上次发文章还在上次(近一年前了),当时写的好稚嫩啊2333,各位大师傅看我这篇文章应该也会有同样的感受吧hhh
想来上一次挖洞还在一年前的大一下,然后就一直在忙活写论文,感觉挺枯燥的(可能是自己不太适合弄学术吧QAQ),所以年初1~2月的时候,有空的时候就又会挖一挖国内外各大知名厂商的设备,拿了几份思科、小米等大厂商的公开致谢,也分配到了一些CVE和CNVD编号,之后就没再挖洞,继续忙活论文了QAQ。
某捷算是国内挺大的厂商了,我对其某系统进行了漏洞挖掘,并发现了一个可远程攻击的未授权命令执行漏洞,可以通杀使用该系统的所有路由器、交换机、中继器、无线接入点AP以及无线控制器AC等众多设备 ,危害还是相当严重的。
根据厂商的要求,在修补后的固件未发布前,我对该漏洞细节进行了保密。如今新版本固件都已经发布,在这里给大家分享一下这一次的漏洞挖掘经历(包括固件解密、仿真模拟、挖掘思路 等),希望能给各位师傅带来些许启发(大师傅们请绕道QAQ)。
声明: 本文仅供用于安全技术的交流与学习,文中涉及到的敏感内容都进行了删减或脱敏处理,仅分析了漏洞链。若读者将本文内容用作其他用途,由读者承担全部法律及连带责任,文章作者不承担任何法律及连带责任。
CVE编号:CVE-2023-34644 / CNVD编号:CNVD-2023-68249
2023-02-27:发现漏洞,并将该漏洞上报给了厂商
安全通告:864K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2J5N6h3W2B7K9h3g2Q4x3X3g2U0L8$3#2Q4x3X3g2U0L8W2)9J5c8X3N6&6i4K6u0r3P5s2N6Q4x3X3c8S2M7i4c8Y4i4K6u0V1k6%4N6Q4x3V1j5&6x3e0x3^5z5g2)9J5c8R3`.`. d1aK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2J5N6h3W2B7K9h3g2F1k6i4c8%4L8%4u0C8M7#2)9J5k6h3y4G2L8g2)9J5c8Y4y4#2M7s2m8G2M7Y4c8Q4x3V1k6K6k6h3y4#2M7X3W2@1P5f1u0#2L8r3I4W2N6r3W2F1M7#2)9J5c8X3y4&6j5X3g2J5M7$3g2U0N6i4u0A6N6s2W2Q4y4h3k6T1N6h3I4D9k6i4c8A6L8Y4y4Q4x3V1j5I4x3o6l9H3x3b7`.`.
CVSS 3.1评分:9.8(严重,CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H)
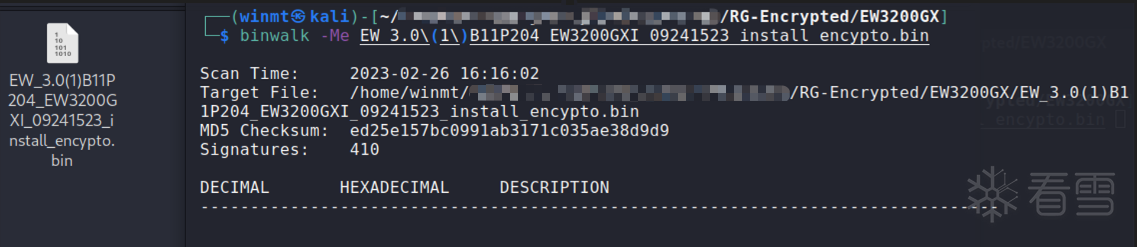
可以从厂商官网下载到最新固件,然而可以发现其中的固件大多都是加密的,用binwalk是无法解开的:通过解开这些未加密固件,找到解密程序,并逆向分析出相关算法 ,这也是固件解密最常用的一种手段。并且,一般一个厂商的固件加密算法都是相同的,故这样所有的固件我们都能够解开了。
此时,我们惊喜地发现xxx系列产品的xxx型号固件并没有被加密,可以成功解开。然而,如何找到固件的解密程序呢?显然,固件的解密操作肯定是在刷固件之前进行的,因此我们可以查找OpenWrt中用于刷固件的mtd命令进行定位 :rg-upgrade-crypto自然就是我们所要找到固件解密程序,并找到它的路径/usr/sbin/rg-upgrade-crypto,对其逆向分析。
(由于该加解密算法仍然被广泛应用于某捷的各类核心产品中,故这里不放出具体逆向分析的过程,此处省略xxx字........)
后注: 有很多师傅在问我,找不到过渡版本的固件怎么办?常见的可以考虑是简单的异或 加密,对于本固件来说,可参考:https://bbs.kanxue.com/thread-278816.htm#msg_header_h2_1 ,我和ZIKH26师傅简单说了一下,ZIKH26师傅记录的也很详细,我这里就不再赘述了。
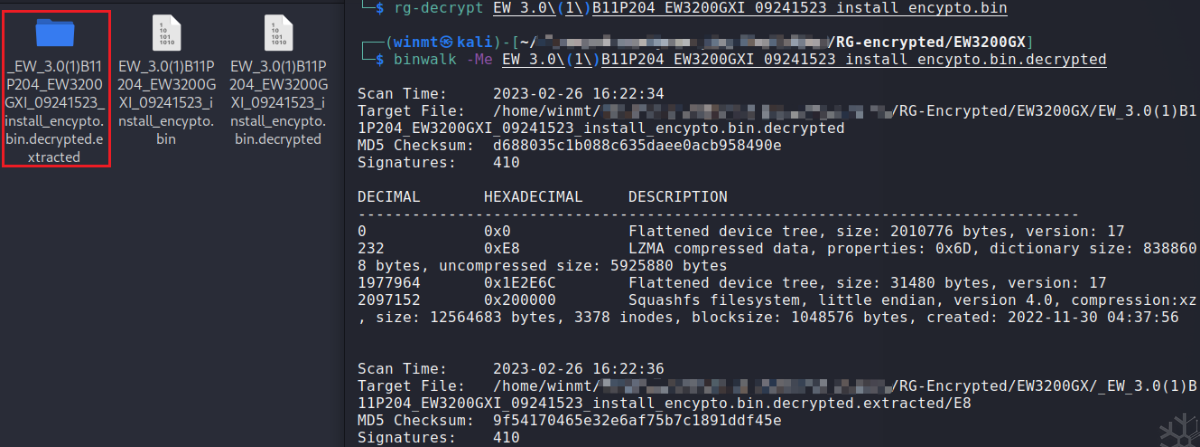
因此,我们只需要根据rg-upgrade-crypto写出解密脚本,即可成功解开固件了:未授权远程命令执行漏洞 。
此部分以xxx固件为例进行分析,该固件是aarch64架构的。其他固件也许架构或部分字段的偏移不同,但均存在该漏洞。
显然,此类固件的cgi部分是用Lua所写的。我们既然想要挖未授权的漏洞,那么首先就要找到无鉴权的API接口,定位到/usr/lib/lua/luci/controller/eweb/api.lua文件。
可以看到,只有对/cgi-bin/luci/api/auth发送请求的时候,不需要权限验证 :
根据调用的rpc_auth函数,可见此处对应的处理文件是/usr/lib/lua/luci/modules/noauth.lua:
进一步分析/usr/lib/lua/luci/utils/jsonrpc.lua中的handle及其相关函数,可以得知这里通过JSON数据的method字段定位并调用noauth.lua中对应的函数,同时将Json数据的params字段内容作为参数传入 (由于与该漏洞原理关系不大,此处不展开分析)。
在noauth.lua中,有login,singleLogin,merge和checkNet四个方法。其中,singleLogin函数无可控制的参数,不用看;checkNet函数中参数可控的字段只有params.host,并拼接入了命令字符串执行,但是在之前有tool.checkIp(params.host)对其的合法性进行了检查,无法绕过。
再来看到login登录验证函数,这里可控的字段乍一看比较多,比如params.password,params.encry,params.limit等字段。其中,对params.password字段用tool.includeXxs函数过滤了危险字符,故大概率之后会有相关的命令执行点。
再来看到继续调用的tool.checkPasswd函数(在/usr/lib/lua/luci/utils/tool.lua中),其中检测了传入的encry和limit字段的真假值,并在这两个字段中写入了相应的固定字符串,checkStat.username又是传入的固定用户名admin,因此真正可控的只有password字段 ,并调用了cmd.devSta.get函数进一步处理。
然而,虽然password字段用includeXxs函数(同样在tool.lua中)过滤了危险字符,但是并没有过滤\n这个命令分隔符 。因此,若之后当真存在命令执行点的话,似乎还是有希望完成命令注入的。
继续往下看到/usr/lib/lua/luci/modules/cmd.lua,devSta.get对应着如下处理函数,其中opt[i]循环匹配到get方式,会通过doParams函数对传入的Json参数进行解析,将其中的data等字段分离出来,传入fetch函数做进一步处理。
然而,注意到doParams函数中对data字段进行提取的时候,用到了luci.json.encode函数。这里的data字段就是上述checkPasswd函数中传入devSta.get作为Json参数的_data的内容,我们的疑似注入点password字段就在其中。此处的luci.json.encode函数会对\n(即\u000a)类字符进行转义,也就不会被解析成换行符了 ,不论我们后续再如何传参,这个疑似的漏洞点已经被封堵住了。
因此,我们只能将目光聚焦于noauth.lua中最后一个可能的入口merge方法了。这个函数比较简单,调用了devSta.set函数,其Json参数中的data字段就是传入的POST报文中params的内容 。
这里merge方法的入口处没有任何过滤,不过之后是否存在字符过滤和命令执行点还需要进一步分析。
在noauth.lua的merge函数中,调用了devSta.set函数,同样是对应着cmd.lua中的如下位置,此时opt[i]循环到了set方式。此时,由于之前没有任何过滤 ,无需使用换行符作为命令分隔符,最简单的分号、反引号之类的即可,故doParams函数中的encode不会造成影响。
接着,我们可控的data字段将被传入cmd.lua的fetch函数中。其中,会将从第四个开始的参数(包括data字段),均传递到第一个参数所指向的函数中,即/usr/lib/lua/dev_sta.lua中的fetch函数 。
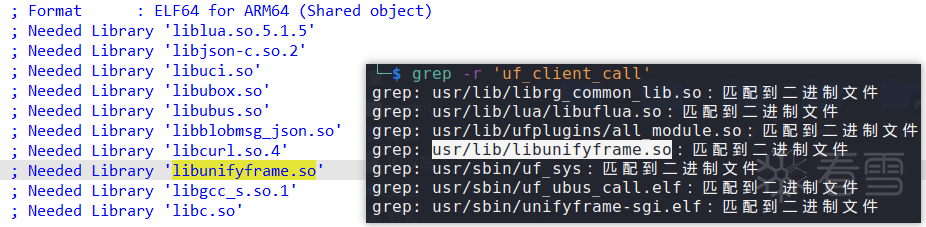
在/usr/lib/lua/dev_sta.lua的fetch函数中,这里的cmd是set方式,module是networkId_merge,而此处的param就是我们可控的data字段(即最初POST报文中params的内容)。可见,对一些字段赋予了真假值后,最终将参数都传递给了/usr/lib/lua/libuflua.so中的client_call函数 。接下来,就是对二进制文件逆向分析并寻找是否存在命令执行点了。
然而,分析libuflua.so可以发现,Lua中所调用的client_call函数,其实是uf_client_call函数 ,这是在其他共享库中定义的函数。查找对比一下,不难发现这个函数定义在/usr/lib/libunifyframe.so中。在/usr/lib/libunifyframe.so的uf_client_call函数 中,先将传入的data等字段转为Json格式的数据,作为param字段的内容。然后将Json数据通过uf_socket_msg_write用socket套接字(分析可知,此处采用的是本地通信的方式)进行数据传输 。
既然这里采用uf_socket_msg_write进行数据发送,那么肯定有某个地方会使用uf_socket_msg_read进行数据接收 ,再进一步处理。匹配一下,一共三个文件,很容易锁定/usr/sbin/unifyframe-sgi.elf文件。又发现在初始化脚本/etc/init.d/unifyframe-sgi中,启动了unifyframe-sgi.elf,即说明unifyframe-sgi.elf一直挂在进程中 。因此,我们可以确定unifyframe-sgi.elf就是接收libunifyframe.so所发数据的文件(这里采用了Ubus总线进行进程间通信)。
接下来就是最核心的部分,对unifyframe-sgi.elf二进制文件进行逆向分析并寻找命令执行点了。
由于篇幅限制,笔者无法对所有细节都做到详细分析,故建议读者在复现此部分内容之前,自己先逆向分析一遍,体会一下。
在unifyframe-sgi.elf中,对uf_socket_msg_read函数交叉引用 ,找到socket数据接收点。如下方代码段,v6 = 0x432000,简单计算一下,可知v57即为uf_socket_msg_read函数,其中接收到的数据存储在v56[1]中 。接收到的Json数据形如{"method":"devSta.set", "params":{"module":"networkId_merge", "async":true, "data":"xxx"}}(可结合上文,自行分析得出) ,其中data字段可控。
接下来就是根据调试等级向日志写入相关信息的部分,不需要管。之后,会调用parse_content函数,从这个名字就可以看出是对v56中的Json数据进行解析的。解析成功后,就会将处理后的v56作为参数传入add_pkg_cmd2_task函数。
我们先来看parse_content函数,显然method字段不包含cmdArr,因此进入else分支,其中调用parse_obj2_cmd函数进行数据解析。
在parse_obj2_cmd函数中,需要注意记录一下各字段存储位置的偏移,后续逆向过程需要用到。这里暂且只记录两个,from_url字段的偏移为81,我们可控的data字段的偏移为24v5是QWORD类型,八字节)。
此外,当async字段为false的时候,偏移76和77的位置都为1。但这里的async字段为true,故这两个偏移处均为初始值0 。
再来看到add_pkg_cmd2_task函数,前面部分是一些检查和无关操作,就不仔细分析了。很容易发现最后调用了一个很敏感的函数uf_cmd_call,看名字应该是命令执行相关的。
在uf_cmd_call函数中,乍一看,貌似有一个命令执行点,这里的v20是偏移24的位置,也就是data字段内容,之后将data字段中的数据转成Json格式存入v24,然后从中提取url字段的内容拼接入命令字符串中,并用popen执行。
然而,仔细分析一番,就会发现这是空欢喜一场。因为v19是偏移81的from_url字段,这是我们不可控的 。若是该字段为假,会将data字段内容传给v85[19] (v85是int64类型,八字节),并直接跳转到LABEL_96处,也就无法执行到上方的程序片段了 。
【2025年笔者注】: 当时笔者\S\B了,这里的from_url字段是可控的,from_url字段和data字段都是最初报文传进来的JSON报文体中param字段的一部分。当时或许是把这里的data字段,当作Lua里param传递给的data了,所以认为from_url不在param中,是不可控的了。逆的时候脑子不好使搞混了,也没验证QAQ...让我惊奇的是,竟然时隔本文发表后两年半(一坤年)才有人发现这个问题,感谢福州大学ROIS的Sheep师傅指出,这里也产生了一个新的CVE,锐捷PSIRT团队也是一如既往快速且负责地修复了:e2aK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2J5N6h3W2B7K9h3g2Q4x3X3g2U0L8$3#2Q4x3X3g2U0L8W2)9J5c8X3N6&6i4K6u0r3P5s2N6Q4x3X3c8S2M7i4c8Y4i4K6u0V1P5Y4N6Q4x3V1j5&6x3K6l9I4z5e0m8Q4x3V1j5`.
从LABEL_96处开始是一堆字段的提取,存放入v85数组中,还有一些关于v85数组中数据的处理。这里需要关注的是:v85偏移8和9的位置为a1偏移77和76的位置(上文分析过,此时这两个偏移的值均为0)
既然从LABEL_96开始都是对v85数组进行操作的,那么v85指针肯定会作为参数传递给下一个调用的函数 ,以这个思路,就很容易定位到下面的ufm_handle(v85)了。
在ufm_handle函数中,由于我们是set方式,因此会调用到sub_410140函数。
进入sub_410140函数,首先sn字段为空的条件满足,跳转到LABEL_36。
接着,会调用到sub_40DA38函数。
在sub_40DA38函数中,显然前面的部分无关紧要,不过需要注意一下v5和v6分别是a3和a4,根据传入的值,均为零。因此,进入else分支,这里会将data字段的内容(前文分析过,此处偏移19*8的位置也被赋为了data字段的内容)拼接入两个单引号内。此处v4字符串形如/usr/sbin/module_call set networkId_merge 'xxx'(可自行分析得出) ,很显然是一个命令,并且单引号内的内容我们可控,所以我们只需要左右分别闭合单引号,中间注入恶意命令,并用分隔符隔开 即可完成命令注入。不过,这里还没到命令执行点,由于不确定之后是否会有过滤,我们需要接着往下看。
接着,由之前的分析,此处v7偏移8的位置为0(async不是false),故进入else分支,其中会将v4传入ufm_commit_add函数,作为第二个参数。
然后,继续进入async_cmd_push_queue函数。
此处,a1为0,将a2存入v4偏移6*8字节处 ,然后跳转到LABEL_28的位置。
在LABEL_28处,注意到最后使用sem_post的原子操作,将信号量加上了1。因此,应该会有其他地方在检测到信号量发生改变后,对数据进行处理 。
通过对此处的信号量stru_433670交叉引用 ,可以定位到sub_419584函数。这里偏移56的位置即为上述代码段中的v7,对应传入的第三个参数,根据上文分析,其值为0。因此,会将6*8字节偏移处的数据(上文分析过,该偏移位置存放着命令字符串)作为popen的参数执行,且没有任何过滤。此处采用的是异步执行 的方式。
至此,该未授权RCE漏洞的调用链分析完毕。
由于该漏洞影响较大,Poc暂不公开。各位师傅可根据上文分析,自行复现。
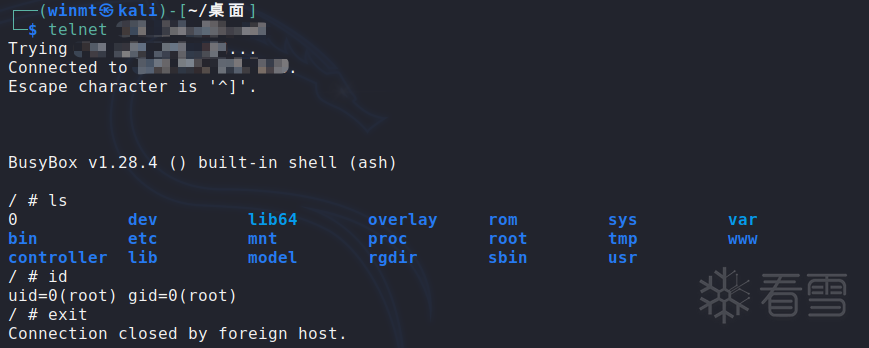
对某远程测试靶机攻击后,无需身份验证即得到了该设备的最高控制权:
此部分仿真采用的是xxx型号的固件,因为这款是mipsel架构的,仿真起来方便一些。
由于目前没有很完美的仿真工具,比较常用的FirmAE,EMUX,firmware-analysis-plus等也都存在各种问题(至少直接仿真大多数设备都是不太行的),所以笔者一般都采用qemu-system自行仿真模拟,再者该系统的固件不涉及到nvram,采用的是uci命令完成类似的效果,故也不需要用上述仿真工具来hook相关函数了。
首先从8cfK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6H3k6h3!0H3L8r3g2Q4x3X3g2V1k6h3u0A6j5h3&6Q4x3X3g2G2M7X3N6Q4x3V1k6Q4y4@1g2S2N6i4u0W2L8o6x3J5i4K6u0r3M7h3g2E0N6g2)9J5c8X3#2A6M7s2y4W2L8l9`.`. vmlinux-3.2.0-4-4kc-malta内核与debian_squeeze_mipsel_standard.qcow2文件系统,这里提供的文件虽然是比较老的了(较新版可以在c5aK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6H3N6h3u0Q4x3X3g2K6k6i4u0Y4k6i4k6Q4x3X3g2G2M7X3N6Q4x3V1k6#2L8X3W2^5i4K6u0r3k6r3g2T1K9h3q4F1i4K6u0V1L8$3&6Q4x3X3c8E0K9i4m8K6x3K6t1`.
下面直接给出qemu的启动脚本:
需要特别注意的是,这里设定了cpu为74kf,因为若不特别说明,默认是24Kc,而该固件需要较高版本的cpu,不然在之后chroot切换根目录的时候就会出现Illegal instruction(非法指令)错误 。可用qemu-system-mipsel -cpu help命令查看qemu-system-mipsel所有支持的cpu版本。
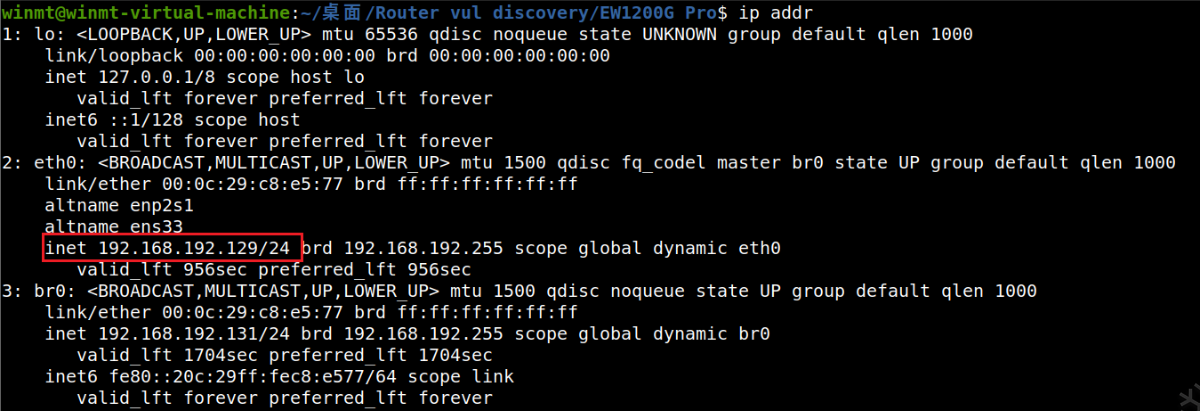
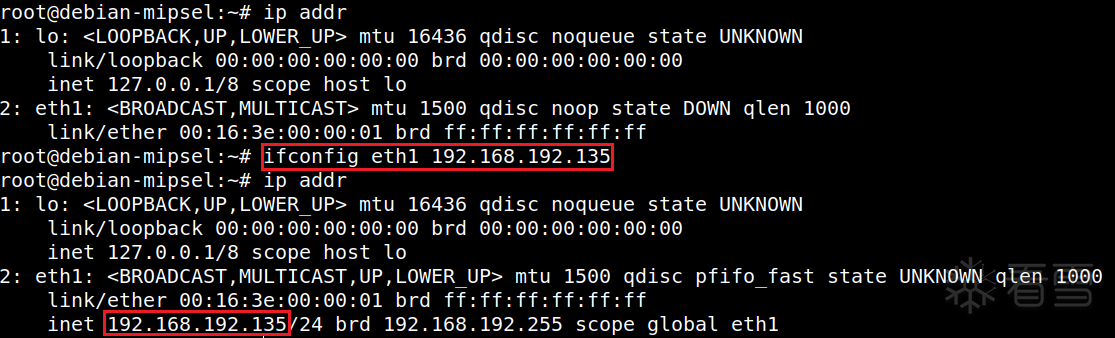
在正式开始仿真前,需要先进行网络配置。用ip addr或ifconfig命令查看一下主机的ip,如下图为eth0(或ens33)对应的192.168.192.129,若是没有,手动用sudo ifconfig eth0 xx.xx.xx.xx分配一下即可。qemu-system(先需要配置一下/etc/qemu-ifup),初始账号密码root/root。在qemu中,也需要给网卡分配一下ip,这样主机和qemu间就能通信了(可以互相ping通)。rootfs.tar.gz,再通过scp rootfs.tar.gz root@192.168.192.135:/root/rootfs传输给qemu虚拟机,然后在qemu虚拟机中tar zxvf rootfs.tar.gz解压即可(打包之后传输更快)。接着,在qemu中依次执行以下命令:
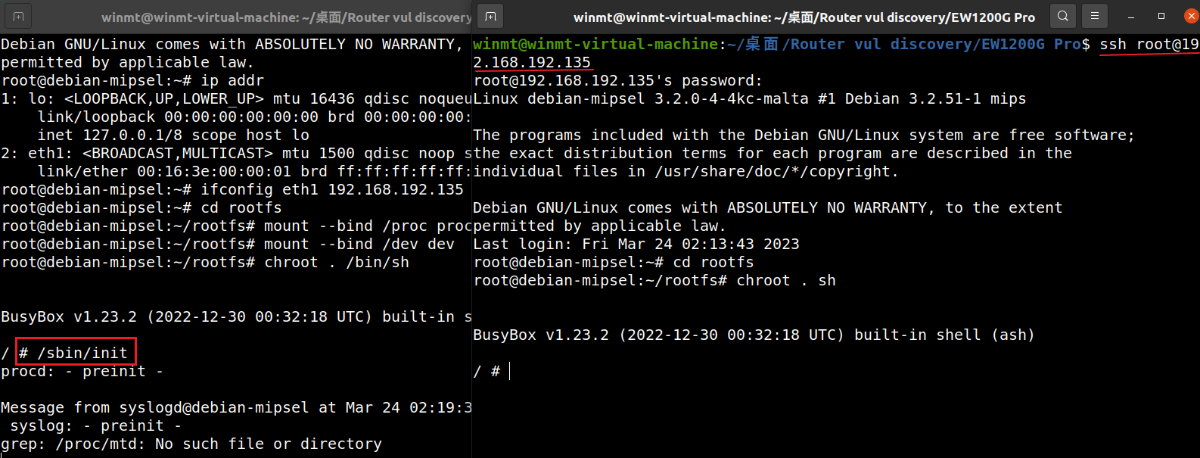
解释一下,这里chmod给全部文件都赋予所有权限,是为了方便在仿真过程中不用再考虑权限问题的影响了。之后使用mount将/proc和/dev系统目录挂载到rootfs中的proc和dev目录(仿真系统只是切换了根目录,本质还是qemu虚拟机的系统,故proc和dev这两个重要的系统目录仍应该是这个系统本身的目录,即qemu虚拟机的系统目录,而切换了根目录后,proc和dev也被切换,因此需要挂载为原先的目录),最后用chroot将rootfs切换为根目录,完成准备工作。
以上都是些用qemu对设备仿真模拟的基本操作,接下来正式开始对这款设备的固件进行仿真。首先,对于OpenWRT来说,内核加载完文件系统后,首先会启动/sbin/init进程 ,其中会进一步执行/etc/preinit和/sbin/procd,进行初步初始化。这当然也是仿真模拟的第一步,在启动/sbin/init后,会卡住挂在进程中,我们可以再ssh开一个新窗口进行后续操作,也可以用/sbin/init &将其作为后台进程执行 。/etc/inittab中按编号次序执行/etc/rc.d中的初始化脚本,而/etc/rc.d中的文件都是/etc/init.d中对应文件的软链接。虽然说真实系统会依次执行所有的初始化脚本,但我们此处的仿真只是为了验证我们的漏洞,因此只需要部分仿真即可。
显然,我们最开始肯定是需要启动httpd服务的,对应/etc/init.d/lighttpd初始化脚本 。用/etc/init.d/lighttpd start命令启动服务后,发现缺少了/var/run/lighttpd.pid文件:/rom/etc/lighttpd/lighttpd.conf的缺失并无影响。因此,创建/var/run/lighttpd.pid文件后,再次/etc/init.d/lighttpd start启动服务 即可。
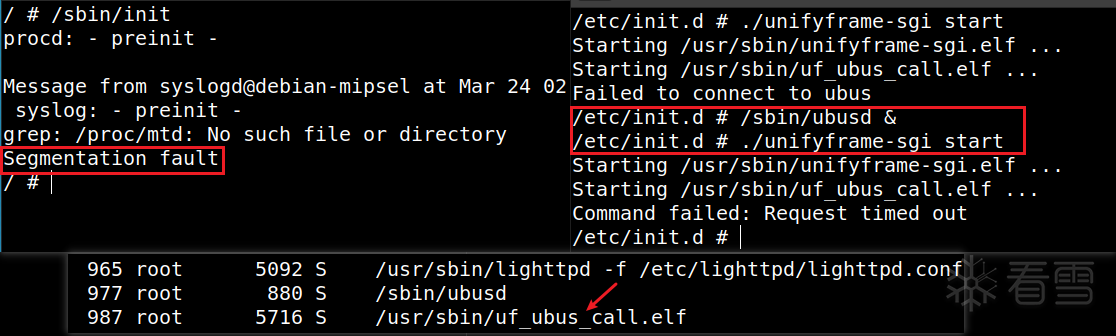
可以看到,此时进程中已经成功执行lighttpd程序,并且通过浏览器可以正常访问该漏洞入口的api。我们需要启动unifyframe-sgi.elf了,对应/etc/init.d/unifyframe-sgi的初始化脚本 。用/etc/init.d/unifyframe-sgi start直接启动后,报错Failed to connect to ubus:因为unifyframe-sgi.elf中用到了ubus总线进行进程间通信 ,因此需要先执行/sbin/ubusd启动ubus通信,才能启动uf_ubus_call.elf,继而才能再启动unifyframe-sgi.elf 。
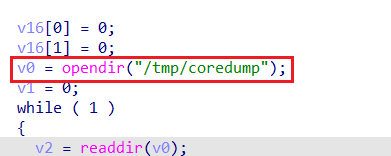
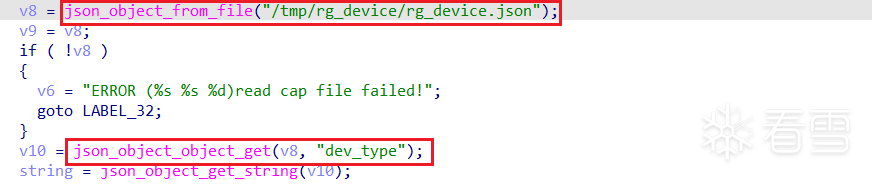
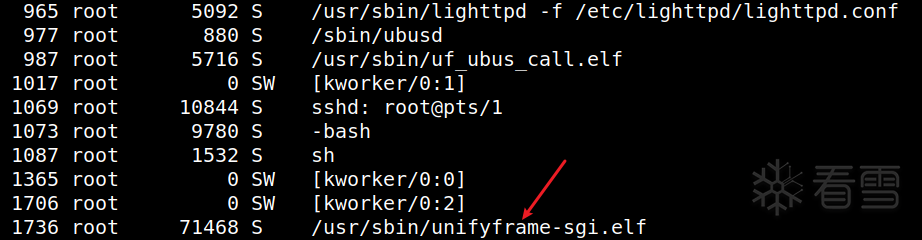
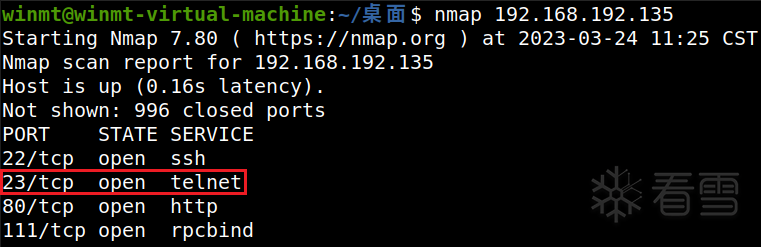
按照上述步骤启动后,可以发现进程中有了uf_ubus_call.elf,但是仍然没有unifyframe-sgi.elf,同时procd守护进程收到了一个Segmentation fault段错误的信号,意味着启动unifyframe-sgi.elf的时候出现了段错误 。unifyframe-sgi.elf为何会出现段错误,大概率是由于缺少一些文件或目录所导致的。首先,发现此时/tmp/uniframe_sgi中已经存在record文件夹,但并未创建sgi.log日志文件,进入unifyframe-sgi.elf的主函数,容易定位到reserve_core函数,其中需要打开/tmp/coredump目录,但这个目录此时是不存在的,因此造成了段错误 。/tmp/coredump目录后,运行/usr/sbin/unifyframe-sgi.elf程序,因缺少/tmp/rg_device/rg_device.json文件 报错:rg_device.json大概率是在某前置操作中从其他位置复制过来的,故搜索同名文件,不过有很多:ufm_init函数中,发现此处之后会从rg_device.json中读取dev_type字段 的内容。/sbin/hw/default/rg_device.json中都有此字段,这里随便复制一个/sbin/hw/60010081/rg_device.json到/tmp/rg_device目录下 。之后再执行/usr/sbin/unifyframe-sgi.elf程序,就发现没有新的报错,执行成功了。/usr/sbin/unifyframe-sgi.elf程序在运行。telnetd命令启动相应服务,可以看到代表telnet服务的23号端口被成功开启 。
遗憾的是,部分型号设备的固件在第一次修补之后仍存在漏洞,笔者已上报给厂商并修复。这里以xxx固件为例,使用Diaphora对新旧版本的unifyframe-sgi.elf文件进行二进制对比分析。
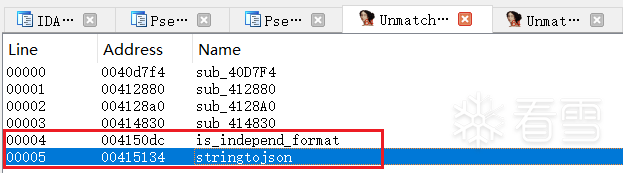
容易发现,在新版固件的unifyframe-sgi.elf文件中新增了stringtojson和is_independ_format函数:stringtojson函数中,调用了is_independ_format函数,判断是否存在单引号和反引号 。若不存在就返回,而返回的内容无法通过单引号闭合 ,也就无法执行任意命令。
若是存在单引号,且前面没有转义符,则对其Unicode编码 ,即\\u0027。反引号也同理。
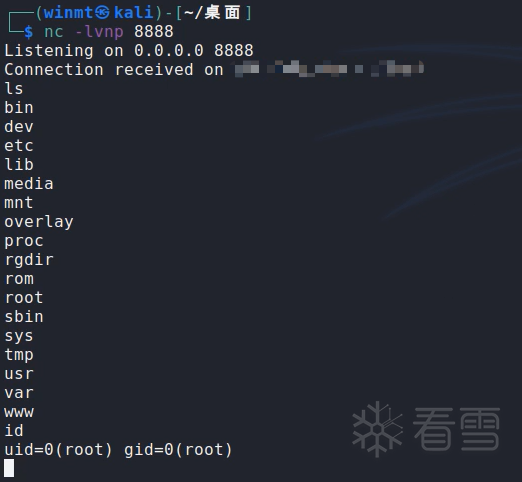
进一步交叉引用,在sub_40DB48函数中,对可控的数据用stringtojson函数进行了过滤。然而,这里的过滤并不严谨,接着往下看。v74不为空,则存放着stringtojson函数过滤后的内容,否则说明不存在单引号或反引号,也就未通过stringtojson函数进行过滤。又由于stringtojson函数处理后会带有双引号 ,故若包含了单引号或反引号,该命令在新版固件中实际为/usr/sbin/module_call set networkId_merge "{...}" 。虽然由于JSON数据中双引号得是\"才行(stringtojson函数也会将双引号编码为\\u0022),无法闭合绕过双引号,但是在双引号内是可以用反引号或$()执行命令 的,而这里只过滤了反引号,并未过滤$() ,也就给了攻击者可趁之机。/etc/init.d/factory中通过rm usr/sbin/telnetd命令删除了telnetd程序 ,也就无法通过开启远程登录而控制设备了。但是,不难想到还可以通过反弹shell获取设备权限,这里笔者采用的是 telnet反弹 的方式。
请求报文:
演示效果:
其实,只要在noauth.lua的merge函数中对传入的params加个过滤即可,如下:
此处,通过includeXxs函数过滤了各种危险字符,以及用includeQuote函数过滤了单引号:
可见,在新版本固件中,将换行符\n也过滤了,提高了安全性。
这篇文章是在挖到这个0day挺久之后写的了。依稀记得当时刚挖到这个漏洞的时候,有着些许兴奋,但更多的是感到不易,因为我当时觉得这条调用链还挺深的,里面也牵涉到了不少东西。但是,当我如今再梳理这个漏洞的相关细节的时候,我觉得这条调用链其实也就那样吧,整个挖掘思路和利用思路都不算难,抛开影响范围,并算不上品相多好的洞QAQ。
在挖这个洞的时候,我遇到的最大挑战就是逆向分析了,我觉得这里的逆向难度还是比较大的(当然我逆向水平也很菜)。在实际逆向分析的过程中,并没有文章中写的那么流畅,当时的挖掘思路也不可能是完全按照文章的流程来的,比如需要多考虑一些东西(例如,文章中一直都在找命令注入的洞,但其实也有可能是可控的params字段造成的缓冲区溢出等等,这些在初次挖掘的时候也都需要考虑),当然也走了不少弯路,但好在最终是坚持下来了。
当时,我只知道params字段是可控的,而params内也是Json的格式,于是猜测是其中的某个特定的字段可能会造成命令注入或缓冲区溢出等问题,因此就一路挖到底了。不过如今再看来,其实就这个洞而言,是否采用自动化的方式会更简单呢(当然就工业界来说,IoT的全自动化漏扫我并没有看到过实际效果很好的工具,基本都是半自动化提高效率)?
进一步地从宏观上来看二进制漏洞的挖掘思路,无非就是从危险函数出发和从交互入口出发两种方式,显然前者在筛掉明显无法利用的危险函数点之后,所涉及的支路会更少,挖起来也会更容易,而后者基本是要从交互入口一路挖到中断点甚至挖到底的。然而,该漏洞却是采用后者的思路进行挖掘的,当时主要是考虑到只有一个可能的未授权入口,因此很自然地采用了后者的思路。现在想来,这里若是采用前者的思路,可能并不会那么容易地挖到此漏洞。如何更好地结合上述两种思路,特别是对于自动化漏扫来说,我觉得仍是值得思考的问题。
说了些自己粗浅的理解和感受,就说到这里吧。希望这篇文章能给各位像我一样刚入门IoT漏洞挖掘的师傅带来些启发,也欢迎各位大师傅与我交流。最后,希望我在不久的将来能挖到在挖掘思路和利用手法上都有所创新的高质量0day吧。
entry({"api", "auth"}, call("rpc_auth"), nil).sysauth = false
entry({"api", "auth"}, call("rpc_auth"), nil).sysauth = false
function rpc_auth()
...
local _tbl = require "luci.modules.noauth"
...
ltn12.pump.all(jsonrpc.handle(_tbl, http.source()), http.write)
end
function rpc_auth()
...
local _tbl = require "luci.modules.noauth"
...
ltn12.pump.all(jsonrpc.handle(_tbl, http.source()), http.write)
end
function login(params)
...
if params.password and tool.includeXxs(params.password) then
tool.eweblog("INVALID DATA", "LOGIN FAILED")
return
end
...
local checkStat = {
password = params.password,
username = "admin", -- params.username,
encry = params.encry,
limit = params.limit
}
local authres, reason = tool.checkPasswd(checkStat)
...
end
function login(params)
...
if params.password and tool.includeXxs(params.password) then
tool.eweblog("INVALID DATA", "LOGIN FAILED")
return
end
...
local checkStat = {
password = params.password,
username = "admin", -- params.username,
encry = params.encry,
limit = params.limit
}
local authres, reason = tool.checkPasswd(checkStat)
...
end
function checkPasswd(checkStat)
...
local _data = {
type = checkStat.encry and "enc" or "noenc",
password = checkStat.password,
name = checkStat.username,
limit = checkStat.limit and "true" or nil
}
local _check = cmd.devSta.get({module = "adminCheck", device = "pc", data = _data})
...
end
function checkPasswd(checkStat)
...
local _data = {
type = checkStat.encry and "enc" or "noenc",
password = checkStat.password,
name = checkStat.username,
limit = checkStat.limit and "true" or nil
}
local _check = cmd.devSta.get({module = "adminCheck", device = "pc", data = _data})
...
end
function includeXxs(str)
local ngstr = "[`&$;|]"
return string.match(str, ngstr) ~= nil
end
function includeXxs(str)
local ngstr = "[`&$;|]"
return string.match(str, ngstr) ~= nil
end
devSta[opt[i]] = function(params)
local model = require "dev_sta"
params.method = opt[i]
params.cfg_cmd = "dev_sta"
local data, back, ip, password, shell = doParams(params)
return fetch(model.fetch, shell, params, opt[i], params.module, data, back, ip, password)
devSta[opt[i]] = function(params)
local model = require "dev_sta"
params.method = opt[i]
params.cfg_cmd = "dev_sta"
local data, back, ip, password, shell = doParams(params)
return fetch(model.fetch, shell, params, opt[i], params.module, data, back, ip, password)
if params.data then
data = luci.json.encode(params.data)
_shell = _shell .. " '" .. data .. "'"
end
if params.data then
data = luci.json.encode(params.data)
_shell = _shell .. " '" .. data .. "'"
end
function merge(params)
local cmd = require "luci.modules.cmd"
return cmd.devSta.set({device = "pc", module = "networkId_merge", data = params, async = true})
end
function merge(params)
local cmd = require "luci.modules.cmd"
return cmd.devSta.set({device = "pc", module = "networkId_merge", data = params, async = true})
end
devSta[opt[i]] = function(params)
local model = require "dev_sta"
params.method = opt[i]
params.cfg_cmd = "dev_sta"
local data, back, ip, password, shell = doParams(params)
return fetch(model.fetch, shell, params, opt[i], params.module, data, back, ip, password)
devSta[opt[i]] = function(params)
local model = require "dev_sta"
params.method = opt[i]
params.cfg_cmd = "dev_sta"
local data, back, ip, password, shell = doParams(params)
return fetch(model.fetch, shell, params, opt[i], params.module, data, back, ip, password)
local function fetch(fn, shell, params, ...)
...
local _res = fn(...)
...
end
local function fetch(fn, shell, params, ...)
...
local _res = fn(...)
...
end
function fetch(cmd, module, param, back, ip, password, force, not_change_configId, multi)
local uf_call = require "libuflua"
...
local stat = uf_call.client_call(ctype, cmd, module, param, back, ip, password, force, not_change_configId, multi)
...
end
function fetch(cmd, module, param, back, ip, password, force, not_change_configId, multi)
local uf_call = require "libuflua"
...
local stat = uf_call.client_call(ctype, cmd, module, param, back, ip, password, force, not_change_configId, multi)
...
end
json_object_object_add(v22, "data", v35);
LABEL_82:
...
json_object_object_add(v5, "params", v22);
v44 = (const char *)json_object_to_json_string(v5);
...
v45 = uf_socket_client_init(0LL);
...
v51 = strlen(v44);
uf_socket_msg_write(v45, v44, v51);
json_object_object_add(v22, "data", v35);
LABEL_82:
...
json_object_object_add(v5, "params", v22);
v44 = (const char *)json_object_to_json_string(v5);
...
v45 = uf_socket_client_init(0LL);
...
v51 = strlen(v44);
uf_socket_msg_write(v45, v44, v51);
$ cat etc/init.d/unifyframe-sgi
...
PROG=/usr/sbin/unifyframe-sgi.elf
...
if [ -f "$IPKG_INSTROOT/lib/functions/procd.sh" ]; then
...
else
...
start() {
...
echo "Starting $PROG ..."
service_start $PROG
...
}
stop() {
...
}
fi
$ cat etc/init.d/unifyframe-sgi
...
PROG=/usr/sbin/unifyframe-sgi.elf
...
if [ -f "$IPKG_INSTROOT/lib/functions/procd.sh" ]; then
...
else
...
start() {
...
echo "Starting $PROG ..."
service_start $PROG
...
}
stop() {
...
}
fi
v6 = 0x432000uLL;
...
v57 = *(__int64 (__fastcall **)(__int64, unsigned int **))(v6 + 1784);
v58 = *v46;
*v56 = v46;
v59 = v57(v58, v56 + 1);
v6 = 0x432000uLL;
...
v57 = *(__int64 (__fastcall **)(__int64, unsigned int **))(v6 + 1784);
v58 = *v46;
*v56 = v46;
v59 = v57(v58, v56 + 1);
if ( !(*(unsigned int (__fastcall **)(unsigned int **))(v6 + 3328))(v56) )
{
...
if ( !(*(unsigned int (__fastcall **)(unsigned int **))(v6 + 1776))(v56) )
...
}
if ( !(*(unsigned int (__fastcall **)(unsigned int **))(v6 + 3328))(v56) )
{
...
if ( !(*(unsigned int (__fastcall **)(unsigned int **))(v6 + 1776))(v56) )
...
}
if ( (unsigned int)json_object_object_get_ex(v4, "method", &v15) == 1 )
{
v6 = (const char *)json_object_get_string(v15);
...
if ( strstr(v6, "cmdArr") )
{
...
}
else
{
*(_DWORD *)(a1 + 60) = 1;
v13 = malloc_cmd();
if ( v13 )
{
v14 = parse_obj2_cmd(v4, string);
...
}
else
{
...
}
}
if ( (unsigned int)json_object_object_get_ex(v4, "method", &v15) == 1 )
{
v6 = (const char *)json_object_get_string(v15);
...
if ( strstr(v6, "cmdArr") )
{
...
}
else
{
*(_DWORD *)(a1 + 60) = 1;
v13 = malloc_cmd();
if ( v13 )
{
v14 = parse_obj2_cmd(v4, string);
...
}
else
{
...
}
}
if ( (unsigned int)json_object_object_get_ex(v42, "from_url", &v43) == 1 )
{
v21 = (const char *)sub_4069B8(v43);
v22 = (char *)v21;
if ( v21 )
{
if ( *v21 == 49 || !strcmp(v21, "true") )
*((_BYTE *)v5 + 81) = 1;
free(v22);
}
if ( (unsigned int)json_object_object_get_ex(v42, "from_url", &v43) == 1 )
{
v21 = (const char *)sub_4069B8(v43);
v22 = (char *)v21;
if ( v21 )
{
if ( *v21 == 49 || !strcmp(v21, "true") )
*((_BYTE *)v5 + 81) = 1;
free(v22);
}
_QWORD *v5;
...
if ( (unsigned int)json_object_object_get_ex(v42, "data", &v43) == 1
&& (unsigned int)json_object_get_type(v43) - 4 <= 2 )
{
if ( json_object_get_string(v43) )
{
v31 = ((__int64 (*)(void))strdup)();
v5[3] = v31;
...
}
}
_QWORD *v5;
...
if ( (unsigned int)json_object_object_get_ex(v42, "data", &v43) == 1
&& (unsigned int)json_object_get_type(v43) - 4 <= 2 )
{
if ( json_object_get_string(v43) )
{
v31 = ((__int64 (*)(void))strdup)();
v5[3] = v31;
...
}
}
if ( (unsigned int)json_object_object_get_ex(v42, "async", &v43) == 1 )
{
v15 = (const char *)sub_4069B8(v43);
v16 = (char *)v15;
if ( v15 )
{
if ( *v15 == 48 || !strcmp(v15, "false") )
{
*((_BYTE *)v5 + 76) = 1;
*((_BYTE *)v5 + 77) = 1;
}
...
}
}
if ( (unsigned int)json_object_object_get_ex(v42, "async", &v43) == 1 )
{
v15 = (const char *)sub_4069B8(v43);
v16 = (char *)v15;
if ( v15 )
{
if ( *v15 == 48 || !strcmp(v15, "false") )
{
*((_BYTE *)v5 + 76) = 1;
*((_BYTE *)v5 + 77) = 1;
}
...
}
}
if ( (unsigned int)uf_cmd_call(*v4, v4 + 1) )
v13 = 2;
else
v13 = 1;
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2025-11-12 00:16
被winmt编辑
,原因: 修正一坤年前的表述错误















 太强了
太强了





