-
-
[原创]以实现方式透彻理解 Linux 物理内存模型及管理(附源码)
-
发表于: 2025-8-12 16:06 7229
-
E-mail: 3350124@qq.com
本篇笔记的文字内容和代码在多年前就已成型,今年才有时间对它进行修改和整理。
在整理过程中,根据近几年内核的变化,增加了一些新的场景。
这些变化提供了一些新的 “条件”。例如,半虚拟化场景下的 Guest first,削弱了Host OS 上的监管能力。还有基于virtio的 virtiofs DAX 在存储栈上的革新,它们在原有的机制上不断“解构”并重组,打破了固有的边界,为了性能不惜一杆子捅到底,在我看来,这些都是可利用的“机会”。功利的说,深入了解某些机制,就能理解不同场景下的trade-off。这里面有性能与吞吐率的权衡,也有对上层支持的权衡,理解这些有助于我们找到新的突破点。
这篇笔记没有统一风格,分段随意,没有严格的章法,段落间也少有文字衔接和过渡。但对于想学习又不了解相关机制的人来说,它的好处是足够的干。对某些概念的解读我不做硬件手册和内核源码的复读机,而是结合场景,给出自己的观点;实现层面,有手搓代码和调试器佐证。
我会尽力做到不含糊其词,不模棱两可。对于我认为在上下文中不重要的概念,会一带而过;对于我认为重要的,则会反复说明并适当举例。我无法做到既“概括”又“精准”的描述,所以会有些口语化的表达,目的只有一个:把事情说清楚。
就我个人而言,仅仅依赖阅读源码或此类文章,极易陷入一种“自以为懂了”的错觉。真正的理解,在于主动地构建和验证。我个人学习内核知识的路径,往往经历这样三个阶段:
阶段一:以为自己明白了,其实没明白。 对诸多概念的理解是片面、模糊甚至错误的。
阶段二:以为自己明白了,其实也明白了,但是让我脱离内核环境和既有数据结构,在自己的场景下从零实现一遍,却发现还是无从下手。 比如,给你一段物理内存,如何组织、映射、分配、回收呢?
阶段三:真正地明白了。 不仅掌握了理论,同时能根据不同场景,独立实现一套物理内存模型,并在其上实现一套物理内存的分配回收算法,将细节与全局贯穿,彻底理解内核迭代过程中所遇到的问题和解决问题的思路。
本笔记旨在记录从阶段二到阶段三的过程。从一个 LKM开始,配合应用层仿照现有内核构建一套适用于某些场景的memory model,并在其上实现一个 Buddy system。通过手搓代码从无到有的构建,同时以调试的方式展现运行中的细节。
概念讨论:
这里需要先讨论一些概念,但不会就概念本身和名词进行阐述,因为相关文档已又很多。放在这里讨论的概念,有些与本篇笔记强相关,有些则间接相关。笔记中提及概念有些是 AI 的描述,我认为有问题的,有些是网上看到的文章,同样我认为不妥的,都一并放在这里了。概念与名词的应用目的是解决问题而不是制造悬念,所以就本篇笔记的上下文而言,我并没有过多的修饰与强调。如果认为有疑义的地方请先参考这里,确保咱们是在同一语境下进行讨论。比如当我提到 “物理内存”和 “DRAM” 的时候我的上下文是那些实际意义上的物理存在的内存条,而不是要讨论出诸如还有很多其它可用于扩展物理内存的方式,也不是要强调 “内存条”的 DDRn DIMM 属性和种类;更不是在讨论 Col/Row 和 Channel 等概念,同样的当我提到 Root Complex、设备内存以及总线相关概念的时候,它不会要扩展到x86 arch 下的 Ring bus等概念。从软件(内核)角度来看特指DRAM的“物理内存”它也叫做 system RAM。后续当我提到SPARSEMEM MODEL中的struct page只会指向System RAM的page frame时,或者说某个mem_section因为对应的是设备内存而没有struct page时,我的这个描述就是在固化规场景。也就是说我没有在讨论 GPU、NVDIMM 或是半虚拟化环境下诸如virtiofs DAX这类场景,在这些场景中设备内存也会被分配 struct page。这些struct page同样会在相应的mem_section中占据位置,并且可以通过 pfn_to_page / page_to_pfn 进行转换。内核这样做,其核心目的是为了对上层 API 保持语义的统一和透明,比如让 GUP API能够处理设备内存。但是,这类struct page与本篇讨论的struct page有着本质的不同,您可以把它看作为 device page frame 的 metadata 结构体。它们通常由devres子系统来辅助分配,由各自的设备驱动程序自己管理,并且会被标记上PG_devmap属性,归属于一个特殊的ZONE_DEVICE区域。最重要的是,它们永远不会被加入到内核的 Buddy System 中进行分配,也不会参与 LRU 页面回收。这类场景话题涉及到的 P2P DMA、GPU Direct RDMA 等机制,根本就不在本笔记讨论范围之内。因此,在本篇笔记的后续所有讨论中,我所说的struct page和page frame,如无特殊说明,均指代由内核伙伴系统管理的、属于 System RAM 的那一部分。总之我们讨论问题的出发点还是软件,只不过它需要与硬件提供的机制与协议相配合,所以这里概念讨论的边界也就止步于此。
讨论概念的过程中不乏参杂一些实现方法,这就需要明确之前用的方法有什么问题?现在的方法解决了哪些问题?什么场景下适用?会带来哪些新问题?
物理地址(x86架构):
当我们讲“物理地址”就意味着我们的出发点是 CPU 视角,那么在 CPU 来看物理地址编码就是从0开始,无论是 UMA 还是 NUMA 架构物理地址都是从 0 开始,也只会从 0 开始,换句话说这与 UMA 和 NUMA 或是否为设备 MMIO 异或 APIC/ACPI 没有关系,物理地址就是物理地址,无论从逻辑还是物理上(地址线)讲都是一样的,不会改变。这里容易造成误解的是物理地址上“承载”的内容不一定就是“物理内存”(DRAM),也有可能是设备寄存器如PCI/PCIe 寄存器,或者 PMEM/NVDIMM/GPU memory 等 device memory 再或是 BIOS/UEFI/ACPI/APIC 它们与 “物理内存”一样在 x86 arch 下都占用“物理地址空间”。
总线地址(x86架构):
当我们讲“总线地址”就意味着我们的出发点是设备视角,在PC上总线地址由BIOS/UEFI来规定从哪里开始,现在绝大多数设备遵循PCI/PCIe规范,设备上的配置寄存器和设备内存(如果有的话)会映射到总线地址,供其它设备以及CPU进行访问,如 PCI/PCIe 的配置空间以及BAR寄存器都会“暴露”到总线地址,这里容易造成误解的是在非 IOMMU 情况下 x86 arch 的“总线地址”与“物理地址”采用“统一编址”方式,导致设备上的寄存器和内存映射到“总线地址”也就是映射到“物理地址”。
IOMMU & DMA remapping
还是从设备视角出发,在使能了 IOMMU 情况下 “总线地址”不在直接等同于 “物理地址“(注意我说的是”不直接等同“,段落最后我会有观点)。设备也可以直接读写 virt_addr 名为 IOVA。在我看,从地址关系视角来说对于 x86 这种统一编址的体系下所谓的“两个地址空间”(总线地址/物理地址) 其转换结果也就是一个 PA space + offset 的关系而已,它的转换过程与 MMU 地址转换没什么区别,只不过多了个需要定位 I/O pagetable 的过程,整体流程大致是这样:在发起 DMA 之前需要建立 I/O pagetable 映射,完成这项工作是通过读 IOMMU 暴露的 root entry 寄存器然后用 BDF 索引得到 ctx entry,这里存放着 I/O pagetable 的 PMLx 基地址,后续就跟 MMU 差不多了,写各 entry 建立好映射关系。当 DMA 发起时 root complex 介入吧 TLP request 转换后路由到 IOMMU 上,IOMMU 判断地址范围,如果超出范围则产生 DMA remapping fault,这里要强调一点的是 IOMMU DMA remapping fault 与 MMU pagewalk 过程中产生的 #PF 异常语义是不一样的,#PF 目的是 fixup / resume ,而前者多半就是个错误了,只有少数虚拟化场景下要介入。这里提到的 root complex 就是我那个年代 MCH 也就是北桥的功能,现在都 CPU die 了。我那个年代 MCH/ICH 都是独立于 CPU 的。我个人认为”总线地址“与”物理地址“在 使能了IOMMU 场景下依然没有什么区别,都使用 IOVA 转换了与 VA 转换有啥区别么?所以不同类不能比,我看到不少文章说当设备侧使能 IOMMU 后在 x86 下 ”总线地址“与”物理地址“就不能等同了,直观上是不等同,但就统一编址来说,我更倾向于还是一致的,因为拿 IOVA 与 PA 比,没有可比性,一个是虚拟地址一个是物理地址,都不是一个层面的东西,怎么拿来比呢?
IOMMU 被提出来解决了啥问题呢?首先它最核心的能力是 DMA remapping 和 interrupt remapping 。最早 PCI-SIG 设计的目的是为了让那些 32bit 老设备的 DMA 可访问任意 PA,这样 IOVA 借助 I/O pagetable 转换就可以没有连续 PA space 的要求了。(早期做过板卡驱动的可能要说只要设备支持 scatter/gather 老设备同样也不需要连续的 PA space,这里就需要注意区分了,DMA remapping跟老设备的 DMA scatter/gather 在功能是不一样的,首先老设备的 scatter/gather 使用的是 VA 而不是 IOVA,这个 VA space是要求连续的,而 IOMMU DMA remapping 的 IOVA 可以是不连续的,更重要的是 scatter/gather 没有任何隔离能力,像 PCIe 的 xR-IOV 分配 VF 绑定到 Guest 这种 passthrough 方式,要隔离就必须要用 IOMMU) 。
interrupt remapping 解决的是早期的 PCIe 的 MSI interrupt 还都是向 IO APIC 的 0xFEE0xxxxxxx 进行投递,这种方式显然无法高效支持虚拟化,在interrupt remapping之前都需要 VMEXIT 到 Host 进行软件修改和处理,这种对性能消耗还是很大的。当使能 interrupt remapping 后 IOMMU 自动修改 MSI interrupt 投递到 vAPIC 上。再要说就是解决了一些安全问题,因为 MSI interrupt 更像是 edeg 这种跳变的中断,而不是 level 那种电平触发,所以投递完无需等待,这就导致通过这个特性可以实现一些时序上的 attack 或者 MSI flooding。interrupt remapping 可以通过配置限制非绑核的投递和投递的 vector range。
DMA remapping 解决的安全问题就更明显了,前面段落介绍 DMA remapping fault 的时候就已经说了解决方案了。我看近几年好像 DMA attack 又火了,其实很早这种攻击就有,我记得在 07 年左右的时候就有利用 1394 firewire (OCHI controll 无地址范围校验)发起 DMA attack 的例子,更早的有 yuangge 利用 ISA DMA 直接废掉杀毒卡的例子。现在这类 DMA attack 基本上也都是旧瓶装新酒,思路都是一样的。
其实以上关于 物理地址 与 IOMMU 和 PCI DMA 的例子我早年在 WSS 论坛上都发过比较详细的介绍。
CPU MMU, Pagewalk & huge page & mTHP
CPU CORE 的 MMU 执行 VA 到 PA 的转换称为 pagewalk,此过程仅在 TLB miss 时触发。pagewalk 目的是根据 VA 定位到 PA,定位成功表示找到指向目标物理页的路径(各级页表的物理地址),而非获取内容本身。该路径指向的具体物理区域由硬件和软件约定(BIOS/UEFI/ACP)。构建路径(pagewalk)过程中,若遇到无效或未建立的页表项(PxE),硬件触发 #PF 异常,请求软件(kernel)介入;kernel 处理程序分配所需物理页表并填写正确的物理指向(注意:entry 里是物理地址),硬件与软件协作最终定位到目标 page frame。这里的瓶颈在于软件处理 #PF ,它是 pagewalk 中最耗时的环节,最坏情况下每次访问 PxE 都可能触发 #PF。
因此,硬件引入了1G/2M 的 huge page概念,以优化地址翻译的效率。这里澄清一个最普遍的误解:地址映射的粒度,与物理内存的管理粒度,是两个完全独立的概念。
MMU 对 1G/2M huge page 的支持,是VA->PA 映射粒度的提升。映射,是在建立一条“通路”,那么一条 2M 的通路,显然比一条 4K 的通路要“宽广”得多。但这里的“宽广”,是从 CPU 和 MMU 的视角来看的,它指的是一个页表项(比如一个 PMD entry)能直接覆盖的虚拟地址范围变大了。但这并不意味着 DRAM 物理内存的基本管理单元——page frame——也变成了 2M。在 x86_64 上,物理内存仍然是由一个个 4K 大小的物理页帧组成。也就是说,我们那条 2M 的“大路”(映射容器),里面装的依然是 512 个独立的、4K 大小的“货物”(page frame)。内核为了描述这 2M 物理内存的状态,就需要 512 个 struct page 实例(现在通过folio 封装)来联合描述。一个 2MB 的 huge page,物理上必须对应着 512 个物理地址连续的 PFN。内核在管理时,会将这 512 个struct page 组织成一个 compound page(复合页)。其中,第一个 struct page 称为head page,带有PG_head 标记,负责记录整个 2M huge page 的总体状态;后续的 511 个struct page称为tail pages,带有PG_tail标记,并包含指回head page的指针。
也就是huge page 是通过扩充映射粒度提高翻译效率,它没有能力改变物理内存管理的单元大小,同样内核也不会改变其元数据struct page 的基本组织方式。
理解了“映射”与“分配”的分离后,我们再来看内核是如何利用 huge page 的。
THP (Transparent huge pages) 的目标,是在运行时自动地为应用程序提供 2M huge page,而无需应用自身做任何修改。其优化策略是:应用程序首次访问内存时,内核仍然为其分配标准的 4K 页面。后台一个名为 khugepaged 的内核后台线程,会定期扫描进程的地址空间,寻找那些物理上连续、且被频繁访问的 512 个 4K 页面组成的区域。如果找到了,它就会尝试将它们“提升”为一个 2M 的 huge page 映射,即修改页表,用一个 PMD entry 来覆盖这片区域。当内存压力变大,或者应用程序的访问模式变得稀疏时,内核又会将这个 2M 的 huge page 拆分回 512 个 4K 的页面映射,以支持更细粒度的内存回收或交换(swap-out)。THP 的问题在于,它的决策是非黑即白的:要么是 4K,要么是 2M。对于很多只需要几十或几百 KB 连续内存的应用来说,分配一个完整的 2M huge page 会造成巨大的内部碎片和浪费。同时,coalesce 和 split 操作本身的开销,以及自动化决策可能出现的误判,都会导致不可预测的性能抖动。所以针对低延迟需求的场景,我见到的更多的是用 Huge TLB,同时 isolcpus + nohz_full ,主动 polling,禁用 swap/irqbalance 等等手段。但这种东西没有十全十美,是需要根据应用行为来定的,也就是场景,就好比这么做了后即便是主动 polling,但受限于单核内存带宽等 hard limit,要突破这个瓶颈 scale-out 是方向,但一致性和性能又是个看场景的问题了,所以说没有一劳永逸的方案,只有根据场景的 trade-off。
mTHP (multi-size THP) 是相对比较新的理念,它的提出是为了在一定程度上解决 THP 所带来的问题,它依然遵循 THP 的基本思想,但打破了 2M 的限制。mTHP 允许 khugepaged 根据实际的内存使用情况和碎片状态,将物理上连续的 4K 页面,合并成多种大小的块,比如 16K...512K。以 64K 举例:
1.分配层面: 内核的伙伴系统分配了 16 个物理上连续的 4K page frame。
2.metadata层面: 内核将这 16 个对应的struct page实例,在软件层面组织成一个compound page (folio),使其在内核的内存管理中,被视为一个不可分割的 64KB 单元进行迁移或回收。
3.映射层面: 在进程的页表中,这 64KB 的虚拟地址范围,仍然是由 16 个连续的、指向各自 4K PTE 来完成映射的。它上层的 PMD entry 只是一个指向这个 PTE 表的普通指针,并没有被设置为大页。
Cache Hit/Miss & Cache Alias
关于 cache 的组成和访问方式 (VIPT/PIPT)和如何产生的 cache alias 以及它的危害,很多文章都有详细介绍,这里推荐直接看 intel SDM,我就不赘述了。这里的切入点还是“问题”和“解决问题的方式”,首先得说 cache alias 这是一特恶心的事儿,跟 arch 有关,这里主要是看 x86 下它是如何保障并发性的同时用 VIPT 解决的,这里以 4K page 映射为例,其 VA 中的低 12bit 代表 PA offset,注意:这一点很关键,明显是刻意安排的,因为它包含了用于定位 cache set 的 index,这个低 12bit 可以索引 4K,对于 32k/ 8 way / 64 line 的 L1 来说足以覆盖了,所以只用11:6 就可以表示了,也就是说 VA 里携带了 PA 信息,而这个信息是用于定位 cache set 的,而且范围足够大,别说两个 VA 了,只要映射到同一个 PA,200 个 VA 的 cache set index 也会相同,因为用的就是 PA 的内容,只不过在 VA 里就包含了定位了 cache set 内容,那么接下就是 PA TAG 了,来在 48bit PA 模式下,其高位 47:12 是全局唯一的作为 TAG 去各 way中比较,找到对应的 TAG 且 valid 为 1 则称为 “cache hit”,如果对应的 8 way 的 TAG 都不匹配则视为 cache miss 接下来就是访存过程,从对应 PA (此时这个PA 指向的肯定是 page frame 中的某位置) ,把物理内存中的 64 bytes 拉回来,回填 cache line,更新 TAG,设置 valid 为 1。
我这里挑两个应用层 VA ,他们映射到了同一 PA 上,这两个 VA 是我从在应用层用 FIXED virt_addr 方式模拟的各 memory model 中选出来的。这里实际走一遍流程,看看 x86 的 VIPT 到底是怎么工作的:
VA1: 0x7f0007fff030
VA2 : 0x7f0007ffe030
PA : 0x627ff030
还是假设我们的 L1 d-cache 是32k、8-way、64 line 的配置,这意味着:offset 要 6 位 [5:0] ,index 要 6 位 [11:6]。以下过程是以 VIPT 方式并行的(传统 PIPT 是串行的,很多文章有介绍他们之间的差别,这里不多说了)
CPU 访问 VA1 = 0x7f0007fff030:
cache 侧 :offset: 0x030 的二进制是 0011 0000,所以 offset 是 VA1[5:0] = 0b110000 ;index: 0xfff030 这个地址的低 12 位是 0x030,但 VA1 的 fff030 部分的低 12 位是0x030。我们来看 VA1 的 [11:0] 部分,也就是 0x030,0x030 的二进制是 0000 0011 0000,取其中的 [11:6] 位,也就是 000000。所以,index = 0。cache 硬件立即根据这个 index=0,去访问第 0个 set,并开始读取这个 se t 里所有的 8个way 的 TAG 和数据。
MMU 侧:MMU/TLB 开始将 VA1 = 0x7f0007fff030 翻译成物理地址。假设 TLB hit 或 TLB miss -> pagewalk 成功,最终得到 PA = 0x627ff030。物理 TAG 是 PA 中 [47:12] 的部分 (假设 48 位物理地址)。其 [47:12 ] 就是 0x627ff,所以物理 TAG 也就是 0x627ff。
待以上两侧都就绪后,开始比较TAG,找到 cache hit ,找不到 cache miss 后面过程都上一段都讲过了。
CPU 访问 VA2 = 0x7f0007ffe030:
cache侧: VA2 的低 12 位是 0x030,和 VA1 完全一样。所以,硬件计算出的 index 仍然是 0。cache 硬件再次去访问第 0 个 set。
MMU侧: MMU 将 VA2 翻译,同样得到 PA为 0x627ff030。
剩下的过程与访问 VA1 一致,总结下来就是如果映射到同一 PA,那么各不同的 VA 的高位(VPN) 可能不同,但 PA offset 必然相同,也就是说不同 VA 的高位不同但可能映射到同一个 PFN,但低位要不同,必不是同一 PA,此时高位都不用看。我个人觉得如果从软件实现结果来说,可以把 x86 的 VIPT 看成是一种高性能的 PIPT,因为实际上使用的都是 PA 不同位去定位最终 cache line。但这样可能不严谨,从硬件角度 intel SDM 还是把它描述为了 VIPT,因为牵扯到时序和并行,但对于一个纯软件开发者,怎么好理解怎么来。最后,我还是要提几句 cache line 里存的是具体的内容,正是因为内容不一致才会带来不可预测的后果。还有多 CORE 的 cache coherence protocol, 类似 intel 的 MESI 这种,主要解决的是不同 CORE 副本之间的数据同步问题,不是针对 cache alias 的,cache ailas 是在单 CORE 上就存在的问题。cache alias 需要一些前置条件比如不同 VA 需要都 cache hit ,这有一定的概率,但这玩意儿有一次就够了。第一段提到在不同 arch 上 VIPT 实现不同,如某些 ARM 版本的 L1 cache VIPT 上就需要软件解决(L2 cache 好像就是 PIPT 了)。能找到最好的例子就是 slab/slub 了,“缓存着色”cache coloring 的一个目的就是解决 cache alias。
TLB Shootdown & Lazy TLB Flush
先明确流程:TLB entry 里存的是 VA<->PA 的地址映射关系,它被提出来是要解决访存性能低下问题,所以只有 TLB miss 的时候 MMU 才会 pagewalk ,如果一切顺利(过程中每一步PxE 如果得不到对应 PA,都会触发 #PF,需要 OS 配合)得到映射关系后会回写 TLB entry,下次再需要 VA->PA 转换时,先去 TLB 里找,TLB hit 后直接返回映射关系,这样即避免了访存带来的性能开销,从以上可以看出当产生 pagewalk 时一定是 TLB miss,也只有先 TLB miss 了才会 pagewalk,这里接上一段的讲 cache 的内容,把流程说完,当下只是得到了映射关系,也就是告诉 CPU CORE 去哪里找,但注意,这个时候还没有去真正的取数据,接下来要拿数据是先从 L1>L2>L3 这样一直找下去,当 cache hit 直接返回数据,如果找不到从 VA->PA 的映射关系,沿着这条“路径”取具体的“地方”拿数据,回写相应的 cache line(64 byets)。每次 CPU CORE 访问 VA 取内容都需要经过以上步骤,所以 CPU cache/TLB 解决的就是访存带来的性能问题,按照以上步骤,最好的情况是 TLB hit->cache hit 拿到内容。最坏的情况是 TLB miss->pagewalk(全程 #PF)->cache miss->访存->拿到内容;以上情况在虚拟化场景下变得更为变态,在硬件辅助(半虚拟化)的情况下即便不产生 EPT violation,EPT pagewalk 同样会全程参与(GPA PTE 要经过 EPT 到 HPA 获取),贯穿了整个过程(intel SDM 里有更详细的解读),这个和非虚拟化场景的 pagewalk 是一样的,这个是硬件设计决定的。如果某一步 GPA 无 HPA 对应则 VMEXIT,此时还不能保障 HVA->HPA 有对应(这里需要看 Host 侧怎么做的,如果是 KVM 会用 GUP 做 pre-fault 简化这个过程),那么最坏的情况(非嵌套场景下的 PML4), pagewalk 会产生 20 次访存。
上一段我们走了遍流程就知道 TLB 为什么会被提出,是如何解决的 pagewalk 性能问题,那么我们就需要想尽办法让 TLB hit 从而减少访存,但传统的进程切换要刷 CR3 ,不刷新的话 TLB 会访问到上一个进程的映射,轻则信息泄露,重则数据混乱,不过一旦刷了 CR3 必然 flush TLB。所以避免进程切换带来的 TLB flush 开销,x86 硬件又提出了 PCID/ASID 与进程绑定,这样切换的时候会索引到 TLB entry = VA[high bit] + PCID ,此时这个 TLB entry 或者一组就与特定进程绑定了,避免进程切换刷 CR3 带来的性能开销,同时隔离了进程的访问,避免了数据混乱,进一步说 PCID/ASID 解决的是不同进程访问 VA 无需担心数据一致性和性能开销。结合当前上下文再进一步,就是不同的 mm_struct 不会由于不去 TLB flush 导致新 mm_struct 错误命中旧 mm_struct 的 TLB entry。Linux 内核对 PCID 的应用是相当保守和务实的。硬件(如 intel )可能提供多达 4096 个 PCID,但内核并不会全部使用,因为管理大量的 PCID 本身也会带来开销。实际上,内核只用了很少几个,好像 6 个(在某些版本中),来区分不同的上下文:有固定的用于内核空间的,另外几个用于分配给频繁切换的进程之间。那为什么不把硬件提供的 4096 个 PCID 全部用上呢?这主要是出于对管理复杂性和同步开销的权衡。如果要为系统中成千上万个可能存在的进程,那么显然 4096个是不够用的,在加上进程之间的频繁切换,和在所有 CPU Core 之间动态地、唯一地分配和回收这 4096 个 PCID,就需要一套非常复杂的全局管理和同步机制。比如,在当进程数量过多 PCID 分配是需要以 TLB entry数量为代价的,虽然可以控制 TLB flush 范围,但是我们无法预测应用的行为,在某些而场景下反而会增加 TLB miss 率。这里我给出一个场景,首先假设以下过程都在同一 CPU
CORE 上产生:
1.TLB entry 被“冷”进程占据: 假设调度器依次换入了一大堆“冷”进程。这些进程可能只是短暂运行,每个都只访问一两个页面。因为我们为每个进程都分配了独立的 PCID,所以它们的 TLB entry 不会被 flush,会一直留在 TLB 中。当足够多的这类进程运行过后,TLB 的 1024 个槽位,很快就被这些几乎不会被再次访问的“冷” TLB entry 填满了。
2.“热”进程运行: 此时,一个对性能至关重要的、“热”进程被调度运行。它需要进行大范围的内存访问,理论上需要大量的 TLB entry 才能高效工作。但它运行时,发现 TLB 这个已经被填满。
3.“热”进程填充TLB entry: 这个“主力”进程的每一次内存访问,都不得不经历一次 TLB miss->pagewalk。因为它每回填一个新的 TLB entry,都必须根据策干掉一个之前“冷”进程留下的 TLB entry。在它完成自己的工作时,它把 TLB 中大部分内容都换成了自己的“热”数据。
4.此时“热”进程被换出,然后之前那一大堆“冷”进程又被调度器轮番换入。它们会发现自己上次留在 TLB 的 entry 已经被“热”进程清理掉了,于是它们又不得不再次经历 TLB miss 和 pagewalk,并用自己新的“冷” entry,再一次地将“热”进程建立起来的 TLB flush 掉。
5.“热”进程下一次再被换入时,它又将面对一个被“污染”过的、几乎无用的 TLB。
在分析了以上 5 个步骤后,我们可以看到,当大量“冷”进程和少量“热”进程交替运行时,无限制地为每个进程分配 PCID,会导致严重的 TLB 污染。那么,在这种场景下,与完全不使用 PCID(每次切换都 flush 整个 TLB)相比,性能表现如何?不使用 PCID 的情况,性能同样很差。因为“热”进程每次被调度回来,都将面对一个被完全清空的 TLB,不得不重新经历大量的 TLB miss 和 pagewalk 来填充。但为什么说“有 PCID 但管理不当”的情况,性能反而可能更差?
核心原因在于,当 TLB 污染发生时,PCID 机制未能带来它最核心的好处——保留“热”进程的 TLB entry以避免 TLB miss——但系统却必须承担管理 PCID 带来的全部额外开销。这个额外开销主要来自于软件层面。当一个“热”进程需要一个 PCID,而所有 PCID 槽位都已被“冷”进程占据时,内核必须介入。它需要执行一套额外的软件逻辑,去查找哪个槽位可以被回收,更新内部的跟踪数据,然后触发INVPCID 指令来无效化被选中槽位的旧内容,最后才将这个槽位分配给“热”进程。
总结下来,在“无 PCID”的场景下,性能损失来自于纯粹的硬件行为——全局 TLB Flush 后的必然TLB miss。而在“滥用 PCID”的这个特定场景下,性能损失来自于几乎等量的 TLB miss(因为 TLB 被污染了),再加上 PCID 管理所带来的、不可避免的软件开销。因此,在特定场景下其性能表现可能比没有 PCID 时那种简单直接的全局刷新更糟糕。
因此,内核选择了一种更务实的策略:为每个 CPU Core 维护一个极小的“活跃进程”PCID 缓存。这种 per-CPU 的设计极大地降低了管理的复杂度和跨核同步的需求,用最小的开销捕获了大部分常见的性能优化场景。
这种有限的使用,正是在“利用硬件特性提升性能”和“避免过度管理带来的复杂性开销”之间做出的一种 trade-off。当必须进行 TLB flush 时,硬件提供了 TLB flush range 的指令可以只刷相关 TLB entry。但!还是那句话,没有什么是白来的,所有的优化都是分场景的,不同场景产生不同的债务,而这些债务都以在暗中标好了价格。
PCID 的提出的最终目的是提高 TLB hit 几率减少 pagewalk。那么在什么情况下即便有 PCID 也必须要进行 TLB flush呢?我们看一下这个场景:在多 CORE 下,当 unmaping 一段 VA->PA 映射后硬件会自动无效本地所有 TLB entry(见 intel SDM 描述), 接着要 send IPI 告知其它 CORE ,因为在多 CORE 环境下,无法保障当前进程是否飘到过这些 CORE 上,如果有,同时也访问过相同 VA(有效映射时),那么这些 CORE 的 TLB 也有机率保持着这段映射的有效性,以上过程是无法明确的,也就是你只知道当前 CORE 的状态和动作,其它 CORE 上的 TLB 是否存过这段映射是不确定的,更加准确的说是没有一套“廉价”的机制可以保障跟踪到“到底哪些 CORE 的 TLB 缓存了哪个VA->PA"。这个时候只能无差别的发送 IPI ,这就叫 TLB shootdown。那么如果不刷的话,会导致什么问题呢?这个 VA 已经 unmap 或重新建立了一个有效映射指向了 new_PA,而当调度到另一个 CORE 的时候正好 TLB hit 之前的 VA->PA 映射,记得之前讲的么,此时不会访存,直接从那段 VA->PA 映射取内容了,但这段映射可能处于无效状态或已经重映射到 new_PA 了。这里又要 trade-off 了,到底要不要刷,何时刷?怎么刷?通过前一段的分析,答案肯定是要刷,在回答何时刷之前先看看之前是怎么刷的:在之前的多 CORE 场景下,TLB shootdown 各 CORE 是无差别的 TLB flush。后来当引入了 PCID/ASID 时硬件提供了 invpcid 指令,可根据参数只 flush 特定 PCID 的 TLB entry。还有 invlpg 也就是 TLB flush range(区别就不赘述了,可参考 intel SDM)。但代价是如果频繁 invpcid/invlpg 就意味着要频繁的 send IPI, 因为需要另其它 CORE 也都 flush 对应的区域,也就是说区域刷新的代价把原来一次 IPI 完成的事儿,改成要多次 send IPI 才能完成。针对这个问题,内核给出的还是 lazy 的方案,把相关的 send IPI 尽量推迟,这期间把需要 flush range 攒着,到时机一次性的刷,这就是所谓的 lazy TLB flush。在当前上下文中何时刷可以分为两方面讨论,一个是刷新时机,一个是可以刷但不刷(目的是记录VA,合并请求)。send IPI 时机还是那几个常用的检查点:上下文切换,进程迁移,syscall/IRQ exit to user-mode...这里展开说一下:
某 CORE 同一 mm_struct:
unmapping VA1 -> 需要同步其它 CORE flush VA1 range,此时不发 IPI,只记录。
....
unmapping VA2 -> 需要同步其它 CORE flush VA2 range,此时还是不发 IPI,只记录。
....
modify VA3 -> 更改页表权限,需要同步其它 CORE flush VA3 range 此时仍然不发
IPI,只记录。
刷新时机,TLB shootdown:
某 CORE 发生一次上下文切换:从 old mm_struct 切换到新进程 new mm_struct,切换前检查记录(具体名称不记得了),发现攒了一堆(VA1,VA2,VA3),此时,内核会一次性地处理所有这些积攒的请求。它可能会计算出一个能覆盖所有这些 VA 的最小范围(如果它们相邻),或者干脆执行一次全地址空间的 flush(如果它们分布得太散,或者请求太多)。然后,它向所有其他 CORE 发送一次 IPI,告诉它们 flush TLB 中关于 old mm_struct 的所有过时信息。
总结下来积攒的内容就是:所有发生在同一个地址空间(mm_struct)中、在两次以上的 flush 事件之间的所有 TLB 失效请求。
权衡了半天的 lazy TLB flush 实现带来的问题是什么呢?与某些 arch 下会导致 cache alias 一样,还是安全性问题。了解了 lazy TLB flush 机制就知道他会导致一个时间窗口,如果能够在这个窗口有效期内构造一个场景:
Core 1: unmapping VA1 -> old_PA ,shrink page -> buddy system 。
Core N : old_PA 重新分配(如:指向一个 sk_buff)可能有一个 KVA_new。
Core 2: TLB hit(VA1 -> old_PA)(获取的是 sk_buff的内容)
有兴趣的可以看看 CVE-2018-18955,CVE-2017-5123。
内存模型演进与本文实践
到这里我把当下能想到的涉及到与硬件体系相关的都讨论完了,接着进入与题目相关的讨论。网上很多文章都介绍过FLATMEM MODEL/Discontigmem/SPARSEMEM->SPARSEMEM EXTREME->SPARSEMEM (EXTREME) + VMEMMAP 这些物理内存模型的概念,包括内核文档中介绍的也比较详细,这里我就不在照本宣科的重复了,主要是挑一些容易混淆和我看到过产生误解的点来介绍。
FLATMEM MODEL
还是先明确一些概念,struct page 本身的地址与任何地址都没有直接关系,但 struct page 地址和 pfn 有关,因为 struct page 描述的就是 PA 指向的那个 page frame的状态的,因为 PA BASE = pfn << PAGE_SHIFT (注意:这里是 PA BASE 而不是 PA,如果要得到确切的 PA,需要加上 PA offset,也就是 virt address 低 12 bit(4K 为例) ,完整的公式是: PA = PA base + offset)。比如我通过 struct page - mem_map 就定位到具体的 pfn 了,因为 mem_map[pfn] 就可以定位到描述它的 struct page。而我之前也说过使用分页机制后的 kernel 是无法直接使用 PA 的,因为软件只能使用 VA(MMU进行转换),这个是硬件规定的,当你读写一个 VA 的时候,大致流程是这样:CPU CORE 的 MMU 单元介入,如果 TLB hit 则查看 Ln cache,如果此时 hit 说明可以直接拿到 data 无需访存。如果遇到TLB miss,那么 MMU 发起 pagewalk(我在上面段落介绍过具体步骤),这一步对软件是透明的,只要访问 VA 硬件都会这么做。之所以有 VA<->PA 这种 1:1 的direct mapped 是为了让kernel自己在做相关转换时,可以快速定位,无需做PML4/PDPE/PDE/PTE这样的遍历。
这里还有一个需要澄清的关系:之所以 pfn 与 struct page 之间对 mem_map 进行 +- 就可以进行转换,是因为mem_map是一个struct page结构数组,它的数组索引与 PFN 存在着直接的线性映射关系。mem_map的第0个元素就对应着PFN 0(system RAM页面的起始地址 0)(在高于 2.6 的版本 system RAM 起始地址需要加上ARCH_PFN_OFFSET。它在引导时通过 e820/ACPI table 获得物理地址布局时,发现 system RAM 的PA的起始地址不为 0 的情况下指定偏移),也就是数组的特性。如系统有4G内存,那么在 FLATMEM MODEL下就有 mem_map[4G_pfn_index] 也就是 mem_map[1048576] 大小的 pfn,因为每个 pfn 代表了一个 4K 的 DRAM 的 page frame,之前段落说过,描述 page rame 的软件结构叫 struct page。mem_map 的地址虽然与物理内存地址没有直接关系,但是它的内容(struct page)与 PA 有间接关系,注意是间接关系,这种关系是这样的:每个线性存储的 struct page 对应一个 pfn,而 pfn 指向的是某一个 DRAM 的 page frame (即一个 4K 页框),那么就存在这么一种形式:当获取到某个 struct page 后,可以根据其地址 page_ptr - mem_map 也就是数组元素地址减去数组首地址获得其 index,而这个 index 就是指向 DRAM 的 page frame 的 pfn,有了这个 pfn 后乘以 4K 就是对齐后的 PA base,那么就得出这么一个公式 pfn << PAGE_SHIFT 就得到了 PA base,其 PAGE_SHIFT 为 12,相当于乘以了 4K,比如我得到的 pfn 是 5 那么 5 乘以 4K 就是 0x5000 这个 PA base,然后加上 virt_addr 的低 12 bit 得到完整的 PA。再反过来看这个PA,它一定是属于某个 page frame 中的一员,page frame 是 DRAM 管理的最小单位,pfn 就是用来定位某个 page frame 的,所以我们要定位一个 PA,就需要先定位到某个 pfn,然后通过以上过程定位到 page frame 中的某个具体的 PA;通过 PA 反向操作得到 pfn 就是以上的逆操作,先去掉 virt_addr 的低 12 bit 还原到 PA base 然后右移 PAGE_SHIFT,也就是除以 4K 得到 pfn。
FLATMEM MODEL 的 direct mapping 有几个遗留问题,很早时候在 x86 32 bit 下内核 1G VA 肯定大于 PA(指向 system RAM),因为 system RAM 有限,基本上在启动的时候就完成 1:1 的映射了,所以PA(指向 system RAM)都映射了,后来 1G VA 小于 PA(system RAM),只是映射了大多数,为什么呢?是因为受限于内核地虚拟址空间某些 PA 只能是需要的时候进行手动建立映射(需要注意的是,linux kenrel 的设计是内核建立映射就是直接建立好了,在建立映射这件事儿上不会有什么 lazy load 设计,也就意味着内核空间的地址不会产生 #PF,如果产生了多半是有BUG了。) 那么手动映射,映射到哪呢?这就有了什么临时映射区,永久映射区,HIGHMEM ZONE 等概念,这也是在这种受限 arch 和内核布局下访问超出那部分物理内存的唯一途径了,为此内核还给出了一堆 kernel API,现在看这些了解不了解其实意义不大,随着 arch 更迭,老设备退出舞台,kernel 会慢慢放弃这些划分与支持的,比如在 x86_64 上 HIGHMEM ZONE 就已经没有了,kmap 之类的也已经没什么实际动作了,也就是所谓的“临时映射”,“永久映射”区域基本都是为了兼容而存留了。
Discontigmem model
Discontigmem model 可以说这是个一过性的模型,本来不想介绍,可以直接写 SPARSEMEM MODEL,之所以还放在这里,是想讨论些内容,就是为什么要用它,解决了些什么问题?我看到某些文章说是为了支持 NUMA,这个说法严格来说是不对的,先不说 NUMA 没有规定 NUMA node上的内存排布,即便是之前的 flat mode 就不能在 NUMA 上用了么?当然不是,你要是硬把 flat mode 怼到 NUMA node 上一样可用(Discontigmem / SPARSEMEM 在每个 NUMA node 上也都是 falt mode 的排布),就像只要没有页面属性挡着,拿到 VA 可以直接读写 page frame 一样,但这样就脱离了内核的管理会造成混乱,放到 flat mode 来说问题就是会浪费掉不少描述 page frame 的 metadata 即内核的 struct page(别忘了它也需要占用物理内存);假设这里有一段连续的 PA space,它所承载的内容前后两端映射为 system RAM,而中间这段映射的是 PCI device,而在 flat mode 下我们依然需要对中间这段 PCI device 分配 struct page,而实际上是用不到的,所以中间这段从 system RAM 占用 PA space 角度来看就称为 PCI memory hole, Discontigmem mode 的目的就是要把类似 PA space 承载不是 system RAM 的 memory hole 区域都跳过去,不“分配" 相应的 page frame 描述结构 strut page,这也恰好是符合了 NUMA node 的使用情况。 那它为什么又马上被取代了呢,在我看最主要的原因是在匹配效率问题上,为了解决物理内存分散在不同 NUMA node 上,所以当需要定位到某个 page frame 和反向操作时都需要遍历全部 NUMA node 也就是一种 O(N) 的复杂度,内核是需要频繁的在 page frame (struct page)与 PFN 之间进行转换的,这种效率其实在内核很难容忍,再有就是管理上不够灵活,它的布局方式需要在编译时就确定下来能够管理的 NUMA node 个数。我看到某些文章提到 Discontigmem model 不支持 hotplug memory ,我觉得这个倒还是次要的,在它的架构上支持 hotplug memory只把编译时固定的 NUMA node 问题解决,支持hotplug memory不是什么问题,最主要的还是 O(N) 的复杂度,这才是它一过性的主要原因。
SPARSEMEM -> SPARSEMEM_EXTREME -> SPARSEMEM + VMEMMAP
SPARSEMEM model 相对于 Discontigmem model 是怎样优化查找方式的:对于的物理内存不连续的情况,SPARSEMEM model 使用类似 pagewalk 的方式来组织,通过二维数组形式,利用 pfn 与 struct page 空闲的高位来做全局索引定位到一个叫 section 的结构(mem_section),这个 section 管理了一段物理内存,系统全部物理内存被划分为多个 section,不同 section 的内部物理内存是连续的,也就是 pfn 是连续的,当通过 pfn 的高位定位到了具体的 section 后,再根据 pfn 的低位作为 section 内的 offset 来定位具体的 struct page,这样的转换都是仿照 pagewalk 的位操作直接定位的,这样也就把原先的需要遍历 NUMA node 的 O(N) 变为了 O(1) 的了,这个是解决了在 metadata 与 pfn 间接的是 VA 到 PA 的高效转换,替代了原来的 O(N)。这里还有个问题需要回答就是如果中间遇到了 memory hole 怎么办呢?很简单相应的第一级 mem_section 置 NULL,这样就不会在这段 PA space 创建下一级 mem_section 了,也就是说 struct page 数组只存在下一级的 mem_section 结构体中。也可以看到 SPARSEMEM model 的出发角度不同,着眼点不是依据 NUMA node 划分非连续物理内存,而是根据不同 section 管理固定大小的物理内存,并保障 section 内的物理内存连续,通过 section 来划分,至于这个 section 内部的物理内存 page frame 到底属于哪个 NUMA node,是在引导时就规定好的。
SPARSEMEM_EXTREME model 的使用场景,首先还是看它解决了什么问题,为什么被提出?上一段说到的 SPARSEMEM 我们说他是一个二维数组是为了更好的理解,其实它的定义是一个指针数组,它本身存放在物理内存中是一个连续的固定大小的区域,而它的大小是在内核引导时候根据当前 arch 可支持的 MAX_PFN 计算出来的,而不是机器上实际的 DRAM,也就是说他很可能会大于实际机器上的物理内存,那么接下来这个问题会被放大,在某些体系架构下,它的 system RAM 可能不多但 device memory 不少 ,我们上一段说到过 SPARSEMEM model 对于 memory hole 的处理是将 section 设置为 NULL 以表示这一段物理地址上承载的不是 system RAM,这就会导致在这种架构下 system RAM 分布可能是这样的:
system RAM - mem_section[5]
device memory - mem_section = NULL
...
system RAM - mem_section[900]
device memory - mem_section = NULL
...
system RAM - mem_section[88888]
...
上面是个例子,只是表明 system RAM 会有很大的跨度,这样可以很直观的看到虽然 mem_section 没有下一级的指向,但 struct mem_section 本身是占用空间的。这就是 SPARSEMEM_EXTREME model 被提出的根本原因,就是要解决某些系统配置下穿插着很多 memory hole 导致 system RAM 极端分散的问题。那么解决方案也很简单,同样参照了 pagewalk 的方式,把原来的二维数组再加一层,只对那些有实际 system RAM 对应的物理地址分配 mem_section 。具体做法是取消了原来的那个固定大的 mem_sections,最上层用 mem_section_root ,第二层为动态分配的 mem_sections ,也就是只有承载了 system RAM 的物理地址才会分配这个结构,这样就解决了这个问题。结构变化了,那么pfn 也需要相应的变化,相对于 SPARSEMEM 模型下,pfn 又加了一级索引,变成高位索引 mem_section_root,中间位索引 mem_sections,最低位还是用于索引在struct page 在 section_mem_map 中的位置。相同的思想,我们可以把 pfn 看成一个 virt_addr ,这个过程可以看成是多级页表的 pagewalk,他们思想如出一辙。
SPARSEMEM + VMEMMAP 的最终优化,虽然 SPARSEMEM 已经把 page frame 的管理结构 struct page 与 pfn 之间的转换做到了 O(1),但毕竟需要一个查表操作,中间涉及到 section 结构,相比 flat model 直接 +- 一个 offset 就可以做到还是冗余了一些。为了达到与 flat mode 一样的高效转换,VMEMMAP 利用 SPARSEMEM 下那些有效的 mem_section (有内容就代表是 system RAM),把他们组织起来依次映射到一个 FIXED virt_addr 叫 vmemmap_base,具体实现方式就是把各个 mem_section 对应的 struct page 物理数组,依次映射到 vmemmap 虚拟空间中相应的偏移位置上。这个偏移位置由该 mem_section 的起始 pfn 决定,即 vmemmap_base + section_start_pfn。这样就形成一个”巨大的不占用物理地址空间”的数组,因为它确实不是一个物理地址上连续的数组,而是一个虚拟地址上连续的数组视图,vmemmap 这个虚拟地址范围本身不消耗物理内存。但是,它所映射的目标,那些 struct page 实例是实实在在地存放在物理内存中的。我们之前说过,SPARSEMEM 模型借鉴了 pagewalk 的思想,在软件层面使用 pfn 的高中低位作为索引,进行多级查找来定位 struct page。而现在启用了 VMEMMAP 之后,内核就不再需要这种软件层面的查找逻辑了。因为 vmemmap 区域的 VA->PA 映射关系已经建立在内核页表中,当代码通过 vmemmap_base + pfn 访问对应的 struct page 时,硬件 MMU 会自动进行真正的 pagewalk 来完成地址翻译,整个过程内核无需介入经过这样的设计达到了与 flat mode 一样的效果。在使用了 SPARSEMEM + VMEMMAP 后,因无需 pfn 相关位做索引,所以 mem_section->section_mem_map 直接改为指向 struct page 的首地址了。说到这里无要吐槽下,为了更加直观且透彻的理解我在 LKM 中实现了一个 sparse_model_pfn_to_page / page_to_pfn 函数,适配了 SPARSEMEM 和 SPARSEMEM_EXTREME 模型,为了达到与 vmemmap +- offset 一样的效果,我用了 AI 来写这段代码,我估计是在 VMEMMAP 下几乎没有人再直接去从 mem_section 中取struct page 和 pfn,导致这方面语料不足。它给出的代码要么直接使用 vmemmap + pfn 实现,要么就是计算结果出错,我调试了半天后发现在 SPARSEMEM_EXTREME + VMEMMAP 模型下 AI 错误的用 pfn 的低位在 section_mem_map 中定位 struct page,最后干脆都删了重新手写,真是写代码 3 分钟,找 BUG 3 小时。
SPARSEMEM 与 hotplug memory
SPARSEMEM + VMEMMAP 模型在 struct page 与 pfn 转换之间直接使用 vmemmap ,弱化了 SPARSEMEM 的作用 ,好像 SPARSEMEM 除了引导时内存排布的作用外,在运行时没有起到什么作用了。这种理解其实是不对的,比如系统的 hotplug memory 实现就是基于 SPARSEMEM 的。涉及到具体的 add/remove 动作,也就是热插拔内存时,就是对mem_section 的操作,当需要添加一段物理内存时就是生成或找到相应的 mem_section 将新增的 page frame 的描述结构 struct page 与 pfn 排布好后,挂入对应 NUMA node 的 buddy system 后设置一个 online 标志就可以被“分配”了,remove 为相反操作。hotplug memory 操作在虚拟化场景下很常见,但这里还是要区分一些特殊情况,比如某些半虚拟话场景下,当 Guest OS probe 某个虚拟设备时,这个设备本身是 PMEM/NVDIMM....这类自带 device memory 的,不会挂入任何 NUMA node 的 Buddy system,而是由设备驱动自己来管理内存,这些设备内存也不会像传统的真实设备那样完全不会有 struct page,而是借用 struct page 结构但会设置 dev_pgmap 字段以及 flags 为 PG_devmap,这样的 struct pag 属于一个特殊的 ZONE_DEVICE 区域,这个区域的内存不会 swapout ,通常情况下会被设置为 write-combining。
在深入探讨具体实现前,必须先谈谈一个支撑起整个 SPARSEMEM MODEL+VMMEMAP 模型的可行性前提,这也是我自己在实现过程中遇到的问题。
实现物理内存管理的选择与问题
在自己实现物理内存模型与管理上大致有两种选择,一种是从引导开始实现一个OS原型,从 BIOS/UEFI/ACPI 等地方获取布局信息,从头建立VA->PA 映射,建立各 physical memory model,在这基础上实现 buddy system。这样做的好处是可以随心所欲的VA->PA映射管理page frame,但需要做很多额外的工作,非我所愿。
还一种是借用现有的运行时环境,通过 LKM 在已有的 buddy system 中分配和隔离出一段物理内存,在此基础上实现 physical memory model 与 buddy system,我的选择是通过与 LKM 的配合把这段物理内存直接映射到应用层,完全在应用层实现 physical memory model 与 buddy system。但这样也有一个问题需要解决,那就是通过内核现有的 buddy system 分配的物理内存,其 PFN 是无法像从头实现 OS 原型那样进行控制。
现有物理内存模型最关键的特性,并不仅仅是它能管理物理上不连续的 PFN(比如,mem_section 之间存在 offline 的空洞),而在于它能确保整个系统的 PFN 空间是全局递增的。也就是说,PFN 永远只会向一个方向增长。这是因为内核在系统引导期间建立 PA->VA 映射时,是从 PFN 0 开始,一路向上排布整个物理地址空间。这确保了在系统的整个生命周期内,不会出现 PFN(n) > PFN(n+1) 这种“回头”的情况。虽然在 SPARSEMEM 模型下,PFN 可以是稀疏离散的,比如我们可能有一个 PFN 0x1000,而下一个有效的 PFN 是 0x1012,它们之间存在一个 “memory hole”。但关键在于,下一个 PFN 绝对不会是 0x0bcd 这样一个比 0x1000 更小的值。也就是系统的 SPARSEMEM MODEL 大致上是这样排布的:
mem_section[0] 管理 PFN [0, N-1]
mem_section[1] 管理 PFN [N, M-1](若存在 memory hole 则跳过)
mem_section[2] 管理 PFN [M, K-1](其中 N < M < K)
mem_section[N]
……
每个有效的mem_section内部的 PFN 是连续的,不同 mem_section 的 PFN 范围全局有序, 即系统所有有效 PFN 构成一个全局单调递增序列,memory hole仅表现为序列中的“跳跃”,而不会出现 PFN 值回退,这种布局是在系统启动时就已经由硬件发现和内核映射所固化下来的,不会在运行时改变,这也正是 VMEMMAP 能够通过 vmemmap_base + pfn 这种简单的线性偏移来定位 struct page 的根本原因。
而我在应用层实现物理内存管理时,遇到的根本性差异就在这里。我的系统核心是通过一个 LKM(可加载内核模块),从内核伙伴系统动态分配出多个连续的 4MB 物理内存块(order=10),我称之为 segment。每个 segment 内部,PFN 确实是连续且递增的。但是,由于这些 segment 是在系统运行时由伙伴系统动态分配的,我无法保证跨 segment 之间 PFN 的单调性。举个例子,我分配的第一个 segment 的起始 base_pfn 可能是 0x29000,但伙伴系统下一次返回的 segment,其 base_pfn 很可能是 0x0bdc0——一个远小于前一个的值。这就是我的模型无法完全模拟 SPARSEMEM MODEL + VMEMMAP 的关键所在。我无法依赖一个全局的、单调递增的 PFN 空间。
为了解决这个问题,我设计了如下架构:
我总共分配 32 个 segment,来管理 128MB 物理内存(当然,系统运行时间越长,负载越高时别说 128M,连 1M 连续物理内存都不见得分配的到,为了方便操作,我会先运行 echo 3 > /proc/sys/vm/drop_caches 来清理缓存)。在 LKM 中,通过 alloc_pages(GFP_DMA32, MAX_SEGMENT_ORDER) 获取每个 4MB segment,然后将其 struct page 标记为“保留”(Reserved),使其脱离内核伙伴系统的管理。接着,通过 remap_pfn_range,将所有这些物理上不连续的 segment,映射到用户空间一个通过 MAP_FIXED 固定的、虚拟地址连续的巨大空间(vaddr_base)中。
这样,我就拥有了一个连续的虚拟地址空间。基于此,我引入了“虚拟页帧号(vPFN) ”的概念。vPFN 可以被看作是在我管理的这片虚拟地址空间中的连续页帧号,它从 0 开始,一直到 (32 * 1024 - 1)。它成为了我管理这些物理页的统一、连续的索引。最后,我还映射了另一块内存,用于存放我们自己的管理结构数组 mem_map_model,它类似于内核的 node_mem_map。通过 vPFN 作为这个数组的下标,我实现了对任何一个 4K 页面对应的管理结构(struct phys_page)的 O(1) 访问。
在这个模型之上,本文的后续章节,将详细展开以下实践:
1、模拟内核转换: 在 LKM 中,我们将实现 sparse_model_pfn_to_page 和 sparse_model_page_to_pfn 的逻辑,它不依赖于 VMEMMAP 这个内中的固定虚拟地址,而是深入到SPARSEMEM MODEL / SPARSEMEM EXTERME MODEL 等模型下实现,。
2、MMU pagewalk 仿真: 在不使用 P4D/PUD/PMD 等内核内置结构和宏的前提下,模拟
x86-64 的页表遍历过程,以便更好的理解 x86 下 MMU pagewalk 过程。
3、实现伙伴系统: 在基于我们构建的物理内存模型之上,从零开始实现一个功能完整、经过 GDB 调试验证的伙伴系统(Buddy System)分配器。
我们先看一下自己管理物理内存结构的相关定义
#define SEGMENTS_PER_NODE 32
#define MAX_SEGMENT_ORDER 10
#define NR_ORDERS (MAX_SEGMENT_ORDER + 1)
#define SEGMENT_SIZE_MB 4
#define PHYS_PAGES ((SEGMENT_SIZE_MB * 1024 * 1024) / PAGE_SIZE)
#define MAX_ALLOC_ORDER 10
#define PHYS_META_SIZE (SEGMENTS_PER_NODE * PHYS_PAGES * sizeof(struct phys_page))
#define MAX_BLOCKS (PHYS_PAGES * 2)
就像上一节介绍的,每一个 NUMA node 有 32 个 segment,每个 segment 是 4M 的物理内存,4M 等同到 order 数是 10 也就是 2^10 ,每个物理页面是 4K,那么每个 segment 一共有 PHYS_PAGES 个物理页面。
从 ACPI SRAT 表中发现 NUMA 拓扑
在尽量不依赖运行时环境的前提下,我们第一步要做的是确定有多少个 NUMA node,这个信息从传统的 BIOS e820 调用无法获取到,只能通过 ACPI table 获取。说到 ACPI 还是忍不住要吐槽,在多年后的今天,我仍能回忆起那个像公厕一样的 ACPI ,在那些冒着腐臭味儿的“坑”位中,被各硬件厂商毫无羞耻心的肆意乱拉。据说这几年有不小改善,但我抱着高度防御的心态来解析 SRAT 和 SLIT,在我机器上环境所限所以只从 SRAT 中解析出一个 NUMA node ,所以也就不存在什么 SLIT(关于 ACPI 的 SRAT 和 SLIT 这里就不介绍了)。解析过程如下:
static int parse_srat_table(void)
{
acpi_status status;
struct acpi_table_header *table_header = NULL;
struct acpi_subtable_header *sub_table;
int node_map_idx = 0;
char *table_end;
bool found_enabled_node = false;
status = acpi_get_table(ACPI_SIG_SRAT, 0, &table_header);
if (ACPI_FAILURE(status)) {
pr_warn("ACPI SRAT table not found.\n");
goto fallback;
}
pr_info("Found ACPI SRAT table at 0x%px, length 0x%x. Parsing...\n", table_header, table_header->length);
memset(&g_numa_info, 0, sizeof(g_numa_info));
memset(g_numa_info.proximity_domain_to_node_id, 0xFF, sizeof(g_numa_info.proximity_domain_to_node_id));
table_end = (char *)table_header + table_header->length;
if (!table_end) {
pr_warn("ACPI SRAT table invalid size.\n");
goto fallback;
}
sub_table = (struct acpi_subtable_header *)((char *)table_header + sizeof(struct acpi_table_header));
if (!sub_table) {
pr_warn("ACPI SRAT sub-table invalid.\n");
goto fallback;
}
while ((char *)sub_table < table_end) {
if (sub_table->length == 0 || (char *)sub_table + sub_table->length > table_end) {
pr_warn("ACPI SRAT sub-table (type 0x%x, len 0x%x). skip and continue.\n",
sub_table->type, sub_table->length);
sub_table = (struct acpi_subtable_header *)((char *)sub_table + 1);
continue;
}
switch (sub_table->type)
{
case ACPI_SRAT_TYPE_CPU_AFFINITY:
{
struct acpi_srat_cpu_affinity *cpu = (struct acpi_srat_cpu_affinity *)sub_table;
if (cpu->flags & ACPI_SRAT_CPU_ENABLED) {
pr_info(" SRAT CPU Entry: PXM %u -> APIC ID 0x%02x -> Enabled\n",
cpu->proximity_domain_lo, cpu->apic_id);
if (g_numa_info.proximity_domain_to_node_id[cpu->proximity_domain_lo] == 0xFF) {
g_numa_info.proximity_domain_to_node_id[cpu->proximity_domain_lo] = node_map_idx ++;
}
found_enabled_node = true;
}
break;
}
case ACPI_SRAT_TYPE_MEMORY_AFFINITY:
{
struct acpi_srat_mem_affinity *mem = (struct acpi_srat_mem_affinity *)sub_table;
if (mem->flags & ACPI_SRAT_MEM_ENABLED) {
pr_info(" SRAT MEM Entry: PXM %u -> [mem 0x%010llx-0x%010llx] -> Enabled%s\n",
mem->proximity_domain,
mem->base_address,
mem->base_address + mem->length - 1,
(mem->flags & ACPI_SRAT_MEM_HOT_PLUGGABLE) ? " (Hotpluggable)" : "");
if (g_numa_info.proximity_domain_to_node_id[mem->proximity_domain] == 0xFF) {
g_numa_info.proximity_domain_to_node_id[mem->proximity_domain] = node_map_idx ++;
}
found_enabled_node = true;
}
break;
}
}
sub_table = (struct acpi_subtable_header *)((char *)sub_table + sub_table->length);
}
acpi_put_table(table_header);
if (!found_enabled_node) {
pr_warn("SRAT parsing did not find any enabled nodes after full scan.\n");
goto fallback;
}
g_numa_info.node_count = node_map_idx;
pr_info("SRAT parsing complete. Discovered %d NUMA node(s).\n", g_numa_info.node_count);
return 0;
fallback:
pr_info("Defaulting to a single-node system configuration.\n");
g_numa_info.node_count = 1;
g_numa_info.proximity_domain_to_node_id[0] = 0;
return 0;
}
解析过程中我的 SRAT 的前12 个 sub-table 均为 0 也就是坏块,我不知道这是“有意”安排还是什么,鉴于 ACPI 之前给我的印象很糟,也就不深究了。我 dump 出来的信息见下图:
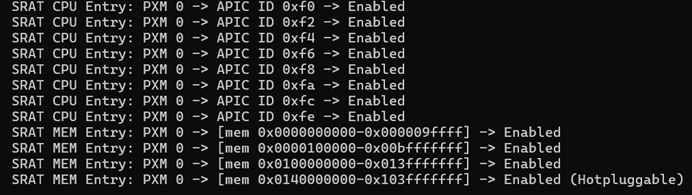
在我自己的 VMware 环境下,这个函数的输出日志,揭示了系统的底层硬件布局:
首先 PXM是Proximity Domain的缩写,意为“邻近域”。这是 ACPI 规范中用来描述 NUMA 节点的术语。一个 PXM 就代表一个 NUMA 节点。
ACPI_SRAT_TYPE_CPU_AFFINITY:
在日志中,我看到所有的 CPU 和内存条目都指向 PXM 0,这清晰地表明,我的系统从硬件层面看,只有一个 NUMA 节点,其邻近域 ID 为 0。这里的 APIC ID 指的是 LAPIC,它的 ID 在系统中是唯一的,因此被用来标识一个特定的 CPU 核心(或线程)。我的日志中只解析出了偶数的 APIC ID(0, 2, 4...),而我的系统启动日志(dmesg)中却有连续的 ID(0, 1, 2, 3...)。这是因为 dmesg 显示的是所有逻辑处理器(包括超线程)的 ID,而我的解析代码只提取了每个物理核心的主 APIC ID。对于确认 NUMA 亲和性而言,这已经足够了,因为它表明所有核心都属于同一个 PXM 0。
ACPI_SRAT_TYPE_MEMORY_AFFINITY:
对于 MEM entry 部分我们可以逐个分析一下
SRAT MEM Entry: PXM 0 -> [mem 0x0000000000-0x000009ffff] -> Enabled
这一行定义了系统最底端的内存。它声明了从物理地址0x0开始,到0x9FFFF(也就是 640 KB 的边界)的这段内存,属于PXM 0(即 Node 0)。这就是我们常说的“常规内存”或“基本内存”,是早期 PC 架构遗留下来的区域。
SRAT MEM Entry: PXM 0 -> [mem 0x0000100000-0x00bfffffff] -> Enabled
这段就有点意思了,物理地址0x100000 (1 MB) 开始,到 0xBFFFFFFF (略低于 3 GB) 的一大块连续内存,也属于PXM 0,但发现没有跟上一段之间相差了从 640K 到 1M 之间的那 384K ,这也就是著名的 “ISA hole”所在的区域了,也就是从
“0xA0000 到 0xFFFFF”,从 DOS 那个年代玩儿过来的,都写过 0xA0000 吧,它在历史上被 ISA/VGA 显卡、系统 BIOS ROM 和其他一些传统设备占用。即使在现代系统中,为了保持向后兼容性,这块物理地址空间通常也不会被分配给主内存(DRAM)。SRAT 表通过这种“跳过”描述的方式反应了这段历史。
SRAT MEM Entry: PXM 0 -> [mem 0x0100000000-0x013fffffff] -> Enabled
这一行描述了另一块位于更高地址的内存。它声明了从物理地址 0x100000000 (4 GB) 开始,到 0x13FFFFFFF (5 GB) 的这 1 GB 内存,也属于 PXM 0。这表明系统的物理内存分布跨越了 4GB 的界限,这在 64 位系统上是常态。
SRAT MEM Entry: PXM 0 -> [mem 0x0140000000-0x103fffffff] -> Enabled (Hotpluggable)
注意这一行中我打印出来的 Hotpluggable,这个标记是 SRAT 给 OS 的一个重要提示。它意味着这块内存区域被设计为支持内存热插拔。在虚拟机环境中,这通常意味着 hypervisor (VMware) 可以动态地为这个虚拟机增加或减少内存,而不需要重启虚拟机。
OS 内核看到这个标记后,会使用SPARSEMEM MODEL的 online / offline机制来管理这片内存对应的 mem_section,以便在收到热插拔事件时,能够动态地将新的物理内存add(加入 Buddy system)或将要移除的内存offline(从中迁走所有数据并移出 Buddy system)。这再次印证了我们之前的结论:SPARSEMEM MODEL不仅仅是为了处理启动时的内存空洞,它更是实现运行时内存动态管理(如热插拔)的底层基础架构。
解构 SPARSEMEM EXTERM MODEL 与 VMEMMAP:
网上又很多文章讲解 SPARSEMEM MODEL + VMEMMAP 的文章,通过分析源码,画各种图形,对于我来说最透彻的理解方式是不使用基于 VMEMMAP 的 pfn_to_page / page_to_pfn 来实现一个基于 SPARSEMEM MODEL 的 pfn 与 struct page 之间的转换,这样会发现不少问题,以及一些文章与 AI 描述的错误,比如在 SPARSEMEM EXTERME MODEL + VMEMMAP 中它的 mem_section->section_mem_map 保存的到底是什么?它的组织方式是否与SPARSEMEM MODEL 中的一致
static struct mem_section *__sparse_model_pfn_to_section(unsigned long pfn)
{
unsigned long section_nr = pfn >> (SECTION_SIZE_BITS - PAGE_SHIFT);
#ifdef CONFIG_SPARSEMEM_EXTREME
struct mem_section **mem_section_base = *g_mem_section_roots_ptr;
struct mem_section *root;
unsigned long root_idx = section_nr / SECTIONS_PER_ROOT;
if (root_idx >= NR_SECTION_ROOTS)
return NULL;
root = mem_section_base[root_idx];
if (!root)
return NULL;
return &root[section_nr % SECTIONS_PER_ROOT];
#else
struct mem_section *mem_section_base = *g_mem_section_roots_ptr;
if (section_nr >= NR_MEM_SECTIONS)
return NULL;
return &mem_section_base[section_nr];
#endif
}
在转换过程中首先需要定位 mem_section ,也就是这个 pfn 到底是属于那个 mem_section 的,它的定位方式借鉴了 MMU pagewalk 的方法,使用几级索引标注,这样的转换更高效,在 SPARSEMEM MODEL 下 pfn 相关 bit 用于索引的说明很多文章都已经介绍过了,这里就不在赘述,我应用层模拟的 SPARSEMEM MODEL 也采取了同样的方式。
struct page *sparse_model_pfn_to_page(unsigned long pfn)
{
struct mem_section *section;
section = __sparse_model_pfn_to_section(pfn);
if (!section || !(section->section_mem_map)) {
return NULL;
}
#if defined(CONFIG_SPARSEMEM_VMEMMAP)
unsigned long vmemmap_base = section->section_mem_map & SECTION_MAP_MASK;
return (struct page *)(vmemmap_base + (pfn * sizeof(struct page)));
#else
struct page *section_mem_map_base;
unsigned long page_offset = pfn & (PAGES_PER_SECTION - 1);
section_mem_map_base = (struct page *)(section->section_mem_map & SECTION_MAP_MASK);
return section_mem_map_base + page_offset;
#endif
}
当通过 pfn 定位到了具体的 mem_section 后需要区分当前系统给是否使能了 VMEMMAP,如果是则 section_mem_map 去掉 MASK 后无需再根据 pfn 相关bit再次索引,可直接将 pfn 当作 offset 定位到 struct page,这就跟 VMEMMAP 与 FLATMODE 下是一样的。
这里展开讨论,那就是VMEMMAP的出现,是为了在保留 SPARSEMEM 模型灵活性的同时,恢复 FLATMEM 模型极致的 pfn <-> struct page 转换效率。要理解其精髓,就必须弄清 mem_section->section_mem_map 字段在 VMEMMAP 模型下的真正含义。
通过在我的 LKM 中直接打印 section->section_mem_map 的值,我发现了一个关键事实:
Aug 5 18:53:06 jia kernel: [640710.396681] vmemmap_base ffffce2d80000000
... (for different PFNs, the base is the same)
无论我检查哪个 online 的 section,其 section_mem_map 字段(屏蔽掉标志位后)都指向了同一个、固定的虚拟地址,在我的系统上是 0xffffce2d80000000。这个地址,正是内核 vmemmap 虚拟内存区域的基地址,内核导出的名称为 vmemmap_base。
而 section->section_mem_map 存储的则是这个指针变量所指向的地址。
我们看看内核具体是怎么做的:
1.内核在启动时,在虚拟地址空间中预留了一块巨大且连续的区域,其基地址就是我们看到的 0xffffce2d80000000。
2.对于每一个 online 的、包含真实物理内存的 mem_section,内核会将其对应的 struct page 数组(这块元数据本身存放在物理内存中),通过修改内核页
表的方式,映射到这个 vmemmap 虚拟区域的正确偏移位置上。
3.这个偏移量由该 mem_section 的起始 PFN 决定。
因此,pfn 和它对应的 struct page 的虚拟地址之间,形成了一个完美的线性关系:
page_address = vmemmap_base + pfn * sizeof(struct page)。
我的 sparse_model_pfn_to_page 这段代码的正确性,就在于它从任何一个有效的mem_section 中获取到了全局唯一的 vmemmap_base,然后直接使用全局 PFN 作为偏移量进行计算。这与FLATMEM 模型的 mem_map + pfn 在效率和原理上已经完全等同。硬件 MMU 会自动处理后续的 VA->PA 的翻译,将我们对这个虚拟 vmemmap 地址的访问,精确地导向到存放着正确 struct page 实例的那块物理内存上。
unsigned long sparse_model_page_to_pfn(struct page *page)
{
if (!page)
return -1UL;
#ifdef CONFIG_SPARSEMEM_VMEMMAP
struct mem_section *section;
static unsigned long vmemmap_base = 0;
unsigned long sec_nr;
if (vmemmap_base == 0) {
for (sec_nr = 0; sec_nr < NR_MEM_SECTIONS; sec_nr ++) {
section = __sparse_model_pfn_to_section(sec_nr << (SECTION_SIZE_BITS - PAGE_SHIFT));
if (section && section->section_mem_map) {
vmemmap_base = section->section_mem_map & SECTION_MAP_MASK;
pr_info("vmemmap_base 0x%lx from section %lu\n", vmemmap_base, sec_nr);
break;
}
}
if (vmemmap_base == 0) {
pr_err("page_to_pfn: Failed to find online section!\n");
return -1UL;
}
}
return ((unsigned long)page - vmemmap_base) / sizeof(struct page);
#else
struct mem_section *section;
struct page *section_mem_map_base;
unsigned long section_nr = page->flags >> PGF_SECTION_SHIFT;
unsigned long pfn_of_section_start = section_nr << (SECTION_SIZE_BITS - PAGE_SHIFT);
section = __sparse_model_pfn_to_section(pfn_of_section_start);
if (!section) {
pr_warn("page_to_pfn: Could not find section for page at %p\n", page);
return -1UL;
}
section_mem_map_base = (struct page *)(section->section_mem_map & SECTION_MAP_MASK);
unsigned long pfn_offset = page - section_mem_map_base;
return pfn_of_section_start + pfn_offset;
#endif
}
对于sparse_model_page_to_pfn 掌握了前者,后者就是相反定位,同样是先获取到对应的 mem_section,由于我的环境是使能了 VMEMMAP,对于另一个分支我就没有进行测试,但思路都是一样的,只不过 pfn 与 struct page 承担了更多的定位 bit,我这里的 page->flags 是在某些特定版本下的,后续版本取消了 flags 中的相关 bit,这个社区内有讨论,最终认为 flags 资源紧张并不应该承担这份责任。有兴趣可以在特定版本试一下,网上也有很多介绍的文章,这里就不展开说了。
通过这个手动实现和验证的过程,才会透彻的理解VMEMMAP是如何巧妙地利用虚拟内存技术,将 SPARSEMEM MODEL 尤其是 EXTERME 极度分散的物理元数据,重新组织成一个逻辑上统一、访问高效的线性数组的。这也就是我为什么说 mTHP 与 SPARSEMEM MODEL 在更高设计理念上是相通的,它们都利用了虚拟地址的连续性,来管理和呈现底层的物理资源。VMEMMAP的核心是利用内核虚拟地址空间。它预留一个固定的虚拟地址起始点然后通过建立页表,将那些为各个mem_section分配的、物理上分散的struct page数组,一一映射到这个连续的虚拟地址空间中。当代码执行vmemmap_base + pfn来访问一个struct page时,硬件MMU pagewalk,将这个虚拟地址最终翻译到存放着正确struct page实例的那块物理内存上。通过这种方式,VMEMMAP将SPARSEMEM MODEL下复杂的软件查找,转换为了高效的硬件地址翻译,从而恢复了FLATMEM模型那种通过简单指针偏移就能 O(1) 定位struct page的能力。而mTHP则是通过连续的 VA,将一组物理上连续的数据页,在软件层面“粘合”成一个更大的管理单元,以优化缺页和回收效率。同样的设计哲学也体现在这里没有详细讨论的MGLRU 中。它通过一种更高效的方式,解决了Classic LRU算法中的一个核心性能瓶颈。传统 Classic LRU 在判断一个页面是否可以回收时,需要知道这个页面最近是否被用户进程访问过。为了得到这个信息,它常常需要启动一次开销巨大的RMAP Walker。这是一个需要遍历所有可能映射了它的用户进程地址空间(VMA)的链表操作。MGLRU 巧妙地利用了 x86 硬件的一个特性:当一个用户进程通过其页表访问一个页面时, MMU 会自动设置 hardware PTE Accessed bit 为 1。而内核pagewalk时,不会导致位更新(见 intel SDM)。这个硬件行为,形成了一个天然的、低成本的“用户空间访问标志”。MGLRU 正是抓住了这一点。它不再需要通过 RMAP Walker 去费力地反查 VMA,而是同样借助了硬件 MMU 能力来达成目的。
说到 MMU pagewalk的转换,为了更加透彻且直观的理解,在验证应用层ioctl 过来的VA->PA转换过程中我使用的是仿真x86_64 MMU pagewalk 方法。比使用内核提供的 PUD/PMD 方式更直观一些,它强调的是无论是否建立了所谓的 1:1 direct mapping 硬件的这一流程始终存在。1:1 只是为了内核自己使用更高效便捷而已。
#define X86_PML4_SHIFT 39
#define X86_PDPE_SHIFT 30
#define X86_PDE_SHIFT 21
#define X86_PTE_SHIFT 12
#define X86_PAGE_PRESENT (1ULL << 0)
#define X86_PAGE_PSE (1ULL << 7)
#define X86_PAGE_SHIFT 12
static inline uint64_t* line_phys_to_virt(uint64_t phys_addr)
{
return (uint64_t*)(phys_addr + PAGE_OFFSET);
}
static uint64_t read_cr3(void)
{
uint64_t cr3;
asm volatile("mov %%cr3, %0" : "=r"(cr3));
return cr3;
}
static uint64_t* return_entry_virt(uint64_t entry_phys, unsigned index)
{
uint64_t pfn = entry_phys >> 12;
uint64_t phys_base = pfn << 12;
phys_base = (phys_base & 0x000ffffffffff000);
uint64_t *entry= line_phys_to_virt(phys_base);
return &entry[index];
}
uint64_t emulate_x86_64_pagewalk(uint64_t virt_addr, uint64_t cr3_reg)
{
const uint32_t pml4_index = (virt_addr >> X86_PML4_SHIFT) & 0x1FF;
const uint32_t pdpe_index = (virt_addr >> X86_PDPE_SHIFT) & 0x1FF;
const uint32_t pde_index = (virt_addr >> X86_PDE_SHIFT) & 0x1FF;
const uint32_t pte_index = (virt_addr >> X86_PTE_SHIFT) & 0x1FF;
const uint32_t page_offset = virt_addr & 0xFFF;
uint64_t phys_addr;
uint64_t *pml4_entry = return_entry_virt(cr3_reg, pml4_index);
if (!pml4_entry)
return 0;
uint64_t pml4_entry_phys = *(pml4_entry);
if (!(pml4_entry_phys & X86_PAGE_PRESENT))
return 0;
uint64_t *pdpe_entry = return_entry_virt(pml4_entry_phys, pdpe_index);
if (!pdpe_entry)
return 0;
uint64_t pdpe_entry_phys = *(pdpe_entry);
if (!(pdpe_entry_phys & X86_PAGE_PRESENT))
return 0;
if (pdpe_entry_phys & X86_PAGE_PSE) {
phys_addr = ((pdpe_entry_phys & 0x3fffffc0000000) |
(virt_addr & 0x3FFFFFFF));
goto end;
}
uint64_t *pde_entry = return_entry_virt(pdpe_entry_phys, pde_index);
if (!pde_entry)
return 0;
uint64_t pde_entry_phys = *(pde_entry);
if (!(pde_entry_phys & X86_PAGE_PRESENT))
return 0;
if (pde_entry_phys & X86_PAGE_PSE) {
phys_addr = ((pde_entry_phys & 0x3fffffffe00000) |
(virt_addr & 0x1FFFFF));
goto end;
}
uint64_t *pte_entry = return_entry_virt(*pde_entry, pte_index);
if (!pte_entry)
return 0;
uint64_t pte_entry_phys = *(pte_entry);
if(!(pte_entry_phys & X86_PAGE_PRESENT))
return 0;
phys_addr = ((pte_entry_phys & 0x7ffffffffffff000) | page_offset);
end:
return phys_addr;
}
以上实现没有什么可过多介绍的,无非是按照手册仿真而已。只不过有一点需要说明,过程中因各 entry 中保存的是物理地址,而在软件仿真过程中我们又无法直接使用物理地址,所以return_entry_virt需要将时机的物理地址进行转换,这也是这种仿真过程中不可避免的一步。
在透彻理解了内核的 memory model 后,我们要接着理解基于它之上的 Buddy system “管理“物理页面的方式。现在的 Buddy system 都是每 NUMA node 上挂一个,从结构角度看 Buddy system 管理的无非是已分配的和未分配的物理内存,其各自有各自的管理结构。对于已分配的 anonymous page 与 file-backed page 由 Classic LRU 或 MGLRU 进行管理(MGLRU 有不少可玩性,我会有专门的文章讲解,就不在这里介绍了)。
而我们现在关注的是未分配的内存。这部分内存,在每个 NUMA node 下由 ZONE 组织,每个ZONE内部又拆分成不同 order 的空闲链表(free_area)来存储物理上相邻的 PFN 块。而每个 PFN 指向的 DRAM page frame,又由我们之前深入分析过的 struct page 这个元数据来描述。一个struct page与PFN的对应关系,则通过类似SPARSEMEM_EXTREME + VMEMMAP 这样的物理内存模型来维护。这样,整个管理链条就串起来了。
通过这样的梳理,我们接下来的目标就非常明确了:要对每个 NUMA node 上的 ZONE 以及其中的 order 进行分析。比如,在 alloc_pages 之前,我指定的ZONE和order是否能够满足我的请求?如果满足不了,为什么?是因为页面总量不够,还是因为碎片化导致没有大的连续块?在分配失败的情况下,内核会如何跨ZONE进行回退?分配成功后,各个 ZONE 的水位线又会发生怎样的变化?内核虽然通过 debugfs 等接口暴露了部分信息,但并没有提供一个直接的方式来查看某个 ZONE 的某个 order 上,具体是哪些 PFN、哪些 struct page 正处于空闲状态,以及它们对应的内核虚拟地址(VA)和物理地址(PA)。这些信息可能过于底层,但对我们来说,通过自己的 LKM dump 这些信息,就可以将 NUMA node -> ZONE -> order -> PFN -> struct page -> VA -> PA 这条完整的链路串联起来,达到真正的理解。为此,我在 LKM 中实现了一套函数,用于在分配内存前,对目标节点的内存状态进行一次扫描。
探测 ZONE 容量与分配策略
第一步是实现一个“策略规划”层。在发起 alloc_pages 调用前,我需要先判断哪个 ZONE 是最合适的分配目标。这需要三个函数协同工作:
static bool check_zone_capacity(struct zone *zone, unsigned long required_pages)
{
unsigned long free_pages;
unsigned long min_wm, low_wm, high_wm;
free_pages = zone_page_state(zone, NR_FREE_PAGES);
min_wm = zone->_watermark[WMARK_MIN];
low_wm = zone->_watermark[WMARK_LOW];
high_wm = zone->_watermark[WMARK_HIGH];
pr_info(" -> Checking Zone '%s':\n"
" Free Pages: %lu\n"
" Watermarks (min/low/high): %lu / %lu / %lu\n"
" Required Pages: %lu\n",
zone->name, free_pages, min_wm, low_wm, high_wm, required_pages);
if (free_pages >= required_pages) {
if (free_pages < high_wm) {
pr_info(" -> Status: Total pages sufficient, but below high watermark. Direct reclaim would be needed.\n");
} else {
pr_info(" -> Status: Healthy. Sufficient pages available above high watermark.\n");
}
return true;
} else {
pr_info(" -> Status: Insufficient total free pages.\n");
return false;
}
}
static const char* find_zone_allocation(int node_id, unsigned long total_pages_needed)
{
pg_data_t *pgdat;
struct zone *zone;
enum zone_type preferred_order[] = {ZONE_NORMAL, ZONE_DMA32, ZONE_DMA};
int i;
pgdat = NODE_DATA(node_id);
if (!pgdat) {
pr_warn("Could not get pg_data_t for node %d\n", node_id);
return NULL;
}
pr_info("Searching for a suitable zone on node %d for %lu pages...\n",
node_id, total_pages_needed);
for (i = 0; i < ARRAY_SIZE(preferred_order); ++i) {
enum zone_type z_type = preferred_order[i];
if (z_type >= MAX_NR_ZONES) {
continue;
}
zone = &pgdat->node_zones[z_type];
if (!populated_zone(zone)) {
pr_info(" -> Zone '%s' is not populated, skipping.\n", zone->name);
continue;
}
if (check_zone_capacity(zone, total_pages_needed)) {
pr_info("==> Found suitable zone on node %d: '%s'\n", node_id, zone->name);
return zone->name;
}
}
pr_warn("No suitable zone found on node %d with enough capacity.\n", node_id);
return NULL;
}
static int prepare_node_allocation(int node_id, gfp_t *gfp_mask_out, int req_order, int seg_cnt)
{
const char *zone_name;
gfp_t result_gfp_mask;
unsigned long pages;
if (seg_cnt > 0)
pages = (1UL << req_order) * seg_cnt;
else
pages = 1UL << req_order;
zone_name = find_zone_allocation(node_id, pages);
if (!zone_name) {
pr_warn("Node %d has no single zone with enough capacity for %d pages.\n",
node_id, req_order);
return -ENOMEM;
}
// This logic has a slight imprecision, corrected in later discussions.
if (strcmp(zone_name, "Normal") == 0) {
result_gfp_mask = GFP_KERNEL;
pr_info("--> Preparing to allocate from ZONE_NORMAL on node %d.\n", node_id);
} else if (strcmp(zone_name, "DMA32") == 0) {
result_gfp_mask = __GFP_DMA32; // This should be OR'd with GFP_KERNEL
pr_info("--> Preparing to allocate from ZONE_DMA32 on node %d.\n", node_id);
} else {
result_gfp_mask = __GFP_DMA; // This should be OR'd with GFP_KERNEL
pr_info("--> Preparing to allocate from ZONE_DMA on node %d.\n", node_id);
}
*gfp_mask_out = result_gfp_mask;
return 0;
}
这三个函数构成了一个决策链。prepare_node_allocation 作为入口,它首先调用find_zone_allocation来寻找一个总体空闲页数足够的ZONE。find_zone_allocation 则按NORMAL->DMA32->DMA 的优先级顺序,依次调用 check_zone_capacity 来检查每个ZONE的状态。check_zone_capacity不仅检查总空闲页数,还会打印出该ZONE的水位线信息,让我们能直观地看到其内存压力状况。最终,prepare_node_allocation 根据找到的 ZONE,设定一个推荐的 gfp_mask,用于指导后续的 alloc_pages 调用。
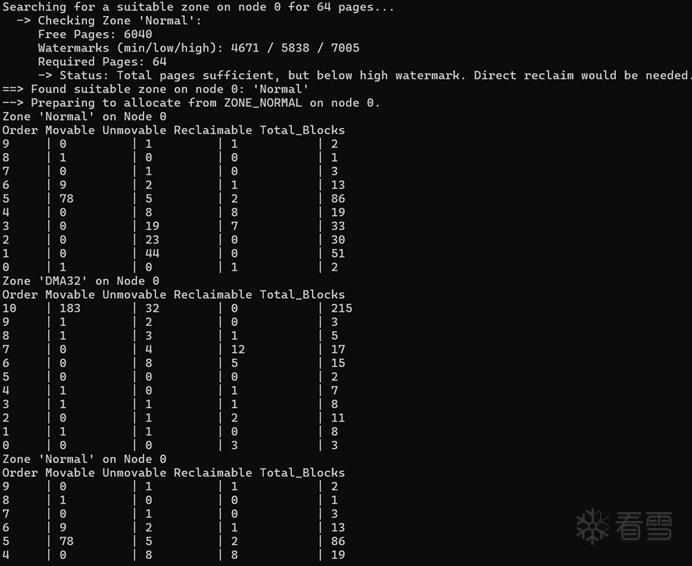
深入free_area:检查order级碎片化仅仅知道ZONE 的总空闲页数是不够的,高阶分配失败的真正原因往往是碎片化。为了验证这一点,我实现了一套函数,用于直接查看zone->free_area 这个伙伴系统的核心数据结构,统计每个order下的空闲块数量。
static void collect_order_entry(struct free_area *free_area, struct order_entry_stats *entry_stats)
{
struct list_head *head;
int type;
if (!free_area) {
pr_err("Failed to free_area is null\n");
return;
}
memset(entry_stats, 0, sizeof(struct order_entry_stats));
for (type = 0; type < MIGRATE_TYPES; type++) {
head = &free_area->free_list[type];
if (!list_empty(head)) {
struct list_head *pos;
list_for_each(pos, head) {
entry_stats->counts[type]++;
}
}
entry_stats->total_blocks += entry_stats->counts[type];
}
}
static void inspect_zone_order(struct zone *zone)
{
struct free_area *free_area;
int order;
unsigned long flags;
memset(all_order_stats, 0, sizeof(all_order_stats));
spin_lock_irqsave(&zone->lock, flags);
for (order = MAX_SEGMENT_ORDER; order >= 0; order--) {
free_area = &zone->free_area[order];
collect_order_entry(free_area, &all_order_stats[order]);
all_order_stats[order].order = order;
}
spin_unlock_irqrestore(&zone->lock, flags);
}
这里的核心是inspect_zone_order函数。它首先获取 zone->lock 自旋锁,以保证在检查期间free_area 链表不会被并发修改。然后,它遍历从order = 10到order = 0的所有阶,对每一阶的free_area调用collect_order_entry。collect_order_entry 则负责遍历该 order 下所有 migratetype(如 MOVABLE, UNMOVABLE 等)的空闲链表,并统计数量。所有这些统计信息被汇总到 all_order_stats 数组中。在 handle_node_zone_order 这个 ioctl 处理函数中,这些采集到的原始数据最终被 copy_to_user 传递给应用层,由应用层进行格式化的打印。通过这个功能,我就能精确地知道,某个ZONE看起来有很多空闲内存,但实际上可能没有任何order = 9或 order = 10的大块,从而用数据证实了碎片化的在。
采集free_area中每个page的详细信息
统计order级别的块数量可以帮我们判断碎片化,但要真正看到 PFN 的分布,就需要深入到 free_list 链表中,采集每一个 struct page 的信息。这由另一套 ioctl 接口和对应的 LKM 函数实现。
static int collect_free_pages_from_area(struct free_area *free_area,
struct page **temp_buffer,
uint32_t buffer_size,
uint32_t *current_idx_ptr)
{
struct list_head *source_list;
struct page *page;
int type;
if (!free_area || !temp_buffer || !current_idx_ptr) return -EINVAL;
for (type = 0; type < MIGRATE_TYPES; type++) {
source_list = &free_area->free_list[type];
list_for_each_entry(page, source_list, lru) {
if (*current_idx_ptr < buffer_size) {
temp_buffer[*current_idx_ptr] = page;
(*current_idx_ptr)++;
} else {
return 0; // Buffer full
}
}
}
return 0;
}
static void inspect_zone_free_pages(struct zone *zone,
struct page **temp_buffer,
uint32_t buffer_size,
uint32_t *collected_count_ptr)
{
int order;
unsigned long flags;
spin_lock_irqsave(&zone->lock, flags);
for (order = 0; order < NR_ORDERS; order++) {
if (*collected_count_ptr >= buffer_size) break;
collect_free_pages_from_area(&zone->free_area[order], temp_buffer,
buffer_size, collected_count_ptr);
}
spin_unlock_irqrestore(&zone->lock, flags);
}
static void parse_node_free_pages(int node_id, enum zone_type z_type,
struct page **temp_buffer,
uint32_t buffer_size,
uint32_t *collected_count_ptr)
{
pg_data_t *pgdat = NODE_DATA(node_id);
struct zone *zone = NULL;
if (!pgdat || z_type >= MAX_NR_ZONES) return;
zone = &pgdat->node_zones[z_type];
if (zone && populated_zone(zone)) {
inspect_zone_free_pages(zone, temp_buffer, buffer_size,
collected_count_ptr);
}
}
以上函数涉及到在内核和用户空间之间传递数据。handle_node_zone_page_data这个ioctl处理函数采用了一个两步走的策略:
第一步ioctl(PHYS_MEM_GET_FREE_PAGES_COUNT): 先调用一个ioctl,在 LKM 内部计算出指定ZONE中总共有多少个 free_block。
第二步 ioctl(PHYS_MEM_GET_FREE_PAGES_DATA): 应用层根据上一步得到的总数,分配一个足够大的缓冲区。然后再次调用ioctl,将缓冲区指针传给内核。LKM 此时才调用parse_node_free_pages->inspect_zone_free_pages->collect_free_pages_from_area 这一系列的函数。
collect_free_pages_from_area在持有zone->lock 的情况下,安全地遍历free_list,并将找到的struct page指针暂存到一个 LKM 内部的临时缓区temp_pages_buffer(通过kvmalloc分配)中。在所有采集完成、锁被释放后,handle_node_zone_page_data再遍历这个temp_pages_buffer,为每个page提取出pfn等信息,填充到一个平坦结构体中,最后通过 copy_to_user 发送给应用层。通过ioctl接口,我能安全地获取到内核 Buddy system最底层的、最详细的状态信息。
对应的应用层代码如下:
static char *migrate_type_string(int migrate_type)
{
switch(migrate_type)
{
case MIGRATE_MOVABLE:
return "MOVABLE";
case MIGRATE_UNMOVABLE:
return "UNMOVABLE";
case MIGRATE_RECLAIMABLE:
return "RECLAIMABLE";
}
return "UNKNOW MIGRATE";
}
static char *zone_type_string(int zone_type)
{
switch(zone_type)
{
case ZONE_NORMAL:
return "NORMAL";
case ZONE_DMA32:
return "DMA32";
case ZONE_DMA:
return "DMA";
}
return "UNKNOW ZONE";
}
int ioctl_krnl_zone_order_stats(int fd, int node_id, enum zone_type z_type)
{
struct zone_inspect_req req;
struct order_entry_stats stats_buffer[NR_ORDERS];
int ret;
memset(&req, 0, sizeof(req));
req.node_id = node_id;
req.zone_type = z_type;
req.user_buffer = (uint64_t)(uintptr_t)stats_buffer;
req.buffer_len = NR_ORDERS;
printf("\n--- Requesting Order Stats for Node %d, Zone %d ---\n", node_id, z_type);
ret = ioctl(fd, PHYS_MEM_GET_ORDER_STATS, &req);
if (ret < 0) {
perror("ioctl(PHYS_MEM_GET_ORDER_STATS) failed");
return -1;
}
printf(" Order | Movable | Unmovable | Reclaimable | Total Blocks\n");
printf(" ----------------------------------------------------------\n");
for (int i = 0; i < NR_ORDERS; i ++) {
int order = NR_ORDERS - 1 - i;
struct order_entry_stats *stats = &stats_buffer[order];
if (stats->total_blocks > 0) {
printf(" %-5d | %-9d | %-9d | %-11d | %d\n",
stats->order,
stats->counts[MIGRATE_MOVABLE],
stats->counts[MIGRATE_UNMOVABLE],
stats->counts[MIGRATE_RECLAIMABLE],
stats->total_blocks);
}
}
return 0;
}
long ioctl_krnl_zone_free_pages_count(int fd, int node_id, enum zone_type z_type)
{
struct zone_inspect_req req;
int ret;
memset(&req, 0, sizeof(req));
req.node_id = node_id;
req.zone_type = z_type;
ret = ioctl(fd, PHYS_MEM_GET_FREE_PAGES_COUNT, &req);
if (ret < 0) {
perror("ioctl failed");
return -1;
}
return (long)req.result_count;
}
int ioctl_krnl_zone_free_pages_data(int fd, int node_id, enum zone_type z_type, long page_count)
{
struct zone_inspect_req req;
struct user_free_page_entry *data_buffer = NULL;
int ret;
if (page_count <= 0) {
printf("No pages to fetch.\n");
return -1;
}
data_buffer = malloc(page_count * sizeof(struct user_free_page_entry));
if (!data_buffer) {
perror("malloc failed");
return -1;
}
memset(&req, 0, sizeof(req));
req.node_id = node_id;
req.zone_type = z_type;
req.user_buffer = (uint64_t)(uintptr_t)data_buffer;
req.buffer_len = page_count;
ret = ioctl(fd, PHYS_MEM_GET_FREE_PAGES_DATA, &req);
if (ret < 0) {
perror("ioctl ailed");
free(data_buffer);
return -1;
}
fprintf(stdout, "\nNUMA node:%d ZONE: %s free page count: %ld\n", node_id,
zone_type_string(z_type),
page_count);
for (int page_idx = 0; page_idx < page_count; page_idx ++) {
fprintf(stdout, "order: %-2d %-11s real PFN:0x%lx struct page: %p\n",
data_buffer[page_idx].order,
migrate_type_string(data_buffer[page_idx].migratetype),
data_buffer[page_idx].pfn,
data_buffer[page_idx].struct_page_vaddr
);
}
return 0;
}
int inspect_krnl_node_zone_free_pages(int dev_fd, int node_id)
{
int rt = -1;
long count;
if (dev_fd < 0 || node_id < 0)
return rt;
ioctl_krnl_zone_order_stats(dev_fd, node_id, ZONE_NORMAL);
ioctl_krnl_zone_order_stats(dev_fd, node_id, ZONE_DMA32);
count = ioctl_krnl_zone_free_pages_count(dev_fd, 0, ZONE_NORMAL);
if (count > 0 ) {
ioctl_krnl_zone_free_pages_data(dev_fd, node_id, ZONE_NORMAL, count);
}
count = ioctl_krnl_zone_free_pages_count(dev_fd, node_id, ZONE_DMA32);
if (count > 0 ) {
ioctl_krnl_zone_free_pages_data(dev_fd, node_id, ZONE_DMA32, count);
}
count = ioctl_krnl_zone_free_pages_count(dev_fd, node_id, ZONE_DMA);
if (count > 0 ) {
ioctl_krnl_zone_free_pages_data(dev_fd, node_id, ZONE_DMA, count);
}
return 0;
}
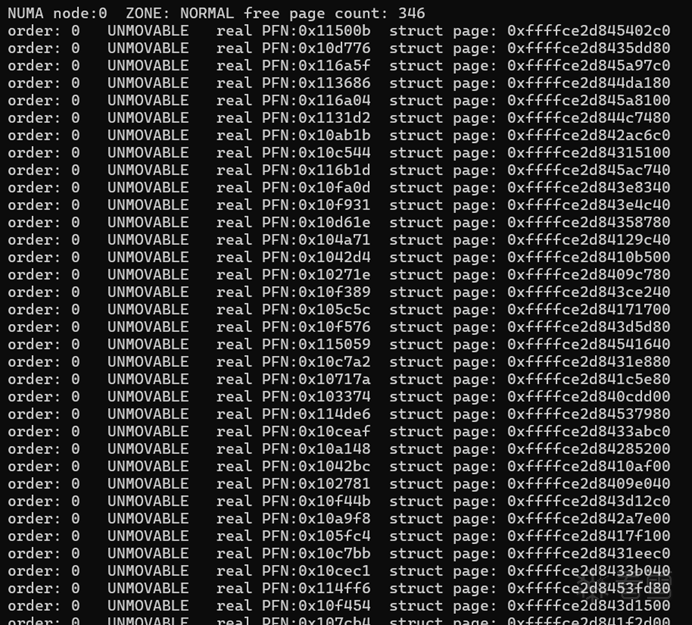
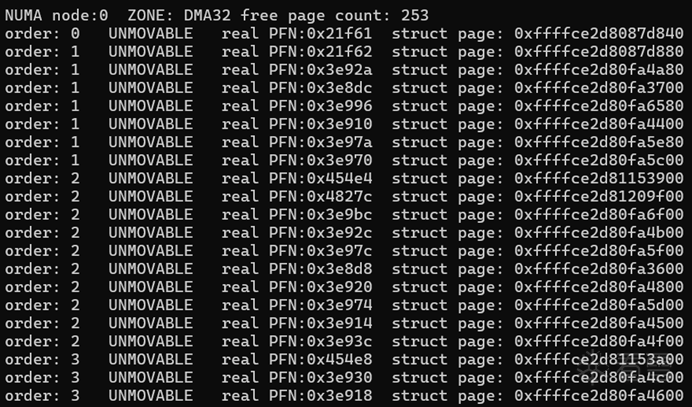
上面两幅图片是输出效果,分别给出了 ZONE_NORMA 与 ZONE_DMA32 的剩余页面数量和各 order 中的页面分布详细信息。
分配、隔离与验证
在深入研究了内核的内存模型,并手动实现了 pfn <-> page 的转换之后,现在回到我这个 LKM 的核心任务上来。它的主要职责,就是作为应用层物理内存管理器的资源提供者,负责从当前内核的Buddy system中申请、隔离并验证物理内存块,为上层应用准备好“原材料”。
per NUMA node segment的管理结构
为了管理从内核中申请到的每一块 4MB 内存,我在 LKM 内部定义了一个核心的管理结构 phys_mem_segment。这个结构体在 LKM 加载时,会形成一个数组 phys_mem_regions,用于记录所有被我们接管的物理内存段的信息。值得强调的是,这个结构体的定义需要与应用层中用于接收 ioctl 信息的结构体保持一致,以确保数据能正确传递。
struct phys_mem_segment {
unsigned long base_pfn;
unsigned long base_vpfn;
unsigned long npages;
unsigned int numa_node;
unsigned int segment_size;
unsigned int segment_id;
……
};
这个结构是 LKM 内部管理的核心,它的一项重要任务就是通过ioctl将base_pfn和numa_node等关键信息传递给用户空间,作为建立 vPFN -> real PFN 映射的基础。
验证segment内部 PFN 的连续性
内核的alloc_pages(..., order) API 承诺返回一块物理上连续的内存。对于order=10的请求,这意味着它应该返回 1024 个连续的 PFN。我们可以坚定信任内核的这个承诺,但在一个旨在“透彻理解”的项目中,还是需眼见为实。为此,我编写了一套验证函数,其核心 pfn_line_mapped 用于检查一个给定的 segment 内部,PFN 是否真正连续。
static bool pfn_line_mapped(uint64_t start_pfn)
{
bool rt_continue = true;
int max_pfn = (1UL << MAX_ALLOC_ORDER);
uint64_t prev_pfn;
int pfn_idx;
for (pfn_idx = 0; pfn_idx < max_pfn; pfn_idx++) {
struct page *current_page = sparse_model_pfn_to_page(start_pfn + pfn_idx);
uint64_t current_pfn;
if (!current_page) {
pr_err("pfn_line_mapped: sparse_model_pfn_to_page failed for PFN 0x%lx\n",
start_pfn + pfn_idx);
rt_continue = false;
break;
}
current_pfn = sparse_model_page_to_pfn(current_page);
if (current_pfn != (start_pfn + pfn_idx)) {
pr_err("pfn_line_mapped: Asymmetry detected! Expected 0x%lx, got 0x%llx\n",
start_pfn + pfn_idx, current_pfn);
rt_continue = false;
break;
}
if (pfn_idx > 0) {
if (current_pfn != prev_pfn + 1) {
rt_continue = false;
break;
}
}
prev_pfn = current_pfn;
}
return rt_continue;
}
这个函数的验证逻辑非常严格。它不仅仅是检查 page_to_pfn 返回的值是否递增,而是进行了两重验证:
1.对称性验证: 它首先验证 sparse_model_page_to_pfn(sparse_model_pfn_to_page(pfn))是否等于 pfn。这确保了我们自己实现的 pfn <-> page 转换函数是正确工作的。
2.连续性验证:在对称性得到保证的前提下,它再检查由 start_pfn 开始的 1024 个PFN,经过这一轮“转换之旅”后,是否仍然保持着 prev_pfn + 1 的完美线性关系。
在此基础上,需对每个 NUMA node 中分配到的物理页面进行验证,于是我又编写了node_segment_pfn_line_mapped 和check_node_all_segment_pfn_continue,以便能通过 ioctl 从用户空间触发对单个 NUMA node上所有已分配 segment 的批量连续性检查。
static bool node_segment_pfn_line_mapped(uint64_t start_seg_idx,
uint64_t end_seg_idx)
{
struct phys_mem_segment *phys_mem_seg;
int start_idx = start_seg_idx;
int end_idx = end_seg_idx;
if (!phys_mem_regions) {
pr_err("Failed to phys_mem_regions not init\n");
return false;
}
if ((start_seg_idx >= end_seg_idx) || (end_seg_idx > total_regions_allocated)) {
pr_err("Failed to invalid start idx %d end idx %d\n", (int)start_idx, (int)end_idx);
return false;
}
while (start_idx < end_idx) {
phys_mem_seg = &phys_mem_regions[start_idx];
if (phys_mem_seg && phys_mem_seg->base_pfn > 0) {
bool rt_continue = pfn_line_mapped(phys_mem_seg->base_pfn);
if (!rt_continue) {
pr_err("SEGMENT %d PFN sequence is not continuous!\n", start_idx);
return false;
}
}
start_idx++;
}
return true;
}
static bool check_node_all_segment_pfn_continue(void)
{
bool rt = false;
int start_seg_idx = 0;
int end_seg_idx = total_regions_allocated;
rt = node_segment_pfn_line_mapped(start_seg_idx, end_seg_idx);
return rt;
}
通过这套机制,我就能在 LKM 层面,对自己从内核获取的每一 segment 连续性进行严格的检验,确保传递给应用层的数据是可靠的。这也为我们后续在应用层基于 vPFN 建立模型的正确性,提供了最底层的保障。
为应用层提供物理内存
在完成了对内核物理内存管理机制的理论探索和状态分析之后,现在进入 LKM 的核心实现环节。这里的目标是,编写一组函数,从内核Buddy system中分批申请 order 为 10 的物理内存,并重映射到应用层。
构建 segment 物理内存管理结构
static int alloc_physmem_regions(void)
{
int page_idx;
int meta_order;
int node;
int allocated_count = 0;
int rt = -1;
int prep_rt;
gfp_t gfp_mask_for_node = 0;
meta_order = get_order(PHYS_META_SIZE);
node = numa_node_id();
prep_rt = prepare_node_allocation(node, &gfp_mask_for_node, meta_order, 0);
if (prep_rt != 0) {
pr_err("Preparation failed for node %d, skipping.\n", node);
goto out;
}
if (buddy_alloc_trace) {
parse_node_zone_order(node, GFP_KERNEL);
parse_node_zone_order(node, __GFP_DMA32);
}
phys_meta_pages = alloc_pages(GFP_KERNEL | __GFP_HIGH, meta_order);
if (!phys_meta_pages) {
pr_err("Failed to allocate metadata pages meta order:%d\n", meta_order);
goto out;
}
if (buddy_alloc_trace) {
parse_node_zone_order(node, GFP_KERNEL);
parse_node_zone_order(node, __GFP_DMA32);
}
for (page_idx = 0; page_idx < (1 << meta_order); page_idx++) {
SetPageReserved(phys_meta_pages + page_idx);
}
meta_pfn_base = sparse_model_page_to_pfn(phys_meta_pages);
for_each_online_node(node) {
prep_rt = prepare_node_allocation(node, &gfp_mask_for_node, MAX_SEGMENT_ORDER, SEGMENTS_PER_NODE);
if (prep_rt != 0) {
pr_warn("Preparation failed for node %d, skipping.\n", node);
continue;
}
while (allocated_count < max_total_segments) {
per_segment_pages[allocated_count] = alloc_pages_node(node, gfp_mask_for_node, MAX_SEGMENT_ORDER);
if (!per_segment_pages[allocated_count]) {
pr_warn("Allocate failed on node %d.\n", node);
break;
}
if (buddy_alloc_trace) {
parse_node_zone_order(node, gfp_mask_for_node);
}
phys_mem_regions[allocated_count].base_pfn = sparse_model_page_to_pfn(per_segment_pages[allocated_count]);
phys_mem_regions[allocated_count].numa_node = page_to_nid(per_segment_pages[allocated_count]);
if (phys_mem_regions[allocated_count].base_pfn % (1UL << MAX_SEGMENT_ORDER) != 0) {
pr_warn("PFN 0x%llx from node %d is not 4MB aligned, freeing and skipping.\n",
(uint64_t)phys_mem_regions[allocated_count].base_pfn, node);
__free_pages(per_segment_pages[allocated_count], MAX_SEGMENT_ORDER);
per_segment_pages[allocated_count] = NULL;
continue;
}
phys_mem_regions[allocated_count].npages = 1 << MAX_SEGMENT_ORDER;
for (page_idx = 0; page_idx < phys_mem_regions[allocated_count].npages; page_idx++) {
SetPageReserved(per_segment_pages[allocated_count] + page_idx);
}
pr_info("SEGMENT %d allocated on node %d base PFN 0x%lx\n",
allocated_count, node, phys_mem_regions[allocated_count].base_pfn);
allocated_count++;
}
if (allocated_count >= max_total_segments) {
break;
}
}
total_regions_allocated = allocated_count;
if (total_regions_allocated < max_total_segments) {
pr_err("Could not allocate all %d segments. only %d.\n",
max_total_segments, total_regions_allocated);
goto out_free_all;
}
rt = 0;
goto out;
out_free_all:
free_physmem_regions();
rt = -ENOMEM;
out:
return rt;
}
这个函数的工作流程体现了“为应用层服务”的目的。首先,它会为应用层的元数据数组(g_mem_map)本身分配物理内存。接着,通过for_each_online_node 循环,在 NUMA 节点上重复调用alloc_pages_node,申请 order=10 (4MB) 的连续物理内存块,直到max_total_segments 个segment被完全分配。每次分配成功,就将base_pfn和numa_node等信息存入phys_mem_regions 数组的对应槽位中。最关键的一步,是通过循环调用 SetPageReserved,将这些物理页面的管理权从内核伙伴系统中剥离,以防止内核回收或移动这些内存。
重映射物理页面到应用层
static int mapphys_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret = 0;
uint64_t segment_size = SEGMENT_SIZE_MB * 1024 * 1024;
uint64_t meta_size = PHYS_META_SIZE;
uint64_t expected_size = (max_total_segments * segment_size) + meta_size;
uint64_t curr_start_virt = vma->vm_start;
uint64_t size = vma->vm_end - vma->vm_start;
int seg_idx;
if (size != expected_size) {
pr_err("Invalid size: 0x%llx, expected 0x%llx\n", size, expected_size);
return -EINVAL;
}
for (seg_idx = 0;
seg_idx < total_regions_allocated;
seg_idx++) {
ret = remap_pfn_range(vma,
curr_start_virt,
phys_mem_regions[seg_idx].base_pfn,
segment_size,
vma->vm_page_prot
);
if (ret) {
pr_err("remap_pfn_range failed at segment %d\n", seg_idx);
goto end;
}
curr_start_virt += segment_size;
}
ret = remap_pfn_range(vma,
curr_start_virt,
meta_pfn_base,
meta_size,
vma->vm_page_prot
);
if (ret) {
pr_err("meta remap_pfn_range failed (PFN 0x%llx)\n", (uint64_t)meta_pfn_base);
goto end;
}
curr_start_virt += meta_size;
end:
printk(KERN_ALERT "start:0x%llx size:0x%llx ret=%d\n", curr_start_virt, segment_size, ret);
return ret;
}
重映射后,应用层就获得了它所需要的一切:一块 128MB(或根据 NUMA 节点数更多)的、虚拟地址连续的内存区域,以及一块用于存放metadata的区域。这块区域背后的物理内存已经从内核中安全地隔离了出来。至此,LKM 作为“资源供应商”的任务完成,后续工作完全交给了应用层。
回收 segment 物理页面
static void free_physmem_regions(void)
{
int seg_idx, page_idx;
int meta_order = get_order(PHYS_META_SIZE);
if (phys_meta_pages) {
for (page_idx = 0; page_idx < (1 << meta_order); page_idx++) {
ClearPageReserved(phys_meta_pages + page_idx);
}
__free_pages(phys_meta_pages, meta_order);
phys_meta_pages = NULL;
}
for (seg_idx = 0; seg_idx < total_regions_allocated; seg_idx++) {
if (per_segment_pages[seg_idx]) {
for (page_idx = 0; page_idx < phys_mem_regions[seg_idx].npages; page_idx++) {
ClearPageReserved(per_segment_pages[seg_idx] + page_idx);
}
__free_pages(per_segment_pages[seg_idx], MAX_SEGMENT_ORDER);
per_segment_pages[seg_idx] = NULL;
}
}
total_regions_allocated = 0;
}
释放的逻辑先处理元数据页面,然后在一个循环中处理所有的数据segment。对于每一块被我们接管的内存,都必须执行两个核心操作:
ClearPageReserved: 这是一个至关重要的步骤。它相当于通知内核,这块内存的管理权被交还。如果没有这一步,free_pages会失败,因为内核不允许释放一个处于“保留”状态的页面。__free_pages: 在解除保留状态后,我们调用 __free_pages,将这块 4MB 的连续内存交还给内核的伙伴系统。伙伴系统会接收它,并尝试将它与周围的空闲伙伴块进行合并。
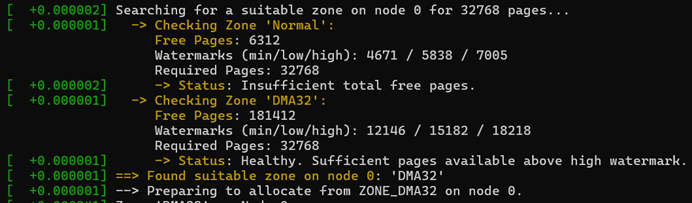
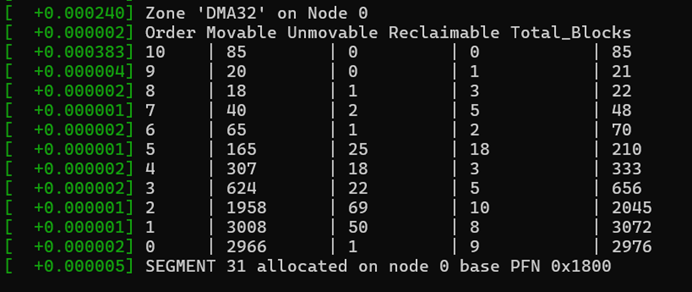
申请过程可以看到对于 128M 的物理内存页面,NORMAL的ZONE 提示页面不足,最后都是在 DMA32 ZONE 中找到的页面。
构建应用层物理内存模型
首先需要定义一套宏和常量,它们是我们整个应用层管理体系的基石。
#define VIRT_ADDR_BASE ((void*)0x00007f0000000000)
#define MEM_MAP_MODEL_BASE ((void*)0x00007f0008000000)
#define VPFN_TO_PFN_MAP_BASE ((void*)0x00007f0008040000)
#define PFN_TO_VPFN_MAP_BASE ((void*)0x00007f0008080000)
这里,我选择了一段位于0x00007f0000000000的高位虚拟地址作为我们整个管理系统的固定基地址。VIRT_ADDR_BASE是128MB物理内存被映射到的虚拟地址空间的起始点。紧随其后的是MEM_MAP_MODEL_BASE,这个地址存放的是我们自己的struct phys_page元数据数组(等同于内核的 struct page)用于跟踪描述 page frame 状态,这与内核FLATMEM模型中的mem_map在概念上是完全一致的。VPFN_TO_PFN_MAP_BASE和PFN_TO_VPFN_MAP_BASE这两个地址的存在,是为了解决我这个应用层模型的核心问题而设计的。因为引入了vPFN (虚拟页帧号) 概念,用这个连续的索引来桥接那些real PFN (真实页帧号)。之前段落提到过,跨segment 导致每个 base_pfn 是不一致的,所以我必须在它们之间建立一个双向的、可快速查询的映射关系:
VPFN_TO_PFN_MAP_BASE: 指向一个正向查找表。这个表是一个数组,可以用 vPFN 作为索引,O(1) 地查到它对应的 real PFN。
PFN_TO_VPFN_MAP_BASE: 指向一个反向查找表。这个表可以用 real PFN 作为索引,O(1) 地查到它对应的 vPFN。
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
赞赏
|
|
|---|---|
|
|
感谢分享。
|
|
|
niubility
|
|
|
写论文呢
|
|
|
|





