-
-
[原创] 浅谈内存分配器设计
-
发表于: 2025-8-9 17:16 1160
-

前置知识
独立内存空间
下图展示了独立内存空间的分布。动态内存分配器(dynamic memory allocator) 就是一种在运行时堆(run-time heap) 上动态分配空间的工具。这里我们特别注意一个变量brk,它指向堆的顶部。内存分配器就是通过增加它的值请求空间的。
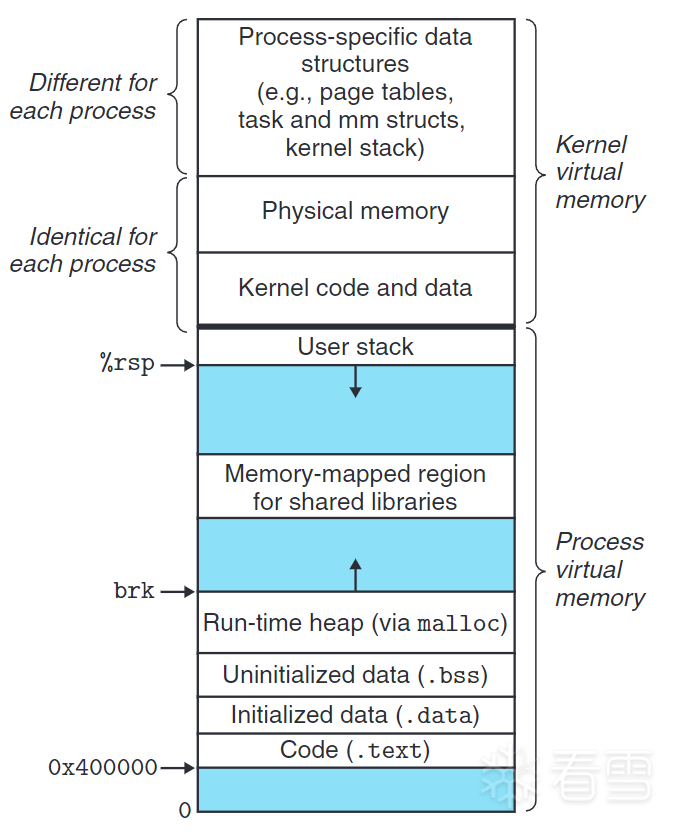
(引用书籍Computer Systems: A Programmer's Perspective插图,以下简称CSAPP)
内存分配
内存分配器分为两种:
- 显式分配器(explicit allocator):要求显式地释放已分配的块。如
malloc, free或new delete。 - 隐式分配器(implicit allocator):或称垃圾收集器(garbage collector),自动释放已分配的块(垃圾收集, garbage collection)。
本文主要介绍显示分配器的实现。
当一块区域的内存被分配后(指被如malloc之类的内存分配器分配),称为已分配块(allocated block)。
反之,还没被分配的块称空闲块(free block)。
碎片
碎片(fragmentation):指虽有未使用的内存,但不能满足分配请求的现象。
有效载荷(payload):指分配器分配后,用户实际可用的部分。(不包括 chunck header 和 pedding,这些名词等下会解释)
碎片分为两种:
- 内部碎片:已分配块比有效载荷大时发生。比如因内存对齐要求,使得分配块比有效载荷大。内部碎片的大小,即已分配块大小与有效载荷差的和。
- 外部碎片:当空闲内存合计起来足以满足分配请求,但没有单独的空闲空间可以处理此请求时发生。比如,空闲块与已分配块交错出现,而单个空闲块又太小无法满足要求。量化外部碎片比量化碎片难,因为它不只取决于先前请求模式和分配器实现方式,还取决于将来请求的模式。
内存分配器架构
想实现一个分配器,必须考虑以下问题:
- 空闲块组织:如何记录空闲块?
- 放置:如何选择合适的空闲块来分配?
- 分割:当空闲块被分配后,如何处理该空闲块的剩余部分?
- 合并:如何处理刚被释放的块?
我们可以使用一种称空闲链表(free list) 的数据结构解决这些问题。
隐式空闲链表
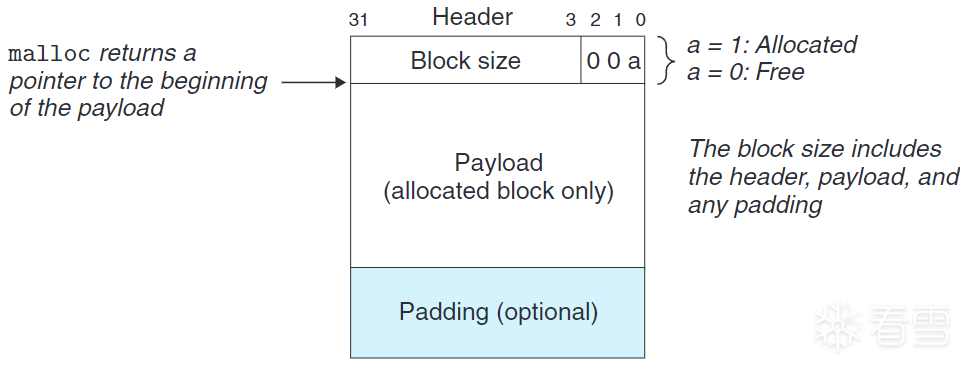
(引用书籍CSAPP插图)
上图展示了一个简易的块结构。
若我们强加一个(块总大小)对8的对齐要求,则块大小的最低3位必是0,所以存储块大小只需要29个高位。在这种情况下,低3位就可以拿来编码其他信息(特别妙的一种想法)。此时,我们利用低3位标记此块是否已分配。
例如,我们有一个已分配的块,大小为24(0x18)字节。则他的头部将是:
1 | 0x00000018 | 0x1 = 0x00000019 |
由上述的块结构,我们可以将堆看做连续的已分配块和空闲块交错出现的序列:

(引用书籍CSAPP插图)
我们称这种结构隐式空闲链表(implicit free list),因为空闲块间由头部的块大小字段隐式连接着。在结构的最后,我们需要一种特殊标记的结束块,此例中是一个设置已分配位且大小为零的终止头部(terminating header)。
此结构的优点是简单,缺点则是操作的开销大。比如,要为新分配的块选择空闲块放置。此时要对空闲链表进行搜索,且时间与堆中已分配块和空闲块总数呈线性关系。
注意,系统对齐要求和分配器块数据结构格式会限制最小块大小,没有任何已分配块可以比这个最小值小。例如,上述的块格式导致最小的块占8字节。4字节作为 header,4字节用来维持对齐。
放置已分配块
当应用请求块,分配器搜索空闲链表,查找足够放置所求块的空闲块。分配器执行搜索的方式由放置策略(placement policy) 确定。
以下是常见的策略:
- 首次匹配:从头开始搜索,选择第一个适合的空闲块。
- 优点:倾向于将大空闲块留在链表后面。
- 缺点:前面留下太多小空闲块碎片,导致搜索较大块的时间增加。
- 下一次匹配:从上一次查询结束的地方开始搜索,选择第一个适合的块。
- 最佳匹配:检查每个空闲块,找到最适合的。
分割空闲块
一旦找到合适的空闲块,就必须做出另一个策略决定,分配这个块中多少空间。
- 若匹配佳,选择使用整个空闲块。缺点:造成内部碎片。
- 若匹配不佳,分割空闲块。
合并空闲块
当分配器释放已分配块时,可能有其他空闲块与新释放的空闲块相邻。相邻的空闲块可能导致假碎片(fault fragmentation)。
为了解决此问题,分配器必须合并相邻的空闲块,此过程称合并(coalescing)。合并分为立即合并与推迟合并(deferred coalescing),延迟合并会等某个分配请求失败,才会扫描整个堆进行合并。
带边界标记的合并
假设我们称想要释放的块为当前块。想要合并处于当前块的下一个空闲块很简单,只要检查下一块的头部,并将它的大小加到当前块的头部即可。
但是若想合并处于当前块之前的空闲块,则必须整个重新遍历一次链表。释放的时间与堆的大小成线性关系。
Knuth提出边界标记(boundary tag) 的技术,允许常数时间的合并。边界标记通过往每个块的结尾添加一个脚部(footer,亦称边界标记) 实现,脚部存放的是头部的副本。当前块可以通过访问脚部来判断当前块之前的块是否空闲。
对每个块添加脚部貌似有点奢侈,其实,只有未分配块才需要脚部。已分配块只需要将已分配/空闲位存储在当前块的头部低位(当前块脚部仍保持当前块的已分配/空闲位),就可以被当前块识别,从而略过合并。但是,空闲块仍需要脚部,因为当前块需要从脚部取得块大小。
显式空闲链表
由于隐式空闲链表的块分配与块数量呈线性关系,所以不适合用于通用分配器。这时,显式空闲链表(explicit free list) 较适用。
因为空闲块不存储用户数据,我们可以将指针数据放在此处。例如,组织成一个双向链表。这样可以使分配时间从总块数的线性时间减少到总空闲块数的线性时间。
将释放块插入空闲链表有两种策略:
- 后进先出(LIFO):将新释放的块放在链表头部。复杂度:O(1)。
- 按地址顺序:将新释放的块放在按地址大小排序的相应位置,因为必须遍历找到新释放块的
pred和succ,所以复杂度较高。复杂度:O(n)。
按地址排序的首次适配有较高内存利用率,这也是为何就算时间复杂度较高也有人选用的原因。
显式链表的缺点是,最小块大小增加,提高内部碎片的程度。
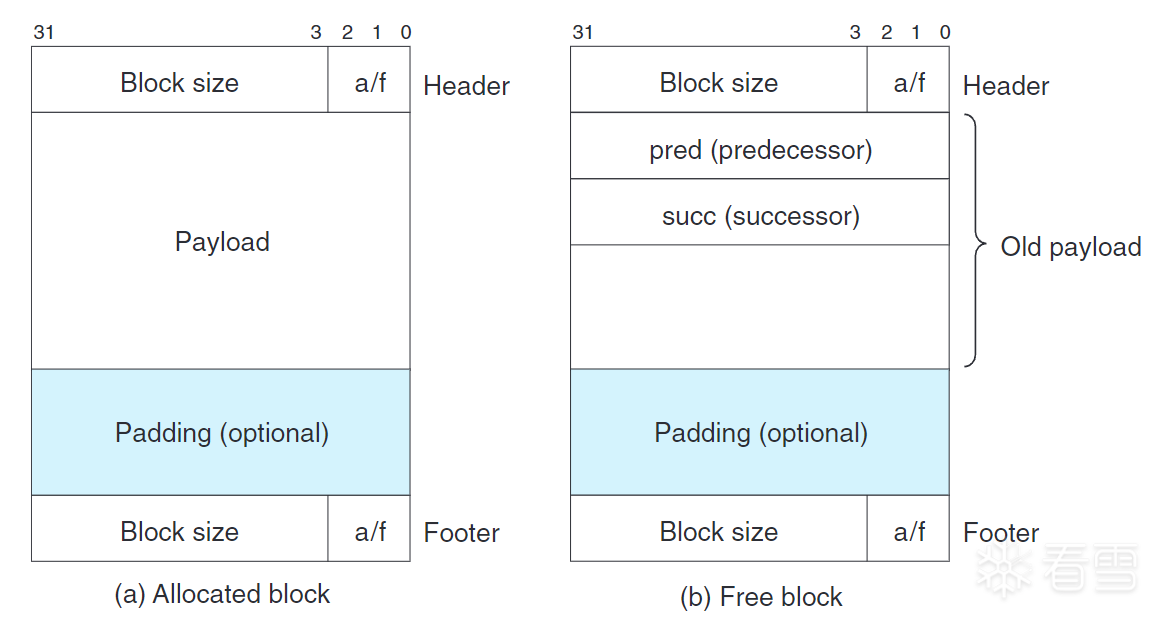
(引用书籍CSAPP插图)
分离的空闲链表
分离的空闲链表(segregated free list) 的核心想法是,把不同大小的块分开管理,每种大小一条链表。我们称这些大小为等价类或大小类(size class)。
- 简单的分离存储
每个大小类的空闲链表都是大小相等的块,每个块的大小都是该大小类中最大元素的值。比如大小类定义为{17∼32}则每个块大小都为32。 - 分离适配
对于不同大小类,分配器维护很多链表与之关联。链表中,每个块的大小都在相应大小类区间中。所以想要操作块时,只要简单的向对应链表搜索即可。
内存分配器实现
这里我们选用CSAPP提供的 malloc lab 来实现一个简化的内存分配器。
可以从这里下载 malloc lab 的压缩文件,从这里取得官方操作说明。
阅读以下内容前,请确保你已经下载并阅读过官方操作说明。
选用架构
空闲链表:segregated free list。
大小类:共32条空闲链表,以2的幂做划分,刚好可以覆盖unsigned int的范围。
未分配块搜寻策略:最佳匹配。
空闲链表插入策略:LIFO。
常用宏实现
我定义了一些宏,专门用来执行指针运算。以免后续代码中全是这种恶心的指针运算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | /* basic constants */#define WSIZE 4#define DSIZE 8#define CLASS_SIZE 32#define MAX(x, y) ((x) > (y) ? (x) : (y))/* pack a size and allocated bit into a word */#define PACK(size, alloc) ((size) | (alloc))/*read and write a word in p */#define GET(p) (*(unsigned int *) (p))#define PUT(p, val) (*(unsigned int *) (p) = (val))/* read the size and allocated bields from address p (that point to a block header) */#define GETSIZE(p) (GET(p) & (~0x7))#define GETALLOC(p) (GET(p) & 0x1)/* given block ptr bp, compute address of its header and footer *//* we have to convert bp to (char *), this ensure pointer arithematic to btye level */#define HDRP(bp) ((char *) (bp) - WSIZE)#define FTRP(bp) ((char *) (bp) + GETSIZE(HDRP(bp)) - 2 * WSIZE)/* find next and previous block in the heap */#define PREV_BLKP(bp) ((char *) (bp) - GETSIZE(HDRP(bp) - WSIZE))#define NEXT_BLKP(bp) ((char *) (bp) + GETSIZE(HDRP(bp)))/* for each given index, return free_list[i] */#define GETLIST(n) (*((void **) ((char *) (heap_listp + (n) * WSIZE))))/* find next and previous blocks in the segregated free list */#define LIST_PREVP(bp) (*((void **) (bp)))#define LIST_NEXTP(bp) (*((void **) ((char *) (bp) + WSIZE))) |
函数定义
mm_init():这个函数实现分配器的初始化。
mm_malloc():实现类似malloc功能。
mm_free():实现类似free功能。
mm_realloc():实现类似realloc功能(因为这个函数是我最后写的,前面debug找的非常烦躁,写的比较丑陋请见谅)。
find_class():传入空闲块指针,返回对应大小类。
insert_list():将空闲块插入到对应空闲链表中。
remove_list():将空闲块从空闲链表中删除(表示马上要被分配了)。
coalesce():检查当前块的前一块与后一块,若也是空闲块则合并。
extend_heap():设置brk,使堆增长。
find_fit():在链表中寻找合适大小的空闲块。
place():修改空闲块数据,使其成为已分配块,并依大小决定是否分割。
代码实现
代码有一点点长,亿点点丑陋,亿点点臃肿...
所以我把它放在了github上面,需要可以取用(包含CSAPP其他lab的实现):e9cK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6A6L8s2y4S2L8#2)9J5c8V1y4e0b7g2m8b7i4K6u0V1L8r3q4T1i4K6u0V1M7$3!0D9N6i4c8A6L8$3&6K6i4K6u0r3j5X3I4G2j5W2)9J5c8X3#2S2K9h3&6Q4x3V1k6E0j5h3I4D9L8$3y4Q4x3U0f1J5x3r3I4S2j5W2)9J5c8X3#2E0i4K6u0W2j5H3`.`.
赞赏
|
|
|---|---|
|
|
|

- [原创] xv6 陷入机制浅析 1281
- [原创] 浅谈内存分配器设计 1160
- [原创]【深入理解计算机系统】 手搓一个tiny shell 1079
- [原创]《深入理解计算机系统》Attack Lab 题解 3384
- [原创]《深入理解计算机系统》Bomb Lab 题解 5176



