本文章仅做移动安全学习交流用途 严禁作其他用途
目标版本是8.55.6
目标算法是s***leSign 目标位置:0xbe11c
所用工具: IDA Pro, 010 Editor, unidbg, frida
把目标so拖进ida 让ida狠狠的分析这个so
当IDA分析完成后 按快捷键G跳转到我们目标函数的位置
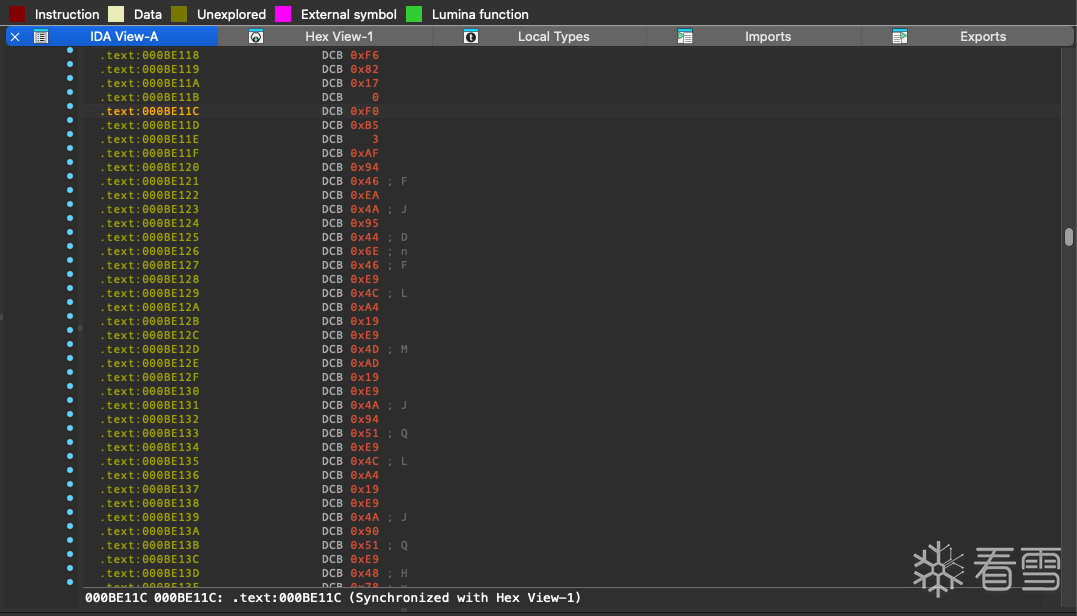 可以看到这个地方的都被识别成数据段了 按C把它强制转成代码 再按P把它定义成一个函数
可以看到这个地方的都被识别成数据段了 按C把它强制转成代码 再按P把它定义成一个函数
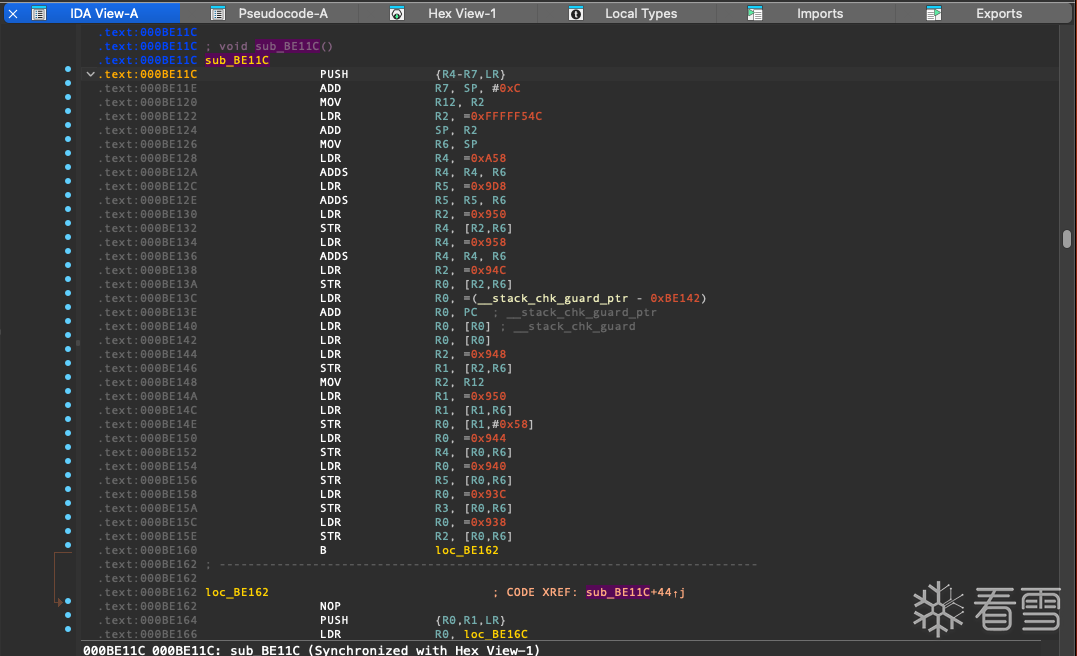 正当我按下f5以为可以高枕无忧,狠狠分析的时候,显示的内容却让我傻了眼
正当我按下f5以为可以高枕无忧,狠狠分析的时候,显示的内容却让我傻了眼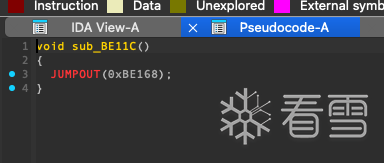
发现有花指令[垃圾指令]的存在干扰了IDA的线性分析 索性撂挑子不干了 直接显示一个JUMPOUT
去到0xBE168看看怎么个事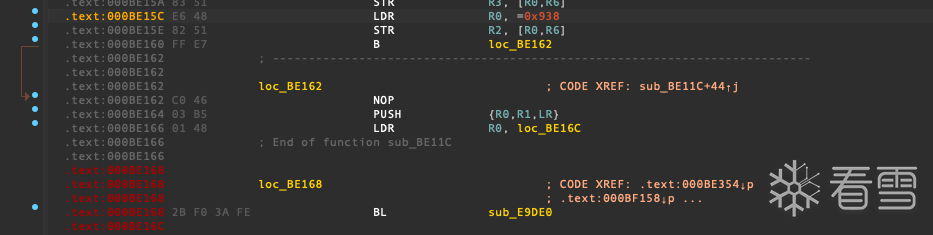
可以看到 当程序正常的执行流走到0xBE164处先进行了一个压栈的操作 随后加载了一个DWORD存储到R0然后就跳转到了SUB_E9DE0函数,到这里IDA就飘红了
再去看看SUB_E9DE0函数: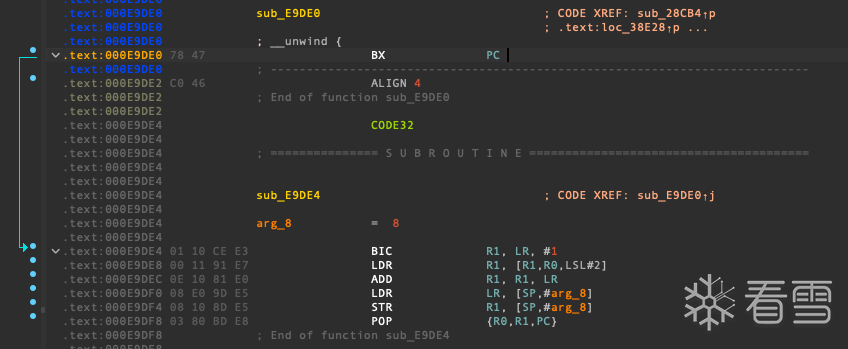
简单分析一下可以看出 这里貌似是在做某种运算?把传入的数值做某种运算后写入栈中,最终弹出PC寄存器使得程序的执行流去到某个地方
到这里 大概可以看出 IDA之所以飘红的原因 是因为IDA是线性反汇编 这种类似于间接跳转的代码块 因为缺少上下文 IDA并不知道这里去到哪里 所以显示的JUMP OUT 从而达到对抗静态分析的目的
上面只是从ida来分析 解决对抗花指令还得从动态执行来
先搭个unidbg架子
发现可以直接跑起来,不需要补环境 还是很不错的
也取到了一份执行过程中的tracecode
使用010 Editor 打开trace文件转到0xbe164处

基于前面从ida中的简单分析 可以看出 在压栈操作后这段代码是把加载的一个跳转数x<<2后加上因为bl #0x400e9de0处而改变的lr寄存器的值 得到一个最终的跳转地址 从而改变程序执行流的位置
即 jump_addr = x * 2 + bl_addr + 4; bl_addr => bl指令所在的地址
注意到这个跳转代码块首尾有压栈出栈(恢复寄存器现场)的操作 故可在压栈处直接改成直接跳转 并不会影响寄存器现场
比如0xbe164处的汇编 可以_修改为: B 0xc5490 _
这样就可以直接patch真实跳转地址 从而让ida更好的反汇编
有了间接跳转块代码的分析 就可以开始写ida python 愉快的去花了
从整个trace文件中搜索 push {r0, r1, lr} 发现共有8097处 汇编代码 且下方紧跟着的就是 ldr r0, [pc, #4]
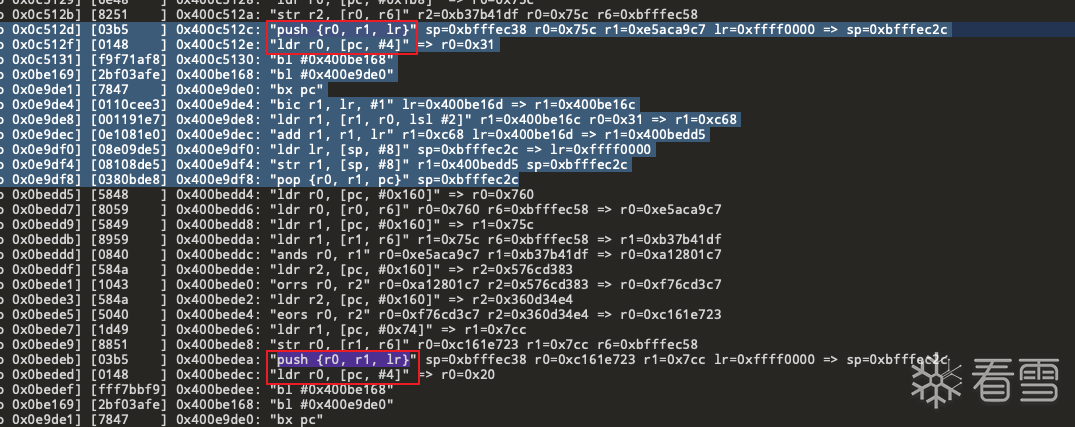
那就可以根据这两行汇编 作为间接跳转块的特征 进行去花
因为ida把大部分汇编代码都识别成数据了 一个一个按c去强转不太现实 但不强转为汇编 用ida python的api 获取当前地址的汇编代码又会发生错误
所以我决定使用capStone 对每一条汇编进行单独解析
在ida中执行脚本后 控制台输出了每一个间接跳转块的真实跳转地址:
把这些真实跳转地址保存到一个patch_jump.txt文件
再写一段ida python脚本 来patch每一个间接跳转点
保存patch完的so文件libxxmain_fix.so 再次拖入ida分析 去到 0xBE164 处
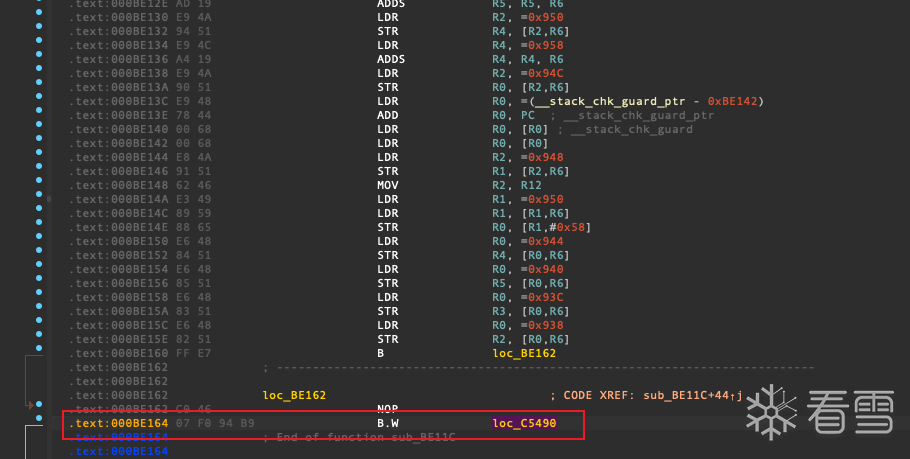
可以看到此处的汇编代码已经变为直接跳转到目标地址了
再次f5

还是有一个jump out 是怎么回事呢 跳到0xbedd4看看
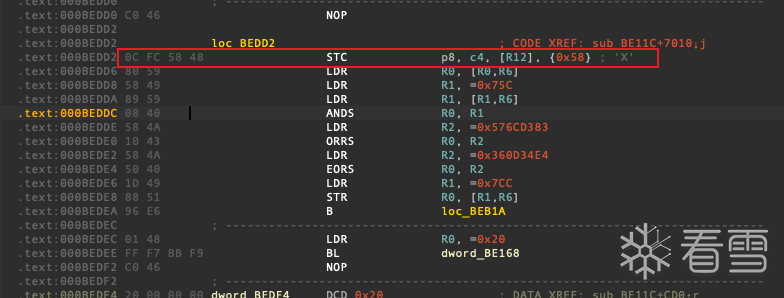
原来是ida把此处识别为了arm汇编代码 只要在0xbedd2处按d 转换为数据 再在0xbedd4处按c 转为汇编即可
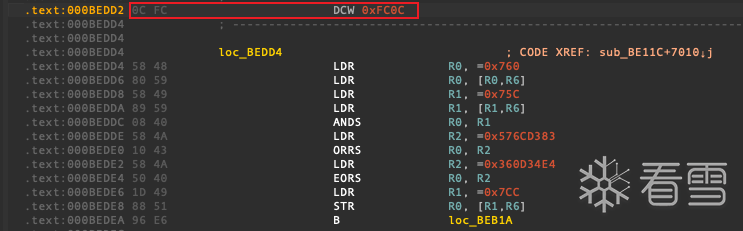
后续多个jumpout大多都是这个问题 如法炮制即可 再在ida左下角选择重新分析
经过多次修复 sub_BE11C 这个函数终于能看到一些jni细节了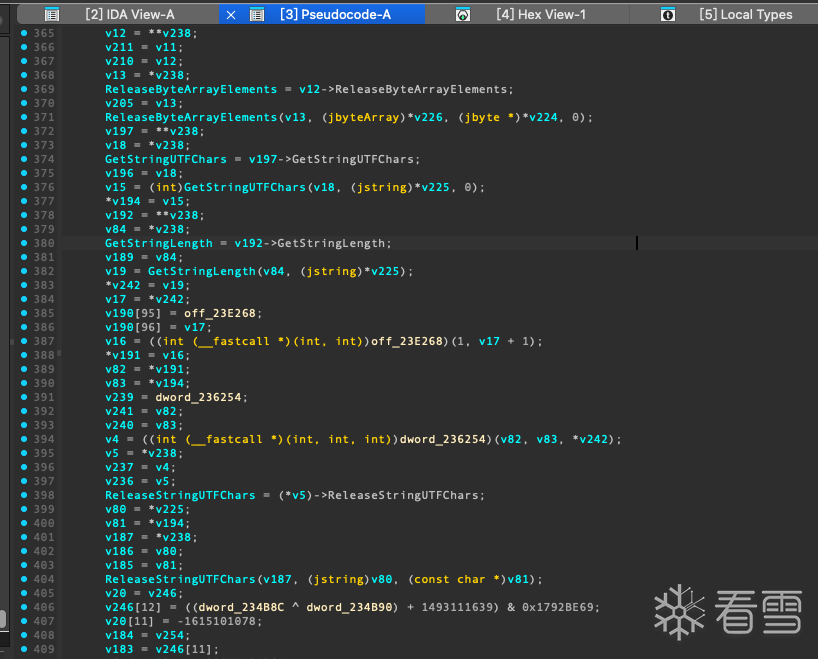
把patch完成的so 放入unidbg中 再次调用目标方法 可以正常跑起来 没有报错 且结果与patch前一致 说明patch并没有改变程序原来的执行流程 图就不放了
当分析一个算法的具体过程的时候 在入参不变的情况下 输出的结果却一直变化 这给分析算法过程增加了不少的工作量 为了减小因结果变化而增加的工作量 对结果进行固定无疑是最好的选择
程序在unidbg中跑起来后,发现即使固定函数的输入 结果依然在变化 猜测结果的内容应该与某些动态参数有关
随机数?时间?还是其他什么因素导致了结果的变化 只需在unidbg中把对应的函数结果固定即可
固定结果后 重新用unidbg取一份trace文件traceCode.txt
固定了结果后发现在时间戳的前面,正好是32个字符,猜测是某种哈希算法 猜测是MD5哈希校验
从trace文件中小端序搜索结果的前8位(四个字节)
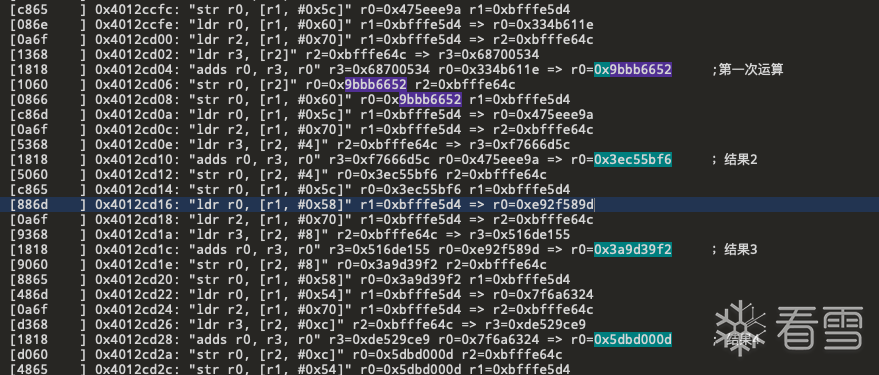
在0x12CD04处是结果第一次生成的地方 且下方不远处也有结果2,3,4 跳转到ida看看

找一份md5实现代码:
既然知道了是md5哈希校验,在trace中搜索标准md5中用的魔数表,初始iv,都没有搜索到 那大概率是改过iv和魔数表了 接下来就是从trace中逆推出明文 初始iv 魔数了
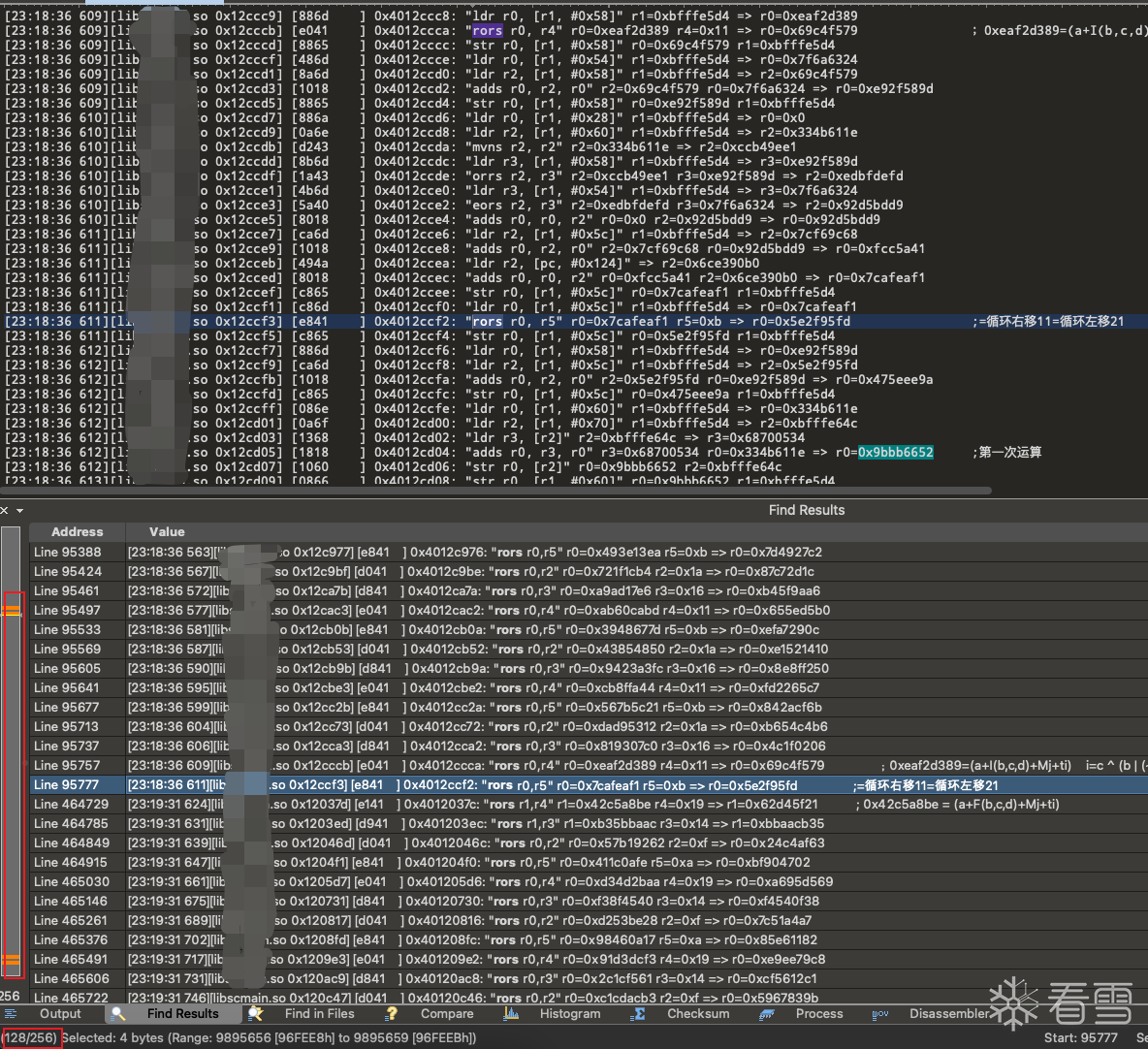
在trace文件中搜索循环右移(rors) 正好在结果的上方不远处就有一个rors 且这个循环右移是第128个循环右移 从左边的搜索结果分布图来看 搜索结果很集中 说明程序的其他地方没有运用到循环右移
由上面md5哈希校验代码可知 一次md5哈希校验 有64轮计算 其中一轮计算有一次循环左移 而这里搜索出了128个循环右移 猜测明文长度超过了64个字节 或者进行了多次md5计算 也可能是修改了计算次数
根据循环右移搜索的结果来看 前64次逻辑左移与后64逻辑左移使用的偏移数与标准md5所使用的一致
在trace文件中找到第一次rors 往上找寻代码
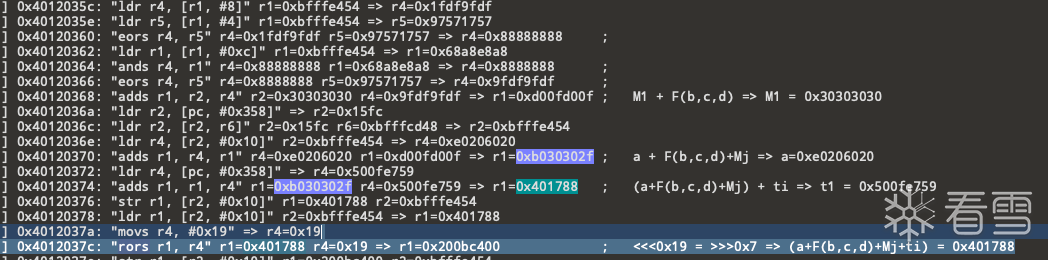
利用上面的分析思路 在整个trace文件中找出从M1至M128 如下:
再像上面一样 从trace中取出整个码表
依据上面的初始模数与码表 写一份magicMD5
前面分析了传入魔改md5的明文 接下来研究明文如何生成的 前面八个字节很明显是我们固定的时间 从第九个字节开始分析
祭出龙哥的HexSearch大法
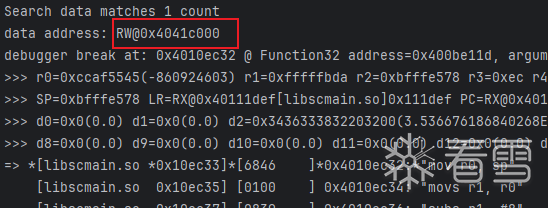
程序在0x10ec32处断下 并且告知 0x4041c000处存放了搜索的数据
对这个地址进行tracewrite看看是哪里写入的这段明文
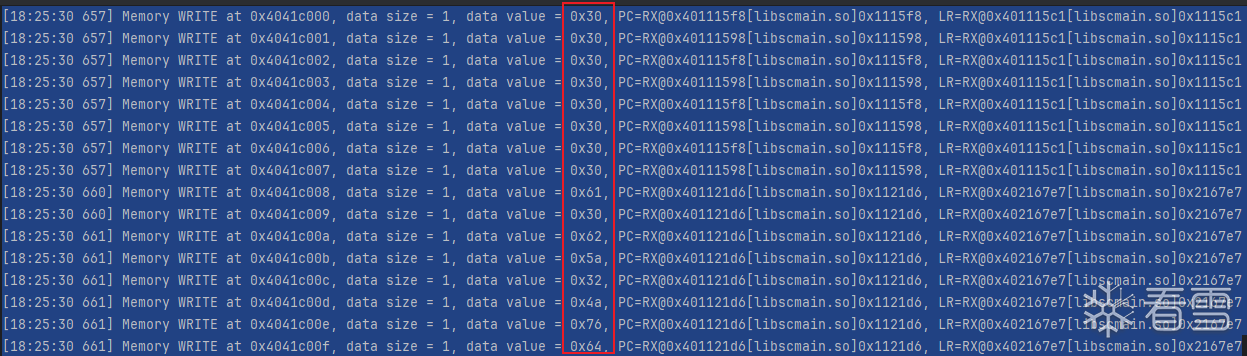
从日志中看出在0x1121d6处对地址写入了明文 再到trace中搜索一下这个地址
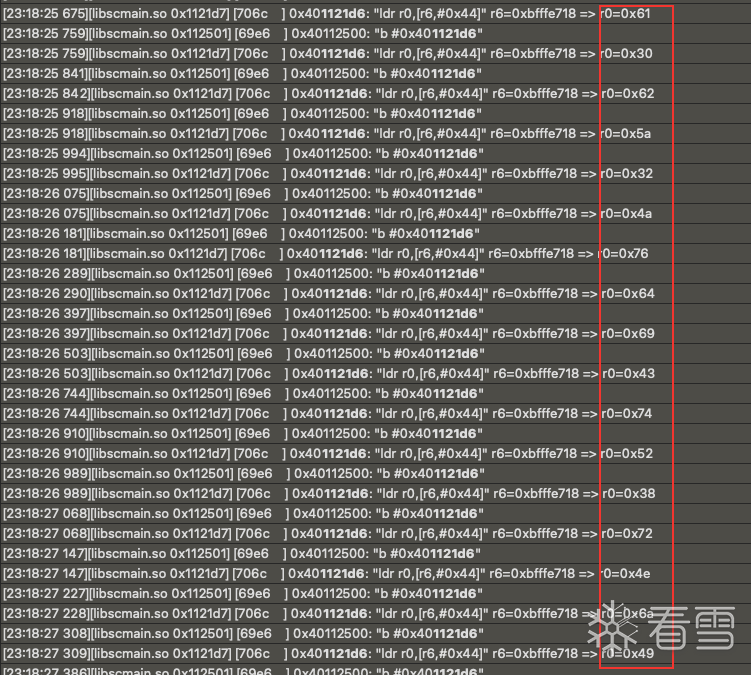
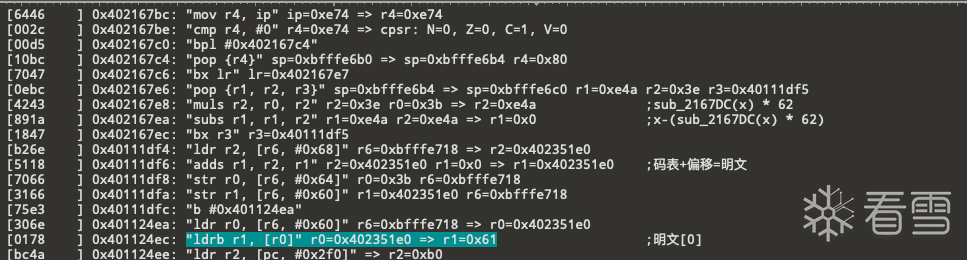
发现与我们明文的一部分一致 往上查找明文0x61从何处来的
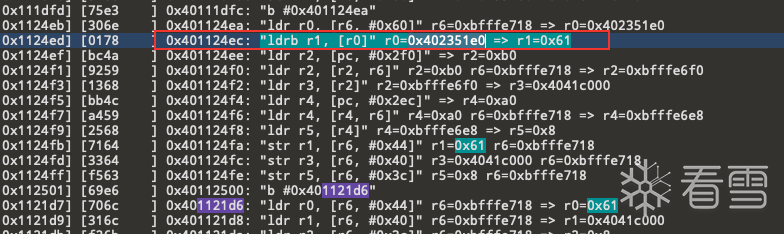
往上寻找0x61生成可以看出 这是直接从0x402351e0处加载一个字节得到的0x61 在0x1121d6 处下个断点看看0x402351e0这个地方存放的什么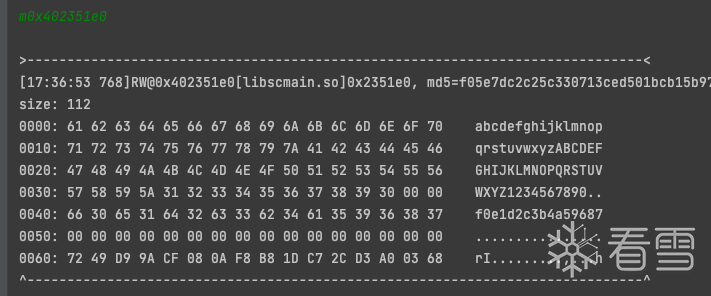
0x402351e0处存放的似乎是一个码表 猜测是经过某种运算 得到一个偏移 随后从码表中加载这个偏移处的字节作为明文
到IDA中看看这部分生成明文的代码
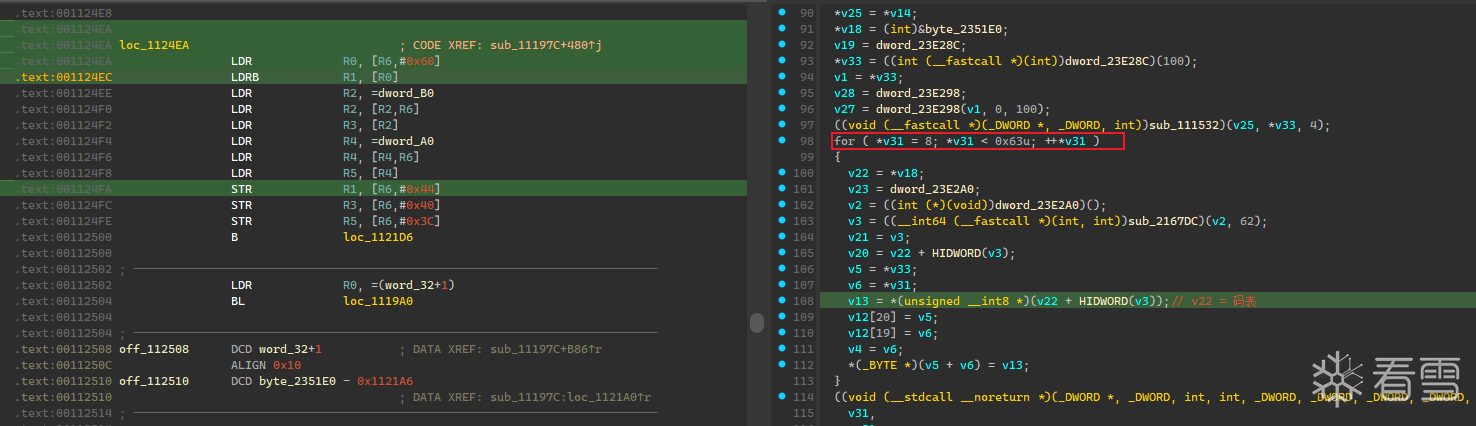
从ida的分析来看这里有一个进行了91次的循环 正好对应了明文的91个字符 sub_2167DC函数返回的结果对应着明文位于码表中的偏移 hook一下看看
 发现结果偏移的结果与明文对照码表中的结果一致
发现结果偏移的结果与明文对照码表中的结果一致
接下来看看这个偏移是如何生成的: hook sub_2167DC的第一个参数v2 得到 0xe4a
第二个参数固定为62不必多说 是码表的长度

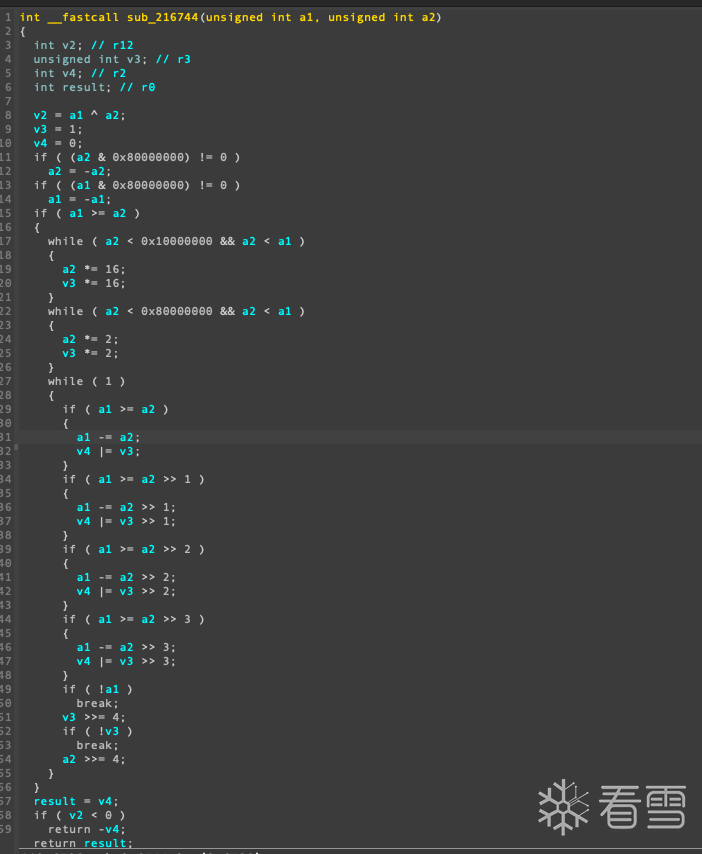
结合tarace汇编与伪c来看 sub_2167DC函数 是调用sub_216744并传入参数a1与固定整数62 随后用a1-(得到的结果*62) = 码表中的偏移
即: 码表中的偏移 = x - (sub_216744(x) * 62)
查看sub_216744函数伪c 应该是某种自写的算法 不分析了 直接丢给gpt 让他转成python代码
接下来就是寻找入参v2的生成了 已知hook到第一次入参为0xe4a 在trace中向上寻找生成
直接上代码
核心思路与前32位一致 在分析前32位时发现有进行两次md5 结果的后32位也是md5
为节省篇幅 长话短说:
其中a,c,d,f,g明文块都是简单异或运算 在trace中就能搜到 不作赘述
上方分析了md5明文的组成部分 其中特别注意到明文块b 长度为32个字节 猜测是sha256 在trace文件中搜索sha256校验中的标准魔数 并未搜索到 猜测是魔改过了
在trace文件中搜索疑似sha256结果的前四个字节 看看在哪生成的
发现并未搜索出结果 往上分析才发现 原来b明文块是经过了异或0xcd运算后的 将结果异或0xcd后再次搜索 有了结果
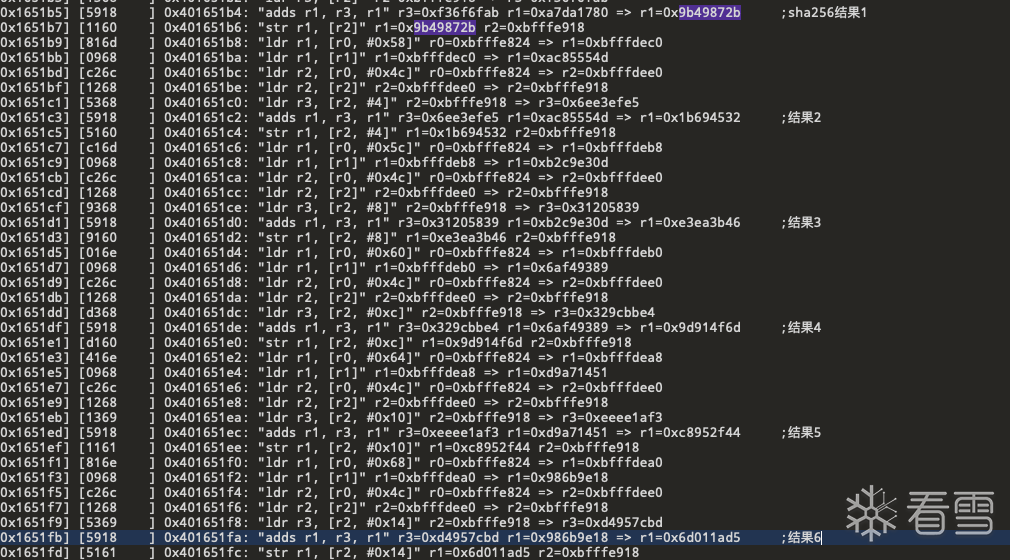
跳转到ida看看
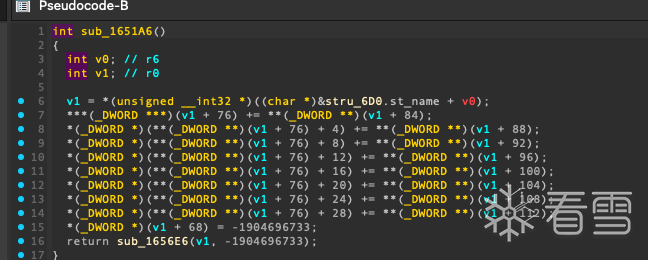
在ida中看到了非常明显的sha256计算特征
综上 确定了这32字节的算法就是经过sha256校验后再异或0xcd
确定了是sha256算法 先寻找sha256的明文
由sha256校验的密码学相关知识可知 sha256算法内核心步骤为:
利用bigSig0的旋转右移进行bigSig定位 在trace文件中搜索旋转右移相关
直接搜索ror rors(旋转右移) 发现并没有相关结果 猜测可能是变换了另外一种形式实现的旋转右移
在trace文件中搜索lsrs(逻辑右移) 发现有很多结果 正则筛选一下 (lsrs*#2)
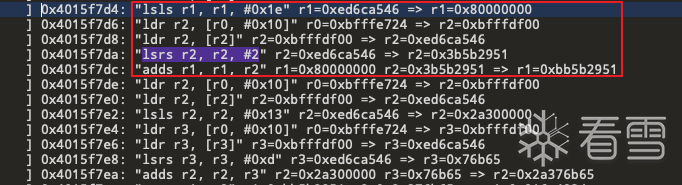
发现在0x15f7d4处有逻辑左移0x1e 往下看到有逻辑右移2 最终相加 这样的运算等价于旋转右移
跳到ida看看

发现此处也有类似sha256计算的代码块 经过简单分析 可以看出 伪代码中 v44就是当前参与计算的明文块
dword_22A0F4[**(_DWORD **)(v39 + 72)] 则是参与当前计算的k表
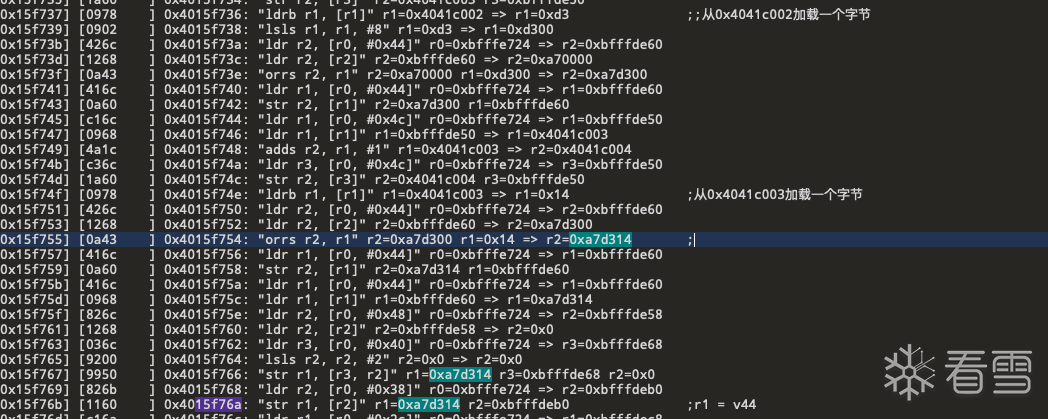
在trace文件中 查看v44的赋值简单分析可以看出 明文存放于0x4041c000处 在0x15f76a处下个断点 看看内存
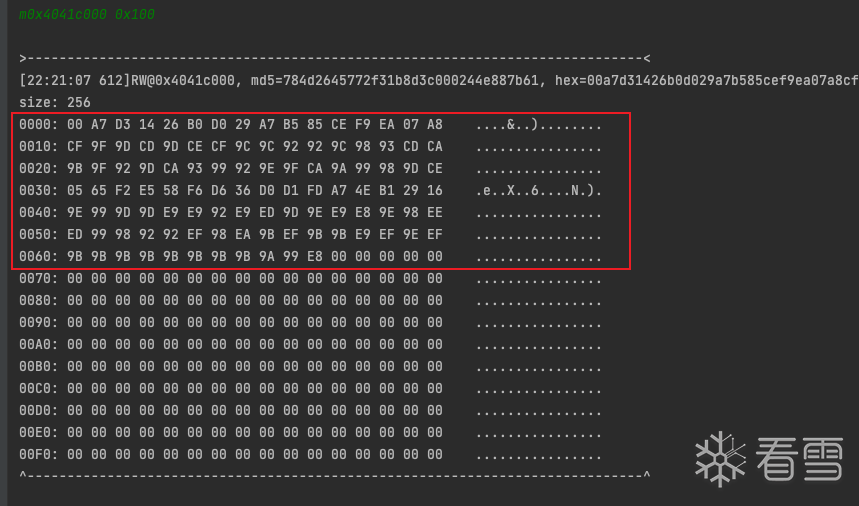
与trace中分析得到的参与计算的明文一致 此处就是sha256参与计算的明文了
至此sha256计算中的初向量 k表 明文 都已找到
找一份标准sha256代码 更改其中的iv和k表 尝试还原该魔改sha256算法
发现输出结果与上面分析md5明文的一致 分析明文完成
明文的组成也比较简单 就是一些简单异或 在trace中均可分析出来 就不作过多赘述了 至此,整个算法的还原完成
样本难度中等 综合了花指令 魔改算法 ollvm混淆 是个练手的好样本
因为混淆的存在 不能过分依赖ida的f5进行静态分析 在trace中进行算法还原是个不错的选择
小弟初接触此类混淆算法还原 若有表述不当之处 还望各位大牛批评指正,共同进步 Xiaoochenn_
希望文章对正在学习移动安全的伙伴有所帮助
感谢星球伙伴 @落叶 的算法笔记
public class SecurityUtil extends AbstractJni {
private final AndroidEmulator emulator;
private final VM vm;
private final Module module;
private final DvmObject NativeLibHelper;
SecurityUtil() {
emulator = AndroidEmulatorBuilder.for32Bit()
.setProcessName("xxxxx.android.xxxx")
.addBackendFactory(new Unicorn2Factory(true))
.build();
final Memory memory = emulator.getMemory();
memory.setLibraryResolver(new AndroidResolver(23));
vm = emulator.createDalvikVM();
vm.setVerbose(true);
vm.setJni(this);
new AndroidModule(emulator, vm).register(memory);
DalvikModule dm = vm.loadLibrary(new File("libxxmain.so"), true);
module = dm.getModule();
dm.callJNI_OnLoad(emulator);
NativeLibHelper = vm.resolveClass("xxxxx/android/xxxxxxxx/SecurityUtil").newObject(null);
}
public void Sign(){
String traceFile = "traceCode.txt";
PrintStream traceStream;
try {
traceStream = new PrintStream(new FileOutputStream(traceFile), true);
emulator.traceCode(module.base,module.base+module.size).setRedirect(traceStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
byte[] bytes = {100,52,54,102,54,101,100,55,55,57,57,55,51,56,102,97,48,52,57,54,97,56,50,57,53,52,97,49,50,51,54,101};
ByteArray barr = new ByteArray(vm,bytes);
StringObject str = new StringObject(vm,"getdata");
String stringObject = NativeLibHelper.callJniMethodObject(emulator,"s***leSign([BLjava/lang/String;)Ljava/lang/String;",barr,str).toString().replace("\"","");
Inspector.inspect(stringObject.getBytes(StandardCharsets.UTF_8),"result");
return;
}
public static void main(String[] args) {
SecurityUtil securityUtil = new SecurityUtil();
securityUtil.Sign();
}
}
public class SecurityUtil extends AbstractJni {
private final AndroidEmulator emulator;
private final VM vm;
private final Module module;
private final DvmObject NativeLibHelper;
SecurityUtil() {
emulator = AndroidEmulatorBuilder.for32Bit()
.setProcessName("xxxxx.android.xxxx")
.addBackendFactory(new Unicorn2Factory(true))
.build();
final Memory memory = emulator.getMemory();
memory.setLibraryResolver(new AndroidResolver(23));
vm = emulator.createDalvikVM();
vm.setVerbose(true);
vm.setJni(this);
new AndroidModule(emulator, vm).register(memory);
DalvikModule dm = vm.loadLibrary(new File("libxxmain.so"), true);
module = dm.getModule();
dm.callJNI_OnLoad(emulator);
NativeLibHelper = vm.resolveClass("xxxxx/android/xxxxxxxx/SecurityUtil").newObject(null);
}
public void Sign(){
String traceFile = "traceCode.txt";
PrintStream traceStream;
try {
traceStream = new PrintStream(new FileOutputStream(traceFile), true);
emulator.traceCode(module.base,module.base+module.size).setRedirect(traceStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
byte[] bytes = {100,52,54,102,54,101,100,55,55,57,57,55,51,56,102,97,48,52,57,54,97,56,50,57,53,52,97,49,50,51,54,101};
ByteArray barr = new ByteArray(vm,bytes);
StringObject str = new StringObject(vm,"getdata");
String stringObject = NativeLibHelper.callJniMethodObject(emulator,"s***leSign([BLjava/lang/String;)Ljava/lang/String;",barr,str).toString().replace("\"","");
Inspector.inspect(stringObject.getBytes(StandardCharsets.UTF_8),"result");
return;
}
public static void main(String[] args) {
SecurityUtil securityUtil = new SecurityUtil();
securityUtil.Sign();
}
}
from capstone import *
from keystone import *
cs = Cs(CS_ARCH_ARM, CS_MODE_THUMB)
ks = Ks(keystone.KS_ARCH_ARM, keystone.KS_MODE_THUMB)
def generate(code, addr):
encoding, _ = ks.asm(code, addr)
return encoding
def get_opcode(machine_code, code_address):
assembly = []
for insn in cs.disasm(machine_code, code_address):
if insn.mnemonic != "":
assembly.append(insn.mnemonic)
assembly.append(insn.op_str)
return assembly
def patch_b(addr, target_addr):
code = f"B {hex(target_addr)}"
bCode = generate(code, addr)
if (bCode != None):
print(hex(addr)+“|”+code)
def patch(addr):
if idc.get_wide_word(addr) == 0xb503:
addr_ = addr + 2
if idc.get_wide_word(addr_) == 0x4801:
lr = ""
jump_code_addr = addr_ + 4 + 4
if (jump_code_addr % 4 == 2):
jump_code_addr = jump_code_addr - 2
jump_code = idc.get_wide_dword(jump_code_addr)
addr_ = addr_ + 2
code = idc.get_wide_dword(addr_).to_bytes(4, byteorder='little')
opcode = get_opcode(code, addr_)
if len(opcode) != 0 and opcode[0] == 'bl':
jump_addr_1 = int(opcode[1][1:], 16)
code = idc.get_wide_dword(jump_addr_1).to_bytes(4, byteorder='little')
opcode = get_opcode(code, jump_addr_1)
if len(opcode) != 0 and opcode[0] == 'bl':
jump_addr_2 = int(opcode[1][1:], 16)
code = idc.get_wide_dword(jump_addr_2).to_bytes(4, byteorder='little')
opcode = get_opcode(code, jump_addr_2)
if len(opcode) != 0 and opcode[0] == 'bx':
lr = jump_addr_1 + 4
elif len(opcode) != 0 and opcode[0] == 'bx':
lr = addr_ + 4
if lr != "":
r1 = idc.get_wide_dword(lr + (jump_code << 2))
real_jump_addr = lr + r1
patch_b(addr, real_jump_addr)
if __name__ == '__main__':
for i in range(0x9EB8, 0x218Acc):
patch(i)
from capstone import *
from keystone import *
cs = Cs(CS_ARCH_ARM, CS_MODE_THUMB)
ks = Ks(keystone.KS_ARCH_ARM, keystone.KS_MODE_THUMB)
def generate(code, addr):
encoding, _ = ks.asm(code, addr)
return encoding
def get_opcode(machine_code, code_address):
assembly = []
for insn in cs.disasm(machine_code, code_address):
if insn.mnemonic != "":
assembly.append(insn.mnemonic)
assembly.append(insn.op_str)
return assembly
def patch_b(addr, target_addr):
code = f"B {hex(target_addr)}"
bCode = generate(code, addr)
if (bCode != None):
print(hex(addr)+“|”+code)
def patch(addr):
if idc.get_wide_word(addr) == 0xb503:
addr_ = addr + 2
if idc.get_wide_word(addr_) == 0x4801:
lr = ""
jump_code_addr = addr_ + 4 + 4
if (jump_code_addr % 4 == 2):
jump_code_addr = jump_code_addr - 2
jump_code = idc.get_wide_dword(jump_code_addr)
addr_ = addr_ + 2
code = idc.get_wide_dword(addr_).to_bytes(4, byteorder='little')
opcode = get_opcode(code, addr_)
if len(opcode) != 0 and opcode[0] == 'bl':
jump_addr_1 = int(opcode[1][1:], 16)
code = idc.get_wide_dword(jump_addr_1).to_bytes(4, byteorder='little')
opcode = get_opcode(code, jump_addr_1)
if len(opcode) != 0 and opcode[0] == 'bl':
jump_addr_2 = int(opcode[1][1:], 16)
code = idc.get_wide_dword(jump_addr_2).to_bytes(4, byteorder='little')
opcode = get_opcode(code, jump_addr_2)
if len(opcode) != 0 and opcode[0] == 'bx':
lr = jump_addr_1 + 4
elif len(opcode) != 0 and opcode[0] == 'bx':
lr = addr_ + 4
if lr != "":
r1 = idc.get_wide_dword(lr + (jump_code << 2))
real_jump_addr = lr + r1
patch_b(addr, real_jump_addr)
if __name__ == '__main__':
for i in range(0x9EB8, 0x218Acc):
patch(i)
0xe556|B 0x17a82
0xeb02|B 0x16ca8
0xeb48|B 0x14972
...
0x1c03b2|B 0x1c0312
0x1c03d4|B 0x1c020c
0xe556|B 0x17a82
0xeb02|B 0x16ca8
0xeb48|B 0x14972
...
0x1c03b2|B 0x1c0312
0x1c03d4|B 0x1c020c
from keystone import *
ks = Ks(keystone.KS_ARCH_ARM, keystone.KS_MODE_THUMB)
def generate(code, addr):
encoding, _ = ks.asm(code, addr)
return encoding
def patch_b(code, addr):
bCode = generate(code, addr)
if (bCode != None):
ida_bytes.patch_bytes(addr, bytes(bCode))
if __name__ == '__main__':
with open('patch.txt', 'r') as file:
for line in file:
parts = line.split('|')
addr = parts[0]
code = parts[1].rstrip('\n')
patch_b(code,int(addr,16))
from keystone import *
ks = Ks(keystone.KS_ARCH_ARM, keystone.KS_MODE_THUMB)
def generate(code, addr):
encoding, _ = ks.asm(code, addr)
return encoding
def patch_b(code, addr):
bCode = generate(code, addr)
if (bCode != None):
ida_bytes.patch_bytes(addr, bytes(bCode))
if __name__ == '__main__':
with open('patch.txt', 'r') as file:
for line in file:
parts = line.split('|')
addr = parts[0]
code = parts[1].rstrip('\n')
patch_b(code,int(addr,16))
src/main/java/com/github/unidbg/unix/UnixSyscallHandler.java
将类中gettimeofday()方法中的取时间固定
// long currentTimeMillis = System.currentTimeMillis();
long currentTimeMillis = 0000000000000L;
当时间固定后 发现结果也随之固定了
0000: 35 32 36 36 42 42 39 42 46 36 35 42 43 35 33 45 5266BB9BF65BC53E
0010: 46 32 33 39 39 44 33 41 30 44 30 30 42 44 35 44 F2399D3A0D00BD5D
0020: 30 30 30 30 30 30 30 30 31 32 43 34 31 41 46 36 0000000012C41AF6
0030: 34 35 43 42 30 32 44 38 35 38 44 33 45 42 44 35 45CB02D858D3EBD5
0040: 46 46 44 38 32 45 35 44 31 35 30 FFD82E5D150
观察到结果的33-40位居然是00000000 这会跟上面固定的时间有关吗
再次改变时间:
long currentTimeMillis = 1234567898765L;
0000: 32 44 41 43 41 37 41 31 36 43 44 44 41 34 31 37 2DACA7A16CDDA417
0010: 33 37 30 43 31 45 42 39 43 43 34 30 34 45 44 32 370C1EB9CC404ED2
0020: 44 41 30 32 39 36 34 39 31 32 43 43 42 31 33 43 DA02964912CCB13C
0030: 41 46 34 36 43 45 31 37 32 38 33 38 45 44 32 46 AF46CE172838ED2F
0040: 36 33 31 36 38 39 37 44 37 34 30 6316897D740
发现这次结果的33-40位变成了DA029649 把他转为小端序再转16进制 发现是1234567898
即十位数的时间戳
综上可知 结果的33-40位是十位数的时间戳 41-43位则是固定的12c
src/main/java/com/github/unidbg/unix/UnixSyscallHandler.java
将类中gettimeofday()方法中的取时间固定
// long currentTimeMillis = System.currentTimeMillis();
long currentTimeMillis = 0000000000000L;
当时间固定后 发现结果也随之固定了
0000: 35 32 36 36 42 42 39 42 46 36 35 42 43 35 33 45 5266BB9BF65BC53E
0010: 46 32 33 39 39 44 33 41 30 44 30 30 42 44 35 44 F2399D3A0D00BD5D
0020: 30 30 30 30 30 30 30 30 31 32 43 34 31 41 46 36 0000000012C41AF6
0030: 34 35 43 42 30 32 44 38 35 38 44 33 45 42 44 35 45CB02D858D3EBD5
0040: 46 46 44 38 32 45 35 44 31 35 30 FFD82E5D150
观察到结果的33-40位居然是00000000 这会跟上面固定的时间有关吗
再次改变时间:
long currentTimeMillis = 1234567898765L;
0000: 32 44 41 43 41 37 41 31 36 43 44 44 41 34 31 37 2DACA7A16CDDA417
0010: 33 37 30 43 31 45 42 39 43 43 34 30 34 45 44 32 370C1EB9CC404ED2
0020: 44 41 30 32 39 36 34 39 31 32 43 43 42 31 33 43 DA02964912CCB13C
0030: 41 46 34 36 43 45 31 37 32 38 33 38 45 44 32 46 AF46CE172838ED2F
0040: 36 33 31 36 38 39 37 44 37 34 30 6316897D740
发现这次结果的33-40位变成了DA029649 把他转为小端序再转16进制 发现是1234567898
即十位数的时间戳
综上可知 结果的33-40位是十位数的时间戳 41-43位则是固定的12c
private static long II(long a, long b, long c, long d, long x, long s,
long ac) {
a += (I(b, c, d)&0xFFFFFFFFL) + x + ac;
a = ((a&0xFFFFFFFFL) << s) | ((a&0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a&0xFFFFFFFFL);
}
private static long I(long x, long y, long z) {
return y ^ (x | (~z));
}
由md5的最后一轮计算 可知
a = II(a, b, c, d, M4, 6, t[60])
b = II(d, a, b, c, M11, 10, t[61])
c = II(c, d, a, b, M2, 15, t[62])
d = II(b, c, d, a, M9, 21, t[63])
因为逻辑运算左右移的互补关系 左移(x) = 右移(32-x)
把这些计算代入到上方ida中的伪c代码 流程十分的契合 结果的前32位大概率就是md5哈希校验了
private static long II(long a, long b, long c, long d, long x, long s,
long ac) {
a += (I(b, c, d)&0xFFFFFFFFL) + x + ac;
a = ((a&0xFFFFFFFFL) << s) | ((a&0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a&0xFFFFFFFFL);
}
private static long I(long x, long y, long z) {
return y ^ (x | (~z));
}
由md5的最后一轮计算 可知
a = II(a, b, c, d, M4, 6, t[60])
b = II(d, a, b, c, M11, 10, t[61])
c = II(c, d, a, b, M2, 15, t[62])
d = II(b, c, d, a, M9, 21, t[63])
因为逻辑运算左右移的互补关系 左移(x) = 右移(32-x)
把这些计算代入到上方ida中的伪c代码 流程十分的契合 结果的前32位大概率就是md5哈希校验了
a = FF(a, b, c, d, M0, 7, 0xd76aa478)
b = FF(d, a, b, c, M1, 12, 0xe8c7b756)
c = FF(c, d, a, b, M2, 17, 0x242070db)
d = FF(b, c, d, a, M3, 22, 0xc1bdceee)
a = FF(a, b, c, d, M4, 7, 0xf57c0faf)
b = FF(d, a, b, c, M5, 12, 0x4787c62a)
c = FF(c, d, a, b, M6, 17, 0xa8304613)
d = FF(b, c, d, a, M7, 22, 0xfd469501)
a = FF(a, b, c, d, M8, 7, 0x698098d8)
b = FF(d, a, b, c, M9, 12, 0x8b44f7af)
c = FF(c, d, a, b, M10, 17, 0xffff5bb1)
d = FF(b, c, d, a, M11, 22, 0x895cd7be)
a = FF(a, b, c, d, M12, 7, 0x6b901122)
b = FF(d, a, b, c, M13, 12, 0xfd987193)
c = FF(c, d, a, b, M14, 17, 0xa679438e)
d = FF(b, c, d, a, M15, 22, 0x49b40821)
private static long F(long x, long y, long z) {
return (x & y) | ((~x) & z);
}
FF = a=b+((a+F(b,c,d)+Mj+ti)<<<s)
只需要找到Mj 即找到了明文
a = FF(a, b, c, d, M0, 7, 0xd76aa478)
b = FF(d, a, b, c, M1, 12, 0xe8c7b756)
c = FF(c, d, a, b, M2, 17, 0x242070db)
d = FF(b, c, d, a, M3, 22, 0xc1bdceee)
a = FF(a, b, c, d, M4, 7, 0xf57c0faf)
b = FF(d, a, b, c, M5, 12, 0x4787c62a)
c = FF(c, d, a, b, M6, 17, 0xa8304613)
d = FF(b, c, d, a, M7, 22, 0xfd469501)
a = FF(a, b, c, d, M8, 7, 0x698098d8)
b = FF(d, a, b, c, M9, 12, 0x8b44f7af)
c = FF(c, d, a, b, M10, 17, 0xffff5bb1)
d = FF(b, c, d, a, M11, 22, 0x895cd7be)
a = FF(a, b, c, d, M12, 7, 0x6b901122)
b = FF(d, a, b, c, M13, 12, 0xfd987193)
c = FF(c, d, a, b, M14, 17, 0xa679438e)
d = FF(b, c, d, a, M15, 22, 0x49b40821)
private static long F(long x, long y, long z) {
return (x & y) | ((~x) & z);
}
FF = a=b+((a+F(b,c,d)+Mj+ti)<<<s)
只需要找到Mj 即找到了明文
"ldr r4, [pc, #0x358]" => r4=0x1fdf9fdf
"ldr r4, [pc, #0x358]" => r4=0x97571757
"ldr r4, [pc, #0x35c]" => r4=0x68a8e8a8
发现参与计算的几个数都是直接通过pc指针+偏移进行读取 为固定值 猜测这就是md5的初始模数
0x120360 "eors r4, r5" r4=0x1fdf9fdf r5=0x97571757 => r4=0x88888888
0x120364 "ands r4, r1" r4=0x88888888 r1=0x68a8e8a8 => r4=0x8888888
0x120366 "eors r4, r5" r4=0x8888888 r5=0x97571757 => r4=0x9fdf9fdf
(b & c) ^ ((~b) & d) => [(c ^ d) & b] ^ d
发现上述计算等价于F(b,c,d)
至此 确定了md5计算的初始模数a,b,c,d
A = 0xe0206020
B = 0x68a8e8a8
C = 0x1fdf9fdf
D = 0x97571757
"ldr r4, [pc, #0x358]" => r4=0x1fdf9fdf
"ldr r4, [pc, #0x358]" => r4=0x97571757
"ldr r4, [pc, #0x35c]" => r4=0x68a8e8a8
发现参与计算的几个数都是直接通过pc指针+偏移进行读取 为固定值 猜测这就是md5的初始模数
0x120360 "eors r4, r5" r4=0x1fdf9fdf r5=0x97571757 => r4=0x88888888
0x120364 "ands r4, r1" r4=0x88888888 r1=0x68a8e8a8 => r4=0x8888888
0x120366 "eors r4, r5" r4=0x8888888 r5=0x97571757 => r4=0x9fdf9fdf
(b & c) ^ ((~b) & d) => [(c ^ d) & b] ^ d
发现上述计算等价于F(b,c,d)
至此 确定了md5计算的初始模数a,b,c,d
A = 0xe0206020
B = 0x68a8e8a8
C = 0x1fdf9fdf
D = 0x97571757
00000000 30 30 30 30 30 30 30 30 5a 62 30 61 64 76 4a 32 |00000000Zb0advJ2|
00000010 52 74 43 69 6a 4e 72 38 64 55 70 49 35 31 50 5a |RtCijNr8dUpI51PZ|
00000020 6e 68 62 55 4b 67 33 57 4c 4d 68 4f 6d 53 33 41 |nhbUKg3WLMhOmS3A|
00000030 75 55 50 55 78 6b 39 35 68 77 37 68 64 4a 79 34 |uUPUxk95hw7hdJy4|
00000040 63 4a 72 4c 70 4d 50 64 78 54 72 49 68 31 67 37 |cJrLpMPdxTrIh1g7|
00000050 79 4c 50 75 48 44 4a 61 78 6b 36 6c 51 4d 71 6d |yLPuHDJaxk6lQMqm|
00000060 80 76 79 31 00 00 00 00 00 00 00 00 00 00 00 00 |.vy1............|
00000070 00 00 00 00 00 00 00 00 00 00 03 18 00 00 00 00 |................|
转为大端序
00000000 30 30 30 30 30 30 30 30 61 30 62 5a 32 4a 76 64 |00000000a0bZ2Jvd|
00000010 69 43 74 52 38 72 4e 6a 49 70 55 64 5a 50 31 35 |iCtR8rNjIpUdZP15|
00000020 55 62 68 6e 57 33 67 4b 4f 68 4d 4c 41 33 53 6d |UbhnW3gKOhMLA3Sm|
00000030 55 50 55 75 35 39 6b 78 68 37 77 68 34 79 4a 64 |UPUu59kxh7wh4yJd|
00000040 4c 72 4a 63 64 50 4d 70 49 72 54 78 37 67 31 68 |LrJcdPMpIrTx7g1h|
00000050 75 50 4c 79 61 4a 44 48 6c 36 6b 78 6d 71 4d 51 |uPLyaJDHl6kxmqMQ|
00000060 31 79 76 80 00 00 00 00 00 00 00 00 00 00 00 00 |1yv.............|
00000070 00 00 00 00 00 00 00 00 18 03 00 00 00 00 00 00 |................|
发现完美符合md5明文拓展后的特征(明文以0x80结尾,倒数第8字节存放明文长度*8)
00000000 30 30 30 30 30 30 30 30 5a 62 30 61 64 76 4a 32 |00000000Zb0advJ2|
00000010 52 74 43 69 6a 4e 72 38 64 55 70 49 35 31 50 5a |RtCijNr8dUpI51PZ|
00000020 6e 68 62 55 4b 67 33 57 4c 4d 68 4f 6d 53 33 41 |nhbUKg3WLMhOmS3A|
00000030 75 55 50 55 78 6b 39 35 68 77 37 68 64 4a 79 34 |uUPUxk95hw7hdJy4|
00000040 63 4a 72 4c 70 4d 50 64 78 54 72 49 68 31 67 37 |cJrLpMPdxTrIh1g7|
00000050 79 4c 50 75 48 44 4a 61 78 6b 36 6c 51 4d 71 6d |yLPuHDJaxk6lQMqm|
00000060 80 76 79 31 00 00 00 00 00 00 00 00 00 00 00 00 |.vy1............|
00000070 00 00 00 00 00 00 00 00 00 00 03 18 00 00 00 00 |................|
转为大端序
00000000 30 30 30 30 30 30 30 30 61 30 62 5a 32 4a 76 64 |00000000a0bZ2Jvd|
00000010 69 43 74 52 38 72 4e 6a 49 70 55 64 5a 50 31 35 |iCtR8rNjIpUdZP15|
00000020 55 62 68 6e 57 33 67 4b 4f 68 4d 4c 41 33 53 6d |UbhnW3gKOhMLA3Sm|
00000030 55 50 55 75 35 39 6b 78 68 37 77 68 34 79 4a 64 |UPUu59kxh7wh4yJd|
00000040 4c 72 4a 63 64 50 4d 70 49 72 54 78 37 67 31 68 |LrJcdPMpIrTx7g1h|
00000050 75 50 4c 79 61 4a 44 48 6c 36 6b 78 6d 71 4d 51 |uPLyaJDHl6kxmqMQ|
00000060 31 79 76 80 00 00 00 00 00 00 00 00 00 00 00 00 |1yv.............|
00000070 00 00 00 00 00 00 00 00 18 03 00 00 00 00 00 00 |................|
发现完美符合md5明文拓展后的特征(明文以0x80结尾,倒数第8字节存放明文长度*8)
0x500fe759L /* 1 */
0x6fa2f477L /* 2 */
0xa34533faL /* 3 */
...
0xadb2919aL /* 63 */
0x6ce390b0L /* 64 */
0x500fe759L /* 1 */
0x6fa2f477L /* 2 */
0xa34533faL /* 3 */
...
0xadb2919aL /* 63 */
0x6ce390b0L /* 64 */
public class magicMD5 {
static final String[] hexs = {"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F"};
private static final long A = 0xe0206020L;
private static final long B = 0x68a8e8a8L;
private static final long C = 0x1fdf9fdfL;
private static final long D = 0x97571757L;
static final int S11 = 7;
static final int S12 = 12;
static final int S13 = 17;
static final int S14 = 22;
static final int S21 = 5;
static final int S22 = 9;
static final int S23 = 14;
static final int S24 = 20;
static final int S31 = 4;
static final int S32 = 11;
static final int S33 = 16;
static final int S34 = 23;
static final int S41 = 6;
static final int S42 = 10;
static final int S43 = 15;
static final int S44 = 21;
private long[] result = {A, B, C, D};
public static void main(String[] args) {
magicMD5 md = new magicMD5();
System.out.println(md.digest("30303030303030306130625a324a76646943745238724e6a497055645a5031355562686e5733674b4f684d4c4133536d5550557535396b786837776834794a644c724a6364504d70497254783767316875504c79614a44486c366b786d714d51317976"));
}
private String digest(String inputHexStr) {
byte[] inputBytes = hexToByteArray(inputHexStr);
int byteLen = inputBytes.length;
int groupCount = 0;
groupCount = byteLen / 64;
long[] groups = null;
for (int step = 0; step < groupCount; step++) {
groups = divGroup(inputBytes, step * 64);
trans(groups);
}
int rest = byteLen % 64;
byte[] tempBytes = new byte[64];
if (rest <= 56) {
for (int i = 0; i < rest; i++)
tempBytes[i] = inputBytes[byteLen - rest + i];
if (rest < 56) {
tempBytes[rest] = (byte) (1 << 7);
for (int i = 1; i < 56 - rest; i++)
tempBytes[rest + i] = 0;
}
long len = (long) (byteLen << 3);
for (int i = 0; i < 8; i++) {
tempBytes[56 + i] = (byte) (len & 0xFFL);
len = len >> 8;
}
groups = divGroup(tempBytes, 0);
trans(groups);
} else {
for (int i = 0; i < rest; i++)
tempBytes[i] = inputBytes[byteLen - rest + i];
tempBytes[rest] = (byte) (1 << 7);
for (int i = rest + 1; i < 64; i++)
tempBytes[i] = 0;
groups = divGroup(tempBytes, 0);
trans(groups);
for (int i = 0; i < 56; i++)
tempBytes[i] = 0;
long len = (long) (byteLen << 3);
for (int i = 0; i < 8; i++) {
tempBytes[56 + i] = (byte) (len & 0xFFL);
len = len >> 8;
}
groups = divGroup(tempBytes, 0);
trans(groups);
}
String resStr = "";
long temp = 0;
for (int i = 0; i < 4; i++) {
for (int j = 0; j < 4; j++) {
temp = result[i] & 0x0FL;
String a = hexs[(int) (temp)];
result[i] = result[i] >> 4;
temp = result[i] & 0x0FL;
resStr += hexs[(int) (temp)] + a;
result[i] = result[i] >> 4;
}
}
return resStr;
}
/**
* 从inputBytes的index开始取512位,作为新的分组
* 将每一个512位的分组再细分成16个小组,每个小组64位(8个字节)
*
* @param inputBytes
* @param index
* @return
*/
private static long[] divGroup(byte[] inputBytes, int index) {
long[] temp = new long[16];
for (int i = 0; i < 16; i++) {
temp[i] = b2iu(inputBytes[4 * i + index]) |
(b2iu(inputBytes[4 * i + 1 + index])) << 8 |
(b2iu(inputBytes[4 * i + 2 + index])) << 16 |
(b2iu(inputBytes[4 * i + 3 + index])) << 24;
}
return temp;
}
/**
* 这时不存在符号位(符号位存储不再是代表正负),所以需要处理一下
*
* @param b
* @return
*/
public static long b2iu(byte b) {
return b < 0 ? b & 0x7F + 128 : b;
}
private void trans(long[] groups) {
long a = result[0], b = result[1], c = result[2], d = result[3];
private static long F(long x, long y, long z) {
return (x & y) | ((~x) & z);
}
private static long G(long x, long y, long z) {
return (x & z) | (y & (~z));
}
private static long H(long x, long y, long z) {
return x ^ y ^ z;
}
private static long I(long x, long y, long z) {
return y ^ (x | (~z));
}
private static long FF(long a, long b, long c, long d, long x, long s,
long ac) {
a += (F(b, c, d) & 0xFFFFFFFFL) + x + ac;
a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a & 0xFFFFFFFFL);
}
private static long GG(long a, long b, long c, long d, long x, long s,
long ac) {
a += (G(b, c, d) & 0xFFFFFFFFL) + x + ac;
a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a & 0xFFFFFFFFL);
}
private static long HH(long a, long b, long c, long d, long x, long s,
long ac) {
a += (H(b, c, d) & 0xFFFFFFFFL) + x + ac;
a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a & 0xFFFFFFFFL);
}
private static long II(long a, long b, long c, long d, long x, long s,
long ac) {
a += (I(b, c, d) & 0xFFFFFFFFL) + x + ac;
a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a & 0xFFFFFFFFL);
}
private static byte hexToByte(String inHex){
return (byte)Integer.parseInt(inHex,16);
}
public static byte[] hexToByteArray(String inHex){
int hexlen = inHex.length();
byte[] result;
if (hexlen % 2 == 1){
hexlen++;
result = new byte[(hexlen/2)];
inHex="0"+inHex;
}else {
result = new byte[(hexlen/2)];
}
int j=0;
for (int i = 0; i < hexlen; i+=2){
result[j]=hexToByte(inHex.substring(i,i+2));
j++;
}
return result;
}
}
public class magicMD5 {
static final String[] hexs = {"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F"};
private static final long A = 0xe0206020L;
private static final long B = 0x68a8e8a8L;
private static final long C = 0x1fdf9fdfL;
private static final long D = 0x97571757L;
static final int S11 = 7;
static final int S12 = 12;
static final int S13 = 17;
static final int S14 = 22;
static final int S21 = 5;
static final int S22 = 9;
static final int S23 = 14;
static final int S24 = 20;
static final int S31 = 4;
static final int S32 = 11;
static final int S33 = 16;
static final int S34 = 23;
static final int S41 = 6;
static final int S42 = 10;
static final int S43 = 15;
static final int S44 = 21;
private long[] result = {A, B, C, D};
public static void main(String[] args) {
magicMD5 md = new magicMD5();
System.out.println(md.digest("30303030303030306130625a324a76646943745238724e6a497055645a5031355562686e5733674b4f684d4c4133536d5550557535396b786837776834794a644c724a6364504d70497254783767316875504c79614a44486c366b786d714d51317976"));
}
private String digest(String inputHexStr) {
byte[] inputBytes = hexToByteArray(inputHexStr);
int byteLen = inputBytes.length;
int groupCount = 0;
groupCount = byteLen / 64;
long[] groups = null;
for (int step = 0; step < groupCount; step++) {
groups = divGroup(inputBytes, step * 64);
trans(groups);
}
int rest = byteLen % 64;
byte[] tempBytes = new byte[64];
if (rest <= 56) {
for (int i = 0; i < rest; i++)
tempBytes[i] = inputBytes[byteLen - rest + i];
if (rest < 56) {
tempBytes[rest] = (byte) (1 << 7);
for (int i = 1; i < 56 - rest; i++)
tempBytes[rest + i] = 0;
}
long len = (long) (byteLen << 3);
for (int i = 0; i < 8; i++) {
tempBytes[56 + i] = (byte) (len & 0xFFL);
len = len >> 8;
}
groups = divGroup(tempBytes, 0);
trans(groups);
} else {
for (int i = 0; i < rest; i++)
tempBytes[i] = inputBytes[byteLen - rest + i];
tempBytes[rest] = (byte) (1 << 7);
for (int i = rest + 1; i < 64; i++)
tempBytes[i] = 0;
groups = divGroup(tempBytes, 0);
trans(groups);
for (int i = 0; i < 56; i++)
tempBytes[i] = 0;
long len = (long) (byteLen << 3);
for (int i = 0; i < 8; i++) {
tempBytes[56 + i] = (byte) (len & 0xFFL);
len = len >> 8;
}
groups = divGroup(tempBytes, 0);
trans(groups);
}
String resStr = "";
long temp = 0;
for (int i = 0; i < 4; i++) {
for (int j = 0; j < 4; j++) {
temp = result[i] & 0x0FL;
String a = hexs[(int) (temp)];
result[i] = result[i] >> 4;
temp = result[i] & 0x0FL;
resStr += hexs[(int) (temp)] + a;
result[i] = result[i] >> 4;
}
}
return resStr;
}
/**
* 从inputBytes的index开始取512位,作为新的分组
* 将每一个512位的分组再细分成16个小组,每个小组64位(8个字节)
*
* @param inputBytes
* @param index
* @return
*/
private static long[] divGroup(byte[] inputBytes, int index) {
long[] temp = new long[16];
for (int i = 0; i < 16; i++) {
temp[i] = b2iu(inputBytes[4 * i + index]) |
(b2iu(inputBytes[4 * i + 1 + index])) << 8 |
(b2iu(inputBytes[4 * i + 2 + index])) << 16 |
(b2iu(inputBytes[4 * i + 3 + index])) << 24;
}
return temp;
}
/**
* 这时不存在符号位(符号位存储不再是代表正负),所以需要处理一下
*
* @param b
* @return
*/
public static long b2iu(byte b) {
return b < 0 ? b & 0x7F + 128 : b;
}
private void trans(long[] groups) {
long a = result[0], b = result[1], c = result[2], d = result[3];
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2024-10-1 13:17
被劫__编辑
,原因:









