本文记录了一次从零开始,利用 LLVM Pass 技术为 Android Native 函数实现 VMP(Virtual Machine Protection)的完整心路历程。文章从一个核心观点出发:逆向工程的深度与正向开发的能力紧密相连。为了真正理解 VMP 的工作原理,笔者选择亲手“造轮子”,设计并实现了一个小型的虚拟机(VM)。文中详细阐述了从最初构思、CPU 状态模拟、指令集(ISA)设计,到解释器实现的全过程,并坦诚地分享了在处理函数调用、全局变量等复杂问题时遇到的两大认知误区与失败尝试。最终,通过借鉴社区成熟方案的思路,成功构建了一个可用的原型 SmallVMP。这不仅是一篇技术实现指南,更是一次关于“通过创造来学习”的深度思考与复盘。
近来,VMP 技术在软件保护领域的讨论热度居高不下。作为一名技术探索者,与其临渊羡鱼,不如退而结网。我坚信,一个人的逆向功底始终与其开发水平呈现正相关性,若能洞悉其底层原理,那么逆向分析时必将如虎添翼。
本着“我学会,就等于大家学会”的分享精神,我决定开启这次 VMP 的探索之旅。这篇文章旨在纯粹的技术交流,记录我如何一步步领略 VMP 的风采。若能抛砖引玉,得到前辈大佬的指点,那更是幸事一桩。
核心思路:能否利用强大的 LLVM 框架来构建一个 VMP?经过一番调研,我发现这恰恰是业界许多成熟方案的选择。我的初步构想是:
在 C/C++ 层实现一个微型虚拟 CPU,包含解释器,负责执行自定义的字节码。
编写一个 LLVM Pass,在编译期间将目标函数的 LLVM IR (Intermediate Representation) 翻译成我们的自定义字节码。
同时,将原函数体清空,替换为一个“跳板”(Stub),负责引导程序流程进入我们的虚拟 CPU 解释器。
理论上,这个方案完全可行。那么,让我们开始吧!
万丈高楼平地起,VMP 的核心在于那个“VM”。我们需要先设计一个虚拟的 CPU。参考 ARM64 架构,我们可以定义出它的核心组成部分。
一个 CPU 最核心的就是它的寄存器状态。我们将其极度简化,只保留通用寄存器和状态旗标。
没错,一个极简 CPU 的模型就是这么纯粹。
为了方便操作 VMState,我们封装一些工具函数,用于寄存器的读写和状态旗标的更新。
有了 CPU,就需要它能理解的语言——指令集。我们设计一套定长的 32 位指令格式(LearnVMP ISA),便于处理。
我们将 32 位的指令字划分成不同字段,用于表示操作码、寄存器索引和立即数。
为了让解释器能识别和加载我们的字节码,定义一个文件头结构。
解释器是 VM 的大脑,它是一个巨大的 switch-case 循环,根据 PC 指针取出指令,解码并执行。
下面是部分关键指令的实现逻辑:
至此,一个简单的 VM 框架已经搭建完成。我曾天真地以为,下一步只需将 LLVM IR 直接翻译成这套指令就大功告成了。然而,现实很快给了我沉重的一击。
当我尝试直接翻译 call 指令时,问题暴露了。LLVM IR 中的 call 是符号化的,例如: %call = call noalias ptr @fopen(ptr noundef @.str.38, ptr noundef @.str.39)
它并没有提供 @fopen 的绝对地址。IR 是一种更高层的抽象,重定位(Relocation)是在链接阶段才完成的。我的第一版 VM 完全没有处理符号解析和重定位的能力,因此这条路走不通。
吸取教训后,我构思了第二版方案:
LLVM Pass 负责收集所有遇到的外部调用符号(如 fopen),并为它们生成唯一的 ID。
VM 解释器端维护一个符号表,当遇到 OP_CALL_SYM 这样的指令时,根据 ID 查找函数名字符串。
通过 dlsym 等方式在运行时动态解析符号地址,然后执行调用。
这个方案看似可行,但很快又遇到了新的、更棘手的问题:全局变量和静态变量。如果被 VMP 的函数引用了全局变量,我该如何处理?难道要再维护一个全局变量表吗?如果一个外部调用本身又依赖了其他全局状态呢?这种手动模拟链接器行为的复杂度呈指数级增长,很快就让我意识到,这又是一条歧路。
教训总结:这两次失败让我深刻理解到,VMP 的本质不仅仅是指令翻译,更是一个微型的、自洽的运行时(Runtime)环境。我们不应该试图手动模拟编译、链接过程中的所有复杂工作。
在陷入困境后,我开始研究社区的成熟项目,如 xvmp。学习其源码后,我恍然大悟:我应该把链接和符号解析这些脏活累活,再次交给 LLVM 自己来处理!
