能力值:
 ( LV3,RANK:20 )
( LV3,RANK:20 )
|
-
-
2 楼
感谢分享
|
能力值:
 ( LV1,RANK:0 )
( LV1,RANK:0 )
|
-
-
3 楼
感谢分享,向大佬学习
|
能力值:
( LV7,RANK:102 )
|
-
-
4 楼
这种方式效果有限,遇到复杂的就处理不鸟了
|

能力值:
( LV3,RANK:20 )
|
-
-
5 楼
fjqisba
这种方式效果有限,遇到复杂的就处理不鸟了
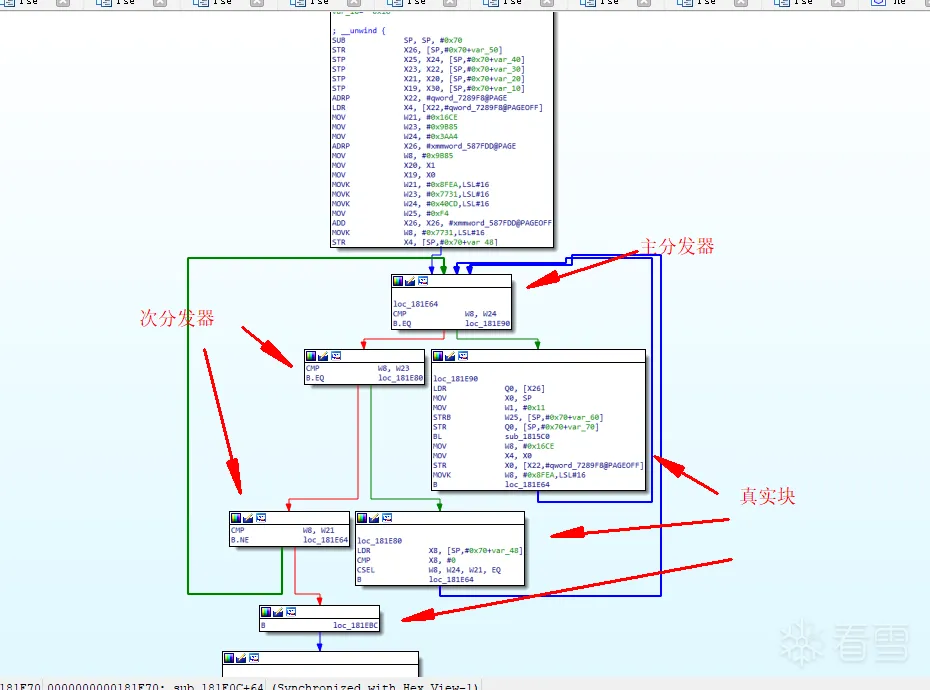
恰恰相反,我写这个的目的就是处理复杂情况,无论是何种情况下 块和块的链接只有2个结果 真实块或者分发块。满足条件即可遍历出结果
|
能力值:
( LV1,RANK:0 )
|
-
-
6 楼
fjqisba
这种方式效果有限,遇到复杂的就处理不鸟了
大佬为啥arm的vmp没有ida插件呢,可否引用你的vm3.5插件呢
|

能力值:
 ( LV12,RANK:280 )
( LV12,RANK:280 )
|
-
-
7 楼
谢谢分享
|
能力值:
( LV1,RANK:0 )
|
-
-
8 楼
IIImmmyyy
恰恰相反,我写这个的目的就是处理复杂情况,无论是何种情况下 块和块的链接只有2个结果 真实块或者分发块。满足条件即可遍历出结果
请问大佬,arm32 thumb适用吗
|

能力值:
 ( LV13,RANK:929 )
( LV13,RANK:929 )
|
-
-
9 楼
IIImmmyyy
恰恰相反,我写这个的目的就是处理复杂情况,无论是何种情况下 块和块的链接只有2个结果 真实块或者分发块。满足条件即可遍历出结果
可曾遇到共用块
|
能力值:
( LV3,RANK:20 )
|
-
-
10 楼
mb_ldbucrik
请问大佬,arm32 thumb适用吗
不适用 暂未有arm32 和x86的支持计划。 如果要做多架构的话 需要抽出一个中间语言作为桥接。 我闲麻烦没有做了
|
能力值:
( LV3,RANK:20 )
|
-
-
11 楼
大帅锅
可曾遇到共用块
for循环就是标准的共用块情况。 查找过程中会对正在查找的block进行标记,如果递归发现是已经正在查找的则返回,同时链接已经存在的block。此处理就可完成for循环的处理 ``` if (block.isFind)
{
Logger.WarnNewline("block is Finding " + block.start_address);
return block.RealChilds;
} ```
最后于 2024-12-20 14:28
被IIImmmyyy编辑
,原因:
|
能力值:
( LV1,RANK:0 )
|
-
-
12 楼
IIImmmyyy
不适用 暂未有arm32 和x86的支持计划。 如果要做多架构的话 需要抽出一个中间语言作为桥接。 我闲麻烦没有做了
好的,retdec优化貌似支持所有的架构
|
能力值:
( LV3,RANK:20 )
|
-
-
13 楼
mb_ldbucrik
好的,retdec优化貌似支持所有的架构
其实这个也支持,也不难。 你可以仿造arm64的写法进行逻辑的剥离。 代码量很少 并不多的。不想支持的原因主要还是目前工作中需要单独去分析arm32 的情况实在是太少了。 arm64已经是主流了
|

能力值:
( LV3,RANK:30 )
|
-
-
14 楼
可以滴
|

能力值:
( LV2,RANK:10 )
|
-
-
15 楼
先拿 tersafe 练练手
|
能力值:
( LV1,RANK:0 )
|
-
-
16 楼
读取 else 分支的时候,仅读取 else 分支下一个 block,还是会继续读取完整个 else 分支继续下去的情况呢?粗看你的实现是会继续读取的,能把所有可能的节点都走过去,和我之前的处理反混淆的时候差不多,我的之前也基本是可用状态,当时碰到过一些问题,目前也没想到好办法,不知道你有没有碰到
1. 因为会按照非常规进入的某段逻辑,所以有时可能会出现错误,导致未遍历完整
2. 要遍历很多,所以速度比较慢
另外一个想讨论的是公共块的问题(上面也有人提出来,不知道和我说的是不是一样),我碰到的公共块问题是,复杂情况下,真实区域中也是好几个块组成的,所以我叫真实区域,没说真实块,然后真实区域之间还会存在块是共用的,即公共块,部分公共块还是真实区域中的出口位置,可能这个块出去有四五个后继区域,这种情况下,我是将 patch 指令复制到了原本的分发器所在位置上,好像并没有看到你有这样分配的情况,不知道你是怎么处理的
|
能力值:
( LV3,RANK:20 )
|
-
-
17 楼
首先关于 1. 因为会按照非常规进入的某段逻辑,所以有时可能会出现错误,导致未遍历完整
2. 要遍历很多,所以速度比较慢 这个我并没有办法回答你,可能是因为样本的原因。我目前没有碰到。 我的设计理念是块只有2种情况,真实块或者分发块。 真实块无论是以什么样的形式存在 只要不是分发器它都是真实块。 当然这种就需要特殊处理真实块,比如情况 ```loc_17F750 STR XZR, [SP,#0xF0+var_C8] ``` 这个也是公共块 它的后继块 要么是分发器 要么是真实块。甚至他的后继块可能是它自己。 但是无论如何是什么块,都会进入循环进行标记。我的设计理念就是找到所有的分支。排除分发器。 另外一个问题关于patch指令的 不知道我理解的对不对 我附上一个情况 ```
//loc_15E604
// LDR X9, [SP,#0x2D0+var_2B0]
// ADRP X8, #qword_7289B8@PAGE
// LDR X8, [X8,#qword_7289B8@PAGEOFF]
// STR X9, [SP,#0x2D0+var_260]
// LDR X9, [SP,#0x2D0+var_2A8]
// STR X8, [SP,#0x2D0+var_238]
// MOV W8, #0x561D9EF8
// STP X19, X9, [SP,#0x2D0+var_270]
// loc_15E628
// CMP W8, W23
// B.GT loc_15E6C0 ```
loc_15e628 是在下一个连接块中。 此时对15e604进行patch修复的 我选择删除掉MOV W8 这个分发指令 然后调整STP X19 X9 的位置 让跳转指令下沉。这样分发块就可以正常的NOP掉。 如果没有MOV 指令, 其实这个块就不是分发块 也不需要进行NOP 修复 因为下个连接块大概率是一个中转指令 就一个 B locXXXX 这个可能连接到分发块 也有可能是真实块。 但是不重要 因为块与块之间是单独修复的 只要管好自己就行。 Patch 的原则就是不要动到真实块的位置。可以删减 但是不能对原块的指令进行扩充。 因为扩充在复杂的情况下我觉的会有分支错误的问题
最后于 2024-12-20 18:37
被IIImmmyyy编辑
,原因:
|
能力值:
( LV1,RANK:0 )
|
-
-
18 楼
IIImmmyyy
其实这个也支持,也不难。 你可以仿造arm64的写法进行逻辑的剥离。 代码量很少 并不多的。不想支持的原因主要还是目前工作中需要单独去分析arm32 的情况实在是太少了。 arm64已经是主流了
好的,试着搞搞
|
能力值:
( LV2,RANK:10 )
|
-
-
19 楼
打开安卓app一看,主流是arm64
|
能力值:
( LV1,RANK:0 )
|
-
-
20 楼
很好的帖子 如果所依赖的寄存器值是动态获取的 ida的静态分析就没用了 就需要动态修复了
|
能力值:
( LV1,RANK:0 )
|
-
-
21 楼
感谢开源,尝试了一下发现报错,缺少MUL | CSET等指令识别。FormatOpCode这个函数(InstructionsExtension.cs .line 119)需要补齐这几个吗
最后于 2024-12-23 11:14
被mb_hsxnkqcc编辑
,原因:
|
能力值:
( LV3,RANK:20 )
|
-
-
22 楼
mb_hsxnkqcc
感谢开源,尝试了一下发现报错,缺少MUL | CSET等指令识别。FormatOpCode这个函数(InstructionsExtension.cs .line 1 ...
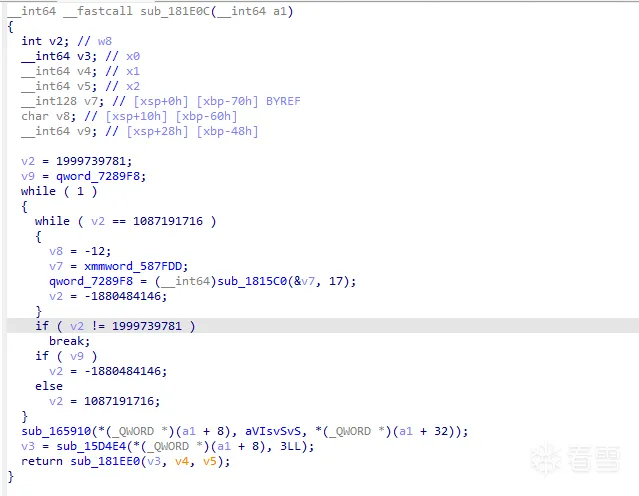
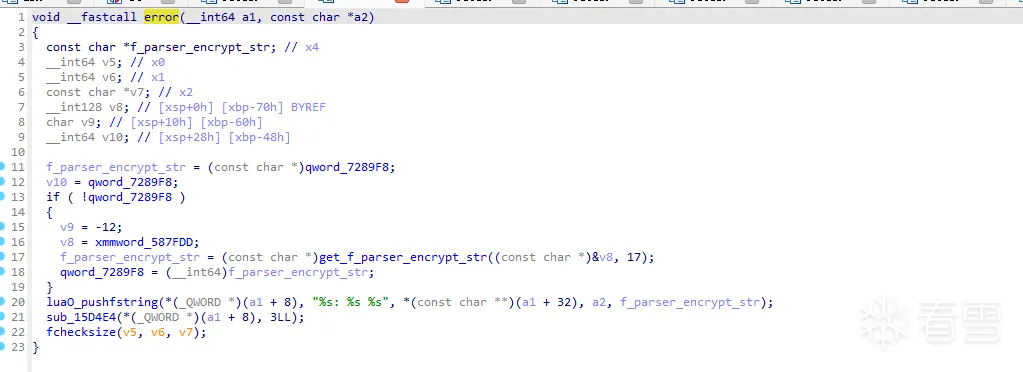
这个是在修复过程中对指令的兼容度不够大。 在runtime的过程中 对其他指令并不敏感 补上对应的OpCode即可。 主要是需要识别CSEL, MOV,MOVK,CMP指令作为runtime的特征运行
最后于 2024-12-23 11:31
被IIImmmyyy编辑
,原因:
|
能力值:
( LV13,RANK:929 )
|
-
-
23 楼
mb_ldbucrik
好的,试着搞搞
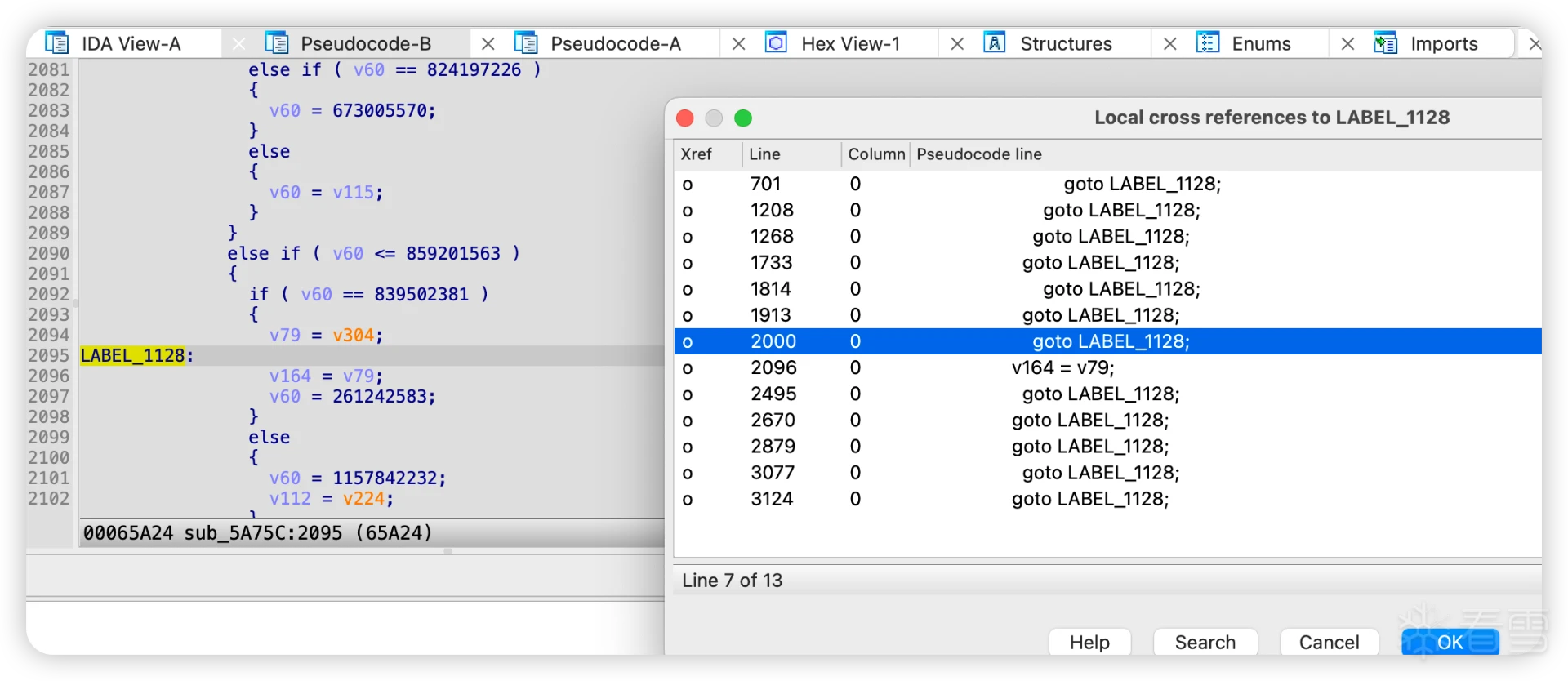
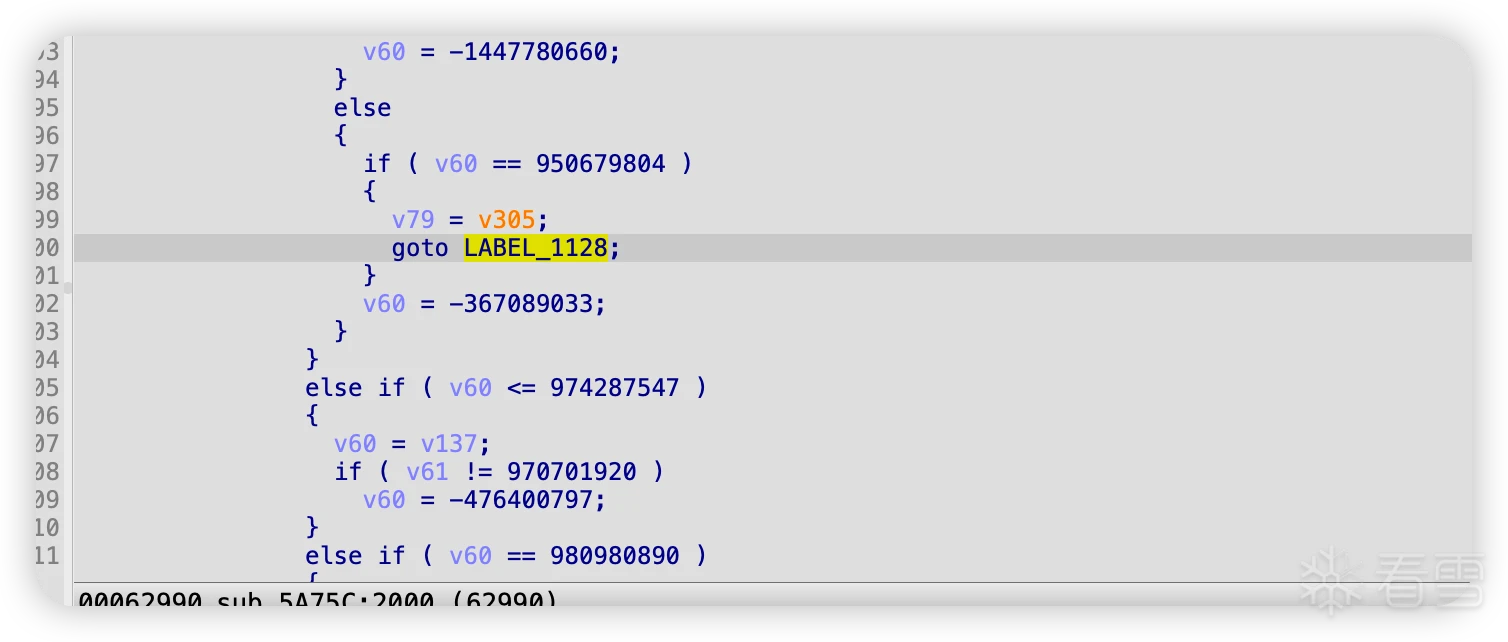
稍微大点的函数都会遇到这个问题,这是因为,编译器优化导致的,很多真实块会跳转到同一个地方,然后再跳转到分发器
|
能力值:
( LV13,RANK:929 )
|
-
-
24 楼
IIImmmyyy
首先关于1. 因为会按照非常规进入的某段逻辑,所以有时可能会出现错误,导致未遍历完整2. 要遍历很多,所以速度比较慢 这个我并没有办法回答你,可能 ...
这个东西可不好patch
|
能力值:
( LV3,RANK:20 )
|
-
-
25 楼
大帅锅
稍微大点的函数都会遇到这个问题,这是因为,编译器优化导致的,很多真实块会跳转到同一个地方,然后再跳转到分发器
这应该是一个函数内包含多个不同的操作分发器引起的 比如CMP W10,W28,这个是主分发器, 然后分支下出现了CMP W8,W30 这种情况导致次的主分发器被认定成了真实块。 不知是否能附上样本?
|
|
|
|