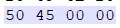“基础不牢,地动山摇。”我们先讲讲算法基础中比较重要的base64和hex,这两种编码不管是哪种算法几乎都需要用到它。
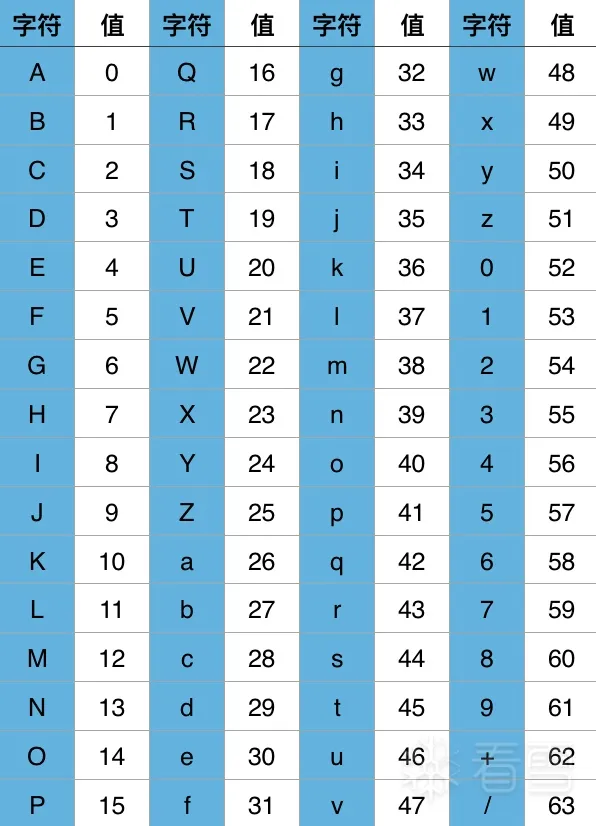
众所周知,在计算机中, 1个字节等于8个二进制位,而base64可以简单理解为就是使用6个二进制位表示1个字节,而六个二进制位的范围为000000~111111,换算成十进制就是0到63,所以 base64 编码会有64个基础字符。base64编码如下图所示:
base64编码是使用6个二进制位表示一字节的,所以上图中的字符就是6个二进制位转换成的10进制对应base64编码所得到的字符。
现在我们对base64稍稍有了点了解,那base64是如何编码和解码的呢?先说结论,编码后源数据会以三个字节为一组转化为4个字符表示,如果源数据字节数量不为三的倍数,那解决这个问题需要补充字节,补充到其二进制位可以整除6的时候。
原因或许有些观察敏锐的同学已经发现了,产生如此情况的原因就是两者之间一个字节所表示的二进制位。一个8个二进制位才表示1字节,一个6个二进制位就表示1字节,假设有三个字符'abc',总共表示3*8=24个二进制位,编码过后,每6个二进制位表示1个字节,24/6=4,可以看到源数据以三个字节为一组转化为4个字符表示,这与结论相符。光说理论也不行,我们来模拟一下编码的过程:
我们要对字符'abc'进行编码,首先我们要得到 'abc' 对应的二进制位,而 'abc' 对应的二进制位我们已经得到了;
其次就是按从左到右的顺序读取6个二进制位并将读到的每组二进制数据转为10进制表示,最后对照base64编码表得到每组二进制对应的字符,如下所示:
从转换结果可以看出 'abc' 用base64编码表示时是 YWJj。这个很简单吧!但不要忽略一个问题,那就是如果要编码的字符不是3的倍数呢?就比如'abcd'这四个字符,4*8=32个二进制位,而32是不能整除6的。那解决这个问题需要补充字节,补充到其二进制位可以整除6的时候。如下所示:
我们可以发现到后面只有2个二进制位可读取了,,不足6位,那我们就需要补字节,因为在非base64编码的情况下,一个字节等于8个二进制位,所以补了一个字节后可以发现变成了四个二进制位可读取了,还是不足6位,所以还要补字节,最终在补了俩个字节的情况下终于把所有的二进制位读完了,这里我们一共添加了两个补充字节(上方表格中二进制位数据被括号括起来的就是这两个补充字节的二进制位)。我们最终得到的结果是: YWJjhAAA,但是如果去用工具验证下结果就会发现我们得到的这个结果和工具得到的结果不符,那这是为什么呢?
其实这是因为我们编码过程中加了两个补充字节,而当需要解码的时候,解码的一方根本不知道最后两个字节是补充字节, 会将7个字节当成原始数据处理,这样解码得到的结果就和我们的源数据大相径庭了。这样不就出问题了,所以我们必须同时要告诉对方我们加了几个补充字节,那怎么告诉呢?其实可以发现完全由补充字节的二进制位组成的字节一定是A,也就是说加一个补充字节, 正常base64编码的最后一个字符一定是A,加两个补充字节, 正常base64编码的最后两个字符一定是A。但是解码的时候并不能凭最后的字符是A就确定是补充字节,因为一个正常字符编码的结尾也可以是A 或者AA的情况,那这就要牵扯到base64的第65个字符了,这个字符就是"=",这是一个特殊字符,该字符的作用就是用来告知对方添加了多少个补充字节的。
所以我们将完全由补充字节的二进制位组成的字节的原本值A替换为=,这样就告知对方我们添加了两个补充字节,最后得到结果是:YWJjhA==,而这个结果和用在线工具进行编码的结果如出一辙。
现在我们明白了base64编码的过程,其实base64解码的过程就是把编码的过程给倒过来,解码过程如下:
还记得开始说的结论:编码后源数据会以三个字节为一组转化为4个字符表示,如果源数据字节数量不为三的倍数,那解决这个问题需要补充字节,补充到其二进制位可以整除6的时候。如果理解了上面整个过程,那么就对base64有了一定的了解了。
这里多提一句,在URL中使用base64会产生冲突,例如 = 在URL中用来对参数名和参数值进行分割,那么为了安全就出现了一种名为URL base64的算法,该算法会将 + 替换成 - ,将 / 替换成 _ ,而 = 有时候会用 ~ 或者 . 代替。为什么 = 是有时候替换呢?这是因为URL base64编码也有好多种,有些编码不会去掉等号,有些编码替换的符号不同。
base64是以6个二进制位来表示一个字符, 那么hex是什么呢?其实hex也称为base16,意思是以4个二进制位表示一个字符。这个是不是很熟悉,是不是感觉hex和十六进制十分相似?这两者不能说一模一样,只能说毫无差别,hex编码就是将原始字符用16进制表示。所以hex具体的编码与解码过程我就不细说了,毕竟十六进制大部分学计算机的都还是懂的。
与这两者相似的还有base32,base32是以5个二进制位来表示一个字符,一共使用32个可见字符来表示一个二进制数组,编码后源数据会以五个字节为一组转化为8个字符表示,如果源数据字节数量不为五的倍数,那解决这个问题需要补充字节,补充到其二进制位可以整除5的时候。
什么是消息摘要算法?百度百科是这样解释的:
消息摘要算法的主要特征是加密过程不需要密钥,并且经过加密的数据无法被解密,可以被解密逆向的只有CRC32算法,只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的密文。
一般地,把对一个信息的摘要称为该消息的指纹或数字签名。数字签名是保证信息的完整性和不可否认性的方法。数据的完整性是指信宿接收到的消息一定是信源发送的信息,而中间绝无任何更改;信息的不可否认性是指信源不能否认曾经发送过的信息。其实,通过数字签名还能实现对信源的身份识别(认证),即确定“信源”是否是信宿意定的通信伙伴。 数字签名应该具有唯一性,即不同的消息的签名是不一样的;同时还应具有不可伪造性,即不可能找到另一个消息,使其签名与已有的消息的签名一样;还应具有不可逆性,即无法根据签名还原被签名的消息的任何信息。这些特征恰恰都是消息摘要算法的特征,所以消息摘要算法适合作为数字签名算法。
其实我们在讲apk文件结构的时候讲过什么是数字摘要、什么是数字签名、什么是对称加密、什么是非对称加密、什么是数字证书。这里我们主要讲消息摘要算法。
要讲消息摘要算法就不得不提MD5消息摘要算法了,MD5(Message Digest Algorithm 5)翻译成中文就是消息摘要算法第五版,这是一种应用十分广泛的消息摘要算法。在生活中如果官方网站下载软件实在太慢,你等的不耐烦,就去寻找第三方下载渠道,这个时候该如何判断第三方渠道的软件和官方下载的软件是否相同呢?是否被植入病毒呢?这可以用MD5做到判断两者是否相似,官方渠道一般会提供下载文件的MD5值,我们只需要检查第三方软件的MD5值与官方提供的MD5值是否一致便可。如果有一点开发经验的朋友们可能知道,用户输入的账号密码保存到数据库中都是将经过消息摘要算法处理过后的内容保存到数据库里,这样可以避免内部人员获知用户的账号和密码。
MD5是一种典型的散列函数,也可以叫做哈希函数,MD5可以将任意消息内容变成长度固定为128位的散列值,也就是128个二进制位。
MD5处理同一个消息结果始终相同,不同的消息得到的结果截然不同。
听我这么一介绍是不是觉得MD5十分安全,其实不然,MD5已经被证明不再安全,而且关键性的工作还是来自我国的学者——王小云院士。虽然MD5已被证明不再安全,但是MD5直到今天也未被彻底抛弃,而是处于一种死而不僵的状态。想要明白为何会如此,还需了解MD5的原理才能明白。
MD5算法将任意消息内容变成长度固定为128位的散列值的过程可以分为三步:填充对齐、分块、多轮压缩。
第一步、填充对齐
说到底计算机中的内容就是由二进制的0和1组成的,我们需要对这些二进制数据进行补齐操作,需要将数据填充到64字节(512bit)的倍数,不仅如此在补齐的数据中最后8字节(64bit)固定用来表示原始数据的大小,使用小端序的格式进行存储。
什么是小端序呢?其实很简单,小端序就是把数据左边的字节存放到内存当中的右边,我们来看个例子:
这是PE文件头中的PE签名,按照我们正常从左到右观看是不是以为这里存储的值为“50450000”,实则不然,这里是小端序的格式进行存储的,所以正确的值为“00004550”。
现在明白了什么是小端序,那么源数据和数据中最后8字节之间会被填充为什么呢?中间剩下的字节第一个填0x80,剩下的全部填0x0。换句话也可以表达为源数据和数据中最后64个二进制位之间除了第一个二进制位填充1,剩下的二进制位全部都填充0。现在就完成了填充补齐,接下来我们模拟一下填充补齐的过程。我们有一个65字节的数据,首先该数据不符合64字节的倍数,所以要填充补齐,填充后我们得到了128字节的数据,其中65字节为我们的源数据,还有最后8字节固定用来表示原始数据的大小,中间还剩下55字节,这55字节除了第一个字节填充0x80之外,其余的字节全部填充0x0,这样我们就得到了填充补齐后的数据。
我们填充补齐数据后,那就进行第二步分块,因为我们已经将数据补齐为64字节(512bit)的倍数,所以我们就可以把数据分为若干个64字节(512bit)的数据块。就比如我们前面填充补齐得到的128字节的数据,经过分块后就得到了两大块。
现在完成了分块操作,之前讲过MD5最终的输出结果是一个长度固定为128位的散列值,这128位长度最开始被分为了四个部分,每个部分占大小32位。而这四个部分初始化了四个数据,这四个数据均为8个16进制数据组成,每个16进制数据为4bit,这四个初始数据是固定的,不管你输入任意数据给MD5处理这四个初始数据都是固定的。这四个初始数据假设由ABCD这四个变量分别存储着,而在进行处理初始数据之前,会把ABCD中存储的初始数据赋值给四个新的变量abcd,这是因为我们在处理数据的时候需要反复对初始数据进行处理,所以我们需要保留一份最开始的初始数据留到后面使用。
第三步多轮压缩一共有四轮,每轮压缩会使用数据块和abcd中存储的初始数据进行十六次计算操作,这十六次计算操作中的每一次最终都会把abcd各自更新一次,四轮压缩一共会把abcd各自更新六十四次,所以64字节(512bit)大小的分组数据和abcd中存储的初始数据共进行六十四次位运算。现在读起来你可能会感到疑惑,没事我们接着往下看就知道是什么意思了。
还记得我们前面保留在ABCD四个变量中的初始数据吗?现在就用的到了,当完成多轮压缩的计算操作后就需要进行以下操作:
当完成对第一个数据块所进行的四轮压缩后,那接下来就需要进行对第二个数据块的处理,在对第二个数据块进行处理的时候就需要把上一次存储最后处理结果的四个变量ABCD中存储的值再次赋值给变量abcd,这样就把最后得到的散列值分别加回到当前散列值的四个部分,散列值就被更新了。处理第二个数据块的操作和处理第一个数据块的操作一致,要说不同,那只有要进行处理的散列值是前一个数据块的最终值。
源数据经过填充补齐和分块后,一共有多少数据块,就要进行多少轮这样的操作。当我们在所有数据块上完成多轮压缩,散列值也就被更新为最终的MD5值,最终的MD5值会被使用小端序的方式存储到内存当中,就是最终128位的结果了。
MD5消息摘要算法的整体细节相信大家也多多少少清楚了些,下面我们讲讲在多轮压缩时的一系列计算操作是怎样的。
假设我们现在已经将数据初始化好了,得到了存储初始化数据的ABCD四个变量,并且将初始数据赋值给四个新的变量abcd。我们这是已经完成了第一步,我们第二步就需要进行计算数据,以下是使用64字节(512bit)大小的分组数据和abcd中存储的初始数据共进行64 次位运算所用到的公式:
这公式是什么意思呢?还请听我娓娓道来。
我们先来看一下这个计算公式中的F是什么:
循环进行六十四次位运算,从i=0循环到i=63
前面说过64字节(512bit)大小的分组数据和abcd中存储的初始数据共进行64 次位运算,而以上代码中的变量i就表示这是第多少次位运算。可能有朋友疑惑F、G、H、I是什么?这是四轮压缩要使用的四种运算公式,四种运算公式如下:
在六十四次位运算当中,第一次到第十六次F的值用F(X, Y, Z) = (X & Y) | (~X & Z)这个公式来计算出来,其实第一次到第十六次也就是第一轮压缩,所以也可以说是第一轮压缩使用公式F来计算出最开始那计算数据公式中F1的值。第二轮压缩使用公式G来计算出最开始那计算数据公式中F2的值。第三轮压缩使用公式H来计算出最开始那计算数据公式中F3的值。第四轮压缩使用公式I来计算出最开始那计算数据公式中F4的值。
这四个公式涉及到三个值,分别是bcd,也就是前面讲过的abcd四个变量中的bcd。
接着我们来看最开始那计算数据公式中K的值,K的值要用到一个常量表,这常量表有六十四个数据,常量表如下:
第n次位运算就使用以上常量表中的第n个常量来作为K的值,比如第二次位运算K的值就应该为0xe8c7b756。
接着我们来看最开始那计算数据公式中M的值,M的值与64字节(512bit)大小的分组数据有关,假设有以下填充对齐后的64字节数据:
六十四个字节会被分为十六组四字节,在第一轮压缩是第几次位运算就选择十六组四字节当中的第几组;在第二轮压缩是使用公式((i * 5) + 1) % 16来计算出要取出十六组四字节当中的第几组;在第三轮压缩是使用公式((i * 3) + 5) % 16来计算出要取出十六组四字节当中的第几组;在第四轮压缩是使用公式(i * 7) % 16来计算出要取出十六组四字节当中的第几组;
接着就是将(a+F + K[i] + M[g])这四个值的和再向左循环左移s,这个s要用到一个位移表,这个位移表也是有六十四个数据,位移表如下:
s值和K值一样,第n次位运算就使用以上位移表中的第n个常量来作为s的值,比如第三次位运算s的值就应该为17,也就是说在第三次位运算的时候要把值循环左移17位。
现在搞清楚了F、K、M、S,然后再加上b的值就可以计算出结果。最后一步还需对数据进行交换,交换数据需要将b的值交换到c,将c的值交换到d,将d的值交换到a,最后把刚刚计算出来的a的结果交换到b。这样就完成了六十四次位运算中的一次,剩下还需要如此这般进行63次位运算,在最后一次位运算完成后,还需要使用大写的ABCD加上小写的abcd就可以计算出结果了,最后将这些结果使用小端序的方式存储到内存当中就是最终的MD5值了!
至此MD5的细节和原理现在已经多多少少有一定的了解了,我们现在来讲讲MD5的安全隐患在哪吧!
首先MD5并不是加密算法,而是一个产生消息摘要的散列函数,它的不安全性并不是拿着它的密文去试图破解它的明文,因为MD5处理数据的过程中会不断的产生信息损失,所以MD5是不可逆的。那么它是什么方面不安全了呢?
前面讲过MD5可以将任意消息内容变成长度固定为128位的散列值,这句话告诉我们两个信息,任意消息和固定为128位的散列值,经过MD5处理过后的数据固定为128位就意味着MD5值它是有边界的,而任意数据就意味着输入给MD5进行处理的数据是没有边界的,也就是说输入给MD5处理的数据是无穷的。输入给MD5处理的数据是无穷的,MD5处理过后的数据是有穷的,以有穷对无穷就会出现一个问题,那就是一定会有不同的数据经过MD5处理后得到相同的MD5值!而这个情况被称之为MD5的碰撞性。
以有穷对无穷还会导致同一个MD5值对应的可能数据也应该有无穷多个,但是MD5的作者在设计之初认为我们无法主动找到碰撞。既然一个MD5值可能有无穷多个对应的数据,那我们可不可以找到任意一个能产生这个MD5值的数据呢?这个问题就是所谓的"原像攻击",那原像攻击是否对MD5的安全性产生了巨大的影响呢?结果很遗憾,到现在原像攻击还没有什么通用可行的方案。你看MD5值的范围在0到2的128次方之间,我们使用暴力穷举法不断的尝试使用不同的数据生成MD5值,理论上只要尝试的次数足够多,那么就能把这个MD5值对应的任意一个数据给找出来。虽然说理论上合理,但实践起来可不容易,0到2的128次方就意味着有2的128次方种可能,像这样的工程量无异于大海捞针。
既然原像攻击行不通,那么就放宽条件,假设给定一个数据和该数据经过MD5处理后的MD5值,那么可不可以找到另外一个MD5值相同的数据呢?这个问题就是所谓的"第二原像攻击",那么第二原像攻击是否对MD5的安全性产生了巨大的影响呢?目前来看MD5对于抗第二原像攻击的情况不容乐观,但是这并不是让MD5某些方面安全性堪忧的关键所在,真正让MD5安全性堪忧的是抗强碰撞性。
对于抗强碰撞性在2004年之前一直困于伪碰撞的范围,直到2004年我国山东大学的王小云团队找到了快速发现大量MD5真碰撞的方法,这是一次重大突破,并在2005年发布了详细的研究细节,她们的方法可以在十五分钟到一个小时之内找到碰撞,在基于王小云团队的研究上,人们后续的研究可谓是将MD5安全性的最后一块遮羞布给扯了下来。2007年埃因霍芬理工大学的Marc Stevens基于王小云团队的研究提出了两项新的成果,第一项成果是用一个原始数据内容生成另外两个MD5值一样但是数据内容不一样的数据,最为重要的一点是生成的这两个MD5值一样的数据内容有意义,这就很恐怖了!这一项成果被称之为相同前缀碰撞,原始数据内容作为前缀,然后不断尝试构造两个不同的后缀数据,直到最终产生的数据内容的MD5值相同为止,而为什么最终产生的数据内容都有意义,那是因为前缀数据保留了原始数据内容原本的意义。可能讲到这里你会认为这还是有手段可以反制,还是可以看出端倪,还不至于没得打,那再看看Marc Stevens提交的第二项成果,那就是可以自由的选择前缀的数据内容,然后生成两个MD5值一样但是前缀内容不相同的数据内容,这被称之为选择前缀碰撞。这个操作性可就很大了,如果仔细去想那不得不为MD5的安全性感到堪忧了!如果有人有这个生成两个文件,一个文件正常无隐患,一个各种木马病毒加身,但是它们两个文件的MD5值一样,如果网站用MD5值进行判断,那岂不是危矣!这让我想到万人敬仰韩天尊,杀人放火厉飞羽。
既然MD5已经不安全了,那为什么它会死而不僵呢?因为它的这些安全隐患并非全场景覆盖,就比如前面提到的第三方渠道下载和数据保存到数据库就不在MD5的安全隐患范围内。
现在对MD5应该有了一定的了解,那么下一步我们来看看Java是如何使用MD5处理数据的:
以上代码使用Java的MessageDigest自定义类来计算字符串"Hello, World!"的MD5摘要。在主函数main中,定义了一个字符串类型变量data,并将其转换为字节数组。然后调用calculateMD5方法计算MD5摘要,将结果保存在digest字节数组中。
calculateMD5方法中,通过MessageDigest.getInstance("MD5")获取MD5摘要算法的实例。如果获取失败,则会抛出NoSuchAlgorithmException异常。在这里,我们通过try-catch块捕获异常并打印异常信息,然后返回null。
如果成功获取到MD5摘要算法的实例,调用md.digest(data)方法计算摘要。这个方法接受一个字节数组作为输入,并返回计算得到的摘要字节数组。
在main函数中添加assert digest != null;是为了确保calculateMD5方法返回的摘要字节数组不为null。在正常情况下,calculateMD5方法应该能够成功计算并返回摘要字节数组。然而,如果在获取MD5摘要算法实例时发生异常,calculateMD5方法将返回null。
通过添加断言assert digest != null;,我们可以在调试和测试阶段捕获这种异常情况。如果calculateMD5方法返回null,断言将会触发并抛出AssertionError异常,从而提醒我们出现了意外的情况。
最后,调用bytesToHex方法将摘要字节数组转换为十六进制字符串,并将结果打印出来。
最终的打印结果如下:
现在总算把MD5算法给讲清楚了,好累!现在向我们走来的是消息摘要算法之SHA算法。
SHA算法百度百科解释如下:
安全散列算法 (英语:Secure Hash Algorithm,缩写为SHA)是一个密码散列函数家族,是FIPS所认证的安全散列算法。能计算出一个数字消息所对应到的,长度固定的字符串(又称消息摘要)的算法。且若输入的消息不同,它们对应到不同字符串的机率很高。
SHA算法还是一个家族,SHA家族的五个算法,分别是SHA-1、SHA-224、SHA-256、SHA-384,和SHA-512,由美国国家安全局(NSA)所设计,并由美国国家标准与技术研究院(NIST)发布;是美国的政府标准。后四者有时并称为SHA-2。SHA-1在许多安全协定中广为使用,包括TLS和SSL、PGP、SSH、S/MIME和IPsec,曾被视为是MD5(更早之前被广为使用的杂凑函数)的后继者。但SHA-1的安全性如今被密码学家严重质疑;虽然至今尚未出现对SHA-2有效的攻击,它的算法跟SHA-1基本上仍然相似;因此有些人开始发展其他替代的杂凑算法。
有关SHA系列算法摘要长度如下表所示:
SHA系列算法与MD5算法有很多相似之处,这里对SHA系列算法的原理就不做过多阐述,我们就直接来看看Java是如何使用SHA系列算法处理数据的:
以上这段代码为我们展示了如何使用SHA-256算法计算给定数据的哈希值,并将结果以十六进制字符串的形式输出。
在main方法中,首先定义了一个字符串类型变量data,表示要计算哈希值的数据为"Hello, World!"。然后调用calculateSHA方法,将data转换为字节数组,并计算其SHA哈希值。接着将计算得到的哈希值转换为十六进制字符串,并输出结果。
calculateSHA方法接受一个字节数组作为参数,通过MessageDigest类的getInstance方法初始化SHA-256算法的实例md。然后调用md的digest方法对数据进行摘要处理,返回计算得到的哈希值。
bytesToHex方法接受一个字节数组作为参数,将字节数组中的每个字节转换为十六进制字符串,并将其拼接为一个完整的十六进制字符串后返回。
在main方法中,调用calculateSHA方法计算数据的SHA哈希值,然后调用bytesToHex方法将哈希值转换为十六进制字符串并输出。
SHA-256算法在实际应用中,可以用于数据完整性验证、密码存储等安全领域。如果NoSuchAlgorithmException异常被抛出,表示指定的算法不可用。
我们来看看SHA-256算法处理后的打印结果是如何模样的:
SHA系列算法详细的处理过程大家可以自己去了解,具体的处理过程我这里就不详解了。
现在我们大致了解了MD5消息摘要算法、SHA系列消息摘要算法,接下来向我们走来的是MAC消息摘要算法,该消息摘要算法是含有密钥的消息摘要算法。
MAC(Message Authentication Code,消息认证码算法)是含有密钥散列函数算法,兼容了MD和SHA算法的特性,并在此基础上加上了密钥。因此MAC算法也经常被称作HMAC算法。
MAC算法主要集合了MD和SHA两大系列消息摘要算法。MD系列算法有HmacMD2、HmacMD4和HmacMD5三种算法,SHA系列算法有HmacSHA1、HmacSHA224、HmacSHA256、HmacSHA384和HmacSHA512五种算法。
有关MAC算法摘要长度如下表所示:
接下来我们来看看Java是如何使用MAC系列算法处理数据的:
我们可以看到以上代码演示了如何使用Java的javax.crypto包中的Mac类来计算消息的摘要。具体来说,代码的功能如下:
在代码中使用了try-catch语句来捕获可能抛出的NoSuchAlgorithmException和InvalidKeyException异常,并在发生异常时打印异常堆栈信息。
总而言之,以上代码展示了如何使用HmacSHA256算法计算消息的摘要,并将摘要以十六进制字符串的形式打印出来。
我们来看看HmacSHA256算法处理后的打印结果是如何模样的:
到此为止,我们将常用到的消息摘要算法都简单了解了一遍,接下来,我们就要进入对称加密算法了,这里我们先简单了解一下对称加密算法,对称加密算法与消息摘要算法最大的区别在于加密和解密的过程是可逆的,这里多一嘴,不管是对称加密算法还是非对称加密算法,最常见的加密算法都是分组加密算法,那什么是分组加密算法呢?简单来说就是把明文分成一组或多组进行加密,而分组加密算法一般会有五种加密模式,这五种加密模式分别是ECB、CBC、CFB、OFB、CTR,这里着重讲一下比较常见的ECB和CBC这两种加密模式。
ECB加密模式是最基本的工作模式,将待处理明文进行分组,每组分别进行加密或解密处理,当然明文分组的长度是根据密钥的长度来的,至于分组长度的规则这里就不细讲,总之只要知道有这么一个分组的概念就可以了。
假设我们有这么一段明文:123456789,这段明文假设被分为三段,分别是第一段明文123、第二段明文456、第三段明文789。
明文分组后我们使用密钥对每一组明文进行加密,处理后得到加密后的密文,假设得到了三组密文,分别是由123加密得来的"qsc"、由456加密得来的"asf"、由789加密得来的"jgh"。
得到三组密文后,最后将三组密文拼接起来得到最终的密文——"qscasfjgh"。
以上模拟的加密模式便是ECB加密模式,这里讲讲ECB加密模式的优缺点,该加密模式的缺点很明显,它的加密模式导致它只需要猜其中一部分就可以了,其中一部分错了其他部分还有可能对,解密的时候是按照区块去解密的,所以在破解密文的时候不需要每一个都猜对,我们可以进行枚举,或者在数据库中存一些字典,这些字典记录着一个明文对应哪个密文,然后进行穷举嘛!只要这个计算时间足够长,总有一天会破解出来的。
到这里你会发现ECB加密模式安全性并不高,但为什么还是这么的常用呢?这就得讲讲ECB加密模式的优点了。ECB加密模式最大的优点就是方便、简单、可并行。这里的可并行是什么可能大家并不太清楚,这个可并行的优点是由于ECB加密模式的各分组之间没有关联,所以ECB的操作可以并行化。
CBC加密模式和ECB加密模式最大的不同就是IV向量,我们先来看看这个IV向量在CBC加密模式中扮演着怎么样的角色。CBC加密模式依旧是先将待处理的明文进行分组,分好组后就需要用到IV向量了,CBC会先将第一组明文与IV向量进行异或运算,进行异或运算后才是使用密钥进行加密,从而得到第一组密文。你以为会是把每一组明文都与IV向量进行异或运算后加密得到密文,然后再将所有组密文拼接在一起得到最后的密文?不不不,大错特错,在得到第一组密文后,下一组明文在加密前不是与IV向量进行异或运算,而是与前一组密文进行异或运算,然后再使用密钥进行加密得到新的密文。简单来说就是第一组用IV向量来进行异或运算然后加密得到密文,第二组用前一组的密文来进行异或运算然后加密得到新的密文,直到最后一组用前一组的密文来进行异或运算然后加密得到最后的密文,最后的最后把所有组密文拼接起来得到完整的密文。因此CBC加密模式中文名为密文分组链接模式,你可以从CBC的加密模式中看出在加密的过程中密文分组就像链条一样相互连接在一起,而IV向量就是这链条的头部。
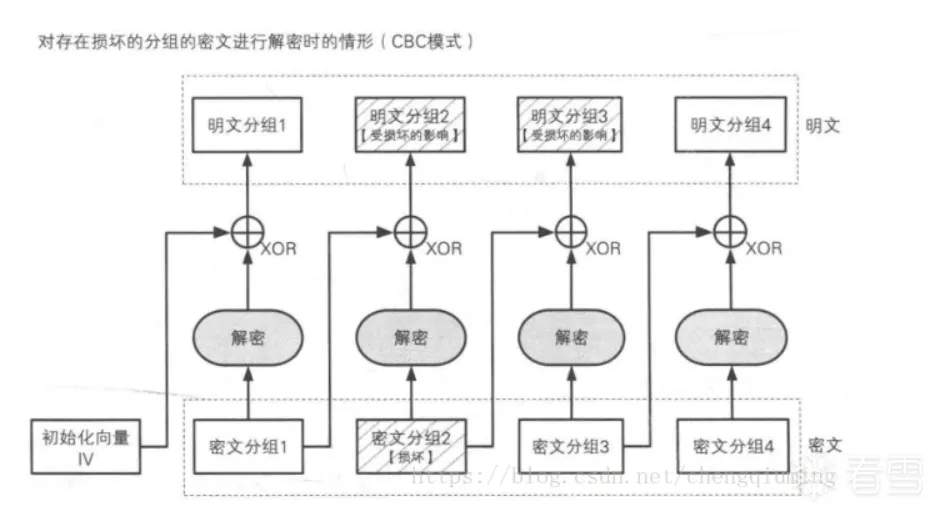
从CBC的加密模式可以看出来,CBC加密模式的特点,首先特点一在加密的过程中必然有一个IV向量,而IV向量的值不一样得到的结果也就不一样;特点二某一组明文加密结果错误了,那后面的每组加密也就全都错误了;特点三无法单独对中间某一组明文进行加密,假设要加密第三组明文,那就需要先加密第一、二组明文才可以加密第三组明文,而无法单独加密第三组明文;特点四如果一个密文分组损坏了,解密时最多只有两个分组(损坏分组及其后的一个分组)会受到影响;特点四我从网上扒下来一张图来讲解讲解。
以下是对图中CBC模式分组损坏的影响的讲解:
因此,在CBC模式下,如果一个密文分组损坏了,解密时最多只有两个分组(损坏分组及其后的一个分组)会受到影响。图中清晰地展示了这一点。
特点五如果密文分组中有比特缺失,缺失比特的位置之后的所有密文分组都将无法正确解密。
以下是对图中CBC模式当密文分组中有比特缺失时的影响:
具体影响如下:
因此,在CBC模式下,如果密文分组中有比特缺失,缺失比特的位置之后的所有密文分组都将无法正确解密。图中清晰地展示了这一点。
前面的示例中都是假设分组后每一组明文长度相同,但实际情况不会是假设,所以当ECB和CBC加密模式把明文分组后如果出现最后一组明文长度和其他组明文长度不一致的情况,那么是如何应对的?这就牵扯到一个叫做填充方式的东西,这个填充方式就是用来保证分组加密算法中的每组明文长度一致的,而填充方式有No Padding 、ANSI X9.23 、ISO 10126 、PKCS#5 、PKCS#7 、Zero Padding 、ISO/IEC 7816-4 等填充方式。
在分组加密算法中,填充(Padding)是一种在分组加密算法中用于处理明文长度不符合分组长度要求的方法。不同的填充方式会根据不同的规则来添加填充数据,以确保明文数据长度能被正确地分组加密。以下是我对各种填充方式的讲解:
No Padding :不填充,要求明文的长度必须是加密算法分组长度的整数倍。如果长度不符合要求,则需要手动补充符合要求的填充数据。
ANSI X9.23 :在填充字节序列中,最后一个字节填充为需要填充的字节长度,其余字节填充0。这种填充方式以0填充,同时使用最后一个字节记录填充的长度信息。
ISO 10126 :在填充字节序列中,最后一个字节填充为需要填充的字节长度,其余字节填充随机数。这种填充方式将除最后一个字节外的填充字节用随机数填充。
PKCS#5和PKCS#7 :在填充字节序列中,每个字节填充为需要填充的字节长度。这两种填充方式中,每个填充字节的数值都等于需要填充的字节长度,但细心的你会发现我把PKCS#5和PKCS#7放在一起了,那么PKCS#5和PKCS#7是什么关系呢?其实这两者是包含关系,PKCS#7包含PKCS#5,你可以理解为PKCS#5支持填充的范围比较小,而PKCS#7支持填充的范围比较大。
ISO/IEC 7816-4 :在填充字节序列中,第一个字节填充固定值80,其余字节填充0。若只需填充一个字节,则直接填充80。这种填充方式将第一个字节填充为固定值80,其余字节填充为0。
Zero Padding :在填充字节序列中,每个字节填充为0。这种填充方式简单地使用0填充剩余字节。
每种填充方式都有其特定的规则和应用场景,用于确保在对非标准长度的数据进行加密时,能够正确地进行分组加密操作。不同的加密算法或协议可能会采用不同的填充方式来处理数据长度不足分组长度的情况。
到这我们就讲解了对称加密算法的前菜,了解了一点算法基础,接下来我们将进入主菜环节,讲讲常见的几种对称加密算法。
这里我们简单了解一下常用的三种对称加密算法,分别是DES算法和DESede算法,以及AES算法。而第一个向我们迎面走来的对称加密算法便是DES对称加密算法。
我们先讲一下概念,DES(Data Encryption Standard)是一种对称加密算法,由IBM研发并在1977年被美国政府正式采纳作为数据加密标准。DES基于分组密码的概念,将数据分成64位的数据块(即一个分组),采用56位的密钥对数据进行加密和解密。虽然密钥长度是56个二进制位,但在Java中提供的是八个字节,也就是64个二进制位,因为其中8个二进制位是要做校验的。
当获得了一组64位的数据之后,DES将通过一些步骤进行加密,而关于DES对称加密算法的加密流程我们简单概括一下:
DES加密算法共有16个轮次,每个轮次都包括以下四个步骤:
a. 数据块分割
b. 右侧数据块处理
c. 左右数据块交换
d. 生成新数据块
总结
这里只是DES对称加密算法的加密流程的简单概括,如果有兴趣了解具体的加密流程可以自行去参考这篇文章或者自行寻找:
通俗易懂,十分钟读懂DES,详解DES加密算法原理,DES攻击手段以及3DES原理。Python DES实现源码-CSDN博客
好了,接下来我们就来看看Java是如何使用DES对称加密算法对数据进行加解密的:
以上这段代码是一个Java类DesExample,它为我们演示对字符串进行DES加密和解密操作。以下是这段代码的讲解:
DesExample类包含了两静态属性keys和values,用于存储DES加密密钥和待加密的字符串。
DesEncryption方法是一个私有静态方法,用于对输入的字符串进行DES加密操作。该方法接收加密密钥和待加密的字符串作为参数,并返回加密后的字节数组。
main方法是程序的入口点。在这个方法中:
我在代码中添加的注释为每个关键步骤提供了解释,可以帮助大家更容易理解代码执行流程。
需要注意的是,代码中使用了sun.misc.BASE64Decoder和sun.misc.BASE64Encoder这两个类,它们是sun.*的非标准API,不建议在生产环境中使用,因为它们不是公共API,并可能在将来的Java版本中被移除。
现在我们就来看看Java使用DES对称加密算法对数据进行加解密后的效果:
我们可以看到从加密前的"12345678"到加密后的"ZEi7hkmMp+Dr8CE3zdeHkg==",再到解密后得到的明文"12345678"这么一个完整的过程。但这里要注意的是加密和解密的过程是相对的,比如说上面的代码中对于明文的加密流程是先通过getBytes方法将明文转换为byte 序列,然后再进行加密操作并返回密文,最后把密文进行BASE64编码操作;我们再来看看上面代码中解密的过程,因为加密和解密的过程是相对的,所以你在代码中可以看到解密的第一步是先对密文进行BASE64解码操作,然后再进行解密操作,最后把解密后的内容转换为字符串,从而得到最后的明文。
DES对称加密算法我们就讲到这,接下来我们快速了解DESede对称加密算法,其实这两种对称加密算法是差不多的,要说区别有这么几种,在讲区别之前我们先来看看DESede对称加密算法如何使用JAVA代码实现:
1. 引入的类和包
2. 类功能
该类的功能是通过 DESede 算法加密和解密文本。DESede 是通过三重 DES (Triple DES)算法实现的一个变种,提供比单一 DES 更强的安全性。
3. 主要方法
3.1 DESedeDecode(String keys, String values)
该方法负责执行 DESede 解密操作。
3.2 main(String[] args)
主方法用于演示加密和解密的过程。
步骤
:
4. 使用示例
假设密钥为 123456781234567812345678,要加密的明文为 a12345678,它的过程如下:
我们简单的了解了以上代码,我们可以看出这两种算法最明显的区别是密钥的长度不一样,一个是八位的,一个是二十四位的。其次就是使用的实例化函数和实例化得到的结果不一样,还有就是SecretKeyFactory.getInstance函数指明的类型也是不一样的,其他的地方就是差不多的。
好了,简单的过了DESede对称加密算法,我们接下来去了解下一个常用的对称加密算法——AES;废话不多说,直接上代码:
1. 引入的类和包
2. 类功能
该类的功能是使用 AES 算法对文本数据进行加密和解密。引入了初始化向量(IV)以增强加密安全性。
3. 主要方法
3.1 encrypt(String data, String key, String iv)
此方法负责执行 AES 加密操作。
3.2 decrypt(String data, String key, String iv)
此方法负责执行 AES 解密操作。
3.3 main(String[] args)
主方法用于演示加密和解密的过程。
步骤
:
4. 使用示例
假设要加密的文本为 a12345678,密钥和 IV 均为 1234567890abcdef。执行过程如下:
我们来运行一下以上代码,看看结果如何:
通过看代码我们其实也能发现AES对称加密算法和前两种对称加密算法的一些区别,但写法上是差不多的。而AES与其他两种的区别就比如说最明显的就是AES对称加密在密钥实例化时用的是SecretKeySpec方法,而该方法其实是通用的,其实前两种对称加密算法也可以用该方法进行密钥实例化的,只不过前两种对称加密算法是有专门的方法来进行密钥实例化的,而AES是没有的,只能通过该方法来进行密钥实例化。
到此为止常见的对称加密算法就基本讲完了,那接下来就讲讲非对称加密算法,而在非对称加密算法的使用中比较常见的就是RSA算法。非对称加密算法和对称加密算法最大的区别就是加解密使用不同的密钥,它是有一个公钥和一个私钥的,这两把密钥之间是有联系的。还有一个点就是对称加密的密钥是可以随便写的,但是非对称加密的密钥是由函数来生成的,而且通过公钥是推导不出来私钥的,但私钥里面是包含公钥信息的,所以可以通过私钥来得到公钥的。
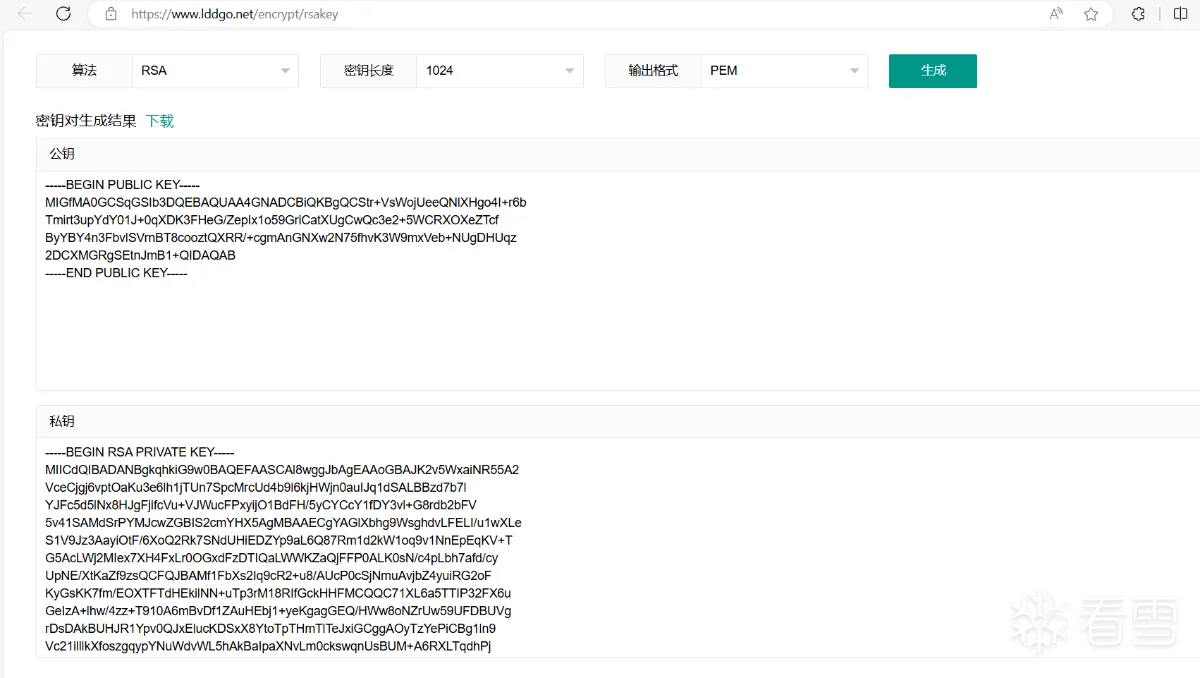
我们可以通过一些网站或者工具生成RSA的公钥和私钥,我们去试试看:
我们可以看到私钥的长度比公钥的长度长很多,前面讲过私钥里面是包含公钥信息的;我们往上看,可以看到在可以选择的内容中有密钥长度,而密钥长度越长它加密的时间自然也就越长,也越安全,而且在非对称加密算法中你密钥的长度决定了你明文的长度,所以在密钥长度中用的比较多的是1024位,也就是128字节,除了1024位之外还有2048位、4096位以及512位,但512位现在几乎没什么人用了,4096位也用的少,主要还是1024位以及2048位用的多点。
我们可以从上面看出非对称加密算法加密处理还是很安全的,但是性能极差,而且单次加密长度还有限制,也就是说非对称加密算法单次加密对于明文长度是有限制的,不是像对称加密一样对于明文加密是没有长度限制的。而明文的最大字节数是根据密钥长度来决定的,所以这个密钥的位数是比较重要的。但是明文的最大字节数具体是多少会跟填充方式会有一定的关系,比如说当填充方式为PKCS1Padding时,明文的最大字节数为密钥字节数-11,密文与密钥等长;当填充方式为NoPadding时,明文的最大字节数为密钥字节数,密文与密钥等长。
我们在前面的文章讲过非对称加密的常见用法:
第一步:服务器会将非对称加密中的公钥发送给浏览器,浏览器生成一串随机数字,而这串随机数字使用服务器发送过来的公钥进行加密。
第二步:将通过公钥加密的随机数字发送给服务器,服务器接收后使用私钥进行解密,这样双方就都得到了一个同样的随机数字,而这个随机数字可以作为对称加密的密钥。
第三步:使用随机数字作为密钥对真正需要传递的数据进行加密传输。
而当我们逆向的时候我们是可以取巧的,至于怎么取巧且听我娓娓道来:
首先假设每一次随机生成的密钥都是一样的,那么通过RSA非对称加密算法加密的结果都是一样的,当然也有情况加密的结果是不一样的,比如说填充方式为PKCS1Padding,即使是这样那解密出来的结果也是一样的。是不是有点绕,你想想每次RSA对称加密的加密结果都不同,但不管它怎么变,后台解密出来的都是一个明文,那我们是不是可以把RSA对称加密的加密结果给固定下来,这样一来提交给后台解密出来的明文还是那个明文。这样做的好处就是逆向算法的时候RSA算法就不用找了,而是直接把加密结果固定下来就可以了。
讲了这么多关于非对称加密算法的理论,我们还是来讲讲怎么用JAVA代码来实现RSA加密算法吧!RSA加密算法有两种不同的写法,分别是base64版和hex版,我们一个个来了解,因为这两个不同的写法在我们逆向的时候都有可能会遇到。
base64版:
上面的代码看起来很长,没关系我们下面对其进行逐步详解:
1. 包与依赖
这行代码定义了代码的包名,便于组织和管理 Java 类。
2. 导入必要的类
3. 类定义与成员变量
4. 静态初始化块
这个静态块在类加载时执行,初始化了 Base64 编码和解码的实例。
5. 获取公钥与私钥的方法
这两个方法从 Base64 编码的字符串中生成相应的公钥和私钥。
6. 加密与解密方法
7. 将字节数组转换为十六进制字符串
这个方法将字节数组转换为其对应的十六进制字符串,以便于输出和查看。
8. 主方法
主方法中:
在base64版中如果我们想要通过HOOK获取明文,你仔细看可以发现应当通过HOOK函数X509EncodedKeySpec来获取到其参数,而这个参数便是我们要获取的明文信息。
hex版:
还是一样,我们下面将对代码的详细逐部分解释:
1. 导入和包声明
2. 属性定义
定义了四个
类型的静态属性,用来存储公钥和私钥的参数:
3. 加密方法
4. 解密方法
5. 创建公私钥对象
6. 字节数组转十六进制字符串
7. 密钥生成与加密解密示例
8. 主方法
现在对于RSA加密算法的两种不同写法有一定了解了对吧!那么在这过程中,大家应该都好奇过为什么可以做到一把公钥和一把私钥可以做到公钥加密而公钥无法解密,只能私钥解密这个问题吧?
RSA的安全性主要基于大数分解问题。为了我们大家更好的理解为什么在RSA中公钥用于加密而私钥用于解密,我们可以从以下几个方面进行分析:
第一步我们需要选择两个大质数 p 和 q。
第二步计算n,计算n的公式为n=p×q,这个 n 将被用作公钥和私钥的一部分。
第三步计算欧拉函数,我们不需要知道欧拉函数是怎么样推导过来的,我们只需要知道欧拉函数的公式为ϕ(n)(欧拉函数)=(p−1)×(q−1)。
第四步选择公钥e,选择公钥e要满足三个条件,分别是公钥e必须是质数、公钥e必须是大于1并且小于ϕ(n) 的整数、公钥e必须与ϕ(n)互质,也就是公钥e不能是ϕ(n)的因子。通过这些条件的筛选就可以得到一些数字,就可以在这些数字里进行挑选作为公钥e。
第五步计算私钥d,计算私钥d只需要满足一个公式,也就是(d * e) % ϕ(n) = 1。
最终生成的公钥为(n,e),而私钥为(n,d)。
我们有了公钥和私钥,就可以简单的模拟加解密的过程了,假设我们有明文m,使用公钥 (n,e) 进行加密,生成密文 c。那么加密过程可以简化为公式c = (m^e) % n。
而解密呢?解密使用私钥(n,d)进行解密,恢复明文m。解密过程可以简化为公式m = (c^d) % n 。
我们回顾制作公私钥对和非对称加解密的过程,这个算法不想被破解核心点就在不能让人知道私钥中的数字d,而要想知道d就需要e和ϕ(n),因为e是公钥,所以e是被公开的,因此ϕ(n)是算出d的重要数字,而我们要算出ϕ(n)就需要p和q两个大质数,核心点就在于这两个大质数了,为什么叫它们大质数,因为只有当p和q这两个质数足够大时,不管ϕ(n)还是n都会变得十分的大,这样计算出公钥对应的私钥才会变得异常困难。
现在我们了解了加解密常用的算法的实现原理以及Java代码如何使用算法进行加密,那学习了加解密那我们需要去追算法,其实追算法在之前就玩过,这次再讲这个未免有点太无聊了,所以我们要学习一个十分常用的技能来帮助我们追算法,那就是大名鼎鼎的Hook!!!
想要了解Hook,Hook 英文翻译过来就是钩子的意思,那我们就绕不开Xposed,而Xposed 框架是一个运行在 Android 操作系统之上的钩子框架,用钩子来进行表示是十分形象的,它能够在事件开始到事件结束这个期间进行截获并监控事件的传输,以及可以对事件进行自定义的处理。
Hook技术可以让一个程序的代码“植入”到另一个程序的进程中,成为目标程序的一部分。API Hook技术可以改变系统API函数的执行结果,让它执行重定向。在Android系统中,普通用户程序的进程是独立的,相互不干扰。这就意味着我们不能直接通过一个程序来改变其他程序的行为。但是有了Hook技术,我们可以实现这个想法。根据Hook对象和处理事件的方式不同,Hook还可以分为不同的种类,比如消息Hook和API Hook。
但是不管怎么样,衍生框架都是基于Xposed的,我们这还是主讲Xposed,下面将开始讲如何使用Xposed框架。
如果想要看Xposed官方文档,可以看这篇文章:
Development tutorial · rovo89/XposedBridge Wiki (github.com)
如果觉得英文看得费劲,那可以看这篇文章:
Xposed模块开发入门保姆级教程 - 狐言狐语和仙贝的魔法学习记录 (ketal.icu)
如果还觉得环境好麻烦啊!我不想准备环境,那可以看这篇文章:
《安卓逆向这档事》七、Sorry,会Hook真的可以为所欲为-Xposed快速上手(上)模块编.. - 『移动安全区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|615K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4N6%4N6#2)9J5k6e0f1J5M7r3!0B7K9h3g2Q4x3X3g2U0L8R3`.`.
如果想对Xposed源码及其原理更加深入一点的了解,可以看这篇文章,包括我下面关于Xposed的原理也是参考于随风而行aa大佬的这篇文章:
[原创]源码编译(3)——Xposed框架定制-Android安全-看雪-安全社区|安全招聘|kanxue.com
环境配置什么的我就省略了,我们直接步入正题,开始尝试Hook,以下使用的是Lsposed进行的Hook。
遇到某些情况怎么怎么解决,其他博主那也有写,我就不多做介绍了,我们直接进行实战,在实战中了解那些代码的作用以及该怎么灵活运用。
开始还是用个熟悉的APP来做演示,那就觉得是你了——X嘟牛!之前关于X嘟牛登录相关的加解密已经讲解过了,这次就不多赘述,只截取X嘟牛中的相关代码,如果想要了解之前的加解密讲解可以移步去此处:
[原创][原创]安卓逆向基础知识之动态调试以及安卓逆向的那些常规手段-Android安全-看雪-安全社区|安全招聘|kanxue.com
好了,废话就先讲到这,接下来就正式进入实战,让我们一起来揭开Hook的神秘面纱!
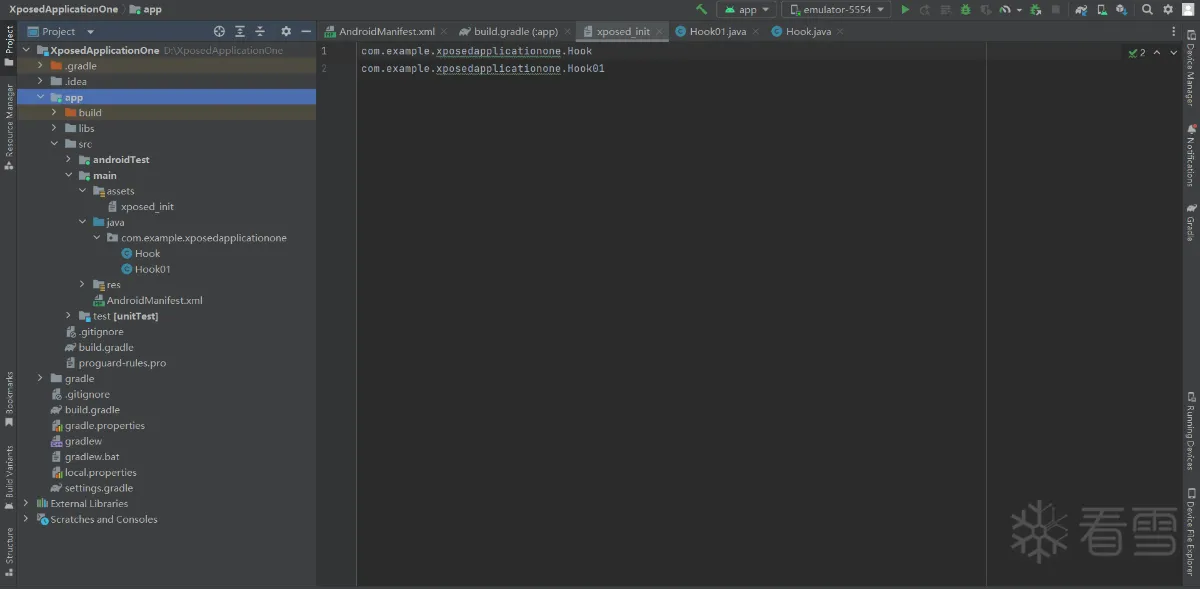
当我们准备好环境后,我们先新建一个名为Hook01的hook类,该类最开始的Hook代码就只是这样的:
Hook01类新建完成后,我们的Hook操作都在这个类里面完成。首先我们是要对X嘟牛进行Hook,最好是将其他APP排除在外,只对X嘟牛进行Hook。因为我们新建的Hook01类实现了接口IXposedHookLoadPackage,并且实现了该接口中关键的方法handleLoadPackage(XC_LoadPackage.LoadPackageParam loadPackageParam),而该方法会在每个应用程序启动时被调用,因此我们需要通过目标包名进行筛选。所以我们可以通过对包名进行判断,从而将X嘟牛之外的APP都排除在外。
但是我不知道为什么我的环境中这么写不会执行if语句中的内容,所以我一般只能这么写:
但是这就会出现一个问题,那岂不是我每要hook一个APP,那岂不是都要重新创建一个新的项目?不需要如此麻烦,完成Xposed环境搭建的小伙伴们还记不记得在main下新建的assets文件夹,我们是需要在assets目录下新建xposed_init,在里面写上hook类的完整路径(包名+类名),而xposed_init中可以定义多个类,每一个类写一行,如下图所示:
这样我们就解决了每要hook一个APP就需要重新创建一个新的项目的问题。接下来我们该思考如何对X嘟牛进行Hook,在一般的情况下我们应该对APP进行查壳,看这个APP有没有壳,但这次不是一般的情况,因为知道X嘟牛是没有进行加壳的,那如果我们遇到加壳的APP除了进行脱壳之外还有什么办法吗?诶!还真有,只不过不能应对所有的壳,只能也能应对绝大多数的免费壳了。我们可以使用以下代码来解决绝大多数的加壳:
以上代码主要用于在 Android 应用的生命周期内对 Application 类的 attach 方法进行 Hook 操作。attach方法是 Application 类中的一个方法。这是一个内部方法,用于初始化 Application 实例并设置其上下文。
可以看到我们对attach方法进行Hook主要是获取param.args[0],而param.args[0]是attach方法的第一个参数,即上下文对象 Context。随后,通过Context获取ClassLoader,ClassLoader 是一个用于加载类的对象,可以在后面的 Hook 逻辑中使用。
这种方式不仅仅可以应对加壳这种情况,我们还可以通过这种方式Hook多个dex文件,因为一个dex文件最多只能存在65535个方法,如果超过这个数量就会重新生成一个新的dex文件。所以正常情况下APP可能会有多个dex文件,如果我们要hook的方法不是在第一个dex文件中,我们就需要通过这种方式将需要Hook的方法的类加载进来,然后再进行Hook操作。
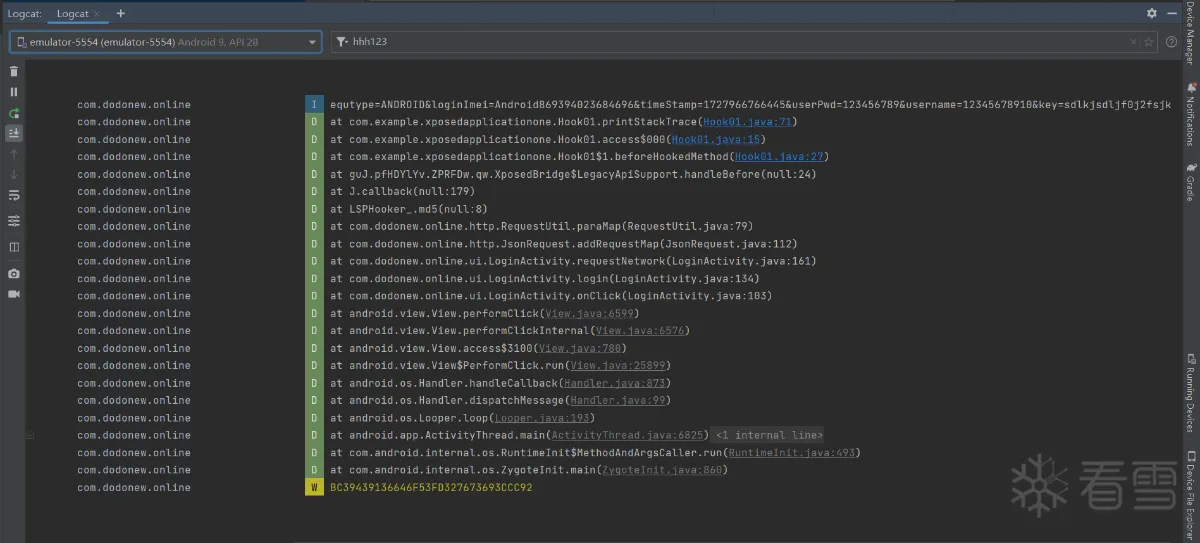
但是这个用于测试的这个X嘟牛既没有加壳也没有多个dex文件,那这里就不需要如此这般去获取类的加载器,在之前讲动态调试的那篇帖子中分析过X嘟牛,它在对称加密之前使用过MD5消息摘要算法,并将MD5处理过后的结果存入Map中的“sign”键值对中,那我们第一步hook的便是X嘟牛中的这个MD5消息摘要算法:
这里我们就需要通过Xposed进行Hook来获取md5方法的参数和返回值,我们可以看到md5方法的参数只有一个字符串类型的参数,返回值的类型也同为字符串类型,那么我们可以如此写Hook代码:
看完了这段hook代码,你们可能会认为printStackTrace()方法是系统自带的用于打印当前调用栈的方法,然而并不是,这个是一个自定义的方法,以下是printStackTrace()方法的完整代码:
那么我们写完了这个Hook代码,那么我们运行下看看效果:
我们可以从上图看出蓝色的日志为md5方法的参数,黄色的日志为md5方法的返回值,而绿色的日志就是md5方法当前的调用栈,这个栈怎么看呢?很简单,你看栈最上面那个方法是不是很熟悉,没错那就是我们写的打印当前调用栈的printStackTrace方法;再往下看还能看到熟悉的身影,比如beforeHookedMethod方法,那么我们Hook的那个方法是哪个呢?其实就是调用栈中显示的LSPHooker_.md5,在这个方法的上面是LSPosed调用的方法不用管,在这个方法的下面才是有价值的信息。
我们可以通过调用栈看到调用md5方法的是com.dodonew.online.http.RequestUtil类下的paraMap方法,大家可能对之前分析的paraMap方法没有多少印象了,以下是paraMap方法的代码:
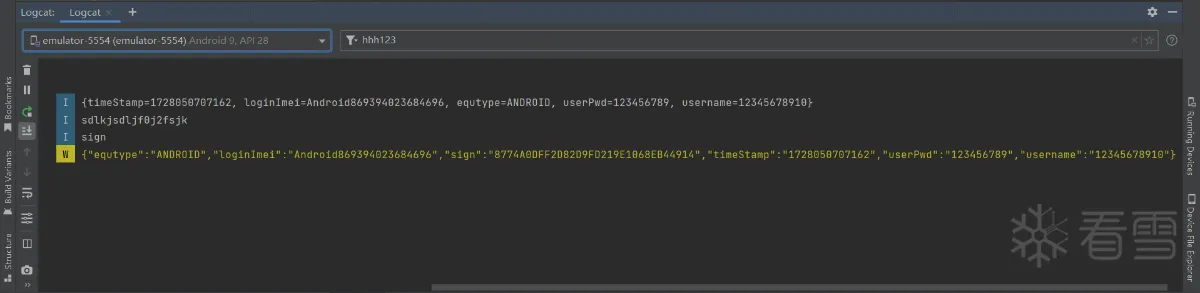
我们可以看到以上代码中对拼接后的URL参数字符串进行MD5加密,并将加密结果存入Map中的“sign”键值对中。那么我们接下来就Hook这个方法,来获取这个方法的参数和返回值。
这一次还是使用XposedHelpers.findAndHookMethod方法来Hook,这个方法参数要么需要类名和类加载器,要么就需要给它类的class对象,除此之外还需要提供要Hook方法的参数类型,那么有些参数的类型是自定义类型那又该如何应对呢?其实有办法可以解决这个问题,就是会要摒弃这种精准打击,而是直接进行火力覆盖,至于具体如何实现我们稍后揭晓。
我们先来看看hook成功后得到的参数和返回值吧!
我们成功的获取到了paraMap方法的参数和返回值,你看到现在可能觉得一直在获取参数和返回值有些无聊了,那我们去玩点有意思的,至于是什么有意思的,我们继续往下走就知道了。
运行完paraMap方法后,X嘟牛会把paraMap方法的返回值进行Des加密,那么我们先来回顾一下这个方法:
在RequestUtil类下一共有三个关于DES加解密的方法,我们要Hook的是第二个Des加密方法,这里进行Hook我们依旧可以使用之前的那种方式进行Hook,但是一直使用那种方式是无聊的,经过我测试之后,我们这次就来进行火力覆盖,甭管它多少个参数,参数是什么奇奇怪怪的类型,它都能Hook到。
还记得JAVA当中有一个概念叫做重载的吗?所谓的重载其实就是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。而在以上代码中encodeDesMap方法即是重载方法,而我们要实现火力覆盖其实就是不管方法的参数和返回值是多少,只要方法名字是对的,那就会全Hook了,也可以说是会把指定方法的重载方法全部Hook了。
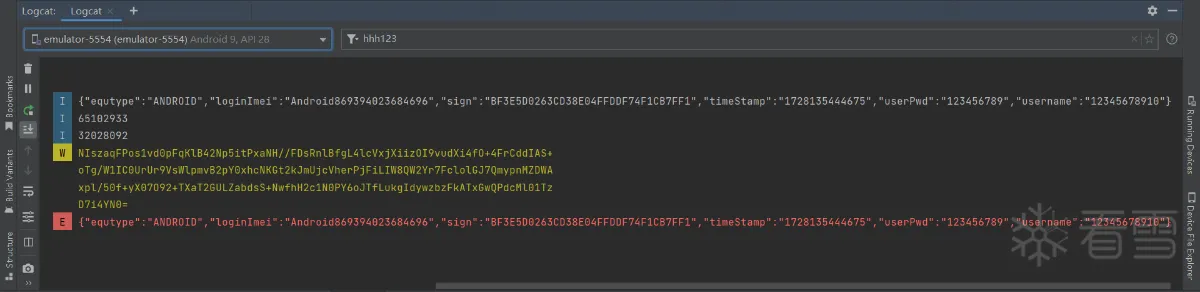
我测试过了,参数为四个String类型,返回值为Map类型的那个encodeDesMap方法并未被调用,我们可以直接进行火力覆盖来作为演示,在这之前我们再多干点事情,encodeDesMap方法会使用 DES 加密算法对给定的数据字符串进行加密,那么我们在encodeDesMap方法执行之后,就调用decodeDesJson方法把加密后的结果进行解密,来看看加密后再用自己的方法进行解密,结果是不是一致。
我们来看看结果是否如我们所愿:
可以从上图看出来,我们通过Hook所有的encodeDesMap方法也如愿得到了我们需要的那三个参数和返回值,而且我们在encodeDesMap方法调用之后调用 decodeDesJson 静态方法也成功的解密了密文,我们可以看到加密前和解密后的源数据是相同的。
在这一次实例中我们学会了如何Hook普通方法,学会了如何Hook带有复杂的、自定义的参数的方法,还学会了如何调用静态方法,这里还提一嘴,调用静态方法是使用XposedHelpers.callStaticMethod来实现,而调用实例方法其实也差不多:
X嘟牛我们已经完成Hook了,但是关于Hook可还没有结束,现在大家对于Hook也大概知道是个怎么回事了,那么我们可以去尝试写稍微复杂点的Hook代码了,接下来我们要Hook的程序是一个写入程序,它会把文件写入到一个地址去,而我们要做的就是找到这个程序它把文件写入到了哪里。
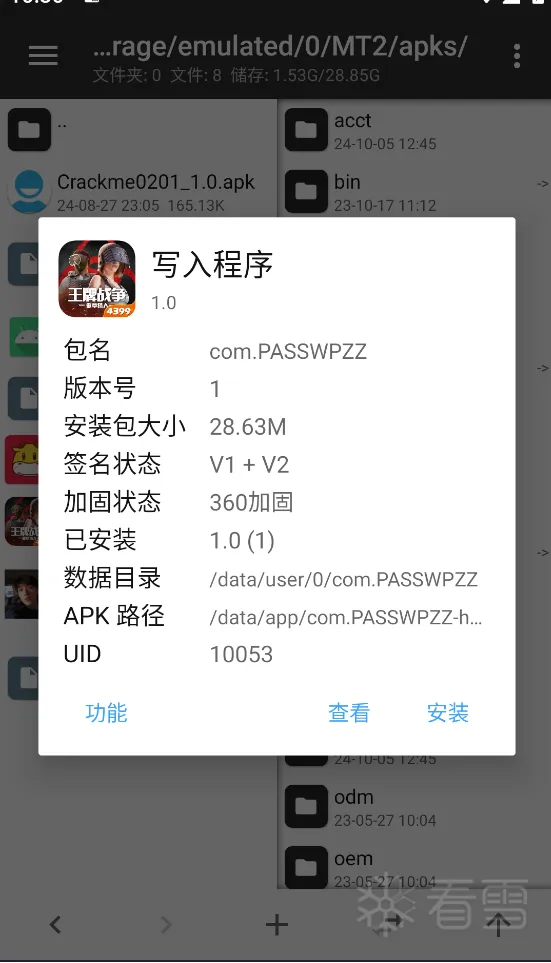
第一步我们还是需要对这个APP进行查壳,看是否有壳:
可以看到这个APP是有壳的,现在我们还对脱壳与修复知之甚少,所以我们只能使用对 Application 类的 attach 方法进行 Hook 操作来获取上下文对象,从而获取类加载器来应付加壳的情况。那我们赶紧试试是否有效吧!
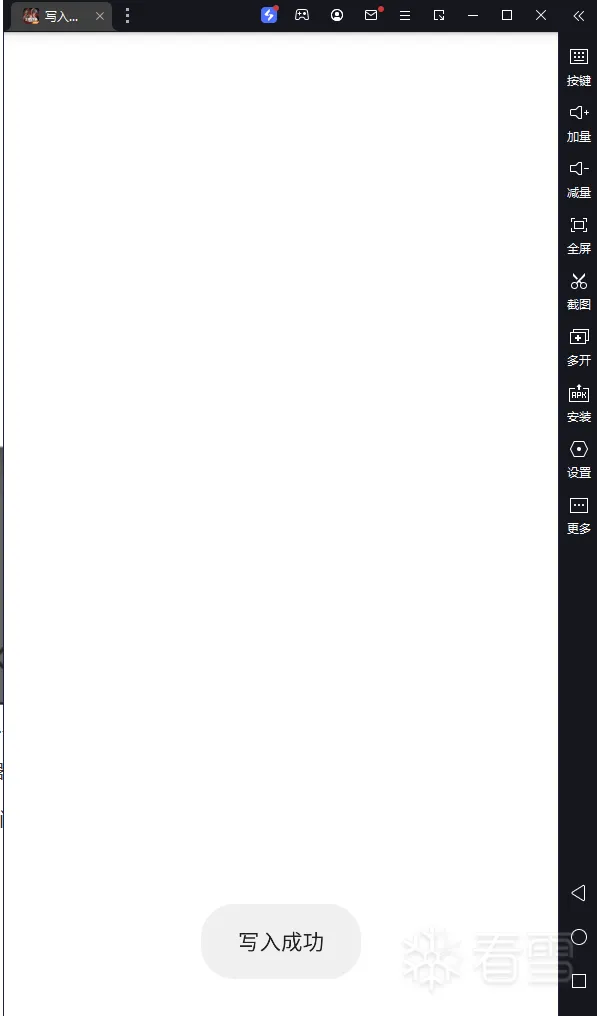
那么我们第一步该怎么做呢?不急我们先来看看这个程序在写入时有什么特征:
我们可以看到它成功写入时会使用Toast.makeText方法在屏幕上显示短暂的提示信息,那么我们可以尝试将它作为突破口进行Hook。
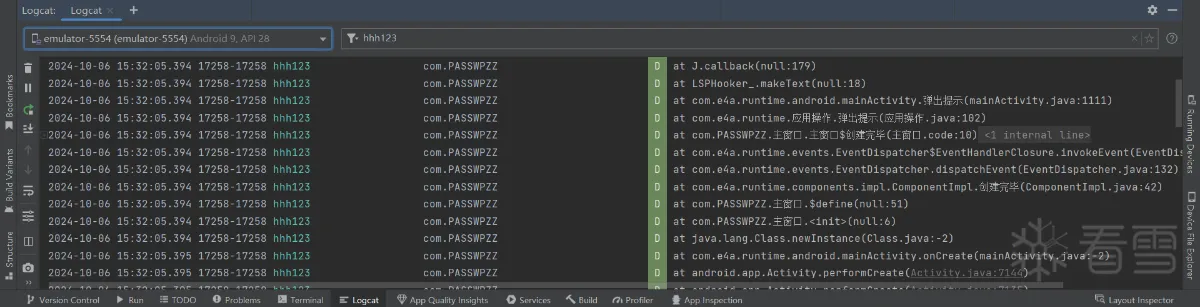
我们尝试运行一下,看能否打印出我们要的堆栈信息:
我们可以从堆栈信息中看出调用传入参数包含写入成功的android.widget.Toast类下makeText方法的,是com.e4a.runtime.android.mainActivity类下的弹出提示方法,你们肯定好奇为什么这玩意的方法名还是中文,其实这个APP是用E4A写的,E4A又称易安卓,是一个快速上手操作简便的中文开发安卓程序的软件,所以有中文是正常的。
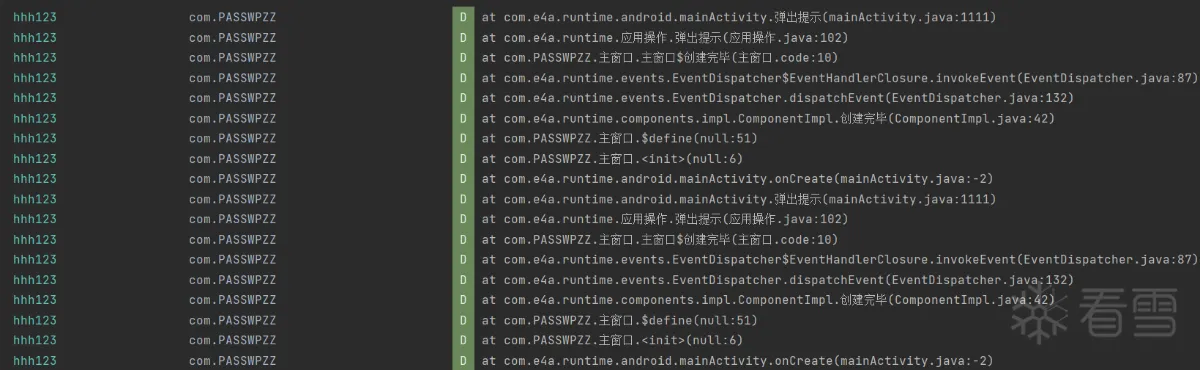
那么我们尝试把调用堆栈中有价值的方法进行Hook,我们需要先看看这些有价值的方法都有什么特征。可以看出有价值的方法所属类都有两个共同点,就是类名要么包含com.e4a.runtime或者要么包含com.PASSWPZZ,那我们可以获取堆栈跟踪元素后进行Hook,什么意思呢?其实就是把之前的打印堆栈信息中遍历堆栈跟踪元素后就不直接打印它们的信息了,而是获取到它们的类名和方法名,这样是不是就可以进行Hook了,为了确认没有Hook错方法,我们就把Hook了的堆栈跟踪元素的信息打印确认一下即可。这样是不是就可以获取到这些方法的参数和返回值了?事不宜迟,咱们说干就干!
让我们来看看运行以上代码得到的结果是否如我们所愿吧!
可以从上图看出以上的方法确实是我们需要Hook的有价值的方法,那这些方法的参数和返回值是怎样的呢?如下图所示:
可以从上图看出来这些方法的参数没有一个像文件存储路径的,那这该怎么办?我们是不是没办法解决了,小问题,既然这条路走不通,那就换条路走,比如说Hook写入文件的方法。
如果要Hook写入文件的方法,安卓的写入文件有好几种写入方式,我们不知道这个APP是使用的哪种写入文件的方式,这种情况我们也只能一种种方式去尝试,那么我们先了解一下Java的IO流。
开发者在Android中使用Java的IO流可以轻松地进行文件的读取和写入操作。对于本地文件系统,FileInputStream和FileOutputStream是常用的类,适用于处理各类文件。接下来我们对Java的IO流进行讲解:
1. IO流简介
IO流(输入/输出流)是Java中处理文件和数据流的一种方式,它提供了对数据的读取(输入)和写入(输出)的能力。
2. FileInputStream和FileOutputStream
3. 优缺点分析
优点:
缺点:
4. 代码示例
以下是一段Java的IO流代码示例:
代码说明:
好了,现在我们对Java的IO流有了了解,现在大家应该知道我们需要Hook什么方法了吧!没错就是Hook构造方法,FileOutputStream类下的构造方法,这样我们就可以获取到写入文件的路径。
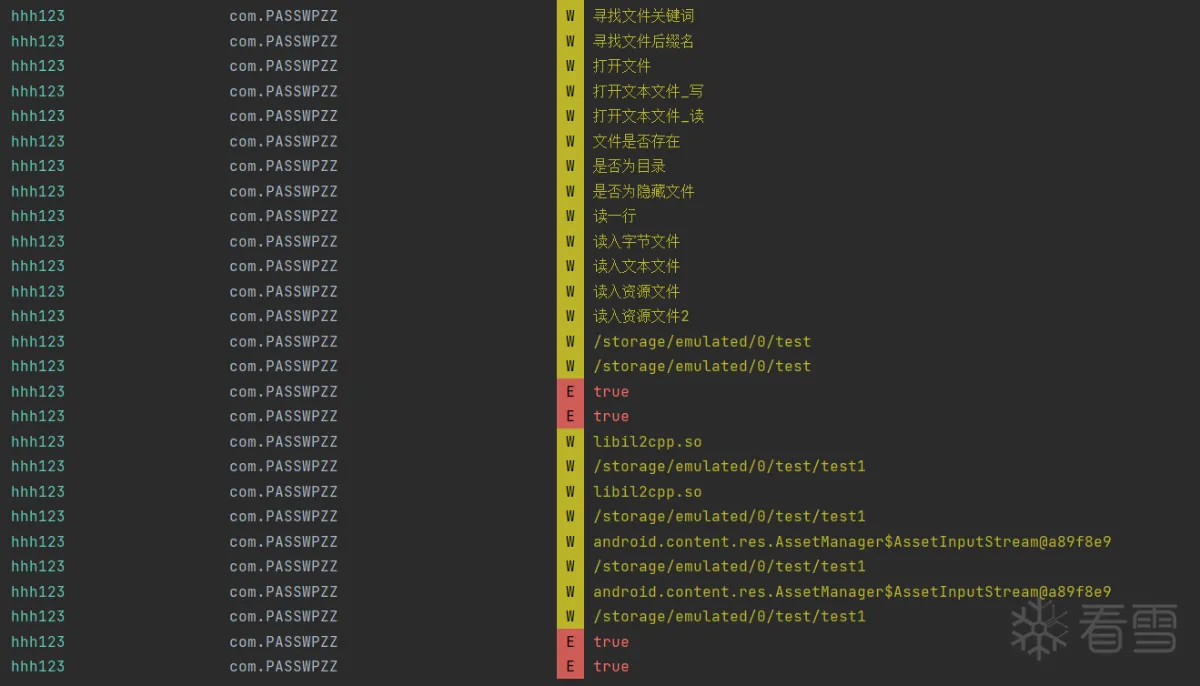
我们可以通过XposedBridge.hookAllConstructors方法来Hook指定类的所有构造函数,这里我们除了打印它的参数以外,我们还打印了堆栈信息,主要是想看看是什么方法调用了Java的IO流来写入文件。
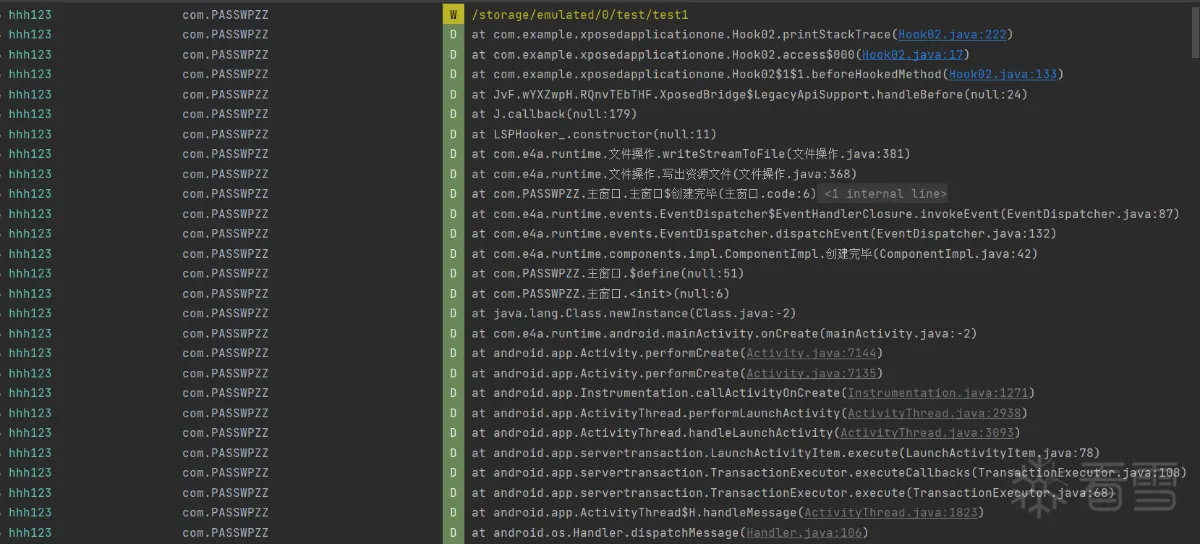
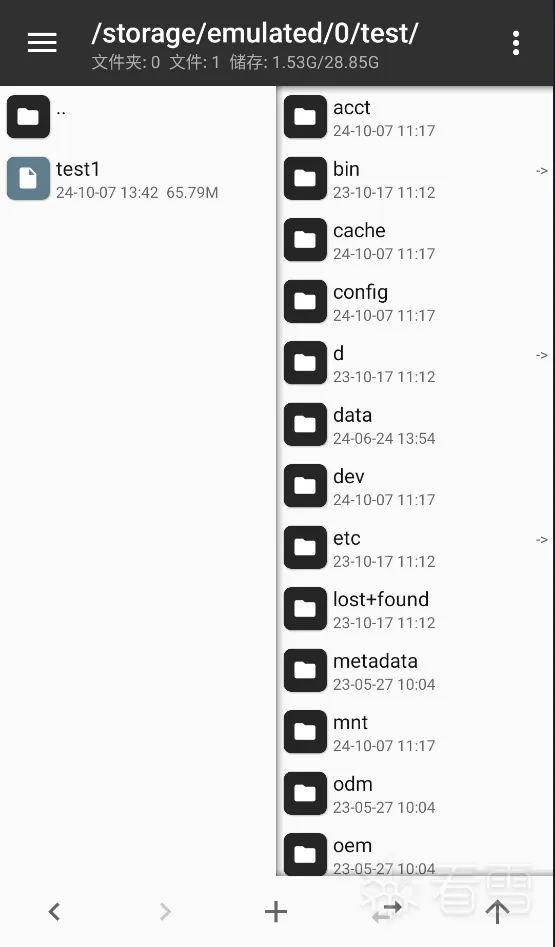
我们打开日志一看,第一眼就看到了泛着黄光的文件路径,看来我们思路没有找错,那我们赶紧去看看这个路径下写入的文件吧!
看来我们确实找到了写入文件的路径,但我们Hook就这样结束了?不不不,我们还有些好玩的没有尝试,即使已经Hook到了我们要的内容。现在我们不仅有了写入文件的路径,还有了其堆栈信息,我们可以从堆栈信息中看出com.e4a.runtime.文件操作类是进行写入文件的主要类,那么接下来我们换一种方法来Hook写入文件的路径,我们可以通过此种方式Hook到指定类下的所有方法。
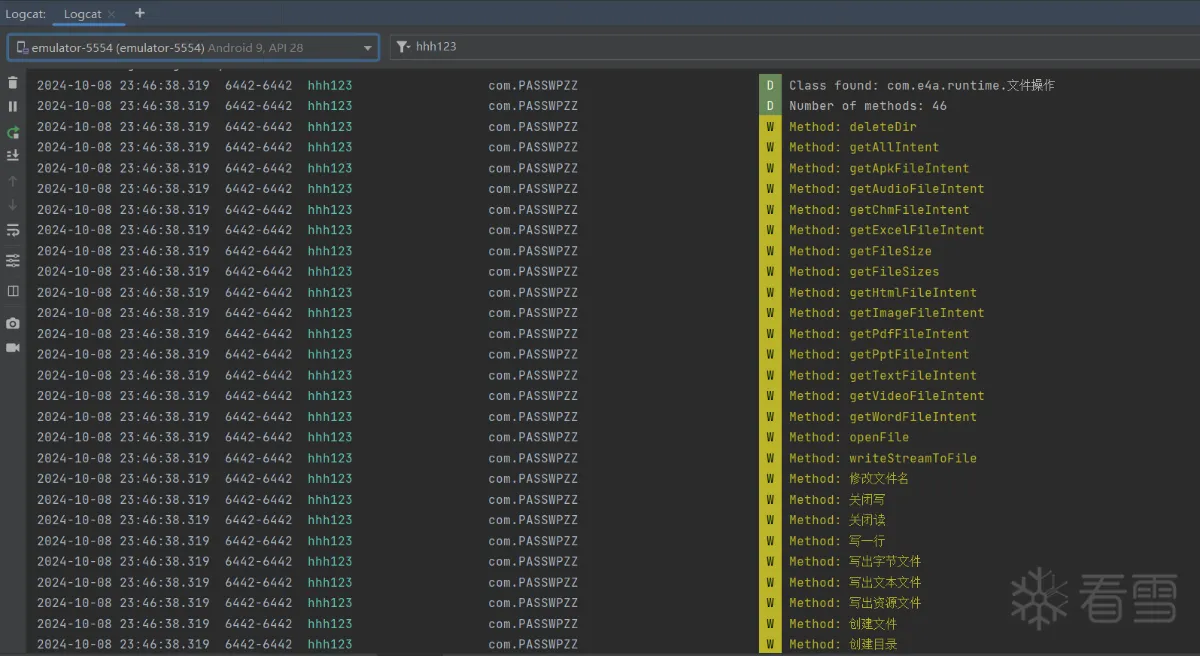
我们在Hook到指定类下的所有方法之前,先看看指定类下类名、方法个数以及所有的方法名称,这样我们对类下的情况就更加的清楚了,这样写Hook代码时就更加的方便了。
我们可以看到文件操作类下有46个方法,还挺多的,接下来我们就需要用到java中的反射来Hook指定类下的所有方法。
主要就是通过类加载器将类的class对象成功加载,这个类的class对象是可以给反射用的,这样就可以通过反射来获取类下的所有方法,从而帮助我们进行Hook代码的编写。
参数有很多,但是有价值的也就后面出现的写入文件的路径。这个方法虽然看起来比之前的麻烦的多,但这个方式只要你确定你要的东西在一个类中,就可以直接火力覆盖,管它什么牛鬼蛇神全给它Hook就完事了。
这次关于Hook的写法我在实战中并不会全部都用上,我只是把我觉得有意思的方法写下来,如果要全面的学习写Hook代码,可以在网上搜索其他大佬写的博客,相信大家一定会有收获的。
字符
二进制位
a
01100001
b
01100010
c
01100011
abc
01100001 01100010 01100011
按顺序读取的六个二进制位
转换得到的十进制
base编码表对应字符
011000
24
Y
01 0110
22
W
0010 01
9
J
100011
35
j
按顺序读取的六个二进制位
转换得到的十进制
base编码表对应字符
011000
24
Y
01 0110
22
W
0010 01
9
J
100011
35
j
011001
33
h
00 (0000)
0
A
(000000)
0
A
(000000)
0
A
base64字符
字符对应的十进制
六个二进制位为一组的字节(base64)
八个二进制位为一组的字节
八位一字节对应的字符
删除补充字节后的字节
最后得到的字符
Y
24
011000
011000 01
a
01100001
a
W
22
010110
0110 0010
b
01100010
b
J
9
001001
01 100011
c
01100011
c
j
35
100011
011001 00
d
01100100
d
h
33
011001
0000 0000
补充字节
A
0
000000
00 000000
补充字节
=
0
000000
=
0
000000
A: 0x67452301
B: 0xefcdab89
C: 0x98badcfe
D: 0x10325476
a=A; b=B; c=C; d=D;
A: 0x67452301
B: 0xefcdab89
C: 0x98badcfe
D: 0x10325476
a=A; b=B; c=C; d=D;
A = a + A;
B = b + B;
C = c + C;
D = d + D;
A = a + A;
B = b + B;
C = c + C;
D = d + D;
a=((a+F + K[i] + M[g])<<s[i])+ b
a=((a+F + K[i] + M[g])<<s[i])+ b
if(0 <= i <= 15){
F1 = F(b, c, d);
g = i;
}
else if(16 <= i <= 31){
F2 = G(b, c, d);
g = ((i * 5) + 1) % 16;
}
else if(32 <= i <= 47){
F3 = H(b, c, d);
g = ((i * 3) + 5) % 16;
}
else{
F4 = I(b, c, d);
g = (i * 7) % 16;
}
if(0 <= i <= 15){
F1 = F(b, c, d);
g = i;
}
else if(16 <= i <= 31){
F2 = G(b, c, d);
g = ((i * 5) + 1) % 16;
}
else if(32 <= i <= 47){
F3 = H(b, c, d);
g = ((i * 3) + 5) % 16;
}
else{
F4 = I(b, c, d);
g = (i * 7) % 16;
}
F(X, Y, Z) = (X & Y) | (~X & Z)
G(X, Y, Z) = (X & Z) | (Y & ~Z)
H(X, Y, Z) = X ^ Y ^ Z
I(X, Y, Z) = Y ^ (X | ~Z)
F(X, Y, Z) = (X & Y) | (~X & Z)
G(X, Y, Z) = (X & Z) | (Y & ~Z)
H(X, Y, Z) = X ^ Y ^ Z
I(X, Y, Z) = Y ^ (X | ~Z)
K[] = {0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391}
K[] = {0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391}
S[] = {7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21}
S[] = {7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21}
MD5 Hash: 65a8e27d8879283831b664bd8b7f0ad4
MD5 Hash: 65a8e27d8879283831b664bd8b7f0ad4
算法
摘要长度
SHA-1
160
SHA-224
224
SHA-256
256
SHA-384
384
SHA-512
512
SHA Hash: dffd6021bb2bd5b0af676290809ec3a53191dd81c7f70a4b28688a362182986f
SHA Hash: dffd6021bb2bd5b0af676290809ec3a53191dd81c7f70a4b28688a362182986f
算法
摘要长度
HmacMD5
128
HmacSHA1
160
HmacSHA256
256
HmacSHA384
384
HmacSHA512
512
HmacMD2
128
HmacMD4
128
HmacSHA224
224
Message Digest: 57e61895de001a806d5a22ba0e4ee2011a02c258f00e121165ba855dbf271321
Message Digest: 57e61895de001a806d5a22ba0e4ee2011a02c258f00e121165ba855dbf271321
ZEi7hkmMp+Dr8CE3zdeHkg==
12345678
ZEi7hkmMp+Dr8CE3zdeHkg==
12345678
Encrypted Data: 0l99zkQGHvlWysaJwl5naA==
Decode Data: a12345678
Encrypted Data: 0l99zkQGHvlWysaJwl5naA==
Decode Data: a12345678
package com.java.Reverse;
package com.java.Reverse;
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
import javax.crypto.Cipher;
import java.security.KeyFactory;
import java.security.PrivateKey;
import java.security.PublicKey;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
import javax.crypto.Cipher;
import java.security.KeyFactory;
import java.security.PrivateKey;
import java.security.PublicKey;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
public class RsaBase {
public static BASE64Encoder base64Encoder;
public static BASE64Decoder base64Decoder;
public static String pub_str = "MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCB...";
public static String pri_str = "MIICdQIBADANBgkqhkiG9w0BAQEFA...";
public class RsaBase {
public static BASE64Encoder base64Encoder;
public static BASE64Decoder base64Decoder;
public static String pub_str = "MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCB...";
public static String pri_str = "MIICdQIBADANBgkqhkiG9w0BAQEFA...";
static {
base64Encoder = new BASE64Encoder();
base64Decoder = new BASE64Decoder();
}
static {
base64Encoder = new BASE64Encoder();
base64Decoder = new BASE64Decoder();
}
public static PublicKey getPublicKey(String pub_key) throws Exception {
...
}
public static PrivateKey getPrivateKey(String pri_key) throws Exception {
...
}
public static PublicKey getPublicKey(String pub_key) throws Exception {
...
}
public static PrivateKey getPrivateKey(String pri_key) throws Exception {
...
}
public static byte[] encrypt(byte[] encrypt_str) throws Exception {
...
}
public static byte[] decrypt(byte[] decrypt_str) throws Exception {
...
}
public static byte[] encrypt(byte[] encrypt_str) throws Exception {
...
}
public static byte[] decrypt(byte[] decrypt_str) throws Exception {
...
}
public static String bytesToHex(byte[] bytes) {
...
}
public static String bytesToHex(byte[] bytes) {
...
}
public static void main(String[] args) throws Exception {
String str_base64 = "0123456789";
byte[] ec_cipher = encrypt(str_base64.getBytes());
System.out.println("明文:" + str_base64);
System.out.println("密文:" + bytesToHex(ec_cipher));
byte[] deByteStr = decrypt(ec_cipher);
String deString = new String(deByteStr);
System.out.println("解密结果:" + deString);
}
public static void main(String[] args) throws Exception {
String str_base64 = "0123456789";
byte[] ec_cipher = encrypt(str_base64.getBytes());
System.out.println("明文:" + str_base64);
System.out.println("密文:" + bytesToHex(ec_cipher));
byte[] deByteStr = decrypt(ec_cipher);
String deString = new String(deByteStr);
System.out.println("解密结果:" + deString);
}
package com.java.Reverse;
/*
RsaHex类演示了RSA加密解密的过程,包括密钥对生成、加密、解密等操作。
*/
import javax.crypto.Cipher;
import java.math.BigInteger;
import java.security.*;
import java.security.interfaces.RSAPrivateKey;
import java.security.interfaces.RSAPublicKey;
import java.security.spec.RSAPrivateKeySpec;
import java.security.spec.RSAPublicKeySpec;
package com.java.Reverse;
/*
RsaHex类演示了RSA加密解密的过程,包括密钥对生成、加密、解密等操作。
*/
import javax.crypto.Cipher;
import java.math.BigInteger;
import java.security.*;
import java.security.interfaces.RSAPrivateKey;
import java.security.interfaces.RSAPublicKey;
import java.security.spec.RSAPrivateKeySpec;
import java.security.spec.RSAPublicKeySpec;
public static BigInteger publicN;
public static BigInteger publicE;
public static BigInteger privateN;
public static BigInteger privateD;
[培训]《冰与火的战歌:Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2024-10-11 12:38
被黎明与黄昏编辑
,原因: