YOLOv5 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.
1. 环境搭建
9b7K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6T1L8r3!0Y4i4K6u0W2j5%4y4V1L8W2)9J5k6h3&6W2N6q4)9J5c8X3!0v1K9g2N6#2h3s2g2S2L8W2)9J5c8X3q4J5N6r3W2U0L8r3g2Q4x3V1k6V1k6i4c8S2K9h3I4K6i4K6u0r3x3e0l9%4y4e0f1^5x3U0R3$3 和0ddK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6#2L8s2c8J5j5h3I4&6N6r3W2U0M7#2)9J5c8Y4W2G2L8r3!0$3y4b7`.`. 按照官方指导进行安装。
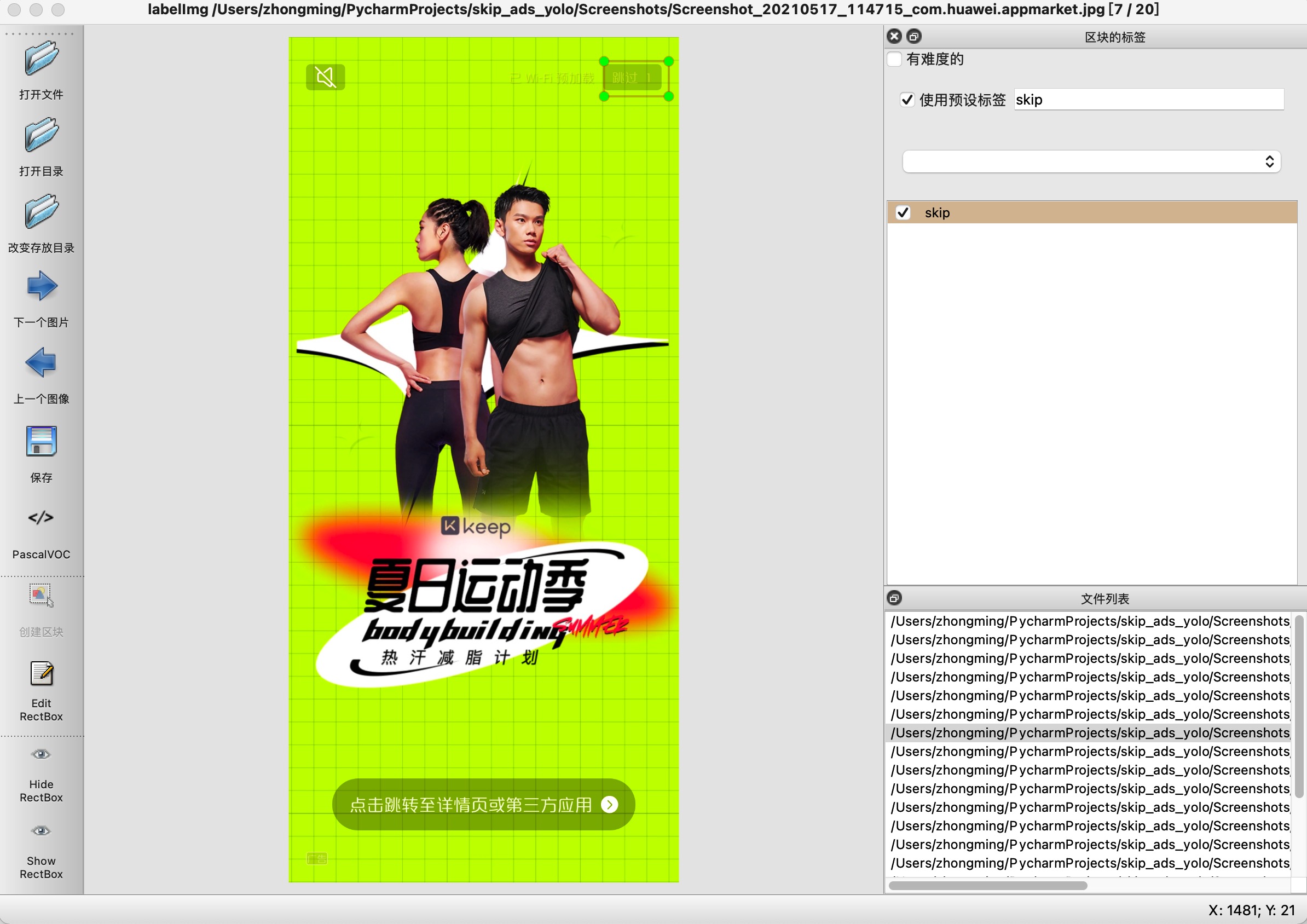
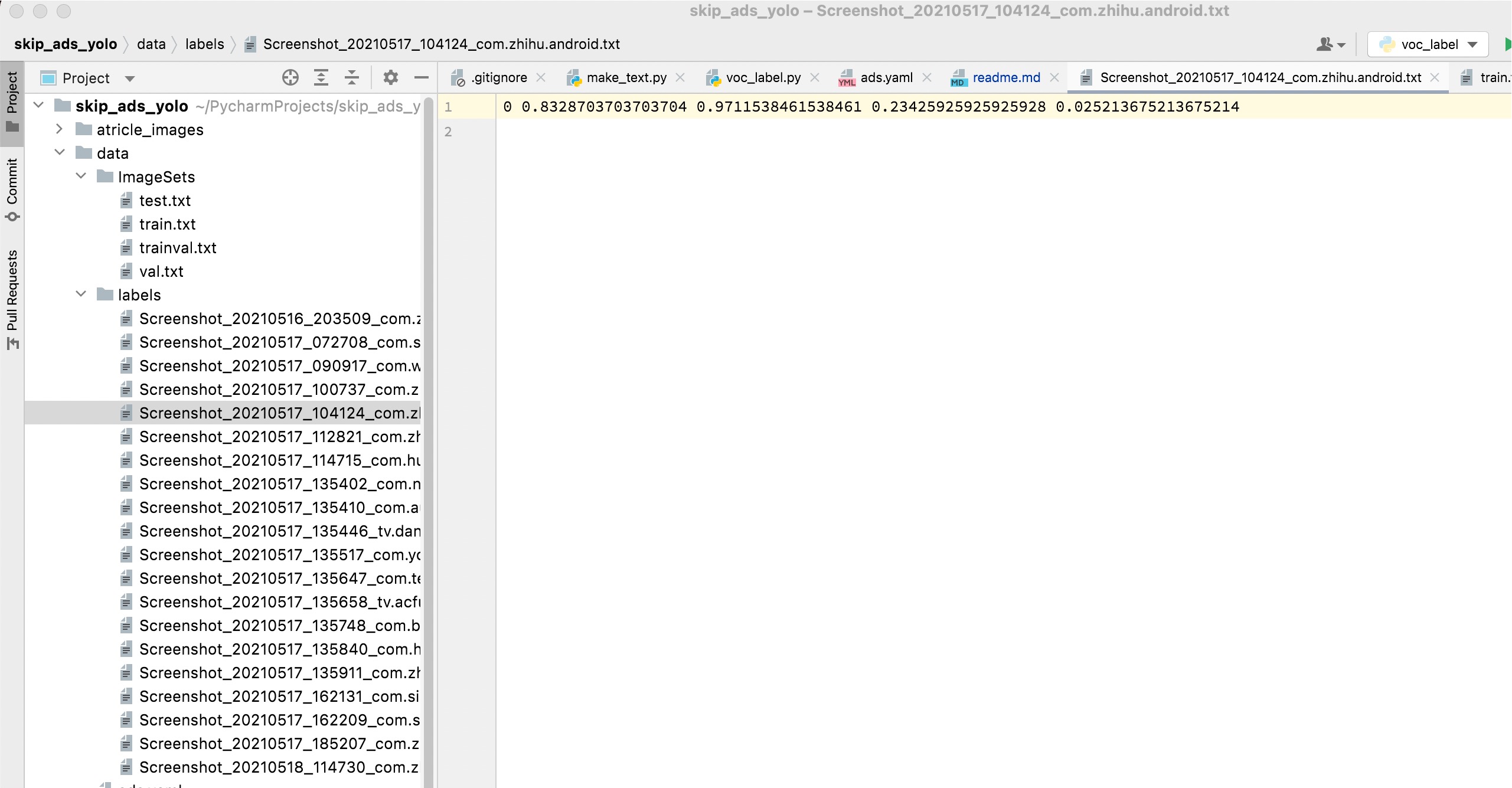
2.数据准备 labelImg {conda 环境地址:0e9K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6S2L8X3q4U0L8$3&6V1j5g2)9J5k6h3!0J5k6#2)9J5c8X3!0T1j5h3u0&6i4K6u0r3L8r3q4T1k6h3I4A6L8h3M7`. 可以直接导入使用},对图片进行标记。将标记后的xml文件保存到xmls目录下。3.构建数据集: 以下代码基本都是拷贝自:b57K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6T1L8r3!0Y4i4K6u0W2j5%4y4V1L8W2)9J5k6h3&6W2N6q4)9J5c8X3!0v1K9g2N6#2h3s2g2S2L8W2)9J5c8X3q4J5N6r3W2U0L8r3g2Q4x3V1k6V1k6i4c8S2K9h3I4K6i4K6u0r3x3e0l9%4y4e0f1^5x3U0R3$3 这篇文章,表示感谢!! ):
创建voc_label.py代码如下,需要注意classes中的列别信息:
分别运行makeTxt.py和voc_label.py。
make_text.py主要是将数据集分类成训练数据集和测试数据集,默认train,val,test按照8:1:1的比例进行随机分类,运行后ImagesSets文件夹中会出现四个文件,主要是生成的训练数据集和测试数据集的图片名称,如下图。同时data目录下也会出现这四个文件,内容是训练数据集和测试数据集的图片路径。4.修改配置文件
修改网络参数models/yolov5s.yaml(这里取决于你使用了哪个模型就去修改对于的文件,该项目中使用的是yolov5s模型),主要修改nc参数:
train_ads.py 参数修改,主要参数解释如下。我们平时训练的话,主要用到的只有这几个参数而已:–weights,–cfg,–data,–epochs,–batch-size,–img-size,–project:
5.训练模型
训练结束之后的文件保存在Optimizer stripped from runs/train/exp3/weights/last.pt, 14.4MB Optimizer stripped from runs/train/exp3/weights/best.pt, 14.4MB两个文件中。到这里模型训练就结束了。
命令行输入信息的整体显示如下所示:
到这一步后,我们就可打开 http://localhost:6006/ 网页查看每一轮次训练的结果,如图所示。6.实现检查
通过下面的命令进行检测:
检测回显:
如果不修改detect.py文件这可以通过下面的命令进行检测:
检测效果,由于样本太少,导致检测到的概率太低,为了显示出来这里把parser.add_argument('--conf-thres', type=float, default=0.1,)--conf-thres调成了0.1否则直接检测不到跳过按钮,调低之后检测到的跳过按钮有的并不是跳过按钮(后一张图)。
安卓apk开屏广告跳过按钮识别项目,地址:4bcK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6G2j5X3q4T1P5g2)9J5c8Y4y4C8K9i4m8Q4y4h3k6S2k6s2y4Q4y4h3k6&6L8$3I4G2N6U0f1`.
obaby@mars0a8K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4N6%4N6#2)9J5k6h3R3@1j5$3E0Q4x3X3g2G2M7X3N6Q4x3X3g2U0L8R3`.`. 02fK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4N6%4N6#2)9J5k6h3!0T1j5h3u0&6i4K6u0W2L8%4u0Y4i4K6u0W2j5$3^5`.
参考链接:128K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6q4N6X3N6W2L8V1#2W2M7$3S2C8K9h3&6Q4x3V1k6e0j5%4u0W2k6h3&6e0K9r3!0@1i4K6u0r3j5X3I4G2j5W2)9J5c8X3#2S2M7%4c8W2M7W2)9J5c8X3q4H3M7q4)9J5c8Y4y4J5j5#2)9J5c8X3#2S2K9h3&6Q4x3V1k6B7j5i4k6S2i4K6u0r3j5Y4W2Q4x3V1k6S2L8X3c8J5L8$3W2V1i4K6u0r3k6i4k6Y4k6h3&6Q4x3V1k6K6j5%4u0W2k6h3&6K6K9r3!0@1i4K6u0r3f1$3y4J5k6h3g2F1b7h3y4@1K9i4k6A6N6s2W2Q4x3X3g2B7j5i4k6S2 cfcK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6T1L8r3!0Y4i4K6u0W2j5%4y4V1L8W2)9J5k6h3&6W2N6q4)9J5c8Y4q4I4i4K6g2X3x3K6R3@1z5e0V1^5y4e0W2Q4x3V1k6S2M7Y4c8A6j5$3I4W2i4K6u0r3k6r3g2@1j5h3W2D9M7#2)9J5c8U0V1H3y4e0t1K6x3U0R3K6 9e8K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6B7N6h3g2B7K9h3&6Q4x3X3g2U0L8W2)9J5c8Y4m8G2M7%4c8Q4x3V1j5$3z5o6b7@1z5e0l9K6y4e0R3&6x3e0t1%4y4U0f1I4x3K6x3#2 794K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6K6N6r3q4U0K9$3!0$3k6i4u0X3L8r3!0%4i4K6u0W2j5$3!0E0i4K6u0r3M7i4g2W2M7%4c8A6L8$3&6K6i4K6u0r3x3U0j5$3x3e0f1K6y4W2)9J5c8X3S2G2N6#2)9J5k6s2c8G2i4K6u0V1M7s2u0G2k6%4u0S2L8h3#2S2N6r3W2U0j5h3I4D9P5g2)9J5k6s2c8S2K9$3g2Q4x3X3c8S2i4K6u0V1M7$3y4J5k6h3g2F1M7$3S2G2N6q4)9J5k6r3!0F1i4K6u0V1j5h3&6V1M7X3!0A6k6l9`.`. 2f3K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6H3P5i4c8G2M7X3y4Z5i4K6u0W2L8%4u0Y4 31eK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6V1k6i4k6W2L8r3!0H3k6i4u0Q4x3X3g2F1N6X3W2V1K9h3q4Q4x3X3g2U0L8$3#2Q4x3V1k6U0N6h3c8S2i4K6u0V1k6r3!0%4L8X3I4G2j5h3c8K6i4K6y4r3N6r3q4J5k6$3g2@1i4K6g2X3L8%4y4Q4x3@1c8i4K9h3&6V1L8%4N6K6i4K6t1$3j5h3#2H3i4K6y4n7N6r3q4J5k6$3g2@1i4K6g2X3j5i4u0U0K9q4)9K6c8s2R3^5y4W2)9#2k6U0j5@1i4K6t1$3j5h3#2H3i4K6y4n7N6r3q4J5k6$3g2@1i4K6g2X3N6X3g2J5M7$3W2G2L8W2)9K6c8o6p5H3i4K6t1$3j5h3#2H3i4K6y4n7N6r3q4J5k6$3g2@1i4K6g2X3N6s2W2H3k6g2)9K6c8r3g2^5k6g2)9#2k6X3&6W2N6s2N6G2M7X3D9`.
conda env create user/my-environment
source activate my-environment
conda env create user/my-environment
source activate my-environment
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'xmls'
txtsavepath = 'Screenshots'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'xmls'
txtsavepath = 'Screenshots'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['skip']
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('train/%s.xml' % (image_id), encoding='utf-8')
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
if size != None:
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['skip']
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('train/%s.xml' % (image_id), encoding='utf-8')
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
if size != None:
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
train: data/train.txt
val: data/val.txt
test: data/test.txt
nc: 1
names: ['skip']
train: data/train.txt
val: data/val.txt
test: data/test.txt
nc: 1
names: ['skip']
nc: 1
depth_multiple: 0.33
width_multiple: 0.50
anchors:
- [10,13, 16,30, 33,23]
- [30,61, 62,45, 59,119]
- [116,90, 156,198, 373,326]
backbone:
[[-1, 1, Focus, [64, 3]],
[-1, 1, Conv, [128, 3, 2]],
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]],
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]],
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]],
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]],
]
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]],
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]],
[-1, 3, C3, [256, False]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]],
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]],
[-1, 3, C3, [1024, False]],
[[17, 20, 23], 1, Detect, [nc, anchors]],
]
nc: 1
depth_multiple: 0.33
width_multiple: 0.50
anchors:
- [10,13, 16,30, 33,23]
- [30,61, 62,45, 59,119]
- [116,90, 156,198, 373,326]
backbone:
[[-1, 1, Focus, [64, 3]],
[-1, 1, Conv, [128, 3, 2]],
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]],
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]],
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]],
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]],
]
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]],
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]],
[-1, 3, C3, [256, False]],
[注意]看雪招聘,专注安全领域的专业人才平台!
最后于 2021-9-16 09:37
被obaby编辑
,原因: 文档内容有问题,编辑器不支持火箭











 用过3款跳过的软件, 自动跳过,轻启动,李跳跳.感觉速度都很快.假如用识别的话速度是多大呢。不过识别确实大有可为
用过3款跳过的软件, 自动跳过,轻启动,李跳跳.感觉速度都很快.假如用识别的话速度是多大呢。不过识别确实大有可为



