QBDI的代码位于: https://github.com/QBDI/QBDI
QBDI的含义为: A Dynamic Binary Instrumentation framework based on LLVM。
它对标的是像Frida Stalker这样的工具,但是QBDI没有像frida那样提供了代码注入的功能,需要自己实现注入代码并且启动QBDI。
其他相似的工具有:
valgrind: 一款用于内存调试、内存泄漏检测以及性能分析的软件开发工具,只支持linux平台,使用起来比较复杂
DynamoRIO: 开源多平台的应用程序动态instrumentation框架
以下内容没有特别说明都是针对arm64平台。
从github下载代码以后,修改cmake/config/config-android-aarch64.sh文件加入以下行 :
编译:
运行示例程序:
调试:
将ndk的lldb-server push到手机中
在手机端执行:
在PC端执行:
可以看到在这个示例的代码(examples/cpp/fibonacci.cpp)中,需要自己调用被trace的函数并且传递需要的参数:
其实我们可以利用frida的inline hook功能拦截原始函数的参数并且转交给qbdi让它trace,就不需要我们自己准备参数了。
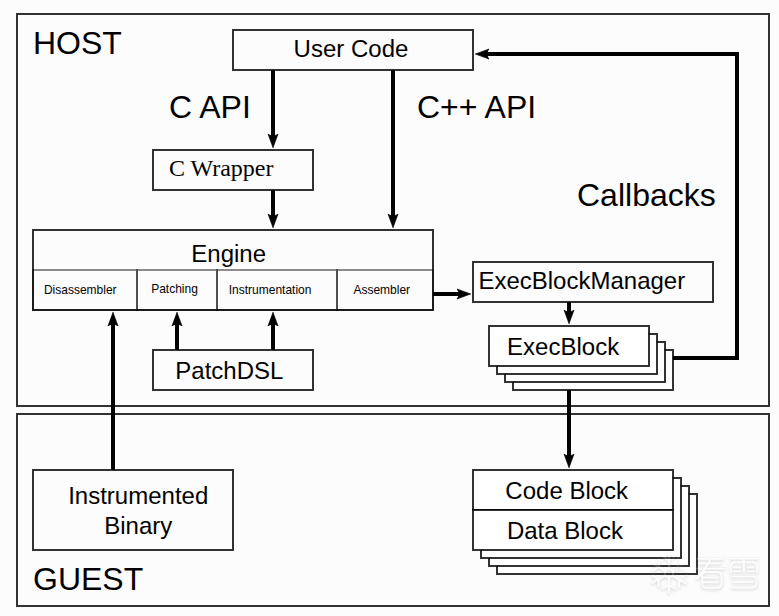
qbdi本质上是一个VM,监视程序的运行指令流并跟随该流实时的patch代码。
所以会有qbdi context和guest context并有上下文切换的操作。
遇到不在指定trace范围的代码经由ExecBroker将控制权递交出去并监控返回点,返回以后再接管控制。
执行流程:
知道了大概原理以后来看一下trace相关API:
操纵trace范围的api:
跟踪指令执行:
VM事件API:
内存访问API:
dbi意味着需要修改原始指令添加instrument代码,那么就需要创建新的内存空间容纳这些代码并且重定向 ,由于不可能事先处理整个二进制代码,因此需要运行时监视程序指令流,只处理真正需要执行的代码块。因此就引入了qbdi上下文和guest(我这里用虚拟化中的术语称之为guest) 上下文,这有点类似于qemu tcg中的用x86指令模拟arm指令运行时的上下文切换与指令处理技术,两者有些相通性,只不过qbdi运行在和guest一样的用户进程中,也因此带来了一些缺陷: trace框架本身用到的非重入性库函数可能会导致死锁,而且qbdi对目标程序属于弱控制,不像qemu或者java虚拟机可以完全控制目标的执行流。
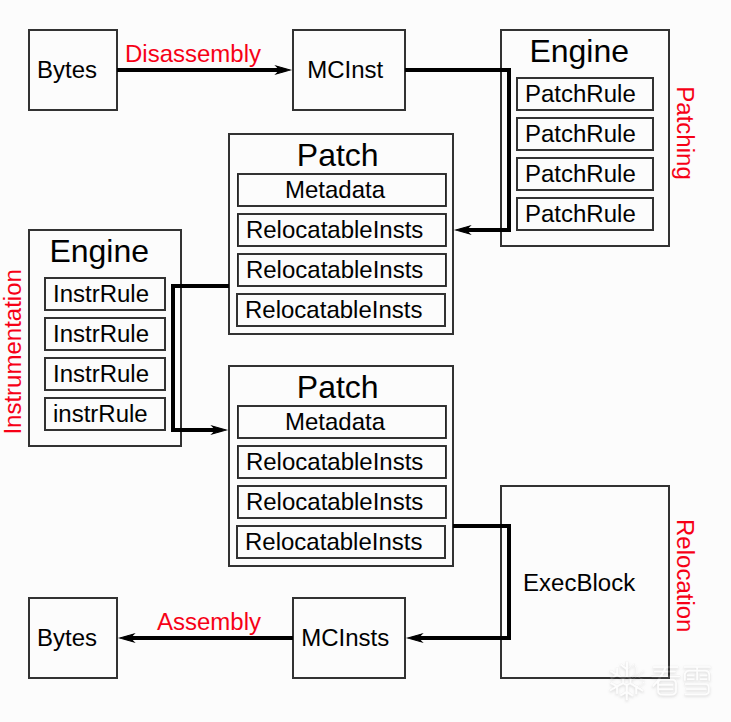
由于目标trace代码可能有pc相关指令因此需要重定向修复操作,这个步骤称为patch,而且需要加入跟踪指令,这个步骤称为instrument,还需要进一步组装加入上下文切换相关代码,因此整个执行过程如下: 反汇编 -> patch -> instrument -> 组装 -> 执行 -> 反汇编 ...
上下文切换:
guest上下文主要由 GPRState和FPRState结构组成, GPRState包括了体系结构的所有通用寄存器(也包括条件码),FPRState则包括了所有浮点寄存器。它们都作为Engine类的成员变量。
切换到guest执行需要恢复GPRState和FPRState,而切回qbdi则需要保存GPRState和FPRState。在执行guest时宗旨是不能修改guest状态,包括栈和寄存器,因为被trace的代码可能各种各样,不能假设trace代码如何使用栈和寄存器,最好的方式就是原样维持否则将会引发与原有程序执行不一致的问题。
