-
-
[原创]KCTF2025 day8 wp
-
发表于: 2025-8-31 11:00 8190
-
程序实现了一个虚拟机, 有自己的栈和内存区, 虚拟机的内存段被固定映射到0x200000, 代码区被随机映射:
相关结构体:
写个脚本导出函数让AI分析各个操作码对应的操作(我到底什么时候能用上MCP啊):
同时拷打AI写出汇编工具:
程序中所有涉及到数组的操作都对下标进行了检验, 有关下标唯一的漏洞我只在push_imm里找到一个, 在栈指针自增后是先进行赋值再检验下标的, 可以越界访问1个qword, 但是我不知道有什么用.
另外程序还对地址值有检验, 要通过vm来执行类似mov [r0], r1的操作时会对r0检验其最高位是否置1, 这是vm对有效地址打的tag, 同时通过运算得出的地址(通过是否带tag来判断)会检测其是否在vm的栈和内存段的合法区域, 不在的话会强制转化为内存段的初始位置.
而在限制运算得到地址这一点上程序对寄存器之间的运算和寄存器与立即数之间的运算是不同的, 以乘法为例:
寄存器之间的运算只会在运算前寄存器本身就是带tag的地址值才会进行检测, 而和立即数的运算会在运算完后检测算出的结果是否为地址值并检测合法性.
另外一点就出在check_addr上:
本来只需要检验地址是否落在固定映射的mem上就好了, stack本身是随机映射的, 用户不应该能得到其地址值.
综合以上两点可以通过爆破的方式得到stack被映射到的地址, 伪代码如下:
调试可以发现vm栈段被映射到的地址低12位是320h:
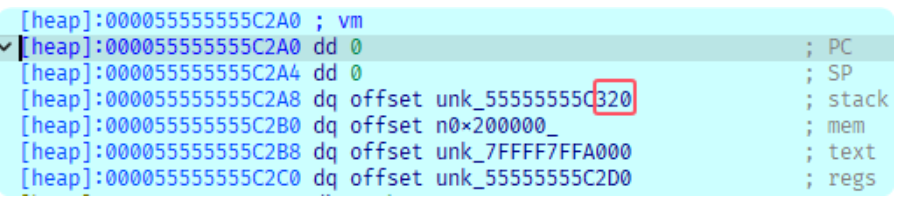
最高1字节就选定为0x55, 只需要爆破中间56位即可, bytecode如下:
上面说过寄存器和立即数的运算会导致检测地址, 所以这里存起来的实际上是(TAG | addr) >> 1, 在要算出地址时与存放了2的r4做乘法即可得到带tag地址且不会被检测, 这一步在本机上的爆破时间不超过5秒, 但是靶机很可能程序给的100秒alarm都不够用, 要多尝试几次, 至此我们获得了任意已知地址读写的能力.
在得到了一个堆地址后就好办很多了, 注意到开头push了两次吗? 现在只需要将堆上vm代码段的地址放入vm的栈基址中, 再进行一次pop操作就能将一个mmap出的地址送入寄存器中, 而mmap出的地址与ld间有固定偏移:

而ld中存放了大量libc中的地址:
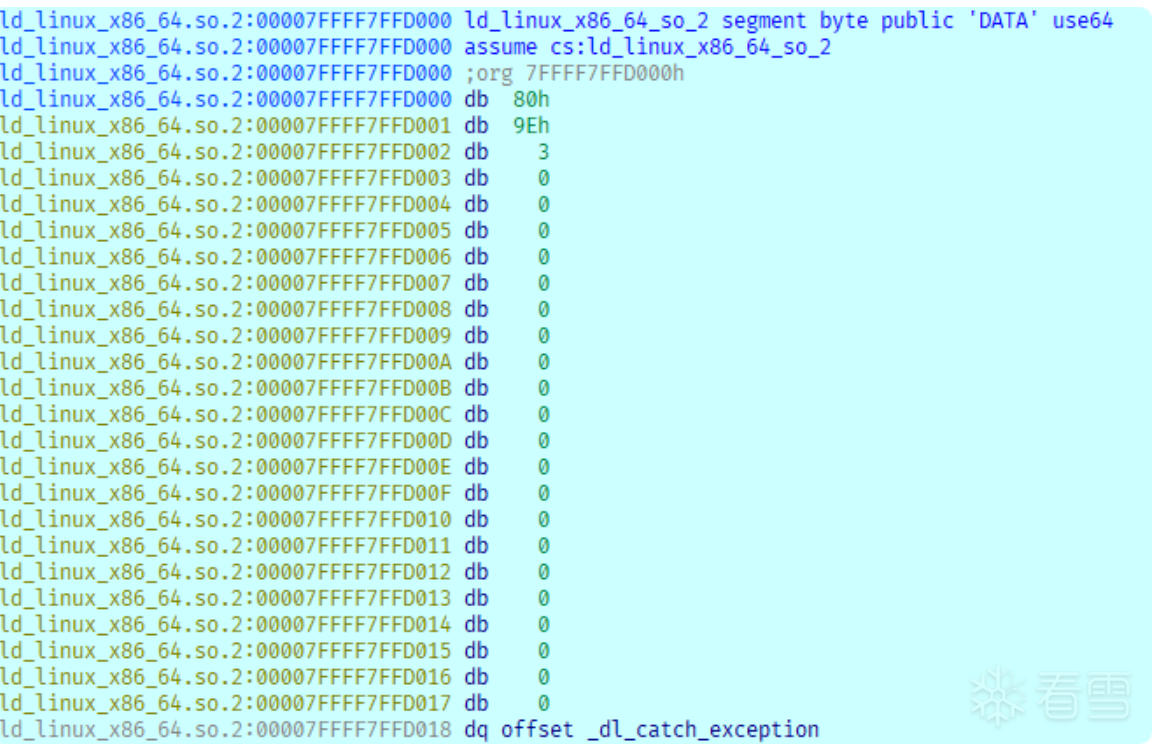
这里就选择这个_dl_catch_exception, 它与mem段的偏移为0x3018, 这一步的bytecode:
程序开启了got表保护, 不用思考改got来getshell了, 我的想法是通过libc中的environ泄露栈地址来修改函数返回地址写入ROP链, 这一步的bytecode:
接下来就没什么好说的了, 写入返回到system('/bin/sh')的ROP链, 这里直接返回上去栈会不对齐, 要多放一个ret
vm *do_malloc(){ vm *vm; // rbx vm *vm_1; // rbx vm *vm_2; // rbx vm *vm_3; // rbx vm *vm_4; // rax alarm(0x64u); vm = (vm *)zalloc(0x28u); vm->PC = 0; vm = vm; vm->text = zmmap(0, 0x1000u); vm_1 = vm; vm_1->mem = zmmap((void *)0x200000, 0x1000u); vm_2 = vm; vm_2->regs = zalloc(0x40u); vm_3 = vm; vm_3->stack = zalloc(0x800u); vm_4 = vm; vm->SP = 0; return vm_4;}vm *do_malloc(){ vm *vm; // rbx vm *vm_1; // rbx vm *vm_2; // rbx vm *vm_3; // rbx vm *vm_4; // rax alarm(0x64u); vm = (vm *)zalloc(0x28u); vm->PC = 0; vm = vm; vm->text = zmmap(0, 0x1000u); vm_1 = vm; vm_1->mem = zmmap((void *)0x200000, 0x1000u); vm_2 = vm; vm_2->regs = zalloc(0x40u); vm_3 = vm; vm_3->stack = zalloc(0x800u); vm_4 = vm; vm->SP = 0; return vm_4;}struct vm{ _DWORD PC; _DWORD SP; _BYTE *stack; _BYTE *mem; _BYTE *text; _QWORD *regs;};struct vm{ _DWORD PC; _DWORD SP; _BYTE *stack; _BYTE *mem; _BYTE *text; _QWORD *regs;};import ida_funcs, ida_hexraysstart = 0x0000000000001314end = 0x0000000000002A64func = set()while start <= end: f = ida_funcs.get_func(start) if f and f.start_ea not in func: func.add(f.start_ea) with open('funcs.txt', 'a') as file: file.write(ida_hexrays.decompile(f).__str__() + '\n') start += 1import ida_funcs, ida_hexraysstart = 0x0000000000001314end = 0x0000000000002A64func = set()while start <= end: f = ida_funcs.get_func(start) if f and f.start_ea not in func: func.add(f.start_ea) with open('funcs.txt', 'a') as file: file.write(ida_hexrays.decompile(f).__str__() + '\n') start += 1| Opcode | 原函数 | 作用 | 建议命名 |
|---|---|---|---|
| 0x00 | sub_1314 | 从寄存器 chunk4[rN] 压栈 | op_push_reg |
| 0x01 | sub_13AA | 压常数到栈 | op_push_imm |
| 0x02 | sub_141B | 压常数地址解引用的值到栈 | op_push_mem |
| 0x03 | sub_1494 | 栈顶弹出 → 存到寄存器 rN | op_pop_reg |
| 0x04 | sub_1532 | r[dst] = r[src](寄存器间拷贝) | op_mov_reg_reg |
| 0x05 | sub_15AC | r[dst] = imm(立即数写寄存器) | op_mov_reg_imm |
| 0x06 | sub_1600 | r[dst] = r[dst] + r[src](带溢出检查) | op_add_reg_reg |
| 0x07 | sub_1787 | r[dst] += imm | op_add_reg_imm |
| 0x08 | sub_1864 | r[dst] = r[dst] - r[src] | op_sub_reg_reg |
| 0x09 | sub_19EB | r[dst] -= imm | op_sub_reg_imm |
| 0x0A | sub_1AC8 | r[dst] *= r[src] | op_mul_reg_reg |
| 0x0B | sub_1C53 | r[dst] *= imm | op_mul_reg_imm |
| 0x0C | sub_1D34 | r[dst] /= r[src] | op_div_reg_reg |
| 0x0D | sub_1EC0 | r[dst] /= imm | op_div_reg_imm |
| 0x0E | sub_1FA2 | r[dst] &= r[src] | op_and_reg_reg |
| 0x0F | sub_2129 | r[dst] &= imm | op_and_reg_imm |
| 0x10 | sub_2206 | r[dst] |= r[src] | op_or_reg_reg |
| 0x11 | sub_238D | r[dst] |= imm | op_or_reg_imm |
| 0x12 | sub_246A | r[dst] ^= r[src] | op_xor_reg_reg |
| 0x13 | sub_25F1 | r[dst] ^= imm | op_xor_reg_imm |
| 0x14 | sub_26CE | r[dst] = *r[src](寄存器作为指针解引用 load) | op_load_mem |
| 0x15 | sub_2782 | *r[addr] = r[value](store) | op_store_mem |
| 0x16 | sub_2831 | if (r[a] > r[b]) pc += imm(条件跳转) | op_jmp_gt |
| 0x17 | sub_28ED | if (r[a] < r[b]) pc += imm | op_jmp_lt |
| 0x18 | sub_29A9 | if (r[a] == r[b]) pc += imm | op_jmp_eq |
| 0x19 | - | 结束程序 | op_halt |
# asmbuilder.py# Tiny bytecode builder for the 8-byte-per-instruction VM.import structfrom typing import Dict, List, Tuple, Union# --- Registers (VM 里 min(..., 8u),保守支持 0..8) ---R0, R1, R2, R3, R4, R5, R6, R7, R8 = range(9)def _clamp_reg(r: int) -> int: if r < 0: return 0 if r > 8: return 8 return rdef _ins(op: int, b1: int = 0, b2: int = 0, imm: int = 0) -> bytes: """ 通用编码器:|op|b1|b2|pad0|imm32_le| """ return bytes([op & 0xFF, _clamp_reg(b1) & 0xFF, _clamp_reg(b2) & 0xFF, 0]) + struct.pack("<I", imm & 0xFFFFFFFF)# --- Stack / register moves ---def push_reg(src_reg: int) -> bytes: # opcode 0x00: 从寄存器压栈(读 +2) :contentReference[oaicite:3]{index=3} return _ins(0x00, 0, src_reg, 0)def push(imm: int) -> bytes: # opcode 0x01: 压 32 位立即数(读 +4) :contentReference[oaicite:4]{index=4} return _ins(0x01, 0, 0, imm)def push_ptr(addr32: int) -> bytes: # opcode 0x02: 压“指针”风味立即数(执行期做 tag/转换) :contentReference[oaicite:5]{index=5} return _ins(0x02, 0, 0, addr32)def pop_reg(dst_reg: int) -> bytes: # opcode 0x03: 栈顶弹出到寄存器(写 +1) :contentReference[oaicite:6]{index=6} return _ins(0x03, dst_reg, 0, 0)def mov_reg_reg(dst_reg: int, src_reg: int) -> bytes: # opcode 0x04: r[dst]=r[src](读 +1/+2) :contentReference[oaicite:7]{index=7} return _ins(0x04, dst_reg, src_reg, 0)def mov_reg_imm(dst_reg: int, imm: int) -> bytes: # opcode 0x05: r[dst]=imm(读 +1,+4) :contentReference[oaicite:8]{index=8} return _ins(0x05, dst_reg, 0, imm)# --- ALU (reg/reg & reg/imm) ---def add_reg_reg(dst: int, src: int) -> bytes: # 0x06 :contentReference[oaicite:9]{index=9} return _ins(0x06, dst, src, 0)def add_reg_imm(dst: int, imm: int) -> bytes: # 0x07 :contentReference[oaicite:10]{index=10} return _ins(0x07, dst, 0, imm)def sub_reg_reg(dst: int, src: int) -> bytes: # 0x08 :contentReference[oaicite:11]{index=11} return _ins(0x08, dst, src, 0)def sub_reg_imm(dst: int, imm: int) -> bytes: # 0x09 :contentReference[oaicite:12]{index=12} return _ins(0x09, dst, 0, imm)def mul_reg_reg(dst: int, src: int) -> bytes: # 0x0A :contentReference[oaicite:13]{index=13} return _ins(0x0A, dst, src, 0)def mul_reg_imm(dst: int, imm: int) -> bytes: # 0x0B :contentReference[oaicite:14]{index=14} return _ins(0x0B, dst, 0, imm)def div_reg_reg(dst: int, src: int) -> bytes: # 0x0C :contentReference[oaicite:15]{index=15} return _ins(0x0C, dst, src, 0)def div_reg_imm(dst: int, imm: int) -> bytes: # 0x0D :contentReference[oaicite:16]{index=16} return _ins(0x0D, dst, 0, imm)# --- Bitwise ---def and_reg_reg(dst: int, src: int) -> bytes: # 0x0E :contentReference[oaicite:17]{index=17} return _ins(0x0E, dst, src, 0)def and_reg_imm(dst: int, imm: int) -> bytes: # 0x0F :contentReference[oaicite:18]{index=18} return _ins(0x0F, dst, 0, imm)def or_reg_reg(dst: int, src: int) -> bytes: # 0x10 :contentReference[oaicite:19]{index=19} return _ins(0x10, dst, src, 0)def or_reg_imm(dst: int, imm: int) -> bytes: # 0x11 :contentReference[oaicite:20]{index=20} return _ins(0x11, dst, 0, imm)def xor_reg_reg(dst: int, src: int) -> bytes: # 0x12 :contentReference[oaicite:21]{index=21} return _ins(0x12, dst, src, 0)def xor_reg_imm(dst: int, imm: int) -> bytes: # 0x13 :contentReference[oaicite:22]{index=22} return _ins(0x13, dst, 0, imm)# --- Memory ---def load_mem(dst_reg: int, src_ptr_reg: int) -> bytes: # 0x14: r[dst]=*r[src_ptr](读 +1/+2) :contentReference[oaicite:23]{index=23} return _ins(0x14, dst_reg, src_ptr_reg, 0)def store_mem(addr_reg: int, value_reg: int) -> bytes: # 0x15: *r[addr]=r[value](读 +1/+2) :contentReference[oaicite:24]{index=24} return _ins(0x15, addr_reg, value_reg, 0)# --- Control flow (PC 从下一条起算 += imm32;自然语义只支持向前偏移) ---def jmp_gt(ra: int, rb: int, delta: int) -> bytes: # 0x16 :contentReference[oaicite:25]{index=25} return _ins(0x16, ra, rb, delta)def jmp_lt(ra: int, rb: int, delta: int) -> bytes: # 0x17 :contentReference[oaicite:26]{index=26} return _ins(0x17, ra, rb, delta)def jmp_eq(ra: int, rb: int, delta: int) -> bytes: # 0x18 :contentReference[oaicite:27]{index=27} return _ins(0x18, ra, rb, delta)def halt() -> bytes: # 0x19 return _ins(0x19, 0, 0, 0)# --------------------------------------------------------------------# Label-aware builder (可选):支持 jmp_* 到标签名,会在 finalize() 时求偏移# --------------------------------------------------------------------JumpSpec = Tuple[int, int, int, str] # (opcode, ra, rb, label)class ProgramBuilder: def __init__(self): self.buf = bytearray() self.labels: Dict[str, int] = {} self.fixups: List[Tuple[int, JumpSpec]] = [] # (ins_index, spec) def pc(self) -> int: """返回当前指令号(每条 8 字节)。""" return len(self.buf) // 8 def emit(self, ins: bytes) -> "ProgramBuilder": assert isinstance(ins, (bytes, bytearray)) and len(ins) == 8 self.buf += ins return self def label(self, name: str) -> "ProgramBuilder": self.labels[name] = self.pc() return self # 绑定标签的跳转(偏移从下一条起算:delta = label_idx - (ins_idx + 1)) def jmp_gt(self, ra: int, rb: int, target: Union[int, str]) -> "ProgramBuilder": return self._jmp_op(0x16, ra, rb, target) def jmp_lt(self, ra: int, rb: int, target: Union[int, str]) -> "ProgramBuilder": return self._jmp_op(0x17, ra, rb, target) def jmp_eq(self, ra: int, rb: int, target: Union[int, str]) -> "ProgramBuilder": return self._jmp_op(0x18, ra, rb, target) def _jmp_op(self, op: int, ra: int, rb: int, target: Union[int, str]) -> "ProgramBuilder": ins_idx = self.pc() if isinstance(target, int): self.emit(_ins(op, ra, rb, target)) else: # 先放占位 0,记录修正信息 self.emit(_ins(op, ra, rb, 0)) self.fixups.append((ins_idx, (op, ra, rb, target))) return self def finalize(self) -> bytes: # 回填标签跳转偏移 for ins_idx, (_, ra, rb, label) in self.fixups: if label not in self.labels: raise KeyError(f"Undefined label: {label}") label_idx = self.labels[label] delta = label_idx - (ins_idx + 1) # 从“下一条”起算 :contentReference[oaicite:28]{index=28} # 写回 imm32(小端) pos = ins_idx * 8 + 4 self.buf[pos:pos + 4] = struct.pack("<I", delta & 0xFFFFFFFF) self.fixups.clear() return bytes(self.buf)# --- 简短别名,方便直接拼接 ---# 例如:bytecode = b""; bytecode += push(123); bytecode += pop_reg(R0); bytecode += halt()# asmbuilder.py# Tiny bytecode builder for the 8-byte-per-instruction VM.import structfrom typing import Dict, List, Tuple, Union# --- Registers (VM 里 min(..., 8u),保守支持 0..8) ---R0, R1, R2, R3, R4, R5, R6, R7, R8 = range(9)def _clamp_reg(r: int) -> int: if r < 0: return 0 if r > 8: return 8 return rdef _ins(op: int, b1: int = 0, b2: int = 0, imm: int = 0) -> bytes: """ 通用编码器:|op|b1|b2|pad0|imm32_le| """ return bytes([op & 0xFF, _clamp_reg(b1) & 0xFF, _clamp_reg(b2) & 0xFF, 0]) + struct.pack("<I", imm & 0xFFFFFFFF)# --- Stack / register moves ---def push_reg(src_reg: int) -> bytes: # opcode 0x00: 从寄存器压栈(读 +2) :contentReference[oaicite:3]{index=3} return _ins(0x00, 0, src_reg, 0)def push(imm: int) -> bytes: # opcode 0x01: 压 32 位立即数(读 +4) :contentReference[oaicite:4]{index=4} return _ins(0x01, 0, 0, imm)def push_ptr(addr32: int) -> bytes: # opcode 0x02: 压“指针”风味立即数(执行期做 tag/转换) :contentReference[oaicite:5]{index=5} return _ins(0x02, 0, 0, addr32)def pop_reg(dst_reg: int) -> bytes: # opcode 0x03: 栈顶弹出到寄存器(写 +1) :contentReference[oaicite:6]{index=6} return _ins(0x03, dst_reg, 0, 0)def mov_reg_reg(dst_reg: int, src_reg: int) -> bytes: # opcode 0x04: r[dst]=r[src](读 +1/+2) :contentReference[oaicite:7]{index=7} return _ins(0x04, dst_reg, src_reg, 0)def mov_reg_imm(dst_reg: int, imm: int) -> bytes: # opcode 0x05: r[dst]=imm(读 +1,+4) :contentReference[oaicite:8]{index=8} return _ins(0x05, dst_reg, 0, imm)# --- ALU (reg/reg & reg/imm) ---def add_reg_reg(dst: int, src: int) -> bytes: # 0x06 :contentReference[oaicite:9]{index=9} return _ins(0x06, dst, src, 0)def add_reg_imm(dst: int, imm: int) -> bytes: # 0x07 :contentReference[oaicite:10]{index=10} return _ins(0x07, dst, 0, imm)def sub_reg_reg(dst: int, src: int) -> bytes: # 0x08 :contentReference[oaicite:11]{index=11} return _ins(0x08, dst, src, 0)def sub_reg_imm(dst: int, imm: int) -> bytes: # 0x09 :contentReference[oaicite:12]{index=12} return _ins(0x09, dst, 0, imm)def mul_reg_reg(dst: int, src: int) -> bytes: # 0x0A :contentReference[oaicite:13]{index=13} return _ins(0x0A, dst, src, 0)def mul_reg_imm(dst: int, imm: int) -> bytes: # 0x0B :contentReference[oaicite:14]{index=14} return _ins(0x0B, dst, 0, imm)def div_reg_reg(dst: int, src: int) -> bytes: # 0x0C :contentReference[oaicite:15]{index=15} return _ins(0x0C, dst, src, 0)def div_reg_imm(dst: int, imm: int) -> bytes: # 0x0D :contentReference[oaicite:16]{index=16} return _ins(0x0D, dst, 0, imm)# --- Bitwise ---def and_reg_reg(dst: int, src: int) -> bytes: # 0x0E :contentReference[oaicite:17]{index=17} return _ins(0x0E, dst, src, 0)def and_reg_imm(dst: int, imm: int) -> bytes: # 0x0F :contentReference[oaicite:18]{index=18} return _ins(0x0F, dst, 0, imm)def or_reg_reg(dst: int, src: int) -> bytes: # 0x10 :contentReference[oaicite:19]{index=19} return _ins(0x10, dst, src, 0)def or_reg_imm(dst: int, imm: int) -> bytes: # 0x11 :contentReference[oaicite:20]{index=20} return _ins(0x11, dst, 0, imm)def xor_reg_reg(dst: int, src: int) -> bytes: # 0x12 :contentReference[oaicite:21]{index=21} return _ins(0x12, dst, src, 0)def xor_reg_imm(dst: int, imm: int) -> bytes: # 0x13 :contentReference[oaicite:22]{index=22} return _ins(0x13, dst, 0, imm)# --- Memory ---def load_mem(dst_reg: int, src_ptr_reg: int) -> bytes: # 0x14: r[dst]=*r[src_ptr](读 +1/+2) :contentReference[oaicite:23]{index=23} return _ins(0x14, dst_reg, src_ptr_reg, 0)def store_mem(addr_reg: int, value_reg: int) -> bytes: # 0x15: *r[addr]=r[value](读 +1/+2) :contentReference[oaicite:24]{index=24} return _ins(0x15, addr_reg, value_reg, 0)# --- Control flow (PC 从下一条起算 += imm32;自然语义只支持向前偏移) ---def jmp_gt(ra: int, rb: int, delta: int) -> bytes: # 0x16 :contentReference[oaicite:25]{index=25} return _ins(0x16, ra, rb, delta)def jmp_lt(ra: int, rb: int, delta: int) -> bytes: # 0x17 :contentReference[oaicite:26]{index=26} return _ins(0x17, ra, rb, delta)def jmp_eq(ra: int, rb: int, delta: int) -> bytes: # 0x18 :contentReference[oaicite:27]{index=27} return _ins(0x18, ra, rb, delta)def halt() -> bytes: # 0x19 return _ins(0x19, 0, 0, 0)# --------------------------------------------------------------------# Label-aware builder (可选):支持 jmp_* 到标签名,会在 finalize() 时求偏移# --------------------------------------------------------------------JumpSpec = Tuple[int, int, int, str] # (opcode, ra, rb, label)class ProgramBuilder: def __init__(self): self.buf = bytearray() self.labels: Dict[str, int] = {} self.fixups: List[Tuple[int, JumpSpec]] = [] # (ins_index, spec) def pc(self) -> int: """返回当前指令号(每条 8 字节)。""" return len(self.buf) // 8 def emit(self, ins: bytes) -> "ProgramBuilder": assert isinstance(ins, (bytes, bytearray)) and len(ins) == 8 self.buf += ins return self def label(self, name: str) -> "ProgramBuilder": self.labels[name] = self.pc() return self # 绑定标签的跳转(偏移从下一条起算:delta = label_idx - (ins_idx + 1)) def jmp_gt(self, ra: int, rb: int, target: Union[int, str]) -> "ProgramBuilder": return self._jmp_op(0x16, ra, rb, target) def jmp_lt(self, ra: int, rb: int, target: Union[int, str]) -> "ProgramBuilder": return self._jmp_op(0x17, ra, rb, target) def jmp_eq(self, ra: int, rb: int, target: Union[int, str]) -> "ProgramBuilder": return self._jmp_op(0x18, ra, rb, target) def _jmp_op(self, op: int, ra: int, rb: int, target: Union[int, str]) -> "ProgramBuilder": ins_idx = self.pc() if isinstance(target, int): self.emit(_ins(op, ra, rb, target)) else: # 先放占位 0,记录修正信息 self.emit(_ins(op, ra, rb, 0)) self.fixups.append((ins_idx, (op, ra, rb, target))) return self def finalize(self) -> bytes: # 回填标签跳转偏移 for ins_idx, (_, ra, rb, label) in self.fixups: if label not in self.labels: raise KeyError(f"Undefined label: {label}") label_idx = self.labels[label] delta = label_idx - (ins_idx + 1) # 从“下一条”起算 :contentReference[oaicite:28]{index=28} # 写回 imm32(小端) pos = ins_idx * 8 + 4 self.buf[pos:pos + 4] = struct.pack("<I", delta & 0xFFFFFFFF) self.fixups.clear() return bytes(self.buf)# --- 简短别名,方便直接拼接 ---# 例如:bytecode = b""; bytecode += push(123); bytecode += pop_reg(R0); bytecode += halt()unsigned __int64 __fastcall mul_reg_reg(__int64 a1){ unsigned __int64 result; // rax _QWORD *v2; // rbx unsigned __int8 v3; // [rsp+14h] [rbp-Ch] char v4; // [rsp+15h] [rbp-Bh] unsigned __int8 v5; // [rsp+16h] [rbp-Ah] char v6; // [rsp+17h] [rbp-9h] v3 = min(*(unsigned __int8 *)(a1 + 1), 8u); v4 = isaddr(vm->regs[v3]); v5 = min(*(unsigned __int8 *)(a1 + 2), 8u); v6 = isaddr(vm->regs[v5]); result = vm->regs[v5] * vm->regs[v3]; vm->regs[v3] = result; if ( v4 || v6 ) { if ( v4 && v6 ) { result = (unsigned __int64)&vm->regs[v3]; *(_QWORD *)result &= ~0x8000000000000000LL; } else { v2 = &vm->regs[v3]; result = check_addr(*v2 & 0x7FFFFFFFFFFFFFFFLL); *v2 = result; } } return result;}unsigned __int64 __fastcall mul_reg_imm(__int64 a1){ unsigned __int64 result; // rax _QWORD *v2; // rbx unsigned __int8 v3; // [rsp+17h] [rbp-9h] v3 = min(*(unsigned __int8 *)(a1 + 1), 8u); vm->regs[v3] *= *(unsigned int *)(a1 + 4); result = isaddr(vm->regs[v3]); if ( (_BYTE)result ) { v2 = &vm->regs[v3]; result = check_addr(*v2 & 0x7FFFFFFFFFFFFFFFLL); *v2 = result; } return result;}unsigned __int64 __fastcall mul_reg_reg(__int64 a1){ unsigned __int64 result; // rax _QWORD *v2; // rbx unsigned __int8 v3; // [rsp+14h] [rbp-Ch] char v4; // [rsp+15h] [rbp-Bh] unsigned __int8 v5; // [rsp+16h] [rbp-Ah] char v6; // [rsp+17h] [rbp-9h] v3 = min(*(unsigned __int8 *)(a1 + 1), 8u); v4 = isaddr(vm->regs[v3]); v5 = min(*(unsigned __int8 *)(a1 + 2), 8u); v6 = isaddr(vm->regs[v5]); result = vm->regs[v5] * vm->regs[v3]; vm->regs[v3] = result; if ( v4 || v6 )[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|

- [原创]KCTF2025 day10 wp 1223
- [原创]KCTF2025 day9 wp 8604
- [原创]KCTF2025 day8 wp 8190
- [原创]KCTF2025 day7 wp 7013
- [原创]KCTF2025 day6 wp 7138



