@
笔者刚入门 v8 利用不久,以下内容可能存在错误,如发现相关错误,希望各位大佬雅正,谢谢。
参考文章 [V8 Deep Dives] Understanding Map Internals
下面概念性的内容基本上就是对该参考文章的翻译或总结,建议看原文章
V8 中的 Map 是在哈希表的基础上构建出来的,但是不等同于哈希表,因为哈希表是不提供插入元素的顺序保证的,但是 ES 标准要求 Map 要记录元素的插入顺序。所以 Map 底层采用的是 deterministic hash tables,当然对于我们而言无需关心其具体是什么,类似哈希表就完了。 确定性哈希表采用的数据结构伪代码如下:
这里的 CloseTable 代码的就是代表的哈希表,其成员 hashTable 的大小代表 buckets 的数量,其第 i 个元素代表的就是第 i 个 buckets 头元素在 dataTable 中的 index:
其实这里把 hashTable 当作 bucket 使用数组,dataTable 当作 bucket 数组就好了,这样做的目的就是为了记录元素的插入顺序。
当删除元素时,这里仅仅就是将 key 和 value 设置为 undefined,所以这里被删除的元素仍然占据内存空间。
当然还有一个问题就是当 dataTable 满了,V8 是如何进行扩容的呢?这里引入 v8 中的实现规则:
这里的验证可以看参考文章,后面讲了 v8 中 Map 的内存模型了在简单验证验证。
在 v8 中,JSMap 的内存布局如下:
考虑如下代码:
可以看到这里的 OrderedHashMap:

初始时,buckets 的数量为 2:
可以看到这里 dataTable 的大小为 12(8字节为单位哈),而每个 entry 占 3,所以总的容量其实就是 4,其为 2 * buckets 是满足之前说的 dataTable.length = 2 * buckets = 2 * hashTable.length。
当添加四个元素时:
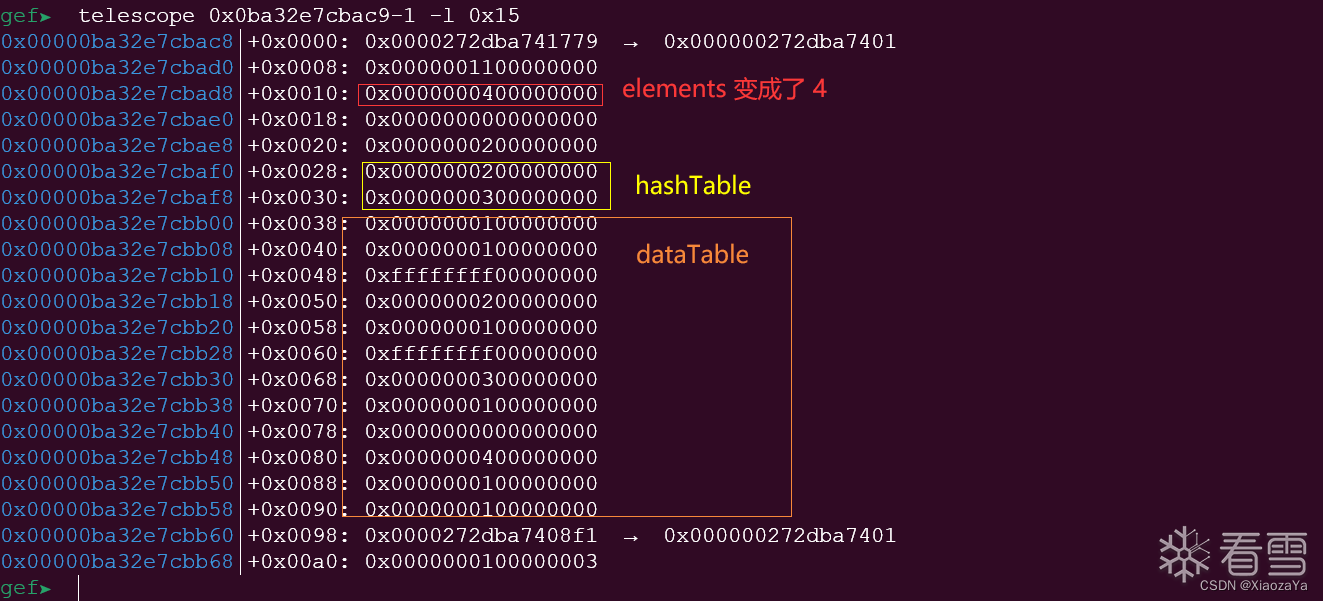
这里来看下 hashTable 和 dataTable,这里我直接画了一个图:
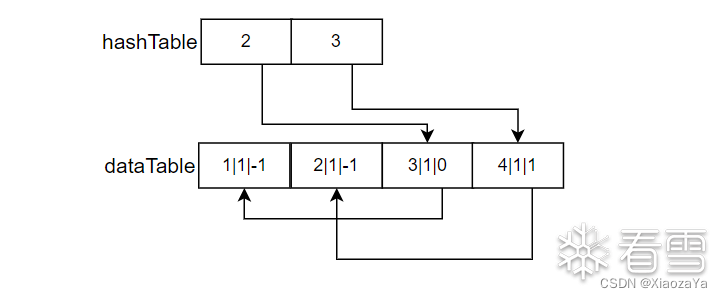
这里似乎与上面参考文章说的有点不同,这里采用的头插法?而且我也没看出来这里是咋记录插入顺序的,但是这里使用 for...of 循环确实是按照顺序打印的:
然后删除 (3, 1):
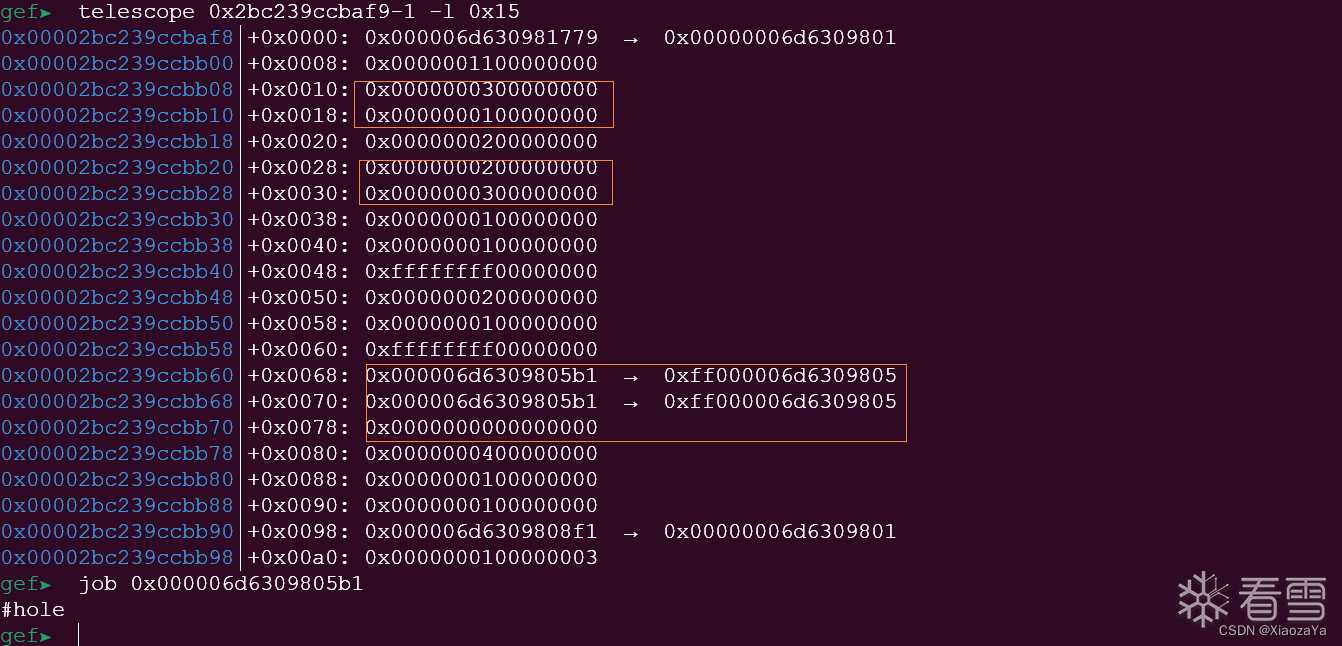
可以看到这里的 elements = 3,而 deleteds = 1,这是符合逻辑的,并且 hashTable 并没有改变,仅仅将对应的 entry 的 key/value 设置成了 #hole:
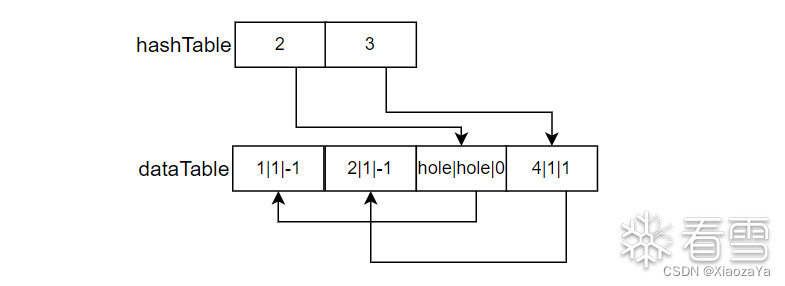
然后再添加一个元素:
可以看到这里的 OrderedHashMap 已经发生了变换,即这里发生了扩容:

来看下 OrderedHashMap:
可以看到这里清除了 deleted entry:
map.set(key, value) 的作用就是给 map 添加元素(其实就是键值对,只是笔者习惯叫做元素,读者自己明白就好),其在 V8 层面的接口定义如下:
set 的整个逻辑如下:
检查 key 是否存在
若 key 存在,则直接更新 value
若 key 不存在,则检查是否存在空闲 entry
这里是用 TryLookupOrderedHashTableIndex 函数去寻找 key 对应的 entry 的,即判断 key 是否存在:
可以看到对于不同类型的 key,有着不同的寻找方式,这里以 Smi 类型的 key 为例,对于 Smi 类型的 key 寻找其 entry 利用的函数是 FindOrderedHashTableEntryForSmiKey:
该函数比较简单,就是先利用 ComputeIntegerHash 计算出 key 的哈希值,然后再用 FindOrderedHashTableEntry 进行查找,ComputeIntegerHash 函数如下:
重点还是在 FindOrderedHashTableEntry 上:
整个逻辑我都注释清楚了,就不多说了,值得注意的是这里遍历 bucket 链表时存在范围检查。
后面 StoreFixedArrayElement 函数我没有找到其定义,就分析下 StoreOrderedHashMapNewEntry 函数,其实都比较比较简单,值得注意的是这里写入的 entry 是根据 hashTable 的偏移计算得到的:
map.delete(key) 的作用就是删除对应元素,其在 V8 层的接口函数如下:
逻辑比较清楚了,看注释吧,这里来看下 Runtime::kMapShrink 函数:
其主要就是调用的 OrderedHashMap::Shrink 函数:
话不多说,跟进 Rehash 函数:
前面对 JSMap 分析了那么多,哪么 hole 泄漏如何利用 JSMap 进行攻击呢?
Hole 是 JS 内部的一种数据类型,用来标记不存在的元素,这个数据类型通常是不能泄露到用户 JS 层面。Hole 类型的漏洞利用是指由于内部数据结构 Hole 通过漏洞被暴露至 用户 JS 层,因此可以根据 Hole 创建⼀个长度为 -1 的 JSMap 结构,导致越界读写,从而实现 RCE。
根据前面的分析,我们知道当使用 map.delete 删除一个元素时,只是将该元素的 key、value 设置为 hole,并没有实际的删除该元素,实际上只是做了个标记,当进行 shrink 操作时,这些被 hole 标记的元素才会被真正的删除。那么如果我们可以创建 key = hole 的元素,那么我们就可以多次删除元素从而导致 map.size = -1(当然这里前提是不进行 shrink 操作,因为 shrink 操作会清除 hole 元素)。考虑如下代码:
可以看到这里的 elements = -1、deleted = 0、buckets = 2:
当然这里的触发代码为啥这样写呢?为啥要 map.set(1, 1) 呢?直接 map.set(hole, 1),然后再 delete 两次不行吗?其实这里就是涉及到 shrink 操作会清除 hole 元素,比如考虑如下代码:
map.set(hole, 1) 后:
可以看到这里的:elements = 1、deleted = 0、buckets = 2
第一次 map.delete(hole) 后:
第一次 map.delete(hole) 后,elements = 0、deleted = 1、buckets = 2,由于 elements < buckets / 2,所以第一次 delete 后会发生 shrink、从而导致 hole 元素被删除,因此第二次 map.delete(hole) 时直接返回 false(这里不理解的看上面 delete 操作的源码分析)
Ok,现在已经成功构造了 map.size = -1 了,哪么接下来该如何去进行 OOB 呢?先来看看如果现在我们继续向 map 中添加元素,这时会发生什么呢?
在之前的 set 操作的源码分析中,我们知道当添加一个新的元素时(即 key 事先不存在)new entry 的寻找方式为:&hashTable + buckets + occupancy * 3,这里的 occupancy = elements + deleted
而在构造好 map.size = -1 后,其相关字段的值为: elements = -1、deleted = 0、buckets = 2
所以 new_entry = &hashTable + 2 + (-1 + 0) * 3 = &hashTable - 1 = hashTable[-1] = &buckets
所以 new_entry = key|value|chain = buckets|hashTbale[0]|hashTable[1],即下一次添加新元素时,就可以修改 buckets = key1、hashTable[0] = value1
然后我们再添加新元素,此时:new_entry = &hashTable + buckets + (0 + 0) * 3 = hashTable[key1],而 key1 我们是可以控制的,所以 new_entry 也是可控的,从而导致越界写 key/value,这里一般就是去写 JSArray 的 length 字段。
但是需要注意的是,在之前分析 set 操作源码时,我们知道当对 bucket 链表进行遍历时会存在检查,所以我们得让 bucket[hash(key) & (buckets - 1)] = -1 从而避免遍历 bucket 链表。在构造好 map.size = -1 后,第一次添加新元素是无所谓的,因为此时 bucket[0] = -1、bucket[1] = -1,但是第二次就得注意了,第一次添加时会导致 bucket[0] != -1 或者 bucket[1] != -1,但是其实 bucket[0] = value1,所以可以让 bucket[0] = value1 = -1,这样在第二次添加时我们只需要让:hash(key2) & (buckets - 1) = 0 即可,这里到时候爆破一下就 ok 了。
模板如下:
key2 爆破脚本,这里的 ComputeUnseededHash 函数以实际的 V8 源码为准:
题目其实没啥好说的,关键就是利用漏洞把 hole 泄漏出来,后面基本都是一样的。所以这里直接用 %TheHole() 来获取 hole,以此来演示利用手法:
效果如下:

可以看到这里的 oob_arr.length 成功被修改为 0x2002 导致越界读写。然后就是基本的 OOB 类型漏洞利用了,就没啥好说的了。
interface Entry {
key: any;
value: any;
chain: number;
}
interface CloseTable {
hashTable: number[];
dataTable: Entry[];
nextSlot: number;
size: number;
}
interface Entry {
key: any;
value: any;
chain: number;
}
interface CloseTable {
hashTable: number[];
dataTable: Entry[];
nextSlot: number;
size: number;
}
var map = new Map();
%DebugPrint(map);
readline();
map.set(1, 1);
map.set(2, 1);
map.set(3, 1);
map.set(4, 1);
%DebugPrint(map);
readline();
map.delete(3);
%DebugPrint(map);
readline();
map.set(5, 1);
%DebugPrint(map);
readline();
var map = new Map();
%DebugPrint(map);
readline();
map.set(1, 1);
map.set(2, 1);
map.set(3, 1);
map.set(4, 1);
%DebugPrint(map);
readline();
map.delete(3);
%DebugPrint(map);
readline();
map.set(5, 1);
%DebugPrint(map);
readline();
......
for (let x of map) {
print(x);
}
......
for (let x of map) {
print(x);
}
TF_BUILTIN(MapPrototypeSet, CollectionsBuiltinsAssembler) {
Node* const receiver = Parameter(Descriptor::kReceiver);
Node* key = Parameter(Descriptor::kKey);
Node* const value = Parameter(Descriptor::kValue);
Node* const context = Parameter(Descriptor::kContext);
ThrowIfNotInstanceType(context, receiver, JS_MAP_TYPE, "Map.prototype.set");
key = NormalizeNumberKey(key);
TNode<OrderedHashMap> const table = CAST(LoadObjectField(receiver, JSMap::kTableOffset));
VARIABLE(entry_start_position_or_hash, MachineType::PointerRepresentation(), IntPtrConstant(0));
Label entry_found(this), not_found(this);
TryLookupOrderedHashTableIndex<OrderedHashMap>(table, key, context,
&entry_start_position_or_hash,
&entry_found, ¬_found);
BIND(&entry_found);
StoreFixedArrayElement(table, entry_start_position_or_hash.value(), value,
UPDATE_WRITE_BARRIER,
kPointerSize * (OrderedHashMap::kHashTableStartIndex +
OrderedHashMap::kValueOffset));
Return(receiver);
Label no_hash(this), add_entry(this), store_new_entry(this);
BIND(¬_found);
{
GotoIf(IntPtrGreaterThan(entry_start_position_or_hash.value(), IntPtrConstant(0)), &add_entry);
entry_start_position_or_hash.Bind(SmiUntag(CallGetOrCreateHashRaw(key)));
Goto(&add_entry);
}
BIND(&add_entry);
VARIABLE(number_of_buckets, MachineType::PointerRepresentation());
VARIABLE(occupancy, MachineType::PointerRepresentation());
TVARIABLE(OrderedHashMap, table_var, table);
{
number_of_buckets.Bind(SmiUntag(CAST(LoadFixedArrayElement(table, OrderedHashMap::kNumberOfBucketsIndex))));
STATIC_ASSERT(OrderedHashMap::kLoadFactor == 2);
Node* const capacity = WordShl(number_of_buckets.value(), 1);
Node* const number_of_elements = SmiUntag(CAST(LoadObjectField(
table, OrderedHashMap::kNumberOfElementsOffset)));
Node* const number_of_deleted = SmiUntag(CAST(LoadObjectField(
table, OrderedHashMap::kNumberOfDeletedElementsOffset)));
occupancy.Bind(IntPtrAdd(number_of_elements, number_of_deleted));
GotoIf(IntPtrLessThan(occupancy.value(), capacity), &store_new_entry);
CallRuntime(Runtime::kMapGrow, context, receiver);
table_var = CAST(LoadObjectField(receiver, JSMap::kTableOffset));
number_of_buckets.Bind(SmiUntag(CAST(LoadFixedArrayElement(
table_var.value(), OrderedHashMap::kNumberOfBucketsIndex))));
Node* const new_number_of_elements = SmiUntag(CAST(LoadObjectField(
table_var.value(), OrderedHashMap::kNumberOfElementsOffset)));
Node* const new_number_of_deleted = SmiUntag(CAST(LoadObjectField(
table_var.value(), OrderedHashMap::kNumberOfDeletedElementsOffset)));
occupancy.Bind(IntPtrAdd(new_number_of_elements, new_number_of_deleted));
Goto(&store_new_entry);
}
BIND(&store_new_entry);
StoreOrderedHashMapNewEntry(table_var.value(), key, value,
entry_start_position_or_hash.value(),
number_of_buckets.value(), occupancy.value());
Return(receiver);
}
TF_BUILTIN(MapPrototypeSet, CollectionsBuiltinsAssembler) {
Node* const receiver = Parameter(Descriptor::kReceiver);
Node* key = Parameter(Descriptor::kKey);
Node* const value = Parameter(Descriptor::kValue);
Node* const context = Parameter(Descriptor::kContext);
ThrowIfNotInstanceType(context, receiver, JS_MAP_TYPE, "Map.prototype.set");
key = NormalizeNumberKey(key);
TNode<OrderedHashMap> const table = CAST(LoadObjectField(receiver, JSMap::kTableOffset));
VARIABLE(entry_start_position_or_hash, MachineType::PointerRepresentation(), IntPtrConstant(0));
Label entry_found(this), not_found(this);
TryLookupOrderedHashTableIndex<OrderedHashMap>(table, key, context,
&entry_start_position_or_hash,
&entry_found, ¬_found);
BIND(&entry_found);
StoreFixedArrayElement(table, entry_start_position_or_hash.value(), value,
UPDATE_WRITE_BARRIER,
kPointerSize * (OrderedHashMap::kHashTableStartIndex +
OrderedHashMap::kValueOffset));
Return(receiver);
Label no_hash(this), add_entry(this), store_new_entry(this);
BIND(¬_found);
{
GotoIf(IntPtrGreaterThan(entry_start_position_or_hash.value(), IntPtrConstant(0)), &add_entry);
entry_start_position_or_hash.Bind(SmiUntag(CallGetOrCreateHashRaw(key)));
Goto(&add_entry);
}
BIND(&add_entry);
VARIABLE(number_of_buckets, MachineType::PointerRepresentation());
VARIABLE(occupancy, MachineType::PointerRepresentation());
TVARIABLE(OrderedHashMap, table_var, table);
{
number_of_buckets.Bind(SmiUntag(CAST(LoadFixedArrayElement(table, OrderedHashMap::kNumberOfBucketsIndex))));
STATIC_ASSERT(OrderedHashMap::kLoadFactor == 2);
Node* const capacity = WordShl(number_of_buckets.value(), 1);
Node* const number_of_elements = SmiUntag(CAST(LoadObjectField(
table, OrderedHashMap::kNumberOfElementsOffset)));
Node* const number_of_deleted = SmiUntag(CAST(LoadObjectField(
table, OrderedHashMap::kNumberOfDeletedElementsOffset)));
occupancy.Bind(IntPtrAdd(number_of_elements, number_of_deleted));
GotoIf(IntPtrLessThan(occupancy.value(), capacity), &store_new_entry);
CallRuntime(Runtime::kMapGrow, context, receiver);
table_var = CAST(LoadObjectField(receiver, JSMap::kTableOffset));
number_of_buckets.Bind(SmiUntag(CAST(LoadFixedArrayElement(
table_var.value(), OrderedHashMap::kNumberOfBucketsIndex))));
Node* const new_number_of_elements = SmiUntag(CAST(LoadObjectField(
table_var.value(), OrderedHashMap::kNumberOfElementsOffset)));
Node* const new_number_of_deleted = SmiUntag(CAST(LoadObjectField(
table_var.value(), OrderedHashMap::kNumberOfDeletedElementsOffset)));
occupancy.Bind(IntPtrAdd(new_number_of_elements, new_number_of_deleted));
Goto(&store_new_entry);
}
BIND(&store_new_entry);
StoreOrderedHashMapNewEntry(table_var.value(), key, value,
entry_start_position_or_hash.value(),
number_of_buckets.value(), occupancy.value());
Return(receiver);
}
template <typename CollectionType>
void CollectionsBuiltinsAssembler::TryLookupOrderedHashTableIndex(
Node* const table, Node* const key, Node* const context, Variable* result,
Label* if_entry_found, Label* if_not_found) {
Label if_key_smi(this), if_key_string(this), if_key_heap_number(this), if_key_bigint(this);
GotoIf(TaggedIsSmi(key), &if_key_smi);
Node* key_map = LoadMap(key);
Node* key_instance_type = LoadMapInstanceType(key_map);
GotoIf(IsStringInstanceType(key_instance_type), &if_key_string);
GotoIf(IsHeapNumberMap(key_map), &if_key_heap_number);
GotoIf(IsBigIntInstanceType(key_instance_type), &if_key_bigint);
FindOrderedHashTableEntryForOtherKey<CollectionType>(
context, table, key, result, if_entry_found, if_not_found);
BIND(&if_key_smi);
{
FindOrderedHashTableEntryForSmiKey<CollectionType>(
table, key, result, if_entry_found, if_not_found);
}
BIND(&if_key_string);
{
FindOrderedHashTableEntryForStringKey<CollectionType>(
context, table, key, result, if_entry_found, if_not_found);
}
BIND(&if_key_heap_number);
{
FindOrderedHashTableEntryForHeapNumberKey<CollectionType>(
context, table, key, result, if_entry_found, if_not_found);
}
BIND(&if_key_bigint);
{
FindOrderedHashTableEntryForBigIntKey<CollectionType>(
context, table, key, result, if_entry_found, if_not_found);
}
}
template <typename CollectionType>
void CollectionsBuiltinsAssembler::TryLookupOrderedHashTableIndex(
Node* const table, Node* const key, Node* const context, Variable* result,
Label* if_entry_found, Label* if_not_found) {
Label if_key_smi(this), if_key_string(this), if_key_heap_number(this), if_key_bigint(this);
GotoIf(TaggedIsSmi(key), &if_key_smi);
Node* key_map = LoadMap(key);
Node* key_instance_type = LoadMapInstanceType(key_map);
GotoIf(IsStringInstanceType(key_instance_type), &if_key_string);
GotoIf(IsHeapNumberMap(key_map), &if_key_heap_number);
GotoIf(IsBigIntInstanceType(key_instance_type), &if_key_bigint);
FindOrderedHashTableEntryForOtherKey<CollectionType>(
context, table, key, result, if_entry_found, if_not_found);
BIND(&if_key_smi);
{
FindOrderedHashTableEntryForSmiKey<CollectionType>(
table, key, result, if_entry_found, if_not_found);
}
BIND(&if_key_string);
{
FindOrderedHashTableEntryForStringKey<CollectionType>(
context, table, key, result, if_entry_found, if_not_found);
}
BIND(&if_key_heap_number);
{
FindOrderedHashTableEntryForHeapNumberKey<CollectionType>(
context, table, key, result, if_entry_found, if_not_found);
}
BIND(&if_key_bigint);
{
FindOrderedHashTableEntryForBigIntKey<CollectionType>(
context, table, key, result, if_entry_found, if_not_found);
}
}
template <typename CollectionType>
void CollectionsBuiltinsAssembler::FindOrderedHashTableEntryForSmiKey(
Node* table, Node* smi_key, Variable* result, Label* entry_found,
Label* not_found) {
Node* const key_untagged = SmiUntag(smi_key);
Node* const hash = ChangeInt32ToIntPtr(ComputeIntegerHash(key_untagged, Int32Constant(0)));
CSA_ASSERT(this, IntPtrGreaterThanOrEqual(hash, IntPtrConstant(0)));
result->Bind(hash);
FindOrderedHashTableEntry<CollectionType>(
table, hash,
[&](Node* other_key, Label* if_same, Label* if_not_same) {
SameValueZeroSmi(smi_key, other_key, if_same, if_not_same);
},
result, entry_found, not_found);
}
template <typename CollectionType>
void CollectionsBuiltinsAssembler::FindOrderedHashTableEntryForSmiKey(
Node* table, Node* smi_key, Variable* result, Label* entry_found,
Label* not_found) {
Node* const key_untagged = SmiUntag(smi_key);
Node* const hash = ChangeInt32ToIntPtr(ComputeIntegerHash(key_untagged, Int32Constant(0)));
CSA_ASSERT(this, IntPtrGreaterThanOrEqual(hash, IntPtrConstant(0)));
result->Bind(hash);
FindOrderedHashTableEntry<CollectionType>(
table, hash,
[&](Node* other_key, Label* if_same, Label* if_not_same) {
SameValueZeroSmi(smi_key, other_key, if_same, if_not_same);
},
result, entry_found, not_found);
}
inline uint32_t ComputeIntegerHash(uint32_t key, uint64_t seed) {
uint32_t hash = key;
hash = hash ^ static_cast<uint32_t>(seed);
hash = ~hash + (hash << 15);
hash = hash ^ (hash >> 12);
hash = hash + (hash << 2);
hash = hash ^ (hash >> 4);
hash = hash * 2057;
hash = hash ^ (hash >> 16);
return hash & 0x3fffffff;
}
inline uint32_t ComputeIntegerHash(uint32_t key, uint64_t seed) {
uint32_t hash = key;
hash = hash ^ static_cast<uint32_t>(seed);
hash = ~hash + (hash << 15);
hash = hash ^ (hash >> 12);
hash = hash + (hash << 2);
hash = hash ^ (hash >> 4);
hash = hash * 2057;
hash = hash ^ (hash >> 16);
return hash & 0x3fffffff;
}
template <typename CollectionType>
void CodeStubAssembler::FindOrderedHashTableEntry(
Node* table, Node* hash,
std::function<void(Node*, Label*, Label*)> key_compare,
Variable* entry_start_position, Label* entry_found, Label* not_found) {
Node* const number_of_buckets = SmiUntag(CAST(LoadFixedArrayElement(
CAST(table), CollectionType::kNumberOfBucketsIndex)));
Node* const bucket =
WordAnd(hash, IntPtrSub(number_of_buckets, IntPtrConstant(1)));
Node* const first_entry = SmiUntag(CAST(LoadFixedArrayElement(
CAST(table), bucket,
CollectionType::kHashTableStartIndex * kPointerSize)));
Node* entry_start;
Label if_key_found(this);
{
VARIABLE(var_entry, MachineType::PointerRepresentation(), first_entry);
Label loop(this, {&var_entry, entry_start_position}), continue_next_entry(this);
Goto(&loop);
BIND(&loop);
GotoIf(
WordEqual(var_entry.value(), IntPtrConstant(CollectionType::kNotFound)),
not_found);
CSA_ASSERT(
this, UintPtrLessThan(
var_entry.value(),
SmiUntag(SmiAdd(
CAST(LoadFixedArrayElement(
CAST(table), CollectionType::kNumberOfElementsIndex)),
CAST(LoadFixedArrayElement(
CAST(table), CollectionType::kNumberOfDeletedElementsIndex))))));
entry_start =
IntPtrAdd(IntPtrMul(var_entry.value(), IntPtrConstant(CollectionType::kEntrySize)),
number_of_buckets);
Node* const candidate_key = LoadFixedArrayElement(
CAST(table), entry_start,
CollectionType::kHashTableStartIndex * kPointerSize);
key_compare(candidate_key, &if_key_found, &continue_next_entry);
BIND(&continue_next_entry);
var_entry.Bind(SmiUntag(CAST(LoadFixedArrayElement(
CAST(table), entry_start,
(CollectionType::kHashTableStartIndex + CollectionType::kChainOffset) *
kPointerSize))));
Goto(&loop);
}
BIND(&if_key_found);
entry_start_position->Bind(entry_start);
Goto(entry_found);
}
template <typename CollectionType>
void CodeStubAssembler::FindOrderedHashTableEntry(
Node* table, Node* hash,
std::function<void(Node*, Label*, Label*)> key_compare,
Variable* entry_start_position, Label* entry_found, Label* not_found) {
Node* const number_of_buckets = SmiUntag(CAST(LoadFixedArrayElement(
CAST(table), CollectionType::kNumberOfBucketsIndex)));
Node* const bucket =
WordAnd(hash, IntPtrSub(number_of_buckets, IntPtrConstant(1)));
Node* const first_entry = SmiUntag(CAST(LoadFixedArrayElement(
CAST(table), bucket,
CollectionType::kHashTableStartIndex * kPointerSize)));
Node* entry_start;
Label if_key_found(this);
{
VARIABLE(var_entry, MachineType::PointerRepresentation(), first_entry);
Label loop(this, {&var_entry, entry_start_position}), continue_next_entry(this);
Goto(&loop);
BIND(&loop);
GotoIf(
WordEqual(var_entry.value(), IntPtrConstant(CollectionType::kNotFound)),
not_found);
CSA_ASSERT(
this, UintPtrLessThan(
var_entry.value(),
SmiUntag(SmiAdd(
CAST(LoadFixedArrayElement(
CAST(table), CollectionType::kNumberOfElementsIndex)),
CAST(LoadFixedArrayElement(
CAST(table), CollectionType::kNumberOfDeletedElementsIndex))))));
entry_start =
IntPtrAdd(IntPtrMul(var_entry.value(), IntPtrConstant(CollectionType::kEntrySize)),
number_of_buckets);
Node* const candidate_key = LoadFixedArrayElement(
CAST(table), entry_start,
CollectionType::kHashTableStartIndex * kPointerSize);
key_compare(candidate_key, &if_key_found, &continue_next_entry);
BIND(&continue_next_entry);
var_entry.Bind(SmiUntag(CAST(LoadFixedArrayElement(
CAST(table), entry_start,
(CollectionType::kHashTableStartIndex + CollectionType::kChainOffset) *
kPointerSize))));
Goto(&loop);
}
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2024-7-8 20:39
被XiaozaYa编辑
,原因: