在分析某app的so时遇到了间接跳转类型的混淆,不去掉的话无法使用ida f5来静态分析,f5之后就长下面这样:
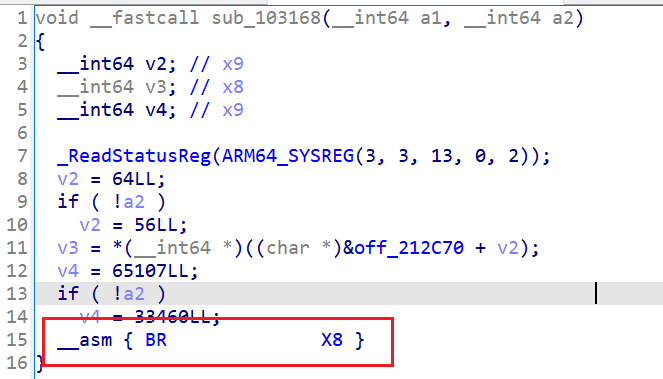
本文记录一下使用python+unicorn模拟执行来去掉混淆的过程。
混淆的汇编代码如下:

可以看到,这个代码块进行了一通运算,然后通过 br x8,跳转到寄存器x8中保存的地址,仔细分析这个x8的来源,可以观察到如下的固定模式:
先看 LDR X8, [X25,X9],X25寄存器是一张偏移表的基址, 这条指令从偏移表+X9出取出8字节数据放到了X8中,而X9的值来源于csel指令是0x38或者是0x40,由cmp的结果决定,如果X19等于0,则X9此时等于0x38,负责等于0x40。
再看 SUB X8, X8, X9,从偏移表取出一个8字节数据到X8之后,用X8减X9,结果放到X8,X9的值也是来源于csel指令,0x82B4或者是0xFE53
最后,通过br X8跳转到目标地址
也就是说,根据X9值的不同,最终跳转的地址会有两个,把正常的分支指令混淆成了上面这种模式,手动还原混淆可以把br X8 patch成:
本来想的是直接用python来匹配这种模式,然后手动计算出两个分支的地址,最后patch,但是后面发现,一个被混淆的函数中只有第一个混淆块会给X25赋值偏移表的地址,其他的块就直接用X25的值了,不会再次赋值,比如下面这个:
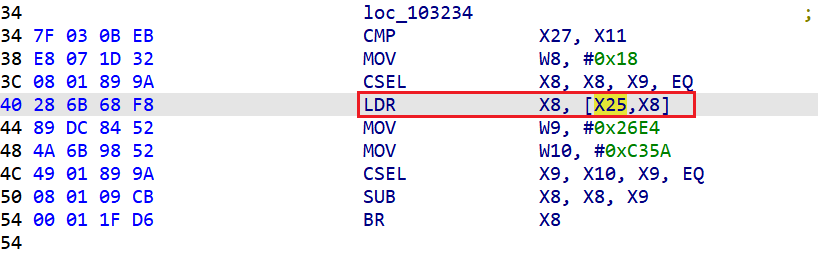
这样的话就不能把这些被混淆的块单独的拿出来看,因为缺少计算分支地址的必要条件,必须从函数的第一个被混淆的块出发,获取到偏移表的地址才行。如果还想通过手动的计算出目的地址,那就需要手动去确定函数的边界,这样就太麻烦了。
所以最后还是选择使通过模拟执行的方式,从函数头开始执行,跑通每一个块,在执行到混淆块的时候,计算出分支地址,最后进行patch
这里模拟执行的框架选择unicorn,之前学习过无名侠大佬用unicorn去ollvm混淆的文章,这里借鉴一下思路
由于代码中有需要访问偏移表,这些偏移表是在so的第二个segment,这个segment的内存便宜和文件便宜不一样,跟windows加载pe一样存在一个拉伸的效果,所以为了模拟执行代码时可以正常访问到偏移表的数据,我们手动将so拉伸成内存视图:
这里借鉴无名侠大佬的思路,先把入口节点放到队列中,然后不停从队列中取节点,以这个节点为起点模拟执行,直到下一个br reg,或者是ret。
一个节点包括地址和上下文环境(寄存器),在模拟执行之前,需要把寄存器的值设置好,同时在找到分支之后,也需要保存现场的上下文环境。
在找到下一个br reg之后,计算出分支地址,将分支地址放到队列中,继续循环即可。
hook_code是在unicorn中注册的指令执行回调,当执行uc.emu_start(addr, 0x10000)之后,就会开始模拟执行指令,同时调用hook_code,在hook_code中有很多重要的逻辑。
进入hook_code之后,需要保存执行的汇编指令以及上下文环境,供后续判断是否到达混淆块使用:
这两个是函数的边界,执行到这里就需要停下,我没有找到如何优雅的判断执行到了bl .__stack_chk_fail,所以就判断bl后面的地址了。
需要跳过这些指令,并不影响寻路
先判断是否是br指令,如果是,调用get_double_branch尝试去进一步匹配特征
进入get_double_branch,遍历指令栈,判断是否存在特定的指令,如果有则获取指定寄存器的值,最后计算出两个分支地址,这几个指令存在先后顺序,所以需要几个标志变量来控制。
除了双分支,还有单分支的情况:

这种只有一个固定的分支,所以直接patch成 b 0xxxxxxxxx即可
所以如果上述特征匹配不成功,则认为是单分支
当遇到混淆块,计算出分支地址之后,就要进行patch了,双分支的patch需要两条指令的空间,但是有时候混淆块的倒数第二个指令是原来的指令,不能被覆盖,那么能用的就只有一条指令的空间。
那就只能找代码段中别的的空闲空间,调b跳转到空闲空间,然后在跳转到两个分支,找一个跳板。
当我在so中搜索nop时,居然发现了一段很长的nop,那用这里不就行了吗,反正去混淆也只是为了静态分析,不需要塞回去让so正常跑。
patch代码:
最后将so数据写回文件
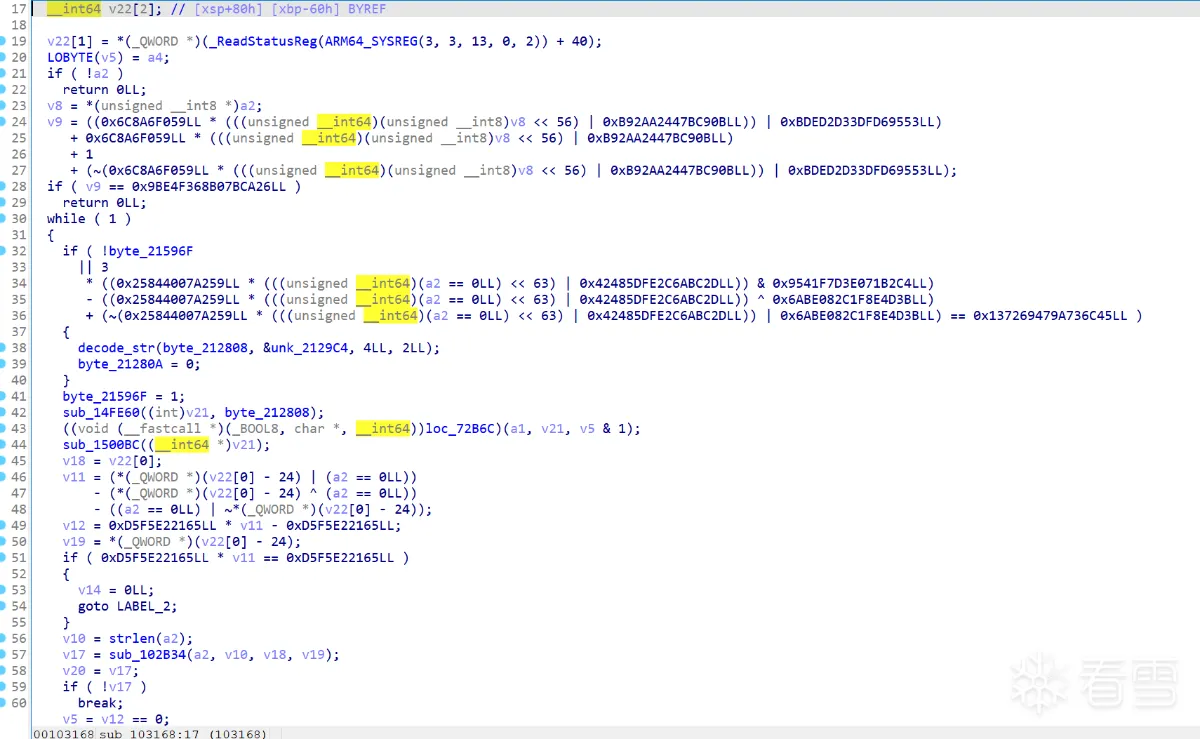
还存在一些虚假控制流,但是已经不影响分析了
CMP X19,
MOV W9,
MOV W10,
ADRP X25,
CSEL X9, X10, X9, EQ ; if X19 == 0 then X9 = X10
ADD X25, X25,
LDR X8, [X25,X9] ; X8 = qword[X25 + X9]
MOV W9,
MOV W10,
CSEL X9, X10, X9, EQ ; if X19 == 0 then X9 = X10
SUB X8, X8, X9 ; X8 = X8 - X9
BR X8 ; 跳转到X8
CMP X19,
MOV W9,
MOV W10,
ADRP X25,
CSEL X9, X10, X9, EQ ; if X19 == 0 then X9 = X10
ADD X25, X25,
LDR X8, [X25,X9] ; X8 = qword[X25 + X9]
MOV W9,
MOV W10,
CSEL X9, X10, X9, EQ ; if X19 == 0 then X9 = X10
SUB X8, X8, X9 ; X8 = X8 - X9
BR X8 ; 跳转到X8
beq addr1
b addr2
def load_elf(filename):
global img_size
global out_data
segs = []
with open(filename, 'rb') as f:
out_data = f.read()
for seg in ELFFile(f).iter_segments('PT_LOAD'):
print('file_off:%s, va: %s, size: %s' %(hex(seg['p_offset']), hex(seg['p_vaddr']), hex(seg['p_filesz'])))
segs.append((seg['p_offset'],seg['p_vaddr'], seg['p_filesz'], seg.data()))
img_size = segs[-1][1] + segs[-1][2]
byte_arr = bytearray([0] * img_size)
for seg in segs:
vaddr = seg[1]
size = seg[2]
data = seg[3]
byte_arr[vaddr: vaddr + size] = bytearray(data)
return byte_arr
def load_elf(filename):
global img_size
global out_data
segs = []
with open(filename, 'rb') as f:
out_data = f.read()
for seg in ELFFile(f).iter_segments('PT_LOAD'):
print('file_off:%s, va: %s, size: %s' %(hex(seg['p_offset']), hex(seg['p_vaddr']), hex(seg['p_filesz'])))
segs.append((seg['p_offset'],seg['p_vaddr'], seg['p_filesz'], seg.data()))
img_size = segs[-1][1] + segs[-1][2]
byte_arr = bytearray([0] * img_size)
for seg in segs:
vaddr = seg[1]
size = seg[2]
data = seg[3]
byte_arr[vaddr: vaddr + size] = bytearray(data)
return byte_arr
def init_unicorn(file_name):
global bin_data
global uc
bin_data = bytes(load_elf(file_name))
uc = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
uc.mem_map(0x80000000, 8 * 0x1000 * 0x1000)
uc.mem_map(0, 8 * 0x1000 * 0x1000)
uc.mem_write(0, bin_data)
uc.reg_write(UC_ARM64_REG_SP, 0x80000000 + 0x1000 * 0x1000 * 6)
uc.hook_add(UC_HOOK_CODE, hook_code)
uc.hook_add(UC_HOOK_MEM_UNMAPPED, hook_mem_access)
barr = uc.mem_read(0x144320, 8)
print(barr)
def init_unicorn(file_name):
global bin_data
global uc
bin_data = bytes(load_elf(file_name))
uc = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
uc.mem_map(0x80000000, 8 * 0x1000 * 0x1000)
uc.mem_map(0, 8 * 0x1000 * 0x1000)
uc.mem_write(0, bin_data)
uc.reg_write(UC_ARM64_REG_SP, 0x80000000 + 0x1000 * 0x1000 * 6)
uc.hook_add(UC_HOOK_CODE, hook_code)
uc.hook_add(UC_HOOK_MEM_UNMAPPED, hook_mem_access)
barr = uc.mem_read(0x144320, 8)
print(barr)
def deobf():
filename = 'libxxxx.so'
patched_filename = 'out.so'
start_addr = 0x0103168
init_unicorn(filename)
q = queue.Queue()
q.put((start_addr, None))
traced = {}
while not q.empty():
addr, context = q.get()
traced[addr] = 1
s = run(addr, context)
if s is None:
continue
if len(s) == 2:
if s[0] not in traced:
q.put(s)
else:
if s[0] not in traced:
q.put((s[0], s[2]))
if s[1] not in traced:
q.put((s[1], s[2]))
def run(addr, context):
global uc
global is_success
global block_flow
set_context(uc, context)
uc.emu_start(addr, 0x10000)
if is_success == True:
is_success = False
return block_flow[addr]
def deobf():
filename = 'libxxxx.so'
patched_filename = 'out.so'
start_addr = 0x0103168
init_unicorn(filename)
q = queue.Queue()
q.put((start_addr, None))
traced = {}
while not q.empty():
addr, context = q.get()
traced[addr] = 1
s = run(addr, context)
if s is None:
continue
if len(s) == 2:
if s[0] not in traced:
q.put(s)
else:
if s[0] not in traced:
q.put((s[0], s[2]))
if s[1] not in traced:
q.put((s[1], s[2]))
def run(addr, context):
global uc
global is_success
global block_flow
set_context(uc, context)
uc.emu_start(addr, 0x10000)
if is_success == True:
is_success = False
return block_flow[addr]
def hook_code(uc, address, size, user_data):
global ins_stack
global is_success
if is_success == True:
uc.emu_stop()
return
ins_help = InsHelp()
code = uc.mem_read(address, size)
ins = list(ins_help.disasm(code, address, False))[0]
print("[+] tracing instruction\t0x%x:\t%s\t%s" % (ins.address, ins.mnemonic, ins.op_str))
ins_stack.append((address, get_context(uc)))
def hook_code(uc, address, size, user_data):
global ins_stack
global is_success
if is_success == True:
uc.emu_stop()
return
ins_help = InsHelp()
code = uc.mem_read(address, size)
ins = list(ins_help.disasm(code, address, False))[0]
print("[+] tracing instruction\t0x%x:\t%s\t%s" % (ins.address, ins.mnemonic, ins.op_str))
ins_stack.append((address, get_context(uc)))
if ins.mnemonic.lower() == 'ret':
print("[+] encountered ret, stop")
ins_stack.clear()
uc.emu_stop()
return
if ins.mnemonic.lower() == 'bl' and ins.operands[0].imm == 0x237C0:
print("[+] encountered bl .__stack_chk_fail, stop")
ins_stack.clear()
uc.emu_stop()
return
if ins.mnemonic.lower() == 'ret':
print("[+] encountered ret, stop")
ins_stack.clear()
uc.emu_stop()
return
if ins.mnemonic.lower() == 'bl' and ins.operands[0].imm == 0x237C0:
print("[+] encountered bl .__stack_chk_fail, stop")
ins_stack.clear()
uc.emu_stop()
return
if ins.mnemonic.lower().startswith('bl') or is_ref_ilegel_emm(uc, ins) or ins.mnemonic.lower().startswith('svc'):
print("[+] pass instruction 0x%x\t%s\t%s" % (ins.address, ins.mnemonic, ins.op_str))
uc.reg_write(UC_ARM64_REG_PC, address + size)
return
def is_ref_ilegel_emm(mu, ins):
if ins.op_str.find('[') != -1:
if ins.op_str.find('[sp') == -1:
for op in ins.operands:
if op.type == ARM64_OP_MEM:
addr = 0
if op.value.mem.base != 0:
addr += mu.reg_read(reg_ctou(ins.reg_name(op.value.mem.base)))
if op.value.mem.index != 0:
addr += mu.reg_read(reg_ctou(ins.reg_name(op.value.mem.index)))
if op.value.mem.disp != 0:
addr += op.value.mem.disp
if 0x0 <= addr <= img_size:
return False
elif 0x80000000 <= addr < 0x80000000 + 0x1000 * 0x1000 * 8:
return False
else:
return True
else:
return False
else:
return False
if ins.mnemonic.lower().startswith('bl') or is_ref_ilegel_emm(uc, ins) or ins.mnemonic.lower().startswith('svc'):
print("[+] pass instruction 0x%x\t%s\t%s" % (ins.address, ins.mnemonic, ins.op_str))
uc.reg_write(UC_ARM64_REG_PC, address + size)
return
def is_ref_ilegel_emm(mu, ins):
if ins.op_str.find('[') != -1:
if ins.op_str.find('[sp') == -1:
for op in ins.operands:
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2024-1-17 06:59
被st0ne编辑
,原因: 修改格式









