本文档是进行完相关分析之后的总结回忆, 所以可能有的地方的花指令是被去除了再截图的, 函数名和数据结构被重命名了. 这决赛的混淆太恶心了,我无法做到将代码还原, 所以完全手撕汇编做的.
这一部分和初赛是一样的, il2cpp那块并没有过多的加密, 还是和初赛一样从内存中将libil2cpp.so dump下来之后使用il2cppdumper得到对应的cs文件, 定位到MouseController__CollectCoin方法中, 找到偏移0x4652AC这里, 使用gg修改器将CMP W0, #0x3E8这条指令修改为CMP W0, #0之后随便吃一个金币得到flag.
有了初赛的经验, 所以这次也是将frida_server的二进制文件patch掉re.frida.server字符串, 并且使用./fs -l 0.0.0.0:2394命令切换监听端口, 为了保证万无一失, 将工作目录从tmp文件夹移到别的地方取, 这样一来就能够成功过掉这一大类的检测.
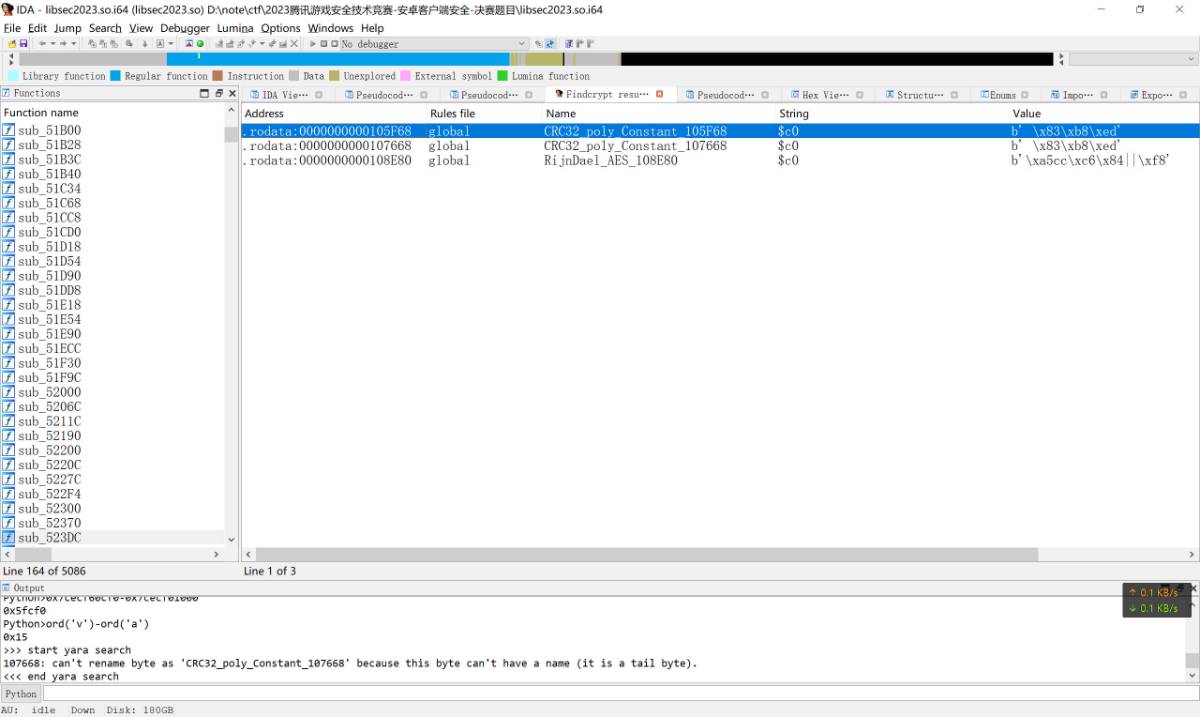
但是也是一样的, 除了文件检测和端口检测, libsec2023.so中还有针对代码段的crc检测, 使用findcrypt插件从so文件的特征中也能够发现. 意外的这里还看到了aes特征, 后面的算法也有可能使用到了aes算法, 只是说可能.
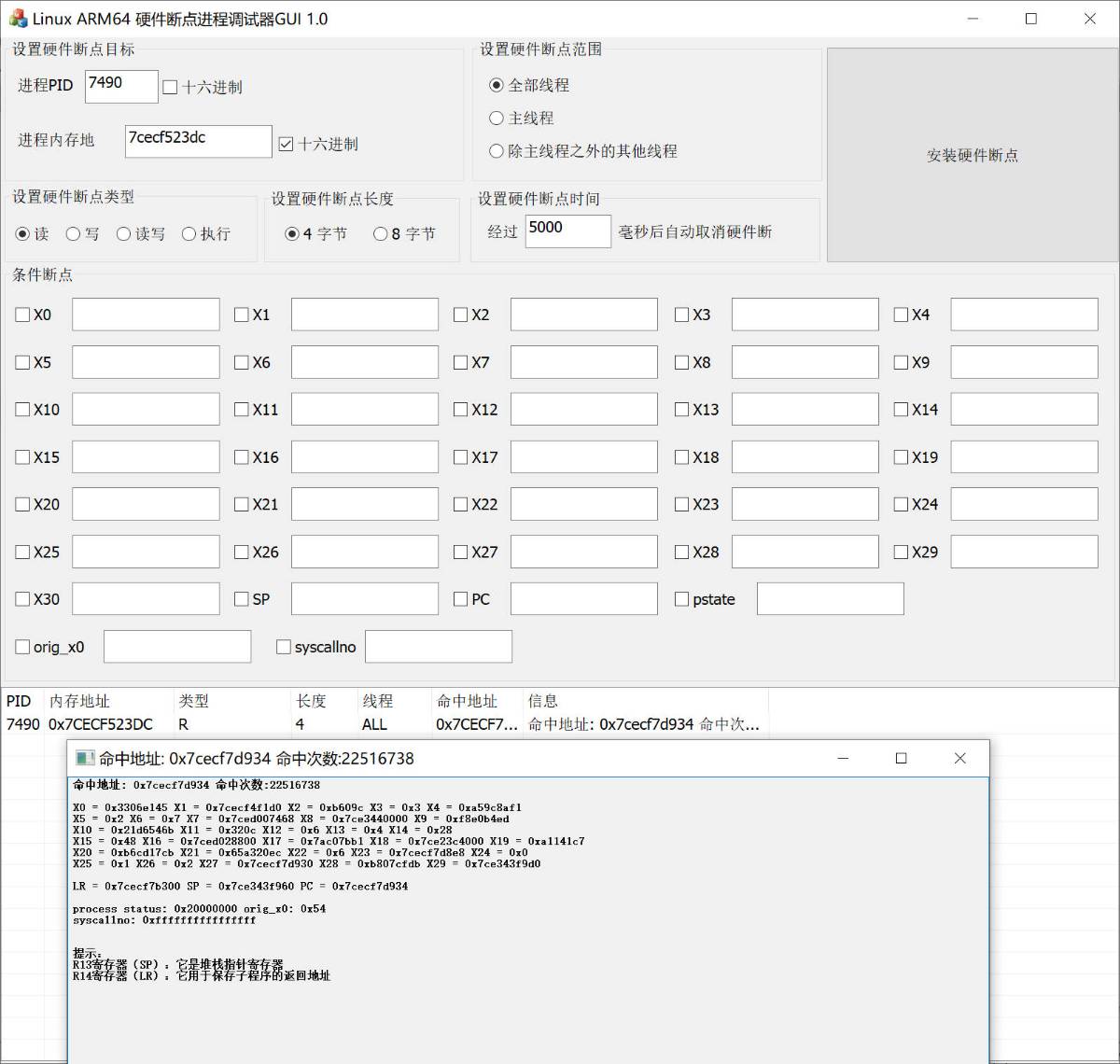
也是同初赛一样, 对于crc检测一定是不间断的读取代码段数据, 所以只需要对其代码段下一个硬件读写断点就能够定位到检测的关键点. 我依旧是使用rwProcMem项目中的内核硬件断点程序进行操作, 在libsec2023.so的内存区域中随意选择一个地址, 如下图所示成功定位到读取的关键点.
此时libsec2023.so的内存基址是0x7cecf00000. 可以定位到读取内存段的代码在libsec2023.so + 0x7d934处, 这里因为混淆方式的改变, 所以f5也不能和初赛一样将其还原出来, 因此只能查看汇编代码.
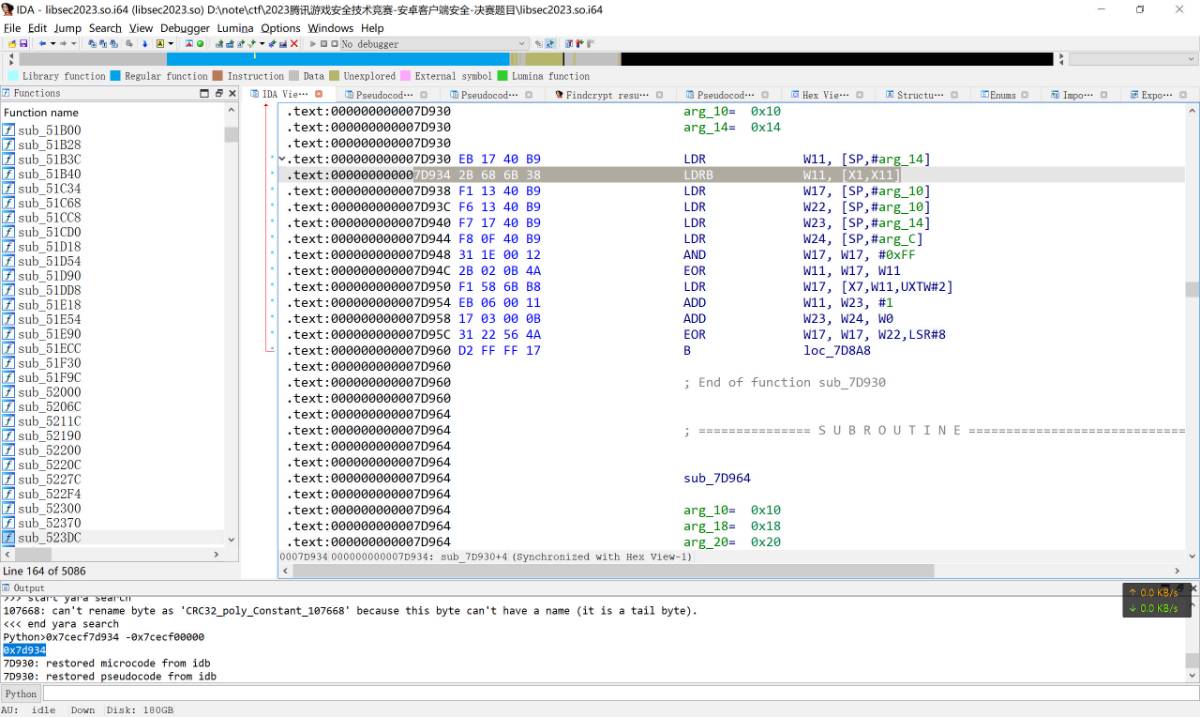
这里因为被混淆了, 并且这里只是做了读取内存的操作, 所以找不到合适的patch点, 此时查看lr寄存器, 可以得到调用读取函数的返回的上一层地址是libsec2023.so + 0x7B300.
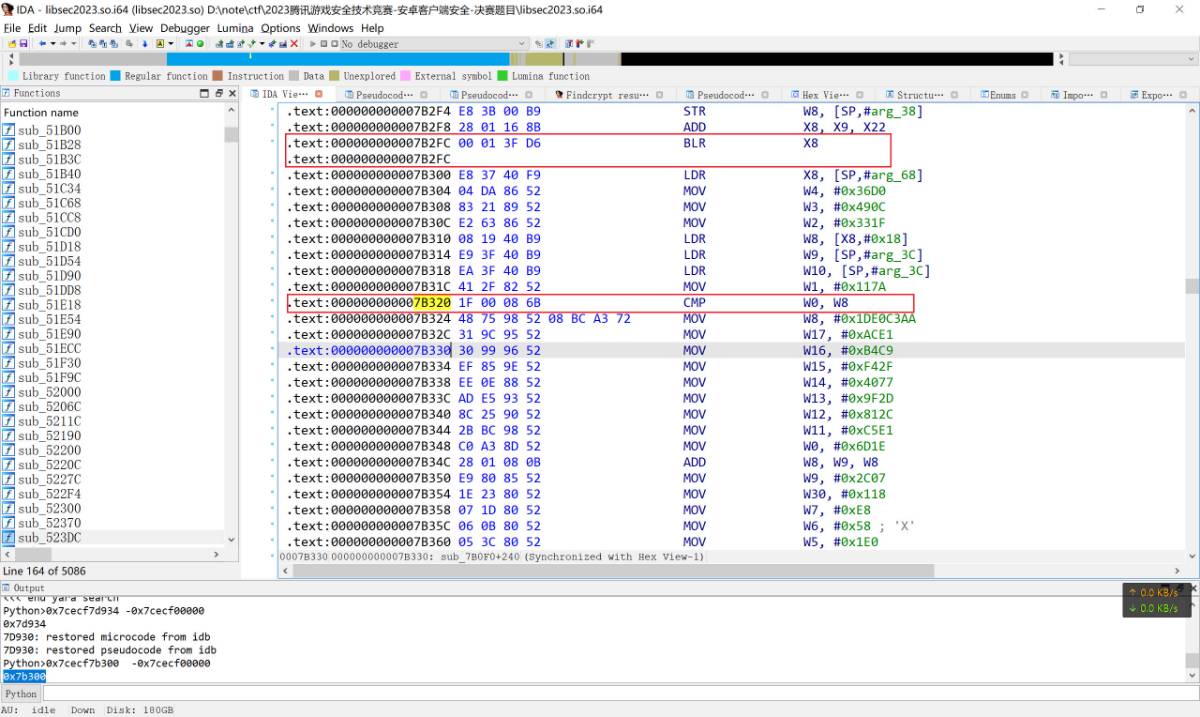
这里能够看到0x7B2FC的blr x8就是调用点, 读取完代码段的校验和之后返回值会存储在x0寄存器中, 因此可以按照此为线索往下面拉, 看到0x7B320处有一个cmp w0, w8. 之后一个b跳转到0x7AF00处
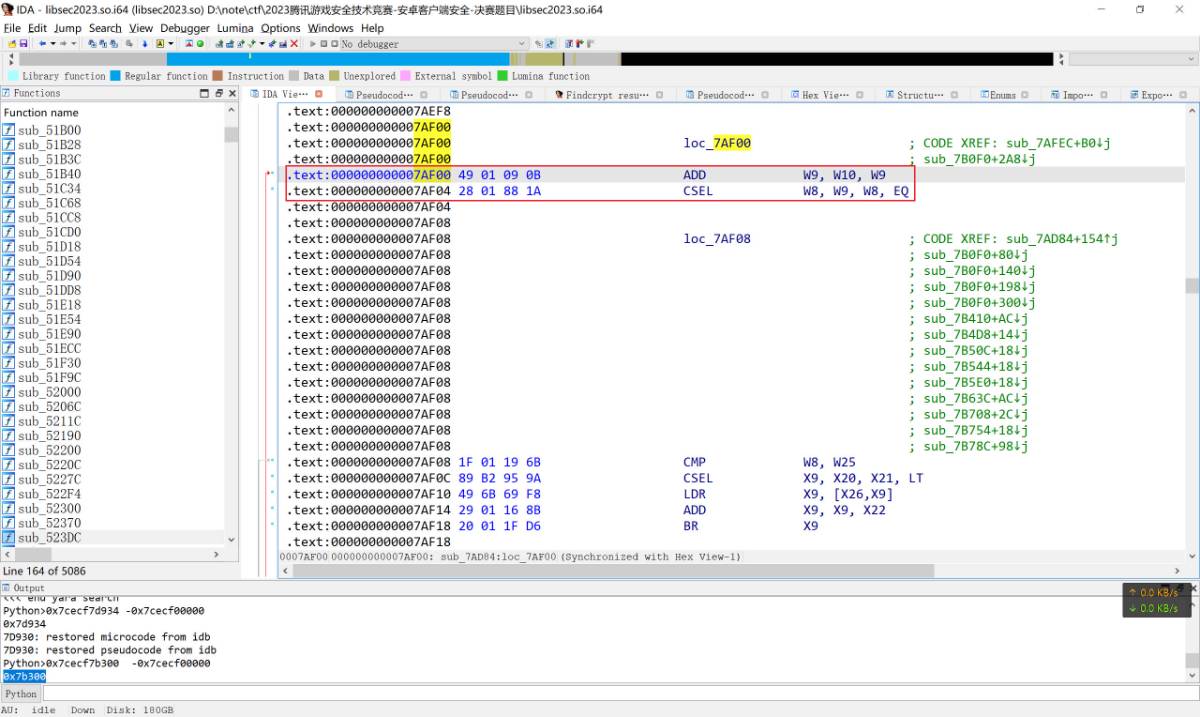
在0x7AF04这里会依据前面的cmp语句的结果对w8进行赋值, 而w8的值就会影响到之后的分支, 所以这就能够找到patch的关键点了, 用硬件断点工具下执行断点查看寄存器的数据可以发现正常流程中w0和w8的值应当是相等的, 所以要越过crc检测则应该将cmp w0, w8语句改成mov w0, w8, 同时将csel w8, w9, w8, eq改成mov w8, w9. 实践中发现后面那句不改也可以, eq默认成立.
所以在frida的脚本中初始化中加入以下语句即可彻底过掉检测.
至此反调试就分析完毕, frida能够正常使用了.
相比于初赛, 决赛的混淆程度更加严重了, ida的伪代码功能彻底报废, 程序中函数的跳转和程序内分支语句全部变成了寄存器间接跳转, 对于函数跳转尚可使用unidbg这种模拟执行的方式还原, 但是条件分支具有动态性, 所以很难还原回去. 所以我选择了frida-trace日志静态分析 + frida hook动态的方式进行分析.
同样先大概看了一下流程, 同初赛一样, 刚开始会从libil2cpp.so中接收输入数字, 然后传入后续的算法执行, 然后生成随机的token.

通过frida hook可以得知这里的跳转会跳转到libsec2023.so + 0x70E74.
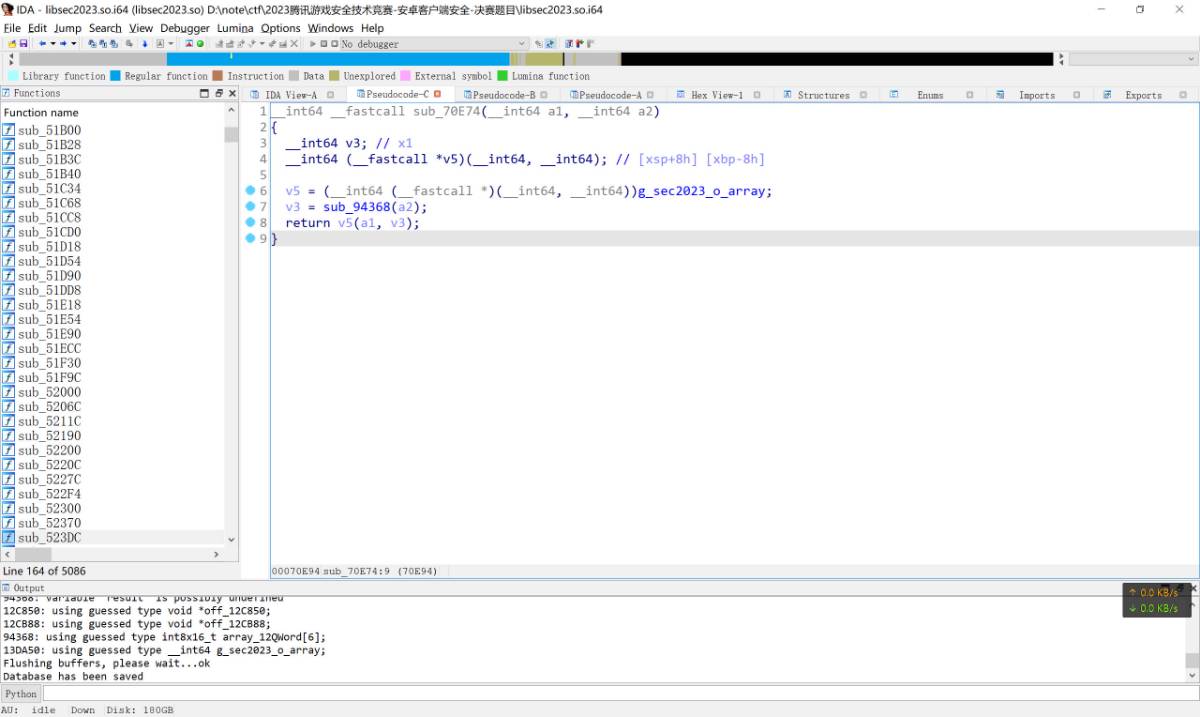
上图的sub_94368便是加密算法的主体部分, v5跳转则会跳回libil2cpp.so + 0x465994, 参数v3是返回的int64值.
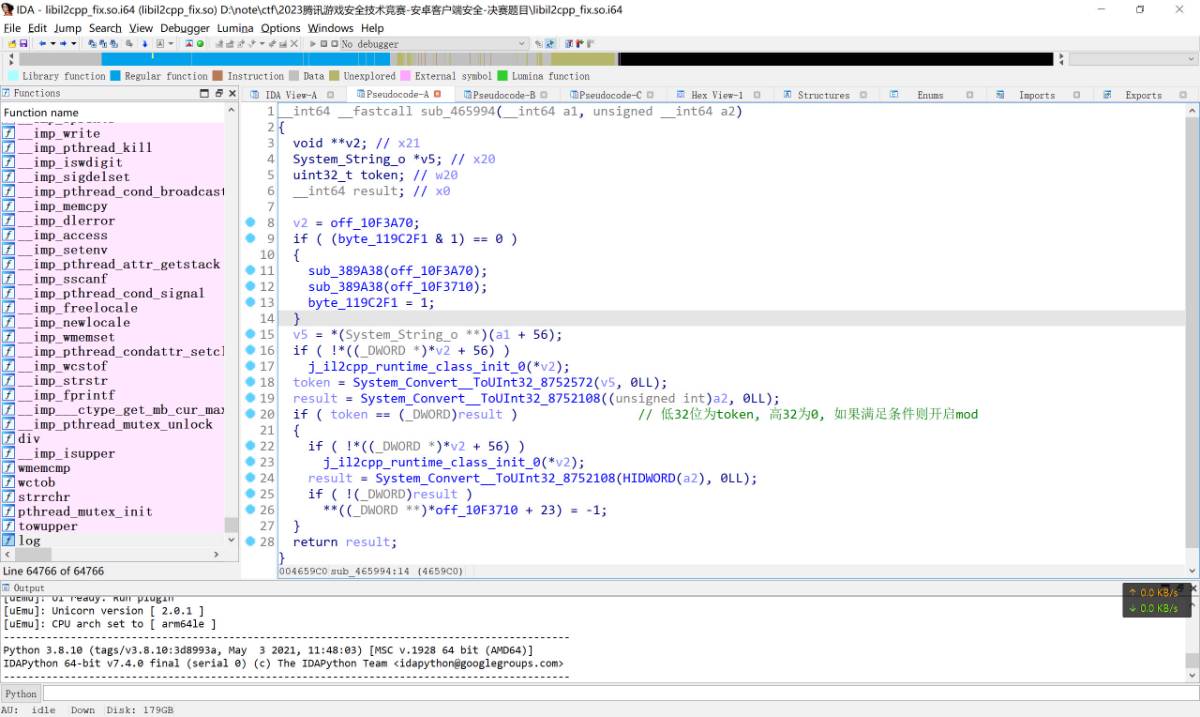
返回的值如果满足低32位等于token, 高32为0, 则开启mod. 不同于初赛, 这里最后并没有其他校验, 所以算法的全部实现都在libsec2023.so中.
首先假设输入的数字是666666, 对应的十六进制表达是0xa2c2a. 先进入sub_94368函数, 从这里开始的所有代码都被严重混淆了, 截图为我部分修复之后的伪代码. 其中要满足strcmp结果一致之后才会进入离散对数算法之后的后续逻辑
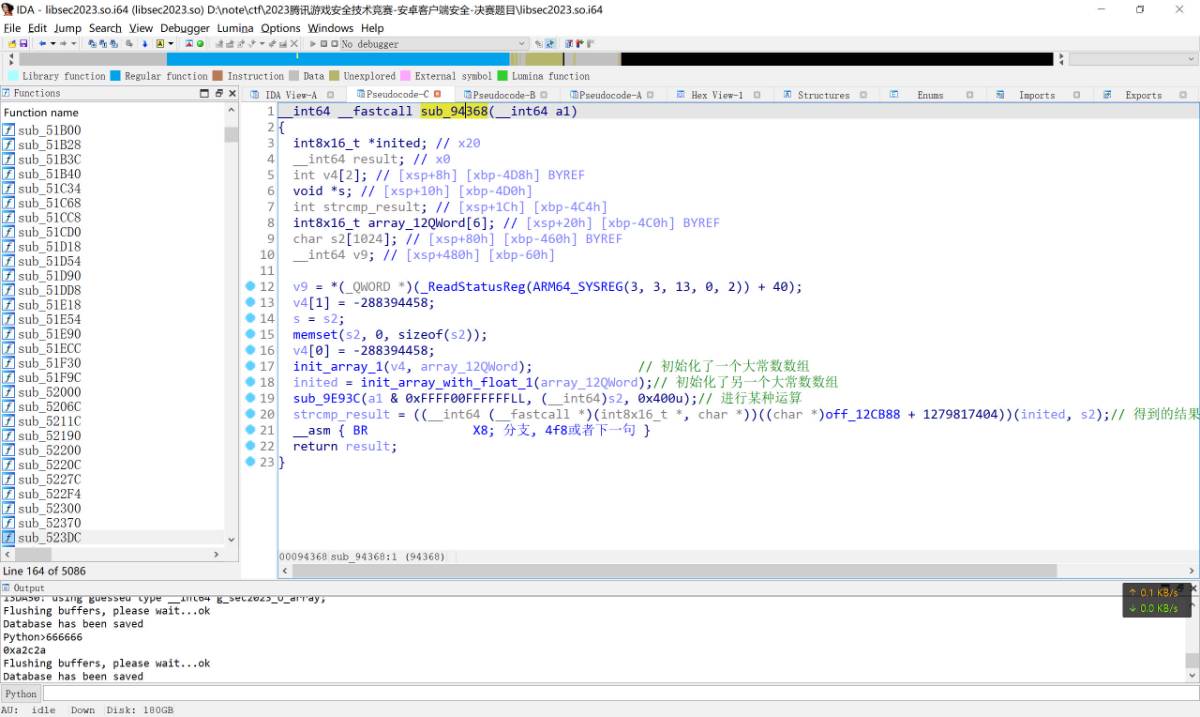
在这个函数中主要是初始化了两个大数数组, 之后进入sub_9e93c中进行某种运算, 其中第一个参数是输入的数字和0xffff00ffffff进行按位与运算的结果. 对于输入数字数字666666, 其计算的结果是1db29b949927d377f0270e1161964bb0b9fc004f7125b6956d057e09a7c2fadf77df04bbcae93aa0000字符串, 之后将s2的字符串与前面初始化的某个数组使用strcmp函数进行比较, 经过hook获取发现该数组是一个恒定不变的字符串25f6b048b4f32e3ce9175bb64930f65101a706ae74988a4ec87b4d5ec7feb9223ab782bcf1ec9d7fee750. 刚开始看到这个字符串想到了哈希, 但是具体是什么还需要进入sub_9e93c函数查看.
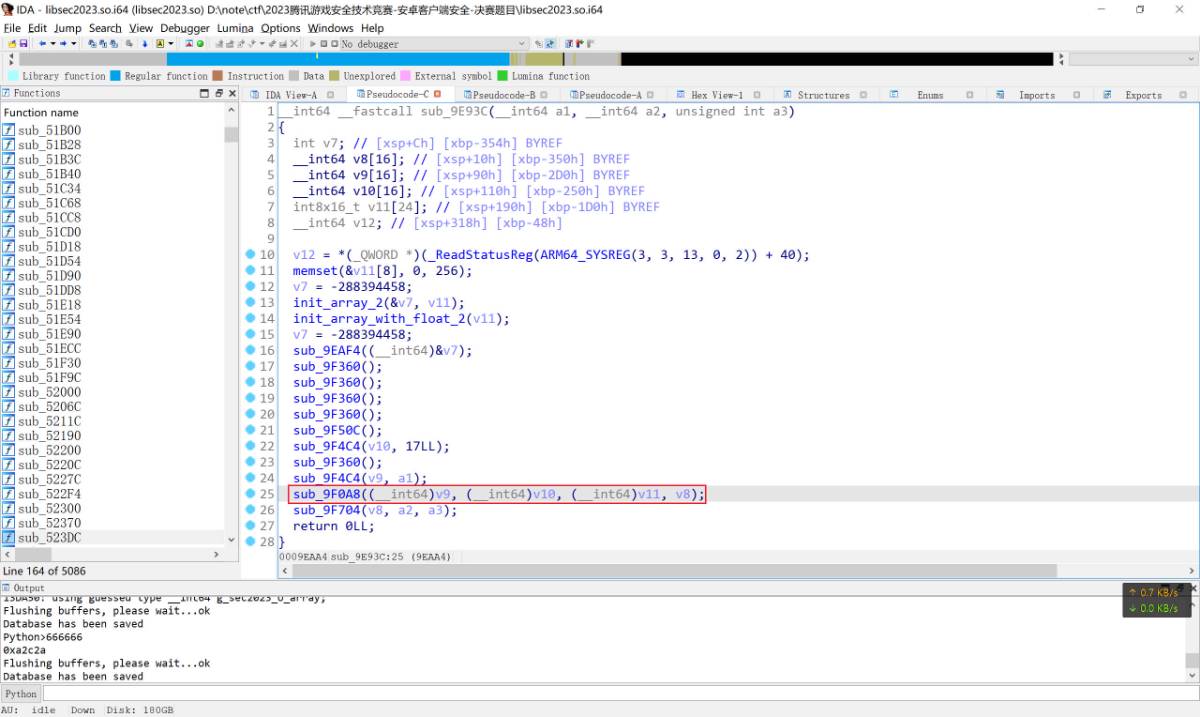
sub_9e93c函数首先会进行一系列初始化, 然后进入sub_9F0A8函数和sub_9f704中, 使用frida hook也能够发现输入的数字是在最后执行完sub_9f704出现了字符串. 理所应当先进入sub_9f704看看这个字符串是如何产生的, 查看frida-trace的log能够发现其在某处开始会每8个一组产生0, 一直产出了168个0之后才生成想看到的字符串.
而上面的那个br跳转则是进入了sub_9FC3C这个函数
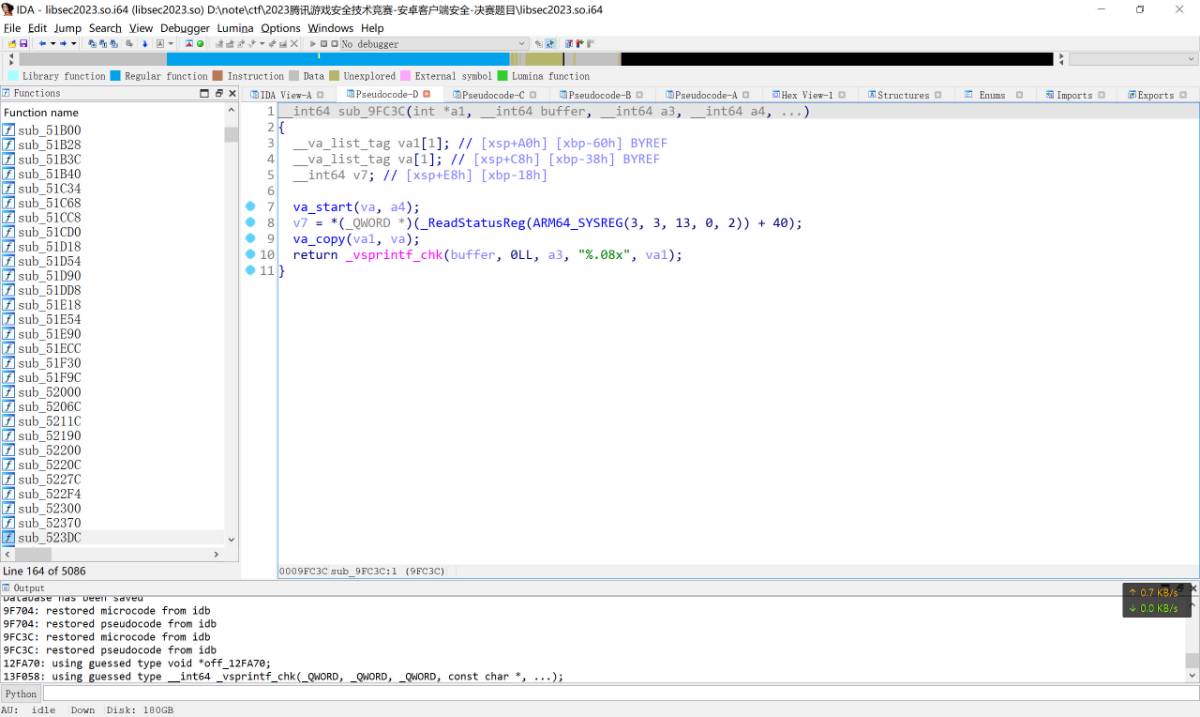
进去查看发现这个函数实现的功能是将某个数字按照十六进制生成字符串, 不足8位补齐, 所以前面的00000000就是这么产生的, 经过hook发现最终生成的一长串数字也是在这里一组一组生成最终拼接而成. 经过详细的比对, 最终确定sub_9f704函数只是一个类似于显示层的函数, 计算出的数字是在sub_9F0A8中生成出来的.
sub_9F0A8函数存在有控制流混淆, 使用OBPO插件去除混淆后能够得到这样伪代码, 其中注释和函数名称是我经过大量hook与对应trace log比对后得到其对应功能后命名的.
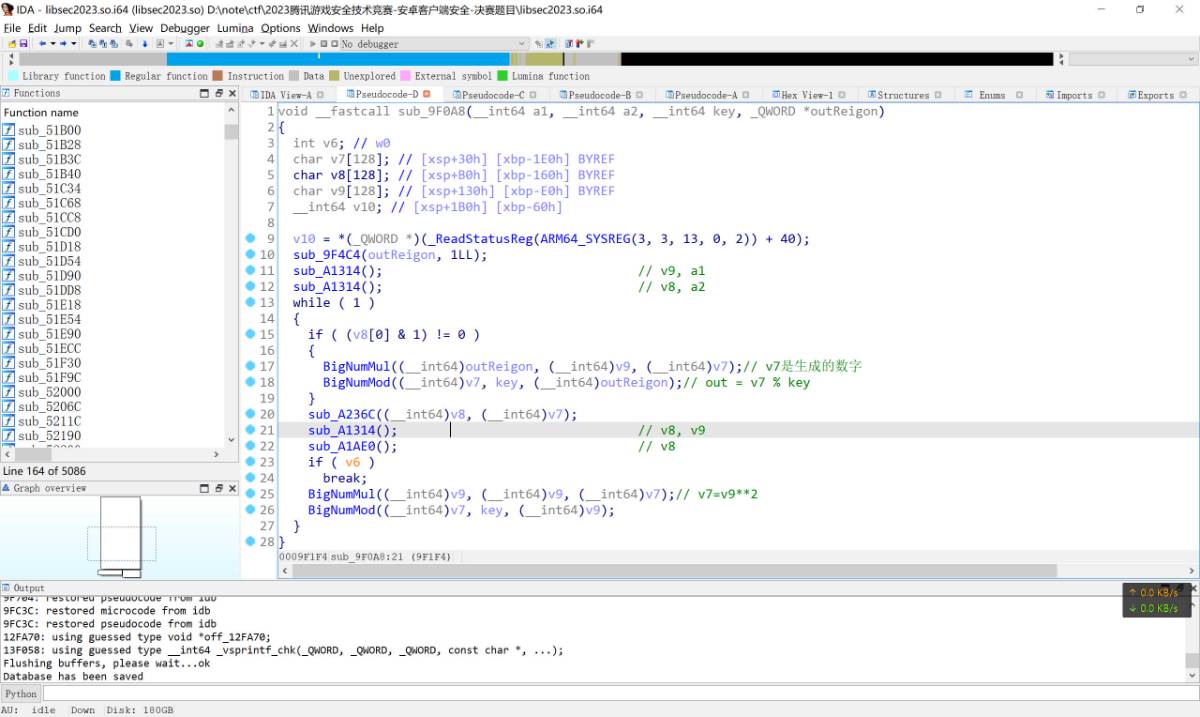
这个函数最终实现的功能是对于输入数字x, 输出结果y = pow(x, 17) mod key, 其中key的值是已知的, 也就是前面初始化的某个数组之一, 经过hook后得到key为0x028a831a5bf4b902e95318e50c2075259f91094d08d84409e1b76eadfa0865d1278acc90fa7c6cf6acb375. 这个算法是离散对数问题, y为已知的25f6b048b4f32e3ce9175bb64930f65101a706ae74988a4ec87b4d5ec7feb9223ab782bcf1ec9d7fee750, 其逆算法也就是求得输入数字x. 其中x的范围已知是和0xffff00ffffff按位与之后的结果, 那么最简单的逆算法就是爆破枚举.
在满足前面的strcmp条件之后, 程序执行流会进入到sub_99EF4中.
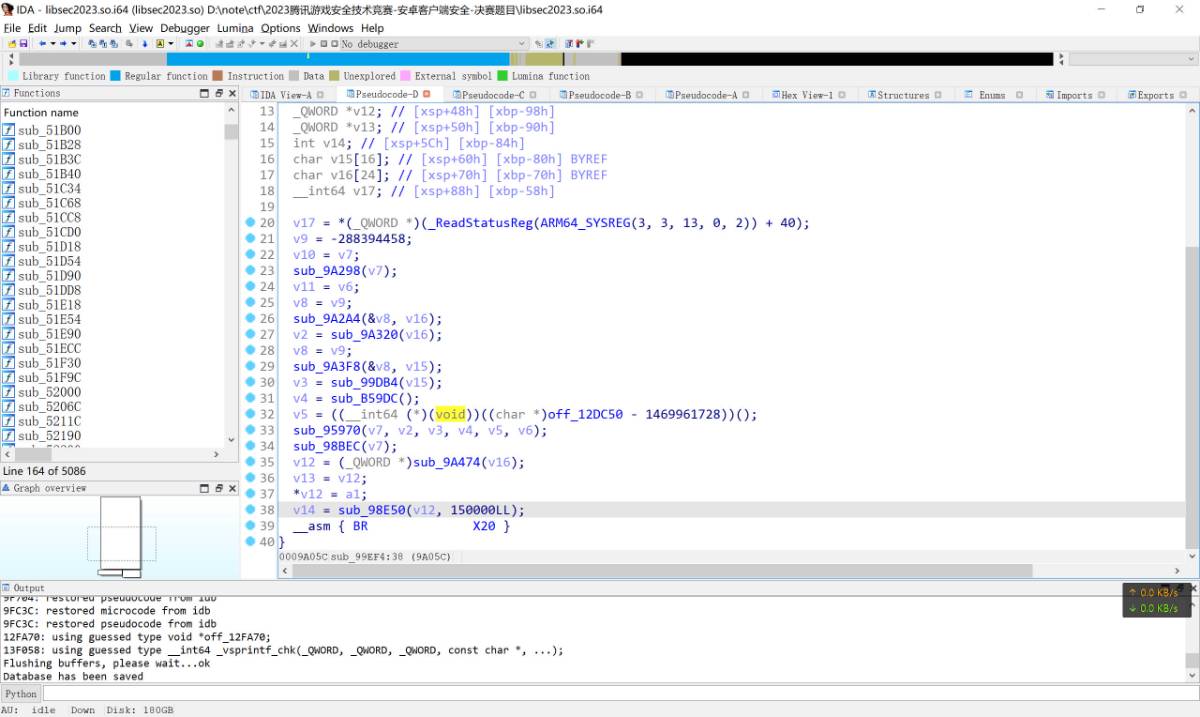
在上图中能够看到修复后伪代码, 主要是会初始化一些参数. 使用frida-trace对其进行trace能够看到一些奇怪的字符串
其中能看到PK, vm_main, builtin, PK是压缩包的magic标识, 有可能这里的br是执行了解压缩操作, 回溯查看这个PK的来源能够发现是sub_B59DC函数获取该地址的.
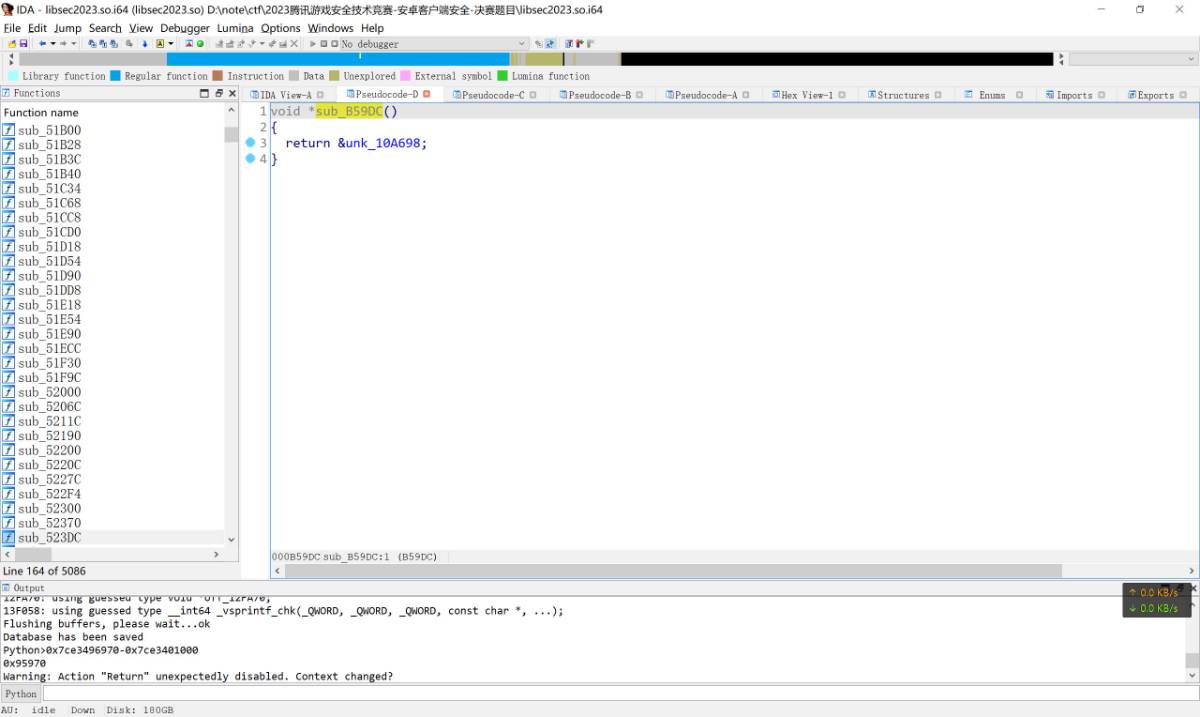
其中libsec2023.so + 0x10A698处便是压缩包的数据.

使用010editor将其手动提取出来, 打开后可以发现里面存在两个文件a64.dat和a64.sig. 此处尚且知其具体含义, 继续阅读后面的汇编代码, 查看是如何使用该数据的. 果不其然在0x96190附近看到了这样一段汇编记录
其中x0是压缩包的二进制数据地址, x1为该压缩包二进制数据的长度, x2是a64.dat字符串, x3是某个数据. 使用ida进入该函数sub_523DC可以发现并没有被混淆. 那么大概率不是什么重要的函数, 根据参数猜测应该是从安装包中提取a64.dat这个文件. 使用frida hook查看参数和内存变化情况.
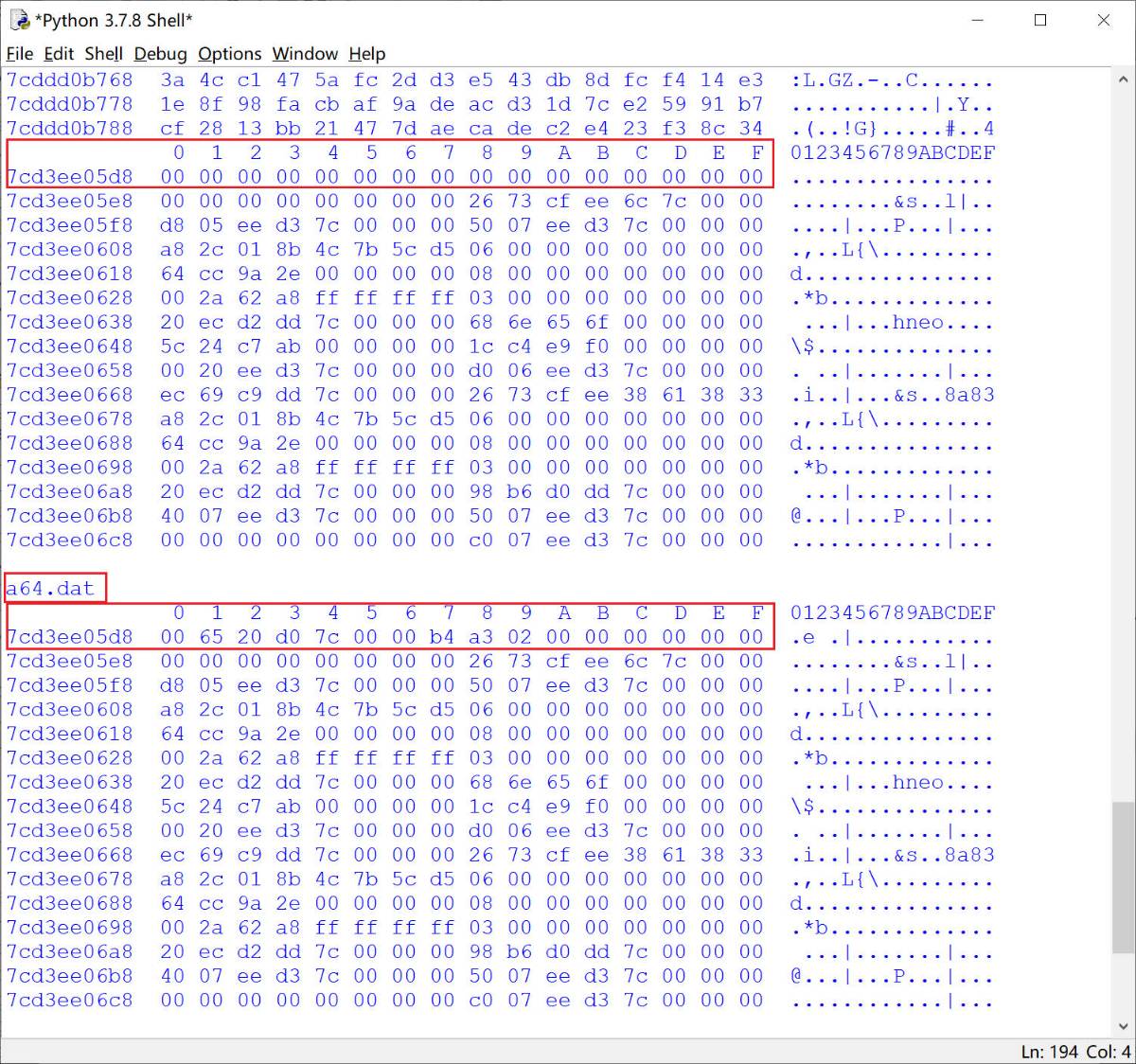
从上面的图中可以看到, 0x7cd3ee05d8这个地址的内存数据在经过sub_523DC之后被修改了, 其中前8个字节像一个指针, 后两个字节像是文件大小.
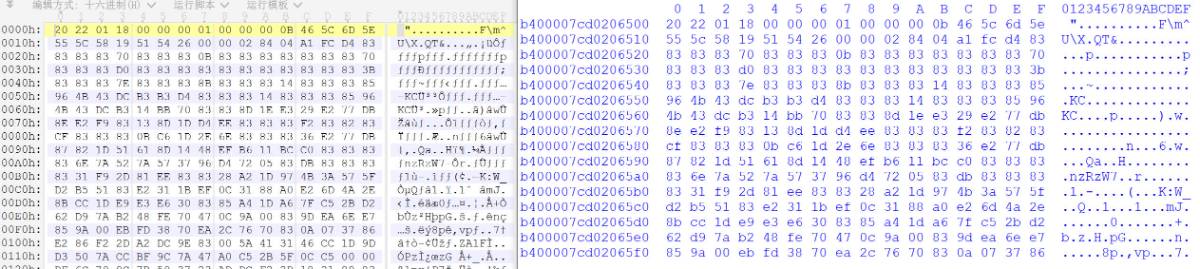
将该内存区域打印后和文件做对比发现确实是该文件, 0x2a3也是a64.dat的文件大小. 得知sub_523DC提取了a64.dat文件之后, 继续往后面看汇编代码, 看看是如何使用该文件的.
可以看到97da8中调用了sub_5A65C函数
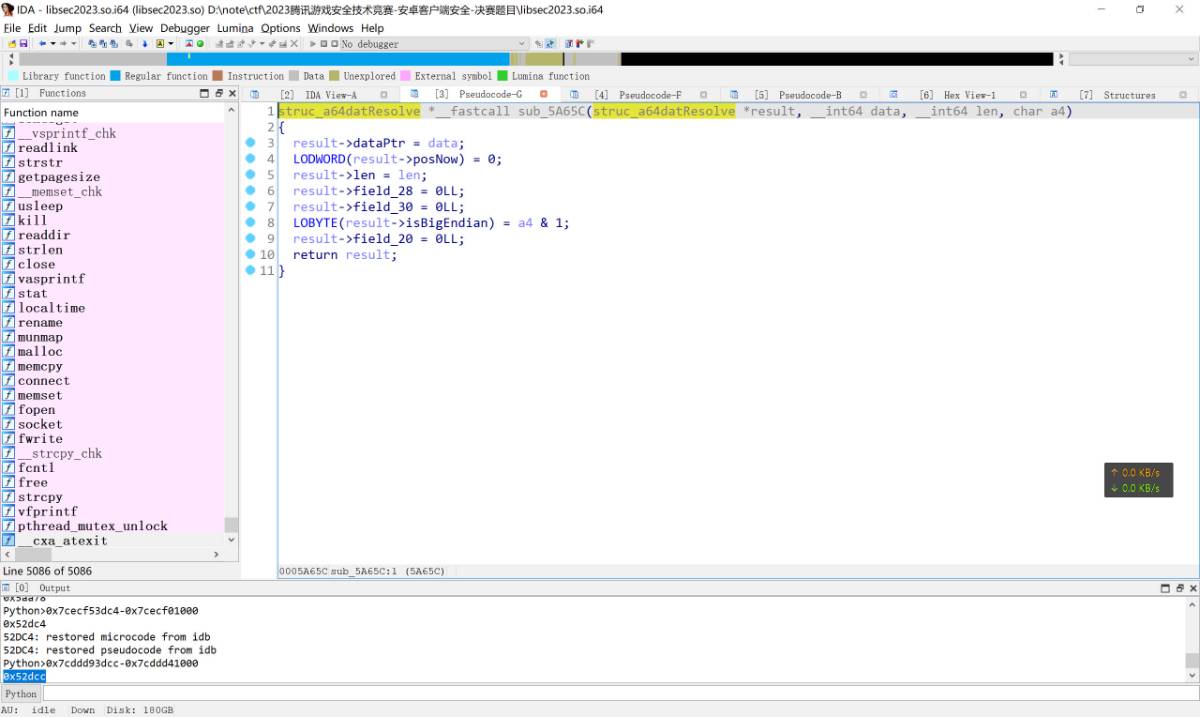
这个函数是我分析完对结构体命名后的结果, 其主要是初始化了某个结构体, 将文件地址填入前8字节. 猜测是某种数据流的实现, 用于读取文件的信息. 在初始化完之后, 之后的分析应该是围绕这个结构体进行的.
可以看到这里调用了sub_5A7A8函数, 使用到了该结构体, 进ida查看
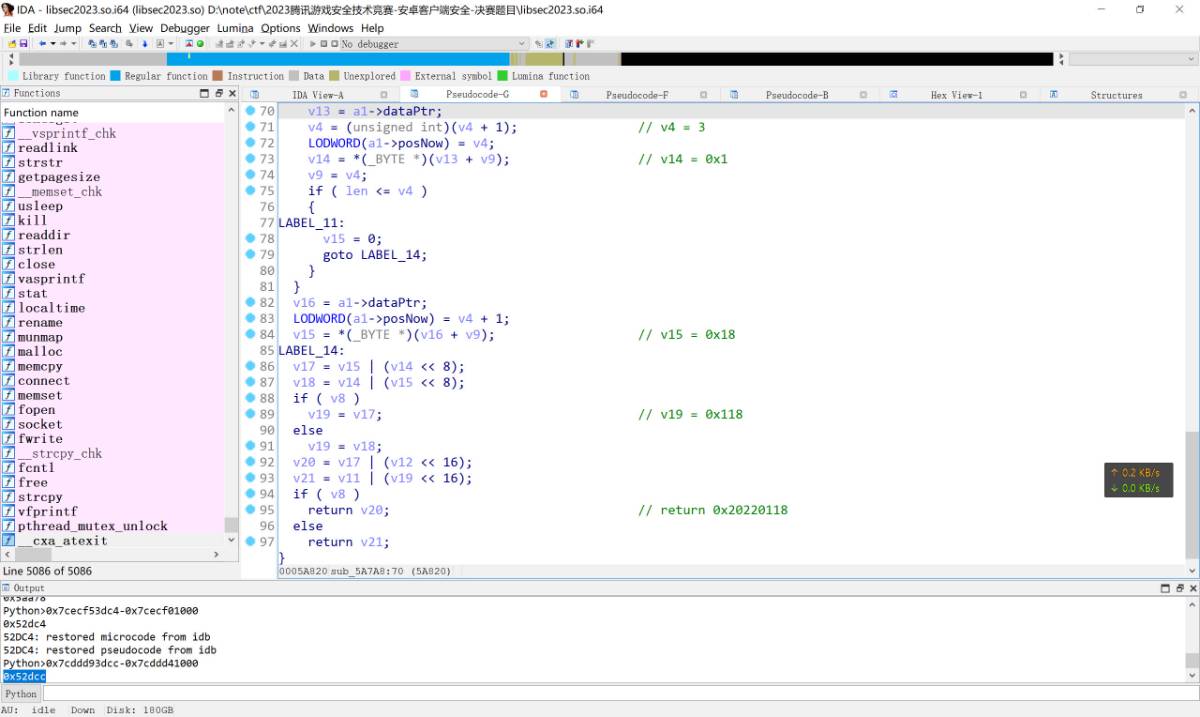
其主要的功能是按照大端读取四个字节的int数字并返回.
从汇编中分析可以看出在977a8之后出现了字符串, 因此对其内部进行分析, 发现会调用sub_5AAD8函数, 而这个函数确实是读取某一块内存并且对字符串进行解密. 然后使用frida hook发现这里会产出这三个字符串: vm_main.img, __ff_11, __ff_12.
在上面这段汇编中0xb400007bef75a300是之前定义的结构体指针, x2参数很明显是某个比文件小的长度. 进入sub_5AA78看看.
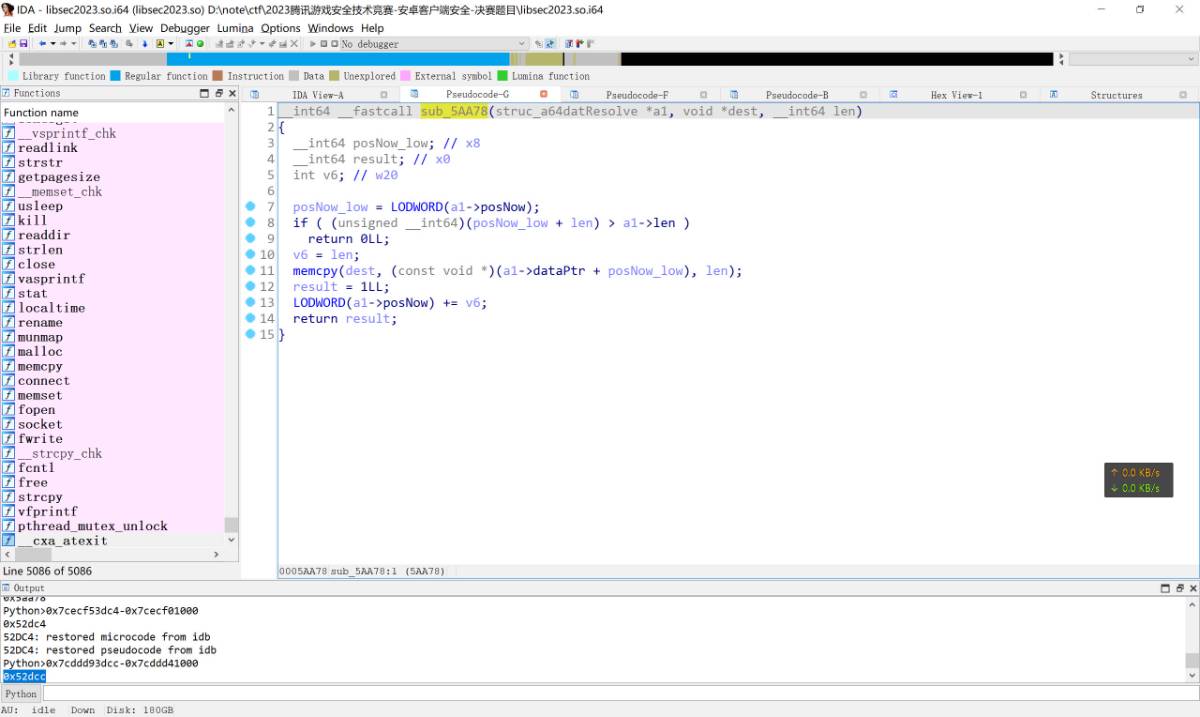
发现该函数的主要功能是对文件的某一段内容复制到另一块内存区域当中, 对应到上面的调用, 那含义很明显就是从a64.dat文件的0x1b起始, 长度为0x284的部分. 继续跟进看看其是如何使用这个区域的.
可以发现前面内存复制之后, 会马上使用到这块区域, 这是一个很明显的加解密操作, 其实现的操作是取第一个字节0x4和0x23异或得到结果0x27, 然后从原来的字节被替换为MEM[0x10A536 + 0x27]的值. 那么这个0x10A536偏移的区域很有可能是映射码表之类的东西.
继续查看后面的汇编可以发现果然在后面的x8会逐渐递增, 并重复这段操作, 也就是循环对每个字节进行这样的操作. 那么可以看看这个码表解密之后是什么样的. 这里使用hook会造成程序卡死, 那么使用以下的python脚本静态解密一下看看是什么东西.
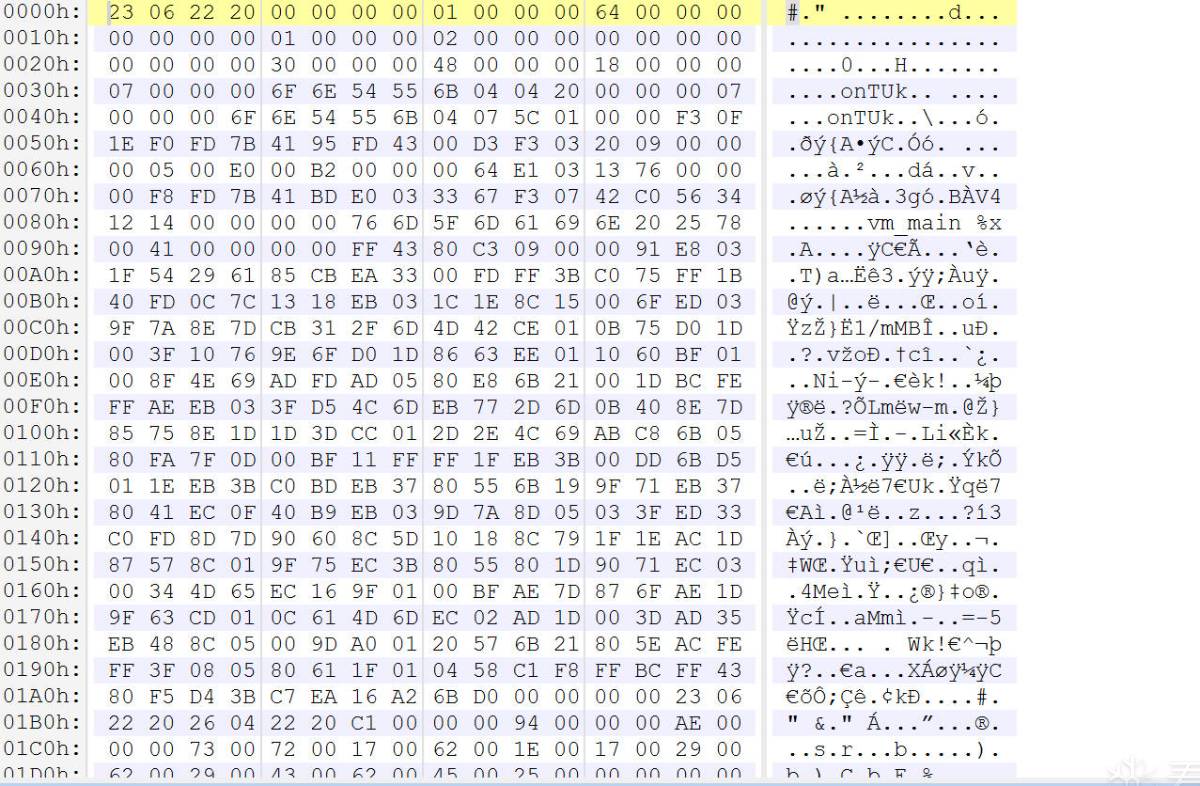
可以看到这块区域被解密出来了, 其中也能够看到vm_main字符串, 所以应该是没有错误的.
时间和精力原因后面的没有分析完, 前面findcrypt插件发现了aes的特征, 所以也有可能后面用到了aes算法, 看字符串带vm字样也不排除使用了vm技术. 看汇编是真的累
到此为止成功获取了flag, 过掉了所有反调试使得frida能够正常工作, 之后静态分析加动态调试还原了离散对数算法, 并且还给出了其逆算法.看汇编还是太累了, 说实在的这么高强度的混淆和前面的vm混打, 这次比赛难度真不小.
function PatchCode(addr, value){
Memory.protect(addr, 4, 'rwx');
addr.writeInt(value);
}
PatchCode(libsec2023.base.add(0x7B320), 0x2a0803e0);//过crc32
function PatchCode(addr, value){
Memory.protect(addr, 4, 'rwx');
addr.writeInt(value);
}
PatchCode(libsec2023.base.add(0x7B320), 0x2a0803e0);//过crc32
......
9f934 mov x27, x1 ; x27 = 0x81d8ae82 --> 0x7ce2ef7850
9f938 adrp x3,
9f93c add x1, x1, x8 ;
9f940 ldr x8, [sp,
9f944 add x0, sp,
9f948 mov x2,
9f94c add x3, x3,
9f950 ldr w4, [x8, x9, lsl
9f954 ldr w8, [sp,
9f958 adrp x9,
9f95c ldr x9, [x9,
9f960 str w8, [sp,
9f964 mov w8,
9f968 movk w8,
9f96c add x8, x9, x8 ; x8 = 0x37c289f0 --> 0x7cecfa0c3c
9f970 blr x8 ; x0 = 0x7ce2ef73e0 --> 0x8 x1 = 0x7ce2ef7850 --> 0x7ce2ef6b83 x2 = 0xffffffffffffffff --> 0x9 x3 = 0x7ced00b64b --> 0x7ce2ef7260 x4 = 0x0 --> 0x7ce2ef6b84 x5 = 0x50 --> 0x7ce2ef7858 x6 = 0x110 --> 0x30 x7 = 0x108 --> 0x30 x8 = 0x7cecfa0c3c --> 0xd55c7b4c8b012ca8 x9 = 0x7cb537824c --> 0xd55c7b4c8b012ca8 x10 = 0xcd53af93 --> 0x0 x11 = 0x7cecfa092c --> 0x2 x12 = 0x48 --> 0x0 x13 = 0x400 --> 0x7ffffff7 x14 = 0xc8 --> 0xeecf7326 x15 = 0xf0fc4d01 --> 0x0 x16 = 0xd1993aaf --> 0x7dd3e069a0 x17 = 0xb952cbee --> 0x7dd3d4bb94
9f974 ldr w8, [sp,
9f978 ldr w9, [sp,
9f97c ldr w10, [sp,
9f980 mov w11,
9f984 mov w4,
9f988 mov w3,
9f98c mov w2,
9f990 mov w0,
9f994 mov w17,
9f998 mov w16,
9f99c mov w15,
9f9a0 mov x1, x27 ; x1 = 0x7ce2ef6b83 --> 0x7ce2ef7850 (00000000)
;这里能看到生成了一串0, 这个0就是上面的br跳转得到的
9f9a4 mov w27,
......
......
9f934 mov x27, x1 ; x27 = 0x81d8ae82 --> 0x7ce2ef7850
9f938 adrp x3,
9f93c add x1, x1, x8 ;
9f940 ldr x8, [sp,
9f944 add x0, sp,
9f948 mov x2,
9f94c add x3, x3,
9f950 ldr w4, [x8, x9, lsl
9f954 ldr w8, [sp,
9f958 adrp x9,
9f95c ldr x9, [x9,
9f960 str w8, [sp,
9f964 mov w8,
9f968 movk w8,
9f96c add x8, x9, x8 ; x8 = 0x37c289f0 --> 0x7cecfa0c3c
9f970 blr x8 ; x0 = 0x7ce2ef73e0 --> 0x8 x1 = 0x7ce2ef7850 --> 0x7ce2ef6b83 x2 = 0xffffffffffffffff --> 0x9 x3 = 0x7ced00b64b --> 0x7ce2ef7260 x4 = 0x0 --> 0x7ce2ef6b84 x5 = 0x50 --> 0x7ce2ef7858 x6 = 0x110 --> 0x30 x7 = 0x108 --> 0x30 x8 = 0x7cecfa0c3c --> 0xd55c7b4c8b012ca8 x9 = 0x7cb537824c --> 0xd55c7b4c8b012ca8 x10 = 0xcd53af93 --> 0x0 x11 = 0x7cecfa092c --> 0x2 x12 = 0x48 --> 0x0 x13 = 0x400 --> 0x7ffffff7 x14 = 0xc8 --> 0xeecf7326 x15 = 0xf0fc4d01 --> 0x0 x16 = 0xd1993aaf --> 0x7dd3e069a0 x17 = 0xb952cbee --> 0x7dd3d4bb94
9f974 ldr w8, [sp,
9f978 ldr w9, [sp,
9f97c ldr w10, [sp,
9f980 mov w11,
9f984 mov w4,
9f988 mov w3,
9f98c mov w2,
9f990 mov w0,
9f994 mov w17,
9f998 mov w16,
9f99c mov w15,
9f9a0 mov x1, x27 ; x1 = 0x7ce2ef6b83 --> 0x7ce2ef7850 (00000000)
;这里能看到生成了一串0, 这个0就是上面的br跳转得到的
9f9a4 mov w27,
......
//这里使用了gmp库来计算大整数, 会暴力输出所有满足的解
//这里得到的解是原始输入int64 & 0xffff00ffffff之后应当满足的部分
void GetAns() {
mpz_class z("0x28a831a5bf4b902e95318e50c2075259f91094d08d84409e1b76eadfa0865d1278acc90fa7c6cf6acb375", 0);
mpz_class y("0x25f6b048b4f32e3ce9175bb64930f65101a706ae74988a4ec87b4d5ec7feb9223ab782bcf1ec9d7fee750", 0);
mpz_class j, x;
mpz_ui_pow_ui(j.get_mpz_t(), 2, 32); // j = 2^32
for (int i = 0x0; i <= 0xffff; i++) {
x = i;
x *= j; // x = i * 2^32
for (int k = 0; k <= 0xffffff; k++) {
x += k;
mpz_class result;
mpz_powm_ui(result.get_mpz_t(), x.get_mpz_t(), 17, z.get_mpz_t());
if (result == y) {
std::cout << x << std::endl;
}
}
}
return 0;
}
//这里使用了gmp库来计算大整数, 会暴力输出所有满足的解
//这里得到的解是原始输入int64 & 0xffff00ffffff之后应当满足的部分
void GetAns() {
mpz_class z("0x28a831a5bf4b902e95318e50c2075259f91094d08d84409e1b76eadfa0865d1278acc90fa7c6cf6acb375", 0);
mpz_class y("0x25f6b048b4f32e3ce9175bb64930f65101a706ae74988a4ec87b4d5ec7feb9223ab782bcf1ec9d7fee750", 0);
mpz_class j, x;
mpz_ui_pow_ui(j.get_mpz_t(), 2, 32); // j = 2^32
for (int i = 0x0; i <= 0xffff; i++) {
x = i;
x *= j; // x = i * 2^32
for (int k = 0; k <= 0xffffff; k++) {
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。