正确的思路是:
收集与桥接:LLVM Pass 在处理函数时,将所有对外部函数、全局变量的引用收集起来。为每一个引用生成一个“桥接函数”(Thunk)。这个桥接函数是原生的、未被VMP的,它的唯一作用就是执行原始的调用或访问。
符号替换:在生成字节码时,将原来对 @fopen 的调用,替换为对 __thunk_fopen 的调用,并赋予其一个 ID。
VM 调用:VM 解释器通过 OP_BL 指令,根据 ID 调用对应的原生 Thunk 函数。由于 Thunk 函数是编译器正常生成的,它自然就拥有了所有正确的链接信息和地址。
通过这种方式,我们巧妙地将 VM 世界和原生世界连接起来,所有复杂的符号问题都迎刃而解。
基于上述思路,我的 SmallVMP 终于诞生了。它集成在一个修改版的 LLVM (内置 Hikari 混淆框架) 中。
使用方法:
编译并配置好定制版的 LLVM/Clang 环境变量。
在代码中引入 VMP.h 头文件。
使用 IRVM_SECTION 宏来标记需要 VMP 加固的函数。
编译时,你会看到类似如下的日志,表明 VMP Pass 已经生效:
-mllvm -enable-bcfobf (伪控制流)
-mllvm -enable-splitobf (基本块分割)
-mllvm -enable-subobf (指令替换)
-mllvm -enable-allobf (开启所有)
...等等
效果展示:
这是要混淆的函数:
vm后变成了这样:
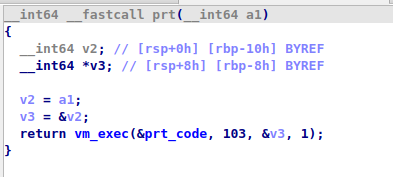
这是未混淆的vm解释器
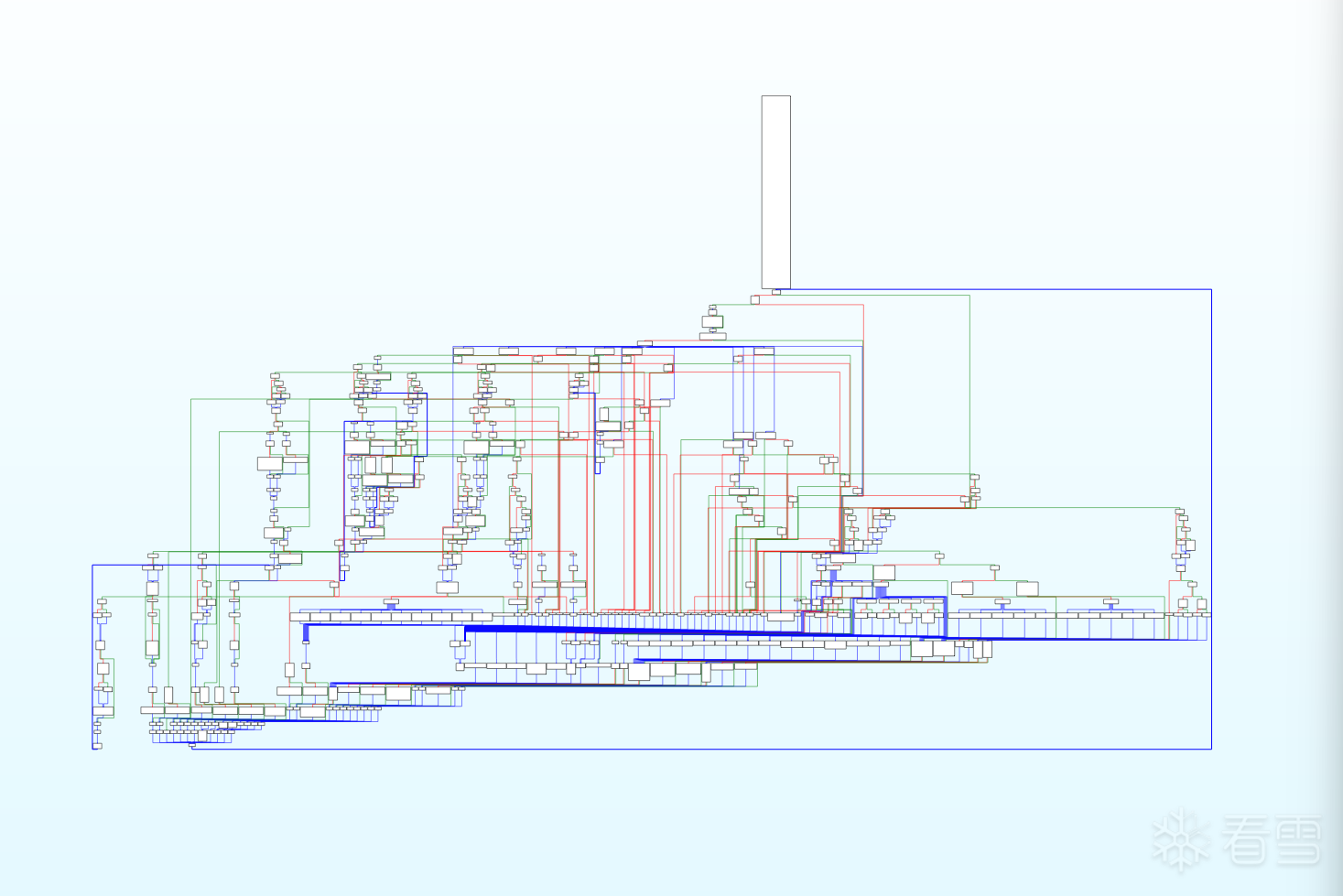
加一点 混淆 后 这里只 添加伪控制流 , 平坦化开启 ida 就无法 显示cfg图了

目前 SmallVMP 仍处于实验阶段,它成功实现了对目标函数核心逻辑的抽取和解释执行。但它仍有局限,例如对某些复杂的 LLVM IR 指令(如 select)尚未支持,遇到这类函数会自动跳过加固,保证编译的稳定性。
未来的工作可以围绕以下几点展开:
Code 加密:对生成的字节码进行加密存储,在解释执行前动态解密,执行后再加密回去,对抗静态分析。
动态分发:动态生成 Handler 映射表,让操作码与处理函数的对应关系不再固定。
嵌套 VM:实现二级 VM,即解释器本身也被另一层 VM 保护,进一步提升分析难度。
从最初一个简单的想法,到经历两次失败,再到最终实现一个可用的原型,这个“造轮子”的过程让我对 VMP 的理解产生了质的飞跃。我不再仅仅是知道 VMP“是什么”,而是深刻体会到它“为什么是这样”。
我已将这个过程中的代码开源,包括那些失败的尝试,希望能为同样在探索路上的朋友们提供一些参考。代码尚不完美,欢迎各位大佬批评指正。
另外我在学习过程中的失败产物 我放到这个仓库里了:
ca0K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6z5K9g2c8A6j5h3&6q4M7W2S2A6L8X3M7$3y4U0k6Q4x3V1k6Q4x3X3c8m8L8X3c8J5L8$3W2V1f1X3g2$3k6i4u0K6k6g2)9J5c8Y4c8J5k6h3g2Q4x3V1k6E0j5h3W2F1i4K6u0r3g2V1#2b7i4K6t1#2c8e0N6Q4x3U0g2m8c8W2)9J5y4e0R3%4
不造轮子,何以知轮之精髓? 希望我的分享,能为你带来一点启发。
可以配合混淆 来提高vmp 的强度
下面我把demo 进行vmp 的样本放出来 供大家 看看
c
typedef struct {
uint64_t R[32];
uint8_t N,Z,C,V;
} VMState;
c
typedef struct {
uint64_t R[32];
uint8_t N,Z,C,V;
} VMState;
c
#pragma once // 防止头文件被重复包含
#include <stdint.h> // 使用固定宽度整数类型
static inline uint64_t VR(const VMState* s, uint8_t i) { return i == 31 ? 0ull : s->R[i]; }
static inline void VW(VMState* s, uint8_t i, uint64_t v) { if (i != 31) s->R[i] = v; }
static inline void setNZ(VMState* s, uint64_t r) { s->Z = (r == 0); s->N = (uint8_t)((r >> 63) & 1); }
static inline void setNZ_add(VMState* s, uint64_t a, uint64_t b, uint64_t r) {
setNZ(s, r);
s->C = (r < a);
s->V = (uint8_t)((~(a ^ b) & (a ^ r)) >> 63);
}
static inline void setNZ_sub(VMState* s, uint64_t a, uint64_t b, uint64_t r) {
setNZ(s, r);
s->C = (a >= b);
s->V = (uint8_t)(((a ^ b) & (a ^ r)) >> 63);
}
c
#pragma once // 防止头文件被重复包含
#include <stdint.h> // 使用固定宽度整数类型
static inline uint64_t VR(const VMState* s, uint8_t i) { return i == 31 ? 0ull : s->R[i]; }
static inline void VW(VMState* s, uint8_t i, uint64_t v) { if (i != 31) s->R[i] = v; }
static inline void setNZ(VMState* s, uint64_t r) { s->Z = (r == 0); s->N = (uint8_t)((r >> 63) & 1); }
static inline void setNZ_add(VMState* s, uint64_t a, uint64_t b, uint64_t r) {
setNZ(s, r);
s->C = (r < a);
s->V = (uint8_t)((~(a ^ b) & (a ^ r)) >> 63);
}
static inline void setNZ_sub(VMState* s, uint64_t a, uint64_t b, uint64_t r) {
setNZ(s, r);
s->C = (a >= b);
s->V = (uint8_t)(((a ^ b) & (a ^ r)) >> 63);
}
c
typedef uint32_t vm_insn_t;
enum vm_op {
OP_NOP=0,
OP_LIMM,
OP_MOVrr,
OP_ADD, OP_ADDI, OP_SUB, OP_SUBI,
OP_AND, OP_ORR, OP_EOR,
OP_LSL, OP_LSR, OP_ASR,
OP_CMPrr, OP_CMPri,
OP_LDRB, OP_LDRH, OP_LDRW, OP_LDRX,
OP_STRB, OP_STRH, OP_STRW, OP_STRX,
OP_B, OP_BCC,
OP_BL,
OP_RET,
OP_TRAP,
OP_MAX_
};
c
typedef uint32_t vm_insn_t;
enum vm_op {
OP_NOP=0,
OP_LIMM,
OP_MOVrr,
OP_ADD, OP_ADDI, OP_SUB, OP_SUBI,
OP_AND, OP_ORR, OP_EOR,
OP_LSL, OP_LSR, OP_ASR,
OP_CMPrr, OP_CMPri,
OP_LDRB, OP_LDRH, OP_LDRW, OP_LDRX,
OP_STRB, OP_STRH, OP_STRW, OP_STRX,
OP_B, OP_BCC,
OP_BL,
OP_RET,
OP_TRAP,
OP_MAX_
};
c
static inline uint8_t op(vm_insn_t x) { return (x >> 24) & 0xFF; }
static inline uint8_t rd(vm_insn_t x) { return (x >> 19) & 0x1F; }
static inline uint8_t ra(vm_insn_t x) { return (x >> 14) & 0x1F; }
static inline uint8_t rb(vm_insn_t x) { return (x >> 9) & 0x1F; }
static inline int32_t imm9(vm_insn_t x){
int32_t v = (int32_t)(x & 0x1FF); return (v << 23) >> 23;
}
static inline int32_t br_off_se21(vm_insn_t x){
int32_t v = (int32_t)(x & 0x1FFFFF); return (v << 11) >> 11;
}
static inline vm_insn_t ENC_RRR(uint8_t o, uint8_t d, uint8_t a, uint8_t b){...}
static inline vm_insn_t ENC_RI (uint8_t o, uint8_t d, uint8_t a, int32_t i){...}
c
static inline uint8_t op(vm_insn_t x) { return (x >> 24) & 0xFF; }
static inline uint8_t rd(vm_insn_t x) { return (x >> 19) & 0x1F; }
static inline uint8_t ra(vm_insn_t x) { return (x >> 14) & 0x1F; }
static inline uint8_t rb(vm_insn_t x) { return (x >> 9) & 0x1F; }
static inline int32_t imm9(vm_insn_t x){
int32_t v = (int32_t)(x & 0x1FF); return (v << 23) >> 23;
}
static inline int32_t br_off_se21(vm_insn_t x){
int32_t v = (int32_t)(x & 0x1FFFFF); return (v << 11) >> 11;
}
static inline vm_insn_t ENC_RRR(uint8_t o, uint8_t d, uint8_t a, uint8_t b){...}
static inline vm_insn_t ENC_RI (uint8_t o, uint8_t d, uint8_t a, int32_t i){...}
c
typedef struct __attribute__((packed)) {
char magic[4];
uint8_t version;
uint8_t flags;
uint16_t reserved;
uint32_t code_words;
} vmp_bc_header_t;
c
typedef struct __attribute__((packed)) {
char magic[4];
uint8_t version;
uint8_t flags;
uint16_t reserved;
uint32_t code_words;
} vmp_bc_header_t;
c
case OP_LIMM: {
uint8_t dst = rd(ins);
uint64_t val = ((uint64_t)code[pc+1]) | (((uint64_t)code[pc+2]) << 32);
VW(&S, dst, val);
pc += 3;
break;
}
case OP_ADD: {
uint8_t dst = rd(ins), a_reg = ra(ins), b_reg = rb(ins);
uint64_t a = VR(&S, a_reg), b = VR(&S, b_reg);
uint64_t r = a + b;
VW(&S, dst, r);
setNZ_add(&S, a, b, r);
pc++;
break;
}
case OP_CMPrr: {
uint8_t a_reg = ra(ins), b_reg = rb(ins);
uint64_t a = VR(&S, a_reg), b = VR(&S, b_reg);
uint64_t r = a - b;
setNZ_sub(&S, a, b, r);
pc++;
break;
}
case OP_B: {
int32_t off = br_off_se21(ins);
int nxt_pc = pc + off;
pc = nxt_pc;
break;
}
case OP_BCC: {
uint8_t cond = rd(ins) & 0xF;
bool take = false;
switch(cond) {
case 0: take = S.Z; break;
case 1: take = !S.Z; break;
}
if (take) {
int32_t off = br_off_se21(ins);
pc += off;
} else {
pc++;
}
break;
}
case OP_BL: {
uint32_t thunk_idx = code[pc] & 0xFFFFu;
if (is_valid(thunk_idx)) {
long long ret = thunks[thunk_idx](S.R);
VW(&S, 0, (uint64_t)ret);
}
pc++;
break;
}
case OP_RET: {
return (long long)VR(&S, 0);
}
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2025-9-11 17:39
被逆天而行编辑
,原因:









