有人可能会问:怎么又是虚拟机的文章?其实我认为,其他方向大多数都已经有不少人分析过了,再去写类似的内容意义不大。而虚拟机保护的分析门槛相对较高,相关的文章也相对较少,因此我选择了这个方向。
虚拟机保护到目前为止依然是许多人难以跨越的门槛。但在当前的逆向工程实践中,虚拟机并不是通往目标的唯一路径。很多时候,我们可以绕过虚拟机本身,通过 trace 等方式,直接回溯 app 的指令与数据流。即便最终需要还原虚拟机,其所占的工程量其实也有限,可能只占整体工作的 5%-10%。
每个人的分析思路、工具使用习惯、乃至对逆向工程的理解都有差异。本文只是分享我个人的一些分析方法和思考方式,或许不是最优解,有些方法在别人看来甚至显得笨拙。但每个人都有自己的技术盲区,正因如此,才需要交流。欢迎大家留言指出我的不足,共同进步。
随着这几年对抗手段的不断升级,目前大厂几乎都采用了虚拟机保护,导致分析工作量大幅上升。一个人对抗一个企业多个安全团队的情况,已显得力不从心,单兵作战早已成为过去式。
逆向工程从来不是一件轻松的事。很多时候,分析过程更像是一种精神上的磨炼。但时间久了,你会慢慢适应这种状态。逆向涉及的内容极其广泛:经验、知识面、理解能力、甚至天赋。可惜这些我似乎都不怎么占优,有时候还会钻进死胡同出不来。但这就是逆向的魅力所在——永远有新的挑战,永远有成长的空间。
App版本:versionCode='1200280405' versionName='12.28.405'
手机系统:android 11/pixel 2 xl
PC: macOS 15.3
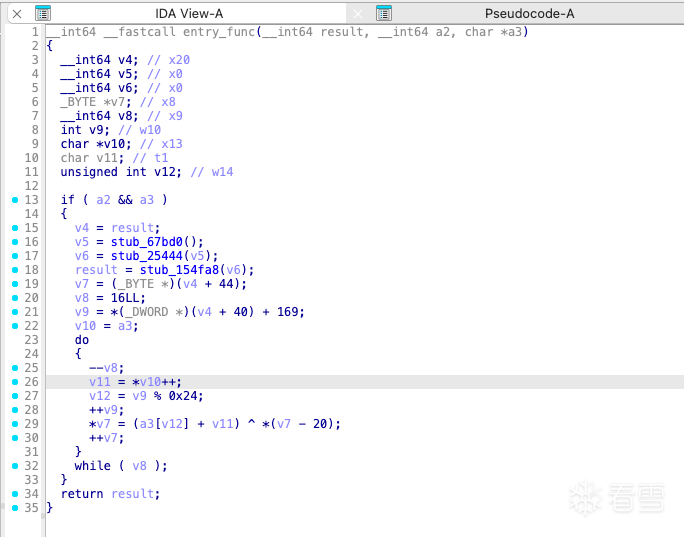
以 vm_interpreter 函数为例,它的起止边界很清晰,代码也没有和其他函数混在一起,说明混淆或乱序只是发生在这个函数内部。
分析中发现代码块(由多个连续基本块组成)在结尾处都使用了无条件跳转指令进行连接。
在正常编译生成的代码中,无条件跳转一般出现在结构控制语句的位置,比如:if-then-end、if-else-end、break、continue、switch-case、switch-end、循环入口、循环体和循环出口等。但在当前分析的代码中,无条件跳转的数量明显异常。
看来app加密开发者还是很懂逆向的,一般来说handler执行完成会回到取指的基本块位置,这里将分发取指的基本块进行了复制作为handler的后续终止符进行连接,防止一个位置下断或hook拿取opcode数据。
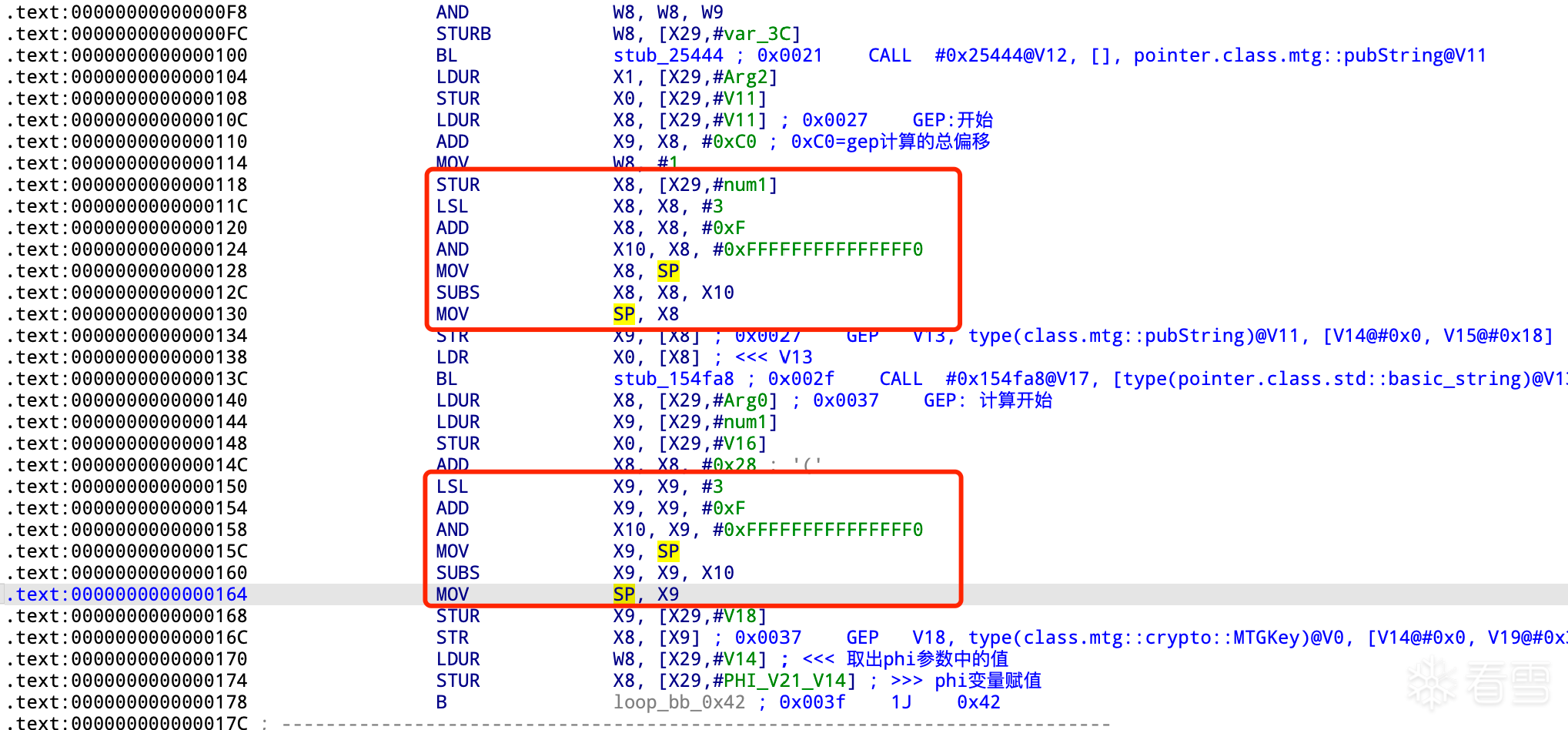
去除间接跳转的目的是为了便于在 IDA 中查看和分析代码结构。
运行上面的删除间接跳转 脚本应用补丁后,重新加载分析文件,等 IDA Pro分析完成后,打开函数视图(Functions window),点击函数列表上方的 Length 表头,以函数大小进行排序。
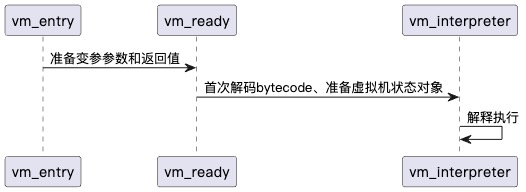
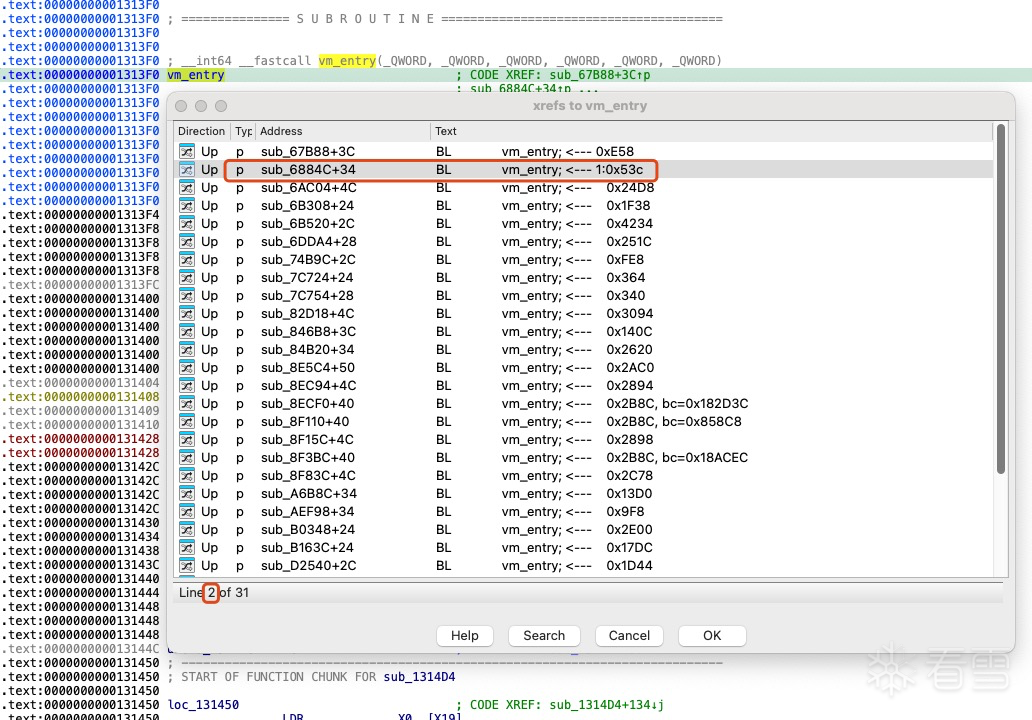
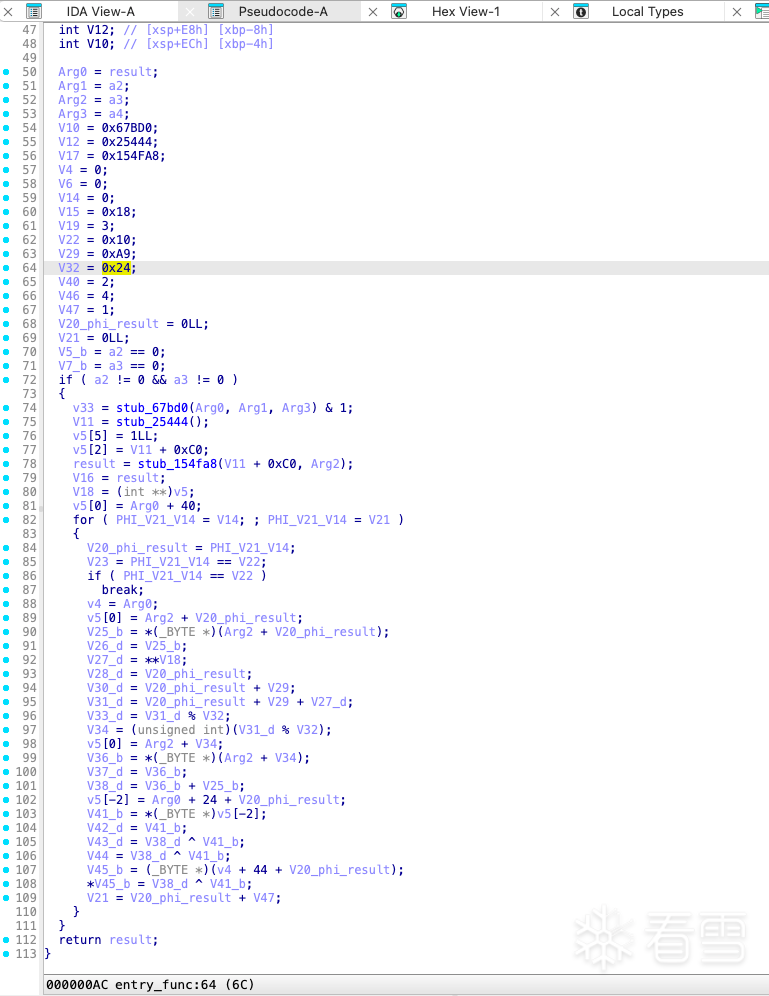
虚拟机入口点(vm_entry)的起始地址是 0x1313F0。在该地址处,存在 31 个引用地址,这些引用地址指示了 31 个将被虚拟化执行的函数的入口。其中,编号为 2 的引用地址指向了应用程序启动后首次执行的虚拟机代码。接下来,将从该地址开始逐步展开分析。
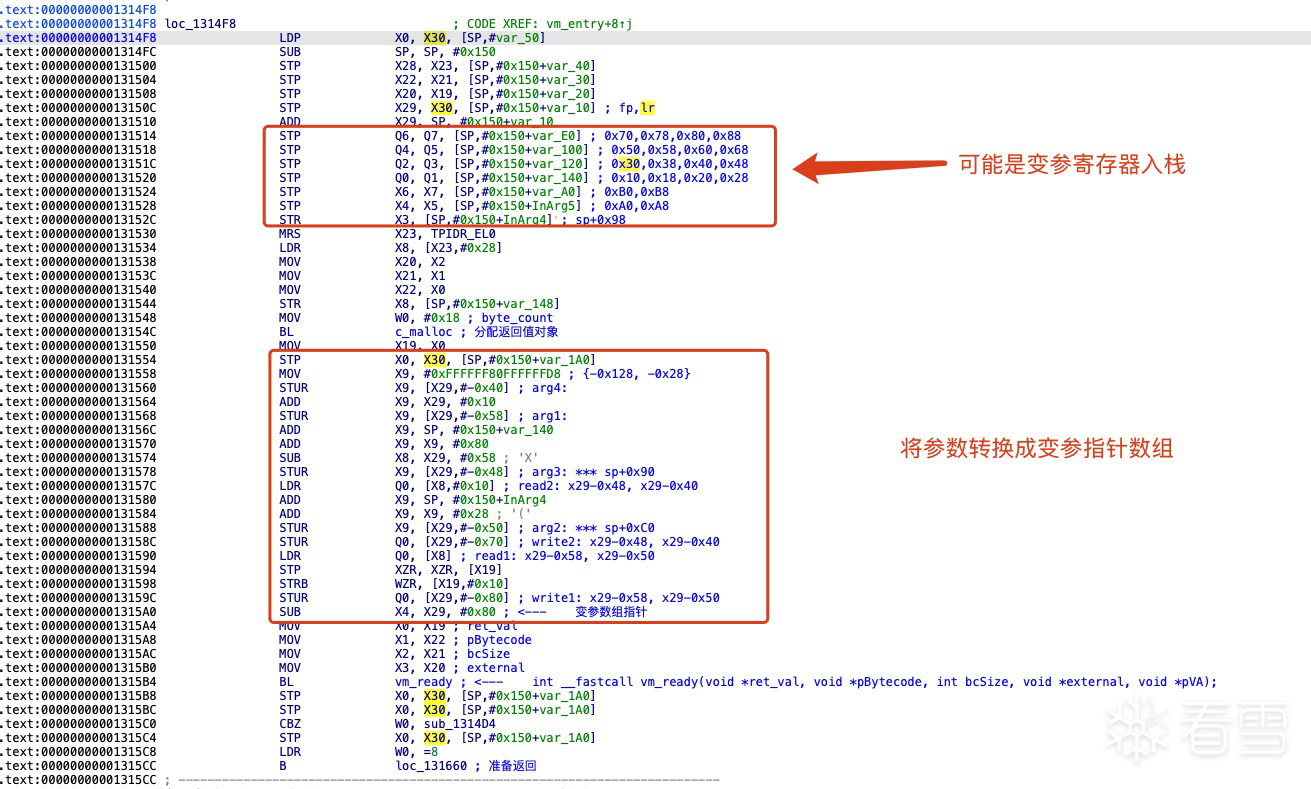
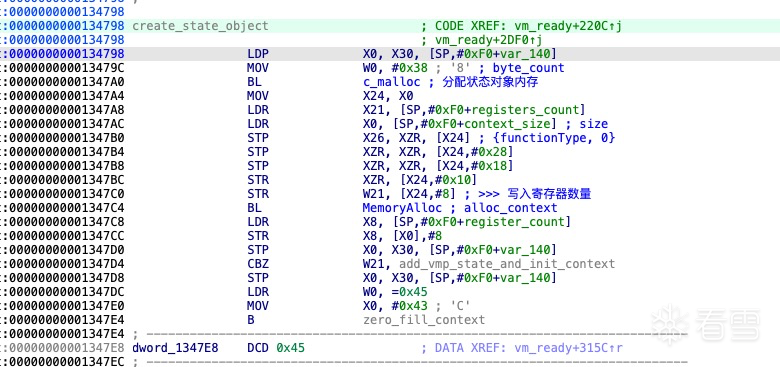
描述:准备参数和返回值对象bytecode: 字节码指针bc_size: 字节码大小external: 外部指针数组,它可能包含外部函数地址和全局变量指针。
描述:构建或准备bytecode对应的VMPState对象,bytecode映射一个VMPState。pRetVal: 返回值regCount: 虚拟寄存器数量pRegister: 虚拟寄存器typeCount: 类型表数据pTypeList: 类型表insCount: 虚拟机指令数量pInstructons: 虚拟机指令pBranchs: 分支表
解析器较为复杂,因此本文将重点介绍简单的 handler 分析过程。分析过程中,务必时刻清楚以下五个重要数据的位置和含义:虚拟机 PC 、指令对象 、上下文对象 、类型表对象 。对于分支表对象 ,则需要在遇到分支指令时重点关注。如果不明确这些信息,分析时很容易迷失方向。
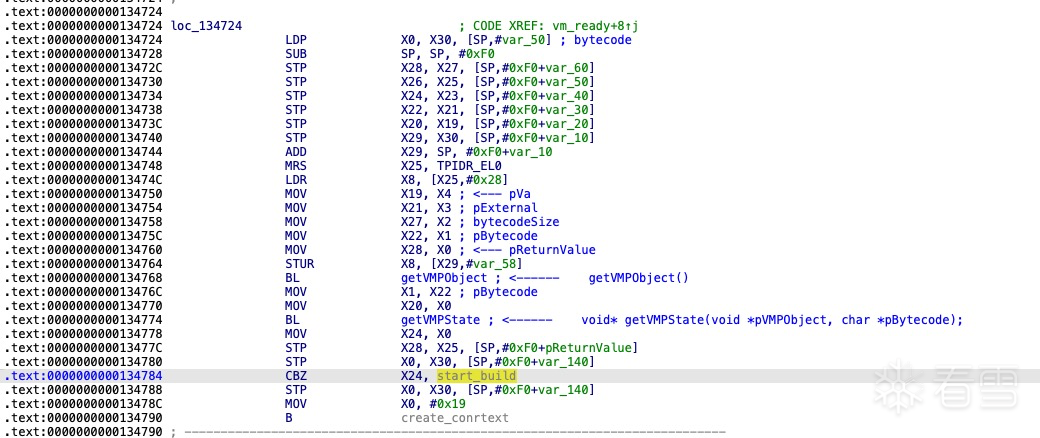
getVMPObject函数
获取全局虚拟机缓存对象,其返回值是一个 std::list
getVMPState
根据输入参数 pBytecode,尝试从缓存中查找对应的 VMPState 对象。如果缓存中不存在该 VMPState 对象,则跳转到 start_build 函数解析 bytecode 并生成新的 VMPState 对象(相关分析参考bytecode首次解码 )。否则(即缓存命中),则开始创建上下文对象。
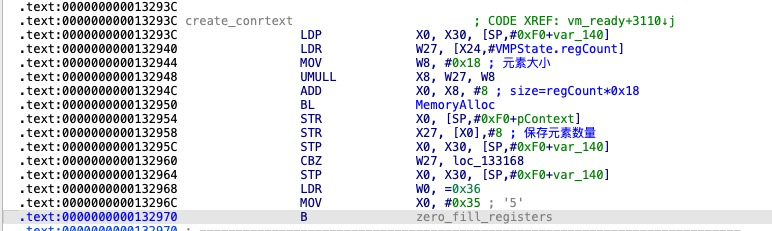
创建一个上下文对象 初始化寄存器
将全部寄存器初始化为0值
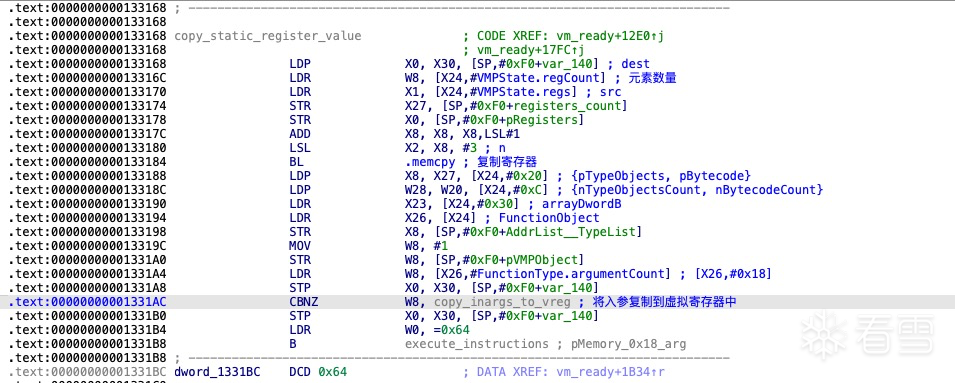
复制寄存器数据
在首次解码过程中,部分寄存器将被赋予初始值。这些初始值来源于未加密的原始汇编代码常量,因其不可修改特性,需创建寄存器副本。
复制入参到虚拟机寄存器
若未检测到输入参数,则执行vm_interpreter;否则,按传入顺序将可变参数加载至虚拟寄存器序列(从V0开始顺序存储)。
数据结构VMPState->entryFunction保存着加密前的函数信息,其中包括参数数量、参数的类型和返回值
准备执行
在进入解释器之前,系统会将 VMPState 的数据结构成员作为参数传入,为执行虚拟机解释器做准备。
void *pRetVal: 返回值
int regCount: 虚拟寄存器数量
void *pRegister: 虚拟机寄存器
int typeCount: 类型表数量
void **pTypeList: 类型表
int insCount: 虚拟机指令数量
int16_t **pInstructons: 虚拟机指令
int16_t **pBranchs: 分支表
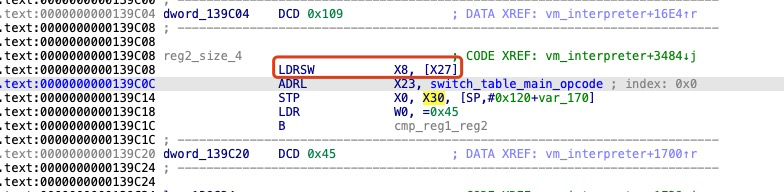
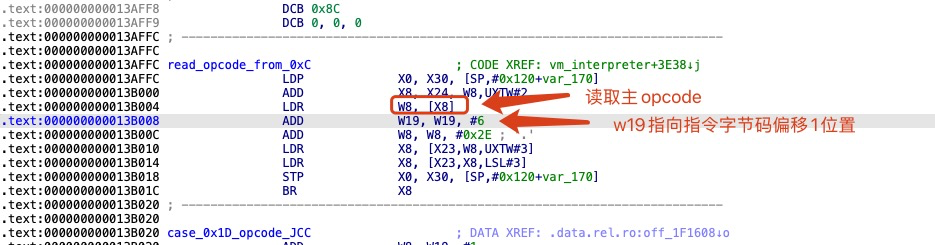
首次读取主操作码
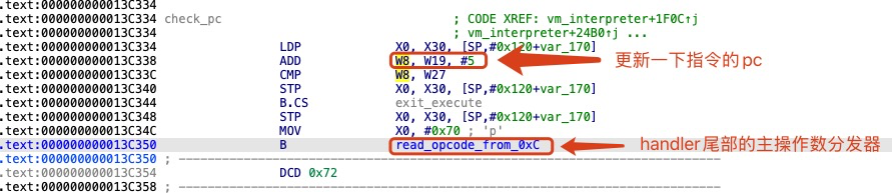
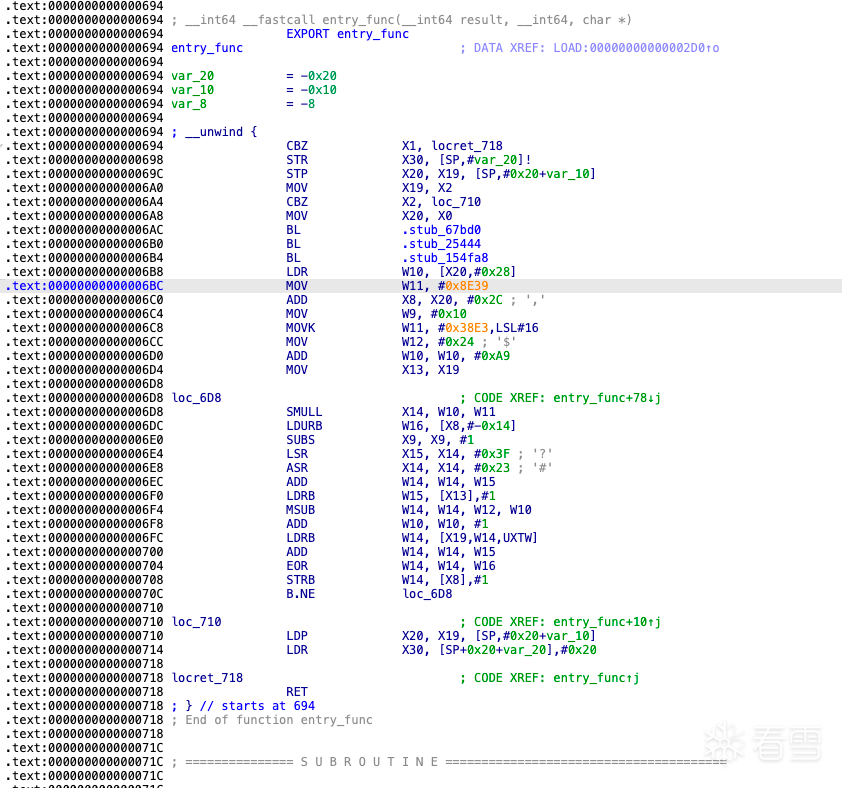
在进入解释器之后,这里的指令分发逻辑只会执行一次。由于指令分发基本块被分别复制到了 13 个 handler 的尾部,每个 handler 都拥有独立的主操作码分发器。当一个 handler 执行完成后,会继续读取下一条虚拟机指令的主操作码,并跳转至对应的下一个 handler。具体实现细节可参见上面的相关章节指令分发基本块复制 。
分发指令时关注对象 :
虚拟pc: 0x0
指令对象:X24
在读取主操作数时,需要关注两个关键对象:指令对象的指针和程序计数器(PC)。刚开始执行时,PC 的初始值为 0,此时只需关注寄存器 x24 中保存的指令对象。然而需要注意的是,在某些主操作码分发器中,指令对象可能被保存在其他通用寄存器中,而不是固定的 x24。
13A5C0 MOV W19, #1
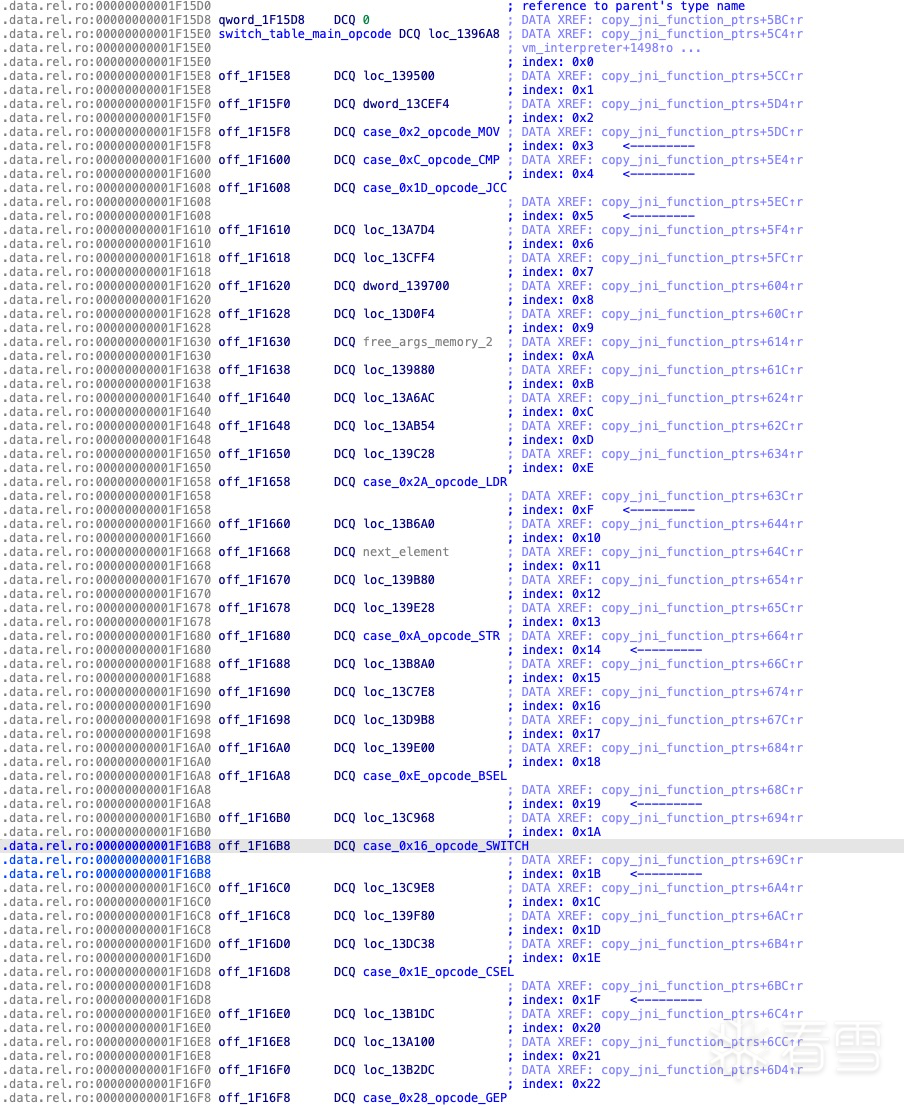
主操作码switch分发表
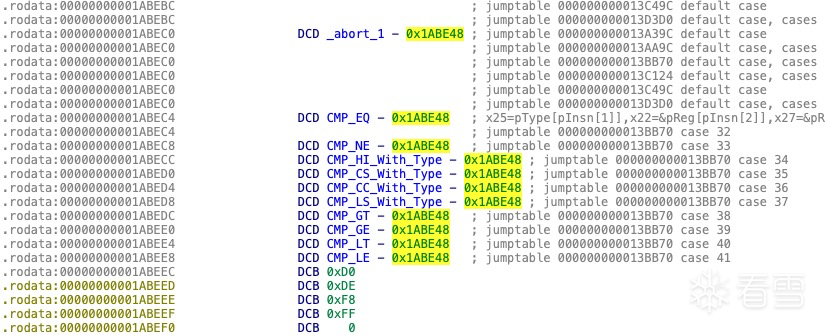
switch 表中共包含 13 个真实的 handler。图中未命名、以 loc_ 开头且显示为暗蓝色的条目,其实是用于填充的伪造地址,并不对应任何实际的 handler 实现,目的是干扰分析、增加反汇编时的迷惑性。
下图展示了虚拟机支持的全部指令集,以及每条指令是否包含第二操作码的情况。若某条指令存在第二操作码,通常意味着该指令会触发一次额外的 switch 子分发,用于进一步解析其具体行为。
本节仅介绍部分基础指令的分析过程,旨在帮助读者理解虚拟机指令的基本结构与执行逻辑。对于更复杂的指令,因涉及内容较多,以避免影响整体内容的条理性。
MOV 指令格式 (6): [opcode, op2, dtype, stype, sreg, dreg]
汇编语法:
MOV dreg, sreg
有时,MOV 指令并不只是简单地将源寄存器的值复制到目标寄存器,它还可能隐含执行零扩展、有符号扩展、截断等操作。这类行为的多样性也是为什么需要使用 op2 作为第二操作码,以进一步指定具体的数据处理方式。
提示:IDA PRO中的注释op和pBytecode是同一个指针变量两者等价,原因是我懒得一个一个的去回改注释了。
在分析虚拟机执行流程时,几个关键对象的重要性大致可以按以下顺序排列:虚拟机 PC、指令对象、上下文对象、类型表对象,以及分支表对象(仅在遇到分支类指令时需要特别关注)。
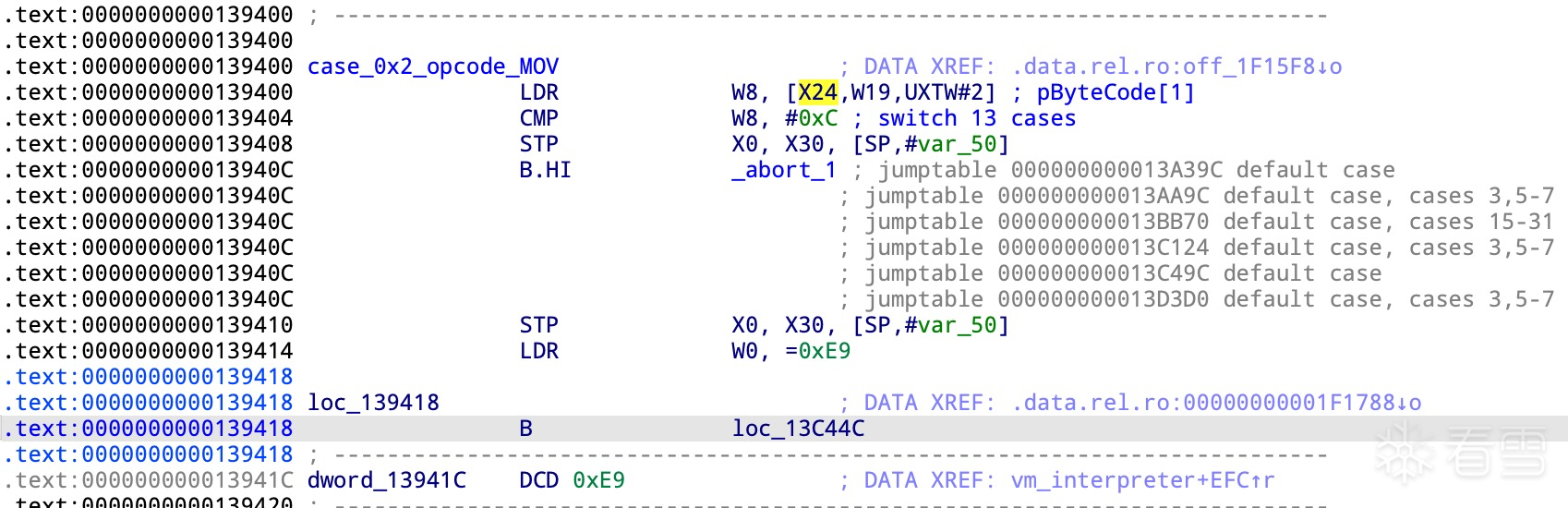
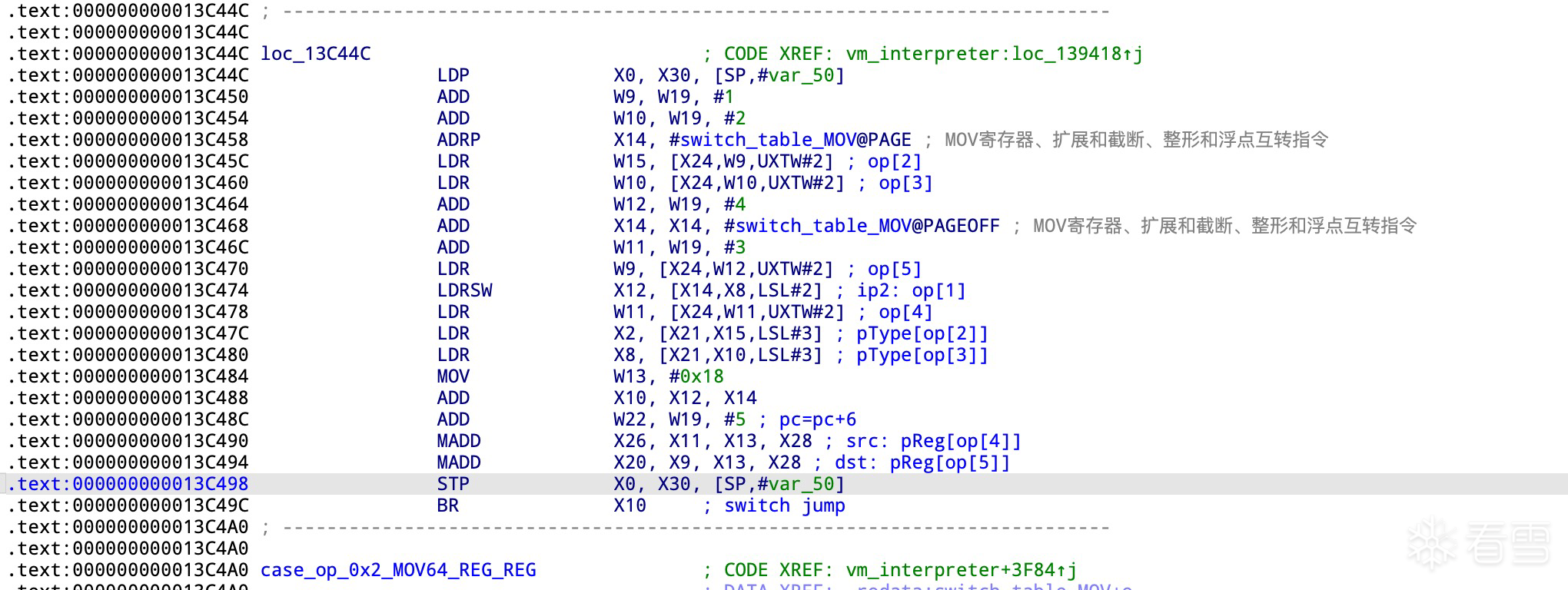
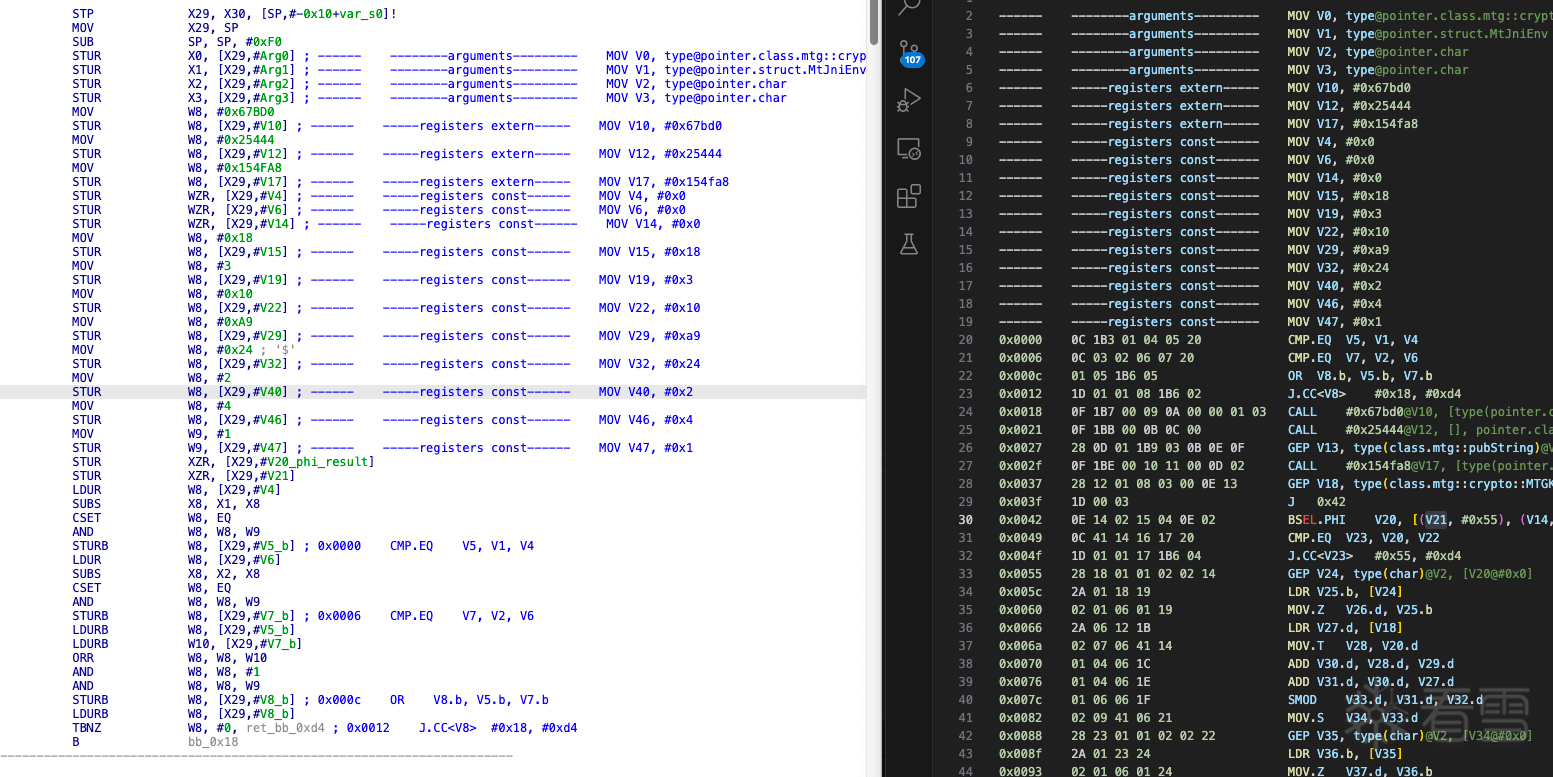
虚拟机 PC(当前指令偏移 op/pInsn): 当前指令 MOV 来源于 13 个 handler 中的一个,其尾部的主操作码分发器已修正 PC 指针。因此,原来的偏移 0 不再使用,PC 现在指向偏移 1的位置,且 W19 在主分发器中已更新为当前指令的正确偏移位置,之后只需关注 W19 即可。指令对象(pReg): 该对象由真实寄存器 x24 指向,作为当前指令的存储位置。
前驱节点: w25=0。
x24 寄存器指向 pInstructions 的起始位置,而 w19 寄存器则指向当前指令字节码中的偏移 1 位置。地址0x139400 : 将op2 第二个操作码提取到 w8 寄存器,并检查 op2 的合法性。
ADD W9, W19, #1
w19=当前指令偏移op
x24=指令对象:它是一个 16 位的数组,通过 w19 计算得到的偏移索引来访问。
当指令执行到0x13C49C 位置时开始分发op2,此时的数据状态如下:目标操作数类型: x2=pType[op[2]],从当前指令偏移2读取索引值,然后使用索引获取类型指针源操作数类型: x8=pType[op[3]],从当前指令偏移3读取索引值,使用索引获取类型指针源寄存器: x26=pReg[op[4]],从当前指令偏移4读取索引值,再从使用索引获取寄存器指针目标寄存器: x20=pReg[op[5]],从当前指令偏移5读取索引值,再从使用索引获取寄存器指针
0x13C48C ADD W22, W19, #5下一个pc: 此时,W19 指向当前指令的偏移 1 处。加上 5 后,W22 指向下一条指令的起始位置,即偏移 0。因此可以推断当前指令的长度为 6 个字节。
指令执行时,会将源寄存器中的值取出,并存入目标寄存器。
0x13C4BC: MOV handler 尾部附加的主操作码分发逻辑入口。
MOV handler主操作码分发器:
x24是指向指令对象的,使用索引w22(new pc)获取下一条指令的主操作码。
此时W19指向上一指令偏移1的位置并且上一条指令的长度是6个字节,在执行W19, W19, #6之后W19正好指向下一条指令偏移1的位置。注:加上长度是6个字节,是因为 此分析器是MOV专用的只有MOV指令执行完成后才可到达此位置。
CMP 指令格式(6): [opcode, type, sreg1, sreg2, creg, op2]
汇编语法:
CMP.EQ creg, sreg1, sreg2
分析开始前,先再次说明五个重要对象。接下来的 handler 分析将主要围绕它们的数据进行展开。
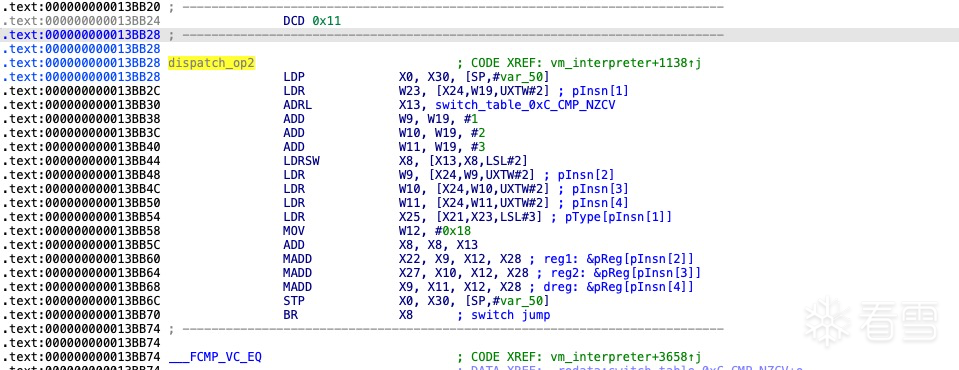
虚拟机pc: 当前的 CMP 指令来源于 13 个 handler 之一,其尾部的主操作码分发逻辑。此时,指令已经成功分发至当前指令位置,虚拟机 PC 的偏移 0 已不再使用。指令对象: 真实寄存器x24指向它。
W19 指向当前指令偏移 1 的位置,加上 4 后,W8 指向偏移 5。根据该类指令的格式,偏移 5 对应的是操作数 op2。ADD W8, W19, #4 LDR W8, [X24,W8,UXTW#2] MOV W26, W25 CMP W8, #0x28
接下来将分发第二个操作数,该操作数用于指定比较条件类型,例如 EQ、NE、GT、GE、LT、LE 等条件码。上下文对象: X28
类型表对象: X21
获取操作数类型type :LDR W23, [X24,W19,UXTW#2] LDR X25, [X21,X23,LSL#3] **ADD W9, W19, #1 MOV W12, #0x18 LDR W9, [X24,W9,UXTW#2] * MADD X22, X9, X12, X28* sreg2*指针ADD W10, W19, #2* LDR W10, [X24,W10,UXTW#2]* MADD X9, X11, X12, X28 creg 条件码寄存器指针ADD W11, W19, #3 LDR W11, [X24,W11,UXTW#2] MADD X9, X11, X12, X28
在指令执行到地址 0x13BB70 时,所有操作数已被提取,且类型对象和指令对象不再参与后续处理。接下来,只需关注 type、sreg1、sreg2 和 dreg 寄存器的内容。
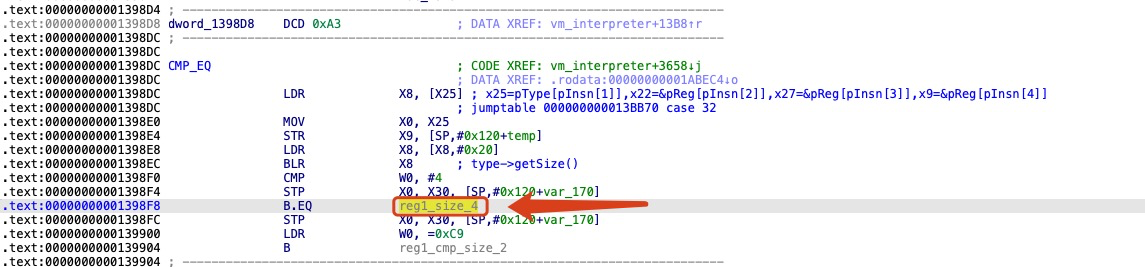
第二个操作数用于指定 CMP 条件码的类型,条件码支持包括浮点数在内的多种比较方式。本分析将以常用的 CMP.EQ 条件码为例进行探讨。
首先,根据指令要求确定比较操作数的大小。接着,从寄存器指针 sreg1 获取操作数的值,以操作数的大小为 4 字节为例。
取sreg1的值:
sreg1_val: X20
取sreg2操作数大小和寄存器的值:
比较sreg1和sreg2获取EQ条件码
更新下一条指令的 PC,并检查其是否超过 macPC。W19 指向当前指令的偏移 1 位置,执行 ADD W8, W19, #5 后,W8 指向下一条指令的偏移 0 位置,表明当前指令(CMP)的长度为 6 字节。
CMP 尾部主操作码分发器:
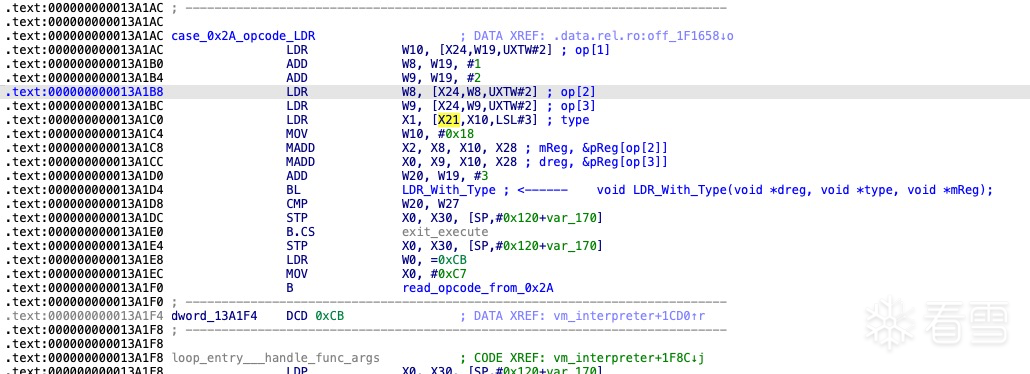
LDR 指令(4): [opcode, type, mreg, dreg]
汇编语法:
LDR dreg, [mreg]
关键对象:虚拟机pc、指令对象、上下文对象、类型表对象、分支表对象(遇到分支指令时关注)
获取操作数类型type:
0x13A1AC LDR W10, [X24,W19,UXTW#2]
获取目标操作数寄存器dreg:
0x13A1B0 ADD W8, W19, #1
LDR_With_Type函数分析 :
函数原型:void LDR_With_Type(void *dreg, void *type, void *mReg);
参数:x0=dreg, x1=type, x2=mreg
0x13FF60 BLR X8
类型长度不能大于8个字节:
0x13FF68 CMP W8, #7
获取mreg中的指针:
LDR X8, [X20]
根据类型的长度(1、2、4、8 字节),然后从指针中获取相应长度的值。
0x13FF88 LDRSB W8, [X8]
最后将值赋值给dreg:
0x13FF98 STR X8, [X19]
或
0x13FFB4 STR W8, [X19]
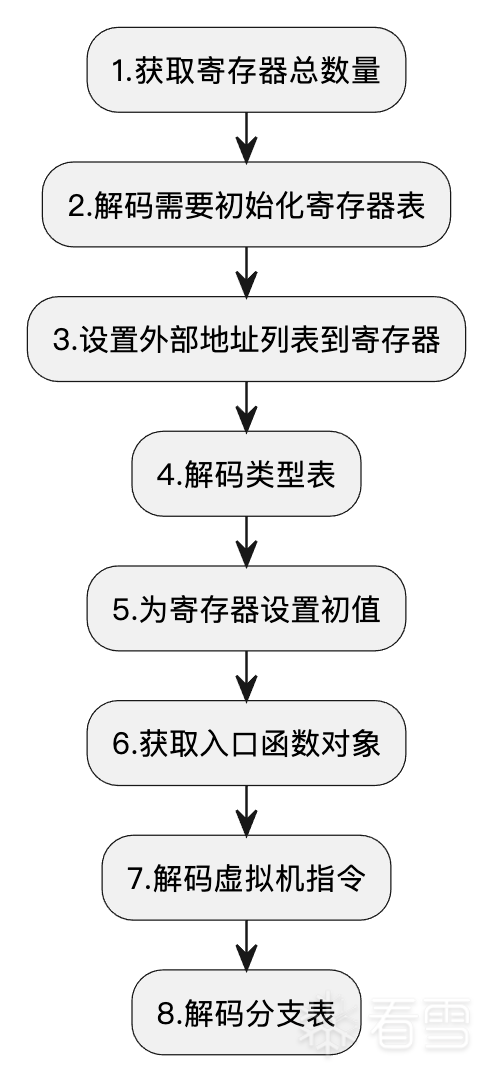
解码的目的就是将bytecode反序列到VMPState对象。
bytecode采用Variable Bitrate(VBR)编码格式,这种编码广泛应用于音频、视频等多个领域,有兴趣的也可以AI了解。5.1、Varints 编码(变⻓的类型才使⽤)
000101
在 6 位编码中,最高位为 1 表示后续还有更多字节的数据。
100101 001111
在解码组合位数据时,首先取出第 0 到第 4 位的有效数据(低 5 位):00101。第 5 位为 1,表示还有后续字节数据。接着,取下一个字节的 6 位数据(001111)。第 5 位为 0,表示没有后续字节数据。有效数据是低 5 位:01111。最终,解码后的组合数值为 0x1E5(即 0b111100101)。注意:后 6 位数据在组合时应放置在高位。
01111 00101 ---> 111100101
脚本实现decode:
在 IDA Pro 中,按 Ctrl + M 快捷键可以打开收藏的书签。如果快捷键不可用,也可以通过菜单 View -> Open subviews -> Bookmarks 来打开书签。此外,[step<n>] 用于表示字节码解码的流程,它可以帮助快速定位到相关的解码位置。
读取第一个字节码
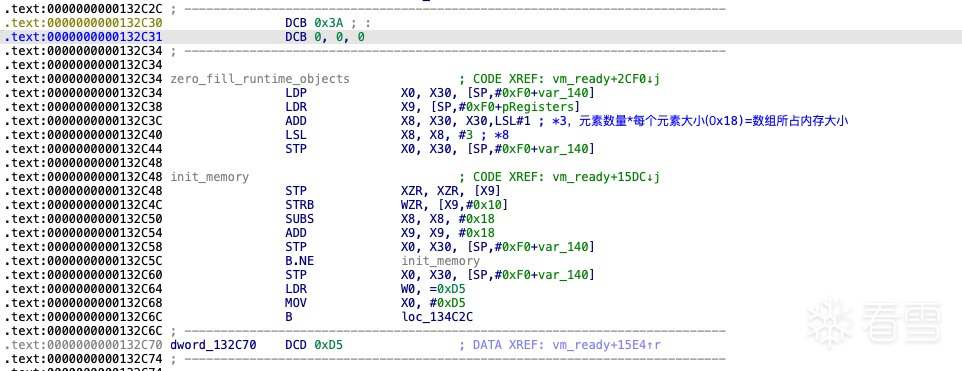
字节码解码按 64 位为单位处理,而 VBR 编码则以 6 字节为单位进行数据处理。如果当前 64 位字节码数据不足 6 字节,解码器将读取下一个 64 位数据,并从低位开始提取字节,直到补充足够的 6 字节数据为止。在解码的同时,堆栈中会维护当前 VBR 解码的状态信息,这些信息包括:指向字节码的指针 pBytecode,当前剩余的 64 位字节码数据 remain_bytecode,以及剩余位数 remain_bit。
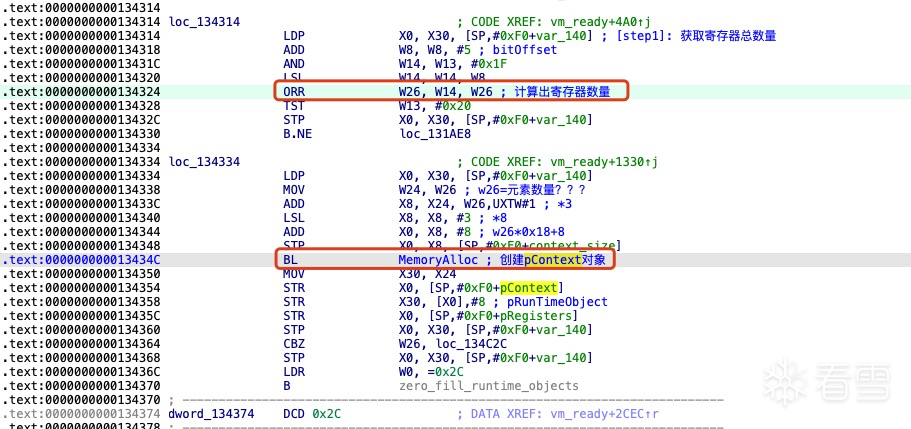
计算出寄存器数量
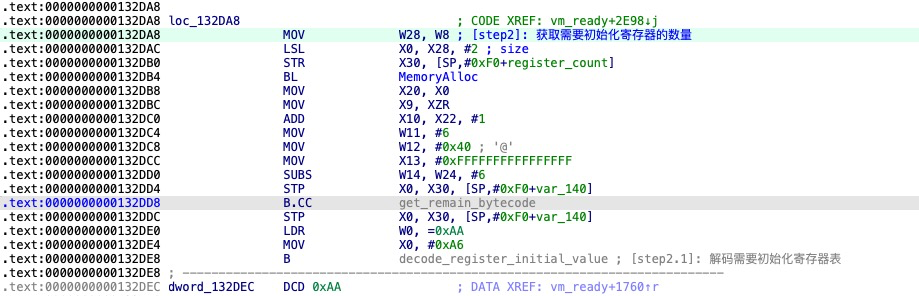
解码需要初始化寄存器
初始化寄存器的数量
解码需要初始化寄存器表
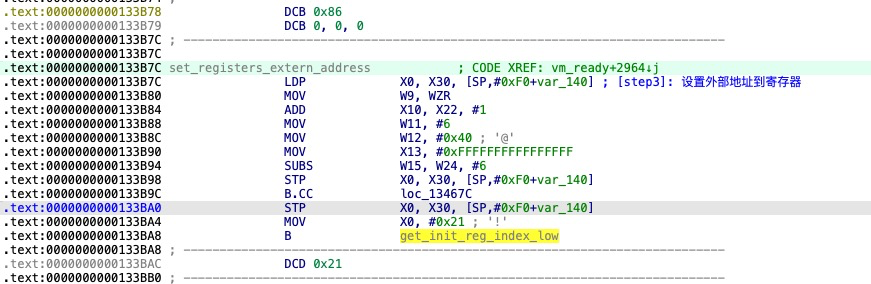
设置外部地址列表到寄存器
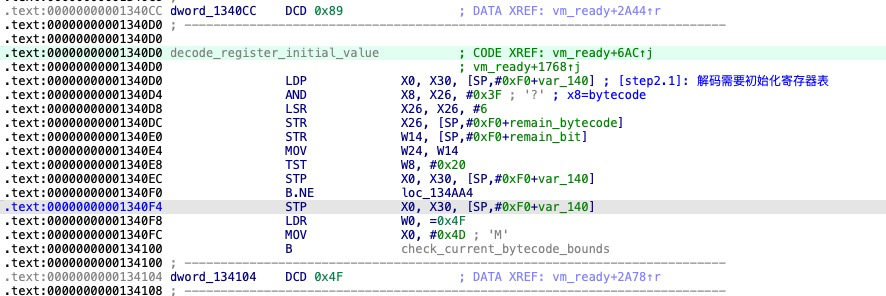
解码类型对象表
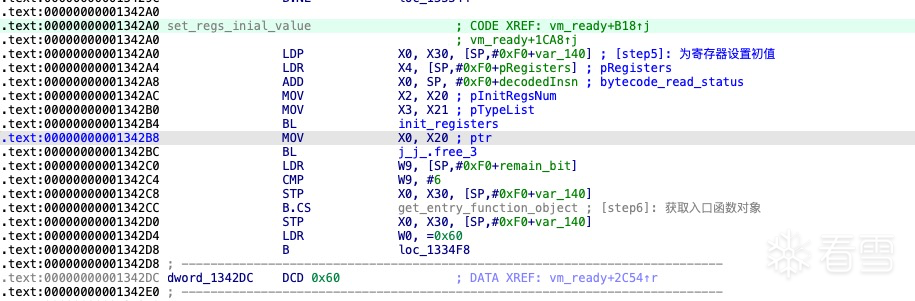
为寄存器设置初值
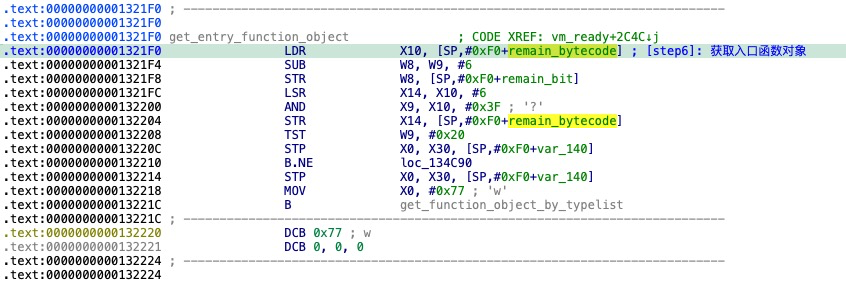
获取入口函数对象
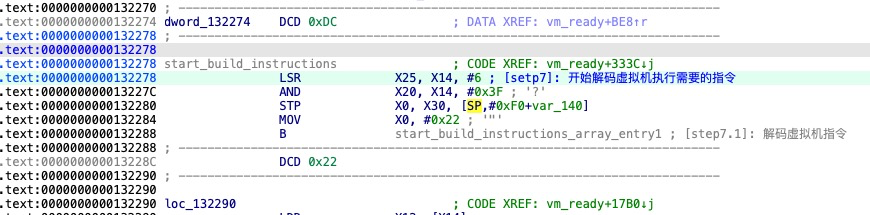
解码虚拟机指令
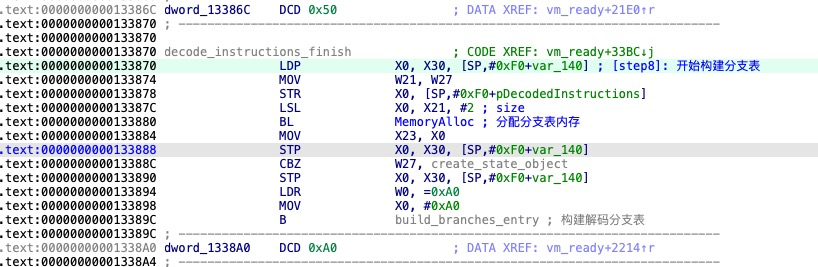
创建分支表
创建VMPState对象
在解码完字节码后,入口函数类型、虚拟寄存器数量、类型表数量、指令数量、上下文对象、类型表对象、指令表对象和分支表的关键数据都已获取,接下来创建 VMPState 对象。
在逆向分析和虚拟机执行时,这个数据结构非常重要。理解这些数据结构的分析,有助于避免在执行过程中迷失方向,特别是在解释执行时,常常需要访问指令、类型、寄存器和分支等数据结构。
类型对象用于描述类型数据,并不会包含类型的值。
类型签标
所有类型的基类内存长度: 0x10
空类型内存长度: 0x10
浮点类型内存长度: 0x10
整形内存长度: 0x10nbit成员用于描述1位/8位/16位/32位/64位。
函数类型内存长度: 0x28
结构体类型内存长度: 0x38
数组类型内存长度: 0x18
指针类型内存长度: 0x18
内存长度: 0x18
内存长度: 内存长度不确定,依据count的数值决定大小, size=count * sizeof(Register)
内存长度: 内存长度不确定,首次解码有长度数据,具体参考bytecode解码流程step8 。
内存长度: 内存长度不确定,VMPState->insCount描述了指令数量,具体参考bytecode解码流程step1 。
注:在第一次解码时,系统会构建 VMPState 核心数据结构,存储字节码的基本信息。第二次解码则发生在虚拟机执行过程中,主要用于指令解码和执行。
最外层的 [] 类似于 Python 的列表,内层的 [] 表示数据是可选的,而 () 通常表示成对的数据。
虚拟机还原分为两部分:还原到汇编时,通常理解其中的逻辑就足够了;而还原到原生代码则是将还原过程做到极致。直接还原汇编语言是最接近虚拟机指令的方式,它不仅最容易理解,而且最不容易出错,也是真正的虚拟机指令的映射。
解码后的字节码仍然是一堆数据,为了便于理解,字节码需要转化为汇编代码进行阅读。如果虚拟机指令与原生架构相似,则可以借用原生架构的汇编语言进行还原。对于拥有独立指令集的虚拟机,通常需要根据指令集的特点,定义一套与虚拟机语义相符的汇编语言。关键是将字节码转化为语义相近的汇编语言。这里的汇编语言参考了 MIPS、RISC-V、Smali、Binary Ninja 中间语言等语法。
操作数长度
操作数标识符说明
指令集
算术指令
MOV指令
MOV指令辅助操作
CALLOC指令
内存分配指令,向堆申请内存
内存访问指令
比较指令
FCMP指令用到的很少暂不列入
分支数据选择指令(PHI)
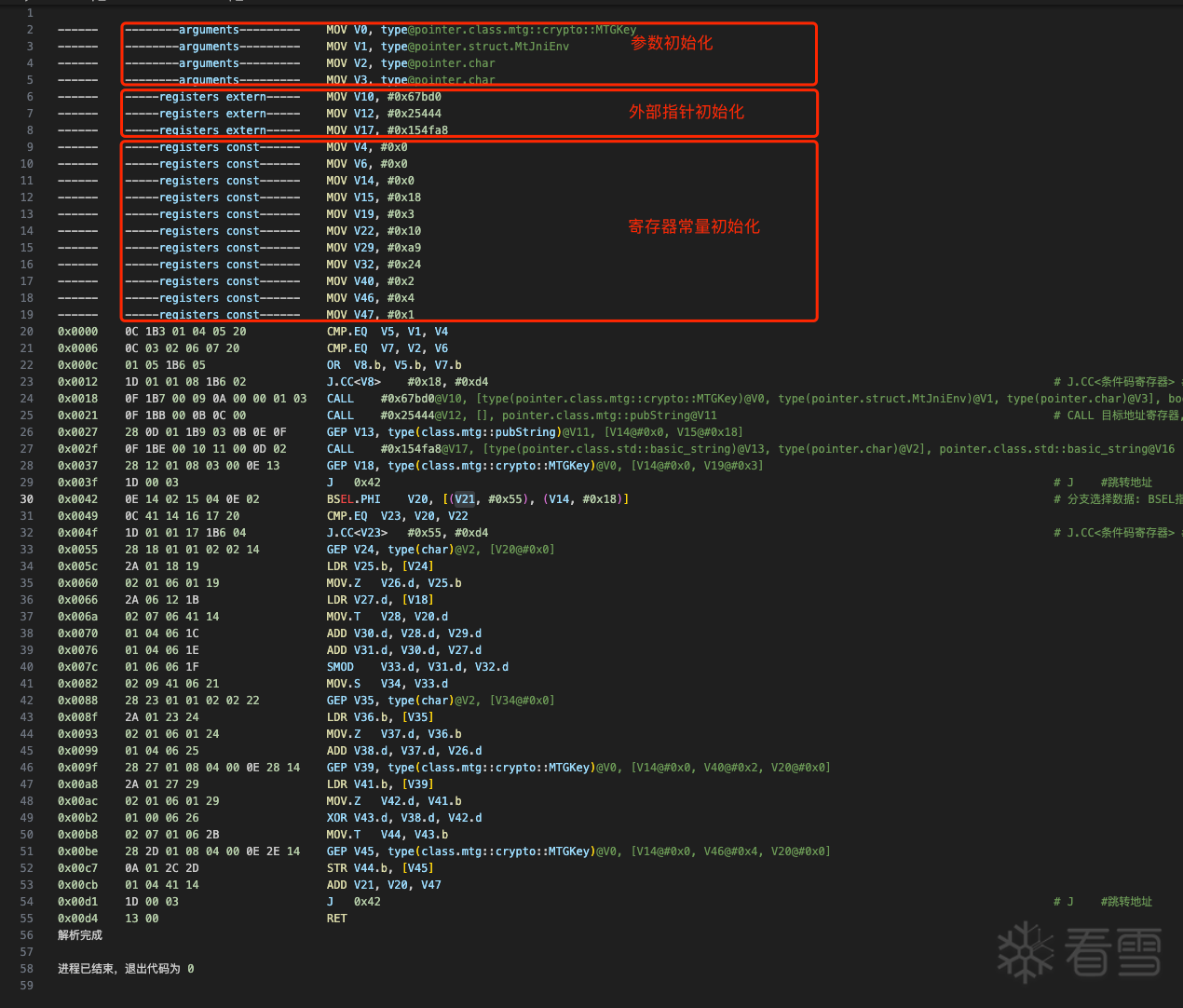
指令说明:BSEL.PHI 指令用于检查当前指令来自哪个前驱分支,通过 BranchIndex 来标识该分支。它会将匹配到的分支中的寄存器值赋给 dreg,通常这个寄存器值代表循环的起始位置(即循环的第一条指令),类似于 for 循环中的初始化语句和自增块(inc)部分。
详情参考llvm ir中的phi指令。
调用子程序指令
分支指令
基本块的终止符指令
条件选择指令
取元素指针指令
GEP是getelementptr指令的缩写,详细可以llvm ir中的getelementptr指令
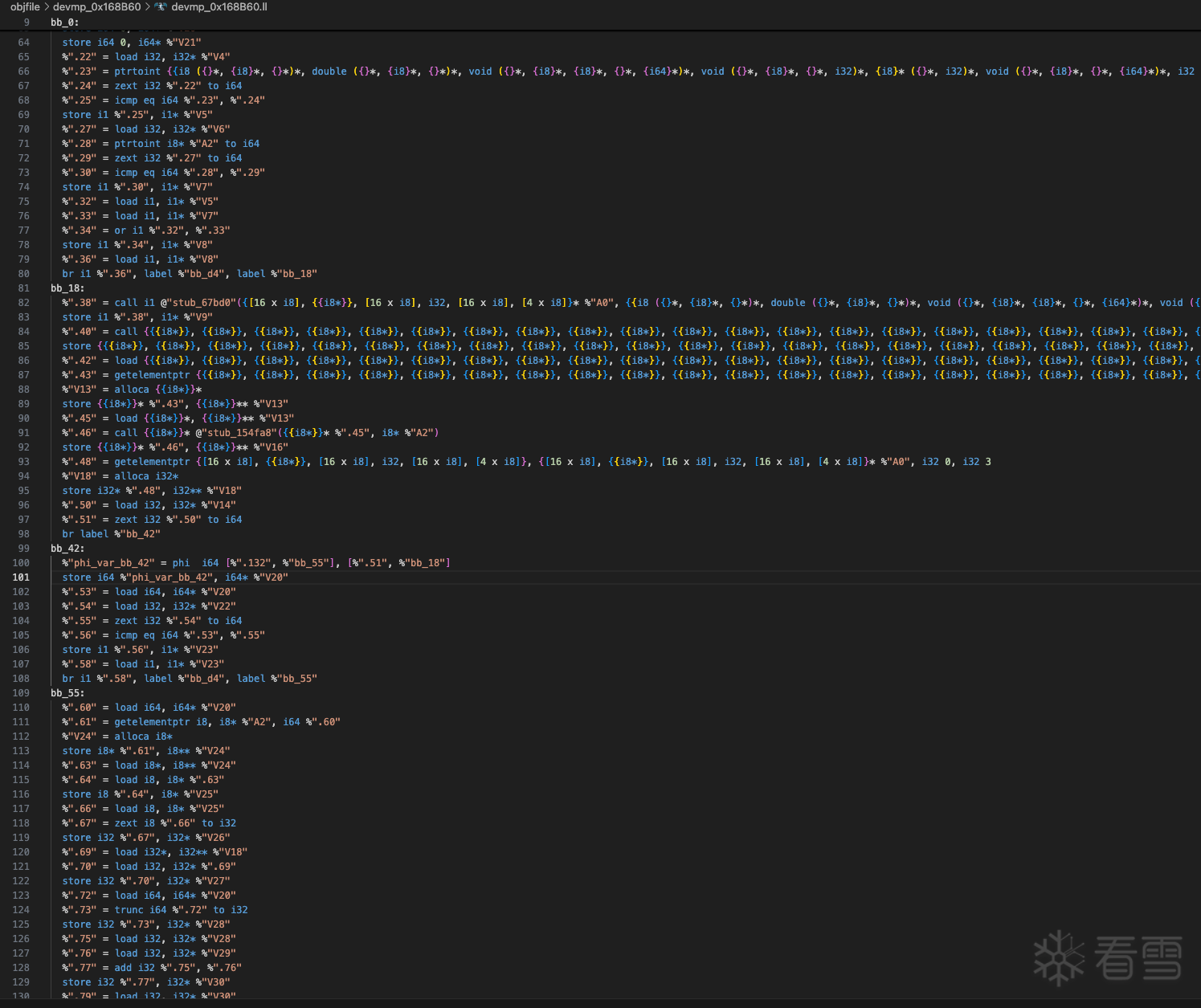
在前面的工作中,我们已经设计了自定义的汇编代码,并深入理解了 [指令解码格式]。现在,我们尝试解析指令数据并打印出相应的汇编指令。通过分析代码,可以看出该虚拟机与传统的原生汇编语言不同,它没有堆栈指针寄存器,这主要是因为它是基于寄存器的虚拟机,而非基于堆栈的架构。
目前尝试了两种方案来还原原生代码。第一种方案是将虚拟机指令转换为 LLVM IR,再使用 Clang 编译器编译 .ll 文件生成原生代码,目前来看,这是最有效的方案。第二种方案是构建反编译器的 IL 中间语言,并尝试将其还原为伪 C 代码。当前只进行了初步尝试,尚未完成,欢迎有兴趣的朋友继续尝试。
llvmlite 实现了 LLVM IR 大部分功能,对于我的需求来说,已经足够用来进行还原。如果不喜欢 llvmlite,也可以选择官方的 LLVM 或其他替代库。
安装:
开源仓库:llvmlite
文档:llvmlite文档
在初始化外部指针和寄存器常量赋值时,寄存器的类型信息丢失,这导致在后续构建 IR 时需要进行大量类型和数据长度转换。实际上,从反汇编的角度来看,只需识别 1/2/4/8 字节的数据和指针类型等,缺乏类型信息反而使编写过程更简单。
在还原后的汇编代码中,包含了大量寄存器,而不同的原生函数在虚拟化后使用的寄存器数量各不相同。这些寄存器实际上可以视为变量。在高级语言中,我们定义变量时无需考虑寄存器的分配问题,因为编译器会自动为我们分配寄存器。同样,在 IR 语言中,变量的寄存器分配也由编译器自动处理,因此我们不需要关心寄存器的分配细节。
定义变量 :
C/C++定义一个局部变量是这样的,指定一个类型和变量名并未赋初值。
C/C++声明变量:
IR声明变量:
在高级语言中,int num; 变量默认会在堆栈上分配;而在 IR 中,builder.alloca 也用于在堆栈上分配变量。与高级语言不同的是,IR 中的返回值是一个指针,例如 int* ptr_num。要使用该值,必须通过 builder.load 将指针解引用,这与高级语言中的 *ptr_num 操作类似。
加法运算 :
c/c++;
IR:
简单的3行高级语言代码在IR中有不少行的逻辑,有点麻烦笨拙的感觉
数值扩展 :
在IR中左值和右值类型或类型长度不至时是不能够直接参与运算的,需要进行转换后才能够使用。
c/c++:
IR:
定义函数:
要向函数添加指令,首先需要声明函数类型,并指定其参数和返回值类型,接着定义函数对象。函数对象包含基本块,而基本块包含指令。在向函数添加指令之前,必须至少有一个基本块。对于多个基本块,需使用“指令指针”定位到目标基本块,再向其添加指令。
IR指令指针移动到向基本块的未尾:
IR指令指针移动到向基本块的开始:
常用的IR指令 :
加减乘除:
带符号取模操作:
指针类型之间的转换:
整形转指针:
指针转整形:
比较:
无条件跳转:
有条件跳转:
返回指令:
我的还原方法不一定很好都多都是临时有想法加进去的,对IR非常熟悉的完全可以按照自己的想法去实现。
解码虚拟机指令字节数据
由于指令长度不固定,指令字节数据被存放在列表中,这便于在查找基本块时将指令添加到基本块中。
创建基本块
这里的基本块是还原后的虚拟机基本块,基本块的终止符指令有:ret、switch、j、jcc指令,从第一条指令开始扫描这些指令,并记录下这些指令的真假和多路跳转目标地址,这些跳转地址是基本块的起始地址,当遇到终止符指令结束基本块并把基本块的信息保存到基本块列表中。
初始化模块
声明外部函数声明
函数中会调用calloc来分配内存。从汇编代码的dump信息来看,calloc分配的内存大小通常都小于0x100。对于较小的数据,实际上可以将calloc分配的内存转移到堆栈中,这样可以提高性能并节省堆内存。不过,由于懒得在写完后再进行验证,我没有实现这一优化。
声明一个函数类型填好参数和返回值的类型,然后创建一个函数对象指令外部符号名称"calloc"。
定义一个入口函数
虚拟机所有的指令将会使用IR接口向函数写入指令。
为入口函数创建所有的基本块
调用 func.append_basic_block 为函数添加基本块,此时这些基本块尚未写入指令,内容为空。
在create_all_basic_blocks函数返回后,在调试控制台输入print(entry_func)回车后打印该函数已经写入的所有IR信息。
为模块创建一个IR构建器
当通过 func.append_basic_block() 为函数添加新基本块时,该基本块的 parent 成员会指向其所属的函数对象,而函数对象的 parent 成员会指向所属的模块对象。因此,若以基本块作为参数创建 IR 构建器,即可通过层级关系自动关联到模块,从而方便地为模块生成代码。
初始化外部指针
在上一章还原的汇编代码中,外部指针会被加载到虚拟寄存器中,因此需要为这些寄存器变量设置初始值。如之前所述,外部地址的引用和寄存器的初始化过程均无类型信息,此处暂将其初始值设为32位整型常量。
初始化寄存器
寄存器的初始化值是一个常量,该值在后续指令执行过程中始终保持不变。这些常量来源于原始汇编代码中的立即数,例如 MOV X3, #0x88 中的 #0x88。在虚拟化后的代码中,该操作可能变为 MOV V20, #0x88,其中 V20 是对应 X3 的虚拟寄存器。除 MOV 外,其他原生指令也可能用于寄存器的初始化。
预分配
获取虚拟机指令中的所有PHI指令和PHI参数信息
为所有基本块中的指令添加IR指令
指令插入必须通过IRBuilder定位到目标基本块的特定位置
在基本块遍历开始时,需要先为IRBuilder设置目标基本块
由于之前的寄存器初始化操作,基本块中已包含部分指令
此时应将IRBuilder的插入点定位到基本块的末尾
从基本块中取出指令开始遍历虚拟机指令生成IR代码,为了方面阅读下面只是框架的部分代码:
在写入完所有指令后开始处理PHI指令,PHI指令必须是基本块的第一条指令位置,因此将IR指令指针移动到基本块最前方的位置,然后再添加PHI组合参数(变量,基本块<label>),最后保存PHI结果变量。
最后打印IR保存 :
为避免编译器优化删除IR生成的原生代码,使用 -O0 禁用优化,并通过 -shared 将无 main 函数的代码编译为动态库。
反汇编校对逻辑
IDA PRO载入devmp_0x168B60_O0.o,查看还原的原生代码和虚拟机汇编逻辑是否一致。禁用优化的伪C代码 优化编译
对比优化前后( -O0 与 -O1)的汇编代码,发现启用优化后指令数量显著减少。
但它不乏也是一种还原思路,目前做了尝试使用Binary Ninja构建IL进行还原只做了少部分几条指令没有时间做下去了,从还原的几条指令效果来看,这个方法是行得通的,但没有还原到llvm IR效果那么好,llvm编译器优化做的非常到位,甚至有的时候能够将非常多的指令精简到难以想像的结果,精简后代码量少了非常方便于进行阅读分析指令。有兴趣的可以参考附加的文件DecodeBNIL.py
IR中有一个指令getelementprt和虚拟机中的一条指令逻辑非常像,之前这条指令名叫ADD.MO现在叫GEP,MO是member offset的简写,查找llvm相关代码发现虚拟机和llvm bitcode有非常大的关系,发现bitcode中的指令、字节码的解析 、解释器 等等两者的逻辑和虚拟机非常的相似,想必大家已经猜了它是由什么改造而来的吧,文章写到止已经非常庞大了不做过多介绍了,有兴趣的可以阅读llvm bitcode的相关代码。
关于判断虚拟机
关于分析时间
很多人都喜欢问这个分析了多久,的确这是一个非常重要的时间考量。对于简单的虚拟机分析在1-2周的工作日,国内大厂的一般在2-4周工作日左右,对于国际大厂他们做的非常好强度是非常高的则需要时间2-4个月,按这个时间成本来算的话已经达到了强不可催的目的了。
之前的短视频虚拟分析和还原脚本大约3.5周的工作日时间,合计18天左右,另外加上写文章1.5周的工作日,总耗时约5周的工作日,文中分析的so是一个未经混淆并且字节码未加密的虚拟机,实际上在其他位置so中的虚拟机是一套东西,只不过混淆有所加强字节码被加密了,分析难度虽说有加强但也不是非常大。
此app的虚拟机分析和汇编还原脚本合计总耗时大约4周的工作日,IR编写大约1.5周的工作日,总耗时接近6周。
关于还原的理论
import idautils
import idc
import idaapi
from keystone import *
def get_insn_const(addr):
op_val = None
if idc.print_insn_mnem(addr) in ['MOV', 'LDR']:
op_val = idc.get_operand_value(addr, 1)
if op_val > 0x1000:
op_val = idc.get_wide_dword(op_val)
else:
raise Exception(f"error ops const: {addr}")
return op_val
def get_patch_data(addr):
addr_list = []
for bl_insn_addr in idautils.XrefsTo(addr):
bl_insn_addr = bl_insn_addr.frm
for xref_addr_l2 in idautils.XrefsTo(bl_insn_addr):
index = get_insn_const(xref_addr_l2.frm - 4)
const_table_start = bl_insn_addr + 4
offset = idaapi.get_dword(const_table_start + index * 4)
link_target = const_table_start + offset
addr_list.append({"bl_insn_addr": bl_insn_addr, "patch_addr": xref_addr_l2.frm, "index": index,
"offset": offset, "link_target": link_target})
return addr_list
def print_patch_data(patch_data):
for item in patch_data:
print(
f"bl_insn_addr: {item["bl_insn_addr"]:#x}, patch_addr: {item["patch_addr"]:#x}, index: {item["index"]}, offset: {item["offset"]:#x}, link_target: {item["link_target"]:#x}")
def patch_insns(patch_data):
index = 0
for item in patch_data:
ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN)
asm = f'B {item["link_target"]:#x}'
print(f'patch addr {item["patch_addr"]:#x}: {asm}')
encoding, count = ks.asm(asm, as_bytes=True, addr=item["patch_addr"])
print(encoding)
for i in range(4):
idc.patch_byte(item["patch_addr"] + i, encoding[i])
index += 1
def start():
modify_x30_func_address = 0x25D00
patch_data = get_patch_data(modify_x30_func_address)
print_patch_data(patch_data)
patch_insns(patch_data)
start()
import idautils
import idc
import idaapi
from keystone import *
def get_insn_const(addr):
op_val = None
if idc.print_insn_mnem(addr) in ['MOV', 'LDR']:
op_val = idc.get_operand_value(addr, 1)
if op_val > 0x1000:
op_val = idc.get_wide_dword(op_val)
else:
raise Exception(f"error ops const: {addr}")
return op_val
def get_patch_data(addr):
addr_list = []
for bl_insn_addr in idautils.XrefsTo(addr):
bl_insn_addr = bl_insn_addr.frm
for xref_addr_l2 in idautils.XrefsTo(bl_insn_addr):
index = get_insn_const(xref_addr_l2.frm - 4)
const_table_start = bl_insn_addr + 4
offset = idaapi.get_dword(const_table_start + index * 4)
link_target = const_table_start + offset
addr_list.append({"bl_insn_addr": bl_insn_addr, "patch_addr": xref_addr_l2.frm, "index": index,
"offset": offset, "link_target": link_target})
return addr_list
def print_patch_data(patch_data):
for item in patch_data:
print(
f"bl_insn_addr: {item["bl_insn_addr"]:#x}, patch_addr: {item["patch_addr"]:#x}, index: {item["index"]}, offset: {item["offset"]:#x}, link_target: {item["link_target"]:#x}")
def patch_insns(patch_data):
index = 0
for item in patch_data:
ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN)
asm = f'B {item["link_target"]:#x}'
print(f'patch addr {item["patch_addr"]:#x}: {asm}')
encoding, count = ks.asm(asm, as_bytes=True, addr=item["patch_addr"])
print(encoding)
for i in range(4):
idc.patch_byte(item["patch_addr"] + i, encoding[i])
index += 1
def start():
modify_x30_func_address = 0x25D00
patch_data = get_patch_data(modify_x30_func_address)
print_patch_data(patch_data)
patch_insns(patch_data)
start()
class BytecodeDecoder():
def __init__(self, bytecode: bytes, extern_address: list, filename):
self.extern_address = extern_address
self.bytecode_bits = bitarray(endian='little')
self.bytecode_bits.frombytes(bytecode)
self.bytecode = bytecode
self.bit_index = 0
self.filename = filename
def decode(self, nBit=6):
num = 0
index = 0
bit_num = 0
exit = False
while index + nBit <= len(self.bytecode_bits):
chunk = self.bytecode_bits[self.bit_index:self.bit_index + nBit]
high_bit = chunk[-1]
low_bits = ba2int(chunk[:-1])
if high_bit == 1:
num = num | (low_bits << bit_num)
else:
num = num | (low_bits << bit_num)
exit = True
self.bit_index += nBit
if exit:
return num
bit_num += 5
raise Exception("bytecode decode error")
class BytecodeDecoder():
def __init__(self, bytecode: bytes, extern_address: list, filename):
self.extern_address = extern_address
self.bytecode_bits = bitarray(endian='little')
self.bytecode_bits.frombytes(bytecode)
self.bytecode = bytecode
self.bit_index = 0
self.filename = filename
def decode(self, nBit=6):
num = 0
index = 0
bit_num = 0
exit = False
while index + nBit <= len(self.bytecode_bits):
chunk = self.bytecode_bits[self.bit_index:self.bit_index + nBit]
high_bit = chunk[-1]
low_bits = ba2int(chunk[:-1])
if high_bit == 1:
num = num | (low_bits << bit_num)
else:
num = num | (low_bits << bit_num)
exit = True
self.bit_index += nBit
if exit:
return num
bit_num += 5
raise Exception("bytecode decode error")
def decode_register_count(self):
regs_count = self.decode()
return regs_count
def decode_register_count(self):
regs_count = self.decode()
return regs_count
def decode_register_initial_value(self):
regs_initial_count = self.decode()
regs_initial = []
for i in range(0, regs_initial_count):
reg_num = self.decode()
regs_initial.append(reg_num)
return regs_initial
def decode_register_initial_value(self):
regs_initial_count = self.decode()
regs_initial = []
for i in range(0, regs_initial_count):
reg_num = self.decode()
regs_initial.append(reg_num)
return regs_initial
def set_registers_extern_address(self,
registers: list[Register],
extern_address: list[int]):
extern: ExternInstructions = ExternInstructions()
addr_list_count = self.decode()
for i in range(0, addr_list_count):
reg_idx = self.decode()
addr_list_idx = self.decode()
addr = self.read_extern_address(extern_address, addr_list_idx)
registers[reg_idx].value = addr
extern.targetRegs.append(reg_idx)
extern.externalAddress.append(addr)
return extern
def set_registers_extern_address(self,
registers: list[Register],
extern_address: list[int]):
extern: ExternInstructions = ExternInstructions()
addr_list_count = self.decode()
for i in range(0, addr_list_count):
reg_idx = self.decode()
addr_list_idx = self.decode()
addr = self.read_extern_address(extern_address, addr_list_idx)
registers[reg_idx].value = addr
extern.targetRegs.append(reg_idx)
extern.externalAddress.append(addr)
return extern
def decode_types(self):
types_count = self.decode()
types = [None] * types_count
for i in range(0, types_count):
type = self.decode()
match(type):
case 0x3 | 0x10 | 0x12:
raise Exception("error")
case 0x5 | 0xc | 0x13:
struct_0xC = 0
struct_0xD = self.decode()
struct_0xE = 1
member_count = self.decode()
members = []
for j in range(0, member_count):
member_type_index = self.decode()
t_membetr = types[member_type_index]
if t_membetr is None:
types[member_type_index] = t_membetr = StructType(0, [], "")
members.append(t_membetr)
type_name = []
type_name_size = self.decode()
for j in range(0, type_name_size):
c = self.decode()
type_name.append(c)
name = "".join(chr(c) for c in type_name)
struct_type = StructType(member_count, members, name)
struct_type.init()
types[i] = struct_type
case 0x1:
types[i] = VMPType()
case 0x6:
nbit = self.decode()
types[i] = IntegerType(nbit)
case 0x9:
element_count = self.decode()
element_type_idx = self.decode()
element_type = types[element_type_idx]
if element_type is None:
raise Exception("error")
types[i] = ArrayType(element_count, element_type)
case 0x7:
ptr_type_index = self.decode()
ptr_type = types[ptr_type_index]
if ptr_type is None:
ptr_type = StructType(0, [], "")
types[ptr_type_index] = ptr_type
types[i] = PointerType(ptr_type)
case 0xb:
types[i] = FloatType()
case 0x14:
flag = self.decode()
return_value_type = self.decode()
argument_count = self.decode()
return_value = types[return_value_type]
arguments = []
if return_value is None:
return_value = None
raise Exception("返回值类型 error")
for j in range(0, argument_count):
arg_type_idx = self.decode()
arg_type = types[arg_type_idx]
if arg_type is not None:
arguments.append(arg_type)
else:
raise Exception("error")
types[i] = FunctionType(
return_value, argument_count, arguments, flag)
case 0x15:
types[i] = DoubleType()
case _:
input(f"未知的类型:{type:#x}\n")
return types
def decode_types(self):
types_count = self.decode()
types = [None] * types_count
for i in range(0, types_count):
type = self.decode()
match(type):
case 0x3 | 0x10 | 0x12:
raise Exception("error")
case 0x5 | 0xc | 0x13:
struct_0xC = 0
struct_0xD = self.decode()
struct_0xE = 1
member_count = self.decode()
members = []
for j in range(0, member_count):
member_type_index = self.decode()
t_membetr = types[member_type_index]
if t_membetr is None:
types[member_type_index] = t_membetr = StructType(0, [], "")
members.append(t_membetr)
type_name = []
type_name_size = self.decode()
for j in range(0, type_name_size):
c = self.decode()
type_name.append(c)
name = "".join(chr(c) for c in type_name)
struct_type = StructType(member_count, members, name)
struct_type.init()
types[i] = struct_type
case 0x1:
types[i] = VMPType()
case 0x6:
nbit = self.decode()
types[i] = IntegerType(nbit)
case 0x9:
element_count = self.decode()
element_type_idx = self.decode()
element_type = types[element_type_idx]
if element_type is None:
raise Exception("error")
types[i] = ArrayType(element_count, element_type)
case 0x7:
ptr_type_index = self.decode()
ptr_type = types[ptr_type_index]
if ptr_type is None:
ptr_type = StructType(0, [], "")
types[ptr_type_index] = ptr_type
types[i] = PointerType(ptr_type)
case 0xb:
types[i] = FloatType()
case 0x14:
flag = self.decode()
return_value_type = self.decode()
argument_count = self.decode()
return_value = types[return_value_type]
arguments = []
if return_value is None:
return_value = None
raise Exception("返回值类型 error")
for j in range(0, argument_count):
arg_type_idx = self.decode()
arg_type = types[arg_type_idx]
if arg_type is not None:
arguments.append(arg_type)
else:
raise Exception("error")
types[i] = FunctionType(
return_value, argument_count, arguments, flag)
case 0x15:
types[i] = DoubleType()
case _:
input(f"未知的类型:{type:#x}\n")
return types
def set_registers_inial_value(self, registers: list[Register], types: list[int],
regs_initial: list[int]):
init_instructions: InialInstructions = InialInstructions()
count = self.decode()
for i in range(0, count):
init_type = self.decode()
reg_idx = regs_initial[i]
init_instructions.opcodes.append(init_type)
init_instructions.dRegs.append(reg_idx)
match(init_type):
case 0 | 0xb | 0x17:
type_idx = self.decode()
deep = self.decode()
breg = self.decode()
member_offset_table = []
for j in range(1, deep):
member_offset_table.append(self.decode())
init_instructions.imm.append(member_offset_table)
init_instructions.type.append(type_idx)
init_instructions.sRegs.append(breg)
case 7:
imm = self.decode()
registers[reg_idx].value = imm
init_instructions.imm.append(imm)
init_instructions.type.append(None)
init_instructions.sRegs.append(None)
case 8:
type_index = self.decode()
t = types[type_index]
if t.tag != 0xe:
registers[reg_idx].value = 0
else:
raise Exception("error")
init_instructions.type.append(type_index)
init_instructions.imm.append(None)
init_instructions.sRegs.append(None)
case 0x15:
while self.decode() & 0x20:
pass
type_idx = self.decode()
t = types[type_idx]
sreg = self.decode()
registers[reg_idx].value = registers[sreg].value
registers[reg_idx].type = t
init_instructions.type.append(type_idx)
init_instructions.imm.append(None)
init_instructions.sRegs.append(sreg)
case _:
input(f"未知的初始化寄存器类型:{init_type:#x}\n")
return init_instructions
def set_registers_inial_value(self, registers: list[Register], types: list[int],
regs_initial: list[int]):
init_instructions: InialInstructions = InialInstructions()
count = self.decode()
for i in range(0, count):
init_type = self.decode()
reg_idx = regs_initial[i]
init_instructions.opcodes.append(init_type)
init_instructions.dRegs.append(reg_idx)
match(init_type):
case 0 | 0xb | 0x17:
type_idx = self.decode()
deep = self.decode()
breg = self.decode()
member_offset_table = []
for j in range(1, deep):
member_offset_table.append(self.decode())
init_instructions.imm.append(member_offset_table)
init_instructions.type.append(type_idx)
init_instructions.sRegs.append(breg)
case 7:
imm = self.decode()
registers[reg_idx].value = imm
init_instructions.imm.append(imm)
init_instructions.type.append(None)
init_instructions.sRegs.append(None)
case 8:
type_index = self.decode()
t = types[type_index]
if t.tag != 0xe:
registers[reg_idx].value = 0
else:
raise Exception("error")
init_instructions.type.append(type_index)
init_instructions.imm.append(None)
init_instructions.sRegs.append(None)
case 0x15:
while self.decode() & 0x20:
pass
type_idx = self.decode()
t = types[type_idx]
sreg = self.decode()
registers[reg_idx].value = registers[sreg].value
registers[reg_idx].type = t
init_instructions.type.append(type_idx)
init_instructions.imm.append(None)
init_instructions.sRegs.append(sreg)
case _:
input(f"未知的初始化寄存器类型:{init_type:#x}\n")
return init_instructions
def get_function_type(self, types: list[int]):
func_type_idx = self.decode()
return types[func_type_idx].type
def get_function_type(self, types: list[int]):
func_type_idx = self.decode()
return types[func_type_idx].type
def decode_bytecode(self):
vm_insn_count = self.decode()
vm_instructions = []
for i in range(0, vm_insn_count):
insn = self.decode()
vm_instructions.append(insn)
return vm_instructions
def decode_bytecode(self):
vm_insn_count = self.decode()
vm_instructions = []
for i in range(0, vm_insn_count):
insn = self.decode()
vm_instructions.append(insn)
return vm_instructions
def decode_branches(self):
branches_count = self.decode()
branches = []
for i in range(0, branches_count):
offset = self.decode()
branches.append(offset)
return branches
def decode_branches(self):
branches_count = self.decode()
branches = []
for i in range(0, branches_count):
offset = self.decode()
branches.append(offset)
return branches
struct VMPState {
0x0: Type* entryFunction;
0x8: int regCount;
0xC: int typeCount;
0x10: int insCount;
0x18 Context* context;
0x20: Type** pTypeList;
0x28: int16_t** pInstructions;
0x30: Branches* pBranches;
}
struct VMPState {
0x0: Type* entryFunction;
0x8: int regCount;
0xC: int typeCount;
0x10: int insCount;
0x18 Context* context;
0x20: Type** pTypeList;
0x28: int16_t** pInstructions;
0x30: Branches* pBranches;
}
enum TypeTag {
VoidType = 0,
FloatType = 2,
DoubleType = 3,
InteterType = 0xb,
FunctionType = 0xc,
StructType = 0xd,
ArrayType = 0xe,
PointerType = 0xf,
VertorType = 0x10
}
enum TypeTag {
VoidType = 0,
FloatType = 2,
DoubleType = 3,
InteterType = 0xb,
FunctionType = 0xc,
StructType = 0xd,
ArrayType = 0xe,
PointerType = 0xf,
VertorType = 0x10
}
struct Type {
+0x0: void* vtable;
+0x8: TypeTag tag;
+0xc: union {
int nbit;
bool field1;
}
+0xd: bool isInit;
+0xe: bool field3;
}
struct Type {
+0x0: void* vtable;
+0x8: TypeTag tag;
+0xc: union {
int nbit;
bool field1;
}
+0xd: bool isInit;
+0xe: bool field3;
}
struct VoidType : public Type {
}
struct VoidType : public Type {
}
struct FloatType : public Type {
}
struct FloatType : public Type {
}
struct DoubleType : public Type {
}
struct DoubleType : public Type {
}
struct IntegerType : public Type {
}
struct IntegerType : public Type {
}
struct FunctionType : public Type {
+0x10: Type* returnValueType;
+0x18: int. argumentCount;
+0x20: type** arguments;
}
struct FunctionType : public Type {
+0x10: Type* returnValueType;
+0x18: int. argumentCount;
+0x20: type** arguments;
}
struct StructType : public Type {
0x10: int32 memberCount;
0x18: type** members;
0x20: int32 memorySize;
0x28: int32* memberOffsetTable;
0x30: char* typeName;
}
struct StructType : public Type {
0x10: int32 memberCount;
0x18: type** members;
0x20: int32 memorySize;
0x28: int32* memberOffsetTable;
0x30: char* typeName;
}
struct ArrayType{
0xc: int32 count;
0x10: Type* element;
}
struct ArrayType{
0xc: int32 count;
0x10: Type* element;
}
struct PointerType{
0x10: Type* pointee;
}
struct PointerType{
0x10: Type* pointee;
}
struct Register {
0x0: int64 value;
0x8: Type* t;
0x10: bool isBuffer;
}
struct Register {
0x0: int64 value;
0x8: Type* t;
0x10: bool isBuffer;
}
struct Context {
0x0: int count;
0x8: Register regs[];
}
struct Context {
0x0: int count;
0x8: Register regs[];
}
struct Branchs {
0x0: int16_t br[];
}
struct Branchs {
0x0: int16_t br[];
}
struct Instructions {
0x0: int16_t ins[];
}
struct Instructions {
0x0: int16_t ins[];
}
指令名称
opcode
长度
格式
说明
ARITH
0x1
6
[opcode, op2, type, sreg1, sreg2, dreg]
MOV
0x2
6
[opcode, op2, dtype, stype, sreg, dreg]
CALLOC
0x6
5
[opcode, a2_type, a1_type, a1_sreg, dreg]
STR
0xa
4
[opcode, stype, sreg, mreg]
CMP
0xc
6
[opcode, type, sreg1, sreg2, creg, op2]
PHI
0xe
变长(3+)
[opcode, dreg, count, [(reg, branch), (reg, branch), (...)]]
CALL
0xf
变长(5+)
[opcode, ftype, [count], tag, [retreg], ereg, none, [areg, ...]]
RET
0x13
变长(2+)
[opcode, type, [retreg]]
SWITCH
0x16
变长(5+)
[opcode, treg, type, defbranch, count, [(casereg, branch), ...]]
J/JCC
0x1d
3或6
[opcode, brtype, tbranch,[creg, ctype, fbranch]]
CSEL
0x1e
7
[opcode, ntype, creg, type, treg, freg, dreg]
GEP
0x28
变长(5+)
[opcode, dreg, none, type, count, breg, [index, ...]]
LDR
0x2a
4
[opcode, type, mreg, dreg]
寄存器
1位
8位
16位
32位
64位
通用寄存器
V0.b
V1.b
V2.h
V3.d
V4
浮点寄存器
H0(半精度)
S0(单精度)
D0(双精度)
标识
说明
备注
op
主要操作码
op2
第二个操作码
dreg
目标寄存器
sreg
源寄存器
只有一个源寄存器时的命名
sreg1
第一个源寄存器
sreg2
第二个源寄存器
type
操作数的类型
表示操作数的长度和数据类型
stype
源操作数类型
dtype
目标操作类型
a1_type
第一个参数类型
只适用于ALLOC指令
a2_type
第二个参数类型
只适用于ALLOC指令
a1_sreg
第一个参数的寄存器
只适用于ALLOC指令
mreg
内存操作数的寄存器
内存访问指令STR/LDR
creg
条件码寄存器
CMP指令
count
元素数量
PHI指令[val, lab]的数量、GEP表示[index]的数量、SWITCH表示case的元素数量
branch
分支
表未基本块的起始标签
ftype
函数类型
只适用于CALL指令, 类型中描述了函数的返回值、参数数量、参数类型
retreg
返回值寄存器
只适用于CALL指令, 保存函数的返回值的寄存器
ereg
调用目标寄存器
只适用于CALL指令, 保存了需要调用的目标地址。例如call 0x1234、call reg
areg
参数寄存器
只适用于CALL指令
treg
用于比较的目标寄存器
只适用于SWITCH指令
defbranch
默认分支基本块标签
只适用于SWITCH指令
casereg
SWITCH的case常量
只适用于SWITCH指令,casereg寄存器保存了case立即数
branch
SWITCH的代码基本块标签
只适用于SWITCH指令
brtype
表示分支指令的类型
值0时无跳转指令,值1时有条件跳转
tbranch
真值分支
只用于J/JCC指令
fbranch
假值分支
只用JCC指令
treg
真值寄存器
freg
假值寄存器
只用于CSEL指令
breg
基址寄存器
只用于GEP指令
index
元素索引寄存器
只用于GEP指令,index保存了访问元素成员的值
助记符
语法
操作数格式
说明
XOR
XOR V0, V1, V2
MOV dreg, sreg1, sreg2
SUB
SUB V0.b, V1.b, V2.b
MOV dreg, sreg1, sreg2
UDIV
UDIV V0.h, V1.h, V2.h
UDIV dreg, sreg1, sreg2
ADD
ADD V0.d, V1.d, V2.d
ADD dreg, sreg1, sreg2
OR
OR V0, V1, V2
OR dreg, sreg1, sreg2
SMOD
SMOD V0.b, V1.b, V2.b
SMOD dreg, sreg1, sreg2
SDIV
SDIV V0.h, V1.h, V2.h
SDIV dreg, sreg1, sreg2
UMOD
UMOD V0.d, V1.d, V2.d
UMOD dreg, sreg1, sreg2
ASR
ASR V0, V1, V2
ASR dreg, sreg1, sreg2
LSL
LSL V0.b, V1.b, V2.b
LSL dreg, sreg1, sreg2
助记符
语法
操作数格式
说明
MOV
MOV V0, V1
MOV dreg, sreg
数据移动
MOV.T
MOV.T V0, V1.b
MOV.T dreg, sreg
将V1操作截断为8位移动到V0
MOV.Z
MOV.Z V0, V1.d
MOV.Z dreg, sreg
将32位操作数V1.d零扩展到64位操作数V0
MOV.S
MOV.S V0, V1.d
MOV.S dreg, sreg
将32位操作数V1.d带符号扩展到64位操作数V0
操作符
描述
T
数据截断
Z
零拓展
S
符号拓展
助记符
语法格式
操作数格式
说明
CALLOC
CALLOC (0x1, 0x20), V21
CALLOC (num, size), RetVal
功能与libc中的calloc一致
助记符
语法格式
操作数格式
说明
STR
STR V0.b, [V3]
STR dreg, [mreg]
与arm指令相同
LDR
LDR V5, [V80]
LDR dreg, [mreg]
与arm指令相同
助记符
语法格式
操作数格式
说明
CMP.EQ
CMP.EQ V3.b, V0, V3
CMP.EQ creg, sreg1, sreg2
比较并将结果EQ条件码存入creg
CMP.NE
CMP.NE V3.b, V0, V3
CMP.NE creg, sreg1, sreg2
比较并将结果NE条件码存入creg
CMP.CC
CMP.CC V3.b, V0, V3
CMP.CC creg, sreg1, sreg2
比较并将结果CC条件码存入creg
CMP.LT
CMP.LT V3.b, V0, V3
CMP.LT creg, sreg1, sreg2
比较并将结果LT条件码存入creg
助记符
语法格式
操作数格式
说明
BSEL.PHI
BSEL.PHI V8, [(V0, #0x3), ...]
BSEL.PHI dreg, [(reg, branch), ...]
()是成对出现的,一般二对数据|
助记符
语法格式
操作数格式
说明
CALL
CALL V3, [V0, V8, V21,...], V33
CALL dreg, [areg, areg,...], retreg
调用子程序,参数和返回值是可选的
助记符
语法格式
操作数格式
说明
RET
RET V8
RET [retreg]
返回子程序, 返回值寄存器retreg是可选的
SWITCH
SWITCH V3, #0x1234, [(V2, #0x5678)]
SWITCH treg, #defbranch, [(reg, #branch), ...]
可以理解为c语言中的switch语句
J
J 0x1234
J address
无条件跳转指令
JCC
JCC<V8.b> 0x1234, 0x5678
JCC<creg> tbranch, fbranch
有条件跳转,当条件码等于1时为真
助记符
语法格式
操作数格式
说明
CSEL
CSEL<V3.b> V6, V7, V9
CSEL
arm64中的CSEL指令类似
助记符
语法格式
操作数格式
说明
GEP
GEP V2, V3, [V8, V9, V20]
GEP dreg, breg,[index, ...]
pip install llvmlite
int num;
t_int32 = ir.IntType(32)
ptr_num = builder.alloca(t, name="num")
t_int32 = ir.IntType(32)
ptr_num = builder.alloca(t, name="num")
int a = 111;
int b = 222;
int c = a + b;
int a = 111;
int b = 222;
int c = a + b;
t = ir.IntType(32)
ptr_a = builder.alloca(t, name="a")
builder.store(ir.Constant(ir.IntType(32), 111), ptr_a)
ptr_b = builder.alloca(t, name="b")
builder.store(ir.Constant(ir.IntType(32), 111), ptr_b)
a_value = builder.load(ptr_a)
b_value = builder.load(ptr_b)
result = builder.add(a_value, b_value)
ptr_c = builder.alloca(t, name="c")
builder.store(result, ptr_c)
t = ir.IntType(32)
ptr_a = builder.alloca(t, name="a")
[培训]Windows内核深度攻防:从Hook技术到Rootkit实战!
最后于 2025-4-22 14:03
被金罡编辑
,原因: