void init_proc()
{
int tick; // w8
const char *v1; // x23
__int64 v2; // x0
unsigned int v3; // w0
unsigned __int64 StatusReg; // [xsp+0h] [xbp-870h] BYREF
void *cmdline_content; // [xsp+8h] [xbp-868h]
bool v6; // [xsp+17h] [xbp-859h]
int v7; // [xsp+18h] [xbp-858h]
int v8; // [xsp+1Ch] [xbp-854h]
void *cmdline_content2; // [xsp+20h] [xbp-850h]
char *v10; // [xsp+28h] [xbp-848h]
char *v11; // [xsp+30h] [xbp-840h]
FILE *v12; // [xsp+38h] [xbp-838h]
char v13[2000]; // [xsp+40h] [xbp-830h] BYREF
__int64 v14; // [xsp+810h] [xbp-60h]
StatusReg = _ReadStatusReg(ARM64_SYSREG(3, 3, 0xD, 0, 2));
v14 = *(StatusReg + 40);
tick = 0xA0BA64CE;
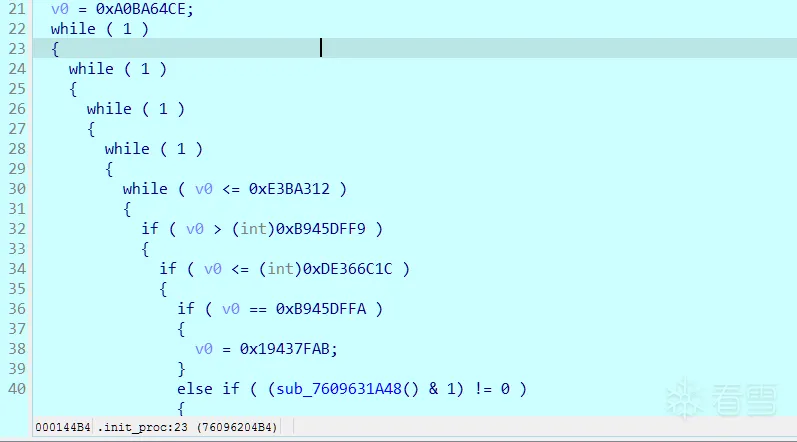
while ( 1 )
{
while ( 1 )
{
while ( 1 )
{
while ( 1 )
{
while ( tick <= 0xE3BA312 )
{
if ( tick > 0xB945DFF9 )
{
if ( tick <= 0xDE366C1C )
{
if ( tick == 0xB945DFFA )
{
tick = 0x19437FAB;
}
else if ( (sub_760A0EFA48() & 1) != 0 )
{
tick = 0x6B8494DB;
}
else
{
tick = 0x5B4C847C;
}
}
else if ( tick == -566858723 )
{
if ( v8 )
tick = 0x4F03BFB3;
else
tick = -1706423140;
}
else if ( tick == -195526736 )
{
v7 = sub_760A0D6830(); // tick 13
tick = 33264006;
}
else if ( v7 == 1 )
{
tick = -1960142196;
}
else
{
tick = 0x4F03BFB3;
}
}
else if ( tick <= 0x9C5EB96E )
{
if ( tick == -1960142196 )
{
v8 = sub_760A0D35C8(); // tick 14
tick = -566858723;
}
else
{
tick = 1803850971;
}
}
else if ( tick == 0x9C5EB96F )
{
if ( v6 ) // tick 5
tick = 0x76541A4F;
else
tick = 0xBB1E2113;
} // tick 4
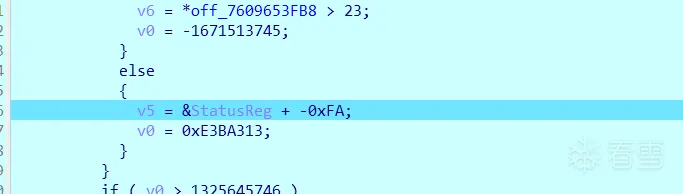
else if ( tick == 0x9F46953A )
{
v6 = *off_760A111FB8 > 23;
tick = -1671513745;
}
else
{
cmdline_content = &StatusReg + -0xFA;// tick 1
tick = 0xE3BA313;
}
}
if ( tick > 1325645746 )
break;
if ( tick <= 423853994 )
{
if ( tick == 238789395 )
{
*off_760A111FB8 = sub_760A0DC3F0();// tick 2
sub_760A0DC550();
tick = 371708096;
}
else
{
sub_760A0DC440(); // tick 3
tick = -1622764230;
}
}
else if ( tick == 0x19437FAB )
{
v2 = sub_760A0DD728(); // tick 12
sub_760A0EDAD4(v2);
tick = -195526736;
}
else if ( tick == 0x23D89166 )
{
memset(v11, 0, 0x7D0uLL); // tick 8
v3 = getpid();
_sprintf_chk(v13, 0LL, 2000LL, "/proc/%d/cmdline", v3);
v12 = fopen(v13, "r");
if ( v12 )
tick = 0x65C6D61D; // tick 9
else
tick = 0x19437FAB;
}
else
{
sub_760A0E5EC4(); // tick 11
tick = -1186603014;
}
}
if ( tick > 1803850970 )
break;
if ( tick == 0x4F03BFB3 )
{
sub_760A0D3150();
tick = -1706423140;
}
else if ( tick == 1531741308 )
{
v11 = v13; // tick 7
tick = 601395558;
}
else
{
cmdline_content2 = cmdline_content; // tick 10
memset(cmdline_content, 0, 0x7D0uLL);
v1 = cmdline_content;
fscanf(v12, "%s", cmdline_content);
fclose(v12);
v10 = strchr(v1, 58);
tick = 2139705484;
}
}
if ( tick != 1985223247 )
break;
*off_760A111ED8 = 1; // tick 6
tick = -1155653357;
}
if ( tick != 2139705484 )
break;
if ( v10 )
tick = -1186603014;
else
tick = 965695107;
}
}