
0x430DC B loc_43120
# 转化成微码优化之后合并成一条指令
mov #0x665797A5.4, w8.4 ; 430D8
goto @3 ; 430DC
扁平化进行还原的时候,需要修改基本块的跳转指令的目标
如果基本块的最后不是跳转指令,也可以自由新增跳转指令
def change_goto(mba, cur_block_id, new_block_id):
cur_mblock = mba.get_mblock(cur_block_id)
if cur_mblock.tail.opcode != ida_hexrays.m_goto :
old_block_id = cur_mblock.succset[0]
add_new_goto(mba, cur_block_id, new_block_id) # 新增跳转指令
return old_block_id
else:
old_block_id = cur_mblock.tail.l.b
cur_mblock.tail.l.b = new_block_id # 修改跳转目标
return old_block_id
def add_new_goto(mba, cur_block_id, new_block_id):
# 构建跳转操作码
new_mop = ida_hexrays.mop_t()
new_mop.t = ida_hexrays.mop_b
new_mop.b = new_block_id
new_mop.size = ida_hexrays.NOSIZE
# 构建跳转指令
cur_mblock = mba.get_mblock(cur_block_id)
new_goto = ida_hexrays.minsn_t(cur_mblock.tail.ea)
new_goto.opcode = ida_hexrays.m_goto
new_goto.l = new_mop
# 插入跳转指令
cur_mblock.insert_into_block(new_goto, cur_mblock.tail)
扁平化进行还原的时候,需要修改基本块的跳转指令的目标
如果基本块的最后不是跳转指令,也可以自由新增跳转指令
def change_goto(mba, cur_block_id, new_block_id):
cur_mblock = mba.get_mblock(cur_block_id)
if cur_mblock.tail.opcode != ida_hexrays.m_goto :
old_block_id = cur_mblock.succset[0]
add_new_goto(mba, cur_block_id, new_block_id) # 新增跳转指令
return old_block_id
else:
old_block_id = cur_mblock.tail.l.b
cur_mblock.tail.l.b = new_block_id # 修改跳转目标
return old_block_id
def add_new_goto(mba, cur_block_id, new_block_id):
# 构建跳转操作码
new_mop = ida_hexrays.mop_t()
new_mop.t = ida_hexrays.mop_b
new_mop.b = new_block_id
new_mop.size = ida_hexrays.NOSIZE
# 构建跳转指令
cur_mblock = mba.get_mblock(cur_block_id)
new_goto = ida_hexrays.minsn_t(cur_mblock.tail.ea)
new_goto.opcode = ida_hexrays.m_goto
new_goto.l = new_mop
# 插入跳转指令
cur_mblock.insert_into_block(new_goto, cur_mblock.tail)
import re
import idaapi
import ida_hexrays
# 自定义printer,去掉颜色
color_pat = re.compile(r'[\x01\x02].')
class my_printer(ida_hexrays.vd_printer_t):
def __init__(self):
super().__init__()
self.lines = []
def _print(self, indent, text):
s = (" " * int(indent)) + str(text)
s = color_pat.sub("", s)
s = s.rstrip("\n")
self.lines.append(s)
return len(text)
def dump_microcode(func_ea, maturity=ida_hexrays.MMAT_LVAR3):
pfn = idaapi.get_func(func_ea)
hf = ida_hexrays.hexrays_failure_t()
rng = ida_hexrays.mba_ranges_t(pfn)
mba = ida_hexrays.gen_microcode(rng, hf, None, ida_hexrays.DECOMP_WARNINGS, maturity)
if not mba:
raise RuntimeError("gen_microcode failed: " + (hf.desc() or ""))
vp = my_printer()
mba._print(vp)
return vp.lines
# 调用
lines = dump_microcode(0x43058)
print("lines len:", len(lines))
for line in lines:
print(line)
import re
import idaapi
import ida_hexrays
# 自定义printer,去掉颜色
color_pat = re.compile(r'[\x01\x02].')
class my_printer(ida_hexrays.vd_printer_t):
def __init__(self):
super().__init__()
self.lines = []
def _print(self, indent, text):
s = (" " * int(indent)) + str(text)
s = color_pat.sub("", s)
s = s.rstrip("\n")
self.lines.append(s)
return len(text)
def dump_microcode(func_ea, maturity=ida_hexrays.MMAT_LVAR3):
pfn = idaapi.get_func(func_ea)
hf = ida_hexrays.hexrays_failure_t()
rng = ida_hexrays.mba_ranges_t(pfn)
mba = ida_hexrays.gen_microcode(rng, hf, None, ida_hexrays.DECOMP_WARNINGS, maturity)
if not mba:
raise RuntimeError("gen_microcode failed: " + (hf.desc() or ""))
vp = my_printer()
mba._print(vp)
return vp.lines
# 调用
lines = dump_microcode(0x43058)
print("lines len:", len(lines))
for line in lines:
print(line)
1、找到分发器地址:dispatcher_ea
2、找到状态寄存器:state_reg
3、找到改变状态值:block_ea :state_reg = next_state
4、找到命中状态值:if state_reg == cur_state : block_ea
5、进行扁平化还原:block_ea -> next_state == cur_state -> block_ea
1、找到分发器地址:dispatcher_ea
2、找到状态寄存器:state_reg
3、找到改变状态值:block_ea :state_reg = next_state
4、找到命中状态值:if state_reg == cur_state : block_ea
5、进行扁平化还原:block_ea -> next_state == cur_state -> block_ea
def get_dispatcher(mba):
dispatcher_id = None
max_in = -1
for i in range(mba.qty):
mblock = mba.get_mblock(i)
nin = mblock.npred() # 前驱数量
if nin > max_in:
max_in = nin
dispatcher_id = i
return dispatcher_id
# 调用
dispatcher_id = get_dispatcher(mba)
# 输出
dispatcher_id: 3
# 微码
可以看出前驱 INBOUNDS:有很多
3. 0 ; 2WAY-BLOCK 3 INBOUNDS: 1 2 10 17 21 25 28 33 35 36 37 40 41 42 45 46 47 48 49 50 53 56 9 16 39 44 52 55 OUTBOUNDS: 4 11 [START=43120 END=43128] MINREFS: STK=0/ARG=A90, MAXBSP: 0
def get_dispatcher(mba):
dispatcher_id = None
max_in = -1
for i in range(mba.qty):
mblock = mba.get_mblock(i)
nin = mblock.npred() # 前驱数量
if nin > max_in:
max_in = nin
dispatcher_id = i
return dispatcher_id
# 调用
dispatcher_id = get_dispatcher(mba)
# 输出
dispatcher_id: 3
# 微码
可以看出前驱 INBOUNDS:有很多
3. 0 ; 2WAY-BLOCK 3 INBOUNDS: 1 2 10 17 21 25 28 33 35 36 37 40 41 42 45 46 47 48 49 50 53 56 9 16 39 44 52 55 OUTBOUNDS: 4 11 [START=43120 END=43128] MINREFS: STK=0/ARG=A90, MAXBSP: 0
def get_state_mreg(mba, dispatcher_id):
dispatcher_mblock = mba.get_mblock(dispatcher_id)
for i in range(dispatcher_mblock.npred()):
block_id = dispatcher_mblock.pred(i)
mblock = mba.get_mblock(block_id)
minsn = mblock.tail
while minsn:
# m_mov imm reg
if (
minsn.opcode == ida_hexrays.m_mov and
minsn.l.t == ida_hexrays.mop_n and
minsn.d.t == ida_hexrays.mop_l
):
return minsn.d.l.var().get_reg1()
minsn = minsn.prev
return None
# 调用
state_mreg = get_state_mreg(mba, dispatcher_id)
state_mreg_name = ida_hexrays.get_mreg_name(state_mreg, 4)
print(f"state_mreg_name: {state_mreg_name}")
# 输出
state_mreg_name: w8
# 微码
1. 2 mov #0x665797A5.4, w8.4 ; 430D8 split4 u= d=w8.4
1. 3 goto @3 ; 430DC u=
def get_state_mreg(mba, dispatcher_id):
dispatcher_mblock = mba.get_mblock(dispatcher_id)
for i in range(dispatcher_mblock.npred()):
block_id = dispatcher_mblock.pred(i)
mblock = mba.get_mblock(block_id)
minsn = mblock.tail
while minsn:
# m_mov imm reg
if (
minsn.opcode == ida_hexrays.m_mov and
minsn.l.t == ida_hexrays.mop_n and
minsn.d.t == ida_hexrays.mop_l
):
return minsn.d.l.var().get_reg1()
minsn = minsn.prev
return None
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2025-10-13 16:33
被GhHei编辑
,原因: 纠错






