在与攻击者对抗的历程中,Web前端一直是非常薄弱的一环。浏览器毫无保留地把所有前端代码拉取到本地并执行、所有前端代码均透明可见。现在JS随着小程序和前端的兴起越来越火,收到了各个厂商的重视。如何保护前端JavaScript代码的安全? 最近自己正好在做JS的加密,分享一下自己的方案。
混淆工具有很多:YUI Compressor、UglifyJS、Google Closure Compiler,其中商业产品 有jscrambler等
2.加密
有些加密工具很有趣,比如aaencode:
加密前
alert("Hello, JavaScript")
加密后
゚ω゚ノ= /`m´)ノ ~┻━┻//*´∇`*/ ['_']; o=(゚ー゚)=_=3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o^_^o)/ (o^_^o);(゚Д゚)={゚Θ゚:
'_' ,゚ω゚ノ : ((゚ω゚ノ==3) +'_') [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ '_')[o^_^o
-(゚Θ゚)]
,゚Д゚ノ:((゚ー゚==3) +'_')[゚ー゚] }; (゚Д゚) [゚Θ゚] =((゚ω゚ノ==3) +'_') [c^_^o];(゚Д゚) ['c'] =
((゚Д゚.....
再比如jjencode:
加密前
alert("Hello, JavaScript")
加密后
$=~[];$={___:++$,$$$$:(![]+“”)[$],__$:++$,$_$_:(![]+“”)[$],_$_:++$,$_$$:({}+“”)[$],$$_$:($[$]+“”)[$],_$$:++$,$$$_:(!“”+“”)[$],$__:++$,$_$:++$,$$__:({}+“”)[$],$$_:++$,$$$:++$,$___:++$,$__$:++$};$.$_=($.$_=$+“”)[$.$_$]+($._$=$.$_[$.__$])+($.$$=($.$+“”)[$.__$])+((!$)+“”)[$._$$]+($.__=$.$_[$.$$_])+($.$=(!“”+“”)[$.__$])+($._=(!“”+“”)[$._$_])+$.$_[$.$_$]+$.__…….
或是使用base64加密
加密前
function a(e){/* ... */console.log(e.title)}a({title:\'buy\'})
加密后
eval(atob("ZnVuY3Rpb24gYShlKXsvKiAuLi4gKi9jb25zb2xlLmxvZyhlLnRpdGxlKX1hKHt0aXRsZTonYnV5J30p"));
加密前
function a(e){/* ... */console.log(e.title)}a({title:'buy'})
加密后
eval(function(p,a,c,k,e,r){e=String;if(!''.replace(/^/,String)){while(c--)r[c]=k[c]||c;k=[function(e){return
r[e]}];e=function(){return'\\w+'};c=1};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return
p}('3
0(1){4.5(1.2)}0({2:\'6\'})',7,7,'a|e|title|function|console|log|buy'.split('|'),0,{}))
先从uglify开始,它是github上点赞最多的JS解析引擎。它的安装容易出现各种问题,此时您需要google寻求答案(百度上的不是很全)。
刚开始做这件事时,半就被叫停了,因为据说我们组之前有人用uglify做过,出现了很多建荣祥问题,所以弃用。
于是我转战spidermonkey,他是火狐浏览器(firefox)自带的解析引擎。由C语言写成的。考虑到和现有系统的兼容,以及对指针操作的方便,我们选择C语言开发,而spidermonkey恰好是C语言开发的。
还是首先尝试使用它,使用时发现它的代码风格类似JNI,以下是我之前写的测试用例:
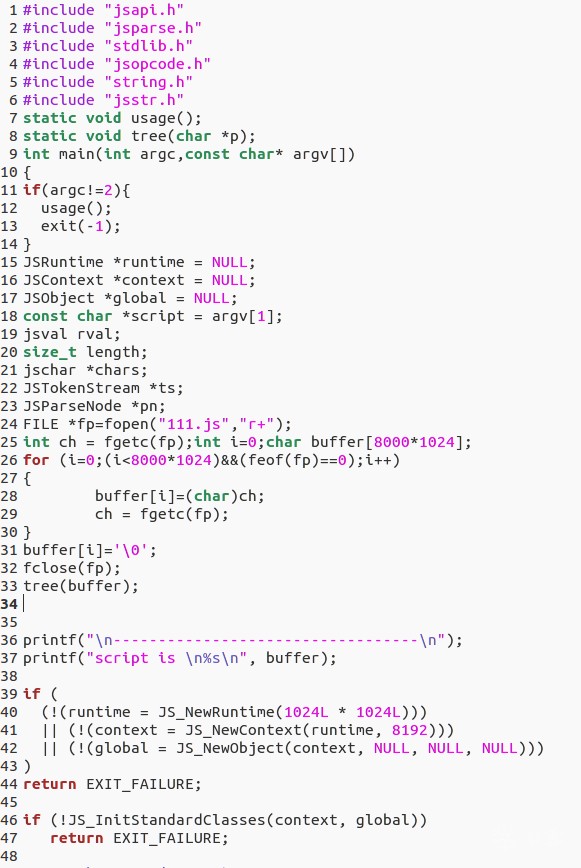
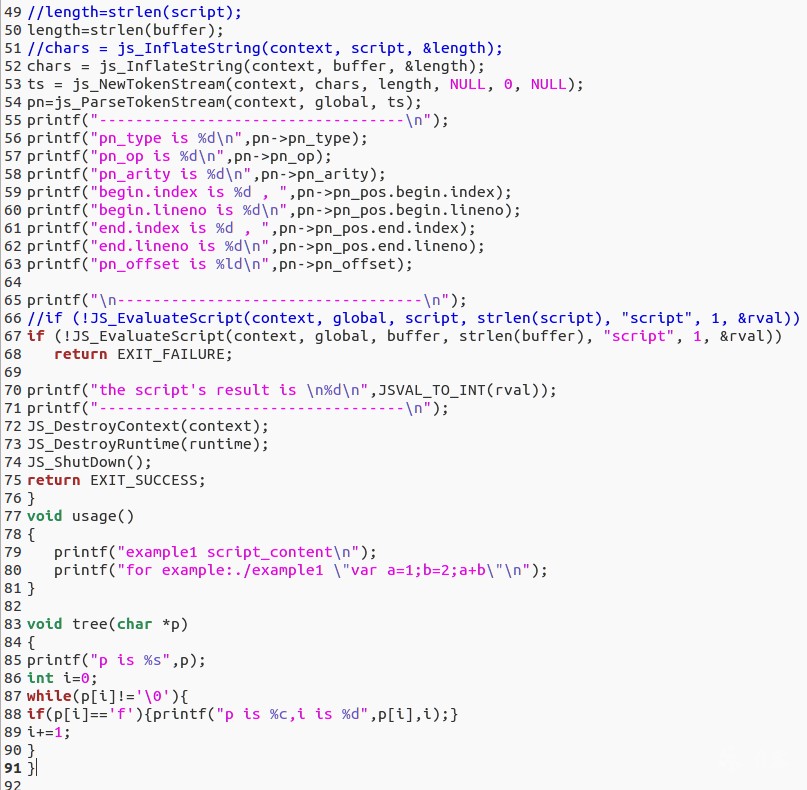
学习spidermonkey的过程大量借助google,官方手册是一个很好地学习途径。贴一个参考链接:
https://wiki.mozilla.org/JavaScript:SpiderMonkey:Parser_API
spidermonkey引擎可帮助我们在C语言的环境下执行JacaScrpt代码,我认为在物联网设备中可以发挥很大的用途。代码使用JNI编写,JNI和普通的C开发区别其实不大,用熟悉了总结出模板以后可以直接用。这段脚本还包含了一些我曾经测试过的痕迹,显示出我曾试图去理解构建语法树的过程和各个参数的含义。
当时我分析了JS的解析和执行过程,它先生成tokenstream,我找出了这个的API,并找出了输入tokenstream,输出语法树的API。然后就开始分析语法树的生成过程。但因为这棵树确实比较复杂,看了两三天都没什么头绪,试图修改别人方案实现自己目的的想法也宣告失败了。
这里只简单记录一下spidermonkey的安装和使用容易忘记的步骤:核心文件在src文件夹下,如果编译以后.o文件在Linux_All_DBG.OBJ里,这个文件夹要配个环境变量。然后,手工移动一下一个头文件
这个方面网上的教程写的很清楚,只需要注意环境变量要配置。具体可参考这篇博客
https://www.cnblogs.com/chenfool/p/3840625.html
走投无路之下,只好自己写语法树了。我买了一本专用于考研的《王道数据结构》,写的比较精炼,推荐给大家。
说起数据结构,由于我本人并不是计算机科班出身,之前并没有接收系统的训练,只能从0开始一点点写起来。我最开始是从顺序表开始的,自己实现了它的插入算法和删除算法。顺序表类似数组,但没有指针域的。写完以后就觉得其实还挺简单的,对于刚入门的初学者难度适中。
接着就开始写二叉树了,通过实现一个简答的二叉树,我了解了数据域,指针域怎么分配,树是如何创建的,记得当时只用了不到一天写完了,很有成就感
如何学习新的知识:原来我是看一点,敲一点代码,理解一点,全部都敲完以后,似乎都懂了,其实印象不深,而且再让你写一遍还写不出来。
这里和大家分享我的导师明姐教我的学习方法,我认为是我自个项目最大的收获:先看一遍,然后自己写,不会的再回头去学。也许刚看完有很多你不会的,但是不要慌张,或者认为自己写不出来,必须全理解了才去做事。遇到不清楚的,自己试着写代码,速度,印象成倍提高,说不定回头看,你写的比教材里的还好。
原来就是看一点敲一点理解一点,太慢了,自从使用新方法后效率成倍增加。感谢我的导师,明姐,这个方法就是她教我的。只要她在安全领域保持5年以上的专注,她以后一定会成为安全圈叱咤风云的人物。希望你一直牛逼下去。乘胜追击写了二叉树的生成,写了二叉树的前序遍历,二叉树的层序遍历,队列的层序遍历,可以说理解了递归思想,和它的使用方法。
现在开始就是本文的重点了,我们的语法树体现了以下点子和技术:
1、使用兄弟孩子表示法,这个从二叉树衍生出的,我们用了这种结构来构建自己的语法树。
2、 结点回溯技术。如果一个根结点开始,树生长完后怎样回到最开始的根结点呢?通过结点回溯。怎么回溯?生成树的时候在指针域里加一个指向前一结点的指针 CBNODE * parent,不停得往回找,直到找到第一个左结点(长子结点)不为空,然后他的右结点(兄弟结点)。挺自豪的,自己的原创
3、 独创 “前序深度遍历”的概念,可以将指定深度的函数一次性全部拿出来,然后执行加密。
4、 修改语法树的方法:采用了结点替换技术,稍后讲到
5、 如何把整个funtion全都拎出来加密呢?根据前序遍历 “根,左,右”的顺序, 只要找到funtion,从那个结点开始做一个前序遍历,函数就全都出来了,
[招生]科锐逆向工程师培训(2024年11月15日实地,远程教学同时开班, 第51期)
最后于 2019-7-5 18:43
被r0Cat编辑
,原因:





 求包养~~
求包养~~




