前一段时间一直没上来看,刚把新版做好。昨天想更新,发现原来的帖子不能编辑了,再发一个。http://bbs.pediy.com/showthread.php?t=143377 2013/01/30更新 v1.4
这样就可以了。
实际上是一组平行的循环,功能与高级语言中的循环+switch类似
由于插件反汇编是以指令块为单位的,一般情况下目标在和转移相同的指令块中生成,但是计算这种转移的目标需要同时考虑多个指令块。现在的方法是反汇编时发现目标已经分析过,就检查目标是不是动态转移,如果是的话就把当前反汇编路径上的指令块连接起来计算。由于反汇编使用深度优先遍历,正好和执行顺序相同,这样就可以计算了。
有了算法分析再看这些检查就容易多了,可以看出返回地址是
这里两个来源的堆栈信息不同,堆栈是错位的。如果选择了使用来源1的堆栈信息,需要做以下调整,使栈顶对齐
现在可以通过vESP偏移来引用相同的数据了,但是由于改变了数据地址,使用绝对地址引用的数据会错位。
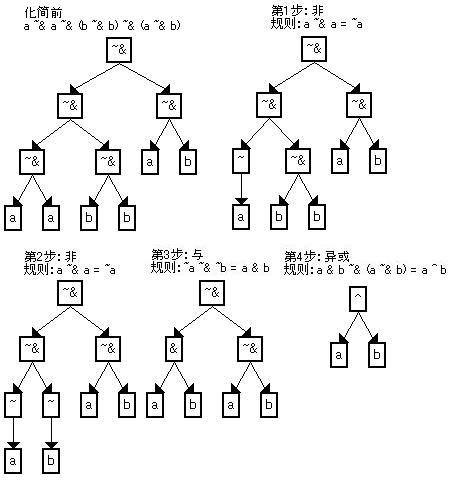
生成的指令关系如下(图形由数据流图功能产生)
这段代码实际是计算a&b和c&d,但是两个表达式的不同部分交替计算,计算过程不是连续的,实际上相邻的两个之间互相无关,如果中间再插入垃圾指令(VMP经常这么做),分析就更麻烦了。由于数据分析时已经建立了关系,可以不受这些干扰,而且已经生成了基本的操作表达式,这里只要按顺序代入表达式里了变量就行了。前面数据分析的例子代入后变成了
这里要把临时变量全部代入,直到结束数据,因为临时变量是计算的中间步骤,最终结果中不能保留。在代入过程中需要定义一些变量,如果产生指令块的结束数据需要定义结束变量,因为结束数据可以在指令块外使用,这肯定是一个完整的表达式。即使加了变形有垃圾转移也不会把原来完整的操作分开,变形是在汇编语言做的,然后再虚拟,所以最多把代码扩张前的表达式分开,不会分开单个汇编指令。读不在已知数据中的堆栈或内存也要定义变量,因为这些数据不是当前分析的代码中产生的,直接定义为堆栈或内存变量。如果两次读取的地址表达式和长度相同,变量名也相同,这一般没有什么问题,如果两次读取之间有写入,第二次读取就会变成读取已知数据的内容。但是如果内存地址不是常量,写入时不会添加到已知数据,两次读取变量名相同,但是内容已经不同了,分析结果就有可能错误。现在认为写未知地址不改变已知数据,因为已知数据是已经知道地址的数据,两次写入之间计算地址一般都相同。如果一个临时变量已经变成其他类型,比如结束变量或堆栈内存变量,可以不代入,直接把表达式中的临时变量改成对应的名称就可以了。
可以看出只需要重复应用一些很简单的规则就能把一个大表达式逐渐化简,VMP的强度就在这些看似简单的规则上,每个部分只做很少的工作,单独看几乎没有什么意义,但其组合却非常复杂,程序中所有功能都是靠这些组合来完成的。其实化简算是比较容易的,大部分时间都花在了拆分表达式和定义变量上,如果变量定义的不好,代码会很难看。
这只能化简指令的操作表达式,不能减少指令数量。每一步计算都显示了,大部分计算的中间步骤是不需要的,必须找出最终操作的位置。前面已经定义过了一些变量,比如结束变量、堆栈变量、内存变量等,这里要做的是拆分结束变量的表达式定义中间变量和清理结束变量。由于结束变量表达式中的内容全部代入了,所有操作组合到了一起,一般都很长,而且有很多重复操作。先找出所有结束变量中重复出现的表达式,对每个重复表达式产生的地方定义中间变量,再把对这些表达式的使用替换成对变量的使用,这样可以减少表达式长度。
这是查找字符串中最后一个\,VMP加壳的入口就有这样的代码,用于截取文件名,这里为了简单直接认为字符串长度不会超过10。因为其中有一个b = a,就是把a复制了一份,b的值等于a,如果不保留复制,这两个变量会产生一个交汇,在后面清除交汇函数时被合并为一个变量。化简和清除交汇函数后会生成下面的代码
下面是保留复制的代码,这是正确的
退出虚拟机(包括调用时)后可以访问的变量也不能清除,这要先知道哪些数据是退出后有效的,由于需要从后向前跟踪数据,直接和识别无效指令放在一遍了。在识别无效指令时如果遇到vCall、vRet和虚拟机内调用的vJmp,把指令执行后依然有效的结束数据做上标记,以后分析时如果发现有指令写入这个数据,说明产生数据是退出后有效的,然后清除结束数据上的标记,因为只想知道最后一次赋值。如果一个指令块分析结束后还没有发现指令写入这个数据,就把标记传播到上一个指令块继续分析。清理结束变量完成后就把结束变量和中间变量全部转成最终操作变量。2013/02/05添加immdbg版
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
上传的附件: