MD5全称为Message Digest Algorithm 5,消息摘要算法第五代
首先对于MD5的结果为固定的32位,并且为hex字符串的输出,那么实际的长度为16字节:
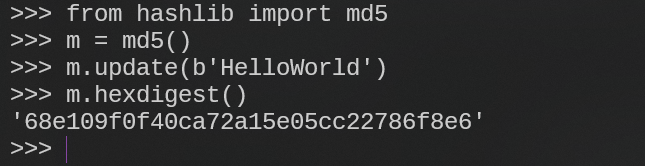
对于HelloWorld的MD5结果为:(==不区分大小写==)
该结果的68描述一个字节,而不是两个字节,所以其结果实际上的位宽为16*8,即128位,对于任意长度的明文数据,最终得到的都是128位的结果,那么该算法得到的结果属于全损压缩,无法从该加密结果中得到原始信息的内容,也无法直接解密出明文,而对于明文中每一位的修改都会影响最终的结果,所以该算法属于散列算法,基于上面描述得到该算法的特点:不可逆性和抗碰撞性,所以广泛用于文件的完整性校验以及签名校验等
关于其可破解,在算法初期通过彩虹表进行md5的碰撞,也即对于通用的明文数据进行加密,将其结果放入彩虹表中,通过查表反推出MD5结果对应的明文数据,由于其加密流程很快速,所以也可以通过暴力破解,通过对明文直接算MD5与结果进行比较,而通过某种算法可实现Hash碰撞,即存在MD5(m1) = MD5(m2)
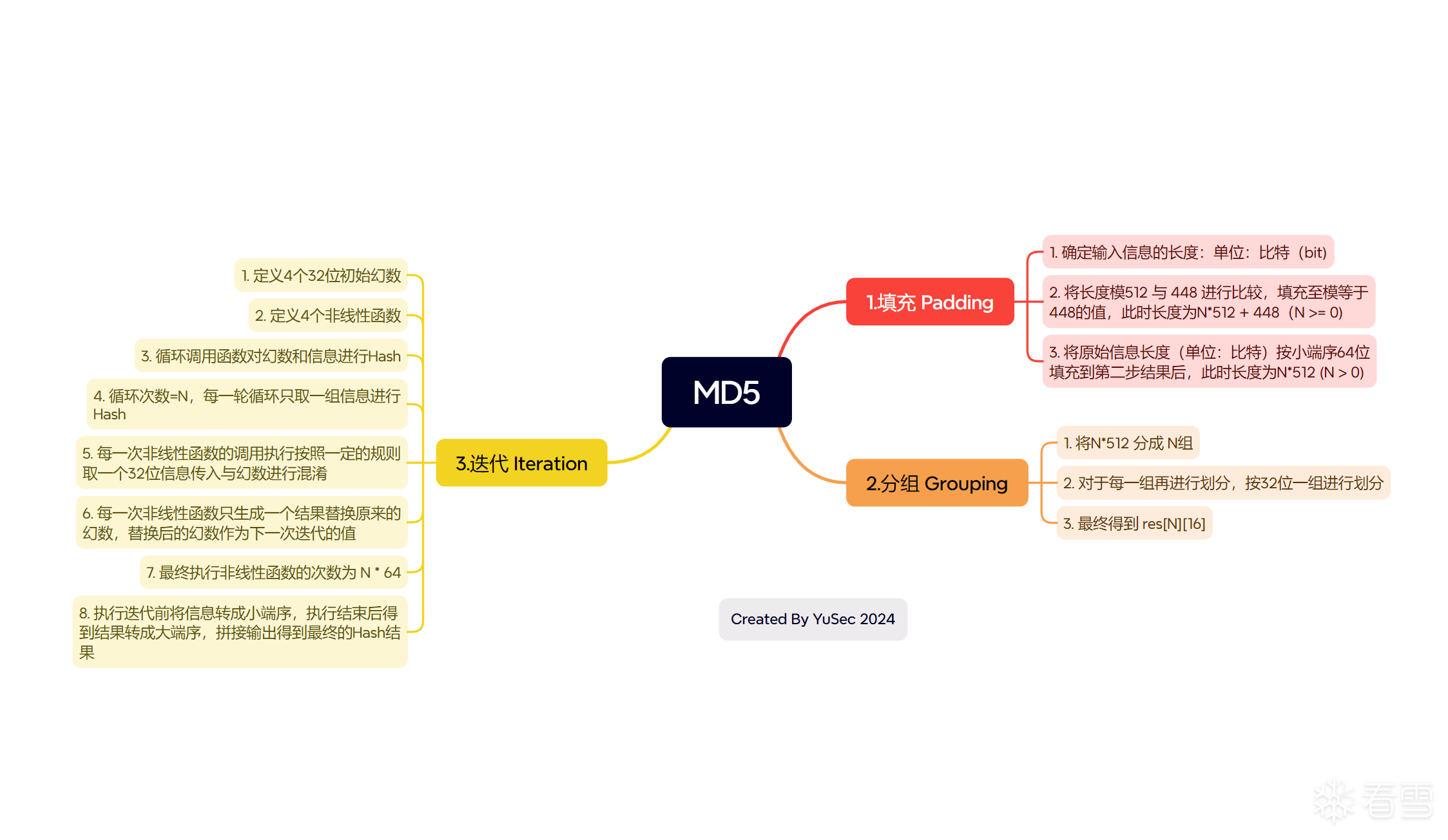
MD5处理步骤
该步骤需要将输入的数据长度填充成模512(bit)等于448(bit)的长度,填充内容为1以及若干个0
存在两种特殊情况:
获取输入数据的bit数,对于每个字符应该为BYTE的长度,否则会影响计算,利用unsigned char数组来接收输入的字符
这里首个字符H的hex值为0x48,实际上是通过整个8位来描述H这个字符,那么实际上的HelloWorld的长度就是10 * 8 = 80位,对于任意长度的信息,其最终的位数都是8的倍数,由于信息长度为8的整数倍,所以就不会出现模512等于447的情况,也就不会出现只移位1位的情况,通过单元测试测试输入
padding函数通过引用传入一个vector数组进行数据填充:
vector移位通过left_shift实现,返回一个移位后的vector容器,该函数需要实现:
单元测试:
第一步填充的正确结果:

确认位数:0b的前缀占用了两位,而python的输出会从1开始算起,所以得到的位数只有449-2=447,实际上在vector中保存的结果长度就是448

将input设置为123456:0x31二进制为0010 0001,所以python转二进制后会省略前面两位得到的就是448,再减0b占位此时输出的实际长度是446,加上省略的两位就是448


第一步填充完成后,此时的数据长度应为N*512 + 448,这里模值为448,就是为了留64位来描述原始输入的数据长度,此时可以描述的信息最大长度为2^64,所以直接通过uint64_t存储原始信息长度,存储单位为bit:
通过uint64ToVector将uint64转成vector<uint8_t>
在插入信息前需要知道大小端概念,对于HelloWorld,其信息长度为0x50,而通过小端存储时会表现为:0x 50 00 00 00 00 00 00 00,所以在追加到信息前需要将其转成小端存储:
最终处理结果:

该步将填充得到的结果按512位为一组进行划分,这也是为何要模512,而由于填充后的位数一定是512,那么最高位一定是1,此时data[0] & 0x80条件为真,不需要考虑data[0]的实际数据长度是否小于类型宽度,
每一组512再按32位进行划分,所以可以根据此定义一个二维vector:
外层vector的数量未定,这取决于输入的信息长度,而内层的vector数量是固定的为16:所以对于每一次循环都可以创建并初始化一个容量为16的uint32_t,通过或操作4个uint8_t并入uint32_t中:
通过步骤一将HelloWorld填充成512位,分割得到:(只有一组512)
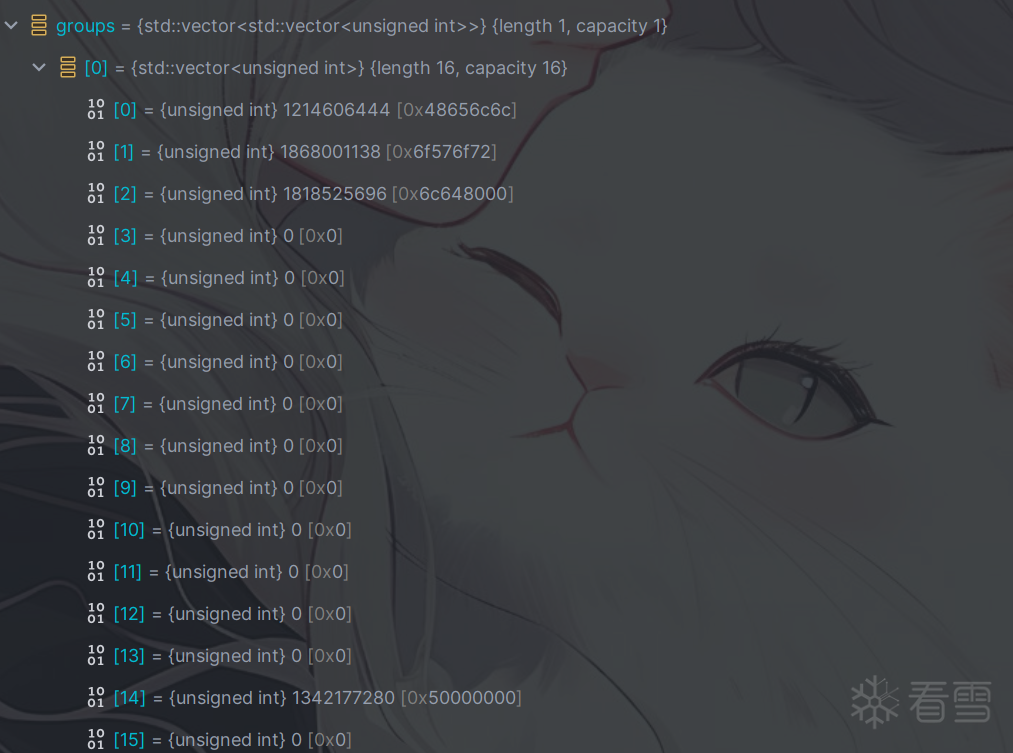
首先定义4个初始的幻数,接下来的所有操作围绕这四个幻数进行:
按照顺序复制一份给res数组:
迭代过程:
循环左移:
非线性函数的子操作,对于输入B,C,D进行与或非操作
⎩⎨⎧F(x,y,z)=(x∧y)∨(¬x∧z)G(x,y,z)=(x∧z)∨(y∧¬z)H(x,y,z)=x⊕y⊕zI(x,y,z)=y⊕(x∨¬z)
迭代操作最简单的就是将每一个函数的参数都逐个传入逐个调用,定义一个transByIterator函数,传入的后四个参数为当前幻数的值,对于分组数大于1的信息,需要多次调用该函数,将每一组执行后的幻数传入:==不同的非线性函数调用时传入的输入信息不是按顺序的==
定义一个vector<uint32_t>用来存储最终的hash结果,注意在调用非线性函数前,需要将输入的信息切换成小端序,而最终的输出需要切回大端序:
单元测试:

对比调用python库的结果:
4个线性函数的操作几乎相同,所以这里采用简化操作,将迭代改成循环,将所有的下标、伪随机数、循环移位的位数设置成数组,幻数也设置成常量,放入constants.h中(此处仅考虑代码简洁性,不考虑其执行性能):
将FF、GG、HH、II四个非线性函数定义为函数指针数组,通过roundFunctions.size()的循环进行调用:
内层循环这里由于伪随机数、移位位数、信息传入顺序都跟调用的非线性函数是一一对应的,所以通过一个for循环取不同的伪随机数数组、移位位数的数组、以及信息传入顺序的数组,再通过i的值判断调用的非线性函数,进入到内层循环对幻数进行Hash,几个矩阵的外层数组都是4,一一对应着每个函数每次迭代时需要的参数,内层则通过内层循环的k进行取值,对于shiftBits需要对4取余进行取值,这里k从16开始的原因是迭代顺序为==A->D->C->B==,所以第二次迭代时res传入的顺序为res[3]->res[0]->res[1]->res[2]
通过循环取值时传入的参数跟迭代类似,只不过此时只需要传入vector<uint32_t>即可:
单元测试:
同样可以成功输入结果

通过main函数调用testing::InitGoogleTest(&argc, argv);, GoogleTest会自动测量每个TEST用例执行的时间,通过该方式比较两个算法下执行时间的差距,经过三次测试,可以发现两种算法的执行效率并无明显区别,通过循环替代直接迭代的算法也无显著影响md5的hash效率:
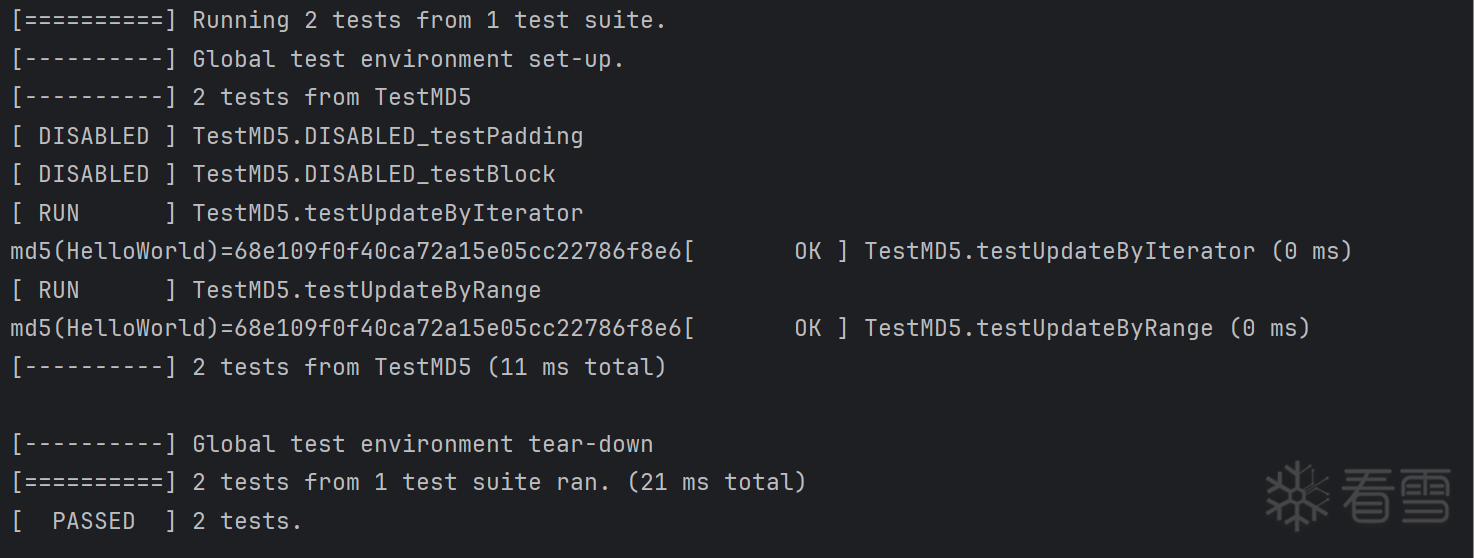
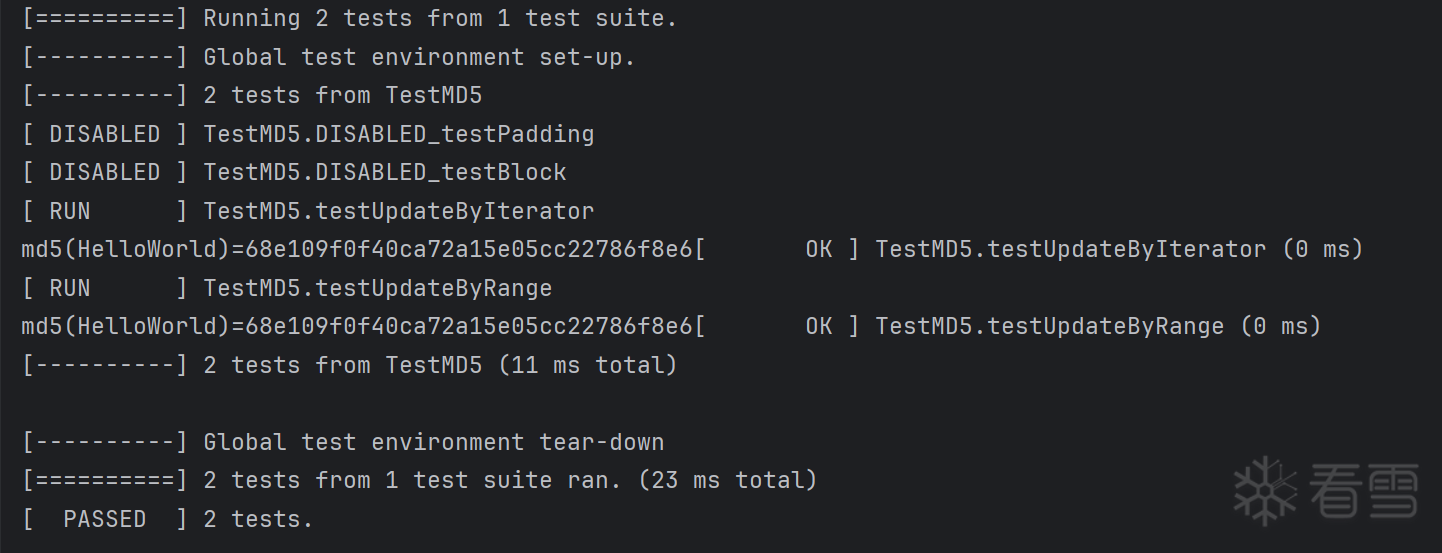
测试填充后分组大于1的信息:

封装单元测试:
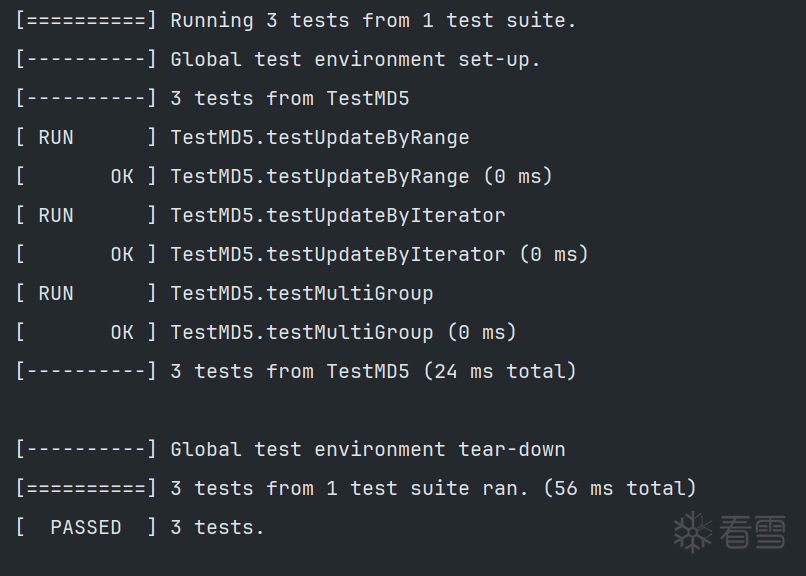
此时单元测试类为TestMD5,单元测试方式由TEST改为TEST_F,分别测试调用迭代器和循环执行的结果是否都正确,并且测试多组信息下结果是否正确:
68E109F0F40CA72A15E05CC22786F8E6
68E109F0F40CA72A15E05CC22786F8E6
size_t x %= 512;
size_t bitsPadding = 0;
if ( x >= 448) {
bitsPadding = 512 - x % 448;
} else {
bitsPadding = 448 - x;
}
size_t x %= 512;
size_t bitsPadding = 0;
if ( x >= 448) {
bitsPadding = 512 - x % 448;
} else {
bitsPadding = 448 - x;
}
vector<uint8_t> data
TEST(TestMD5, testPadding) {
char input[] = "HelloWorld";
vector<uint8_t> plaintext;
plaintext.insert(plaintext.end(), input, input+sizeof(input)-1);
ASSERT_EQ(plaintext.size(), sizeof(input)-1);
}
TEST(TestMD5, testPadding) {
char input[] = "HelloWorld";
vector<uint8_t> plaintext;
plaintext.insert(plaintext.end(), input, input+sizeof(input)-1);
ASSERT_EQ(plaintext.size(), sizeof(input)-1);
}
void MD5::padding(vector<unsigned char> &data) {
uint64_t nBits = data.size() * 8;
size_t paddingBits = 0;
if (nBits % 512 >= 448) {
paddingBits = 512 - nBits % 512 % 448;
} else {
paddingBits = 448 - nBits;
}
data = Tools::left_shift(data, 1);
data[data.size()-1] ^= 0x1;
paddingBits -= 1;
data = Tools::left_shift(data, paddingBits);
}
void MD5::padding(vector<unsigned char> &data) {
uint64_t nBits = data.size() * 8;
size_t paddingBits = 0;
if (nBits % 512 >= 448) {
paddingBits = 512 - nBits % 512 % 448;
} else {
paddingBits = 448 - nBits;
}
data = Tools::left_shift(data, 1);
data[data.size()-1] ^= 0x1;
paddingBits -= 1;
data = Tools::left_shift(data, paddingBits);
}
vector<unsigned char> Tools::left_shift(std::vector<unsigned char> vec, size_t shift) {
if (shift == 0) {
return vec;
}
size_t byte_shift = shift / 8;
size_t bit_shift = shift % 8;
std::vector<unsigned char> result(vec.size() + byte_shift, 0);
for (size_t i = 0; i < vec.size(); ++i) {
result[i] |= (vec[i] << bit_shift);
if (i + 1 < vec.size()) {
result[i] |= (vec[i + 1] >> (8 - bit_shift));
}
}
if (vec[0] >> (8 - bit_shift)) {
result.insert(result.begin(), 1);
result[0] = (vec[0] >> (8 - bit_shift));
}
return result;
}
vector<unsigned char> Tools::left_shift(std::vector<unsigned char> vec, size_t shift) {
if (shift == 0) {
return vec;
}
size_t byte_shift = shift / 8;
size_t bit_shift = shift % 8;
std::vector<unsigned char> result(vec.size() + byte_shift, 0);
for (size_t i = 0; i < vec.size(); ++i) {
result[i] |= (vec[i] << bit_shift);
if (i + 1 < vec.size()) {
result[i] |= (vec[i + 1] >> (8 - bit_shift));
}
}
if (vec[0] >> (8 - bit_shift)) {
result.insert(result.begin(), 1);
result[0] = (vec[0] >> (8 - bit_shift));
}
return result;
}
TEST(TestMD5, testPadding) {
char input[] = "HelloWorld";
vector<uint8_t> plaintext;
plaintext.insert(plaintext.end(), input, input+sizeof(input)-1);
string hexString = Tools::toHexString(plaintext);
cout << "Origin hexString: " << hexString << endl;
MD5 md5;
md5.padding(plaintext);
hexString = Tools::toHexString(plaintext);
cout << "Padding hexString: " << hexString << endl;
}
TEST(TestMD5, testPadding) {
char input[] = "HelloWorld";
vector<uint8_t> plaintext;
plaintext.insert(plaintext.end(), input, input+sizeof(input)-1);
string hexString = Tools::toHexString(plaintext);
cout << "Origin hexString: " << hexString << endl;
MD5 md5;
md5.padding(plaintext);
hexString = Tools::toHexString(plaintext);
cout << "Padding hexString: " << hexString << endl;
}
uint64_t nBits = data.size() * 8;
uint64_t nBits = data.size() * 8;
vector<unsigned char> Tools::uint64ToVector(uint64_t value) {
vector<uint8_t> vec(8);
for (size_t i = 0; i < 8; ++i) {
vec[i] = static_cast<uint8_t>((value >> ((7 - i) * 8)) & 0xFF);
}
return vec;
}
vector<unsigned char> Tools::uint64ToVector(uint64_t value) {
vector<uint8_t> vec(8);
for (size_t i = 0; i < 8; ++i) {
vec[i] = static_cast<uint8_t>((value >> ((7 - i) * 8)) & 0xFF);
}
return vec;
}
uint64_t Tools::swapEndian64(uint64_t x) {
return ((x >> 56) & 0xff) |
((x >> 40) & 0xff00) |
((x >> 24) & 0xff0000) |
((x >> 8) & 0xff000000) |
((x << 8) & 0xff00000000) |
((x << 24) & 0xff0000000000) |
((x << 40) & 0xff000000000000) |
((x << 56) & 0xff00000000000000);
}
uint64_t Tools::swapEndian64(uint64_t x) {
return ((x >> 56) & 0xff) |
((x >> 40) & 0xff00) |
((x >> 24) & 0xff0000) |
((x >> 8) & 0xff000000) |
((x << 8) & 0xff00000000) |
((x << 24) & 0xff0000000000) |
((x << 40) & 0xff000000000000) |
((x << 56) & 0xff00000000000000);
}
void MD5::padding(vector<unsigned char> &data) {
uint64_t nBits = data.size() * 8;
vector<uint8_t> MessageSize = Tools::uint64ToVector(Tools::swapEndian64(nBits));
data.insert(data.end(), MessageSize.begin(), MessageSize.end());
void MD5::padding(vector<unsigned char> &data) {
uint64_t nBits = data.size() * 8;
vector<uint8_t> MessageSize = Tools::uint64ToVector(Tools::swapEndian64(nBits));
data.insert(data.end(), MessageSize.begin(), MessageSize.end());
size_t groupCount = data.size() * 8 / 512;
vector<vector<uint32_t>> groups(groupCount);
size_t groupCount = data.size() * 8 / 512;
vector<vector<uint32_t>> groups(groupCount);
for (size_t i = 0; i < groupCount; i++) {
groups[i] = vector<uint32_t>(16, 0);
for (size_t j = 0; j < 16; j++) {
for (size_t k = 0; k < 4; k++) {
groups[i][j] |= (uint32_t)data[i*64+j*4+k] << ((3-k)*8);
}
}
}
for (size_t i = 0; i < groupCount; i++) {
groups[i] = vector<uint32_t>(16, 0);
for (size_t j = 0; j < 16; j++) {
for (size_t k = 0; k < 4; k++) {
groups[i][j] |= (uint32_t)data[i*64+j*4+k] << ((3-k)*8);
}
}
}
const uint32_t A = 0x67452301;
const uint32_t B = 0xEFCDAB89;
const uint32_t C = 0x98BADCFE;
const uint32_t D = 0x10325476;
const uint32_t A = 0x67452301;
const uint32_t B = 0xEFCDAB89;
const uint32_t C = 0x98BADCFE;
const uint32_t D = 0x10325476;
vector<uint32_t> res = {A, B, C, D};
vector<uint32_t> res = {A, B, C, D};
uint32_t MD5::FF(uint32_t a, uint32_t b, uint32_t c,
uint32_t d, uint32_t M, uint32_t t, uint32_t shift) {
return b + Tools::rotate_left(a + this->F(b,c,d) + M + t, shift);
}
uint32_t MD5::GG(uint32_t a, uint32_t b, uint32_t c,
uint32_t d, uint32_t M, uint32_t t, uint32_t shift) {
return b + Tools::rotate_left(a + this->G(b, c, d) + M + t, shift);
}
uint32_t MD5::HH(uint32_t a, uint32_t b, uint32_t c,
uint32_t d, uint32_t M, uint32_t t, uint32_t shift) {
return b + Tools::rotate_left(a + this->H(b, c, d) + M + t, shift);
}
uint32_t MD5::II(uint32_t a, uint32_t b, uint32_t c,
uint32_t d, uint32_t M, uint32_t t, uint32_t shift) {
return b + Tools::rotate_left(a + this->I(b, c, d) + M + t, shift);
}
uint32_t MD5::FF(uint32_t a, uint32_t b, uint32_t c,
uint32_t d, uint32_t M, uint32_t t, uint32_t shift) {
return b + Tools::rotate_left(a + this->F(b,c,d) + M + t, shift);
}
uint32_t MD5::GG(uint32_t a, uint32_t b, uint32_t c,
uint32_t d, uint32_t M, uint32_t t, uint32_t shift) {
return b + Tools::rotate_left(a + this->G(b, c, d) + M + t, shift);
}
uint32_t MD5::HH(uint32_t a, uint32_t b, uint32_t c,
uint32_t d, uint32_t M, uint32_t t, uint32_t shift) {
return b + Tools::rotate_left(a + this->H(b, c, d) + M + t, shift);
}
uint32_t MD5::II(uint32_t a, uint32_t b, uint32_t c,
uint32_t d, uint32_t M, uint32_t t, uint32_t shift) {
return b + Tools::rotate_left(a + this->I(b, c, d) + M + t, shift);
}
uint32_t Tools::rotate_left(uint32_t value, uint8_t shift) {
const int bits = 32;
shift %= bits;
return (value << shift) | (value >> (bits - shift));
}
uint32_t Tools::rotate_left(uint32_t value, uint8_t shift) {
const int bits = 32;
shift %= bits;
return (value << shift) | (value >> (bits - shift));
}
void MD5::transByIterator(vector<uint32_t> &v, uint32_t &A, uint32_t &B, uint32_t &C, uint32_t &D) {
A = this->FF(A, B, C, D, v[0], 0xd76aa478, 7);
D = this->FF(D, A, B, C, v[1], 0xe8c7b756, 12);
C = this->FF(C, D, A, B, v[2], 0x242070db, 17);
B = this->FF(B, C, D, A, v[3], 0xc1bdceee, 22);
A = this->FF(A, B, C, D, v[4], 0xf57c0faf, 7);
D = this->FF(D, A, B, C, v[5], 0x4787c62a, 12);
C = this->FF(C, D, A, B, v[6], 0xa8304613, 17);
B = this->FF(B, C, D, A, v[7], 0xfd469501, 22);
A = this->FF(A, B, C, D, v[8], 0x698098d8, 7);
D = this->FF(D, A, B, C, v[9], 0x8b44f7af, 12);
C = this->FF(C, D, A, B, v[10], 0xffff5bb1 , 17);
B = this->FF(B, C, D, A, v[11], 0x895cd7be, 22);
A = this->FF(A, B, C, D, v[12], 0x6b901122, 7);
D = this->FF(D, A, B, C, v[13], 0xfd987193 , 12);
C = this->FF(C, D, A, B, v[14], 0xa679438e, 17);
B = this->FF(B, C, D, A, v[15], 0x49b40821 , 22);
A = this->GG(A, B, C, D, v[1], 0xf61e2562, 5);
D = this->GG(D, A, B, C, v[6], 0xc040b340, 9);
C = this->GG(C, D, A, B, v[11], 0x265e5a51, 14);
B = this->GG(B, C, D, A, v[0], 0xe9b6c7aa, 20);
A = this->GG(A, B, C, D, v[5], 0xd62f105d, 5);
D = this->GG(D, A, B, C, v[10], 0x02441453, 9);
C = this->GG(C, D, A, B, v[15], 0xd8a1e681, 14);
B = this->GG(B, C, D, A, v[4], 0xe7d3fbc8, 20);
A = this->GG(A, B, C, D, v[9], 0x21e1cde6, 5);
D = this->GG(D, A, B, C, v[14], 0xc33707d6, 9);
C = this->GG(C, D, A, B, v[3], 0xf4d50d87, 14);
B = this->GG(B, C, D, A, v[8], 0x455a14ed, 20);
A = this->GG(A, B, C, D, v[13], 0xa9e3e905, 5);
D = this->GG(D, A, B, C, v[2], 0xfcefa3f8, 9);
C = this->GG(C, D, A, B, v[7], 0x676f02d9, 14);
B = this->GG(B, C, D, A, v[12], 0x8d2a4c8a, 20);
A = this->HH(A, B, C, D, v[5], 0xfffa3942, 4);
D = this->HH(D, A, B, C, v[8], 0x8771f681, 11);
C = this->HH(C, D, A, B, v[11], 0x6d9d6122, 16);
B = this->HH(B, C, D, A, v[14], 0xfde5380c, 23);
A = this->HH(A, B, C, D, v[1], 0xa4beea44, 4);
D = this->HH(D, A, B, C, v[4], 0x4bdecfa9, 11);
C = this->HH(C, D, A, B, v[7], 0xf6bb4b60, 16);
B = this->HH(B, C, D, A, v[10], 0xbebfbc70, 23);
A = this->HH(A, B, C, D, v[13], 0x289b7ec6, 4);
D = this->HH(D, A, B, C, v[0], 0xeaa127fa, 11);
C = this->HH(C, D, A, B, v[3], 0xd4ef3085, 16);
B = this->HH(B, C, D, A, v[6], 0x04881d05, 23);
A = this->HH(A, B, C, D, v[9], 0xd9d4d039, 4);
D = this->HH(D, A, B, C, v[12], 0xe6db99e5, 11);
C = this->HH(C, D, A, B, v[15], 0x1fa27cf8, 16);
B = this->HH(B, C, D, A, v[2], 0xc4ac5665, 23);
A = this->II(A, B, C, D, v[0], 0xf4292244, 6);
D = this->II(D, A, B, C, v[7], 0x432aff97, 10);
C = this->II(C, D, A, B, v[14], 0xab9423a7, 15);
B = this->II(B, C, D, A, v[5], 0xfc93a039, 21);
A = this->II(A, B, C, D, v[12], 0x655b59c3, 6);
D = this->II(D, A, B, C, v[3], 0x8f0ccc92, 10);
C = this->II(C, D, A, B, v[10], 0xffeff47d, 15);
B = this->II(B, C, D, A, v[1], 0x85845dd1, 21);
A = this->II(A, B, C, D, v[8], 0x6fa87e4f, 6);
D = this->II(D, A, B, C, v[15], 0xfe2ce6e0, 10);
C = this->II(C, D, A, B, v[6], 0xa3014314, 15);
B = this->II(B, C, D, A, v[13], 0x4e0811a1, 21);
A = this->II(A, B, C, D, v[4], 0xf7537e82, 6);
D = this->II(D, A, B, C, v[11], 0xbd3af235, 10);
C = this->II(C, D, A, B, v[2], 0x2ad7d2bb, 15);
B = this->II(B, C, D, A, v[9], 0xeb86d391, 21);
}
void MD5::transByIterator(vector<uint32_t> &v, uint32_t &A, uint32_t &B, uint32_t &C, uint32_t &D) {
A = this->FF(A, B, C, D, v[0], 0xd76aa478, 7);
D = this->FF(D, A, B, C, v[1], 0xe8c7b756, 12);
C = this->FF(C, D, A, B, v[2], 0x242070db, 17);
B = this->FF(B, C, D, A, v[3], 0xc1bdceee, 22);
A = this->FF(A, B, C, D, v[4], 0xf57c0faf, 7);
D = this->FF(D, A, B, C, v[5], 0x4787c62a, 12);
C = this->FF(C, D, A, B, v[6], 0xa8304613, 17);
B = this->FF(B, C, D, A, v[7], 0xfd469501, 22);
A = this->FF(A, B, C, D, v[8], 0x698098d8, 7);
D = this->FF(D, A, B, C, v[9], 0x8b44f7af, 12);
C = this->FF(C, D, A, B, v[10], 0xffff5bb1 , 17);
B = this->FF(B, C, D, A, v[11], 0x895cd7be, 22);
A = this->FF(A, B, C, D, v[12], 0x6b901122, 7);
D = this->FF(D, A, B, C, v[13], 0xfd987193 , 12);
C = this->FF(C, D, A, B, v[14], 0xa679438e, 17);
B = this->FF(B, C, D, A, v[15], 0x49b40821 , 22);
A = this->GG(A, B, C, D, v[1], 0xf61e2562, 5);
D = this->GG(D, A, B, C, v[6], 0xc040b340, 9);
C = this->GG(C, D, A, B, v[11], 0x265e5a51, 14);
B = this->GG(B, C, D, A, v[0], 0xe9b6c7aa, 20);
A = this->GG(A, B, C, D, v[5], 0xd62f105d, 5);
D = this->GG(D, A, B, C, v[10], 0x02441453, 9);
C = this->GG(C, D, A, B, v[15], 0xd8a1e681, 14);
B = this->GG(B, C, D, A, v[4], 0xe7d3fbc8, 20);
A = this->GG(A, B, C, D, v[9], 0x21e1cde6, 5);
D = this->GG(D, A, B, C, v[14], 0xc33707d6, 9);
C = this->GG(C, D, A, B, v[3], 0xf4d50d87, 14);
B = this->GG(B, C, D, A, v[8], 0x455a14ed, 20);
A = this->GG(A, B, C, D, v[13], 0xa9e3e905, 5);
D = this->GG(D, A, B, C, v[2], 0xfcefa3f8, 9);
C = this->GG(C, D, A, B, v[7], 0x676f02d9, 14);
B = this->GG(B, C, D, A, v[12], 0x8d2a4c8a, 20);
A = this->HH(A, B, C, D, v[5], 0xfffa3942, 4);
D = this->HH(D, A, B, C, v[8], 0x8771f681, 11);
C = this->HH(C, D, A, B, v[11], 0x6d9d6122, 16);
B = this->HH(B, C, D, A, v[14], 0xfde5380c, 23);
A = this->HH(A, B, C, D, v[1], 0xa4beea44, 4);
D = this->HH(D, A, B, C, v[4], 0x4bdecfa9, 11);
C = this->HH(C, D, A, B, v[7], 0xf6bb4b60, 16);
B = this->HH(B, C, D, A, v[10], 0xbebfbc70, 23);
A = this->HH(A, B, C, D, v[13], 0x289b7ec6, 4);
D = this->HH(D, A, B, C, v[0], 0xeaa127fa, 11);
C = this->HH(C, D, A, B, v[3], 0xd4ef3085, 16);
B = this->HH(B, C, D, A, v[6], 0x04881d05, 23);
A = this->HH(A, B, C, D, v[9], 0xd9d4d039, 4);
D = this->HH(D, A, B, C, v[12], 0xe6db99e5, 11);
C = this->HH(C, D, A, B, v[15], 0x1fa27cf8, 16);
B = this->HH(B, C, D, A, v[2], 0xc4ac5665, 23);
A = this->II(A, B, C, D, v[0], 0xf4292244, 6);
D = this->II(D, A, B, C, v[7], 0x432aff97, 10);
C = this->II(C, D, A, B, v[14], 0xab9423a7, 15);
B = this->II(B, C, D, A, v[5], 0xfc93a039, 21);
A = this->II(A, B, C, D, v[12], 0x655b59c3, 6);
D = this->II(D, A, B, C, v[3], 0x8f0ccc92, 10);
C = this->II(C, D, A, B, v[10], 0xffeff47d, 15);
B = this->II(B, C, D, A, v[1], 0x85845dd1, 21);
A = this->II(A, B, C, D, v[8], 0x6fa87e4f, 6);
D = this->II(D, A, B, C, v[15], 0xfe2ce6e0, 10);
C = this->II(C, D, A, B, v[6], 0xa3014314, 15);
B = this->II(B, C, D, A, v[13], 0x4e0811a1, 21);
A = this->II(A, B, C, D, v[4], 0xf7537e82, 6);
D = this->II(D, A, B, C, v[11], 0xbd3af235, 10);
C = this->II(C, D, A, B, v[2], 0x2ad7d2bb, 15);
B = this->II(B, C, D, A, v[9], 0xeb86d391, 21);
}
vector<uint32_t> MD5::update1(vector<vector<uint32_t>> &groups) {
vector<uint32_t> res = {A, B, C, D};
for (size_t i = 0; i < groups.size(); i++) {
this->encode(groups[i]);
}
size_t i = 0;
while (i < groups.size()) {
uint32_t tmp_A = res[0];
uint32_t tmp_B = res[1];
uint32_t tmp_C = res[2];
uint32_t tmp_D = res[3];
this->transByIterator(groups[i], tmp_A, tmp_B, tmp_C, tmp_D);
res[0] += tmp_A; res[1] += tmp_B; res[2] += tmp_C; res[3] += tmp_D;
i++;
}
this->decode(res);
return res;
}
vector<uint32_t> MD5::update1(vector<vector<uint32_t>> &groups) {
vector<uint32_t> res = {A, B, C, D};
for (size_t i = 0; i < groups.size(); i++) {
this->encode(groups[i]);
}
size_t i = 0;
while (i < groups.size()) {
uint32_t tmp_A = res[0];
uint32_t tmp_B = res[1];
uint32_t tmp_C = res[2];
uint32_t tmp_D = res[3];
this->transByIterator(groups[i], tmp_A, tmp_B, tmp_C, tmp_D);
res[0] += tmp_A; res[1] += tmp_B; res[2] += tmp_C; res[3] += tmp_D;
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!






