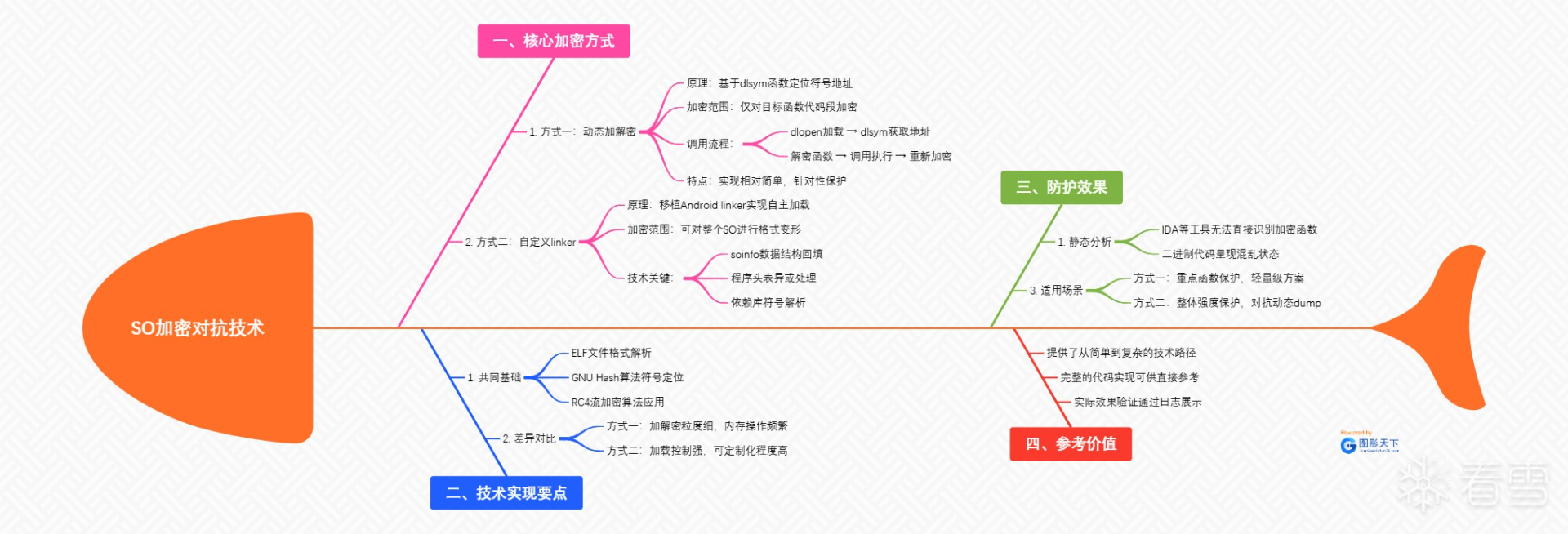
最近翻出一个很久之前实现的一个demo,发现还是有一些参考学习价值,所以整理了下给各位逆向爱好者分享一下,当初是因为在分析某壳vmp时,发现其用自定义了linker去加载so,所以自己稍稍研究了下,想深入了解这篇文章需要先了解elf的格式,以及android中linker加载so的主要流程。
主要是参考android源码中dlsym函数的实现
1.读取so中的elf与段头进行解析
2.采用gnuhash算法对函数符号进行函数位置定位(参考链接代码http://androidxref.com/9.0.0_r3/xref/bionic/linker/linker_soinfo.cpp#176
3.对定位的函数地址段进行加密处理
int harden_handle(char *src_path, char *name, char *dst_path, int mode)
{
Elf64_Ehdr header_;
Elf64_Phdr phdr_;
Elf64_Dyn dyn_;
int dyn_off;
int dyn_size;
int dyn_count;
Elf64_Addr dyn_symtab;
Elf64_Addr dyn_strtab;
Elf64_Addr dyn_gnuhash;
int dyn_strsz;
uint32_t symndex;
size_t gnu_nbucket_;
uint32_t* gnu_bucket_;
uint32_t* gnu_chain_;
uint32_t gnu_maskwords_;
uint32_t gnu_shift2_;
Elf64_Addr *gnu_bloom_filter_;
int fd = open(src_path, O_RDONLY);
if (fd == -1) {
LOGI("error opening file");
return -1;
}
//读elf头
int ret = read(fd, &header_, sizeof(header_));
if (ret < 0) {
LOGI("error read file!");
}
//校验elf头
if (header_.e_ident[EI_MAG0] != ELFMAG0 ||
header_.e_ident[EI_MAG1] != ELFMAG1 ||
header_.e_ident[EI_MAG2] != ELFMAG2 ||
header_.e_ident[EI_MAG3] != ELFMAG3) {
LOGI("\"%s\" has bad ELF magic", src_path);
return -1;
}
if (header_.e_ident[EI_CLASS] != ELFCLASS64) {
LOGI("\"%s\" not 32-bit: %d", src_path, header_.e_ident[EI_CLASS]);
return -1;
}
if (header_.e_ident[EI_DATA] != ELFDATA2LSB) {
LOGI("\"%s\" not little-endian: %d", src_path, header_.e_ident[EI_DATA]);
return -1;
}
if (header_.e_type != ET_DYN) {
LOGI("\"%s\" has unexpected e_type: %d", src_path, header_.e_type);
return -1;
}
if (header_.e_version != EV_CURRENT) {
LOGI("\"%s\" has unexpected e_version: %d", src_path, header_.e_version);
return -1;
}
//读程序头
lseek(fd, header_.e_phoff, SEEK_SET);
for (int i = 0; i < header_.e_phnum; i++) {
ret = read(fd, &phdr_, sizeof(phdr_));
if (ret < 0) {
LOGI("error read file!");
}
LOGI("phdr_.p_type:%d\n", phdr_.p_type);
if (phdr_.p_type != PT_DYNAMIC) {//此段包含动态链接的信息,用于动态链接器解析和处理动态链接库
continue;
}
dyn_off = phdr_.p_offset;
dyn_size = phdr_.p_filesz;
dyn_count = phdr_.p_memsz / (8 * 2);
//LOGI("dyn_off:%d dyn_size:%d dyn_count:%d %d", dyn_off, dyn_size, dyn_count, dyn_size/sizeof(Elf64_Dyn));
}
//读动态段
lseek(fd, dyn_off, SEEK_SET);
for(int i = 0; i < dyn_count; i++) {
ret = read(fd, &dyn_, sizeof(dyn_));
if (ret < 0) {
LOGI("error read file!");
}
switch (dyn_.d_tag) {
case DT_SONAME://so名称在字符串表偏移
break;
case DT_GNU_HASH://GNU HASH表,用于符号定位,表效率更优,查找速度更快
dyn_gnuhash = dyn_.d_un.d_ptr;
break;
case DT_HASH://HASH表,用于符号定位,android5.0以下版本兼容
//nbucket_=reinterpret_cast<uint32_t*>(dyn_.d_un.d_ptr)[0];
//nchain_ = reinterpret_cast<uint32_t*>(dyn_.d_un.d_ptr)[1];
//bucket_ = reinterpret_cast<uint32_t*>(dyn_.d_un.d_ptr + 8);
//chain_ = reinterpret_cast<uint32_t*>(dyn_.d_un.d_ptr + 8 + nbucket_ * 4);
break;
case DT_SYMTAB://动态符号表
dyn_symtab = dyn_.d_un.d_ptr;
break;
case DT_SYMENT://动态符号表大小
break;
case DT_STRTAB://符号字符串表
dyn_strtab = dyn_.d_un.d_ptr;
break;
case DT_STRSZ://符号字符串表大小
dyn_strsz = dyn_.d_un.d_val;
break;
}
}
char *dynstr = (char*) malloc(dyn_strsz);
if(dynstr == NULL){
LOGI("malloc failed");
}
lseek(fd, dyn_strtab, SEEK_SET);
ret = read(fd, dynstr, dyn_strsz);
if (ret < 0) {
LOGI("read .dynstr failed");
}
//Gnu Hash查找法,看不懂算法的可以直接抄写andrdoid源码
lseek(fd, dyn_gnuhash, SEEK_SET);
ret = read(fd, &gnu_nbucket_, 4);
if (ret < 0) {
LOGI("read gnuhash failed");
}
gnu_nbucket_ = gnu_nbucket_ & 0xffff;//ssize_t占8个字节 读4个字节
lseek(fd, dyn_gnuhash + 4, SEEK_SET);
ret = read(fd, &symndex, 4);//支持查找index>=symndx的符号, index<symndx的不能直接通过GNU Hash表查找
if (ret < 0) {
LOGI("read gnuhash failed");
}
lseek(fd, dyn_gnuhash + 8, SEEK_SET);
ret = read(fd, &gnu_maskwords_, 4);
if (ret < 0) {
LOGI("read gnuhash failed");
}
lseek(fd, dyn_gnuhash + 8, SEEK_SET);
ret = read(fd, &gnu_maskwords_, 4);
if (ret < 0) {
LOGI("read gnuhash failed");
}
lseek(fd, dyn_gnuhash + 12, SEEK_SET);
ret = read(fd, &gnu_shift2_, 4);
if (ret < 0) {
LOGI("read gnuhash failed");
}
gnu_bloom_filter_ = reinterpret_cast<Elf64_Addr *>(dyn_gnuhash + 16);//布隆滤波器地址
gnu_bucket_ = reinterpret_cast<uint32_t*>(gnu_bloom_filter_ + gnu_maskwords_);//bucket起始地址
gnu_chain_ = gnu_bucket_ + gnu_nbucket_ - symndex;//chain起始地址减去index偏差
uint32_t hash = gnu_hash(name);
uint32_t h2 = hash >> gnu_shift2_;
uint32_t bloom_mask_bits = sizeof(Elf64_Addr) * 8;
uint32_t word_num = (hash / bloom_mask_bits) & gnu_maskwords_;
uint32_t val = hash % gnu_nbucket_;//找到符号所对应的bucket
uint32_t n;
lseek(fd, reinterpret_cast<uint64_t> (gnu_bucket_ + val), SEEK_SET);
ret = read(fd, &n, 4);
if (ret < 0) {
LOGI("read gnuhash failed");
}
Elf64_Sym s;
uint32_t chain;
do {
lseek(fd, dyn_symtab + n * sizeof(Elf64_Sym), SEEK_SET);
ret = read(fd, &s, sizeof(Elf64_Sym));
if (ret < 0) {
LOGI("read gnuhash failed");
}
LOGI("name = %d %s", s.st_name, dynstr + s.st_name);
lseek(fd, reinterpret_cast<uint64_t>(gnu_chain_ + n), SEEK_SET);
ret = read(fd, &chain, sizeof(chain));
if (ret < 0) {
LOGI("read gnuhash failed");
}
if (((chain ^ hash) >> 1) == 0 && strcmp(dynstr + s.st_name, name) == 0) {//hash只使用了前31位
LOGI("found function(%s) at %p(%zd)", name, reinterpret_cast<void*>(s.st_value), static_cast<size_t>(s.st_size));
break;
}
n++;
lseek(fd, reinterpret_cast<uint64_t>(gnu_chain_ + n), SEEK_SET);
ret = read(fd, &chain, sizeof(chain));
if (ret < 0) {
LOGI("read gnuhash failed");
}
} while((chain & 1) == 0);//hash最后一位判断chain链表是否结束
uint32_t size = get_file_size(src_path);
char *file_buf = (char *)malloc(size);
if (file_buf == NULL) {
LOGI("file buf malloc failed");
}
lseek(fd, 0, SEEK_SET);
ret = read(fd, file_buf, size);
if (ret < 0) {
LOGI("read file buf failed");
}
close(fd);
//so加密修改与保存
char save_path[128] = {0};
fd = open(dst_path, O_RDWR | O_CREAT);
char *encrypt_buf = (char *)malloc(s.st_size);
encrypt((unsigned char *) RC4_KEY, reinterpret_cast<unsigned char *>(encrypt_buf),
reinterpret_cast<unsigned char *>(&file_buf[s.st_value]), s.st_size);
memcpy(&file_buf[s.st_value], encrypt_buf, s.st_size);
if (mode == MODE_DUPLEX) {
for (int i = 0; i < header_.e_phnum * sizeof(phdr_); i++) {
file_buf[header_.e_phoff + i] = file_buf[header_.e_phoff + i] ^ XOR_MAGIC;
}
}
write(fd, file_buf, size);
free(encrypt_buf);
close(fd);
return 0;
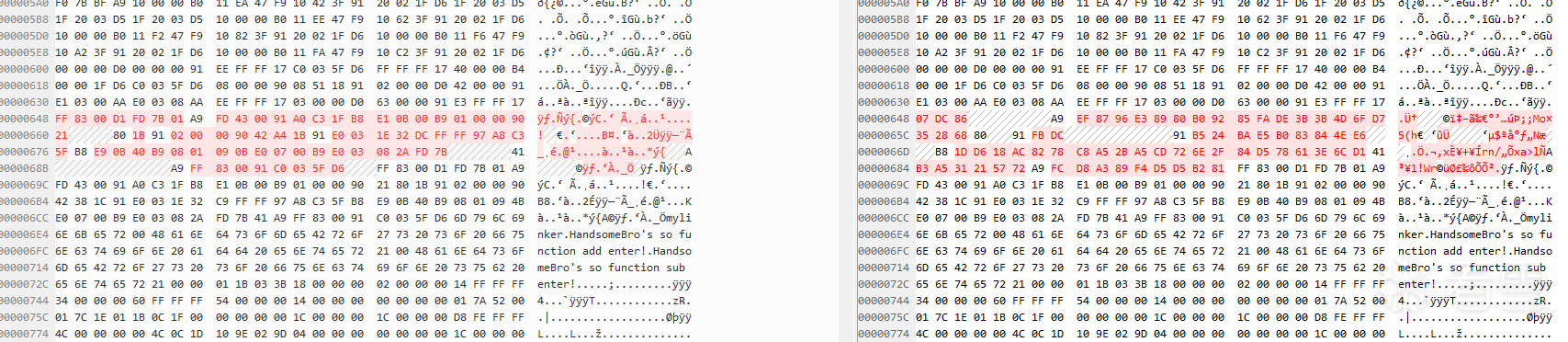
} 加密前后二进制对比
未加密的so用IDA打开
用frida在内存中dump的so用IDA打开(非解密时刻dump)
1.dlopen打开库文件用dlsym获取函数地址
2.修改内存权限,解密覆盖函数地址范围,恢复内存权限
3.调用函数运行
4.修改内存权限,加密覆盖函数地址范围,恢复内存权限
extern "C" JNIEXPORT void JNICALL
Java_com_core_mylinker_MainActivity_loadSO(
JNIEnv* env,
jobject /* this */,
jstring str) {
void *lib;
char libpath[256] ={0};
char buf[512] = {0};
uint64_t start;
uint64_t end;
ssize_t page;
FUNC lib_func = NULL;
RC4_CTX ctx;
int result;
const char *nativepath = env->GetStringUTFChars(str, 0);
sprintf(libpath, "%s/libload_encrypt.so", nativepath);
LOGI("path: %s", libpath);
lib = dlopen(libpath, RTLD_LAZY);
if (lib == NULL) {
LOGI("%s dlopen failed: %s\n", "libload_encrypt.so", dlerror());
}
//获取库函数
lib_func = reinterpret_cast<FUNC>(dlsym(lib, "my_add"));
if (!lib_func) {
LOGI("can't find module symbol: %s\n", dlerror());
}
LOGI("loadso lib_func = %p", lib_func);
//修改内存读写权限
parse_maps_for_lib("libload_encrypt.so", &start, &end);
page = end - start;
if (mprotect((void*)start, page, PROT_READ | PROT_WRITE | PROT_EXEC) == -1) {
LOGI("mprotect failed");
}
//解密覆盖
rc4_init(&ctx, (unsigned char *) RC4_KEY, strlen(reinterpret_cast<const char *>(RC4_KEY)));
rc4_run(&ctx, reinterpret_cast<unsigned char *>(buf), reinterpret_cast<unsigned char *>(lib_func), FUNC_SIZE);
memcpy((void*)lib_func, buf, FUNC_SIZE);
//权限还原
if (mprotect((void*)start, page, PROT_READ | PROT_EXEC) == -1) {
LOGI("mprotect failed");
}
//调用库函数
result = lib_func(1, 2);
LOGI("loadso add result = %d", result);
//修改内存读写权限
parse_maps_for_lib("libload_encrypt.so", &start, &end);
page = end - start;
if (mprotect((void*)start, page, PROT_READ | PROT_WRITE | PROT_EXEC) == -1) {
LOGI("mprotect failed");
}
//加密还原覆盖
rc4_init(&ctx, (unsigned char *) RC4_KEY, strlen(reinterpret_cast<const char *>(RC4_KEY)));
rc4_run(&ctx, reinterpret_cast<unsigned char *>(buf), reinterpret_cast<unsigned char *>(lib_func), FUNC_SIZE);
memcpy((void*)lib_func, buf, FUNC_SIZE);
//权限还原
if (mprotect((void*)start, page, PROT_READ | PROT_EXEC) == -1) {
LOGI("mprotect failed");
}
dlclose(lib);
env->ReleaseStringUTFChars(str, nativepath);
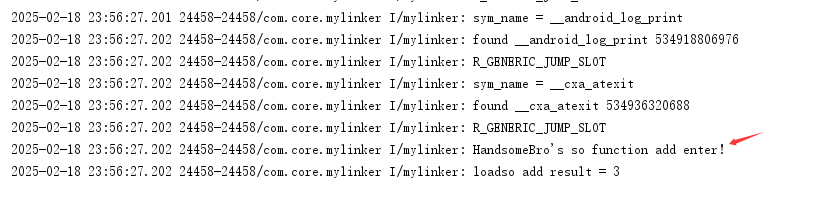
} 正常运行日志,能正常解密并调用so函数
加密代码前面已经贴出来了,就是在方式一的基础上,对每个段头的type进行了异或处理
加密前后二进制对比比方式一多了以下修改
主要是移植android9.0的linker代码对so的进行自定义解密加载,主要流程如下:
1.so读取
bool ElfReader::Read(const char* name, int fd, off64_t file_offset, off64_t file_size) {
if (did_read_) {
return true;
}
name_ = name;
fd_ = fd;
file_offset_ = file_offset;
file_size_ = file_size;
if (ReadElfHeader() && //读取elf头
VerifyElfHeader() &&//校验elf头
ReadProgramHeaders()){//读取段头
did_read_ = true;
}
return did_read_;
} 看下ReadElfHeader函数,基本就是直接读取比较简单
bool ElfReader::ReadElfHeader() {
ssize_t rc = pread(fd_, &header_, sizeof(header_), file_offset_);
if (rc < 0) {
LOGI("can't read file \"%s\": %s", name_.c_str(), strerror(errno));
return false;
}
if (rc != sizeof(header_)) {
LOGI("\"%s\" is too small to be an ELF executable: only found %zd bytes", name_.c_str(),
static_cast<size_t>(rc));
return false;
}
return true;
} 继续看下VerifyElfHeader函数,都是些判断比较,自己实现linker流程也可以去掉这个函数
bool ElfReader::VerifyElfHeader() {
if (memcmp(header_.e_ident, ELFMAG, SELFMAG) != 0) {
LOGI("\"%s\" has bad ELF magic", name_.c_str());
return false;
}
// Try to give a clear diagnostic for ELF class mismatches, since they're
// an easy mistake to make during the 32-bit/64-bit transition period.
int elf_class = header_.e_ident[EI_CLASS];
if (elf_class != ELFCLASS64) {
if (elf_class == ELFCLASS32) {
LOGI("\"%s\" is 32-bit instead of 64-bit", name_.c_str());
} else {
LOGI("\"%s\" has unknown ELF class: %d", name_.c_str(), elf_class);
}
return false;
}
if (header_.e_ident[EI_DATA] != ELFDATA2LSB) {
LOGI("\"%s\" not little-endian: %d", name_.c_str(), header_.e_ident[EI_DATA]);
return false;
}
if (header_.e_type != ET_DYN) {
LOGI("\"%s\" has unexpected e_type: %d", name_.c_str(), header_.e_type);
return false;
}
if (header_.e_version != EV_CURRENT) {
LOGI("\"%s\" has unexpected e_version: %d", name_.c_str(), header_.e_version);
return false;
}
if (header_.e_shentsize != sizeof(ElfW(Shdr))) {
LOGI("invalid-elf-header_section-headers-enforced-for-api-level-26",
"\"%s\" has unsupported e_shentsize 0x%x (expected 0x%zx)");
}
if (header_.e_shstrndx == 0) {
LOGI("invalid-elf-header_section-headers-enforced-for-api-level-26",
"\"%s\" has invalid e_shstrndx", name_.c_str());
}
return true;
} 最后看下ReadProgramHeaders函数,检查完边界后,直接mmap进行映射
bool ElfReader::ReadProgramHeaders() {
phdr_num_ = header_.e_phnum;
// Like the kernel, we only accept program header tables that
// are smaller than 64KiB.
if (phdr_num_ < 1 || phdr_num_ > 65536/sizeof(ElfW(Phdr))) {
LOGI("\"%s\" has invalid e_phnum: %zd\n", name_.c_str(), phdr_num_);
return false;
}
// Boundary checks
size_t size = phdr_num_ * sizeof(ElfW(Phdr));
if (!CheckFileRange(header_.e_phoff, size, alignof(ElfW(Phdr)))) {
LOGI("\"%s\" has invalid phdr offset/size: %zu/%zu\n",
name_.c_str(),
static_cast<size_t>(header_.e_phoff),
size);
return false;
}
if (!phdr_fragment_.Map(fd_, file_offset_, header_.e_phoff, size)) {
LOGI("\"%s\" phdr mmap failed: %s\n", name_.c_str(), strerror(errno));
return false;
}
phdr_table_ = static_cast<ElfW(Phdr)*>(phdr_fragment_.data());
return true;
} 2.so加载
bool ElfReader::Load() {
CHECK(did_read_);
if (did_load_) {
return true;
}
if (ReserveAddressSpace() && //创建足够大加载段的内存空间
LoadSegments()&& //段加载
FindPhdr()) {//寻找程序头
did_load_ = true;
}
return did_load_;
} 先看下ReserveAddressSpace函数,主要是创建一个足够大,并且虚拟地址连续的匿名映射空间
// Reserve a virtual address range big enough to hold all loadable
// segments of a program header table. This is done by creating a
// private anonymous mmap() with PROT_NONE.
bool ElfReader::ReserveAddressSpace() {
ElfW(Addr) min_vaddr;
ElfW(Addr) max_vaddr;
load_size_ = phdr_table_get_load_size(phdr_table_, phdr_num_, &min_vaddr, &max_vaddr);//获取PT_LOAD段的区间跨度大小
if (load_size_ == 0) {
LOGI("\"%s\" has no loadable segments\n", name_.c_str());
return false;
}
uint8_t* addr = reinterpret_cast<uint8_t*>(min_vaddr);
void* start;
size_t reserved_size = 0;
bool reserved_hint = true;
bool strict_hint = false;
// Assume position independent executable by default.
void* mmap_hint = nullptr;
if (load_size_ > reserved_size) {
if (!reserved_hint) {
LOGI("reserved address space %zd smaller than %zd bytes needed for \"%s\"\n",
reserved_size - load_size_, load_size_, name_.c_str());
return false;
}
start = ReserveAligned(mmap_hint, load_size_, kLibraryAlignment);//映射匿名内存空间
if (start == nullptr) {
LOGI("couldn't reserve %zd bytes of address space for \"%s\"\n", load_size_, name_.c_str());
return false;
}
if (strict_hint && (start != mmap_hint)) {
munmap(start, load_size_);
LOGI("couldn't reserve %zd bytes of address space at %p for \"%s\"\n",
load_size_, mmap_hint, name_.c_str());
return false;
}
load_start_ = start;//mmap匿名空间的起始地址
load_bias_ = reinterpret_cast<uint8_t*>(start) - addr;//mmap匿名空间的起始地址偏差,主要用于后续计算
return true;
} 继续看下LoadSegments函数,功能也比较简单,主要将PT_LOAD段映射到前面创建的连续匿名映射内存空间当中
bool ElfReader::LoadSegments() {
for (size_t i = 0; i < phdr_num_; ++i) {
const ElfW(Phdr)* phdr = &phdr_table_[i];
if ((phdr->p_type ^ TYPE_XOR_MAGIC) != PT_LOAD) {//自定义异或解密,加密函数异或处理过
continue;
}
// Segment addresses in memory.
ElfW(Addr) seg_start = phdr->p_vaddr + load_bias_;//段在内存起始地址
ElfW(Addr) seg_end = seg_start + phdr->p_memsz;//段在内存结束地址
ElfW(Addr) seg_page_start = PAGE_START(seg_start);//所在页起始地址
ElfW(Addr) seg_page_end = PAGE_END(seg_end);//所在页结束地址
ElfW(Addr) seg_file_end = seg_start + phdr->p_filesz;
// File offsets.
ElfW(Addr) file_start = phdr->p_offset;
ElfW(Addr) file_end = file_start + phdr->p_filesz;
ElfW(Addr) file_page_start = PAGE_START(file_start);
ElfW(Addr) file_length = file_end - file_page_start;
if (file_size_ <= 0) {
LOGI("\"%s\" invalid file size: %", name_.c_str(), file_size_);
return false;
}
if (file_end > static_cast<size_t>(file_size_)) {
LOGI("invalid ELF file \"%s\" load segment[%zd]:"
" p_offset (%p) + p_filesz (%p) ( = %p) past end of file",
name_.c_str(), i, reinterpret_cast<void*>(phdr->p_offset),
reinterpret_cast<void*>(phdr->p_filesz),
reinterpret_cast<void*>(file_end), file_size_);
return false;
}
if (file_length != 0) {
int prot = PFLAGS_TO_PROT(phdr->p_flags);
if ((prot & (PROT_EXEC | PROT_WRITE)) == (PROT_EXEC | PROT_WRITE)) {
LOGI("writable-and-executable-segments-enforced-for-api-level-26",
"\"%s\" has load segments that are both writable and executable",
name_.c_str());
}
void* seg_addr = mmap64(reinterpret_cast<void*>(seg_page_start),
file_length,
prot,
MAP_FIXED|MAP_PRIVATE,
fd_,
file_offset_ + file_page_start);
if (seg_addr == MAP_FAILED) {
LOGI("couldn't map \"%s\" segment %zd: %s\n", name_.c_str(), i, strerror(errno));
return false;
}
LOGI("seg_addr = %p\n", seg_addr);
}
// if the segment is writable, and does not end on a page boundary,
// zero-fill it until the page limit.
if ((phdr->p_flags & PF_W) != 0 && PAGE_OFFSET(seg_file_end) > 0) {
memset(reinterpret_cast<void*>(seg_file_end), 0, PAGE_SIZE - PAGE_OFFSET(seg_file_end));
}
seg_file_end = PAGE_END(seg_file_end);
// seg_file_end is now the first page address after the file
// content. If seg_end is larger, we need to zero anything
// between them. This is done by using a private anonymous
// map for all extra pages.
if (seg_page_end > seg_file_end) {
size_t zeromap_size = seg_page_end - seg_file_end;
void* zeromap = mmap(reinterpret_cast<void*>(seg_file_end),
zeromap_size,
PFLAGS_TO_PROT(phdr->p_flags),
MAP_FIXED|MAP_ANONYMOUS|MAP_PRIVATE,
-1,
0);
if (zeromap == MAP_FAILED) {
LOGI("couldn't zero fill \"%s\" gap: %s", name_.c_str(), strerror(errno));
return false;
}
}
}
return true;
} 最后看下FindPhdr函数,主要是检测可加载段的内存中是否包含程序头表,总共两种方法进行检测,第一种是直接判断 PT_PHDR段,第二种是找PT_LOAD段中文件偏移为0的段去计算判断
// Sets loaded_phdr_ to the address of the program header table as it appears
// in the loaded segments in memory. This is in contrast with phdr_table_,
// which is temporary and will be released before the library is relocated.
bool ElfReader::FindPhdr() {
const ElfW(Phdr)* phdr_limit = phdr_table_ + phdr_num_;
// If there is a PT_PHDR, use it directly.
for (const ElfW(Phdr)* phdr = phdr_table_; phdr < phdr_limit; ++phdr) {
if ((phdr->p_type ^ TYPE_XOR_MAGIC) == PT_PHDR) {//自定义异或解密,加密函数异或处理过
return CheckPhdr(load_bias_ + phdr->p_vaddr);
}
}
// Otherwise, check the first loadable segment. If its file offset
// is 0, it starts with the ELF header, and we can trivially find the
// loaded program header from it.
for (const ElfW(Phdr)* phdr = phdr_table_; phdr < phdr_limit; ++phdr) {
if ((phdr->p_type ^ TYPE_XOR_MAGIC) == PT_LOAD) {//自定义异或解密,加密函数异或处理过
if (phdr->p_offset == 0) {
ElfW(Addr) elf_addr = load_bias_ + phdr->p_vaddr;
const ElfW(Ehdr)* ehdr = reinterpret_cast<const ElfW(Ehdr)*>(elf_addr);
ElfW(Addr) offset = ehdr->e_phoff;
return CheckPhdr(reinterpret_cast<ElfW(Addr)>(ehdr) + offset);
}
break;
}
}
LOGI("can't find loaded phdr for \"%s\"", name_.c_str());
return false;
} 3.找替身实现数据回填
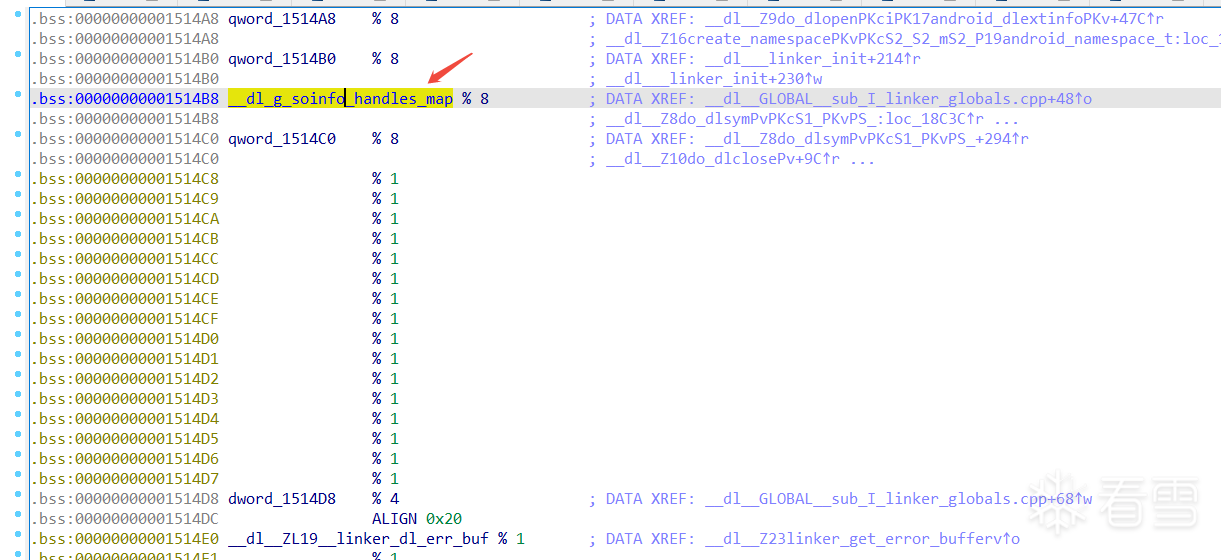
先看下安卓源码dlsym的相关片段代码了解下soinfo (参考链接http://androidxref.com/9.0.0_r3/xref/bionic/linker/linker.cpp#2180
...
std::unordered_map<uintptr_t, soinfo*> g_soinfo_handles_map;
...
static soinfo* soinfo_from_handle(void* handle) {
if ((reinterpret_cast<uintptr_t>(handle) & 1) != 0) {
auto it = g_soinfo_handles_map.find(reinterpret_cast<uintptr_t>(handle));
if (it == g_soinfo_handles_map.end()) {
return nullptr;
} else {
return it->second;
}
}
return static_cast<soinfo*>(handle);
}
...
bool do_dlsym(void* handle,
const char* sym_name,
const char* sym_ver,
const void* caller_addr,
void** symbol) {
ScopedTrace trace("dlsym");
#if !defined(__LP64__)
if (handle == nullptr) {
DL_ERR("dlsym failed: library handle is null");
return false;
}
#endif
soinfo* found = nullptr;
const ElfW(Sym)* sym = nullptr;
soinfo* caller = find_containing_library(caller_addr);
android_namespace_t* ns = get_caller_namespace(caller);
soinfo* si = nullptr;
if (handle != RTLD_DEFAULT && handle != RTLD_NEXT) {
si = soinfo_from_handle(handle);
}
LD_LOG(kLogDlsym,
"dlsym(handle=%p(\"%s\"), sym_name=\"%s\", sym_ver=\"%s\", caller=\"%s\", caller_ns=%s@%p) ...",
handle,
si != nullptr ? si->get_realpath() : "n/a",
sym_name,
sym_ver,
caller == nullptr ? "(null)" : caller->get_realpath(),
ns == nullptr ? "(null)" : ns->get_name(),
ns);
auto failure_guard = android::base::make_scope_guard(
[&]() { LD_LOG(kLogDlsym, "... dlsym failed: %s", linker_get_error_buffer()); });
if (sym_name == nullptr) {
DL_ERR("dlsym failed: symbol name is null");
return false;
}
version_info vi_instance;
version_info* vi = nullptr;
if (sym_ver != nullptr) {
vi_instance.name = sym_ver;
vi_instance.elf_hash = calculate_elf_hash(sym_ver);
vi = &vi_instance;
}
if (handle == RTLD_DEFAULT || handle == RTLD_NEXT) {
sym = dlsym_linear_lookup(ns, sym_name, vi, &found, caller, handle);
} else {
if (si == nullptr) {
DL_ERR("dlsym failed: invalid handle: %p", handle);
return false;
}
sym = dlsym_handle_lookup(si, &found, sym_name, vi);
}
if (sym != nullptr) {
uint32_t bind = ELF_ST_BIND(sym->st_info);
if ((bind == STB_GLOBAL || bind == STB_WEAK) && sym->st_shndx != 0) {
*symbol = reinterpret_cast<void*>(found->resolve_symbol_address(sym));
failure_guard.Disable();
LD_LOG(kLogDlsym,
"... dlsym successful: sym_name=\"%s\", sym_ver=\"%s\", found in=\"%s\", address=%p",
sym_name, sym_ver, found->get_soname(), *symbol);
return true;
}
DL_ERR("symbol \"%s\" found but not global", symbol_display_name(sym_name, sym_ver).c_str());
return false;
}
DL_ERR("undefined symbol: %s", symbol_display_name(sym_name, sym_ver).c_str());
return false;
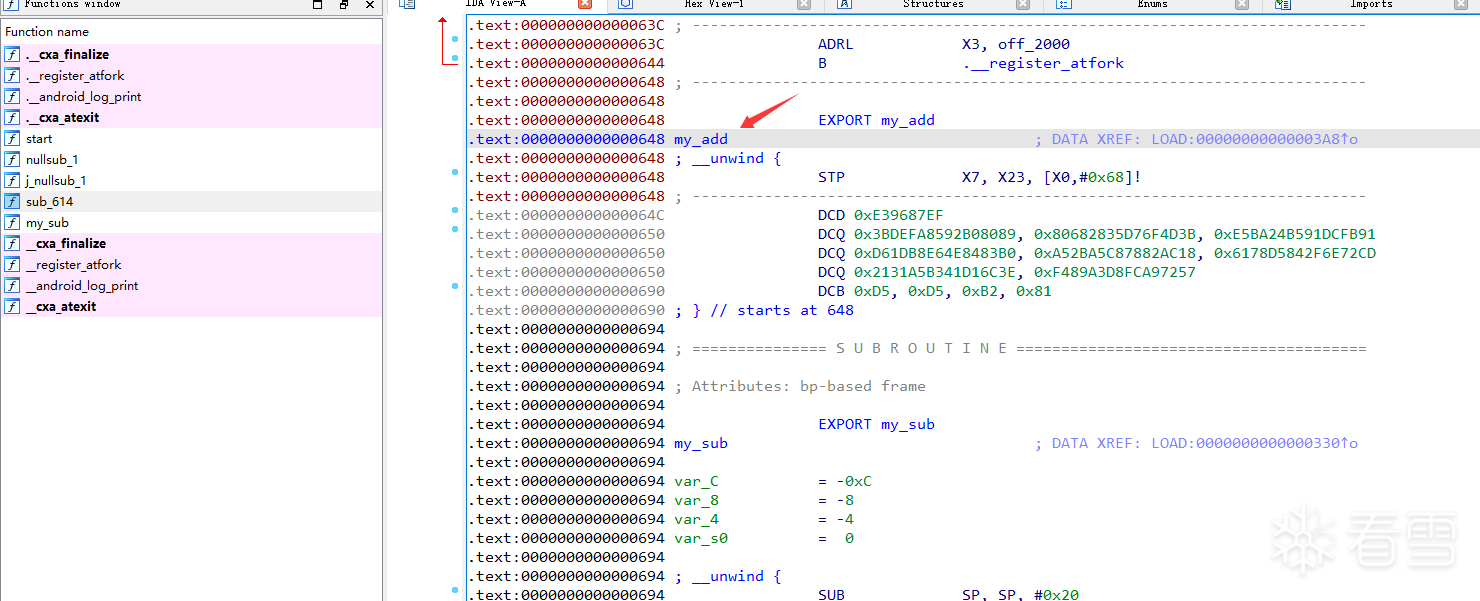
} 传进来的handle是用dlopen打开so后的句柄,要找到函数的地址,必须先用soinfo_from_handle将句柄找到对应的soinfo,因为so在加载链接的时候很多信息都填充在每个so的soinfo里面,所以要定位到函数在内存中的地址必须先找到soinfo,soinfo转换函数中用到了全局变量g_soinfo_handles_map,明显我们可以根据手上机器中linker64的地址偏移进行定位,只需要用dlopen打开一个空壳so,然后用偏移实现soinfo_from_handle,将里面的数据填充成我们自己linker加载的so信息,就能实现借鸡生蛋了
手上机器linker64中g_soinfo_handles_map的偏移地址
相关实现代码
FILE *fp = fopen("/proc/self/maps", "r");
if (!fp) {
LOGI("Failed to open /proc/self/maps");
return;
}
parse_maps_for_lib("linker64", &start, &end);//linker64地址解析
LOGI("linker64 start = 0x%lx end = 0x%lx", start, end);
soinfo_handles_map = reinterpret_cast<std::unordered_map<uintptr_t, soinfo*> *>((char *)start + 0x1514b8);//全局变量偏移计算
LOGI("soinfo_handles_map = 0x%lx", soinfo_handles_map);
void *handle = dlopen(path_fake, RTLD_LAZY);//打开空壳so,创建系统内部的soinfo,获取对应的句柄
if (handle == NULL) {
LOGI("%s dlopen failed: %s\n", path_fake, dlerror());
}
si_ = soinfo_from_handle(soinfo_handles_map, static_cast<std::unordered_map<uintptr_t, soinfo *> *>(handle));
LOGI("sizeof = %d\n", sizeof(struct soinfo));
if (mprotect((void*)PAGE_START(ElfW(Addr)(si_)), sizeof(struct soinfo), PROT_READ | PROT_WRITE) == -1) {
LOGI("mprotect failed");
}
//参照安卓源码,数据回填,偷梁换柱
si_->base = elfreader->load_start();
si_->size = elfreader->load_size();
si_->load_bias = elfreader->load_bias();
si_->phnum = elfreader->phdr_count();
si_->phdr = elfreader->loaded_phdr(); 4.so预链接
bool soinfo::prelink_image() {
/* Extract dynamic section */
ElfW(Word) dynamic_flags = 0;
phdr_table_get_dynamic_section(phdr, phnum, load_bias, &dynamic, &dynamic_flags);
/* We can't log anything until the linker is relocated */
bool relocating_linker = (flags_ & FLAG_LINKER) != 0;
if (!relocating_linker) {
LOGI("si->base = %p si->flags = 0x%08x", reinterpret_cast<void*>(base), flags_);
}
if (dynamic == nullptr) {
if (!relocating_linker) {
LOGI("missing PT_DYNAMIC in \"%s\"", get_realpath());
}
return false;
} else {
if (!relocating_linker) {
LOGI("dynamic = %p", dynamic);
}
}
// Extract useful information from dynamic section.
// Note that: "Except for the DT_NULL element at the end of the array,
// and the relative order of DT_NEEDED elements, entries may appear in any order."
//
// source: e41K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4N6%4N6#2)9J5k6i4y4U0L8#2)9J5k6h3y4G2L8g2)9J5c8X3c8W2N6X3g2D9L8%4m8W2M7Y4y4Q4x3V1k6Y4j5h3u0A6i4K6u0r3x3e0V1&6z5q4)9J5k6o6l9@1i4K6u0V1x3U0W2Q4x3V1k6U0K9o6g2Q4x3X3g2V1P5h3&6S2L8h3W2U0i4K6u0W2K9s2c8E0L8l9`.`.
uint32_t needed_count = 0;
for (ElfW(Dyn)* d = dynamic; d->d_tag != DT_NULL; ++d) {
LOGI("d = %p, d[0](tag) = %p d[1](val) = %p",
d, reinterpret_cast<void*>(d->d_tag), reinterpret_cast<void*>(d->d_un.d_val));
switch (d->d_tag) {
case DT_SONAME://so名称在字符串表偏移
// this is parsed after we have strtab initialized (see below).
break;
case DT_HASH://hash表信息,查找函数定位使用,android5.0以前使用
nbucket_ = reinterpret_cast<uint32_t*>(load_bias + d->d_un.d_ptr)[0];
nchain_ = reinterpret_cast<uint32_t*>(load_bias + d->d_un.d_ptr)[1];
bucket_ = reinterpret_cast<uint32_t*>(load_bias + d->d_un.d_ptr + 8);
chain_ = reinterpret_cast<uint32_t*>(load_bias + d->d_un.d_ptr + 8 + nbucket_ * 4);
break;
case DT_GNU_HASH://gnu hash表信息,查找函数定位使用
gnu_nbucket_ = reinterpret_cast<uint32_t*>(load_bias + d->d_un.d_ptr)[0];
// skip symndx
gnu_maskwords_ = reinterpret_cast<uint32_t*>(load_bias + d->d_un.d_ptr)[2];
gnu_shift2_ = reinterpret_cast<uint32_t*>(load_bias + d->d_un.d_ptr)[3];
gnu_bloom_filter_ = reinterpret_cast<ElfW(Addr)*>(load_bias + d->d_un.d_ptr + 16);
gnu_bucket_ = reinterpret_cast<uint32_t*>(gnu_bloom_filter_ + gnu_maskwords_);
// amend chain for symndx = header[1]
gnu_chain_ = gnu_bucket_ + gnu_nbucket_ -
reinterpret_cast<uint32_t*>(load_bias + d->d_un.d_ptr)[1];
break;
case DT_STRTAB://符号字符串表
strtab_ = reinterpret_cast<const char*>(load_bias + d->d_un.d_ptr);
break;
case DT_STRSZ://符号字符串表大小
strtab_size_ = d->d_un.d_val;
break;
case DT_SYMTAB://动态符号表
symtab_ = reinterpret_cast<ElfW(Sym)*>(load_bias + d->d_un.d_ptr);
break;
case DT_SYMENT://动态符号表大小
if (d->d_un.d_val != sizeof(ElfW(Sym))) {
LOGI("invalid DT_SYMENT: %zd in \"%s\"",
static_cast<size_t>(d->d_un.d_val));
return false;
}
break;
case DT_PLTREL://PLT重定位的类型
if (d->d_un.d_val != DT_RELA) {
LOGI("unsupported DT_PLTREL in \"%s\"; expected DT_RELA");
return false;
}
break;
case DT_JMPREL://与PLT相关重定位表地址
plt_rela_ = reinterpret_cast<ElfW(Rela)*>(load_bias + d->d_un.d_ptr);
break;
case DT_PLTRELSZ://与PLT相关重定位表大小
plt_rela_count_ = d->d_un.d_val / sizeof(ElfW(Rela));
break;
case DT_PLTGOT://与PLT相关的GOT地址
break;
case DT_RELA://RELA重定位表地址(包含显示添加数)
rela_ = reinterpret_cast<ElfW(Rela)*>(load_bias + d->d_un.d_ptr);
break;
case DT_RELASZ://RELA重定位表大小
rela_count_ = d->d_un.d_val / sizeof(ElfW(Rela));
break;
case DT_RELAENT://RELA重定位表条目大小
if (d->d_un.d_val != sizeof(ElfW(Rela))) {
LOGI("invalid DT_RELAENT: %zd", static_cast<size_t>(d->d_un.d_val));
return false;
}
break;
// Ignored (see DT_RELCOUNT comments for details).
case DT_RELACOUNT://RELA重定位表条目数量
break;
case DT_REL://RELA重定位表地址(不包含显示添加数)
LOGI("unsupported DT_REL in \"%s\"", get_realpath());
return false;
case DT_RELSZ://RELA重定位表大小
LOGI("unsupported DT_RELSZ in \"%s\"", get_realpath());
return false;
case DT_RELR://RELA重定位表地址
relr_ = reinterpret_cast<ElfW(Relr)*>(load_bias + d->d_un.d_ptr);
break;
case DT_RELRSZ://RELR重定位表大小
relr_count_ = d->d_un.d_val / sizeof(ElfW(Relr));
break;
case DT_RELRENT://RELR重定位表条目大小
if (d->d_un.d_val != sizeof(ElfW(Relr))) {
LOGI("invalid DT_RELRENT: %zd", static_cast<size_t>(d->d_un.d_val));
return false;
}
break;
// Ignored (see DT_RELCOUNT comments for details).
case DT_RELRCOUNT://RELR重定位表条目数目
break;
case DT_INIT://初始化函数地址
init_func_ = reinterpret_cast<linker_ctor_function_t>(load_bias + d->d_un.d_ptr);
LOGI("%s constructors (DT_INIT) found at %p", get_realpath(), init_func_);
break;
case DT_FINI://终止函数地址
fini_func_ = reinterpret_cast<linker_dtor_function_t>(load_bias + d->d_un.d_ptr);
LOGI("%s destructors (DT_FINI) found at %p", get_realpath(), fini_func_);
break;
case DT_INIT_ARRAY://初始化函数数组的指针
init_array_ = reinterpret_cast<linker_ctor_function_t*>(load_bias + d->d_un.d_ptr);
LOGI("%s constructors (DT_INIT_ARRAY) found at %p", get_realpath(), init_array_);
break;
case DT_INIT_ARRAYSZ://初始化函数数组指针数组大小
init_array_count_ = static_cast<uint32_t>(d->d_un.d_val) / sizeof(ElfW(Addr));
break;
case DT_FINI_ARRAY://终止函数数组的指针
fini_array_ = reinterpret_cast<linker_dtor_function_t*>(load_bias + d->d_un.d_ptr);
LOGI("%s destructors (DT_FINI_ARRAY) found at %p", get_realpath(), fini_array_);
break;
case DT_FINI_ARRAYSZ://终止函数数组指针数组大小
fini_array_count_ = static_cast<uint32_t>(d->d_un.d_val) / sizeof(ElfW(Addr));
break;
case DT_PREINIT_ARRAY://预初始化函数数组的指针
preinit_array_ = reinterpret_cast<linker_ctor_function_t*>(load_bias + d->d_un.d_ptr);
LOGI("%s constructors (DT_PREINIT_ARRAY) found at %p", get_realpath(), preinit_array_);
break;
case DT_PREINIT_ARRAYSZ://预初始化函数数组指针数组大小
preinit_array_count_ = static_cast<uint32_t>(d->d_un.d_val) / sizeof(ElfW(Addr));
break;
case DT_SYMBOLIC://是否优先查找库自身的符号表
has_DT_SYMBOLIC = true;
break;
case DT_NEEDED://动态链接库
g_need_array[needed_count] = d->d_un.d_val;
++needed_count;
break;
case DT_FLAGS://标志位
if (d->d_un.d_val & DF_TEXTREL) {
LOGI("\"%s\" has text relocations", get_realpath());
return false;
}
if (d->d_un.d_val & DF_SYMBOLIC) {
has_DT_SYMBOLIC = true;
}
break;
case DT_BIND_NOW://在执行前处理所有重定位
break;
case DT_VERSYM://.gnu.version节的地址
versym_ = reinterpret_cast<ElfW(Versym)*>(load_bias + d->d_un.d_ptr);
break;
case DT_VERDEF://版本定义表地址
verdef_ptr_ = load_bias + d->d_un.d_ptr;
break;
case DT_VERDEFNUM://版本定义表数目
verdef_cnt_ = d->d_un.d_val;
break;
case DT_VERNEED://版本依赖表地址
verneed_ptr_ = load_bias + d->d_un.d_ptr;
break;
case DT_VERNEEDNUM://版本依赖表数目
verneed_cnt_ = d->d_un.d_val;
break;
case DT_RUNPATH://动态链接器搜索动态库时的运行时路径
// this is parsed after we have strtab initialized (see below).
break;
default:
break;
}
}
LOGI("si->base = %p, si->strtab = %p, si->symtab = %p",
reinterpret_cast<void*>(base), strtab_, symtab_);
// Sanity checks.
if (relocating_linker && needed_count != 0) {
LOGI("linker cannot have DT_NEEDED dependencies on other libraries");
return false;
}
if (nbucket_ == 0 && gnu_nbucket_ == 0) {
LOGI("empty/missing DT_HASH/DT_GNU_HASH in \"%s\" "
"(new hash type from the future?)", get_realpath());
return false;
}
if (strtab_ == 0) {
LOGI("empty/missing DT_STRTAB in \"%s\"", get_realpath());
return false;
}
if (symtab_ == 0) {
LOGI("empty/missing DT_SYMTAB in \"%s\"", get_realpath());
return false;
}
g_need_count = needed_count;
return true;
} 5.so链接
bool soinfo::link_image(void) {
if (rela_ != nullptr) {
LOGI("[ relocating %s rela ]", get_realpath());
if (!relocate(plain_reloc_iterator(rela_, rela_count_))) {
return false;
}
}
if (plt_rela_ != nullptr) {
LOGI("[ relocating %s plt rela ]", get_realpath());
if (!relocate(plain_reloc_iterator(plt_rela_, plt_rela_count_))) {
return false;
}
}
return true;
} 接着看下relocate函数,源码比较多,裁剪了很多,只剩下些可能需要的
template<typename ElfRelIteratorT>
bool soinfo::relocate(ElfRelIteratorT&& rel_iterator) {
for (size_t idx = 0; rel_iterator.has_next(); ++idx) {
const auto rel = rel_iterator.next();
if (rel == nullptr) {
return false;
}
ElfW(Word) type = ELFW(R_TYPE)(rel->r_info);
ElfW(Word) sym = ELFW(R_SYM)(rel->r_info);
ElfW(Addr) reloc = static_cast<ElfW(Addr)>(rel->r_offset + load_bias);
ElfW(Addr) sym_addr = 0;
const char *sym_name = nullptr;
sym_name = reinterpret_cast<const char *>(strtab_+symtab_[sym].st_name);
LOGI("sym_name = %s", sym_name);
for (int i = 0 ; i < g_need_count; i++) {
void *handle = dlopen(strtab_ + g_need_array[i], RTLD_LAZY);
if (handle == NULL) {
LOGI("%s dlopen failed: %s\n", strtab_ + g_need_array[i], dlerror());
}
sym_addr= reinterpret_cast<Elf64_Addr>(dlsym(handle, sym_name));
if (sym_addr == 0) {
dlclose(handle);
continue;
} else {
LOGI("found %s %ld", sym_name, sym_addr);
break;
}
}
switch (type) {
case R_GENERIC_JUMP_SLOT:
LOGI("R_GENERIC_JUMP_SLOT");
*reinterpret_cast<ElfW(Addr)*>(reloc) = sym_addr;
break;
case R_GENERIC_GLOB_DAT:
LOGI("R_GENERIC_GLOB_DAT");
*reinterpret_cast<ElfW(Addr)*>(reloc) = sym_addr;
break;
case R_GENERIC_RELATIVE:
LOGI("R_GENERIC_RELATIVE");
*reinterpret_cast<ElfW(Addr)*>(reloc) = sym_addr;
break;
}
}
return true;
} relocate函数的实现就没有直接进行移植了,因为移植工作量还不小,所以当时应该是参考了网上的做法,用dlopen和dlsym去遍历依赖库直接取出函数地址来进行填充
6.解密调用流程
FUNC func = reinterpret_cast<FUNC>(dlsym(handle, "my_add"));
//修改内存读写权限
if (mprotect((void*)PAGE_START(ElfW(Addr)(func)), PAGE_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC) == -1) {
LOGI("mprotect failed");
}
//解密覆盖
rc4_init(&ctx, (unsigned char *) RC4_KEY, strlen(reinterpret_cast<const char *>(RC4_KEY)));
rc4_run(&ctx, reinterpret_cast<unsigned char *>(buf), reinterpret_cast<unsigned char *>(func), FUNC_SIZE);
memcpy((void*)func, buf, FUNC_SIZE);
//权限还原
if (mprotect((void*)PAGE_START(ElfW(Addr)(func)), PAGE_SIZE, PROT_READ | PROT_EXEC) == -1) {
LOGI("mprotect failed");
}
//调用库函数
int ret = func(1, 2);
LOGI("loadso add result = %d", ret);
//修改内存读写权限
if (mprotect((void*)PAGE_START(ElfW(Addr)(func)), PAGE_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC) == -1) {
LOGI("mprotect failed");
}
//加密还原覆盖
rc4_init(&ctx, (unsigned char *) RC4_KEY, strlen(reinterpret_cast<const char *>(RC4_KEY)));
rc4_run(&ctx, reinterpret_cast<unsigned char *>(buf), reinterpret_cast<unsigned char *>(func), FUNC_SIZE);
memcpy((void*)func, buf, FUNC_SIZE);
//加密还原覆盖
if (mprotect((void*)PAGE_START(ElfW(Addr)(func)), PAGE_SIZE, PROT_READ | PROT_EXEC) == -1) {
LOGI("mprotect failed");
}
fclose(fp); 解密函数调用流程基本跟方式一差不多,主要是多了链接过程中对程序头的异或处理,因为我这边只是一个demo并没有做太多处理,其实用自己实现的linker流程可以加载自己加密处理的任意so格式,只要解密回填soinfo能正常对的上就行。
正常运行日志
方式一加解密方式相对于来说较容易实现一些,但是对so的加密也仅限与dlsym获取出来的函数执行地址段来进行处理,当然在函数解密后dump能成功避过解密流程,但是如果对多个函数进行加密,分时调用,还是能产生不少干扰的。方式二的加密方式实现相对而言要麻烦一些,但是可以自己定义so的函数格式进行加载,只要保证加载填充的soinfo位置不出错就行。
7ceK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6B7N6h3g2B7K9h3&6Q4x3X3g2U0L8W2)9J5c8Y4m8G2M7%4c8Q4x3V1j5%4x3U0V1&6y4U0j5%4x3U0f1&6z5e0l9J5x3U0j5K6x3K6l9$3
fbbK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6T1L8r3!0Y4i4K6u0W2j5%4y4V1L8W2)9J5k6h3&6W2N6q4)9J5c8W2y4j5h3q4W2z5d9p5S2j5h3q4)9J5c8X3q4J5N6r3W2U0L8r3g2Q4x3V1k6V1k6i4c8S2K9h3I4K6i4K6u0r3x3e0b7K6x3K6p5$3z5e0x3&6
c10K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2U0L8X3u0D9L8$3N6K6i4K6u0W2j5$3!0E0i4K6u0r3M7U0m8&6M7%4g2W2i4K6u0r3M7q4)9J5c8U0p5#2x3K6x3I4y4U0t1I4i4K6u0W2K9s2c8E0L8l9`.`.
3c8K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6H3j5h3&6Q4x3X3g2I4N6h3q4J5K9#2)9J5k6h3y4F1i4K6u0r3M7#2)9J5c8X3b7J5y4X3b7^5z5e0t1@1j5e0t1H3k6l9`.`.
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2025-2-20 18:26
被HandsomeBro编辑
,原因: