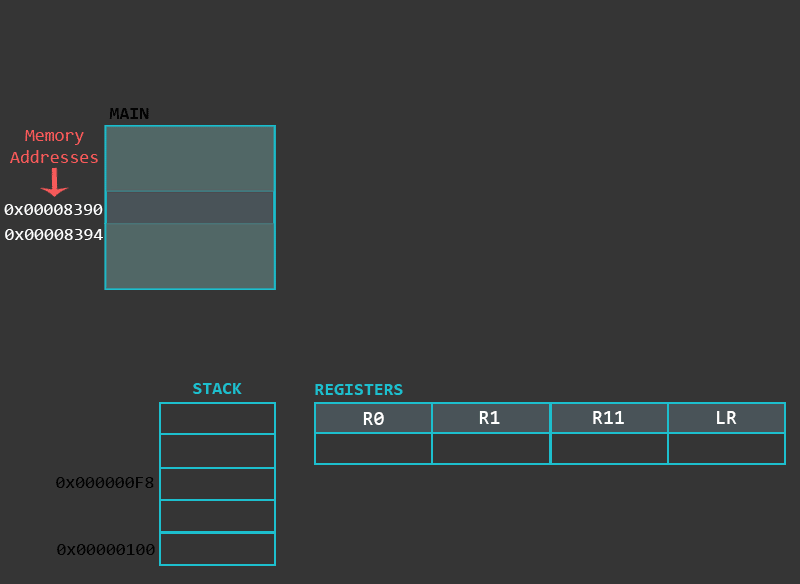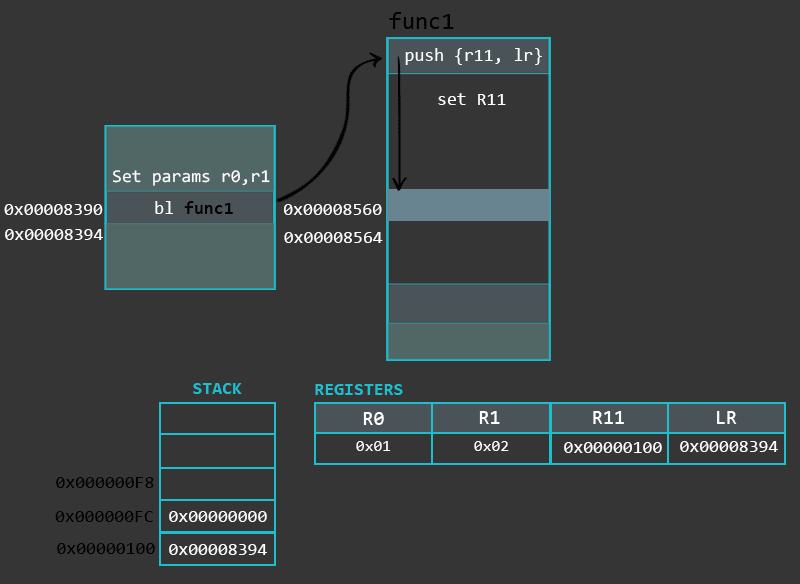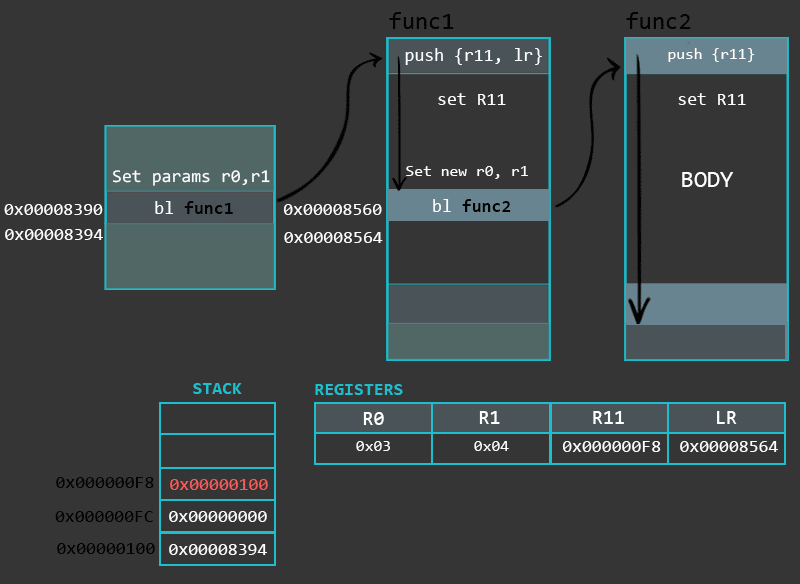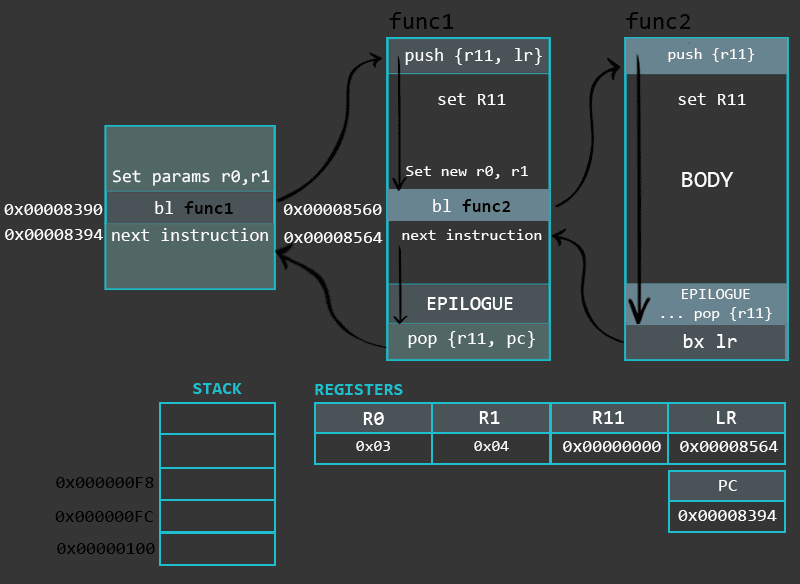
Prologue sets up the environment for the function; 序言部分建立了函数的运行环境
Body implements the function’s logic and stores result to R0;函数体部分实现函数的逻辑并将返回值存储进R0
Epilogue restores the state so that the program can resume from where it left of before calling the function.尾声部分恢复了函数被调用之前的状态并继续运行。
The example above contains two functions: main, which is a non-leaf function, and max – a leaf function. As mentioned before, the non-leaf function calls/branches to another function, which is true in our case, because we branch to a function max from the function main. The function max in this case does not branch to another function within it’s body part, which makes it a leaf function.
Another key difference is the way the prologues and epilogues are implemented. The following example shows a comparison of prologues of a non-leaf and leaf functions另一个很关键的差异是:序言和尾声的实现方式不同。下面的例子比较了叶函数和非叶函数的序言
The main difference here is that the entry of the prologue in the non-leaf function saves more register’s onto the stack. The reason behind this is that by the nature of the non-leaf function, the LR gets modified during the execution of such a function and therefore the value of this register needs to be preserved so that it can be restored later. Generally, the prologue could save even more registers if it’s necessary.
The comparison of the epilogues of the leaf and non-leaf functions, which we see below, shows us that the program’s flow is controlled in different ways: by branching to an address stored in the LR register in the leaf function’s case and by direct POP to PC register in the non-leaf function.
Finally, it is important to understand the use of BL and BX instructions here. In our example, we branched to a leaf function by using a BL instruction. We use the the label of a function as a parameter to initiate branching. During the compilation process, the label gets replaced with a memory address. Before jumping to that location, the address of the next instruction is saved (linked) to the LR register so that we can return back to where we left off when the function max is finished.
The BX instruction, which is used to leave the leaf function, takes LR register as a parameter. As mentioned earlier, before jumping to function max the BL instruction saved the address of the next instruction of the function main into the LR register. Due to the fact that the leaf function is not supposed to change the value of the LR register during it’s execution, this register can be now used to return to the parent (main) function. As explained in the previous chapter, the BX instruction can exchange between the ARM/Thumb modes during branching operation. In this case, it is done by inspecting the last bit of the LR register: if the bit is set to 1, the CPU will change (or keep) the mode to thumb, if it’s set to 0, the mode will be changed (or kept) to ARM. This is a nice design feature which allows to call functions from different modes.
To take another perspective into functions and their internals we can examine the following animation which illustrates the inner workings of non-leaf and leaf functions.
为了从另一个角度观察函数及其内部结构,我们可以看看下面的动画,它说明了非叶和叶函数的内部工作状况。
In this part we will look into a special memory region of the process called the Stack. This chapter covers Stack’s purpose and operations related to it. Additionally, we will go through the implementation, types and differences of functions in ARM.
Generally speaking, the Stack is a memory region within the program/process. This part of the memory gets allocated when a process is created. We use Stack for storing temporary data such as local variables of some function, environment variables which helps us to transition between the functions, etc. We interact with the stack using PUSH and POP instructions. As explained in Part 4: Memory Instructions: Load And Store,PUSH and POP are aliases to some other memory related instructions rather than real instructions, but we use PUSH and POP for simplicity reasons.
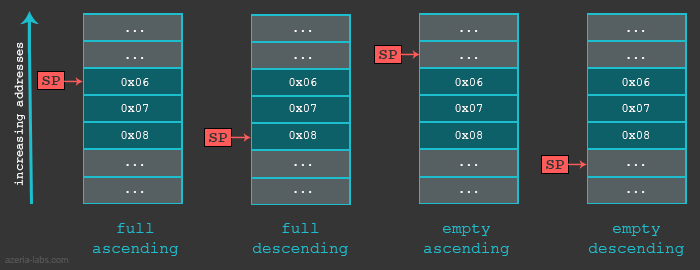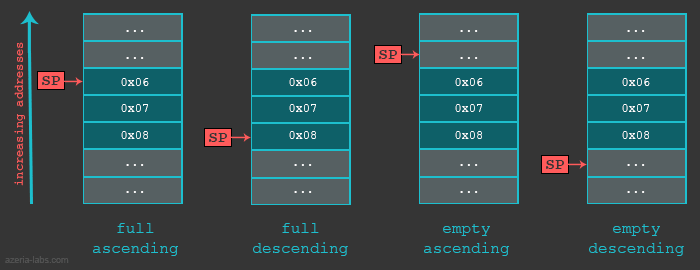
Before we look into a practical example it is import for us to know that the Stack can be implemented in various ways. First, when we say that Stack grows, we mean that an item (32 bits of data) is put on to the Stack. The stack can grow UP(when the stack is implemented in a Descending fashion) or DOWN (when the stack is implemented in a Ascending fashion). The actual location where the next (32 bit) piece of information will be put is defined by the Stack Pointer, or to be precise, the memory address stored in the SP register. Here again, the address could be pointing to the current (last) item in the stack or the next available memory slot for the item. If the SP is currently pointing to the last item in the stack (Full stack implementation) the SP will be decreased (in case of Descending Stack) or increased (in case of Ascending Stack) and only then the item will placed in the Stack. If the SP is currently pointing to the next empty slot in the Stack, the data will be first placed and only then the SP will be decreased (Descending Stack) or increased (Ascending Stack).
As a summary of different Stack implementations we can use the following table which describes which Store Multiple/Load Multiple instructions are used in different cases.
In our examples we will use the Full descending Stack. Let’s take a quick look into a simple exercise which deals with such a Stack and it’s Stack Pointer.
本例中我们使用全递减堆栈。让我们快速查看一个处理堆栈和堆栈指针的简单练习。
/* azeria@labs:~$ as stack.s -o stack.o && gcc stack.o -o stack && gdb stack */
.global main
main:
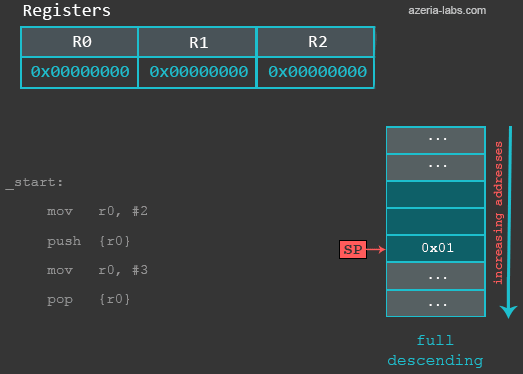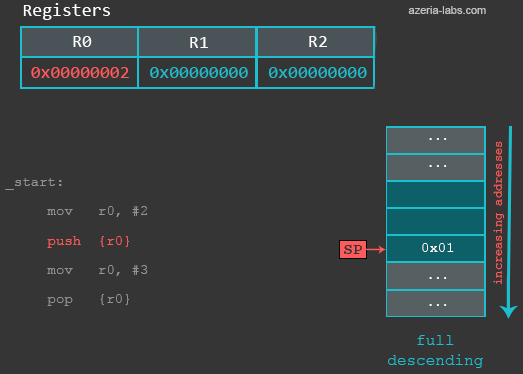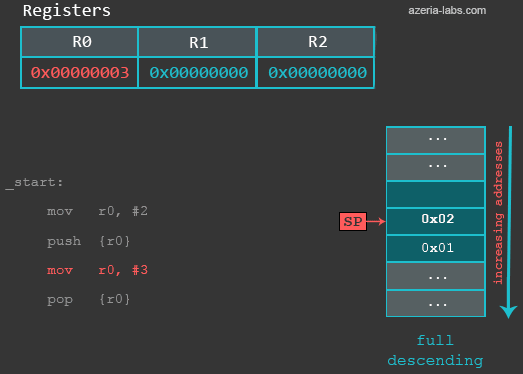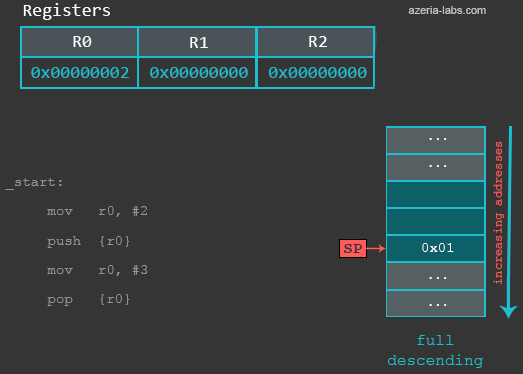
mov r0, #2 /* set up r0 设置R0的数值 */
push {r0} /* save r0 onto the stack 将R0压入栈*/
mov r0, #3 /* overwrite r0 覆盖R0*/
pop {r0} /* restore r0 to it's initial state 将R0恢复到初始状态*/
bx lr /* finish the program 程序结束*/
At the beginning, the Stack Pointer points to address 0xbefff6f8 (could be different in your case), which represents the last item in the Stack. At this moment, we see that it stores some value (again, the value can be different in your case):
After executing the first (MOV) instruction, nothing changes in terms of the Stack. When we execute the PUSH instruction, the following happens: first, the value of SP is decreased by 4 (4 bytes = 32 bits). Then, the contents of R0 are stored to the new address specified by SP. When we now examine the updated memory location referenced by SP, we see that a 32 bit value of integer 2 is stored at that location:
The instruction (MOV r0, #3) in our example is used to simulate the corruption of the R0. We then use POP to restore a previously saved value of R0. So when the POP gets executed, the following happens: first, 32 bits of data are read from the memory location (0xbefff6f4) currently pointed by the address in SP. Then, the SP register’s value is increased by 4 (becomes 0xbefff6f8 again). The register R0 contains integer value 2 as a result.
Please note that the following gif shows the stack having the lower addresses at the top and the higher addresses at the bottom, rather than the other way around like in the first illustration of different Stack variations. The reason for this is to make it look like the Stack view you see in GDB)
We will see that functions take advantage of Stack for saving local variables, preserving register state, etc. To keep everything organized, functions use Stack Frames, a localized memory portion within the stack which is dedicated for a specific function. A stack frame gets created in the prologue (more about this in the next section) of a function. The Frame Pointer (FP) is set to the bottom of the stack frame and then stack buffer for the Stack Frame is allocated. The stack frame (starting from it’s bottom) generally contains the return address (previous LR), previous Frame Pointer, any registers that need to be preserved, function parameters (in case the function accepts more than 4), local variables, etc. While the actual contents of the Stack Frame may vary, the ones outlined before are the most common. Finally, the Stack Frame gets destroyed during the epilogue of a function.