而对原始指令进行pc重定位和添加instrument代码可能会不可避免的引入寄存器的修改。设想有一个需要trace的代码片段,它使用了所有的通用寄存器进行某种计算,在里边添加的instrument指令是某种函数调用,调用到qbdi提供的指令跟踪函数(处于qbdi上下文),那么这些instrument指令如何实现? 如果是近端可以使用pc相对寻址,如果是远端则需要借助于ADRP/LDR这样的指令,这样就引入了对某个guest寄存器的修改,就需要保存该寄存器,执行完指令以后再恢复。那么保存到哪里又成了问题,像普通的函数调用是有调用约定,caller保存一些可能被callee修改的寄存器在栈上,调用完之后从栈中恢复。但对qbdi来说它不能保存在guest的栈上(会破坏原代码环境),那么就需要保存到qbdi上下文的内存中,这段内存需要事先配置好让guest上下文中的代码可以相对寻址访问到,这个方案类似于arm中的常量池(Literal Pool), qbdi对应的则为ExecBlock。
借用官方文档里边的图:
每一段需要执行的代码都被放置在了一个ExecBlock对象当中,它由两个4096大小的页组成:
这样在codeBlock当中的代码就可以使用相对寻址方式访问到dataBlock中的数据,在qbdi所支持的体系结构中,都支持相对寻址至少4096字节。
如果需要执行的代码多于4096字节那么会有多个ExecBlock,每一条需要执行的指令经过重定位并添加instrument片段以后都放置在codeBlock中,伴随着的还有prologue和epilogue代码用于上下文切换以及控制管理,而dataBlock中的GPRState和FPRState用于保存guest上下文, Host Context则保存qbdi一侧所需的上下文信息,因此这个方案会有一些内存冗余。
Shadows区域则保存着和patch、instrument相关的shadow数据如常量等:
结构图(引用自官方):
用户代码通过QBDI::VM暴露出来的api来和Engine对象进行交互,Engine负责总管整个控制流并且利用PatchDSL来对目标指令重定位、instrument和组装,PatchDSL是QBDI自己提出的概念,它用一个中间层让重新组装目标代码变的简单,如果是RET或者BR指令,以下的代码就可以实现重定位:
ExecBlockManager顾名思义管理各个ExecBlock,最终执行的是ExecBlock中的Code Block代码。
LLVM:
qbdi使用LLVM的MC功能来反编译以及生成目标指令,比如反编译我们可以执行: echo "0x76 0x02 0x40 0xf9" | llvm-mc --disassemble -triple=aarch64
qbdi使用CMake的FetchContent_Populate函数将92eK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6D9L8s2k6E0i4K6u0r3L8r3I4$3L8g2)9J5k6s2m8J5L8$3A6W2j5%4c8Q4x3V1k6J5k6h3I4W2j5i4y4W2M7#2)9J5c8X3c8G2N6$3&6D9L8$3q4V1i4K6u0r3L8r3I4$3L8h3!0J5k6#2)9J5k6o6p5&6i4K6u0W2x3g2)9J5k6e0g2Q4x3V1k6D9L8s2k6E0i4K6u0V1x3e0W2Q4x3X3f1I4i4K6u0W2y4g2)9J5k6i4y4J5j5#2)9J5k6i4c8S2M7W2)9J5k6i4S2*7i4@1f1$3i4K6V1$3i4K6R3%4i4@1f1@1i4@1u0n7i4@1t1$3i4@1f1@1i4@1t1^5i4K6S2n7i4@1f1^5i4@1u0p5i4@1u0p5i4@1f1#2i4K6R3^5i4@1t1H3i4@1f1$3i4K6W2o6i4@1q4o6i4@1f1#2i4K6W2o6i4@1t1H3i4@1f1#2i4K6S2r3i4K6R3J5i4@1f1@1i4@1t1^5i4K6S2q4i4@1f1%4i4@1u0o6i4K6V1$3i4@1f1^5i4@1q4r3i4K6V1I4i4@1g2r3i4@1u0o6i4K6S2o6i4@1f1#2i4@1t1&6i4@1t1$3i4@1f1@1i4@1t1^5i4K6V1@1i4@1f1$3i4K6S2o6i4K6R3%4i4@1f1#2i4@1q4q4i4K6W2m8i4@1f1%4i4@1u0o6i4K6V1$3i4@1f1^5i4@1q4r3i4K6V1I4i4@1f1%4i4K6W2m8i4K6R3@1i4@1f1%4i4@1u0n7i4K6R3@1i4@1f1@1i4@1u0n7i4@1t1$3i4@1f1@1i4@1t1^5i4@1u0m8i4K6y4m8
LLVMBinaryFormat
LLVMMCDisassembler
LLVMMCParser
LLVMMC
LLVMSupport
LLVMObject
LLVMTextAPI
LLVMCore
LLVMBitReader
LLVMBitstreamReader
LLVMRemarks
在qbdi中使用了LLVMCPU类做为LLVM库的封装,那么反编译就可以这么来调用:
生成指令:
可以看到指令的低层表示为llvm::MCInst类
ps: llvm::MCInstrDesc的getNumDefs的含义: This is the number of "outs" in the .td file
对应着AArch64InstrInfo.td文件中的outs,比如:
对于MRS_FPSR它的getNumDefs就为1(outs GPR64:$dst),对于MSR_FPSR它的getNumDefs就为0(因为outs后面为空)
接下来就可以看一条具体指令的组成,下图仍然取自官网:
一条原始指令被llvm库反编译为MCInst对象以后,会进入到patch环节,该步骤主要重定位pc相关指令,patch逻辑用PatchRule类表示,PatchRule由PatchCondition和PatchGenerator列表组成,PatchCondition表示指令匹配到该PatchRule需满足的条件,PatchGenerator表示满足条件以后需执行的patch动作。比如下面一条PatchRule:
很明显有个PatchRule列表,每一条PatchRule匹配一类指令,处理的指令有: SVC,BRK,RET,BR,BLR,B,Bcc,ADR,ADRP,TBZ,TBNZ,BRAA, BRAB, BRAAZ, BRABZ, RETAA, RETAB等。如果所有匹配都没命中还会有个default匹配(条件为True)用于确保可以正确保存和恢复x28寄存器:
x28寄存器的作用后面详述。
接下来是一个重要的类:Patch,它的成员变量含义如下:
InstMetadata metadata : 保存原始指令的信息如llvm::MCInst inst、地址address,指令大小instSize等。
std::vector<std::unique_ptr<RelocatableInst>> insts: 可重定位指令由RelocatableInst抽象类表示,在上图中,经过patch以后Patch的insts列表就会被填充为重定位后的RelocatableInst,此时指令还未写入到codeBlock,只有调用RelocatableInst的reloc()以后返回的llvm::MCInst指令才会被qbdi写入到codeBlock。
std::array<RegisterUsage, NUM_GPR> regUsage: 记录了当前指令所使用到的寄存器情况,涉及到寄存器分配。
std::vector<InstrPatch> instsPatchs: 保存instrument以后的RelocatableInst列表,这个列表最终会被合并到insts列表中去。
经过patch阶段以后,接下进入instrument阶段处理,instrument规则由InstrRule表示,它和PatchRule共用一套PatchDSL,生成出来的RelocatableInst列表存放于Patch类的instsPatchs成员变量中。
Patch对象对应的指令最终会在ExecBlockManager::writeBasicBlock函数中被写入到内存。
指令在内存中的变化:
我们来看一下pc相对寻址ldr指令是如何处理的:
LDR Xn, label:
这条指令加载pc+label地址处的值赋值给Xn寄存器
上面PatchDSL中的GetPCOffset、ModifyInstruction、AddOperand以及SaveX28IfSet都属于PatchGenerator,它用来生成RelocatableInst列表:
假设目标指令为ldr x8, #0x14
经过重定位以后指令变为两条:
ldr x28, [x27, #1248]
ldr x8, [x28]
让我们来看看这中间发生了什么。
首先看一下条件部分: LDRSl | LDRDl | LDRQl | LDRXl | LDRWl | LDRSWl
这些值的含义对应于llvm中的tablegen : https://llvm.org/docs/TableGen/
在build/_deps/qbdi_llvm/llvm/lib/Target/AArch64/AArch64InstrInfo.td文件中我们可以找到上述变量的定义:
可以看到这些指令对应于LoadLiteral。
再来看一下PatchGenerator是怎么执行的,分以下步骤:
GetPCOffset
ModifyInstruction
SaveX28IfSet
执行的时候还涉及Temp,Operand和Constant的概念,这些都是PatchDSL相关的。前面提到DataBlock和CodeBlock这两页紧靠在一起是提供给guest一个 Literal Pool常量池的 内存,guest指令可以直接读写DataBlock中的数据。针对
ldr x8, #0x14这样的指令,我们需要计算pc+0x14的值,将该值存放于DataBlock中,这个存储的地方就由Constant表示,然后将结果保存在一个临时寄存器中,这个寄存器由Temp表示,而Operand则是针对llvm::MCInst操作数下标的封装,在这个例子中llvm::MCInst有两个操作数,下标分别为0和1,0为x8寄存器, 1为imm,它的值为5。
总结起来步骤如下:
GetPCOffset --> 得到pc+0x14的值写入dataBlock的Shadow区域并且生成ldr指令即ldr x28, [x27, #1248], x27称为ScratchRegister,它指向dataBlock的起始位置,偏移1248即Shadow区域, x28为TempManager分配出来的寄存器。
ModifyInstruction --> 原地修改指令,将原来的ldr x8, #0x14修改为ldr x8, [x28],等同于以下代码:
SaveX28IfSet --> 如果原始指令修改了x28的值那么需要保存x28的值至dataBlock的Context的gprState对应的x28内存中。
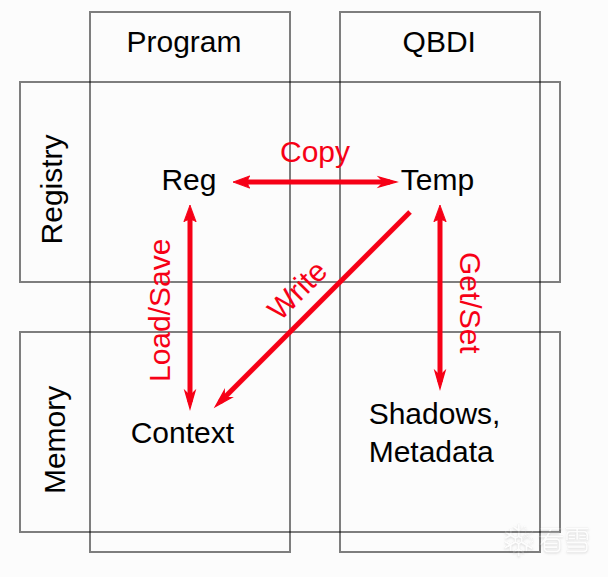
是时候来看一下PatchDSL了,老样子引用一下官方的图:
这张图这样来理解:
Program一列表示guest环境,QBDI表示qbdi环境。
Temp为qbdi所使用的寄存器,由TempManager分配,分配时总是优先使用x28寄存器,原因是这个寄存器靠后,被guest使用的概率比较小有助于提升性能。如果x28被目标指令所使用,TempManage 就会分配其他的通用寄存器做为Temp。上例中Reg = x8, Temp = x28。
Temp寄存器一般需要读写Shadow数据,上例中Shadow数据就是[x27, #1248],它存放于dataBlock。
Reg会需要保存和恢复寄存器数据,那么这些数据就存放在dataBlock的Context结构中。
Temp也可能会直接写dataBlock的Context结构。
是时候考虑一下寄存器保存和恢复的问题了,前面提到过qbdi执行的原则是不修改guest的环境包括栈和寄存器,如果qbdi的patch和instrument代码需要某个寄存器就需要先保存该寄存器至Context,执行完再从Context当中恢复,由于保存和恢复可以基于pc相对寻址来实现,所以这种方式是可行的,这个寄存器我们可以称之为qbdi保存寄存器。相应的也有guest保存寄存器,这个寄存器为x28,TempManager分配出来非x28寄存器都为qbdi保存寄存器,当guest使用到了x28就需要先从Context中恢复该寄存器,而guest中任何写x28的指令最后都会将x28的值写入Context进行保存:
假如guest函数片段从来没有使用到x28(比较常见),那么qbdi使用x28寄存器就无需恢复和保存。
如果guest函数片段有读写x28指令,由于x28是非参数寄存器,qbdi就会假设函数指令肯定会先写x28寄存器 ,这样就触发了x28的保存(上面的SaveX28IfSet::unique()),然后每次使用x28寄存器的时候需要从内存当中恢复该值:
此时Temp寄存器就会选择非x28寄存器,就需要qbdi自己保存和恢复:
选择x28寄存器就是大部分时间无需考虑保存和恢复,性能比较好。
什么是ScratchRegister?
上面我们提到ldr x8, #0x14经过patch变为两条指令:
ldr x28, [x27, #1248]
ldr x8, [x28]
其中的x27叫做ScratchRegister,ScratchRegister的用途是指向dataBlock让PatchDSL中的寄存器可以访问dataBlock, 对于x86和arm32是没有ScratchRegister的,这是因为在这x86和arm32中,pc是作为通用寄存器存在的,比如x86可以这样直接访问dataBlock: movq %rbx, 4330(%rip)
而对于arm64来说pc并不是通用寄存器,想访问dataBlock必须额外分配一个寄存器做为ScratchRegister,因此也必须考虑ScratchRegister的分配和保存问题,这就带来了一些复杂性。
如何分配ScratchRegister?在src/ExecBlock/AARCH64/ExecBlock_AARCH64.cpp文件的以下函数中分配 ScratchRegister
范围是当前需执行的BasicBlock,逻辑是从x0到x28,排除各个Temp所使用到的寄存器,排除原始指令所使用到的寄存器,选择剩余的寄存器下标最大的那个做为ScratchRegister。
对于fibonacci这样的函数来说比较简单,它没有使用x27和x28寄存器,x27就作为ScratchRegister ,而x28作为temp寄存器。ScratchRegister是以basicblock为单位的。
如果所有的寄存器都被使用了怎么办?这个时候就需要分割序列并ScratchRegister ,我们可以使用以下的程序测试:
下面的代码所对应的patch后的指令,主要关注add x0,x0, x27 这条指令:
对于改变了PC的指令也需要patch,如blr x8
这是因为qbdi需要掌控程序的执行流,如果不patch的话跳转到目标函数以后就失去了控制权,来看一下PatchDSL的处理:
BLR Xn: 跳转到Xn寄存器所代表的函数处执行并且将x30(lr)值设为pc+4
对于blr x8,生成的指令为:
来看一下PatchDSL的内容:
GetOperand::unique(Temp(0), Operand(0)) : 将操作数0即x8赋值给Temp寄存器这里是x28,生成的指令为:
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC))) : 将x28的值保存到dataBlock的Context的pc寄存器中,生成的指令为:
SimulateLink::unique(Temp(0)): 将原指令的结束地址(也就是下一条指令地址)写入Constant并赋值给x30寄存器,生成的指令为:ldr x28, [x27, #1112] mov x30, x28
在ExecBlock.cpp的ExecBlock::writeSequence函数中,发现当前指令改变了pc,添加切换回qbdi上下文的指令以接管控制:
生成的指令为:b #3200
这就涉及到上下文的切换以及 序言和尾声的执行。
我们首先来看一下qbdi执行函数的时候准备了什么环境:
分配了一个1M大小虚拟栈将guest的sp指向栈顶,但是虚拟栈也有坏处那就是使用qbdi在安卓系统上调用env函数的时候会遇到StackOverflowError的问题:
https://github.com/QBDI/QBDI/issues/243
这是因为android虚拟机会检查栈指针,具体细节就不在此文章描述了。
然后qbdi会在此栈中准备好函数调用所需的参数,对于arm64来说就是将前8个参数放在r0开始的寄存器中其余参数入栈,并且将Context中的lr寄存器设置为虚拟返回地址42,这样qbdi就可以监控函数的返回。
设置好环境以后qbdi就开始了patch,instrument的操作生成各个ExecBlock,每一块ExecBlock都有序言和尾声片段,序言位于codeBlock起始处,尾声则占据着codeBlock末尾。
序言和尾声部分涉及到存储和保存qbdi和guest上下文,qbdi上下文位于Context.host State结构中 ,guest上下文位于Context. grpState 和Context.frpState结构中。
我们来看一下序言和尾声部分的代码:
序言Prologue:
hint 0x22 --> 是BTI指令的另一种编码形式, 功能上HINT 0x22完全等价于BTI C --> 允许通过 BR 或 BLR 跳转至此。这一步是为了避开开启了BTI安全扩展机制的机器上跳转的限制。这一点可以通过执行echo "BTI C " | llvm-mc --assemble -triple=aarch64 --show-inst得到验证
adrp x28, #4096 -->X28 is used to address the DataBlock(此时仍然处于host上下文,用x28保存datablock基址)
str x30, [sp, #-16]! --> Save return address
mov x0, sp --> Save Host SP
str x0, [x28, #16] --> 保存到Context.host State.sp
add x0, x28, #368 --> Restore SIMD
ld1 { v0.2d, v1.2d, v2.2d, v3.2d }, [x0], #64 --> 加载完成后,X0寄存器的值会自动增加64字节(这是后变址寻址模式)。
ld1 { v4.2d, v5.2d, v6.2d, v7.2d }, [x0], #64
ld1 { v8.2d, v9.2d, v10.2d, v11.2d }, [x0], #64
ld1 { v12.2d, v13.2d, v14.2d, v15.2d }, [x0], #64
ld1 { v16.2d, v17.2d, v18.2d, v19.2d }, [x0], #64
ld1 { v20.2d, v21.2d, v22.2d, v23.2d }, [x0], #64
ld1 { v24.2d, v25.2d, v26.2d, v27.2d }, [x0], #64
ld1 { v28.2d, v29.2d, v30.2d, v31.2d }, [x0], #64
ldp x1, x2, [x0], #16 --> Restore FPCR and FPSR
msr FPCR, x1
msr FPSR, x2
add x0, x28, #72
ldp x1, x2, [x0, #248] --> Restore Stack and NZCV
msr NZCV, x2
mov sp, x1
ldp x29, x30, [x0, #232] --> Restore LR and X29
ldp x26, x27, [x0, #208] --> Load other registers
ldp x24, x25, [x0, #192]
ldp x22, x23, [x0, #176]
ldp x20, x21, [x0, #160]
ldp x18, x19, [x0, #144]
ldp x16, x17, [x0, #128]
ldp x14, x15, [x0, #112]
ldp x12, x13, [x0, #96]
ldp x10, x11, [x0, #80]
ldp x8, x9, [x0, #64]
ldp x6, x7, [x0, #48]
ldp x4, x5, [x0, #32]
ldp x2, x3, [x0, #16]
ldp x0, x1, [x0]
ldr x28, [x28, #24] --> Context.hostState.selector --> Jump selector , 在ExecBlock::selectSeq的函数中赋值
br x28 --> 跳转到对应的selector即基本块运行
函数序言总结起来的动作为:
尾声Epilogue:
adrp x28, #4096 -->利用adrp将x28设置为datablock的起始地址
stp x0, x1, [x28, #72] --> Save GPR from the guest
stp x2, x3, [x28, #88]
stp x4, x5, [x28, #104]
stp x6, x7, [x28, #120]
stp x8, x9, [x28, #136]
stp x10, x11, [x28, #152]
stp x12, x13, [x28, #168]
stp x14, x15, [x28, #184]
stp x16, x17, [x28, #200]
stp x18, x19, [x28, #216]
stp x20, x21, [x28, #232]
stp x22, x23, [x28, #248]
stp x24, x25, [x28, #264]
stp x26, x27, [x28, #280]
stp x29, x30, [x28, #304] --> Save X29 and LR
mrs x1, NZCV --> Save stack and NZCV
mov x0, sp
stp x0, x1, [x28, #320]
add x0, x28, #368 --> set X0 at the beginning of the FPRState
mrs x1, FPCR --> Get FPCR and FPSR
mrs x2, FPSR
st1 { v0.2d, v1.2d, v2.2d, v3.2d }, [x0], #64 --> Save FPR
st1 { v4.2d, v5.2d, v6.2d, v7.2d }, [x0], #64
st1 { v8.2d, v9.2d, v10.2d, v11.2d }, [x0], #64
st1 { v12.2d, v13.2d, v14.2d, v15.2d }, [x0], #64
st1 { v16.2d, v17.2d, v18.2d, v19.2d }, [x0], #64
st1 { v20.2d, v21.2d, v22.2d, v23.2d }, [x0], #64
st1 { v24.2d, v25.2d, v26.2d, v27.2d }, [x0], #64
st1 { v28.2d, v29.2d, v30.2d, v31.2d }, [x0], #64
stp x1, x2, [x0] --> Set FPCR and FPSR
ldr x0, [x28, #16] --> Restore Host SP
mov sp, x0
ldr x30, [sp], #16 --> Return to host
ret
函数尾声总结起来的动作为:
我们来看一下执行流程:
Engine会一直执行直到currentPC是虚构地址42,执行序言代码以后会跳转到其中的patch代码执行,只要遇到修改了pc的指令像上面的blr x8,就会给GPRState的REG_PC赋值为x8,并且跳转回尾声部分切换回qbdi上下文,此时会得到新的目标地址: currentPC = QBDI_GPR_GET(curGPRState, REG_PC); Engine::run函数的循环中会判断这个地址是否在trace的范围内,如果不在则交由ExecBroker,如果在那么需要处理目标地址指令,接着跳转至该地址执行。
因此结论是: 在遇到修改pc指令的代码时,我们需要patch该指令,将目标地址值写入Context.grpState.pc并且跳转到尾声部分让qbdi重新接管控制。
instrument是因为我们添加了trace回调,如:
instrument代码也是由PatchDSL生成,我们先看一下经过instrument以后指令是什么样:
ldr x28, [x27, #896]
str x28, [x27, #32]
mov x28, #0
str x28, [x27, #40]
mov x28, #0
str x28, [x27, #48]
ldr x28, [x27, #904]
str x28, [x27, #336]
adr x28, #12
str x28, [x27, #24]
b #3764
sub sp, sp, #32 // =32 ----> 这一条为原始指令
它的含义为:
执行完第11指令b #3764以后流程会回到VMAction ExecBlock::execute()函数:
执行完代码跟踪回调以后重新进入run()函数,从而进入到序言部分,跳转至Context.hostState.selector处执行,即原始指令sub sp, sp, #32处。
如果遇到不在trace范围内的指令,会交由ExecBroker并将控制权递交出去,这样我们就不用trace已知或者不感兴趣的逻辑,提升效率。
测试函数:
来看一下遇到printf函数时qbdi的行为
在执行Engine::run函数的时候会有所不同,进入到分支:
ExecBroker会生成一个ExecBlock用于控制转移它叫
它的序言部分后面还有一些指令,紧跟在上面38行的序言br x28后面,有两种类型分别是transfertLR和transfertX28
transfertLR:
上面生成的指令使用lr寄存器做为跳转中转寄存器,我们知道如果是在trace范围内的代码段,执行的是已定义好的规则: x28寄存器交由guest保存恢复,现在要将控制权转交出去那么就要将所有通用寄存器的值恢复到guest状态包括x28和x27( scratchRegister)
那么上面指令做的就是两步:
执行前恢复x28和 x27( scratchRegister)的值
执行后保存x27, x28,重新将x27置为scratchRegister
可以看到这两条指令在不引入其他寄存器修改的前提下恢复x28和 scratchRegisterValue x27:
scratchRegister x27做为literal pool datablock的起始地址,这样x28才能保存到该地址,为了不引入其他通用寄存器,qbdi选择了线程指针寄存器TPIDR_EL0做为中转寄存器,当然这个寄存器也需要先保存、使用、再恢复,这里的假设就是转移过去执行的函数(这里是printf)不会用到TPIDR_EL0寄存器。
transfertX28:
当明确不需要恢复x28寄存器时将会使用上面的指令,x28就代替了TPIDR_EL0做为中转寄存器,所以指令会简单很多:
执行前恢复x27( scratchRegister)的值
执行后保存x27重新将x27置为 scratchRegister
执行的是transfertLR还是transfertX28是通过检测Context.gprState->lr是否在trace范围来决定的,正常情况下bl、blr跳转的函数选择的肯定是transfertLR,但如果在函数里边更改了lr(非正常函数),在trace的时候如果用ExecBroker跳过该函数可能会有问题,不过一般跳过的函数都是正常的库函数不太会出现问题。这种情况我也没有具体写函数测试,但是我们应该注意到ExecBroker的实现可能会有缺陷。
ExecBlockManager还需要处理一些边界条件,比如如果往ExecBlock中写,剩下空间只能写一部分的指令怎么办?如何实现缓存机制提升效率?这部分内容也比较复杂但是和核心原理关系不大,这里就不描述了。
只要知道涉及到的基本结构为:
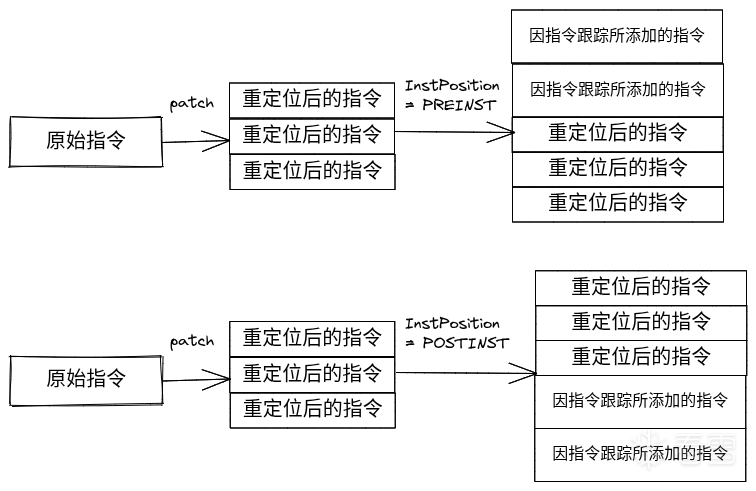
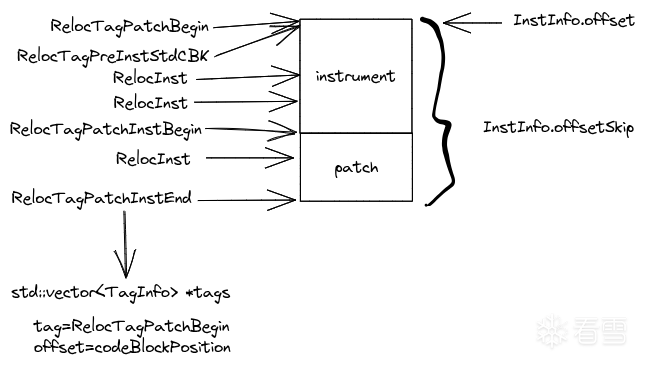
以及qbdi会对指令位置设置标签,这些标签有助于在回调函数中定位到指令的相关信息,如下图:
传播安全知识、拓宽行业人脉——看雪讲师团队等你加入!
最后于 2026-2-7 09:29
被飞翔的猫咪编辑
,原因: