:::color2在开始这篇文章之前,请阅读一下注意事项本文章仅用于学习研究,如有侵犯贵司权益,请联系告知,会立即做出下架删除处理。本文章不针对任何网站,APP ,禁止用于商业,转载,违法等用途。观看则默认同意本约定,未经允许禁止任何形式的转载,保留追究法律责任的权利,
:::
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
package com;
import com.github.unidbg.AndroidEmulator;
import com.github.unidbg.Emulator;
import com.github.unidbg.LibraryResolver;
import com.github.unidbg.Module;
import com.github.unidbg.arm.backend.Unicorn2Factory;
import com.github.unidbg.debugger.Debugger;
import com.github.unidbg.file.FileResult;
import com.github.unidbg.file.IOResolver;
import com.github.unidbg.linux.android.AndroidEmulatorBuilder;
import com.github.unidbg.linux.android.AndroidResolver;
import com.github.unidbg.linux.android.dvm.*;
import com.github.unidbg.memory.Memory;
import com.github.unidbg.virtualmodule.android.AndroidModule;
import com.github.unidbg.virtualmodule.android.JniGraphics;
import com.github.unidbg.virtualmodule.android.MediaNdkModule;
import com.github.unidbg.virtualmodule.android.SystemProperties;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
public class 模板 extends AbstractJni implements IOResolver {
private static final String PackName = "APP 包名";
private static final String AppPath = "传入 APP路径";
private static final String[] SoName = {"SO名字或外部路径"};
private final AndroidEmulator emulator;
private final VM vm;
private final Module module;
final Memory memory;
@Override
public FileResult resolve(Emulator emulator, String pathname, int oflags) {
System.out.println("Load File: " + pathname);
return null;
}
private static LibraryResolver createLibraryResolver() {
return new AndroidResolver(23);
}
private static AndroidEmulator createARMEmulator() {
return AndroidEmulatorBuilder.for64Bit()
.setProcessName(PackName)
.addBackendFactory(new Unicorn2Factory(false))
.build();
}
模板 () {
emulator = createARMEmulator();
emulator.getSyscallHandler().addIOResolver(this);
memory = emulator.getMemory();
memory.setLibraryResolver(createLibraryResolver());
vm = emulator.createDalvikVM(new File(AppPath));
new AndroidModule(emulator,vm).register(memory);
new MediaNdkModule(emulator,vm).register(memory);
new JniGraphics(emulator,vm).register(memory);
vm.setJni(this);
vm.setVerbose(true);
DalvikModule dm = vm.loadLibrary(SoName[0], true);
module = dm.getModule();
dm.callJNI_OnLoad(emulator);
};
public static void main(String[] args) {
模板 action = new 模板();
action.Call();
}
public void Call () {
List<Object> args = new ArrayList<>();
args.add(vm.getJNIEnv());
args.add(0);
args.add(vm.addLocalObject(new StringObject(vm, "123456")));
args.add(vm.addLocalObject(new StringObject(vm, "")));
Number result = module.callFunction(emulator, 0x236c, args.toArray());
DvmObject<?> returnObj = vm.getObject(result.intValue());
String encrypted = ((StringObject) returnObj).getValue();
System.out.println("Encrypted String: " + encrypted);
}
}
逻辑分析 :::warningUnidbg 或者是 看伪 C 进行分析 会适当的引入分析trace文件, 从简单的部分提前锻炼阅读trace文件的能力给后面app铺垫
:::
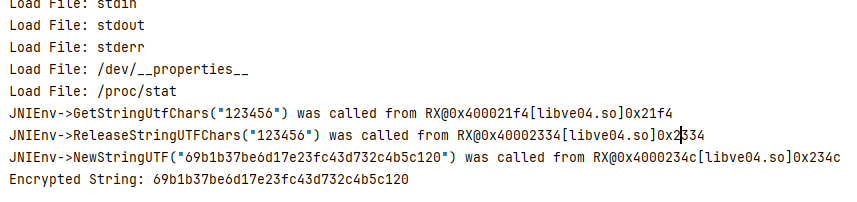
调用结果打印
该So 是静态注册的 函数 这个就可以自己去找一下, Java层的分析,除了特别有特点的部分,基本上文件中不会引入和讲解 本案例中,直接关注该方法 CustAmuCrpty
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
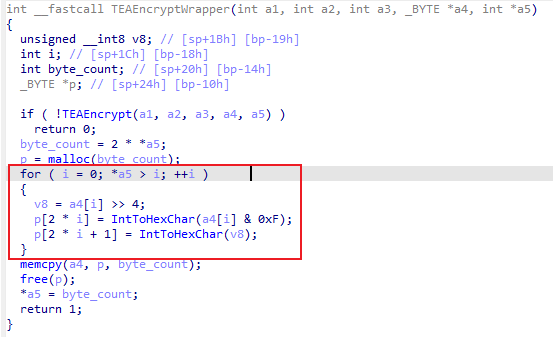
jstring CustAmuCrpty(JNIEnv *a1, int a2, const char *a3, void *a4, int a5, ...)
{
size_t v5;
size_t v6;
int v11;
jstring v12;
const char *v13;
size_t byte_count;
char *v15;
void *p;
v13 = &unk_3A74;
v15 = (*a1)->GetStringUTFChars(a1, a4, 0);
if ( v15 )
{
byte_count = 0;
if ( a5 == 1 )
byte_count = 3 * strlen(v15) + 32;
else
byte_count = strlen(v15);
p = malloc(byte_count);
v11 = 0;
if ( a5 == 1 )
{
v5 = strlen(v15);
if ( TEAEncryptWrapper(v15, v5, a3, p, &v11) )
{
*(p + v11) = 0;
v13 = p;
}
}
else
{
v6 = strlen(v15);
if ( TEADecryptWrapper(v15, v6, a3, p, &v11) )
{
*(p + v11) = 0;
v13 = p;
}
}
(*a1)->ReleaseStringUTFChars(a1, a4, v15);
v12 = (*a1)->NewStringUTF(a1, v13);
free(p);
}
return v12;
}
Java 静态注册的函数
入参1: JNIEnv # 如果IDA版本小于7.7 可能需要自己手动修改类型 快捷键 Y
入参2: JClass
分析当前的 伪代码 其实逻辑是非常清晰的strlen(v15) 那么v15就是入参值v5 就是输入明文的长度先把这一块的内容 简单记忆一下就继续开始倒推
Trace So 调用 :::warning
:::
1
2
3
4
5
6
7
8
9
10
11
public void Trace(){
String traceFile = "trace_sign.txt";
PrintStream traceStream = null;
try{
traceStream = new PrintStream(new FileOutputStream(traceFile), true);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
emulator.traceCode(module.base,module.base+module.size).setRedirect(traceStream);
}
直接开启Trace 固定的调用一组相同的入参就好。Trace 完毕的日志,就可以打开留作备用 Trace 就可以注释掉了。不要重复调用,没必要
返回结果?高低颠倒 :::warningTEAEncryptWrapper 函数中 开始逆推分析了 首先确定好的一件事是,Unidbg 多次调用 最终返回的结果 都是固定不变的,那么就排除随机/时间戳干扰
:::
首先 先记忆一个东西 叫** 高低颠倒** 怎么理解会好一点呢 假如说 张三 是一个字节 那么 **高低颠倒 **后 就叫做 三张 ,可以简单理解为 每个字节的反转 例如 0x6a 反转为 0xa6
这部分实际上实现的作用就是高低颠倒
无论是AI 还是 自己去HOOK 实际上都能直观的看到这部分的作用
那么就直接Hook 高低颠倒前的加密返回值和最终加密输出的结果 进行一次对比 就能明白了
选择Hook 的位置是 p = malloc(byte_count);
P的位置,为什么? 一会再讲
1
2
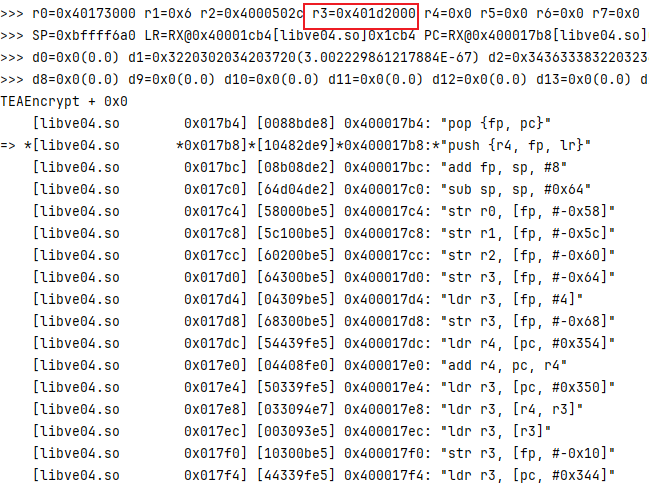
debugger.addBreakPoint(module.base+0x017b8);
debugger.addBreakPoint(module.base+0x01CE0);
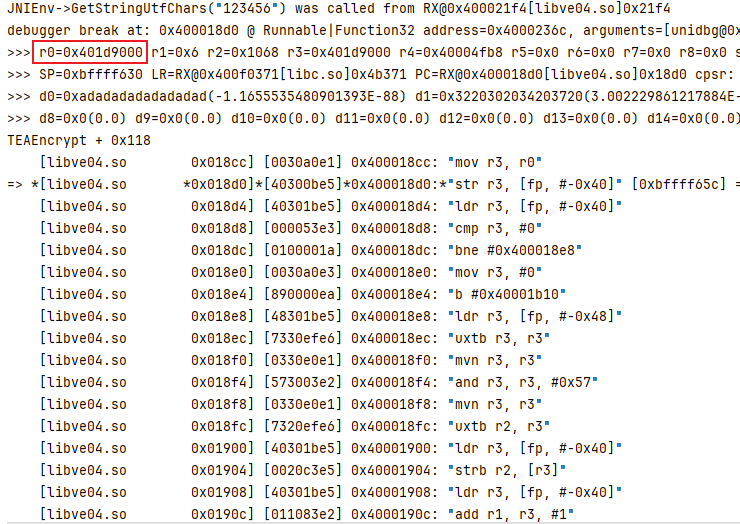
在 0x017b8 TEAEncrypt 调用 的时候 直接拿到返回值的地址 对应的是 r3 0x401d2000
如果 不知道为什么是 r3 就请把鼠标放到 a4 上面去
其实在这里再去打印 比较清晰的看到出来的结果 和最终输出的结果 实际上就是 每个字节反转 这也就是这个小节所说的 高低颠倒 那么这一部分就讲到这里,就不讲了。
这部分需要注意的点就是,Unidbg 断点 的灵活使用以及对各部分代码的灵活分析和忽略
tinyEncrypt 的前后文分析 这个部分为什么叫 tinyEncrypt 的前后文分析, 实际上,分析这个部分 我不建议就死扣一个函数分析,顺带的把该函数处在循环前后的地方都分析了,那么这部分将引入 Unidbg 部分 和 Trace 部分 分析内容
这部分 先简单来分析一下内容
在开始之前 先简单讲讲 tea算法
分组加密 每次加密的 明文 长度是8字节 传入加密的Key 长度是 16字节
首先能看到的 就是一个 for 循环
For 循环 有一个 循环条件
byte_count / 4 > i
I += 2
For 循环内 调用的算法是 tinyEncrypt
调用算法后 有经过几个运算
IDA 识别出来 tinyEncrypt 的入参是 四个 分别是
如果要分析 首先 这四个入参要闹明白
第一步 先从 v20 开始算起,v20 参与计算的有 p 有 i 有 v19 三个变量,那么怎么去分析呢?如果现在 你看我文章熟悉了,那么你就应该明白我下一步的骚操作了 首先 关注 p 是从哪来的 哪里被赋值的 p = malloc(byte_count); 是这里,那么 应该怎么处理呢? 直接在 p 这个字符下断点0x0180
一般情况下, malloc 函数 赋值给谁 谁的寄存器地址对应的就是 0 如果是arm64 就是 x0 如果是 arm 就是 r0
当然 这是我自己总结的情况,如果说错了 大佬别喷 只留一个断点当然不行,还有一个断点在哪里? 当然是 for 循环 for 开始的位置 0x019C4
1
2
debugger.addBreakPoint(module.base+0x018d0);
debugger.addBreakPoint(module.base+0x019c4);
还是很熟悉的操作昂 直接下断点 拿到对应 r0 的地址 直接复制 留到下一个断点打印 看看p 的值到底是什么
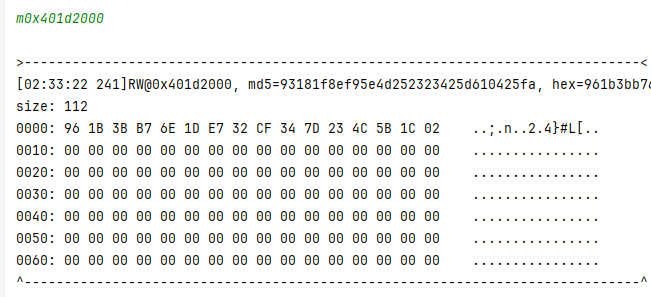
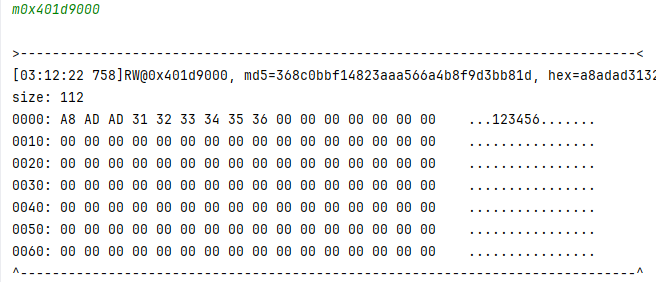
现在继续执行 走到下一个断点 开始打印 p 的值
结果很清晰 包含了输入的明文
1
2
3
4
A8 AD AD 31 32 33 34 35 36 00 00 00 00 00 00 00
# 能看到输入的 123456 也能看到末尾拼接的 7 个 0 这一组正好16个字节
# 关于末尾拼接的 7个0 实际上自己往上翻翻看就知道了,后面一会还会讲的
# 其他上面的逻辑 暂且先不管 我们先只关注 循环内的
P 值已经搞定了,那么接着看 ** i 和 v19**
其实关于 i 值呢 如果大家有分析一遍 伪代码的话 就能看出来 i 实际上是计算出来的,和输入的长度息息相关
但是 我这里 姑且 偷个懒 就先分析 明文数据是 123456 情况下的 i 值 那么有什么办法呢?
直接在 循环内 tinyEncrypt 函数打一个断点 看看 调用了 几次 就对应的是 i 值
还记得我们已经trace 出来的 日志吗? 为什么不利用起来?
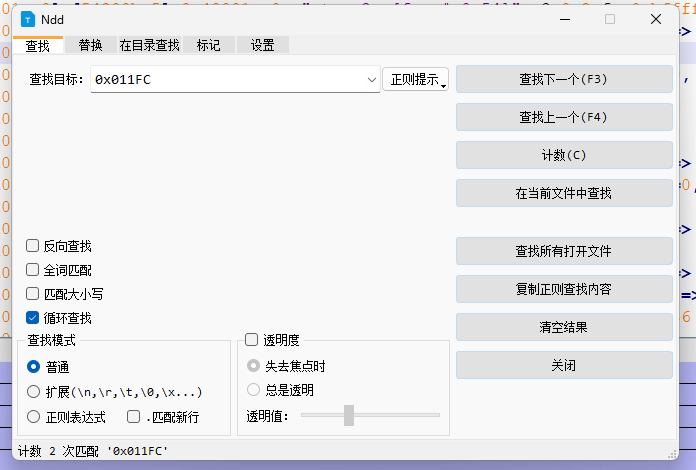
在这里 我就只讲一种 trace 日志 分析的办法 很简单 看看 tinyEncrypt 函数的地址 => 0x011FC 在文本里面直接检索查呗~
注意看 计数2 次匹配 0x011FC 但是呢 为了以防万一 还是要在文件内查找 看看 调用的所处的位置是不是在一个地方,避免被忽悠了。。。。
一次是在 270 行的地方 一次是在 1096行的地方 那么 就已经证实 就是调用了 两次 。那么 i 值就破案了!
**P 值 I 值**** 已经搞定了,那么接着看****v19**
**v19**** 呢实际上 不用看,自己动一动发财的小手,就能看到****v19**** 就是定义的两个****0**** 那么就直接这部分就通顺了**
** 开始写Python 代码**
1
2
3
4
5
6
7
8
p = [0xa8,0xad,0xad,0x31,0x32,0x33,0x34,0x35,0x36,0x00,0x00,0x00,0x00,0x00,0x00,0x00]
v19 = [0, 0]
for i in range(0, 4, 2):
v20 = struct.unpack_from('<I', bytearray(p), i * 4)[0] ^ v19[0]
v21 = struct.unpack_from('<I', bytearray(p), i * 4 + 4)[0] ^ v19[1]
print(hex(v20),hex(v21))
在这里 我在解释一下 Python代码为什么这么写,现在只关注第一次循环的结果是否为正确的就好了,因为第二次循环 v19 是被重新赋值了 那么 v20 和 v21 的值 肯定是不对的
p 和 v19 的定义 其实没有什么好解释的 就不多嘴了
for i in range(0, 4, 2): 这部分 为什么定义的是0,4,2 想一想,我们刚才已经分析出来了 在当前明文数据输入长度是 6 的 时候 循环内的次数是 2 再来看一眼伪C for ( i = 0; byte_count / 4 > i; i += 2 )
循环从 **0 **开始 每次累加 **2 **那么什么时候 byte_count / 4 > i 条件能够成立满足 当前循环次数是 **2 **呢?
那么 简单先简写出来 那不就是 循环的 最大值是 4 嘛 每次累加 2 循环两次就结束了~
1
2
3
4
v20 = struct.unpack_from('<I', bytearray(p), i * 4)[0] ^ v19[0]
v21 = struct.unpack_from('<I', bytearray(p), i * 4 + 4)[0] ^ v19[1]
现在 再来讲一讲 这两句,怎么才能对比 实际执行中 v20 和 v21 的值,目前 虽然是写好了,但是并不能肯定 这就是正确的值昂?,用 Unidbg Hook? Low low low 看 trace日志去
怎么看? 很简单,学完这点 你就认识我了。
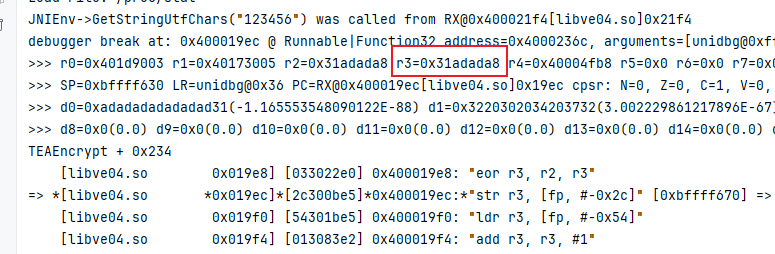
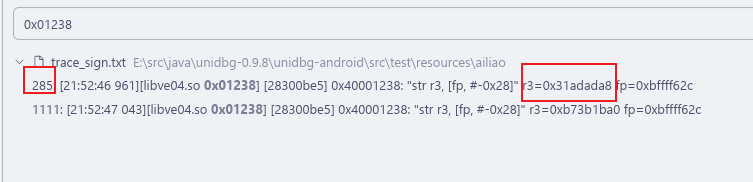
直接鼠标放到 v20 的值 上面去看它对应的地址是什么 这里 v20 对应的地址是 0x019ec 现在去 trace里面搜索
很显然么 第一次循环的时候 v20的值是 0x31adada8 第二次循环的时候 v20 的值是 0xb73b1ba0
**如果你要问我, 我就愿意用Unidbg 去看 那么我只能说 请看 汇编!!! **在 v20 所处的位置 直接切换到 汇编页面中去
很明显啊str指令是 赋值给了 r3 那么直接在 0x019EC 的位置下断点
没什么问题 验证成功
那么现在再切换回整体去 现在这块Python 代码是不是就没什么难度了 就比较清晰易懂了
附件 :
1. struct.unpack_from(format, buffer, offset=0) 这是 struct 模块的一个函数,用于从指定的偏移量(offset)开始,按照给定的格式(format)解析二进制数据(buffer)。
format:指定数据的解析格式,例如 '<I'(稍后解释)。buffer:一个 bytes-like 对象(如 bytes 或 bytearray),包含要解析的二进制数据。offset(可选):从 buffer 的哪个字节开始解析(默认是 0)。
2. '<I' 格式说明 '<I' 是一个 格式字符串,用于告诉 unpack_from 如何解析二进制数据:
<:表示 小端序(Little-Endian),即低位字节在前(Intel/AMD CPU 通常是小端序)。I:表示解析一个 无符号 32 位整数(unsigned int),即 4 字节。
3. 其他常见的格式字符:
'B':1 字节无符号整数'H':2 字节无符号整数'L':4 字节无符号整数(和 'I' 类似)'Q':8 字节无符号整数'f':4 字节浮点数'd':8 字节浮点数
:::success
现在开始关注 tinyEncrypt 算法调用的位置,在开始之前 还是强调一下,伪C就仅仅是伪C 它是伪代码!
:::
tinyEncrypt 具体加密过程 现在 继续分析,已经到了 tinyEncrypt 函数调用的位置 &v20 a3 v22 4
v20 刚才已经通过还原解决了,那么 a3 是什么? 实际上 通过阅读 整个 a3 得知,他就是 一层一层传递过来的,那么 有可能是 tea 加密的 key 直接 hook 他 先拿到数据 可以在 TEAEncrypt 函数开始的地方 直接下断点,具体为什么不在循环内的 传参调用下断呢? 这个地方 我再来解释一下。
在 阅读伪代码的时候,寄存器的标号,不能相信,如果同一个寄存器在代码片段跨度较大的时候,HOOK 只看寄存器是不可信的,可信的是地址,如有说错,轻点喷
1
debugger.addBreakPoint(module.base+0x017b8);
实际上 这个a3 就是 tea 加密的 key 上述我也讲过了,tea加密的 key 长度是 16字节 那么也就是这一段
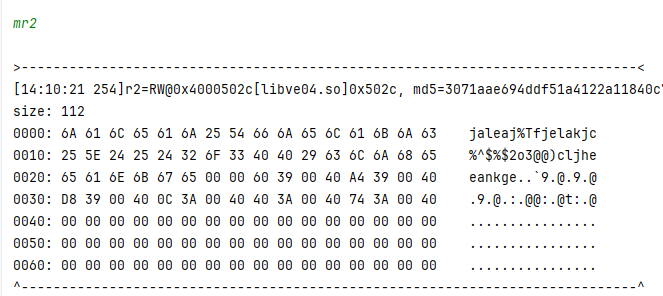
6A 61 6C 65 61 6A 25 54 66 6A 65 6C 61 6B 6A 63 这一段 先放到这里 等会手段讲解。
v22 呢 实际上 就是 tea加密的返回值 后面定义的立即数4 就不要管了。
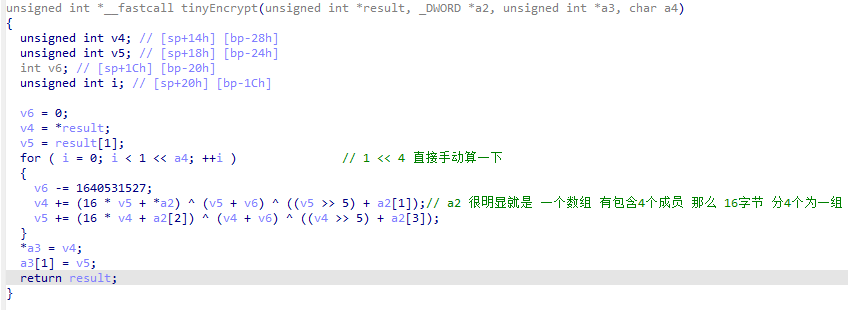
**开始分析 ****tinyEncrypt **函数
其实这块的代码。可以简洁的分析一下一部分的关键点,但是只看伪代码是不行的,要结合汇编代码去看才可以,先来关注一下 上一步传入的 v20在 这块伪代码中 很明显就能看到 v4 是 result[0] v5 是 result[1] 很明显 result 是一个数组 在数组中 如果不指出对应的索引 那么指向的内容就是 当前数组索引[0]的成员 现在 使用 trace日志 确定一下 这两个数组成员 都是什么,注意 现在目前还是在研究第一次循环 v4 地址 0x01238``v5 地址 0x01244
第一次循环 result 数组 包含成员 [0x31adada8,0x35343332] 那不就是 我们复现的代码中 计算出来 v20 和 v21 的值么?
再来看 循环条件 for ( i = 0; i < 1 << a4; ++i ) a4 是固定值 4 那么直接去py里面算一下不就好了 固定下来 print(1<<4) 结果是 16 再切换回汇编看一看
结合 汇编再来分析一下 里面的要点 需要关注的点就只有两个 一个是 v6 的值 一个是 左移 4 其实在汇编里面是能看到的,还原伪代码的时候 一定要结合汇编进行分析 那么就直接写python 还原一下这部分的代码
还是再提一下 a2 的值 在当前的伪代码中 其实很明显就能看得到 a2 的值也是一个数组, a2 参与了计算,那么上文的时候,我们已经通过 Unidbg Hook 的时候 已经找到了 a2 的入参 但是在当前里面的代码是一个数组,包含了4个成员,实际上就是 每4个字节分为一组,4组 正好16个字节,同样也可以去 trace 里面搜索一下这四个值
这部分 实际上 就是 最终加密的Key 数组,其实也能发现出来一定的细节,就是 总加密循环是两轮 其他的值都会发生变化,但是这个a2 不会变化,两轮 值都是一样的 那么现在就可以直接把这段值摘出来了.
1
2
3
4
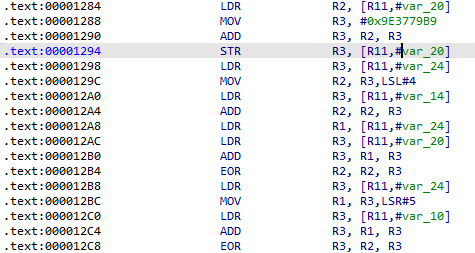
.text:00001284 LDR R2, [R11,#var_20]
.text:00001288 MOV R3, #0x9E3779B9
.text:00001290 ADD R3, R2, R3
.text:00001294 STR R3, [R11,#var_20]
1
2
3
4
5
6
7
8
9
10
11
def tiny_encrypt (result):
v4 = result[0] & 0xFFFFFFFF // 对齐
v5 = result[1] & 0xFFFFFFFF // 对齐
tea_key = [0x656c616a, 0x54256a61, 0x6c656a66, 0x636a6b61]
sum_val = 0
v6 = 0x9E3779B9
for _ in range(16):
sum_val = (sum_val + v6) & 0xFFFFFFFF
v4 = (v4 + (((v5 << 4) + tea_key[0]) ^ (v5 + sum_val) ^ ((v5 >> 5) + tea_key[1]))) & 0xFFFFFFFF
v5 = (v5 + (((v4 << 4) + tea_key[2]) ^ (v4 + sum_val) ^ ((v4 >> 5) + tea_key[3]))) & 0xFFFFFFFF
return [v4, v5]
验证方式 同样也可以直接在 trace 文件中 去搜一下
继续 while 循环内的部分 这部分 快整完了, 手敲累了都......
1
2
3
4
5
*(_DWORD *)&p[4 * i] = v22[0] ^ v17;
*(_DWORD *)&p[4 * i + 4] = v22[1] ^ v18;
memcpy(v19, &p[4 * i], sizeof(v19));
v17 = v20;
v18 = v21;
这部分伪代码的意图还是比较清晰的, 总结一下 v22[0] ^ v17 和 v22[1] ^ v18:让加密结果依赖前一轮明文 memcpy(v19, ...):让下一轮加密依赖前一轮密文 v17 = v20 和 v18 = v21:存储前一轮明文,用于下一轮混淆 这部分其实没有什么东西 直接还原就好了
1
2
3
4
5
6
7
8
cipher0 = v4 ^ v17
cipher1 = v5 ^ v18
struct.pack_into("<I", p, 4 * i, cipher0)
struct.pack_into("<I", p, 4 * i + 4, cipher1)
v19[0] = cipher0 #新 v19 为“当前写入的密文”(关键!)
v19[1] = cipher1 #新 v19 为“当前写入的密文”(关键!)
v17 = v20
v18 = v21
还是需要再总结一下,这部分代码最关键的内容就是 计算结果的写回, 对应的 python 代码中 也要注意这块的内容 例如 memcpy 实际上 就是 针对 前面 两段 小端序内容写写回 又赋值到 v19 中 去 这样正好解释了 为什么 v19 是一个两个成员的数组
:::success
:::
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
def tiny_encrypt (result):
v4 = result[0] & 0xFFFFFFFF
v5 = result[1] & 0xFFFFFFFF
tea_key = [0x656c616a, 0x54256a61, 0x6c656a66, 0x636a6b61]
sum_val = 0
v6 = 0x9E3779B9
for _ in range(16):
sum_val = (sum_val + v6) & 0xFFFFFFFF
v4 = (v4 + (((v5 << 4) + tea_key[0]) ^ (v5 + sum_val) ^ ((v5 >> 5) + tea_key[1]))) & 0xFFFFFFFF
v5 = (v5 + (((v4 << 4) + tea_key[2]) ^ (v4 + sum_val) ^ ((v4 >> 5) + tea_key[3]))) & 0xFFFFFFFF
return [v4, v5]
def tiny_init(str):
v17 = 0
v18 = 0
p = bytearray([0xa8,0xad,0xad,0x31,0x32,0x33,0x34,0x35,0x36,0x00,0x00,0x00,0x00,0x00,0x00,0x00])
v19 = [0, 0]
for i in range(0, 4, 2):
v20 = struct.unpack_from('<I', p, i * 4)[0] ^ v19[0]
v21 = struct.unpack_from('<I', p, i * 4 + 4)[0] ^ v19[1]
[v4, v5] = tiny_encrypt([v20,v21])
print("v20:"+ hex(v20),"v21: "+ hex(v21),"v4: "+ hex(v4),"v5: "+ hex(v5))
cipher0 = v4 ^ v17
cipher1 = v5 ^ v18
struct.pack_into("<I", p, 4 * i, cipher0)
struct.pack_into("<I", p, 4 * i + 4, cipher1)
v19[0] = cipher0
v19[1] = cipher1
v17 = v20
v18 = v21
return reverse_bytes_hex(p).decode('utf-8')
print(tiny_init("1"))
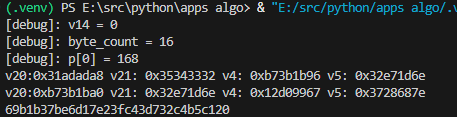
贴一下 实际运行的结果
这部分的内容 还是要多再啰嗦 总结一下, 实际上 并没有很多很高深的内容, 如果有 可能是 应该要对 python 的 一些基本代码,语法 多积累, 以及 不要盲目的全部相信伪C代码 可以结合工具 例如 Unidbg 和 Trace 日志 还有 汇编代码 结合 灵活的 去分析一段的内容.
在这篇文章中,也有不少 trace 日志 结合分析的内容出现, 也是为了 给后续文章, 分析某几个大厂app 的时候 做一定的基础铺垫 , 避免等到 后面的时候 看的懵掉.....
第二部分完成!!!!
明文拼接部分和计算循环次数分析 这部分的内容, 实际上 就是本篇文章的尾声了, 各位看官可以自己先去分析一下剩下的这段伪代码. 相较于 前面的两部分, 这部分反而难度是最简单的, 因为没有复杂的函数调用, 没有过多的循环使用, 就是分析
直接来分析逻辑吧 这部分就不需要倒推了 费劲
a1 就是 输入的明文数据 123456
a2 就是 输出明文数据的长度 6
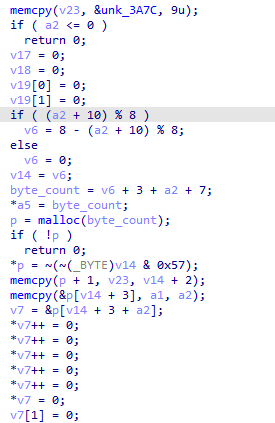
If 如果 a2 <= 0 直接返回 0
v17 v18 v19[0,0] 初始化的部分都在这里
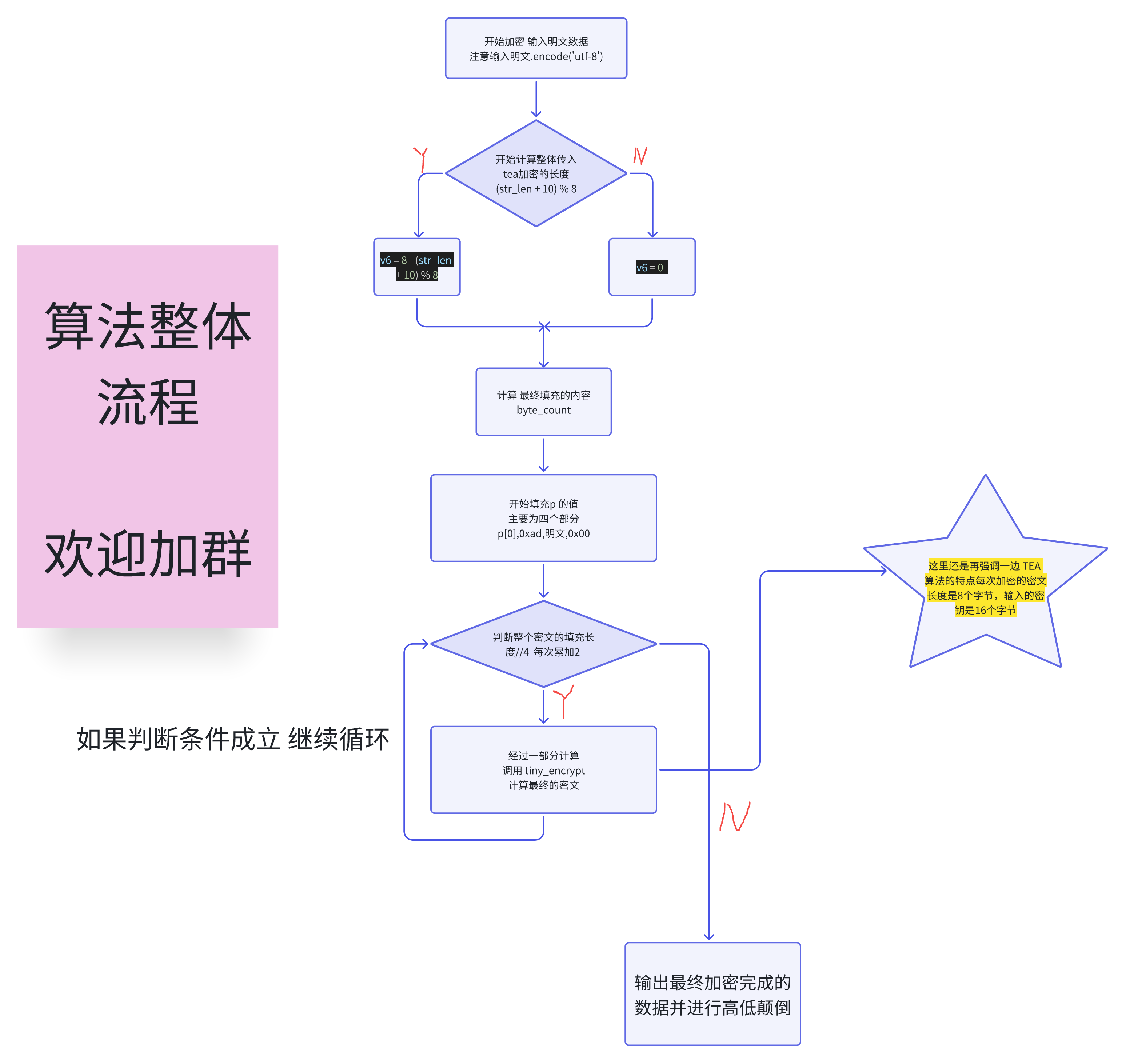
计算 v6 的值 if (a2 + 10) % 8 != 0
则 v6 = 8 - (a2 + 10) % 8
否则 v6 = 0
这部分 同样可以直接验证一下 搜v14 位置的 trace
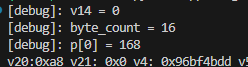
当 明文输入长度 是 6 的情况下 v14 就是 0x0
byte_count 是计算过的 开辟内存的长度
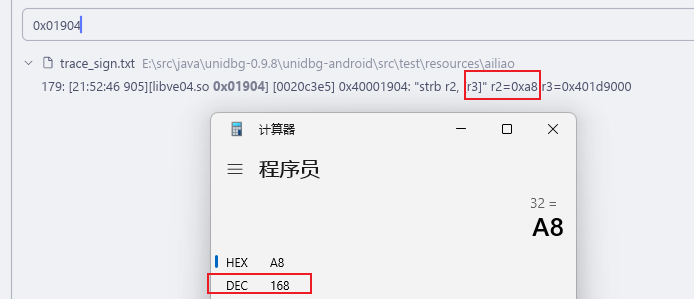
可以直接在Trace 中的日志 0x018c4 => 0x10
手动算了一下 和Python 还原出来的 一样 过!
malloc **** 函数
Malloc 函数 还是要再多讲讲,这块的内容实际上是什么意思呢,byte_count 是一个长度,那么就是 申请开辟一个 该长度的内存地址 但是此时此刻的 p 还是 空内容 如果现在去在Hook 打印 该地址 是 00000000000000.....
现在开始 继续逐步还原, if(!p){return 0;}; 就不讲了 就当看不见吧.
继续摘重点讲!
*p = ~(~(_BYTE)v14 & 0x57); 这句是什么意思呢? *p 我们已经知道了 是一个新开辟的内存地址,那么还是刚才说的 实际上 就是 p[0] = ~(~(_BYTE)v14 & 0x57)``~ 按位取反运算符 那么这句应该怎么还原呢
1
2
p = bytearray()
p[0] = ~(~(v14) & 0x57) & 0xFF
关于 注意对齐的部分,怎么说的,以我的经验就是,原本 & 的 进制数是多长 你就 对齐多少个 F
实在不行 看trace 呗 看看是否是一致的
在这里 就很明显,是一致的那么 又还原好一句代码 接着干!
memcpy(p + 1, v23, v14 + 2); 接着看,昂 还是把这两句拿到一起讲吧
1
2
memcpy(p + 1, v23, v14 + 2);
memcpy(&p[v14 + 3], a1, a2);
**memcpy 函数**
Memcpy 函数 例如 p+1 ,v23 , v14 + 2 详细解释 就是 把 v23 地址的内容 长度是 v14 + 2 复制到 p + 1的位置,就是这样
那么这两句 应该怎么还原呢,首先先想清楚一件事情,复制到的位置是不是 从 需要赋值过去的长度 累加过去 ?
如果 不是累加 长度 那么会出现一件事情,直接把原本长度/索引内的内容覆盖掉。这就是解释一下这块内容的目的
1
2
3
4
p[ 1:1 + v14 + 2] = v23[ 0:v14 + 2]
p[v14 + 3:v14 + 3 + str_len] = a1[0:a2]
======== 简写就是这样
p[v14 + 3:v14 + 3 + str_len] = a1
但是 复现着 发现 v23 还没有搞 过去看看 memcpy(v23, &unk_3A7C, 9u); 实际上就是 复制 9 个 0xad 直接写
1
v23 = bytearray([0xAD] * 9)
这部分 其实最简单了 就是从** v14 + 3 + a2** 开始 往
p 里面 塞 0x00
直接写个 for 循环 往 p[``**v14 + 3 + a2**``] + 0 起始开始塞
1
2
for i in range(7):
p[v14 + 3 + a2 + i] = 0
至此,全部的逻辑 我们已经全部复现完毕了。
现在再对原本的 全部逻辑和思路 做一个总结,善用逆推的思路,对于一些关键的节点,可以灵活的使用Trace 日志 快速的查找 检索,前提是,你输入的明文值,和对应的结果值都是固定的情况下 可以直接对照着分析,各种工具的搭配使用,能够清晰的,又有条理性的解决很多情况和算法。
算法还原 在开始关键的算法还原的时候 我们在去整理一下全部的思路 这里我用一张逻辑图去表示出来
这里我就不再详细写Python 怎么一步一步复现了,直接附上写好的py代码 现在再回头看整个算法 难么? 不难 !
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
import struct
def int_to_hex_char(n: int) -> bytes:
return b"0123456789abcdef"[n & 0xF]
def reverse_bytes_hex(a4: bytes) -> bytes:
a5 = len(a4)
byte_count = 2 * a5
p = bytearray(byte_count)
for i in range(a5):
high = (a4[i] >> 4) & 0xF
low = a4[i] & 0xF
p[2 * i] = int_to_hex_char(low)
p[2 * i + 1] = int_to_hex_char(high)
return bytes(p)
def tiny_encrypt (result):
v4 = result[0] & 0xFFFFFFFF
v5 = result[1] & 0xFFFFFFFF
tea_key = [0x656c616a, 0x54256a61, 0x6c656a66, 0x636a6b61]
sum_val = 0
v6 = 0x9E3779B9
for _ in range(16):
sum_val = (sum_val + v6) & 0xFFFFFFFF
v4 = (v4 + (((v5 << 4) + tea_key[0]) ^ (v5 + sum_val) ^ ((v5 >> 5) + tea_key[1]))) & 0xFFFFFFFF
v5 = (v5 + (((v4 << 4) + tea_key[2]) ^ (v4 + sum_val) ^ ((v4 >> 5) + tea_key[3]))) & 0xFFFFFFFF
return [v4, v5]
def tiny_init(str):
a1 = str.encode('utf-8')
str_len = len(str)
if str_len <= 0:
return "[error]: str len is null"
v6 = 0
if ((str_len + 10) % 8):
v6 = 8 - (str_len + 10) % 8
else:
v6 = 0
v14 = v6
print("[debug]: v14 = %d" % v14)
byte_count = v6 + 3 + str_len + 7
print("[debug]: byte_count = %d" % byte_count)
p = bytearray(byte_count)
p[0] = ~(~(v14) & 0x57) & 0xFF
print("[debug]: p[0] = %d" % p[0])
v23 = bytearray([0xAD] * 9)
p[ 1:1 + v14 + 2] = v23[ 0:v14 + 2]
p[v14 + 3 : v14 + 3 + str_len] = a1
for i in range(7):
p[v14 + 3 + str_len + i] = 0
v17 = 0
v18 = 0
v19 = [0, 0]
random_num = byte_count // 4
for i in range(0, random_num, 2):
v20 = struct.unpack_from('<I', p, i * 4)[0] ^ v19[0]
v21 = struct.unpack_from('<I', p, i * 4 + 4)[0] ^ v19[1]
[v4, v5] = tiny_encrypt([v20,v21])
print("v20:"+ hex(v20),"v21: "+ hex(v21),"v4: "+ hex(v4),"v5: "+ hex(v5))
cipher0 = v4 ^ v17
cipher1 = v5 ^ v18
struct.pack_into("<I", p, 4 * i, cipher0)
struct.pack_into("<I", p, 4 * i + 4, cipher1)
v19[0] = cipher0
v19[1] = cipher1
v17 = v20
v18 = v21
return reverse_bytes_hex(p).decode('utf-8')
print(tiny_init("123456"))
末尾 后续 也会推出一系列的文章,包括但不限于 魔改算法,VMP系列,小众算法
欢迎加V:ass7752321 会给大家拉一个交流群 互相交流一下思路
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。