最近在研究娜迦加固,娜迦加固的SO文件被ollvm混淆,转而研究ollvm反混淆。网上的很多关于ollvm反混淆的资料都基于符号执行。符号执行主要用框架是Miasm和Angr。Miasm和Angr对arm64指令集支持都不是很好,于是采用模拟执行的方式来寻找两个真实块的关系。本文仅提供大体思路,如果有更好的方法欢迎一起讨论,细节优化还要根据具体情况分析
我把ollvm混淆后的代码块分为两类:虚假块和真实块。虚假块仅包含ollvm流程控制指令,不含任何真实指令。只要含有真实指令的代码块就是真实块。
反ollvm混淆的关键是找出两个真实块之间的关系。
两个真实块之间的关系有两种:1、顺序;2、分支
使用符号执行、模拟执行找出真实块之间的关系之后,patch相应的跳转即可实现反混淆。
要获得目标函数的代码块和CFG,首先要反汇编。反汇编使用Capstone 反汇编引擎。
娜迦的样本中存在死循环路径,必须删掉。
真实块结束后会重新跳转入ollvm分发流程的代码块,该代码块一定有很多引用,所以反汇编代码块的时候记录后继节点的引用数目(见前一段代码)
反汇编和代码块识别完成后,如果某个代码块的引用大于1,就可能是分发器,引用该分发器的代码块就可能为真实块,筛选代码如下:
真实情况下,虚假代码块也会引用分发器,所以还要进一步筛选。
采用特征码的方法识别ollvm的虚假块。采用的特征码与寄存器、常量无关,只与指令类型、操作数类型有关。计算一个代码块的特征后进行匹配即可筛掉大量虚假代码块。
如果虚假块没有识别出来,那么可能导致后文的死循环,也是一种筛选思路。
按照定义,含有ret的代码块也属于真实块,但是前文真实块的识别基于引用 大量代码块的共同引用代码块,ret指令显然不会引用任何代码块,故单独处理。
关于Unicorn的教程请自行Google,这里仅讨论Unicorn在寻找路径方面的应用。
Unicorn 基于qemu的模拟,所以必须给代码提供可运行的环境。最大的问题就是要关心内存处理。
我们只想得到ollvm路径,而不是真实代码块的运行结果,因此要尽可能屏蔽非ollvm的内存操作。具体屏蔽方法稍后介绍。上面这段代码初始化Unicorn的虚拟CPU,并映射程序代码内存以及栈空间,最后调用hook_add设置UC_HOOK_CODE和UC_HOOK_MEM_UNMAPPED的事件回调。UC_HOOK_CODE回调会在每条指令执行前被调用,UC_HOOK_MEM_UNMAPPED会在内存异常的时候调用。
启动虚拟机的函数叫find_path,顾名思义,用于寻找真实块的下一个代码块。branch为分支控制。
如果branch = 1,则虚拟机在遇到csel指令的时候会走csel条件分支,否则走csel条件相反的分支。至于如何控制虚拟机内部指令的执行,稍后介绍。
使用队列的方式来路径搜索,起始搜索从函数入口开始。函数入口根据offset变量指定。
queue中的元素是一个二元组,第一项为执行地址,第二项为寄存器环境。每次搜索开始的时候从queue中获取一个将要搜索的真实块,设置寄存器,调用find_path搜索下一个真实块,将搜索到的真实块与新寄存器放入队列(保证上下文完整)使用这样做的好处就是可以搜索任意队列中的代码块,并且寄存器环境一定是和该代码块一致的。
Unicorn在每一条汇编代码执行前会调用UC_HOOK_CODE回调,通过该回调可以控制虚拟机的一些行为。
这一节的代码均属于hook_code
跳过一条指令,直接修改PC寄存器的值为下一条指令的地址:
路径探索,需要禁用掉一切函数调用、非栈空间内存访问,0x80000000为前面代码中提到的栈地址,当虚拟机指令有内存操作需求时,判断目标内存地址范围是否在栈中,如果不在栈中则跳过该指令。
禁用的指令有bl、blx,只要识别bl前缀即可。
寻找到下一个真实块的处理
调试机制。
为了方便调试,我设计了一个简单的调试机制 在[ ]添加断点地址即可断点,! + 寄存器即可查看寄存器的值。
含有branch的真实块处理。人工交换csel指令的值来实现分支。
使用graphviz库绘制流程图。
比较完整的代码
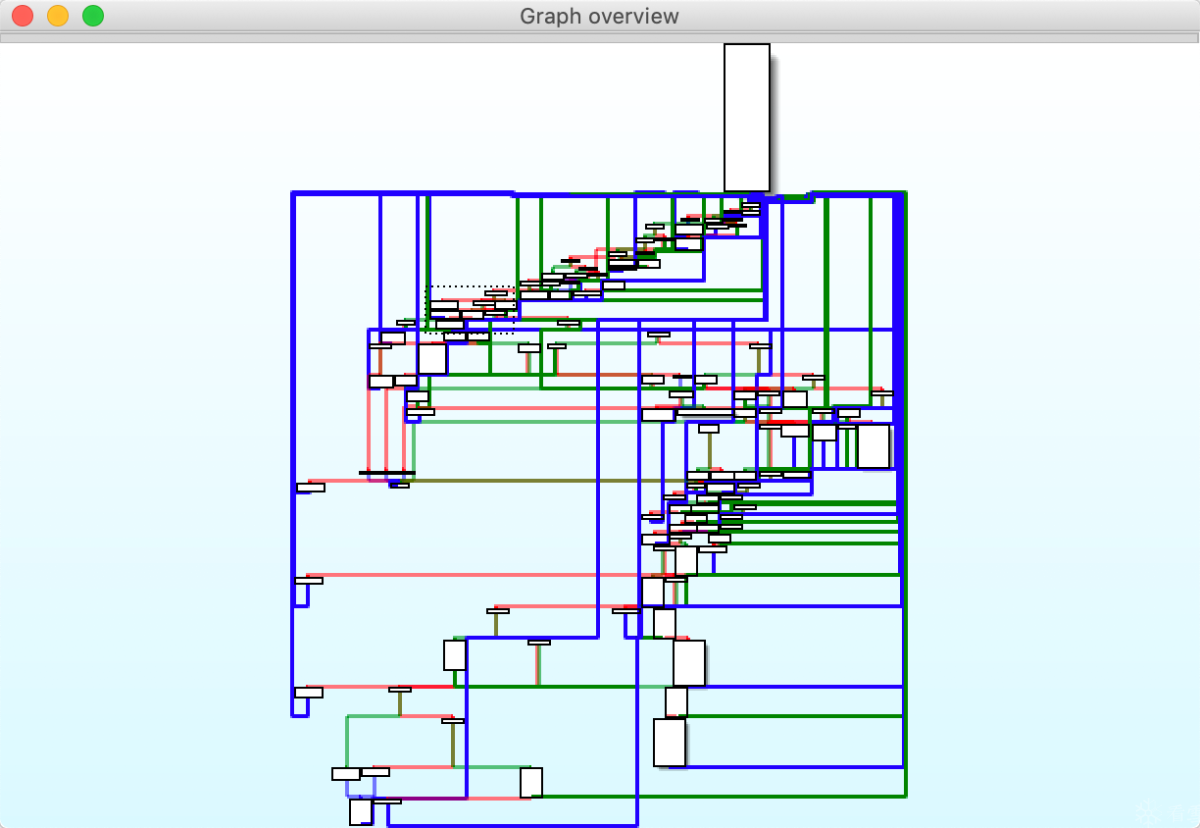
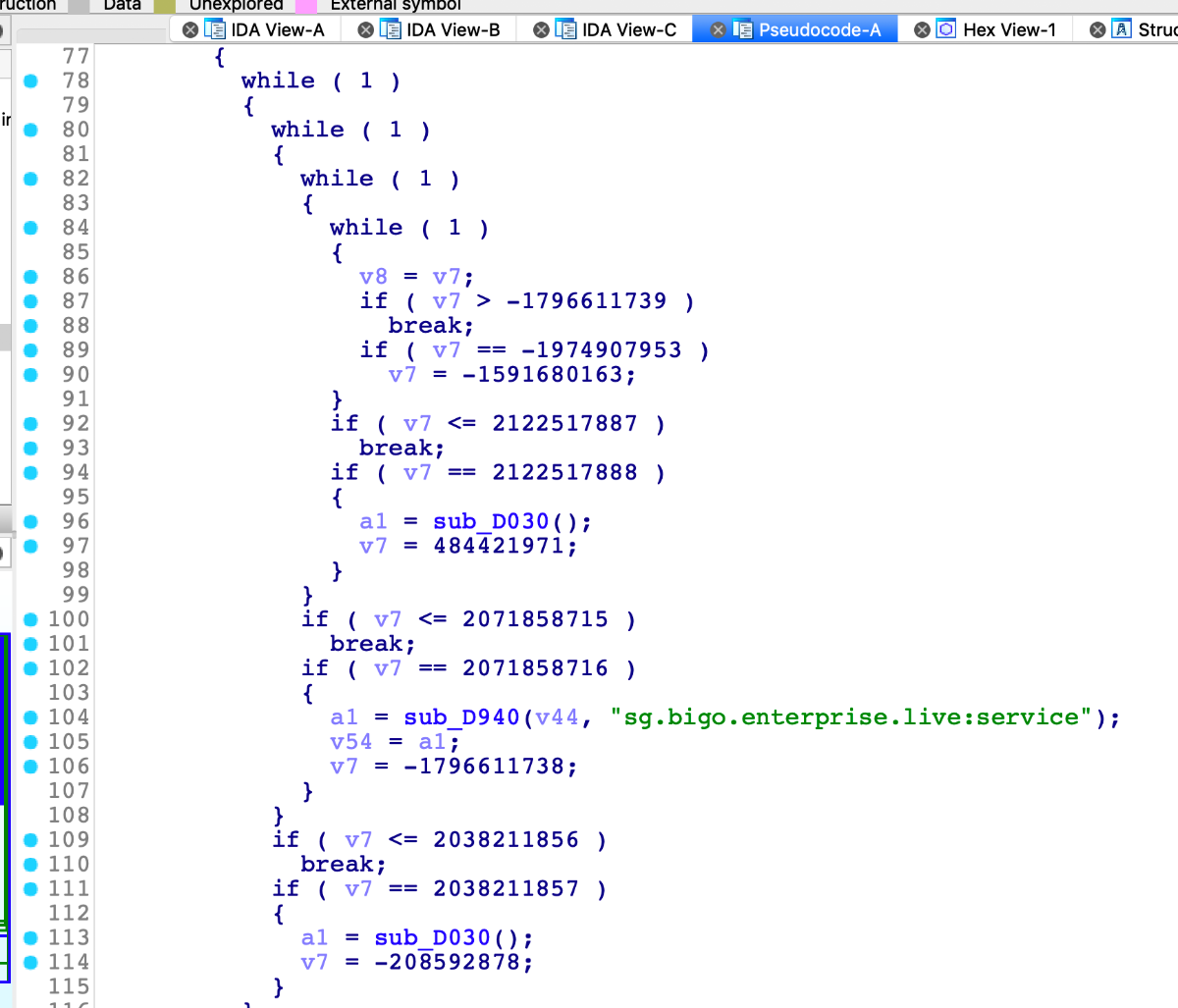

还原patch的代码已经被我阉割,因为不是很完善,我仅提供一个非符号执行的思路供大家研究。
完整代码见附件,代码反混淆的目标是JNI_OnLoad,可以自己修改offset和end来修改目标。输出文件为bin.out。
传递专业知识、拓宽行业人脉——看雪讲师团队等你加入!!
最后于 2019-6-29 16:20
被无名侠编辑
,原因:









