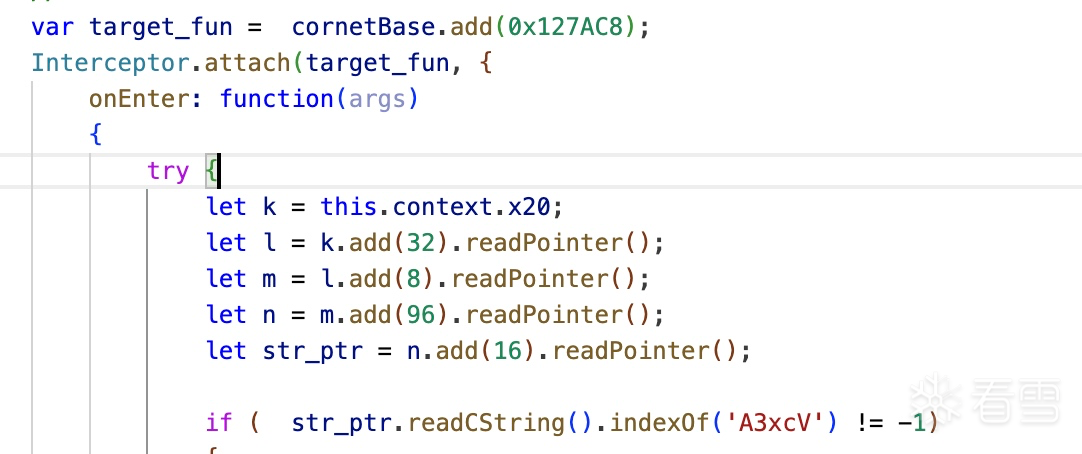
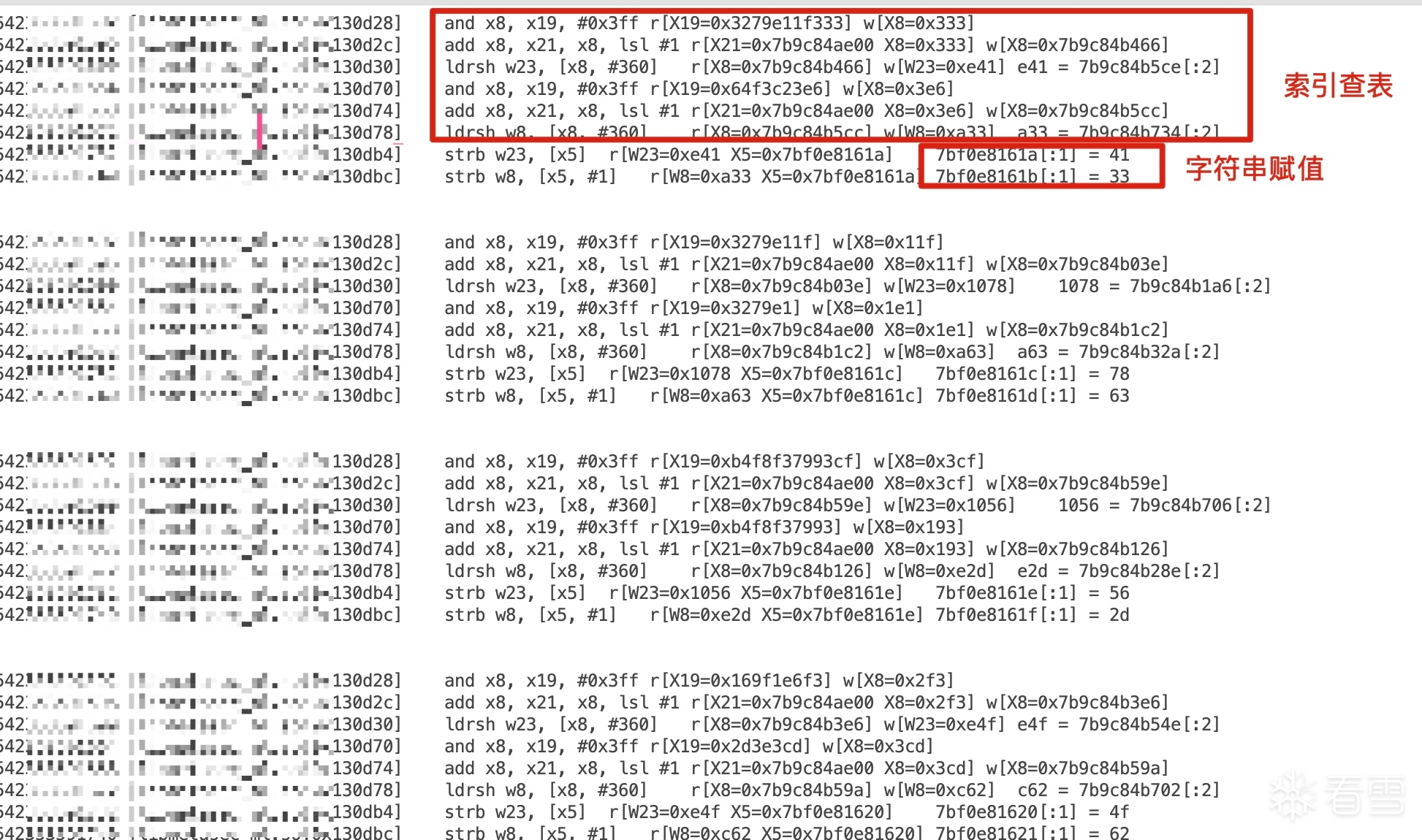
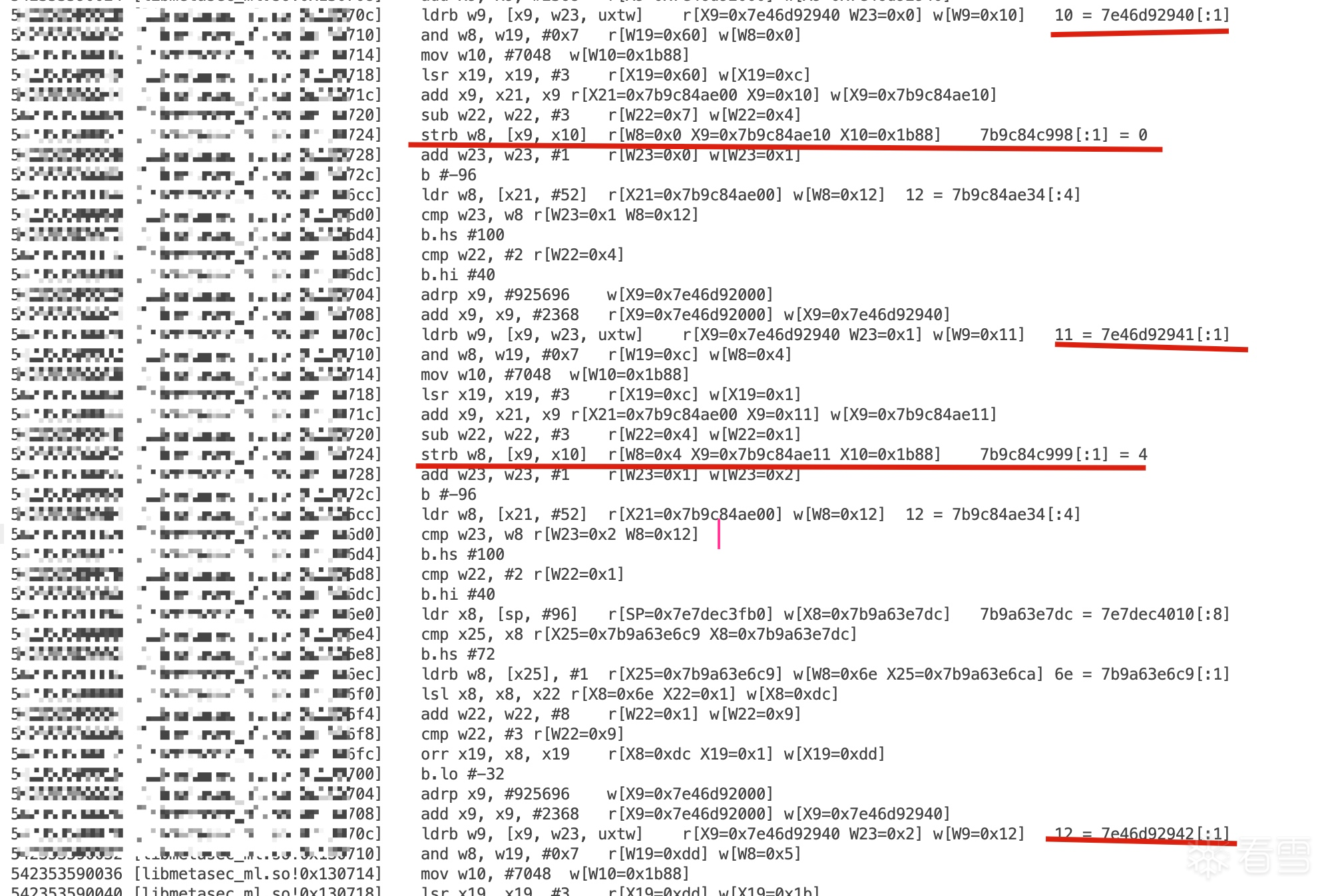
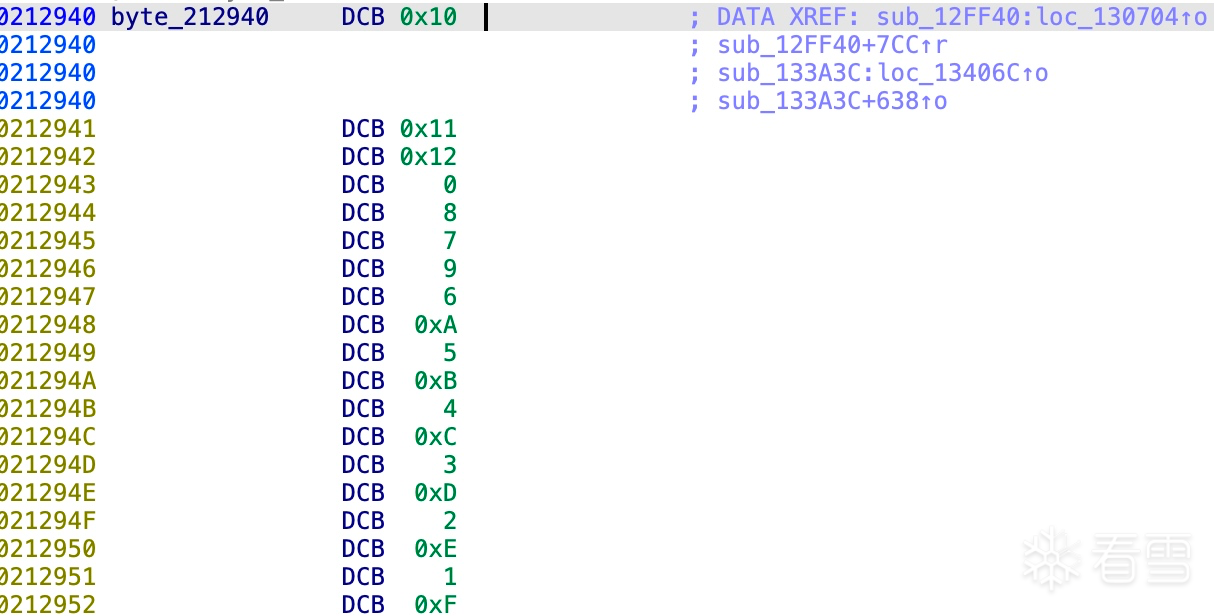
能力值:
 ( LV2,RANK:10 )
( LV2,RANK:10 )
|
-
-
2 楼
+1
|

能力值:
( LV2,RANK:10 )
|
-
-
3 楼
+3
|
能力值:
( LV1,RANK:0 )
|
-
-
4 楼
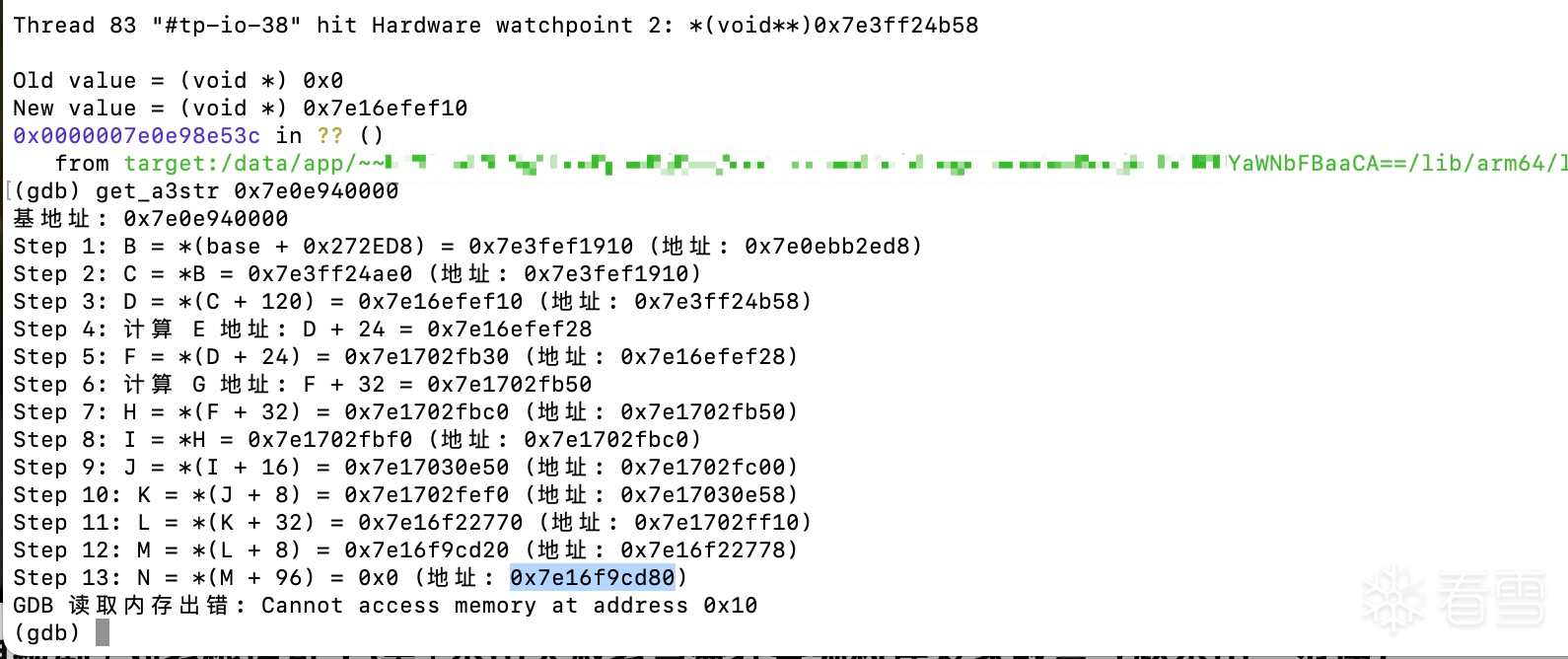
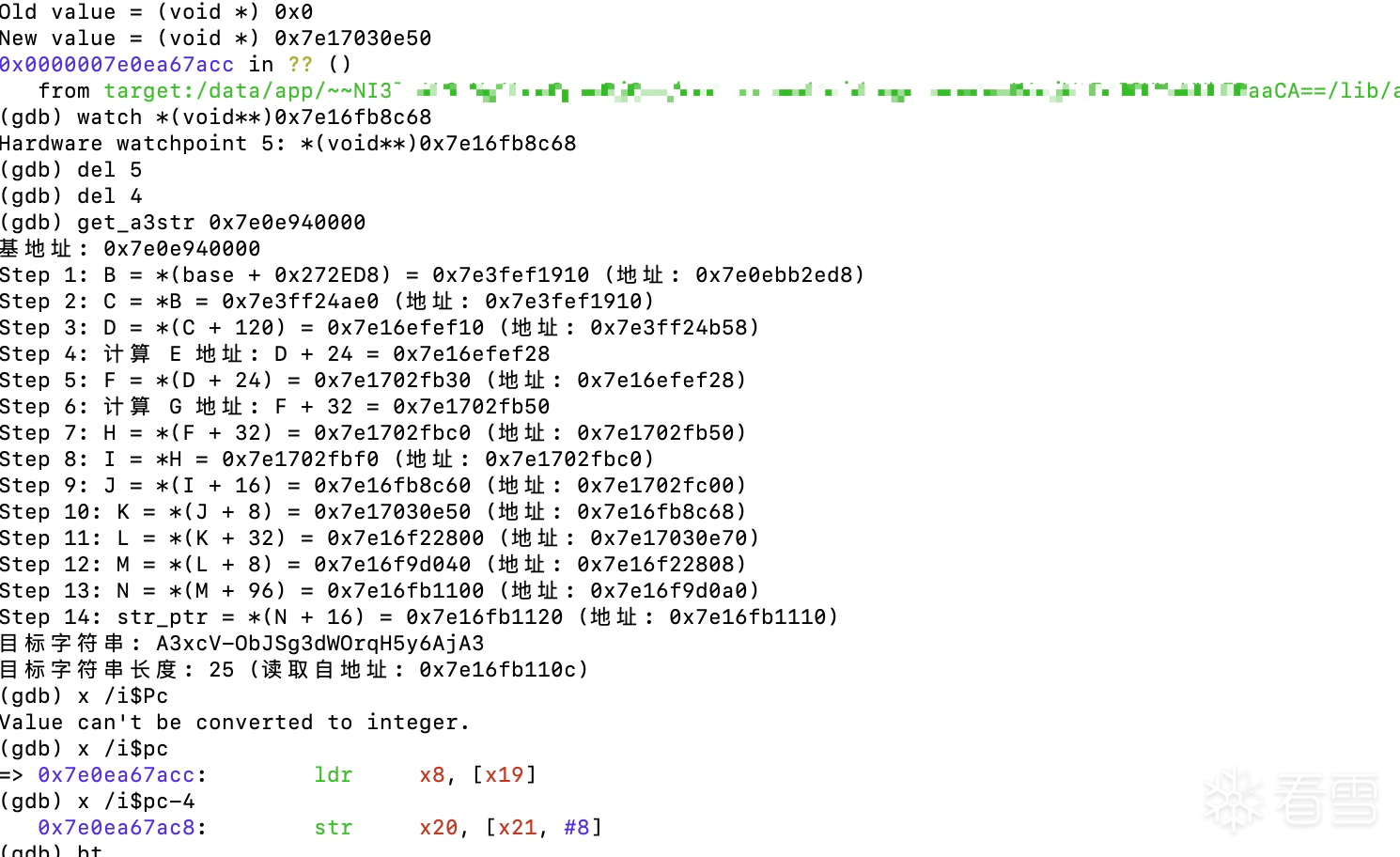
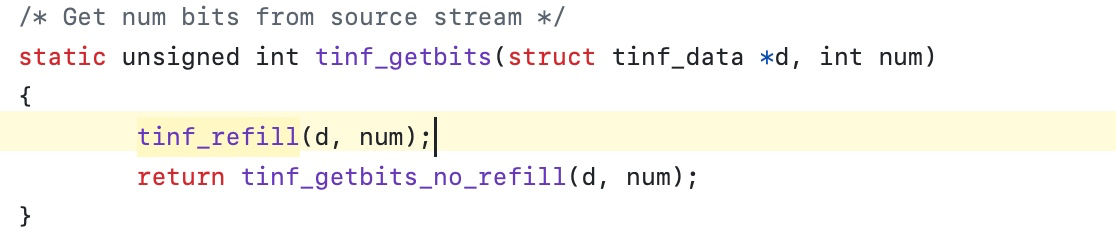
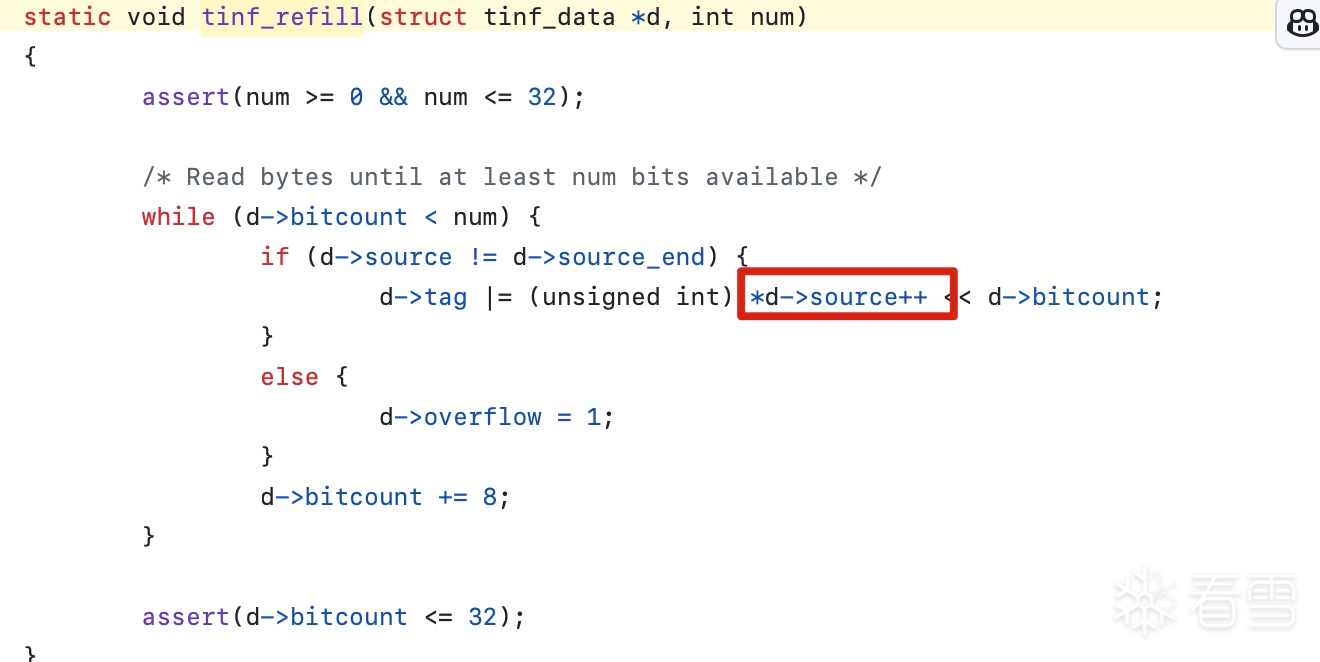
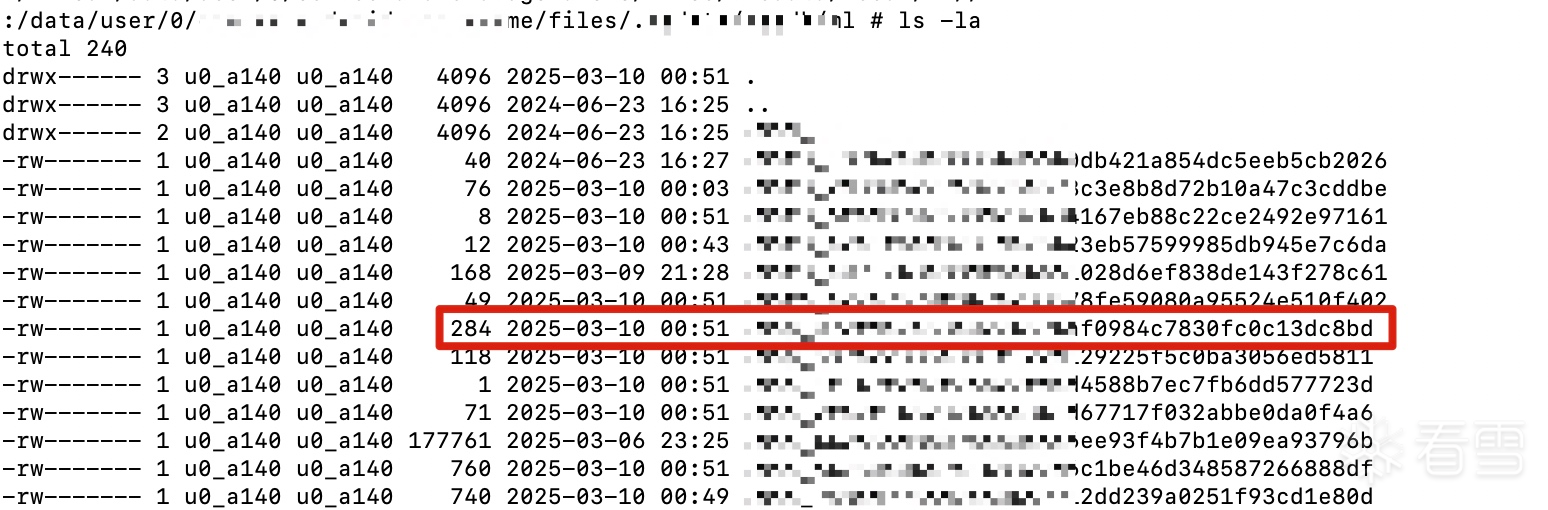
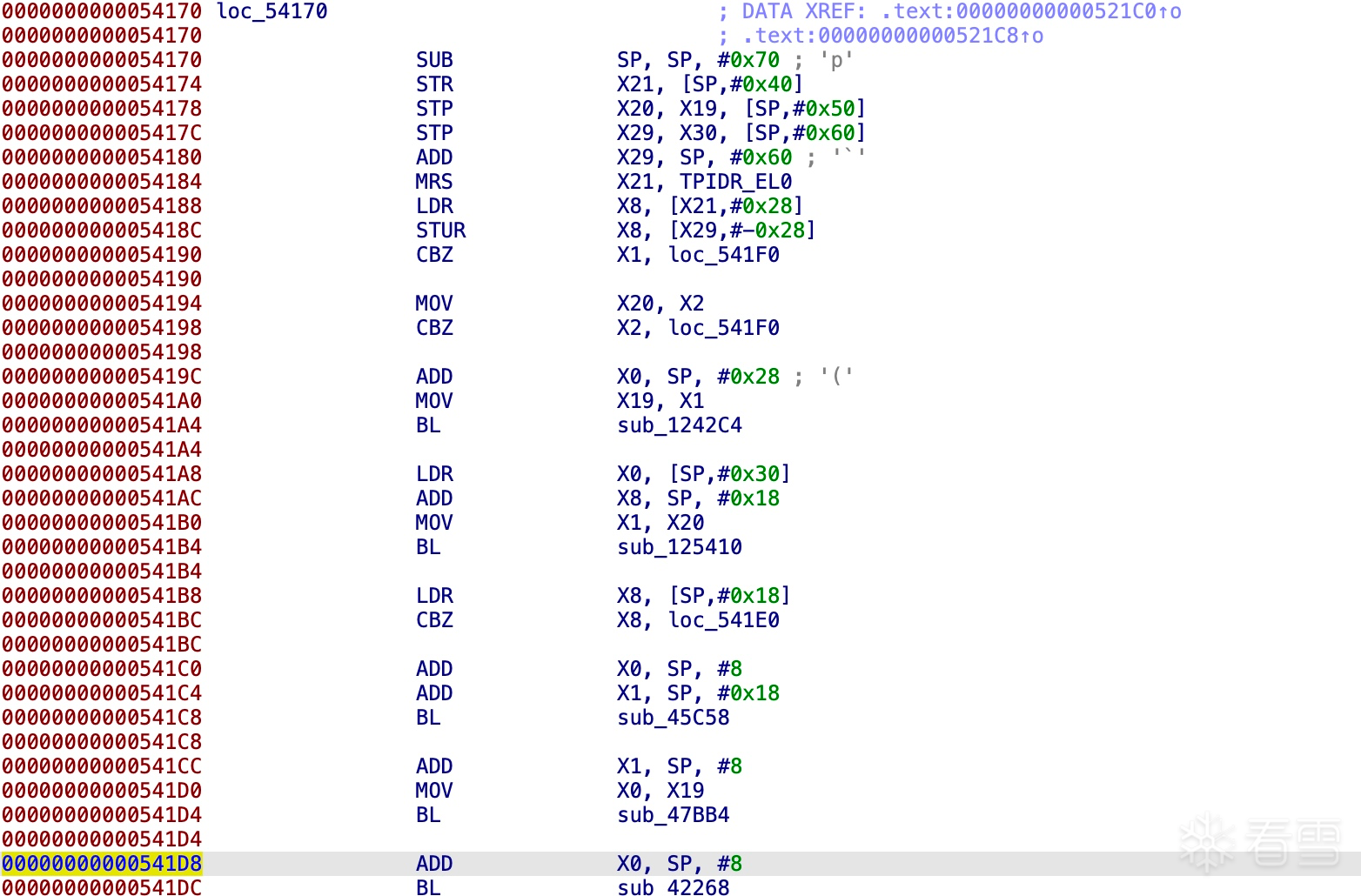
24字节是AES后的最后一个字节 
|

能力值:
( LV2,RANK:10 )
|
-
-
5 楼
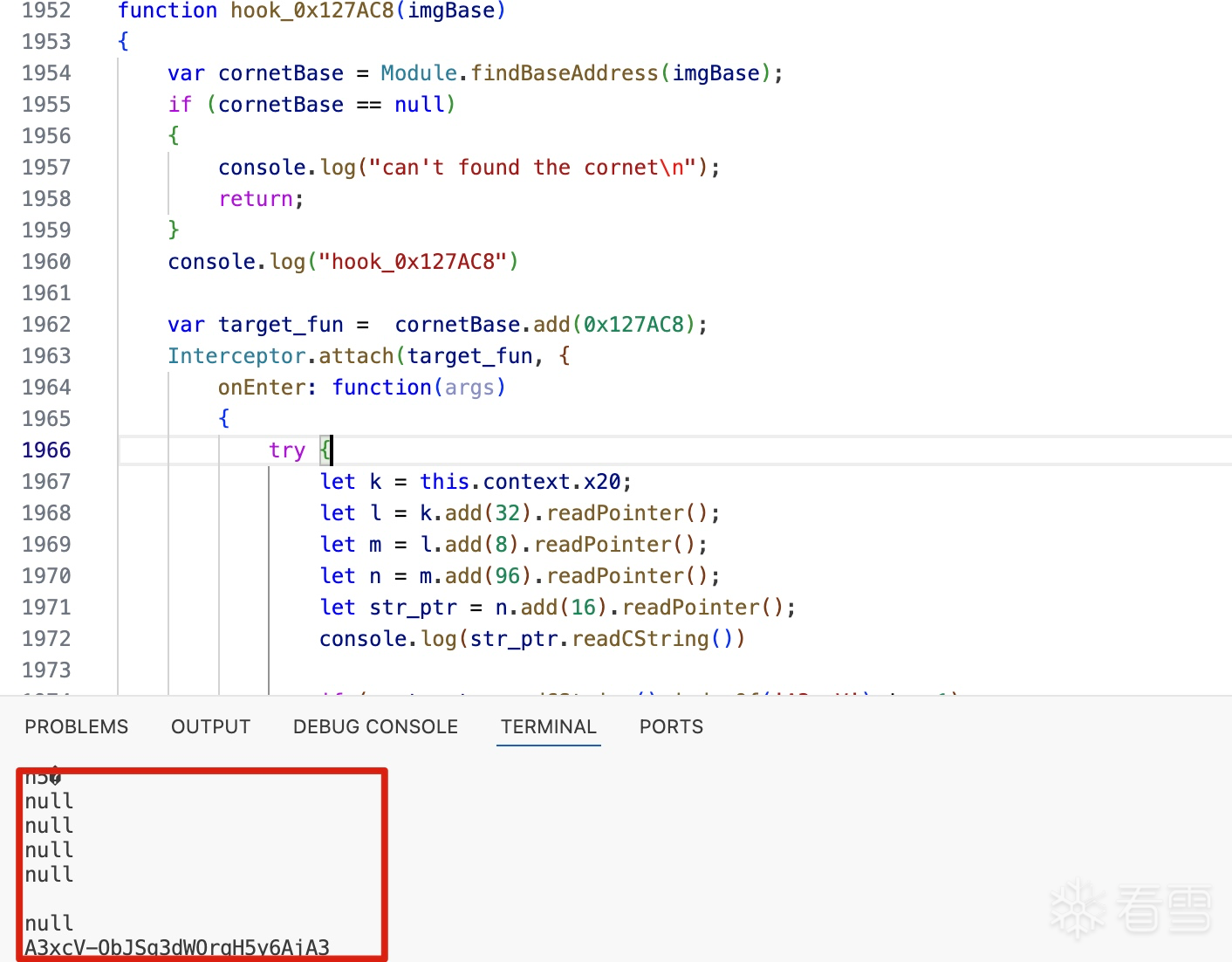
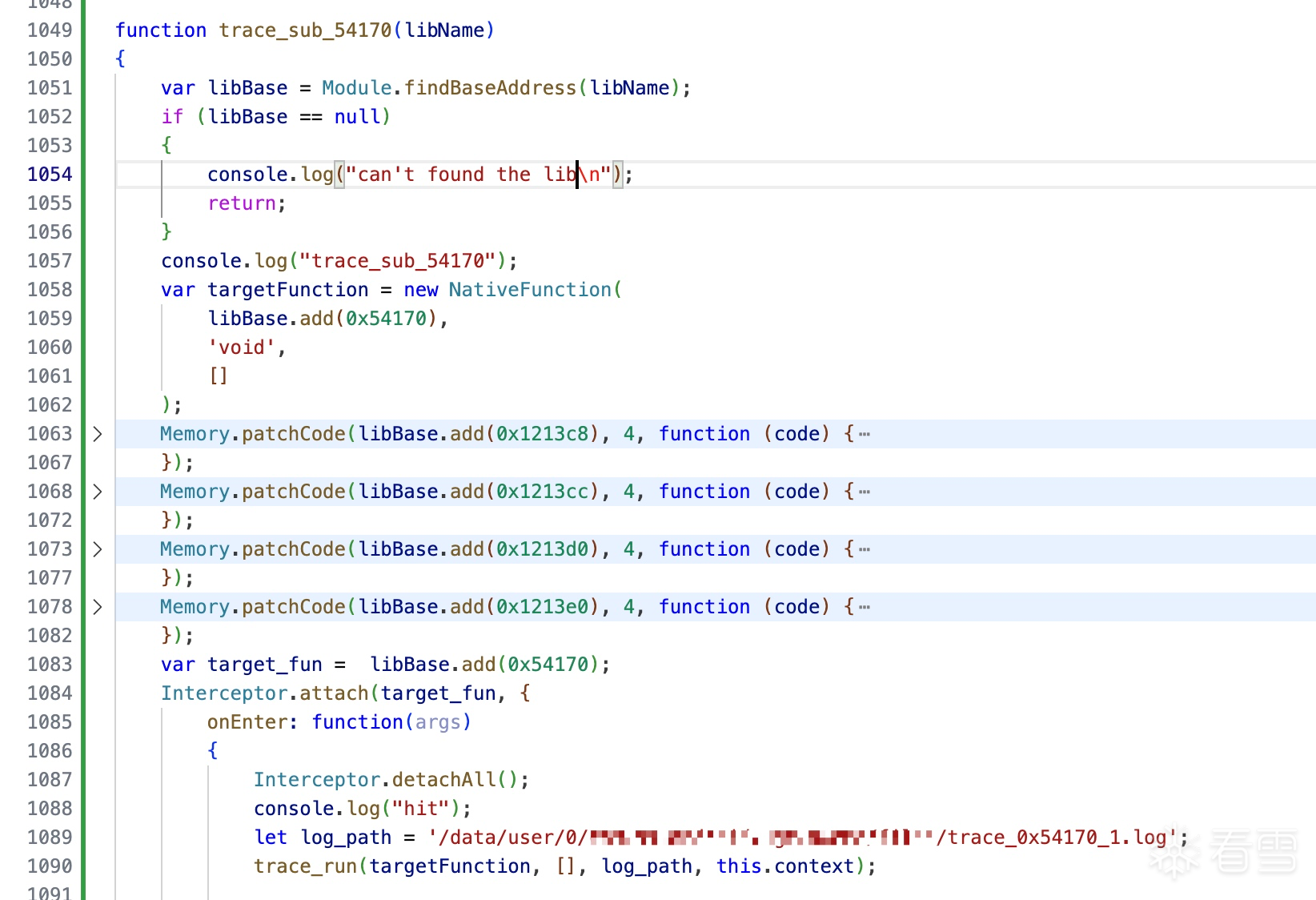
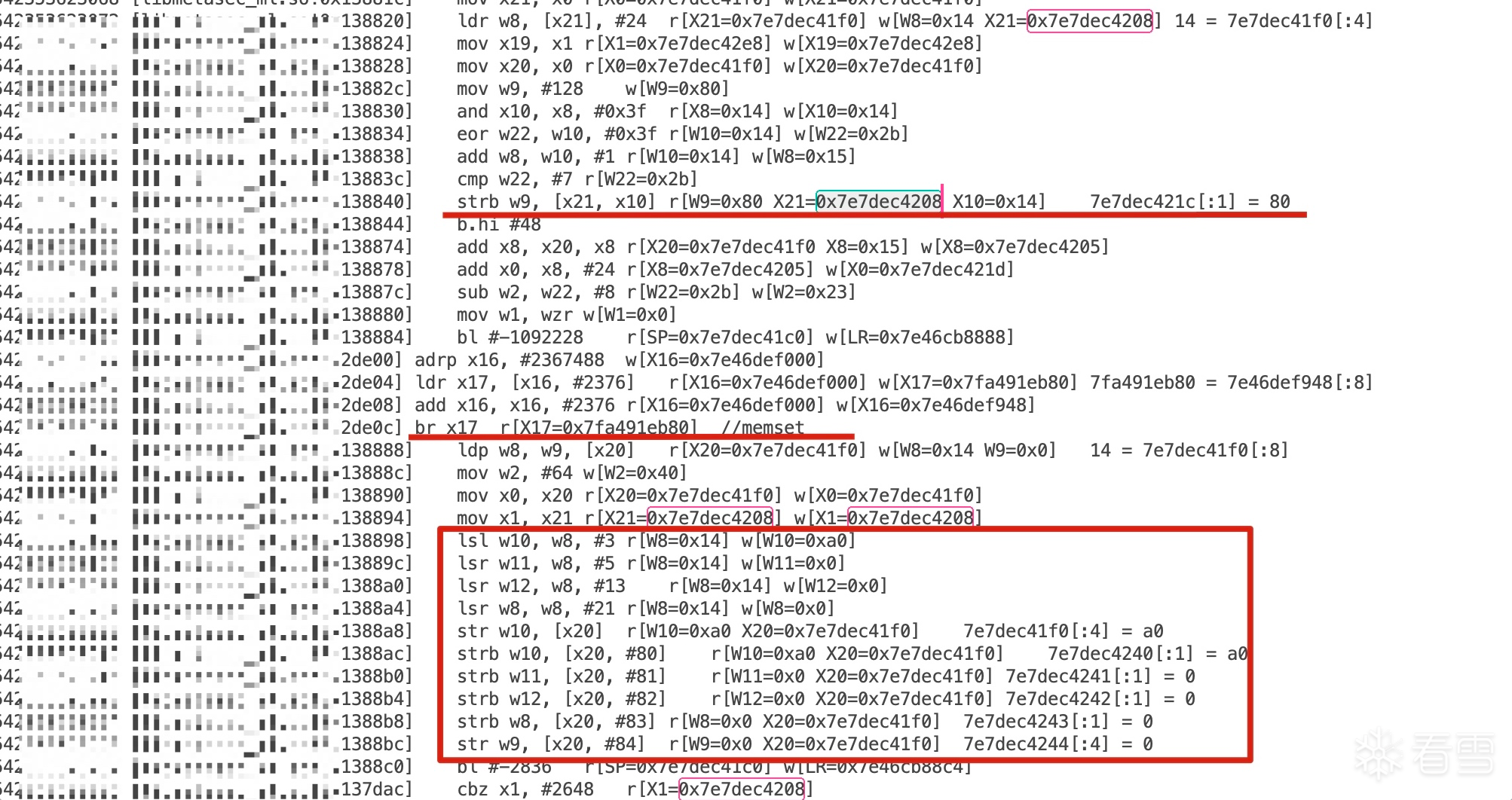
师傅 请教一下你的这个trace的日志是自己写的trace工具trace的吗
|

能力值:
( LV1,RANK:0 )
|
-
-
6 楼
博主 关于tt的jwt刷新机制有研究吗? 
|

能力值:
( LV2,RANK:10 )
|
-
-
7 楼
大哥,你这基本功也太扎实了,服了
|
能力值:
( LV2,RANK:10 )
|
-
-
8 楼
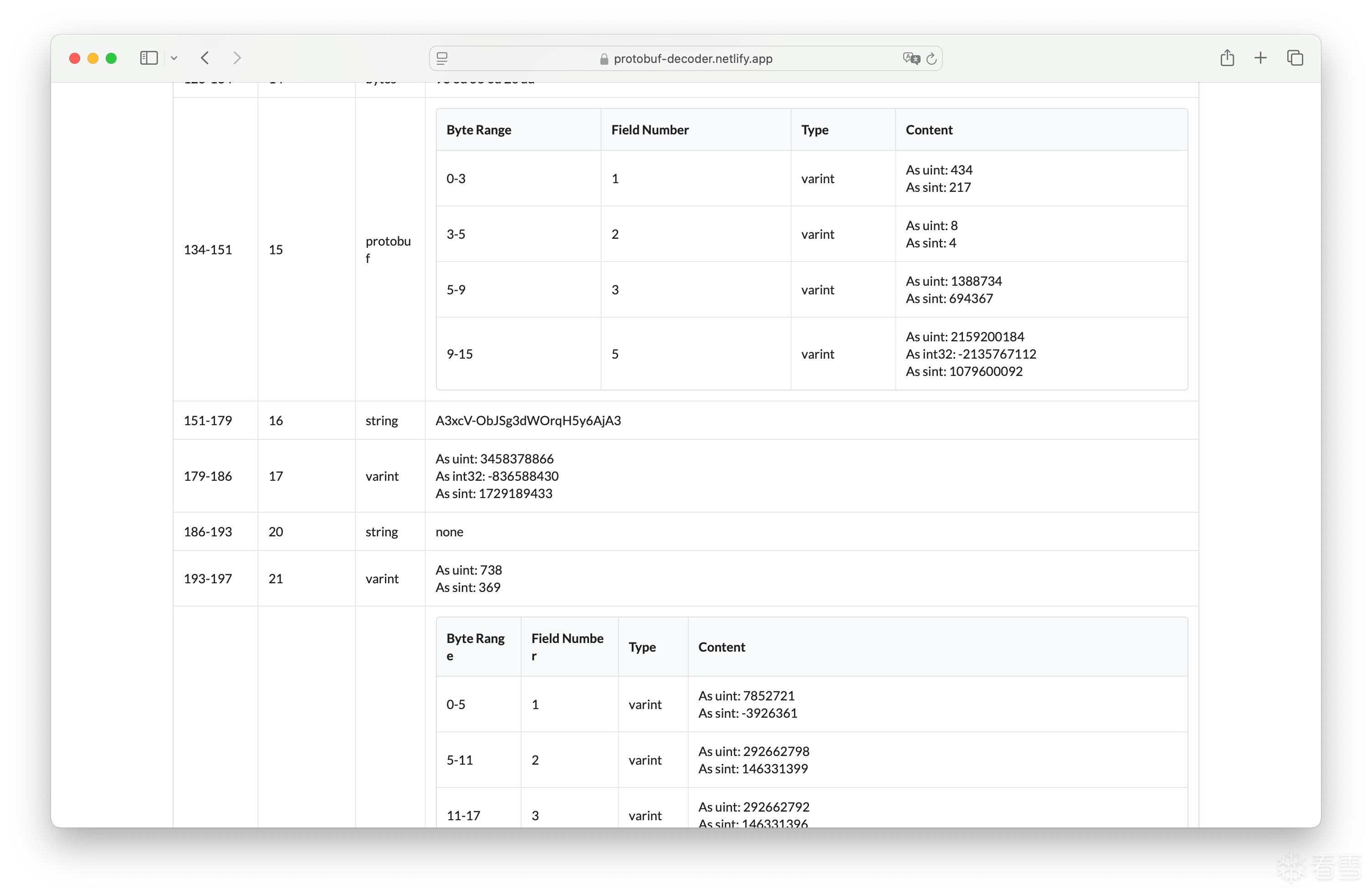
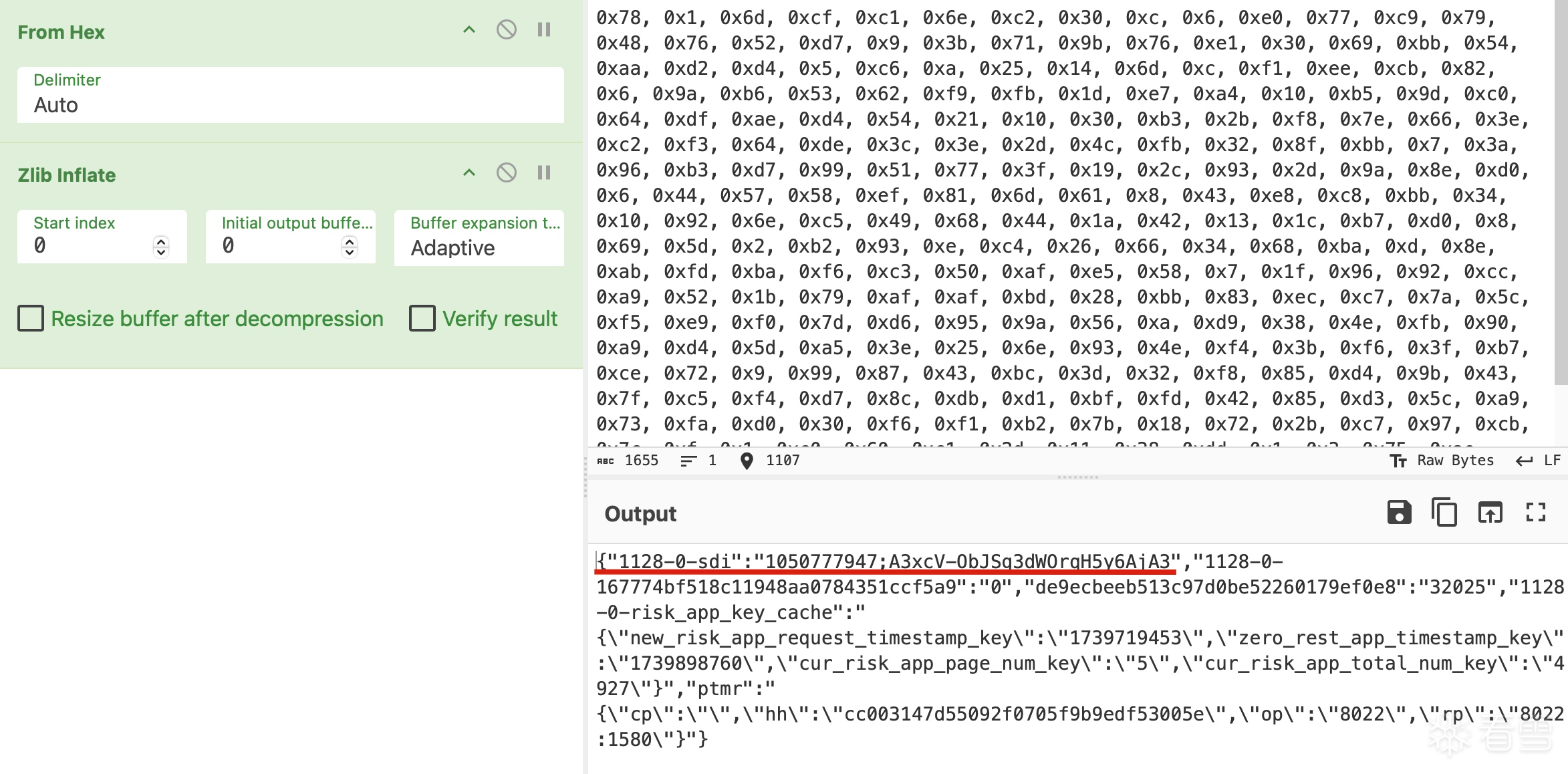
+0x00:时间戳与某个常量异或。
+0x20:随机数的低两位。
+0x22:固定的 0 和 1。
+0x24:魔改AES结果的最后一字节。
+0x25:加密的 Protobuf 数据。
最后两字节:随机数的高两位。
+0x23其实不是固定的1,+0x24也不是aes的最后一字节。只是刚好medusa的数据太长了,才是这样。+0x23是+0x24这部分数据的长度,+0x24是aes前原始数据padding部分的位置对应加密后的所有数据
v157是有效数据长度,v1053是总长度,v1182是pad的长度 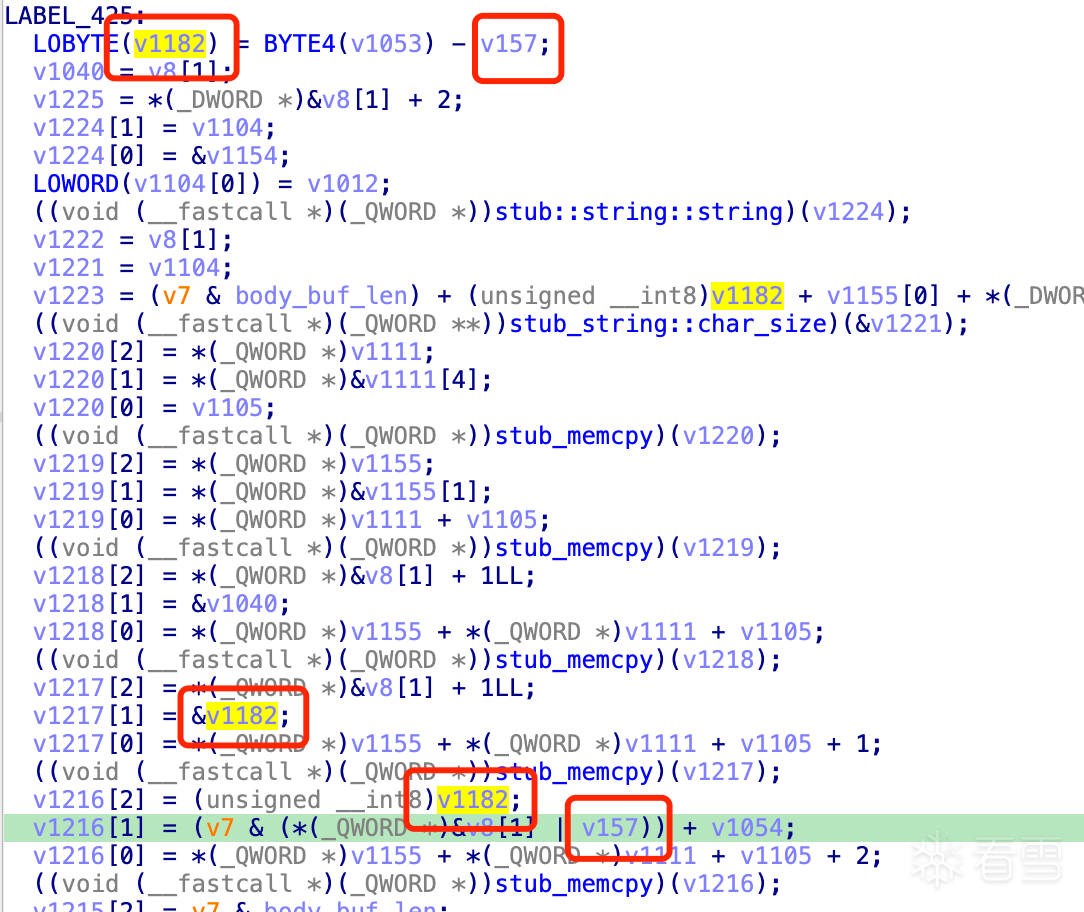
最后于 2025-4-14 00:55
被wx_starfall编辑
,原因:
|
能力值:
( LV2,RANK:10 )
|
-
-
9 楼
很强 只有你这篇有在溯源 pb 的 kv
|

能力值:
( LV2,RANK:10 )
|
-
-
10 楼
这不是get_token请求返回的吗?
|
能力值:
( LV1,RANK:0 )
|
-
-
11 楼
get_token返回的sec_token,mssdk也有加密
|
能力值:
( LV1,RANK:0 )
|
-
-
12 楼
wx_starfall
+0x00:时间戳与某个常量异或。+0x20:随机数的低两位。+0x22:固定的 0 和 1。+0x24:魔改AES结果的最后一字节。+0x25: ...
大佬能在说下嘛,没听太懂
|

能力值:
 ( LV8,RANK:130 )
( LV8,RANK:130 )
|
-
-
13 楼
wx_starfall
+0x00:时间戳与某个常量异或。+0x20:随机数的低两位。+0x22:固定的 0 和 1。+0x24:魔改AES结果的最后一字节。+0x25: ...
这样吗!!我还写了个针对medusa解密的程序,能解好几个版本。根据我之前的定义感觉没啥问题啊。
|
能力值:
( LV1,RANK:0 )
|
-
-
14 楼
怎么联系,大神
|
能力值:
( LV2,RANK:10 )
|
-
-
15 楼
执着的追求
这样吗!!我还写了个针对medusa解密的程序,能解好几个版本。根据我之前的定义感觉没啥问题啊。
那部分应该是个通用函数,在medusa上没啥问题,但是其他地方不一定,你把medusa的算法还原出来就能看到啦
|
能力值:
( LV2,RANK:10 )
|
-
-
16 楼
wx_starfall
那部分应该是个通用函数,在medusa上没啥问题,但是其他地方不一定,你把medusa的算法还原出来就能看到啦
medusa的pcode挺长的,忘了多少了,有1w2吧,最长的是bodyhash的,大概2w7,8的样子
|
能力值:
( LV1,RANK:0 )
|
-
-
17 楼
wx_starfall
medusa的pcode挺长的,忘了多少了,有1w2吧,最长的是bodyhash的,大概2w7,8的样子
您说太长是指xm大于248所以这个地方一定是0x01吗,没太听懂,我和楼主也差不多。解密加密也都正常
|
能力值:
( LV1,RANK:0 )
|
-
-
18 楼
wx_starfall
+0x00:时间戳与某个常量异或。+0x20:随机数的低两位。+0x22:固定的 0 和 1。+0x24:魔改AES结果的最后一字节。+0x25: ...
看明白了
|
能力值:
( LV2,RANK:10 )
|
-
-
19 楼
龙哥在不在
您说太长是指xm大于248所以这个地方一定是0x01吗,没太听懂,我和楼主也差不多。解密加密也都正常
太久没搞我也忘记了,大概是这样,aes的输入数据,是原始数据里取得一些值,好像始终都是提取0x1f字节,这时候,aes pad只有一字节,就是你看到的01 还有魔改aes结果的最后一字节。那么如果原始数据不足提取不了0x1f字节呢,这时候就不是01和最后一字节了,而是好几个字节。具体的实现我也忘了。。。
|

能力值:
( LV2,RANK:10 )
|
-
-
20 楼
wx_starfall
太久没搞我也忘记了,大概是这样,aes的输入数据,是原始数据里取得一些值,好像始终都是提取0x1f字节,这时候,aes pad只有一字节,就是你看到的01 还有魔改aes结果的最后一字节。那么如果原始 ...
最近新出了个X-Persus,Medusa长度变短了,可能会出现你说的这个情况,原有的数据不足以提取出0x1F长度数据,还没验证过 
|

能力值:
( LV2,RANK:10 )
|
-
-
21 楼
执着的追求
这样吗!!我还写了个针对medusa解密的程序,能解好几个版本。根据我之前的定义感觉没啥问题啊。
最后于 2025-10-22 17:11
被陈某人编辑
,原因: 删
|
能力值:
( LV2,RANK:10 )
|
-
-
22 楼
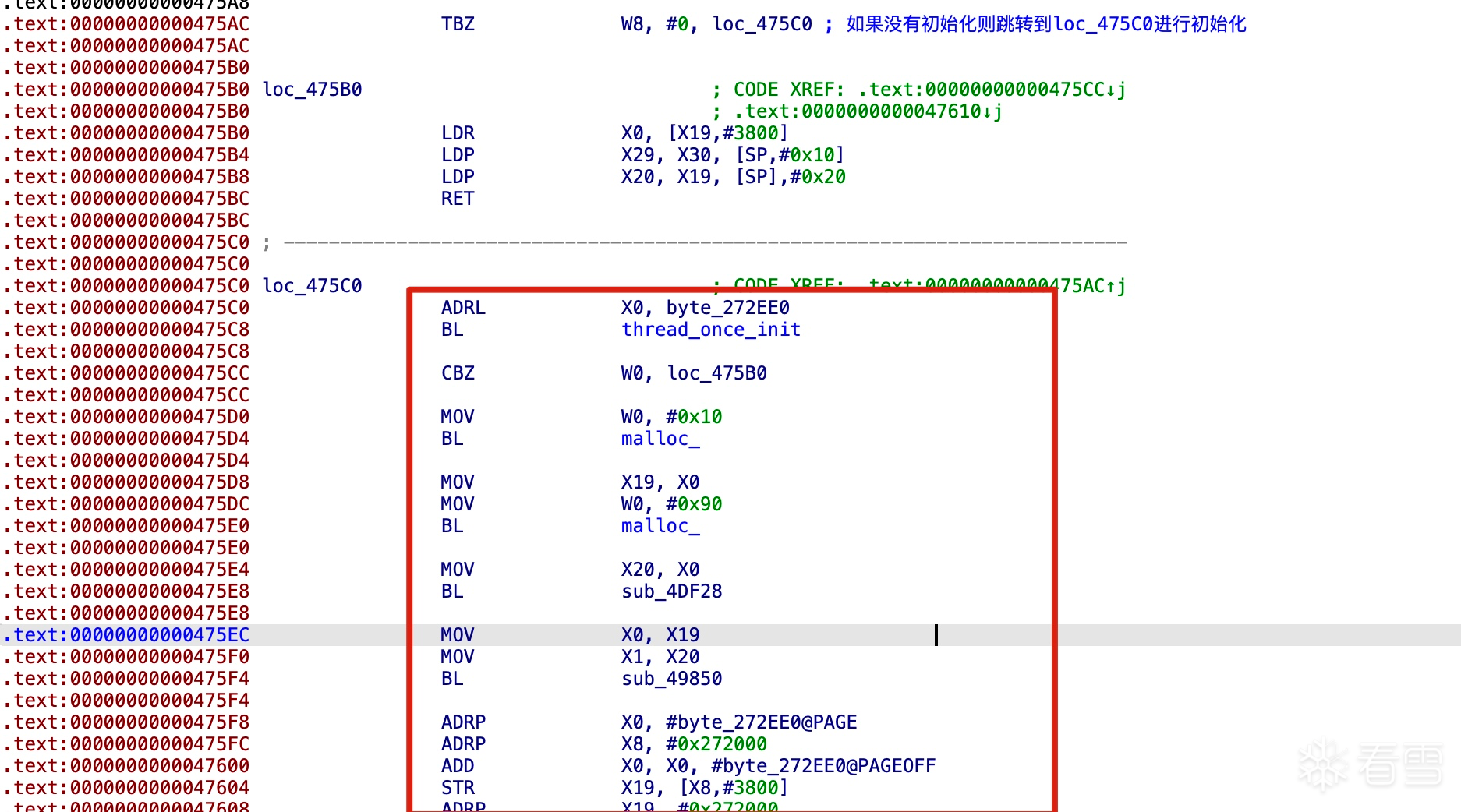
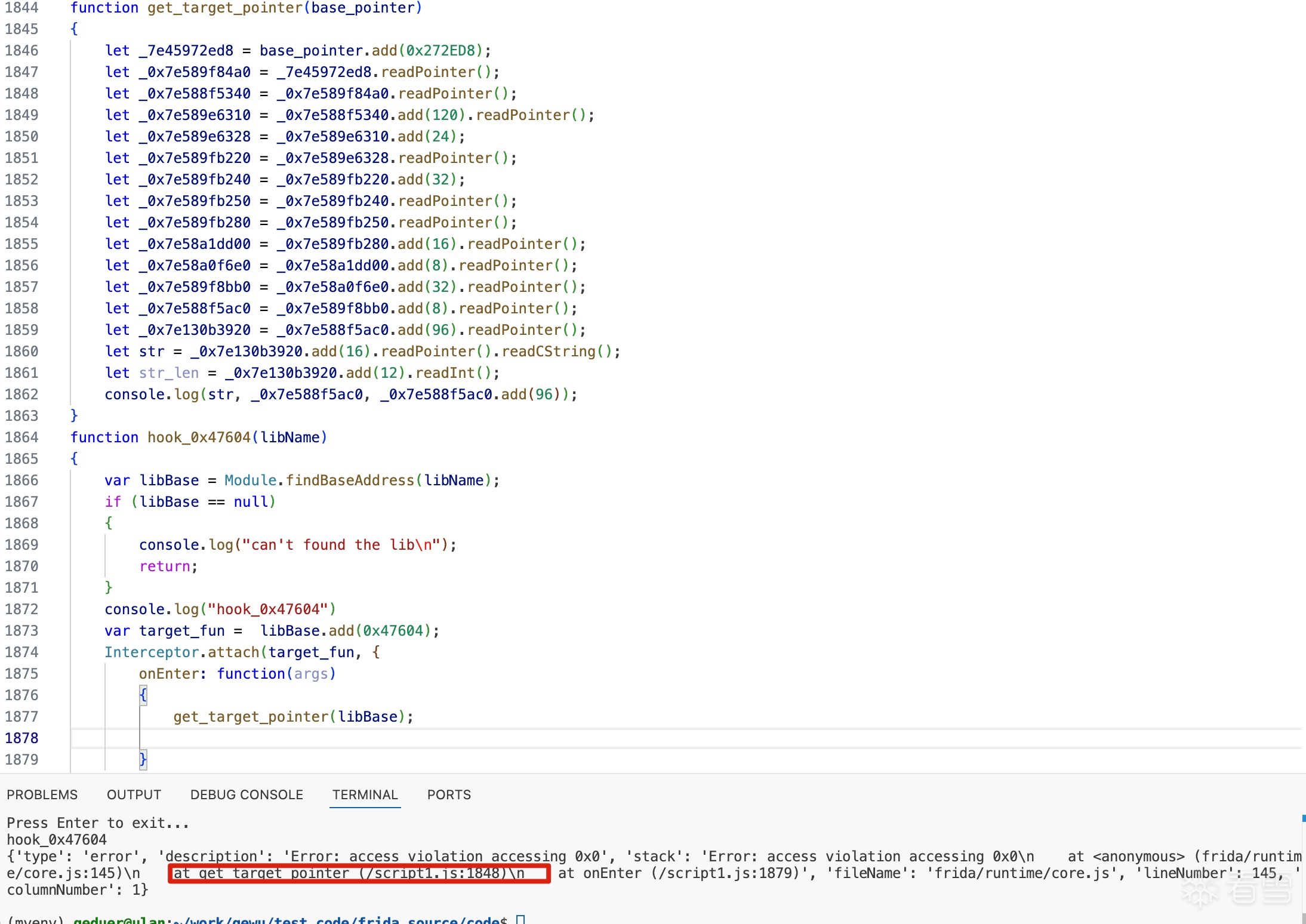
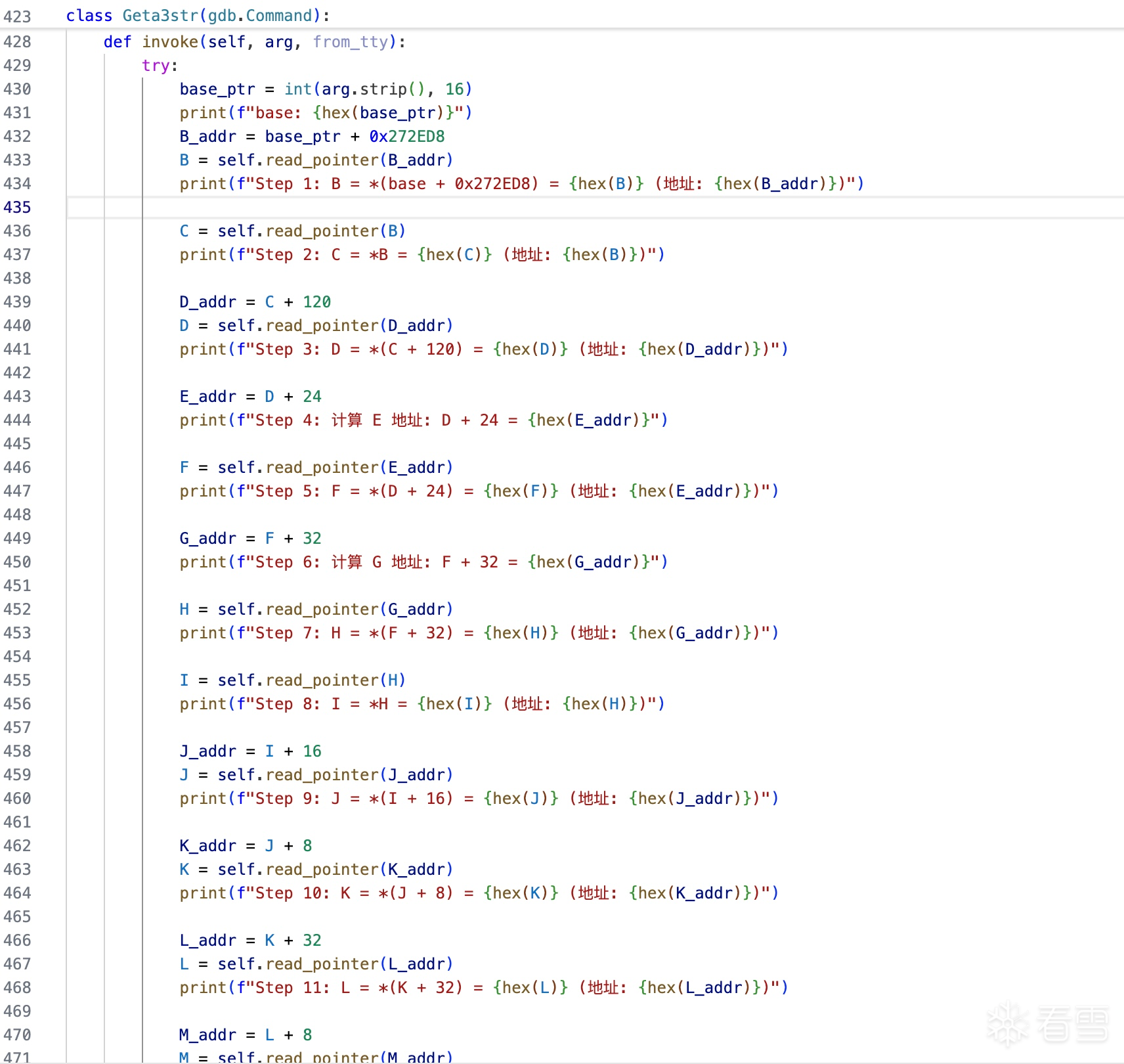
trace用的是什么?Stalker?
|
|
|
|