-
-
[原创]一种基于unicorn的寄存器间接跳转混淆去除方式
-
发表于: 2025-2-27 12:16 11967
-

重新梳理一遍加固,从寄存器间接跳转开始学起吧
新人第一篇,写的不好,各位大佬轻喷:)
寄存器存储地址:寄存器间接跳转依赖于寄存器内的值来指定要跳转到的地址,而这个地址可以在程序运行时动态改变。
跳转指令:在汇编语言中,类似于 jmp eax 或 br x8 的指令,使用寄存器(如 eax, x8 等)存储目标地址,执行这些指令后,程序的控制流就会转移到寄存器中的指定地址。
作为混淆,这种基于寄存器间接跳转的混淆会使反编译器无法正常识别代码逻辑
特征:
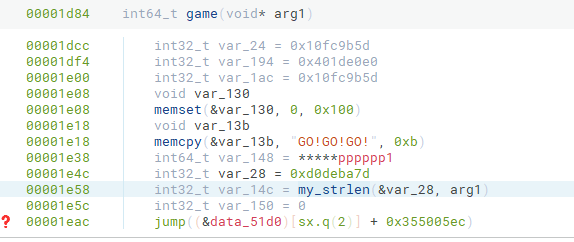
那么为了能够看清程序的逻辑,我们需要对这玩意进行修复。
大部分的间接跳转将用于计算地址的值储存在data段,而反编译器不会去解析data段的常量。这是因为在反编译器的预设中,data段是默认可写的。这时被引用的值被视为变量,就不会进行常量传播优化。
如果我们将data段的属性改为只读,可以促进反编译器的常量传播,去除一部分混淆。
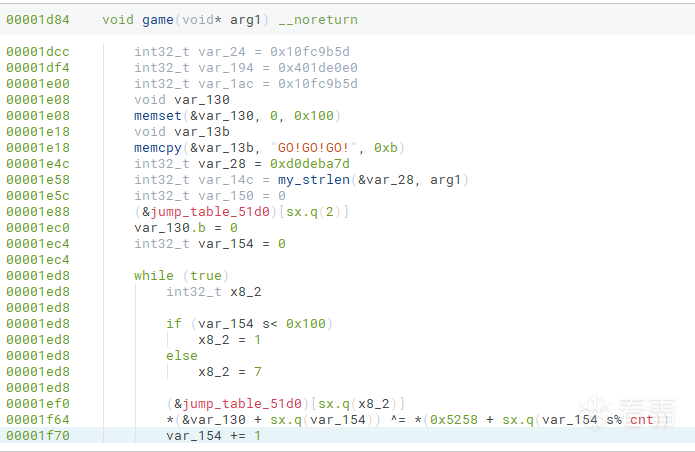
可以看到还是有问题的
一个比较常规的思路是用模拟执行框架来解出跳转时对应寄存器存储的具体值,然后进行patch去除。这里我选择了使用unicorn,当然 angr/qiling等框架应该也是可以的,只是作为初学者我不太会写,还是unicorn写着顺手。
是一个arm64的elf,有间接跳转和字符串混淆。字符串混淆可以通过unicorn 内存写入trace简单的过掉。这里只讨论如何去除间接跳转混淆。
一个具体的汇编代码片段例子:
可以发现很明显的特征代码块:
基于这样的特征,我们可以在初始化的时候,使用模式匹配遍历.text .initarray等代码段。然后将mov的地址,br的地址(cslr地址)存入一个要去执行的list里。在遍历完后,循环分别处理每一段地址作为参数传入模拟执行函数。
假设我们已经识别了所有的指令,现在要做的就是如何去除。
主要的形式是下面的图
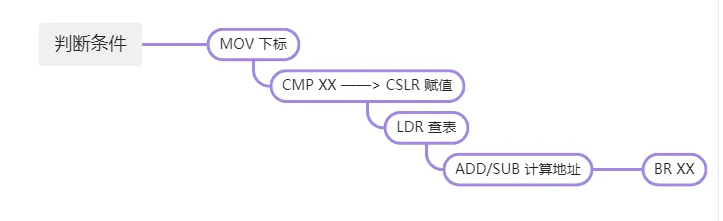
那么如何去掉呢?
如果优化掉后面的查表计算等操作,将前面的值分别确定,模拟执行拿到数据后,就可以直接patch成正常的跳转,自然可以被正常的反编译。即是下面的情况。
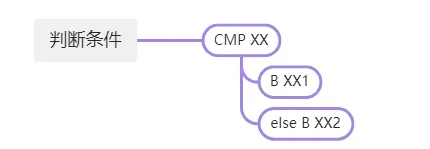
于是我们的思路有了,具体拆成以下几个部分来分别实现。
一步一步完成吧。
先拿到cslr指令和操作数,然后依据对应的操作数,拿到mov指令的形状后,patch,分为两个分支模拟执行
已经有了模拟执行的框架,这里就直接写一个方法去拿到相关的指令储存起来
那么有小伙伴就要问了,如何拿到相关的指令呢?这里其实可以注意到,这段混淆实际上是通过先取立即数和地址,然后存入栈,在后续重新从栈上拿回地址。所以我们可以在范围内遍历有关sp的指令,然后确定偏移,向上溯回,找到所有对改位置进行写入的寄存器。通过跟踪这些寄存器,我们就能拿到相应的赋值指令,进而在后续模拟执行。
在unicorn加载的时候,没有load .data段到正确的地方,导致在.data段上的值无法被正确的读取。我们可以使用lief对文件进行解析,分别计算出对应section的虚拟地址和正确的patch地址,然后代替直接将整个文件加载,把对应的段分别正确的映射到unicorn的虚拟内存里。
跑一下发现,虽然有几个段没有成功映射,但大部分段都成功的加载了。
理所当然的,我们得到了正确的跳转地址:
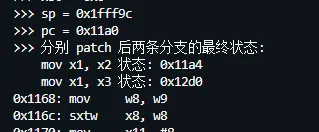
结果出来的一瞬间,心情无比愉悦
获取了正确的跳转地址后,我们就可以想想如何去patch逻辑了。
再看看代码
cslr之后,所有的计算基本都是对最终br的寄存器进行地址计算,而事实上我们已经有了这些值,就不需要再进行这些计算了。
先设计一下应该执行的指令:
注意到,CMP后的指令顺序是不变的

而且cmp的结果就决定了后续跳转的地址。所以我们可以拿下面的固定不变指令来做一点文章。
如果我们设计为:
就可以完成这些工作。但是有一个问题是,如果过早jmp,br后面的代码对于之后程序的执行可能会有一定影响。
所以我们要进行指令前移,在所有其余指令执行完后,再进行br操作。
如何实现指令前移呢?观察代码。在一些混淆中,br之前做了一些常量保存工作,如果贸然nop掉会导致后续指令无法执行。
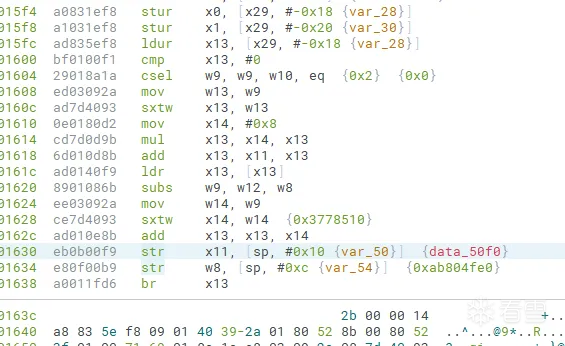
所以我们可以采取这样的做法
代码实现
至此,我们完成了所有的工作。再加上亿点小小的细节,添加一下注释和批量优化,就是完整的实现代码
去混淆之前
去混淆之后,很明显的rc4
https://bbs.kanxue.com/thread-282826.htm
4efK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6T1L8r3!0Y4i4K6u0W2j5%4y4V1L8W2)9J5k6h3&6W2N6q4)9J5c8V1I4#2j5$3E0A6k6i4u0K6i4K6u0r3j5i4u0@1K9h3y4D9k6g2)9J5c8X3c8W2N6r3q4A6L8s2y4Q4x3V1j5I4x3U0R3J5x3U0p5#2x3o6j5`.
https://bbs.kanxue.com/thread-283706.htm
https://bbs.kanxue.com/thread-280231.htm
loc_1E60 ; CODE XREF: sub_1FD4+2C↓jLDR W8, [SP,#0x1C0+var_140] ; Load from MemoryMOV W9, #2 ; Rd = Op2MOV W10, #0 ; Rd = Op2CMP W8, #0x100 ; Set cond. codes on Op1 - Op2CSEL W8, W9, W10, LT ; Conditional SelectMOV W11, W8 ; Rd = Op2SXTW X11, W11 ; Signed Extend WordMOV X12, #8 ; Rd = Op2MUL X11, X12, X11 ; MultiplyLDR X12, [SP,#0x1C0+var_190] ; Load from MemoryADD X11, X12, X11 ; Rd = Op1 + Op2LDR X11, [X11] ; Load from MemoryMOV W8, #0x464CA149LDR W9, [SP,#0x1C0+var_19C] ; Load from MemorySUBS W8, W8, W9 ; Rd = Op1 - Op2MOV W13, W8 ; Rd = Op2SXTW X13, W13 ; Signed Extend WordADD X11, X11, X13 ; Rd = Op1 + Op2BR X11 ; Branch To Registerloc_1E60 ; CODE XREF: sub_1FD4+2C↓jLDR W8, [SP,#0x1C0+var_140] ; Load from MemoryMOV W9, #2 ; Rd = Op2MOV W10, #0 ; Rd = Op2CMP W8, #0x100 ; Set cond. codes on Op1 - Op2CSEL W8, W9, W10, LT ; Conditional SelectMOV W11, W8 ; Rd = Op2SXTW X11, W11 ; Signed Extend WordMOV X12, #8 ; Rd = Op2MUL X11, X12, X11 ; MultiplyLDR X12, [SP,#0x1C0+var_190] ; Load from MemoryADD X11, X12, X11 ; Rd = Op1 + Op2LDR X11, [X11] ; Load from MemoryMOV W8, #0x464CA149LDR W9, [SP,#0x1C0+var_19C] ; Load from MemorySUBS W8, W8, W9 ; Rd = Op1 - Op2MOV W13, W8 ; Rd = Op2SXTW X13, W13 ; Signed Extend WordADD X11, X11, X13 ; Rd = Op1 + Op2BR X11 ; Branch To Registermov x1 #xmov x2 #x...cslr xx x1 x2 eq ...br xxmov x1 #xmov x2 #x...cslr xx x1 x2 eq ...br xxsaved_state = {}def save_state(mu): regs = {} regs_list = [ UC_ARM64_REG_X0, UC_ARM64_REG_X1, UC_ARM64_REG_X2, UC_ARM64_REG_X3, UC_ARM64_REG_X4, UC_ARM64_REG_X5, UC_ARM64_REG_X6, UC_ARM64_REG_X7, UC_ARM64_REG_X8, UC_ARM64_REG_X9, UC_ARM64_REG_X10, UC_ARM64_REG_X11, UC_ARM64_REG_X12, UC_ARM64_REG_X13, UC_ARM64_REG_X14, UC_ARM64_REG_X15, UC_ARM64_REG_X16, UC_ARM64_REG_X17, UC_ARM64_REG_X18, UC_ARM64_REG_X19, UC_ARM64_REG_X20, UC_ARM64_REG_X21, UC_ARM64_REG_X22, UC_ARM64_REG_X23, UC_ARM64_REG_X24, UC_ARM64_REG_X25, UC_ARM64_REG_X26, UC_ARM64_REG_X27, UC_ARM64_REG_X28, UC_ARM64_REG_X29, UC_ARM64_REG_X30, UC_ARM64_REG_SP, UC_ARM64_REG_PC ] for reg in regs_list: regs[reg] = mu.reg_read(reg) return regsdef restore_state(mu, regs): for reg, val in regs.items(): mu.reg_write(reg, val)def branch_hook(mu, addr, size, user_data): # 对当前指令反汇编,若遇到BR指令则终止模拟 for inst in cs.disasm(mu.mem_read(addr, size), addr): if inst.mnemonic.lower() == "br": print(">>> BR 指令在 0x%x 被触发,停止模拟" % addr) mu.emu_stop() break returnpass_addr = [0x24A8,0x24AC,0x1E20]csel_handled = Falsedef hook_code(mu, address, size, user_data): global save_state , csel_handled if address in LIBC_FUNCS: print(">>> Entering simulated library function at 0x%x" % address) LIBC_FUNCS[address](mu) return # if address in pass_addr:# 修改类似eip的寄存器来跳过这两个地址 # mu.reg_write(UC_ARM64_REG_PC, address+size) # print('>>> Skipping address 0x%x' % address) # print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' % (address, size)) # 打印汇编代码 for inst in cs.disasm(mu.mem_read(address, size), address): print("0x%x:\t%s\t%s" % (inst.address, inst.mnemonic, inst.op_str)) #如果当前指令是CSEL if inst.mnemonic.lower() == "csel" and not csel_handled: print(">>> csel detected") csel_handled = True csel_addr = address original_bytes = mu.mem_read(csel_addr, size) saved_state = save_state(mu)#保存当前状态 #获取操作寄存器 op = inst.op_str.split(", ") #组装mov指令 mov_inst1 = "mov " + op[0] + ", " + op[1] +';' mov_inst2 = "mov " + op[0] + ", " + op[2] +';' # print('>>> mov instructions:', mov_inst1, mov_inst2) #编译mov指令 asm_mov_x1_x2, _ = ks.asm(mov_inst1) asm_mov_x1_x3, _ = ks.asm(mov_inst2) # print('there') #定义内部函数,用于进行两次patch def run_branch_test(patch_bytes, branch_label): # patch 当前 csel 指令位置 mu.mem_write(csel_addr, bytes(patch_bytes)) print(f">>> 已将 csel 指令 patch 为 {branch_label},开始执行至遇到 BR 指令") # 添加一个临时 hook 来检测 BR 指令 bh_id = mu.hook_add(UC_HOOK_CODE, branch_hook) try: mu.emu_start(mu.reg_read(UC_ARM64_REG_PC), END_POINT) except UcError as e: print("模拟过程中出现错误:", e) mu.hook_del(bh_id) state = save_state(mu) print(">>> 运行结束后状态:", state) return state # 首先用 mov x1, x2 运行 state_branch1 = run_branch_test(asm_mov_x1_x2, "mov x1, x2") # 恢复现场 restore_state(mu, saved_state) # 然后用 mov x1, x3 运行 state_branch2 = run_branch_test(asm_mov_x1_x3, "mov x1, x3") print(">>> 分别 patch 后两条分支的最终状态:") print(" mov x1, x2 状态:", hex(state_branch1[UC_ARM64_REG_X8])) print(" mov x1, x3 状态:", hex(state_branch2[UC_ARM64_REG_X8])) saved_state = {}def save_state(mu): regs = {} regs_list = [ UC_ARM64_REG_X0, UC_ARM64_REG_X1, UC_ARM64_REG_X2, UC_ARM64_REG_X3, UC_ARM64_REG_X4, UC_ARM64_REG_X5, UC_ARM64_REG_X6, UC_ARM64_REG_X7, UC_ARM64_REG_X8, UC_ARM64_REG_X9, UC_ARM64_REG_X10, UC_ARM64_REG_X11, UC_ARM64_REG_X12, UC_ARM64_REG_X13, UC_ARM64_REG_X14, UC_ARM64_REG_X15, UC_ARM64_REG_X16, UC_ARM64_REG_X17, UC_ARM64_REG_X18, UC_ARM64_REG_X19, UC_ARM64_REG_X20, UC_ARM64_REG_X21, UC_ARM64_REG_X22, UC_ARM64_REG_X23, UC_ARM64_REG_X24, UC_ARM64_REG_X25, UC_ARM64_REG_X26, UC_ARM64_REG_X27, UC_ARM64_REG_X28, UC_ARM64_REG_X29, UC_ARM64_REG_X30, UC_ARM64_REG_SP, UC_ARM64_REG_PC ] for reg in regs_list: regs[reg] = mu.reg_read(reg) return regsdef restore_state(mu, regs): for reg, val in regs.items(): mu.reg_write(reg, val)def branch_hook(mu, addr, size, user_data): # 对当前指令反汇编,若遇到BR指令则终止模拟 for inst in cs.disasm(mu.mem_read(addr, size), addr): if inst.mnemonic.lower() == "br": print(">>> BR 指令在 0x%x 被触发,停止模拟" % addr) mu.emu_stop() break returnpass_addr = [0x24A8,0x24AC,0x1E20]csel_handled = Falsedef hook_code(mu, address, size, user_data): global save_state , csel_handled if address in LIBC_FUNCS: print(">>> Entering simulated library function at 0x%x" % address) LIBC_FUNCS[address](mu) return # if address in pass_addr:# 修改类似eip的寄存器来跳过这两个地址 # mu.reg_write(UC_ARM64_REG_PC, address+size) # print('>>> Skipping address 0x%x' % address) # print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' % (address, size)) # 打印汇编代码 for inst in cs.disasm(mu.mem_read(address, size), address): print("0x%x:\t%s\t%s" % (inst.address, inst.mnemonic, inst.op_str)) #如果当前指令是CSEL if inst.mnemonic.lower() == "csel" and not csel_handled: print(">>> csel detected") csel_handled = True csel_addr = address original_bytes = mu.mem_read(csel_addr, size) saved_state = save_state(mu)#保存当前状态 #获取操作寄存器 op = inst.op_str.split(", ") #组装mov指令 mov_inst1 = "mov " + op[0] + ", " + op[1] +';' mov_inst2 = "mov " + op[0] + ", " + op[2] +';' # print('>>> mov instructions:', mov_inst1, mov_inst2) #编译mov指令 asm_mov_x1_x2, _ = ks.asm(mov_inst1) asm_mov_x1_x3, _ = ks.asm(mov_inst2) # print('there') #定义内部函数,用于进行两次patch def run_branch_test(patch_bytes, branch_label): # patch 当前 csel 指令位置 mu.mem_write(csel_addr, bytes(patch_bytes)) print(f">>> 已将 csel 指令 patch 为 {branch_label},开始执行至遇到 BR 指令") # 添加一个临时 hook 来检测 BR 指令 bh_id = mu.hook_add(UC_HOOK_CODE, branch_hook) try: mu.emu_start(mu.reg_read(UC_ARM64_REG_PC), END_POINT) except UcError as e: print("模拟过程中出现错误:", e) mu.hook_del(bh_id) state = save_state(mu) print(">>> 运行结束后状态:", state) return state # 首先用 mov x1, x2 运行 state_branch1 = run_branch_test(asm_mov_x1_x2, "mov x1, x2") # 恢复现场 restore_state(mu, saved_state) # 然后用 mov x1, x3 运行 state_branch2 = run_branch_test(asm_mov_x1_x3, "mov x1, x3") print(">>> 分别 patch 后两条分支的最终状态:") print(" mov x1, x2 状态:", hex(state_branch1[UC_ARM64_REG_X8])) print(" mov x1, x3 状态:", hex(state_branch2[UC_ARM64_REG_X8])) def hit_hook(self, mu: Uc, addr: int, size: int, user_data) -> None: """ 代码 hook,用于捕获并存储 hit 指令(通过向上追踪含 SP 且 ldr 指令)。 """ try: code = mu.mem_read(addr, size) except UcError: return for inst in self.cs.disasm(code, addr): # print(f"hit hook : >>> {hex(addr)} {inst.mnemonic} {inst.op_str}") if inst.mnemonic.lower() == "br": mu.emu_stop() break if inst.mnemonic.lower() == "stur" or inst.mnemonic.lower() == "ldur": self.mu.reg_write(UC_ARM64_REG_PC, addr + size) # print(f">>> stur or ldur detected, skip") return if "sp" in inst.op_str and "ldr" in inst.mnemonic: # print(f"attached ldr sp instruction: {inst.mnemonic} {inst.op_str}") parts = inst.op_str.split(", [") target = parts[0] if "sp" in parts[0] else parts[1] target_state = False target2 = "" curr_addr = addr for _ in range(1, 200): curr_addr -= inst.size try: code_b = mu.mem_read(curr_addr, 4) except UcError: continue for inst_b in self.cs.disasm(code_b, curr_addr): if target in inst_b.op_str and "ldr" not in inst_b.mnemonic and not target_state: # print(f"hit instruction: {inst_b.mnemonic} {inst_b.op_str}") target_state = True self.hit_inst.append(inst_b) parts_b = inst_b.op_str.split(", ") target2 = parts_b[0] if target not in parts_b[0] else parts_b[1] break if target_state and target2 in inst_b.op_str and "mov" in inst_b.mnemonic and '#0x' in inst_b.op_str: self.hit_inst.append(inst_b) if target_state and target2 in inst_b.op_str and 'adr' in inst_b.mnemonic: # print(f"hit instruction: {inst_b.mnemonic} {inst_b.op_str}") if "adrp" in inst_b.mnemonic: try: next_code = mu.mem_read(curr_addr + inst_b.size, 4) except UcError: continue for inst_el in self.cs.disasm(next_code, curr_addr + inst_b.size): if "add" in inst_el.mnemonic: self.hit_inst.append(inst_el) self.hit_inst.append(inst_b) else: self.hit_inst.append(inst_b) return def branch_hook(self, mu: Uc, addr: int, size: int, user_data) -> None: """ 当执行到 BR 指令时停止模拟 """ try: code = mu.mem_read(addr, size) except UcError: return for inst in self.cs.disasm(code, addr): if inst.mnemonic.lower() == "br": # print(f">>> BR 指令在 0x{addr:x} 被触发,停止模拟") mu.emu_stop() break def get_hit_inst(self, addr: int) -> None: """ 从指定地址向后模拟收集 hit 指令 """ # print(f">>> Getting hit instructions from 0x{addr:x} to 0x{self.inst_br_addr_temp:x}") bh_id = self.mu.hook_add(UC_HOOK_CODE, self.hit_hook) self.mu.hook_del(self.hook_code_id) # 搜寻前面的有没有立即数存储指令 for i in range(1, 50): try: code = self.mu.mem_read(addr - i * 4, 4) except UcError: continue for inst in self.cs.disasm(code, addr - i * 4): # print(f"get_hit_inst : >>> {hex(addr - i * 4)} {inst.mnemonic} {inst.op_str}") if ("mov" in inst.mnemonic or "ldr" in inst.mnemonic ) and '#' in inst.op_str: self.hit_inst.append(inst) try: self.mu.emu_start(addr - 4, self.inst_br_addr_temp) except UcError as e: print("模拟过程中出现错误:", e) self.err_flag = True self.err_addr.append((self.inst_mov_addr_temp, self.inst_br_addr_temp,"error at get_hit_inst:", e)) self.mu.hook_del(bh_id) self.hook_code_id = self.mu.hook_add(UC_HOOK_CODE, self.hook_code) # print("\n>>> Hit instructions:") # for inst in self.hit_inst: # print(f" 0x{inst.address:x}: {inst.mnemonic} {inst.op_str}") def run_hit_inst(self) -> None: """ 只模拟 hit 指令(hit_inst 列表中的指令)。 """ # print(">>> Running hit instructions") original_pc = self.mu.reg_read(UC_ARM64_REG_PC) for inst in reversed(self.hit_inst): try: self.mu.emu_start(inst.address, inst.address + inst.size) except UcError as e: print("run_hit_inst 模拟出现错误:", e) self.err_flag = True self.err_addr.append((self.inst_mov_addr_temp, self.inst_br_addr_temp, "error at run_hit_inst:", e)) self.mu.reg_write(UC_ARM64_REG_PC, original_pc)def hit_hook(self, mu: Uc, addr: int, size: int, user_data) -> None: """ 代码 hook,用于捕获并存储 hit 指令(通过向上追踪含 SP 且 ldr 指令)。 """ try: code = mu.mem_read(addr, size) except UcError: return for inst in self.cs.disasm(code, addr): # print(f"hit hook : >>> {hex(addr)} {inst.mnemonic} {inst.op_str}") if inst.mnemonic.lower() == "br": mu.emu_stop() break if inst.mnemonic.lower() == "stur" or inst.mnemonic.lower() == "ldur": self.mu.reg_write(UC_ARM64_REG_PC, addr + size) # print(f">>> stur or ldur detected, skip") return if "sp" in inst.op_str and "ldr" in inst.mnemonic: # print(f"attached ldr sp instruction: {inst.mnemonic} {inst.op_str}") parts = inst.op_str.split(", [") target = parts[0] if "sp" in parts[0] else parts[1] target_state = False target2 = "" curr_addr = addr for _ in range(1, 200): curr_addr -= inst.size try: code_b = mu.mem_read(curr_addr, 4) except UcError: continue for inst_b in self.cs.disasm(code_b, curr_addr): if target in inst_b.op_str and "ldr" not in inst_b.mnemonic and not target_state: # print(f"hit instruction: {inst_b.mnemonic} {inst_b.op_str}") target_state = True self.hit_inst.append(inst_b) parts_b = inst_b.op_str.split(", ") target2 = parts_b[0] if target not in parts_b[0] else parts_b[1] break if target_state and target2 in inst_b.op_str and "mov" in inst_b.mnemonic and '#0x' in inst_b.op_str: self.hit_inst.append(inst_b) if target_state and target2 in inst_b.op_str and 'adr' in inst_b.mnemonic: # print(f"hit instruction: {inst_b.mnemonic} {inst_b.op_str}") if "adrp" in inst_b.mnemonic: try: next_code = mu.mem_read(curr_addr + inst_b.size, 4) except UcError: continue for inst_el in self.cs.disasm(next_code, curr_addr + inst_b.size): if "add" in inst_el.mnemonic: self.hit_inst.append(inst_el) self.hit_inst.append(inst_b) else: self.hit_inst.append(inst_b) return def branch_hook(self, mu: Uc, addr: int, size: int, user_data) -> None: """ 当执行到 BR 指令时停止模拟 """ try: code = mu.mem_read(addr, size) except UcError: return for inst in self.cs.disasm(code, addr): if inst.mnemonic.lower() == "br": # print(f">>> BR 指令在 0x{addr:x} 被触发,停止模拟") mu.emu_stop() break def get_hit_inst(self, addr: int) -> None: """ 从指定地址向后模拟收集 hit 指令 """ # print(f">>> Getting hit instructions from 0x{addr:x} to 0x{self.inst_br_addr_temp:x}") bh_id = self.mu.hook_add(UC_HOOK_CODE, self.hit_hook) self.mu.hook_del(self.hook_code_id) # 搜寻前面的有没有立即数存储指令 for i in range(1, 50): try: code = self.mu.mem_read(addr - i * 4, 4) except UcError: continue for inst in self.cs.disasm(code, addr - i * 4): # print(f"get_hit_inst : >>> {hex(addr - i * 4)} {inst.mnemonic} {inst.op_str}") if ("mov" in inst.mnemonic or "ldr" in inst.mnemonic ) and '#' in inst.op_str: self.hit_inst.append(inst) try: self.mu.emu_start(addr - 4, self.inst_br_addr_temp) except UcError as e: print("模拟过程中出现错误:", e) self.err_flag = True self.err_addr.append((self.inst_mov_addr_temp, self.inst_br_addr_temp,"error at get_hit_inst:", e)) self.mu.hook_del(bh_id) self.hook_code_id = self.mu.hook_add(UC_HOOK_CODE, self.hook_code) # print("\n>>> Hit instructions:") # for inst in self.hit_inst: # print(f" 0x{inst.address:x}: {inst.mnemonic} {inst.op_str}") def run_hit_inst(self) -> None: """ 只模拟 hit 指令(hit_inst 列表中的指令)。 """ # print(">>> Running hit instructions") original_pc = self.mu.reg_read(UC_ARM64_REG_PC) for inst in reversed(self.hit_inst): try: self.mu.emu_start(inst.address, inst.address + inst.size) except UcError as e: print("run_hit_inst 模拟出现错误:", e) self.err_flag = True self.err_addr.append((self.inst_mov_addr_temp, self.inst_br_addr_temp, "error at run_hit_inst:", e)) self.mu.reg_write(UC_ARM64_REG_PC, original_pc)""" 利用 LIEF 解析 ELF 文件,将各 section 映射到 Unicorn 内存中。 """ binary = lief.parse(self.binary_path) mapped = {} # 已映射区域字典 for section in binary.sections: vaddr = section.virtual_address mem_size = section.size if mem_size == 0 or vaddr == 0: continue if section.name == ".text": self.text_section = section start_addr = (vaddr // self.PAGE_SIZE) * self.PAGE_SIZE end_addr = ((vaddr + mem_size + self.PAGE_SIZE - 1) // self.PAGE_SIZE) * self.PAGE_SIZE map_size = end_addr - start_addr if start_addr not in mapped: try: self.mu.mem_map(start_addr, map_size) mapped[start_addr] = map_size except UcError as e: print(f"映射地址{section.name} 0x{start_addr:x}(大小 0x{map_size:x})失败: {e}") continue if section.content: data = bytes(section.content) offset = vaddr - start_addr try: self.mu.mem_write(start_addr + offset, data) except UcError as e: print(f"写入数据到地址 0x{start_addr+offset:x} 失败: {e}")""" 利用 LIEF 解析 ELF 文件,将各 section 映射到 Unicorn 内存中。 """ binary = lief.parse(self.binary_path) mapped = {} # 已映射区域字典 for section in binary.sections: vaddr = section.virtual_address mem_size = section.size if mem_size == 0 or vaddr == 0: continue if section.name == ".text": self.text_section = section start_addr = (vaddr // self.PAGE_SIZE) * self.PAGE_SIZE end_addr = ((vaddr + mem_size + self.PAGE_SIZE - 1) // self.PAGE_SIZE) * self.PAGE_SIZE map_size = end_addr - start_addr if start_addr not in mapped: try: self.mu.mem_map(start_addr, map_size) mapped[start_addr] = map_size except UcError as e: print(f"映射地址{section.name} 0x{start_addr:x}(大小 0x{map_size:x})失败: {e}") continue if section.content: data = bytes(section.content) offset = vaddr - start_addr try: self.mu.mem_write(start_addr + offset, data) except UcError as e: print(f"写入数据到地址 0x{start_addr+offset:x} 失败: {e}")loc_1E60 ; CODE XREF: sub_1FD4+2C↓jLDR W8, [SP,#0x1C0+var_140] ; Load from MemoryMOV W9, #2 ; Rd = Op2MOV W10, #0 ; Rd = Op2CMP W8, #0x100 ; Set cond. codes on Op1 - Op2CSEL W8, W9, W10, LT ; Conditional SelectMOV W11, W8 ; Rd = Op2SXTW X11, W11 ; Signed Extend WordMOV X12, #8 ; Rd = Op2MUL X11, X12, X11 ; MultiplyLDR X12, [SP,#0x1C0+var_190] ; Load from MemoryADD X11, X12, X11 ; Rd = Op1 + Op2LDR X11, [X11] ; Load from MemoryMOV W8, #0x464CA149LDR W9, [SP,#0x1C0+var_19C] ; Load from MemorySUBS W8, W8, W9 ; Rd = Op1 - Op2MOV W13, W8 ; Rd = Op2SXTW X13, W13 ; Signed Extend WordADD X11, X11, X13 ; Rd = Op1 + Op2BR X11 ; Branch To Registerloc_1E60 ; CODE XREF: sub_1FD4+2C↓jLDR W8, [SP,#0x1C0+var_140] ; Load from MemoryMOV W9, #2 ; Rd = Op2MOV W10, #0 ; Rd = Op2CMP W8, #0x100 ; Set cond. codes on Op1 - Op2CSEL W8, W9, W10, LT ; Conditional SelectMOV W11, W8 ; Rd = Op2SXTW X11, W11 ; Signed Extend WordMOV X12, #8 ; Rd = Op2MUL X11, X12, X11 ; MultiplyLDR X12, [SP,#0x1C0+var_190] ; Load from MemoryADD X11, X12, X11 ; Rd = Op1 + Op2LDR X11, [X11] ; Load from MemoryMOV W8, #0x464CA149LDR W9, [SP,#0x1C0+var_19C] ; Load from MemorySUBS W8, W8, W9 ; Rd = Op1 - Op2MOV W13, W8 ; Rd = Op2SXTW X13, W13 ; Signed Extend WordADD X11, X11, X13 ; Rd = Op1 + Op2BR X11 ; Branch To RegisterMOV W9, #2 ; Rd = Op2MOV W10, #0 ; Rd = Op2CMP W8, #0x100 ; Set cond. codes on Op1 - Op2CSEL W8, W9, W10, LT ; Conditional Select...cmp w8, w9 beq addr1 ; 等于就跳转,即第一种情况 bne addr2 ; 不等就跳转,即第二种情况 ...BR reg ; patch到这里MOV W9, #2 ; Rd = Op2MOV W10, #0 ; Rd = Op2CMP W8, #0x100 ; Set cond. codes on Op1 - Op2CSEL W8, W9, W10, LT ; Conditional Select...cmp w8, w9 beq addr1 ; 等于就跳转,即第一种情况 bne addr2 ; 不等就跳转,即第二种情况 ...BR reg ; patch到这里nop < mov x1 #rnop < mov x2 #i...cmp xx #0br.ne addr1br addr2nop...nop < mov x1 #rnop < mov x2 #i...cmp xx #0br.ne addr1br addr2nop...def patch_br(self) -> None: """ 扫描 self.csel_addr_temp 到 self.inst_br_addr_temp 区间内的所有指令, 记录所有 STR 指令,将所有 STR 指令上移,其余指令下移, 重新构造新的指令序列:首先放置所有 STR 指令, 然后是两条分支指令, 剩余空间填充 NOP 指令, 最后将组装好的字节补丁写入内存。 """ all_insts = [] # 保存区间内所有(地址, 指令)元组 str_insts = [] # 保存STR类型指令 addr_start = self.csel_addr_temp for addr in range(addr_start, self.inst_br_addr_temp, 4): try: code = self.mu.mem_read(addr, 4) except UcError: continue for inst in self.cs.disasm(code, addr): all_insts.append((addr, inst)) if "str" in inst.mnemonic.lower(): str_insts.append((addr, inst)) print(">>> 扫描到的所有指令:") for addr, inst in all_insts: print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}") print(">>> 其中 STR 指令:") for addr, inst in str_insts: print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}") # 构造新的指令序列 new_inst_list = [] # (1) 添加所有 STR 指令(以其原有汇编文本为准) for _, inst in str_insts: asm_line = f"{inst.mnemonic} {inst.op_str}" new_inst_list.append(asm_line) # (2) 添加两条跳转指令(分支指令),这里假定 self.br_value 存储了两个跳转目标 # 构造分支指令文本(注意汇编语法,根据实际需要可能调整条件代码) b_inst1 = "b.ne #" + hex(self.br_value[0] - self.csel_addr_temp - len(str_insts)*4) b_inst2 = "b #" + hex(self.br_value[1] - self.csel_addr_temp - len(str_insts)*4 - 4) for i in range(2): print(f" 0x{self.inst_br_addr_temp + i * 4:x}: {b_inst1 if i == 0 else b_inst2}") new_inst_list.append(b_inst1) new_inst_list.append(b_inst2) # 使用 Keystone 汇编生成机器码,并计算补丁区域大小 patch_bytes = b"" for asm_line in new_inst_list: try: encoding, _ = self.ks.asm(asm_line) patch_bytes += bytes(encoding) except Exception as e: print(f"组装指令失败 {asm_line}: {e}") # 计算目标区域可用字节数 region_size = self.inst_br_addr_temp - self.csel_addr_temp current_size = len(patch_bytes) print(f"累计补丁字节长度: {current_size}, 目标区域大小: {region_size}") # (3) 如果不足,填充 NOP 指令(ARM64 的 nop 固定4字节) if current_size < region_size: remaining = region_size - current_size nop_count = remaining // 4 # 每个 nop 占4字节 for _ in range(nop_count): try: encoding, _ = self.ks.asm("nop") patch_bytes += bytes(encoding) except Exception as e: print(f"组装 nop 失败: {e}") # 如果超过目标区域,根据需要截断(不要溢出) if len(patch_bytes) > region_size: patch_bytes = patch_bytes[:region_size] print(">>> 重新组装后的补丁字节:") print(patch_bytes.hex()) # 将生成的补丁字节写入内存(写回到原区域起始处) self.patch_code(addr_start, patch_bytes) print(">>> 重写区域内指令:") for addr in range(addr_start, self.inst_br_addr_temp, 4): try: code = self.mu.mem_read(addr, 4) except UcError: continue for inst in self.cs.disasm(code, addr): print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}")def patch_br(self) -> None: """ 扫描 self.csel_addr_temp 到 self.inst_br_addr_temp 区间内的所有指令, 记录所有 STR 指令,将所有 STR 指令上移,其余指令下移, 重新构造新的指令序列:首先放置所有 STR 指令, 然后是两条分支指令, 剩余空间填充 NOP 指令, 最后将组装好的字节补丁写入内存。 """ all_insts = [] # 保存区间内所有(地址, 指令)元组 str_insts = [] # 保存STR类型指令 addr_start = self.csel_addr_temp for addr in range(addr_start, self.inst_br_addr_temp, 4): try: code = self.mu.mem_read(addr, 4) except UcError: continue for inst in self.cs.disasm(code, addr): all_insts.append((addr, inst)) if "str" in inst.mnemonic.lower(): str_insts.append((addr, inst)) print(">>> 扫描到的所有指令:") for addr, inst in all_insts: print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}") print(">>> 其中 STR 指令:") for addr, inst in str_insts: print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}") # 构造新的指令序列 new_inst_list = [] # (1) 添加所有 STR 指令(以其原有汇编文本为准) for _, inst in str_insts: asm_line = f"{inst.mnemonic} {inst.op_str}" new_inst_list.append(asm_line) # (2) 添加两条跳转指令(分支指令),这里假定 self.br_value 存储了两个跳转目标 # 构造分支指令文本(注意汇编语法,根据实际需要可能调整条件代码) b_inst1 = "b.ne #" + hex(self.br_value[0] - self.csel_addr_temp - len(str_insts)*4) b_inst2 = "b #" + hex(self.br_value[1] - self.csel_addr_temp - len(str_insts)*4 - 4) for i in range(2): print(f" 0x{self.inst_br_addr_temp + i * 4:x}: {b_inst1 if i == 0 else b_inst2}") new_inst_list.append(b_inst1) new_inst_list.append(b_inst2) # 使用 Keystone 汇编生成机器码,并计算补丁区域大小 patch_bytes = b"" for asm_line in new_inst_list: try: encoding, _ = self.ks.asm(asm_line) patch_bytes += bytes(encoding) except Exception as e: print(f"组装指令失败 {asm_line}: {e}") # 计算目标区域可用字节数 region_size = self.inst_br_addr_temp - self.csel_addr_temp current_size = len(patch_bytes) print(f"累计补丁字节长度: {current_size}, 目标区域大小: {region_size}") # (3) 如果不足,填充 NOP 指令(ARM64 的 nop 固定4字节) if current_size < region_size: remaining = region_size - current_size nop_count = remaining // 4 # 每个 nop 占4字节 for _ in range(nop_count): try: encoding, _ = self.ks.asm("nop") patch_bytes += bytes(encoding) except Exception as e: print(f"组装 nop 失败: {e}") # 如果超过目标区域,根据需要截断(不要溢出) if len(patch_bytes) > region_size: patch_bytes = patch_bytes[:region_size] print(">>> 重新组装后的补丁字节:") print(patch_bytes.hex()) # 将生成的补丁字节写入内存(写回到原区域起始处) self.patch_code(addr_start, patch_bytes) print(">>> 重写区域内指令:") for addr in range(addr_start, self.inst_br_addr_temp, 4): try: code = self.mu.mem_read(addr, 4) except UcError: continue for inst in self.cs.disasm(code, addr): print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}")import lieffrom unicorn import Uc, UcError, UC_ARCH_ARM64, UC_MODE_ARM, UC_HOOK_CODEfrom unicorn.arm64_const import *from capstone import Cs, CS_ARCH_ARM64, CS_MODE_ARMfrom keystone import Ks, KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIANfrom pwn import u32class Arm64ELFSimulator: # Configuration constants STACK_ADDR = 0x100000 STACK_SIZE = 1024 * 1024 PAGE_SIZE = 0x1000# Must be a divisor of the mapped sizes BASE_ADDR = 0x0 ENTRY_POINT = 0x0 END_POINT = 0x0 # Mapping of register names to Unicorn constants regs_dic = { "x0": UC_ARM64_REG_X0, "x1": UC_ARM64_REG_X1, "x2": UC_ARM64_REG_X2, "x3": UC_ARM64_REG_X3, "x4": UC_ARM64_REG_X4, "x5": UC_ARM64_REG_X5, "x6": UC_ARM64_REG_X6, "x7": UC_ARM64_REG_X7, "x8": UC_ARM64_REG_X8, "x9": UC_ARM64_REG_X9, "x10": UC_ARM64_REG_X10, "x11": UC_ARM64_REG_X11, "x12": UC_ARM64_REG_X12, "x13": UC_ARM64_REG_X13, "x14": UC_ARM64_REG_X14, "x15": UC_ARM64_REG_X15, "x16": UC_ARM64_REG_X16, "x17": UC_ARM64_REG_X17, "x18": UC_ARM64_REG_X18, "x19": UC_ARM64_REG_X19, "x20": UC_ARM64_REG_X20, "x21": UC_ARM64_REG_X21, "x22": UC_ARM64_REG_X22, "x23": UC_ARM64_REG_X23, "x24": UC_ARM64_REG_X24, "x25": UC_ARM64_REG_X25, "x26": UC_ARM64_REG_X26, "x27": UC_ARM64_REG_X27, "x28": UC_ARM64_REG_X28, "x29": UC_ARM64_REG_X29, "x30": UC_ARM64_REG_X30, "sp": UC_ARM64_REG_SP, "pc": UC_ARM64_REG_PC } reg_list = list(regs_dic.values()) def __init__(self, binary_path: str): # Initialize Unicorn, Capstone, Keystone self.mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM) try: self.mu.mem_map(self.STACK_ADDR, self.STACK_SIZE) except UcError as e: print(f"映射栈空间失败: {e}") self.mu.reg_write(UC_ARM64_REG_SP, self.STACK_ADDR + self.STACK_SIZE - 100) self.binary_path = binary_path self.cs = Cs(CS_ARCH_ARM64, CS_MODE_ARM) self.ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN) # Simulation state self.hit_inst = [] self.csel_handled = False self.csel_handled = [] self.err_addr = [] # Load ELF sections and record .text section for later analysis self.text_section = None self.load_elf_sections() # 初始化预置寄存器及临时变量 self.mu.reg_write(UC_ARM64_REG_X9, 0x7B6C5B9A) self.inst_mov_addr_temp = 0 self.inst_br_addr_temp = 0 self.br_reg = 0 self.csel_addr_temp = 0 self.csel_args = (0,0,0) self.br_value = (0,0) self.err_flag = False def load_elf_sections(self) -> None: """ 利用 LIEF 解析 ELF 文件,将各 section 映射到 Unicorn 内存中。 """ binary = lief.parse(self.binary_path) mapped = {} # 已映射区域字典 for section in binary.sections: vaddr = section.virtual_address mem_size = section.size if mem_size == 0 or vaddr == 0: continue if section.name == ".text": self.text_section = section start_addr = (vaddr // self.PAGE_SIZE) * self.PAGE_SIZE end_addr = ((vaddr + mem_size + self.PAGE_SIZE - 1) // self.PAGE_SIZE) * self.PAGE_SIZE map_size = end_addr - start_addr if start_addr not in mapped: try: self.mu.mem_map(start_addr, map_size) mapped[start_addr] = map_size except UcError as e: print(f"映射地址{section.name} 0x{start_addr:x}(大小 0x{map_size:x})失败: {e}") continue if section.content: data = bytes(section.content) offset = vaddr - start_addr try: self.mu.mem_write(start_addr + offset, data) except UcError as e: print(f"写入数据到地址 0x{start_addr+offset:x} 失败: {e}") def patch_elf_sections(self, output_file: str) -> None: """ 从 Unicorn 内存中提取所有映射成功的段内容,然后将这些数据 patch 回 ELF 文件,并写入到 output_file 中。 """ # 通过 LIEF 重新解析原始 ELF 文件 elf = lief.parse(self.binary_path) for section in elf.sections: if section.name == ".text" or section.name == ".initarray" or section.name == ".finiarray": vaddr = section.virtual_address mem_size = section.size if mem_size == 0 or vaddr == 0: continue # 根据 PAGE_SIZE 计算映射的起始地址和实际偏移量 start_addr = (vaddr // self.PAGE_SIZE) * self.PAGE_SIZE offset = vaddr - start_addr try: # 从 Unicorn 内存中读取 section 内容,读取大小为 section.size new_content = self.mu.mem_read(start_addr + offset, mem_size) # LIEF 要求 section.content 为列表形式 section.content = list(new_content) print(f"Section {section.name} 更新成功, vaddr: 0x{vaddr:x}, size: {mem_size}") except UcError as e: print(f"读取段 {section.name} 内存失败: {e}") else : continue try: elf.write(output_file) print(f"已将修补后的 ELF 写入到: {output_file}") except Exception as e: print(f"写入补丁 ELF 失败: {e}") def find_reg_jmp_addr(self) -> list: """ 遍历 .text 段寻找寄存器间接跳转地址,返回 tup( mov_addr, br_addr, reg) 列表。 """ reg_jmp_addr = [] addr = self.text_section.virtual_address while addr < self.text_section.virtual_address + self.text_section.size: mov_addr = self.find_mov(addr) if mov_addr: br_addr, reg = self.find_br(mov_addr) if br_addr: reg_jmp_addr.append((mov_addr, br_addr, reg)) addr = br_addr addr += 4 return reg_jmp_addr def find_mov(self, addr: int) -> int: """ 搜索连续两条带立即数的 mov 指令, 返回目标 mov 指令的地址,未找到则返回 0。 """ try: code = self.mu.mem_read(addr, 4) except UcError: print(f">>> read error at find_mov: {hex(addr)}") return 0 for inst in self.cs.disasm(code, addr): if inst.mnemonic == "mov" and '#' in inst.op_str: addr += 4 try: code2 = self.mu.mem_read(addr, 4) except UcError: print(f">>> read error at find_mov: {hex(addr)}") continue for inst_b in self.cs.disasm(code2, addr): if inst_b.mnemonic == "mov" and '#' in inst_b.op_str: return addr return 0 def find_br(self, addr: int) -> tuple: """ 向后搜索 'br' 指令,返回 (addr, operand) 元组, 未找到时返回 (0, 0)。 """ for _ in range(1, 100): try: code = self.mu.mem_read(addr, 4) except UcError: print(f">>> read error at find_br: {hex(addr)}") addr += 4 continue for inst in self.cs.disasm(code, addr): if inst.mnemonic == "br": return addr, inst.op_str addr += 4 print(f">>> find_br 未找到, addr: {hex(addr - 400)}") return 0, 0 def print_regs(self) -> None: """ 打印当前所有寄存器的值 """ print(">>> Registers:") for name, reg in self.regs_dic.items(): print(f" {name} = 0x{self.mu.reg_read(reg):x}") def print_stack_sp(self) -> None: """ 打印当前栈区域的部分内容 """ sp = self.mu.reg_read(UC_ARM64_REG_SP) print(">>> Stack:") for i in range(0, 32, 4): try: data = self.mu.mem_read(sp + i, 4) print(f" 0x{sp + i:x}: {u32(data):x}") except UcError: print(f" 0x{sp + i:x}: ???") print("") def save_state(self) -> dict: """ 保存当前寄存器状态 """ return {reg: self.mu.reg_read(reg) for reg in self.reg_list} def restore_state(self, state: dict) -> None: """ 恢复寄存器状态 """ for reg, value in state.items(): self.mu.reg_write(reg, value) def clear_state(self) -> None: """ 清空所有寄存器,并重置 csel 标志 """ self.csel_handled = False for reg in self.reg_list: self.mu.reg_write(reg, 0) def hit_hook(self, mu: Uc, addr: int, size: int, user_data) -> None: """ 代码 hook,用于捕获并存储 hit 指令(通过向上追踪含 SP 且 ldr 指令)。 """ try: code = mu.mem_read(addr, size) except UcError: return for inst in self.cs.disasm(code, addr): # print(f"hit hook : >>> {hex(addr)} {inst.mnemonic} {inst.op_str}") if inst.mnemonic.lower() == "br": mu.emu_stop() break if inst.mnemonic.lower() == "stur" or inst.mnemonic.lower() == "ldur": self.mu.reg_write(UC_ARM64_REG_PC, addr + size) # print(f">>> stur or ldur detected, skip") return if "sp" in inst.op_str and "ldr" in inst.mnemonic: # print(f"attached ldr sp instruction: {inst.mnemonic} {inst.op_str}") parts = inst.op_str.split(", [") target = parts[0] if "sp" in parts[0] else parts[1] target_state = False target2 = "" curr_addr = addr for _ in range(1, 200): curr_addr -= inst.size try: code_b = mu.mem_read(curr_addr, 4) except UcError: continue for inst_b in self.cs.disasm(code_b, curr_addr): if target in inst_b.op_str and "ldr" not in inst_b.mnemonic and not target_state: # print(f"hit instruction: {inst_b.mnemonic} {inst_b.op_str}") target_state = True self.hit_inst.append(inst_b) parts_b = inst_b.op_str.split(", ") target2 = parts_b[0] if target not in parts_b[0] else parts_b[1] break if target_state and target2 in inst_b.op_str and "mov" in inst_b.mnemonic and '#0x' in inst_b.op_str: self.hit_inst.append(inst_b) if target_state and target2 in inst_b.op_str and 'adr' in inst_b.mnemonic: # print(f"hit instruction: {inst_b.mnemonic} {inst_b.op_str}") if "adrp" in inst_b.mnemonic: try: next_code = mu.mem_read(curr_addr + inst_b.size, 4) except UcError: continue for inst_el in self.cs.disasm(next_code, curr_addr + inst_b.size): if "add" in inst_el.mnemonic: self.hit_inst.append(inst_el) self.hit_inst.append(inst_b) else: self.hit_inst.append(inst_b) return def branch_hook(self, mu: Uc, addr: int, size: int, user_data) -> None: """ 当执行到 BR 指令时停止模拟 """ try: code = mu.mem_read(addr, size) except UcError: return for inst in self.cs.disasm(code, addr): if inst.mnemonic.lower() == "br": # print(f">>> BR 指令在 0x{addr:x} 被触发,停止模拟") mu.emu_stop() break def get_hit_inst(self, addr: int) -> None: """ 从指定地址向后模拟收集 hit 指令 """ # print(f">>> Getting hit instructions from 0x{addr:x} to 0x{self.inst_br_addr_temp:x}") bh_id = self.mu.hook_add(UC_HOOK_CODE, self.hit_hook) self.mu.hook_del(self.hook_code_id) # 搜寻前面的有没有立即数存储指令 for i in range(1, 50): try: code = self.mu.mem_read(addr - i * 4, 4) except UcError: continue for inst in self.cs.disasm(code, addr - i * 4): # print(f"get_hit_inst : >>> {hex(addr - i * 4)} {inst.mnemonic} {inst.op_str}") if ("mov" in inst.mnemonic or "ldr" in inst.mnemonic ) and '#' in inst.op_str: self.hit_inst.append(inst) try: self.mu.emu_start(addr - 4, self.inst_br_addr_temp) except UcError as e: print("模拟过程中出现错误:", e) self.err_flag = True self.err_addr.append((self.inst_mov_addr_temp, self.inst_br_addr_temp,"error at get_hit_inst:", e)) self.mu.hook_del(bh_id) self.hook_code_id = self.mu.hook_add(UC_HOOK_CODE, self.hook_code) # print("\n>>> Hit instructions:") # for inst in self.hit_inst: # print(f" 0x{inst.address:x}: {inst.mnemonic} {inst.op_str}") def run_hit_inst(self) -> None: """ 只模拟 hit 指令(hit_inst 列表中的指令)。 """ # print(">>> Running hit instructions") original_pc = self.mu.reg_read(UC_ARM64_REG_PC) for inst in reversed(self.hit_inst): try: self.mu.emu_start(inst.address, inst.address + inst.size) except UcError as e: print("run_hit_inst 模拟出现错误:", e) self.err_flag = True self.err_addr.append((self.inst_mov_addr_temp, self.inst_br_addr_temp, "error at run_hit_inst:", e)) self.mu.reg_write(UC_ARM64_REG_PC, original_pc) def patch_code(self, addr: int, patch_bytes: bytes) -> None: """ 打补丁,将代码修改为 patch_bytes """ self.mu.mem_write(addr, patch_bytes) # print(f">>> 已将地址 0x{addr:x} patch 为 {patch_bytes}") def hook_code(self, mu: Uc, address: int, size: int, user_data) -> None: """ 检测 CSEL 指令,进行向后分析并实现分支变种测试 """ try: code = mu.mem_read(address, size) except UcError: return for inst in self.cs.disasm(code, address): # print(f">>> addr:{hex(address)} {inst.mnemonic} {inst.op_str}") if inst.mnemonic.lower() == "stur" or inst.mnemonic.lower() == "ldur": self.mu.reg_write(UC_ARM64_REG_PC, address + size) # print(f">>> stur or ldur detected, skip") return if inst.mnemonic.lower() == "csel" and not self.csel_handled: # print(">>> csel detected") self.csel_handled = True self.csel_addr_temp = address saved_state = self.save_state() # 保存当前状态 # 使用 mov_addr_temp 作为先前的 mov 指令地址 # print(">>> start get hit inst\n") # self.print_regs() mov_addr = self.inst_mov_addr_temp self.hit_inst = [] # 重置 hit 指令列表 self.get_hit_inst(mov_addr) self.run_hit_inst() self.restore_state(saved_state) operands = inst.op_str.split(", ") self.csel_args = (operands[0],operands[1], operands[2]) mov_inst1 = f"mov {operands[0]}, {operands[1]};" mov_inst2 = f"mov {operands[0]}, {operands[2]};" asm_mov_branch1, _ = self.ks.asm(mov_inst1) asm_mov_branch2, _ = self.ks.asm(mov_inst2) def run_branch_test(patch_bytes: list, branch_label: str) -> dict: self.mu.mem_write(self.csel_addr_temp, bytes(patch_bytes)) # print(f">>> 已将 csel 指令 patch 为 {branch_label},开始执行至遇到 BR 指令") bh_id = self.mu.hook_add(UC_HOOK_CODE, self.branch_hook) try: self.mu.emu_start(self.inst_mov_addr_temp - 4, self.inst_br_addr_temp) except UcError as e: print("run_branch_test 模拟错误:", e) self.err_flag = True self.err_addr.append((self.inst_mov_addr_temp, self.inst_br_addr_temp,"error at run_branch_test:", e)) self.mu.hook_del(bh_id) return self.save_state() # print(">>> Executing first branch variation") self.run_hit_inst() saved_state = self.save_state() state_branch1 = run_branch_test(asm_mov_branch1, mov_inst1) self.restore_state(saved_state) self.run_hit_inst() # print(">>> Executing second branch variation") state_branch2 = run_branch_test(asm_mov_branch2, mov_inst2) print(">>> Final state:") br_value1 = state_branch1.get(self.regs_dic[self.br_reg], 0) br_value2 = state_branch2.get(self.regs_dic[self.br_reg], 0) if br_value1 + br_value2 > 0x10000: print(f"maybe br addr error: {hex(br_value1)} , {hex(br_value2)}") # self.print_regs() self.err_flag = True self.err_addr.append((self.inst_mov_addr_temp, self.inst_br_addr_temp,"error at run_branch_test:",0)) return else: print(f" 1: {hex(br_value1)}") print(f" 2: {hex(br_value2)}") self.br_value = (br_value1, br_value2) self.mu.emu_stop() return def emulate_single_addr(self,mov_addr, br_addr, br_reg) -> None: """ 模拟执行单组地址 """ self.inst_mov_addr_temp = mov_addr self.inst_br_addr_temp = br_addr self.br_reg = br_reg # print(f"\n>>> Processing indirect jump: mov_addr=0x{mov_addr:x}, br_addr=0x{br_addr:x}, br_reg={br_reg}") try: self.clear_state() self.hook_code_id = self.mu.hook_add(UC_HOOK_CODE, self.hook_code) self.mu.emu_start(self.BASE_ADDR + mov_addr, br_addr) self.mu.hook_del(self.hook_code_id) except UcError as e: print("run() 执行错误:", e) self.err_flag = True self.err_addr.append((mov_addr, br_addr, "error at run():", e)) # python def patch_br(self) -> None: """ 扫描 self.csel_addr_temp 到 self.inst_br_addr_temp 区间内的所有指令, 记录所有 STR 指令,将所有 STR 指令上移,其余指令下移, 重新构造新的指令序列:首先放置所有 STR 指令, 然后是两条分支指令, 剩余空间填充 NOP 指令(注意:不能超过原区域大小)。 最后将组装好的字节补丁写入内存。 """ all_insts = [] # 保存区间内所有(地址, 指令)元组 str_insts = [] # 保存STR类型指令 addr_start = self.csel_addr_temp for addr in range(addr_start, self.inst_br_addr_temp, 4): try: code = self.mu.mem_read(addr, 4) except UcError: continue for inst in self.cs.disasm(code, addr): all_insts.append((addr, inst)) if "str" in inst.mnemonic.lower(): str_insts.append((addr, inst)) # print(">>> 扫描到的所有指令:") # for addr, inst in all_insts: # print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}") # print(">>> 其中 STR 指令:") # for addr, inst in str_insts: # print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}") # 构造新的指令序列 new_inst_list = [] # (1) 添加所有 STR 指令(以其原有汇编文本为准) for _, inst in str_insts: asm_line = f"{inst.mnemonic} {inst.op_str}" new_inst_list.append(asm_line) # (2) 添加两条跳转指令(分支指令),这里假定 self.br_value 存储了两个跳转目标 # 构造分支指令文本(注意汇编语法,根据实际需要可能调整条件代码) b_inst1 = "b.ne #" + hex(self.br_value[0] - self.csel_addr_temp - len(str_insts)*4) b_inst2 = "b #" + hex(self.br_value[1] - self.csel_addr_temp - len(str_insts)*4 - 4) for i in range(2): print(f" 0x{self.inst_br_addr_temp + i * 4:x}: {b_inst1 if i == 0 else b_inst2}") new_inst_list.append(b_inst1) new_inst_list.append(b_inst2) # 使用 Keystone 汇编生成机器码,并计算补丁区域大小 patch_bytes = b"" for asm_line in new_inst_list: try: encoding, _ = self.ks.asm(asm_line) patch_bytes += bytes(encoding) except Exception as e: print(f"组装指令失败 {asm_line}: {e}") # 计算目标区域可用字节数 region_size = self.inst_br_addr_temp - self.csel_addr_temp current_size = len(patch_bytes) # print(f"累计patch字节长度: {current_size}, 目标区域大小: {region_size}") # (3) 如果不足,填充 NOP 指令(ARM64 的 nop 固定4字节) if current_size < region_size: remaining = region_size - current_size nop_count = remaining // 4 # 每个 nop 占4字节 for _ in range(nop_count): try: encoding, _ = self.ks.asm("nop") patch_bytes += bytes(encoding) except Exception as e: print(f"组装 nop 失败: {e}") # 如果超过目标区域,根据需要截断(不要溢出) if len(patch_bytes) > region_size: patch_bytes = patch_bytes[:region_size] # print(">>> 重新组装后的补丁字节:") # print(patch_bytes.hex()) # 将生成的补丁字节写入内存(写回到原区域起始处) self.patch_code(addr_start, patch_bytes) # print(">>> 重写区域内指令:") for addr in range(addr_start, self.inst_br_addr_temp, 4): try: code = self.mu.mem_read(addr, 4) except UcError: continue # for inst in self.cs.disasm(code, addr): # print(f" 0x{addr:x}: {inst.mnemonic} {inst.op_str}") def run(self) -> None: """ 启动模拟执行,先收集间接跳转地址,再逐个模拟 """ self.reg_jmp_addr = self.find_reg_jmp_addr() for addr in self.reg_jmp_addr: print(f"indirect jmp addr: 0x{addr[0]:x}, br addr: 0x{addr[1]:x}, br reg: {addr[2]}") print(f"\n>>> 共找到 {len(self.reg_jmp_addr)} 个间接跳转地址") cnt = 0 for mov_addr, br_addr, br_reg in self.reg_jmp_addr: # if br_addr != 0x1638: # continue cnt+=1 # print(f"\n>>> Processing indirect jump {cnt}: mov_addr=0x{mov_addr:x}, br_addr=0x{br_addr:x}, br_reg={br_reg}") try: self.emulate_single_addr(mov_addr, br_addr, br_reg) if self.err_flag: self.err_flag = False continue self.patch_br() except: continue if self.err_addr: print("\n>>> Error addresses:") for addr in self.err_addr: print(f" indirect jmp addr: 0x{addr[0]:x}, br addr: 0x{addr[1]:x} , {addr[2]} , {addr[3]}") for addr in self.err_addr: print(f"( {addr[0]} , {addr[1]} , \" {addr[2]} \") ," , end="") def main() -> None: binary_path = r"F:\_reverse_study\_unicorn_study\task1\easy-re" simulator = Arm64ELFSimulator(binary_path) simulator.run() # simulator.run_err_addr(err_addr) simulator.patch_elf_sections(binary_path + "_patched")if __name__ == "__main__": main()import lieffrom unicorn import Uc, UcError, UC_ARCH_ARM64, UC_MODE_ARM, UC_HOOK_CODEfrom unicorn.arm64_const import *from capstone import Cs, CS_ARCH_ARM64, CS_MODE_ARMfrom keystone import Ks, KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIANfrom pwn import u32class Arm64ELFSimulator: # Configuration constants STACK_ADDR = 0x100000 STACK_SIZE = 1024 * 1024 PAGE_SIZE = 0x1000# Must be a divisor of the mapped sizes BASE_ADDR = 0x0 ENTRY_POINT = 0x0 END_POINT = 0x0 # Mapping of register names to Unicorn constants regs_dic = { "x0": UC_ARM64_REG_X0, "x1": UC_ARM64_REG_X1, "x2": UC_ARM64_REG_X2, "x3": UC_ARM64_REG_X3, "x4": UC_ARM64_REG_X4, "x5": UC_ARM64_REG_X5, "x6": UC_ARM64_REG_X6, "x7": UC_ARM64_REG_X7, "x8": UC_ARM64_REG_X8, "x9": UC_ARM64_REG_X9, "x10": UC_ARM64_REG_X10, "x11": UC_ARM64_REG_X11, "x12": UC_ARM64_REG_X12, "x13": UC_ARM64_REG_X13, "x14": UC_ARM64_REG_X14, "x15": UC_ARM64_REG_X15, "x16": UC_ARM64_REG_X16, "x17": UC_ARM64_REG_X17, "x18": UC_ARM64_REG_X18, "x19": UC_ARM64_REG_X19, "x20": UC_ARM64_REG_X20, "x21": UC_ARM64_REG_X21, "x22": UC_ARM64_REG_X22, "x23": UC_ARM64_REG_X23, "x24": UC_ARM64_REG_X24, "x25": UC_ARM64_REG_X25, "x26": UC_ARM64_REG_X26, "x27": UC_ARM64_REG_X27, "x28": UC_ARM64_REG_X28, "x29": UC_ARM64_REG_X29, "x30": UC_ARM64_REG_X30, "sp": UC_ARM64_REG_SP, "pc": UC_ARM64_REG_PC } reg_list = list(regs_dic.values()) def __init__(self, binary_path: str): # Initialize Unicorn, Capstone, Keystone self.mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM) try: self.mu.mem_map(self.STACK_ADDR, self.STACK_SIZE) except UcError as e: print(f"映射栈空间失败: {e}") self.mu.reg_write(UC_ARM64_REG_SP, self.STACK_ADDR + self.STACK_SIZE - 100) self.binary_path = binary_path self.cs = Cs(CS_ARCH_ARM64, CS_MODE_ARM) self.ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN) # Simulation state self.hit_inst = [] self.csel_handled = False self.csel_handled = [] self.err_addr = [] # Load ELF sections and record .text section for later analysis self.text_section = None self.load_elf_sections() # 初始化预置寄存器及临时变量 self.mu.reg_write(UC_ARM64_REG_X9, 0x7B6C5B9A) self.inst_mov_addr_temp = 0 self.inst_br_addr_temp = 0 self.br_reg = 0 self.csel_addr_temp = 0 self.csel_args = (0,0,0) self.br_value = (0,0) self.err_flag = False def load_elf_sections(self) -> None: """ 利用 LIEF 解析 ELF 文件,将各 section 映射到 Unicorn 内存中。 """ binary = lief.parse(self.binary_path) mapped = {} # 已映射区域字典 for section in binary.sections: vaddr = section.virtual_address mem_size = section.size if mem_size == 0 or vaddr == 0: continue if section.name == ".text": self.text_section = section start_addr = (vaddr // self.PAGE_SIZE) * self.PAGE_SIZE end_addr = ((vaddr + mem_size + self.PAGE_SIZE - 1) // self.PAGE_SIZE) * self.PAGE_SIZE map_size = end_addr - start_addr if start_addr not in mapped: try: self.mu.mem_map(start_addr, map_size) mapped[start_addr] = map_size[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
\\l4n//
|
|
|
感谢分享
|
|
|
直接用脚本去跑出现以下错误
写入数据到地址 0xf20 失败: Invalid memory write (UC_ERR_WRITE_UNMAPPED) 映射地址.rodata 0x2000(大小 0x1000)失败: Invalid memory mapping (UC_ERR_MAP) 映射地址.eh_frame_hdr 0x2000(大小 0x1000)失败: Invalid memory mapping (UC_ERR_MAP) 映射地址.eh_frame 0x2000(大小 0x2000)失败: Invalid memory mapping (UC_ERR_MAP) 怎么回事啊 我调试的时候发现遇到plt这些 就无法成功映射 哭 |
|
|
rodata也是 是不是得加点处理的东西呀 |
|
|
|





