之前的帖子清理了jumpout,本文尝试静态分析和利用frida来分析mtgsig参数。
定位算法的步骤这里就省略了,直接从一个hook结果开始分析:
从上面结果可以看出一些很长的猜测很关键的字段base64字符串,所以直接利用ida的插件搜索算法特征。
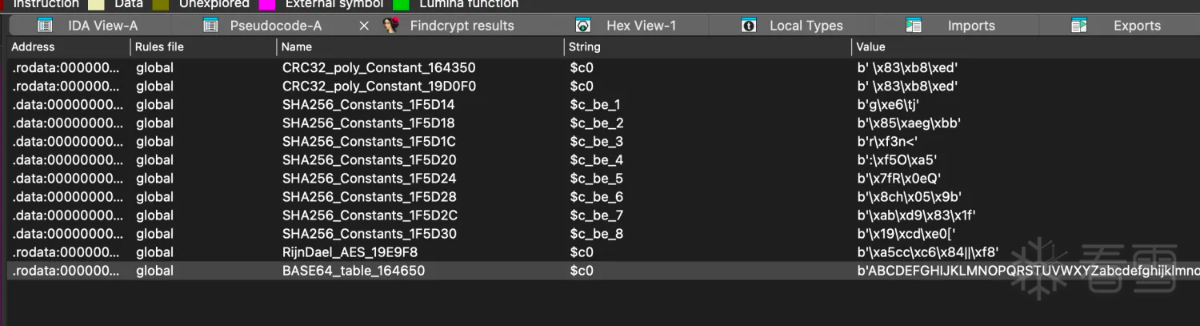
利用上面特征可以定位到函数sub_4cf88, 利用frida hook验证参数中的字段是否出现在此函数中:
通过验证分析看到a5参数调用了此函数,所以分析a5:
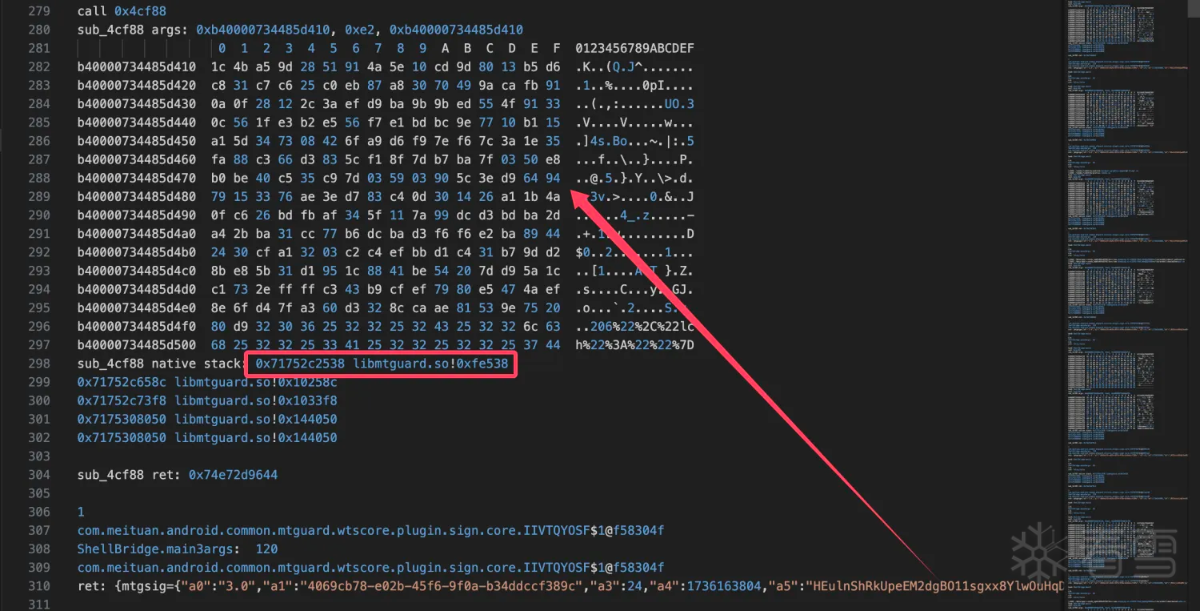
利用堆栈轻松找到调用base64的位置0xfe538:
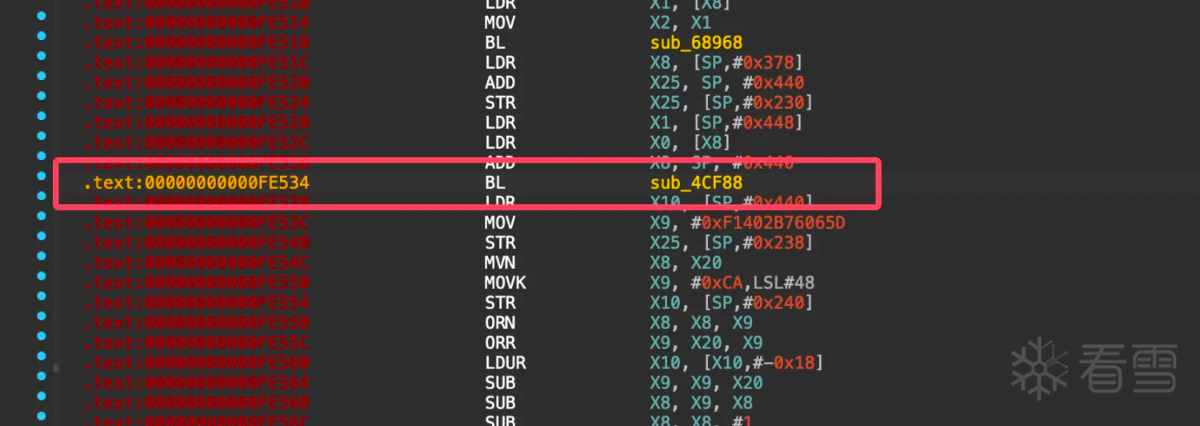
从上图可以看出确实调用了base64函数,但是此位置无法使用f5生成伪C代码,从这里向前翻查找最近的函数序言或者可能函数,查看为什么后面无法被f5,找到函数0xfdaa4如下图所示:
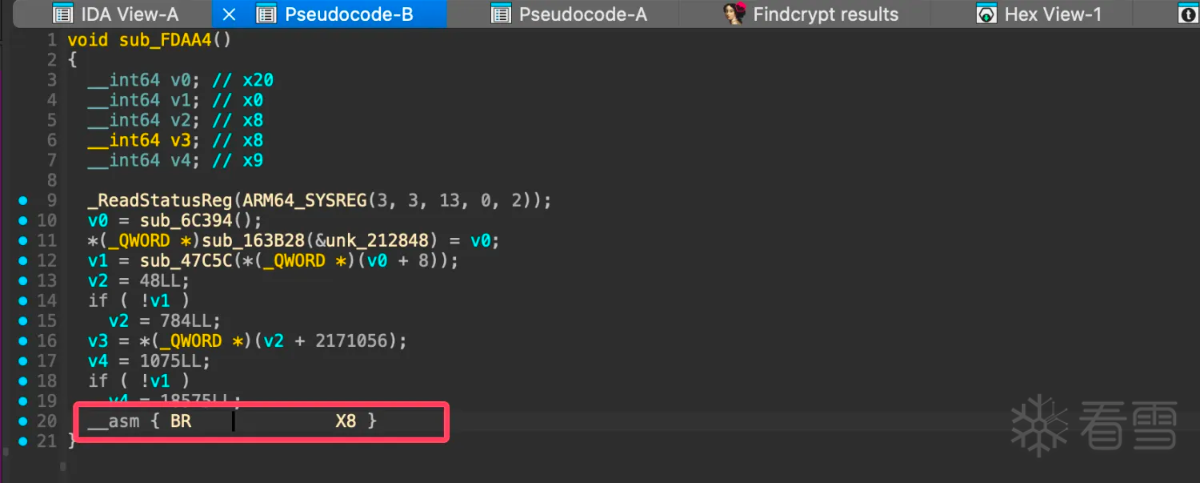
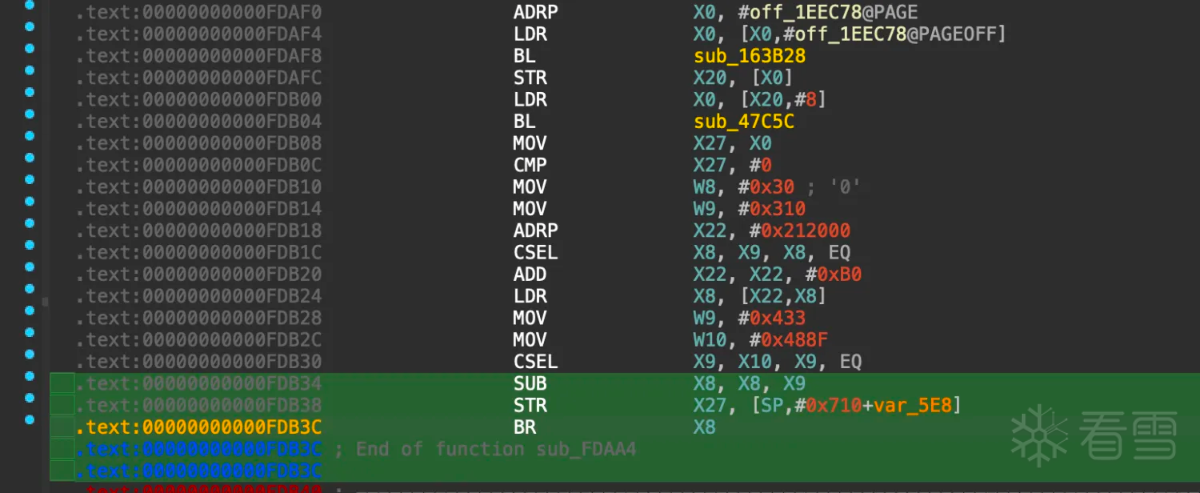
是一个BR X8的跳转,ida无法计算x8的值所以没有办法继续向下分析。
仔细分析跳转位置的汇编指令,分析跳转的逻辑:
简单阅读上面的指令,这个br逻辑可以利用现有的信息计算,看着很像是基于跳转表的跳转。用unicron模拟测试一下:
利用上面模拟可以看出,是从so文件中获取跳转表,并根据不同的条件计算出不同的地址。所以这部分可以恢复,起码可以部分恢复。接下来则是需要分析这种跳转模式在当前函数中有多少,然后识别出来手动计算分支清理出跳转地址。首先需要确定当前0xfdaa4函数的范围,可以利用函数的特征或者是其他手段确认,这里可以尝试利用跳转表x22的特性确认,x22的值一般在同一个函数内是不会变化的,所以直接从函数开始搜索和x22修改读取相关的汇编指令:
结果就不展示了,利用上面函数的搜索脚本可以分析出相邻函数0x100cac, elf
文件一般函数和函数之间不会出现交叉,除非有内联函数或者是其他编译优化策略共用代码块,这里就当一般情况处理。函数范围已经确定,并且通过观察ldr读取跳转表指令可以分析出都是通过x22 + 偏移量的方式寻址,这里只有偏移量计算方式的不同:
1. 立即数
2. 寄存器
3. 寄存器移位操作,这里很单一,只有LSL#3
同时按照上面的寻址方式静态分析,可以看到还有一种其他跳转方式:

这种方式比较简单,直接读取基地址,然后加减偏移量,没有条件选择。
接下来则是通过搜索匹配这些跳转位置收集信息计算地址然后patch。
首先搜索BR Xd语句:
通过上面函数收集到跳转地址之后,需要利用特征收集关键信息,将之前的两种跳转分类成条件跳转case1和无条件跳转case2.case1关键信息特征为:
case2关键信息特征为:
通过上面总结的特征完成信息收集:
通过上面函数收集到关键信息计算条件跳转地址和无条件跳转地址,并且给出patch位置。所以case1的patch思路是:
case2的patch思路:
利用前面的信息计算跳转地址
上面的寄存器值从之前的unicorn模拟执行中可以找到,至此差不多就完全将逻辑替换完成了,只剩最后一步将语句patch进去
清理之后的结果
清理完成之后这个函数大致就可以静态分析。回到最初调用base64函数的部分:
直接hook函数sub_4cf88和函数sub_68968因为两个函数都有统一个参数v154:
hook结果对比:
可以看出sub_68968的结果和base64函数的输入一致。进入函数sub_68968看到如下:

进入函数sub_10f0f8:
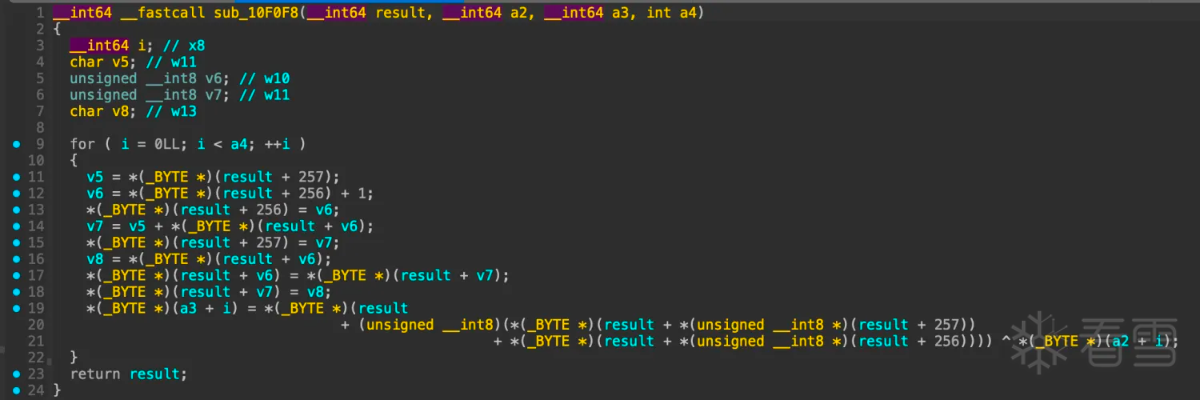
看着好像是rc4加密,搜索一份c语言rc4加密函数对比:
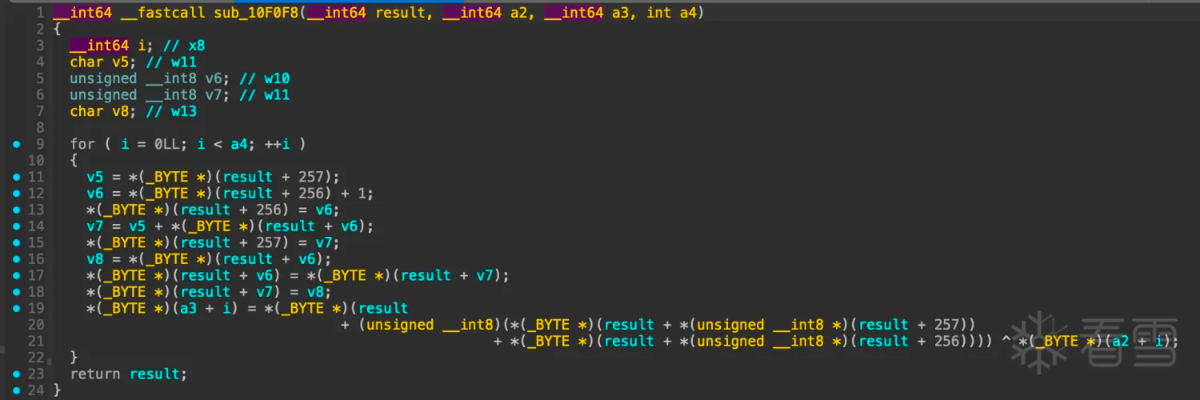

对比起来看真的很像,如果是rc4,那么result应该是sbox,接着看函数sub_68958,hook验证

那么sub_68958极有可能是rc4 init函数:
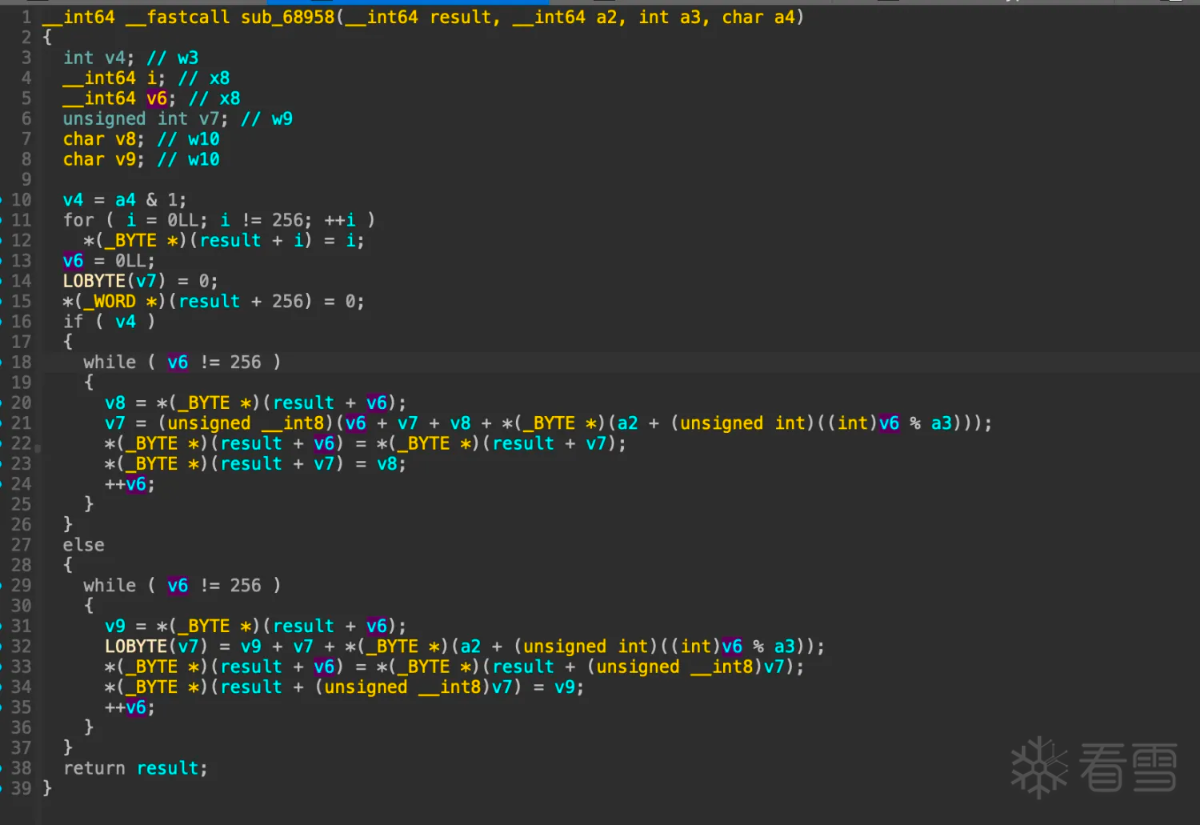
网上搜索rc4 init函数:

好像在rc4 init 过程中多加了一个下标i。先看看key是啥,然后写代码验证魔改位置, 从网上抄个python版本的rc4 init:
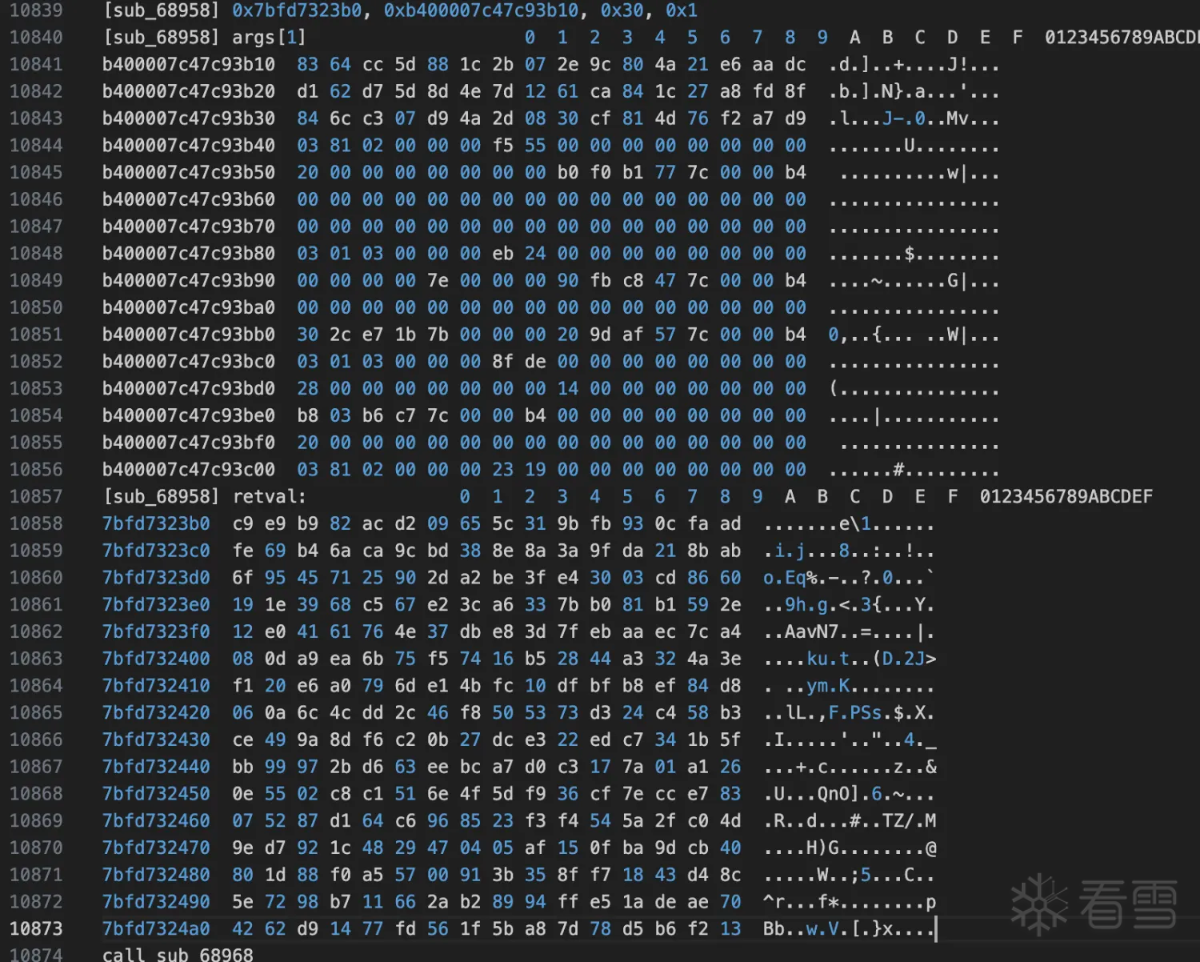
将上面的key带入到修改的rc4 init中:得到如下结果:

验证通过的确是修改了rc4 init函数中的部分。接着看rc4的输入数据然后统一验证。继续向上查看sub_34844函数是和输入相关的
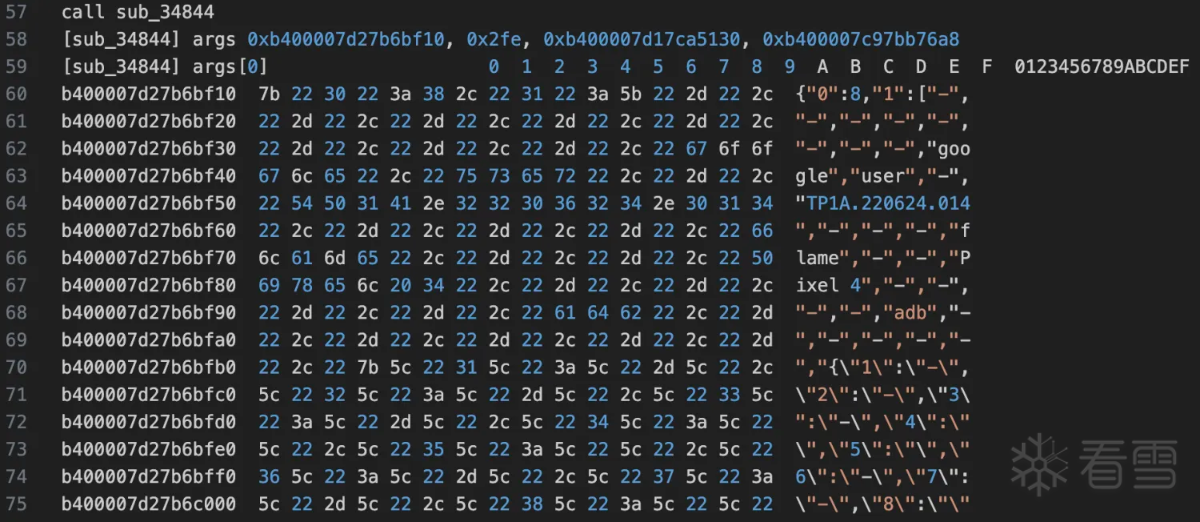
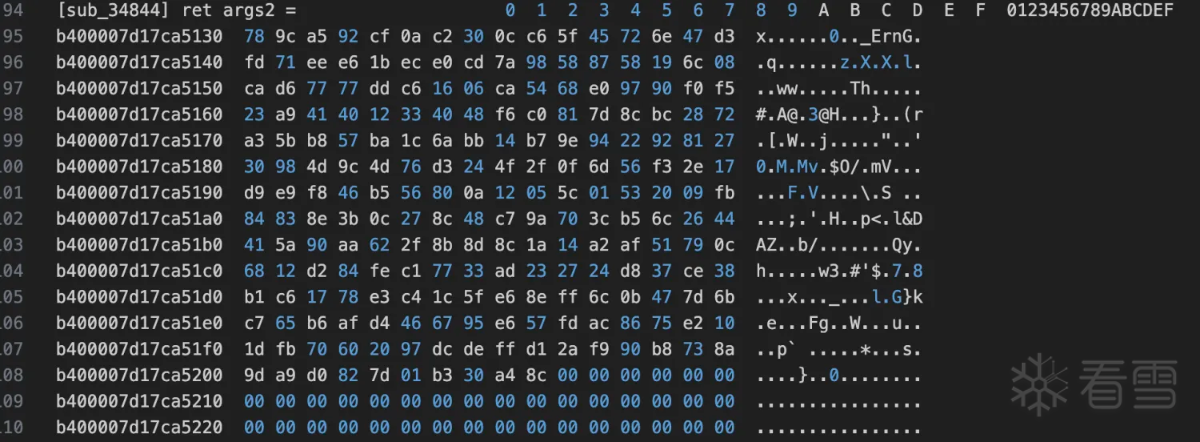
从上面可以看出是一个json字符串应该是一些设备信息相关的压缩后得到的,开头两个字节zlib的默认压缩方式。接着需要看rc4的key是什么,因为每次hook输入的key都是变化的。
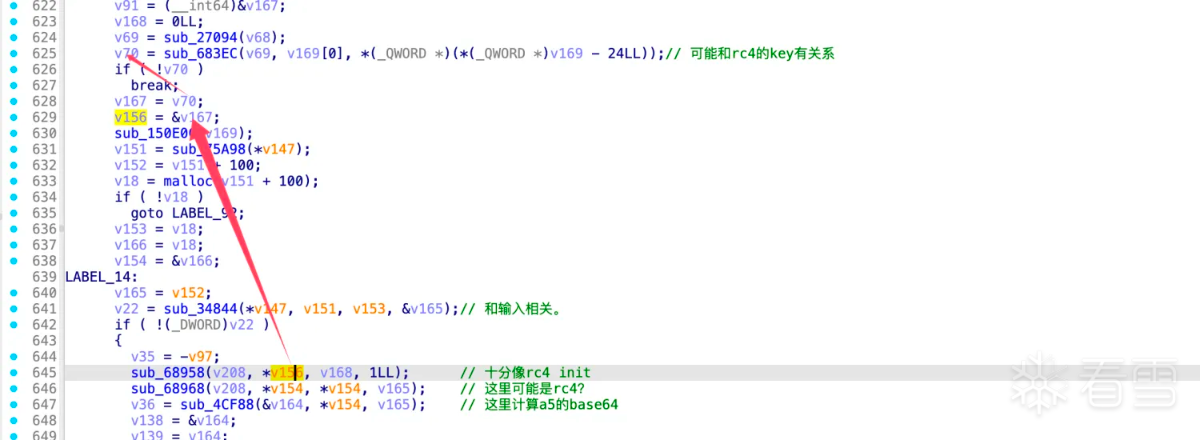
所以函数sub_683ec应该是计算rc4 key的,hook验证:
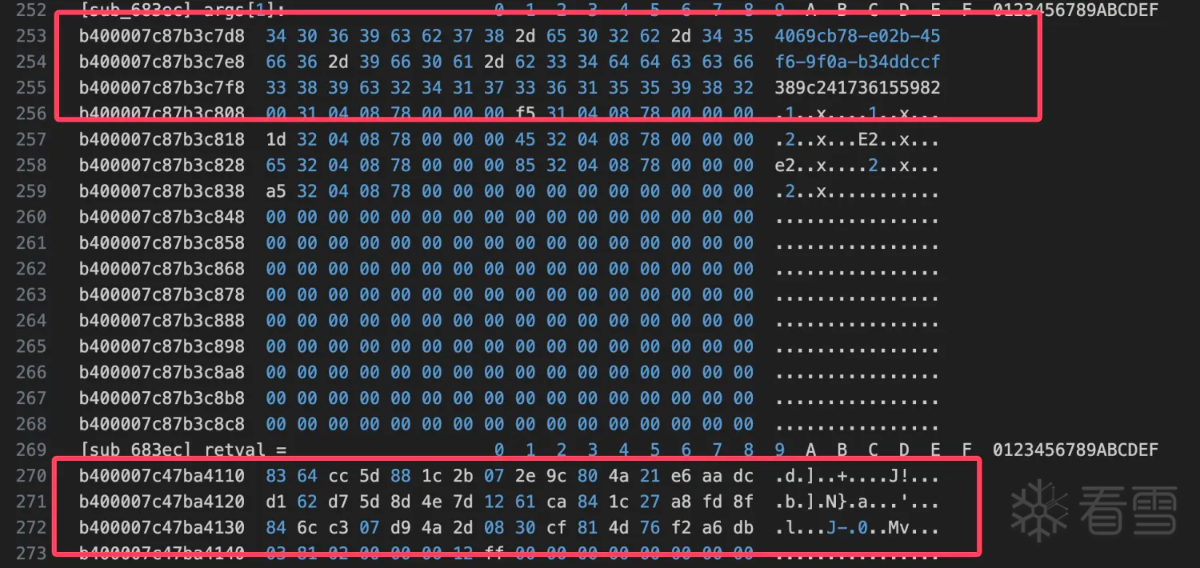

两个函数的数据对比没有问题确实如此。至此算法流程还是比较清晰的,下面用python简单验证一下hook日志中的数据。首先是rc4 算法key的生成:
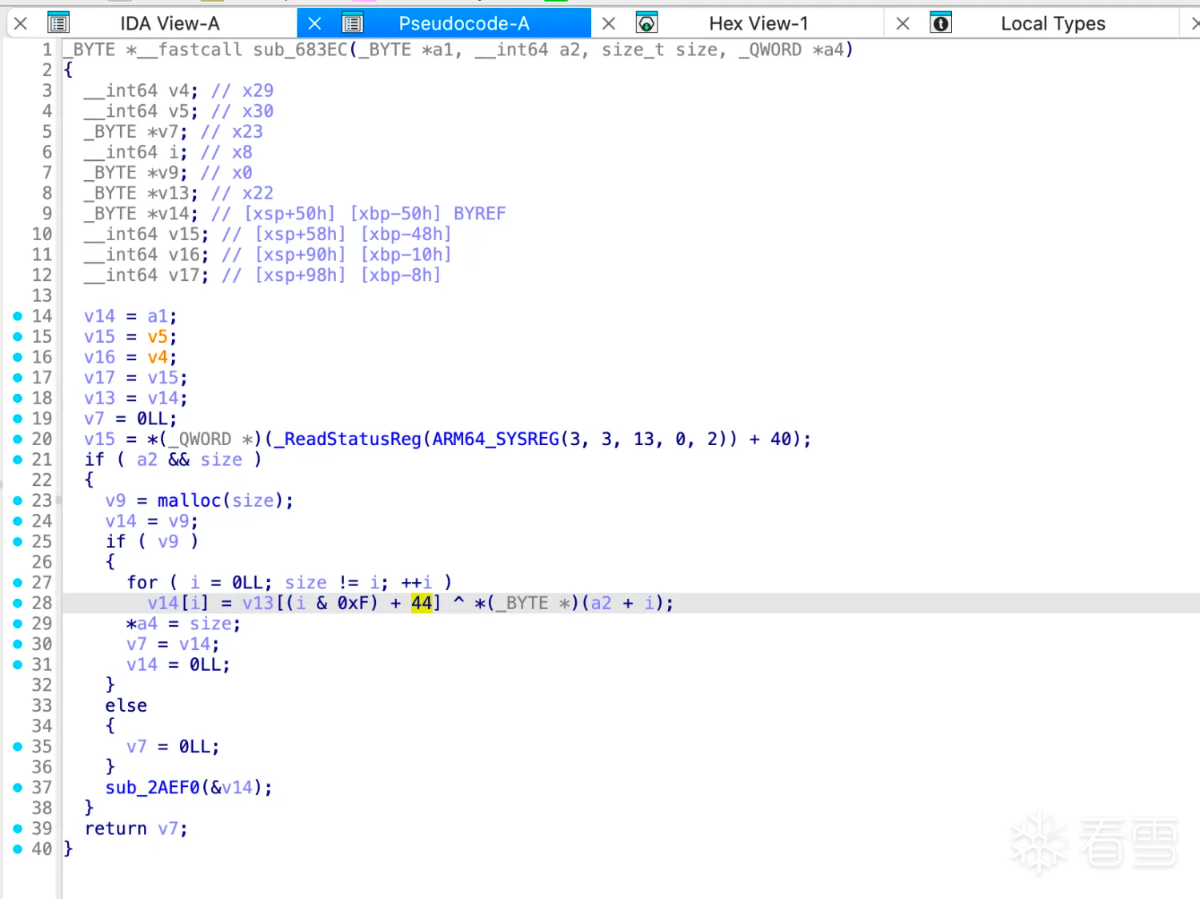
从上图看着是和v13异或得到,那么将输入和结果异或即可得到v13:
取多次hook结果验证这个在同一个机器上起码是不变的。
a5 第一版
mtgsig = {
"a0": "3.0",
"a1": "4069cb78-e02b-45f6-9f0a-b34ddccf389c",
"a3": 24,
"a4": 1736155982,
"a5": "AHepznjTBvV7rHiYm8hD1+169lwTCD+PNAA6LuQx6hGIgKX2FHR3ADYlwF38q/j8dk6sKm+PO57A3AKiYH4RX1FE7Cyy8UkEwWceQURrxfHX2O7LqWtfwYCsTtE0kUoXW4aGxaAiAagM2KtS81ff/NZUgIYvdaLeiljIXbHGV+6QtbotS6/ClGky4cd1RHy7GZsJ8ubecJjv4QKLxAq4cHgsro4z9Iboi4gYCi+dTStYrEWEPRAhk9VPX3oQHeqlpRrqxGQxCbGUWjjEi/CNjuuF7W8xEnTNq0zOY/YO",
"a6": 0,
"a7": "jSAxPWen3i2zs6omj1rD+uRsiQhiPxEE1CA+76YkCHDQqmp25ELpd3PUR0uWoNZ0eAc0RLxbkZrYsmQwKjqe27lZZ8o95TEOOSQLRo8bHYA=",
"a8": "742b25deffb779f5ed08910789926e676ca5f078d42b28d5c7dd370c",
"a9": "dd051dd5C+3hWx/JTxImXsb+pQWQL/bklyGy4z5sN8nq7p/2yW7SAN9GsygMJe3E3IzoY912YiZ0iCnsGiPPRB6lrUP2uehxqbJlpkuyNQwe7Eh5WcvUlzYW39m7Rh5PNTZhoAUnM7NBMbYqz+WK2hslAUX8mSaQJyebUz8jOxMc7RAdK7SOXFxNX+Mcs/RN2nED0lzB4ZF/I8CFMZHjE5cBAKpeXsQaYalSlK9D50zxK/0sjdlc/knfNcMFq5hFfYz8UDPP4OCeHI/U5YcgrsbgxDH41Qs6bmBF+5YoHT+pKsxc3uc=",
"a10": "5,155,1.1.1",
"x0": 1,
"a2": "673fb25da2fb9e3cb2eff5b39b152559"
}
mtgsig = {
"a0": "3.0",
"a1": "4069cb78-e02b-45f6-9f0a-b34ddccf389c",
"a3": 24,
"a4": 1736155982,
"a5": "AHepznjTBvV7rHiYm8hD1+169lwTCD+PNAA6LuQx6hGIgKX2FHR3ADYlwF38q/j8dk6sKm+PO57A3AKiYH4RX1FE7Cyy8UkEwWceQURrxfHX2O7LqWtfwYCsTtE0kUoXW4aGxaAiAagM2KtS81ff/NZUgIYvdaLeiljIXbHGV+6QtbotS6/ClGky4cd1RHy7GZsJ8ubecJjv4QKLxAq4cHgsro4z9Iboi4gYCi+dTStYrEWEPRAhk9VPX3oQHeqlpRrqxGQxCbGUWjjEi/CNjuuF7W8xEnTNq0zOY/YO",
"a6": 0,
"a7": "jSAxPWen3i2zs6omj1rD+uRsiQhiPxEE1CA+76YkCHDQqmp25ELpd3PUR0uWoNZ0eAc0RLxbkZrYsmQwKjqe27lZZ8o95TEOOSQLRo8bHYA=",
"a8": "742b25deffb779f5ed08910789926e676ca5f078d42b28d5c7dd370c",
"a9": "dd051dd5C+3hWx/JTxImXsb+pQWQL/bklyGy4z5sN8nq7p/2yW7SAN9GsygMJe3E3IzoY912YiZ0iCnsGiPPRB6lrUP2uehxqbJlpkuyNQwe7Eh5WcvUlzYW39m7Rh5PNTZhoAUnM7NBMbYqz+WK2hslAUX8mSaQJyebUz8jOxMc7RAdK7SOXFxNX+Mcs/RN2nED0lzB4ZF/I8CFMZHjE5cBAKpeXsQaYalSlK9D50zxK/0sjdlc/knfNcMFq5hFfYz8UDPP4OCeHI/U5YcgrsbgxDH41Qs6bmBF+5YoHT+pKsxc3uc=",
"a10": "5,155,1.1.1",
"x0": 1,
"a2": "673fb25da2fb9e3cb2eff5b39b152559"
}
// hook java 入口函数
function hook_main3() {
var Arrays = Java.use("java.util.Arrays");
var ShellBridge = Java.use("com.meituan.android.common.mtguard.ShellBridge");
ShellBridge.main3.implementation = function (i, objArr) {
console.log("hook ShellBridge.main3");
var ret = this.main3(i, objArr);
console.log(objArr.length);
console.log(objArr[0]);
// var arr = Arrays.asList(objArr);
// for (var i; i < arr.size(); i++) {
// var item = arr.get(i);
// console.log(item);
// }
console.log(`ShellBridge.main3args: ${i}\n${objArr}\nret: ${ret}\n`);
return ret;
}
}
function hook_dlopen() {
Interceptor.attach(Module.findExportByName(null, "android_dlopen_ext"), {
onEnter: function (args) {
var path_ptr = args[0];
if (path_ptr != undefined && path_ptr != null) {
var path = ptr(path_ptr).readCString();
console.log("[LOAD] " + path);
if (path.indexOf("libmtguard.so") != -1) {
this.canHook = true;
}
}
},
onLeave: function (retval) {
if (this.canHook) {
// 这里添加hook native的函数
hook_4cf88(); // base64 1
hook_68958(); // rc4 init
hook_68968(); // rc4 enc
hook_683ec(); // rc4 key related
hook_34844(); // rc4 input
}
}
})
}
// hook base64相关算法
function hook_4cf88() {
var base = Module.findBaseAddress("libmtguard.so");
console.log(`libmtguard.so base: ${base}`);
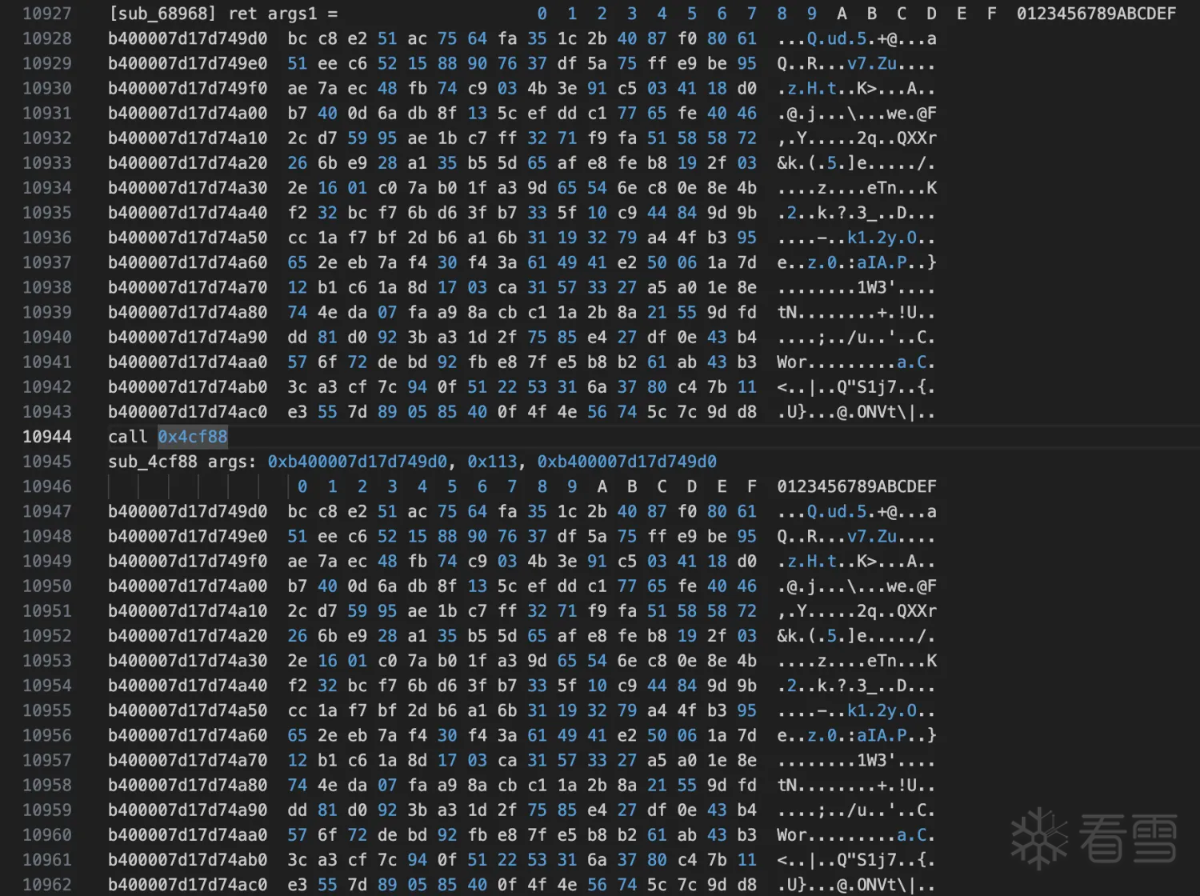
Interceptor.attach(base.add(0x4cf88), {
onEnter: function (args) {
console.log("call 0x4cf88");
console.log(`sub_4cf88 args: ${args[0]}, ${args[1]}, ${args[2]}`);
console.log(hexdump(args[0]));
// 尝试打印native堆栈
console.log(`sub_4cf88 native stack: ${Thread.backtrace(this.context, Backtracer.ACCURATE).map(DebugSymbol.fromAddress).join('\n') + '\n'}`);
},
onLeave: function (retval) {
console.log(`sub_4cf88 ret: ${retval}\n`)
}
})
}
// hook java 入口函数
function hook_main3() {
var Arrays = Java.use("java.util.Arrays");
var ShellBridge = Java.use("com.meituan.android.common.mtguard.ShellBridge");
ShellBridge.main3.implementation = function (i, objArr) {
console.log("hook ShellBridge.main3");
var ret = this.main3(i, objArr);
console.log(objArr.length);
console.log(objArr[0]);
// var arr = Arrays.asList(objArr);
// for (var i; i < arr.size(); i++) {
// var item = arr.get(i);
// console.log(item);
// }
console.log(`ShellBridge.main3args: ${i}\n${objArr}\nret: ${ret}\n`);
return ret;
}
}
function hook_dlopen() {
Interceptor.attach(Module.findExportByName(null, "android_dlopen_ext"), {
onEnter: function (args) {
var path_ptr = args[0];
if (path_ptr != undefined && path_ptr != null) {
var path = ptr(path_ptr).readCString();
console.log("[LOAD] " + path);
if (path.indexOf("libmtguard.so") != -1) {
this.canHook = true;
}
}
},
onLeave: function (retval) {
if (this.canHook) {
// 这里添加hook native的函数
hook_4cf88(); // base64 1
hook_68958(); // rc4 init
hook_68968(); // rc4 enc
hook_683ec(); // rc4 key related
hook_34844(); // rc4 input
}
}
})
}
// hook base64相关算法
function hook_4cf88() {
var base = Module.findBaseAddress("libmtguard.so");
console.log(`libmtguard.so base: ${base}`);
Interceptor.attach(base.add(0x4cf88), {
onEnter: function (args) {
console.log("call 0x4cf88");
console.log(`sub_4cf88 args: ${args[0]}, ${args[1]}, ${args[2]}`);
console.log(hexdump(args[0]));
// 尝试打印native堆栈
console.log(`sub_4cf88 native stack: ${Thread.backtrace(this.context, Backtracer.ACCURATE).map(DebugSymbol.fromAddress).join('\n') + '\n'}`);
},
onLeave: function (retval) {
console.log(`sub_4cf88 ret: ${retval}\n`)
}
})
}
.text:00000000000FDB0C CMP X27,
赋值,和后面的条件选择分支有关
.text:00000000000FDB10 MOV W8,
.text:00000000000FDB14 MOV W9,
x22 赋值
.text:00000000000FDB18 ADRP X22,
条件选择分支,和读取跳转表寻址相关
.text:00000000000FDB1C CSEL X8, X9, X8, EQ
和读取内存寻址相关,x22看着像是跳转表地址
.text:00000000000FDB20 ADD X22, X22,
读取内存,和跳转相关
.text:00000000000FDB24 LDR X8, [X22,X8]
赋值,和条件选择语句不同条件相关
.text:00000000000FDB28 MOV W9,
.text:00000000000FDB2C MOV W10,
条件选择语句,和计算跳转地址相关
.text:00000000000FDB30 CSEL X9, X10, X9, EQ
计算 x8 = x8 - x9 和跳转寄存器相关
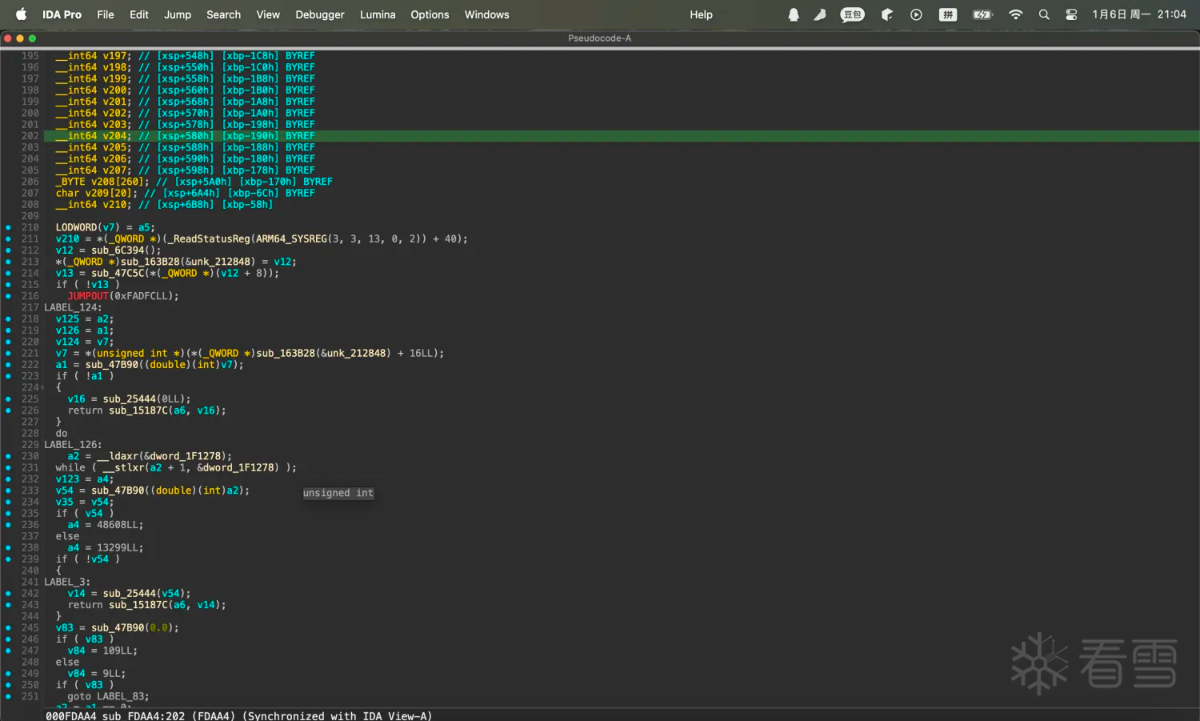
.text:00000000000FDB34 SUB X8, X8, X9
保存x27寄存器的值和跳转指令没有什么关系
.text:00000000000FDB38 STR X27, [SP,
下面是跳转指令
.text:00000000000FDB3C BR X8
.text:00000000000FDB0C CMP X27,
赋值,和后面的条件选择分支有关
.text:00000000000FDB10 MOV W8,
.text:00000000000FDB14 MOV W9,
x22 赋值
.text:00000000000FDB18 ADRP X22,
条件选择分支,和读取跳转表寻址相关
.text:00000000000FDB1C CSEL X8, X9, X8, EQ
和读取内存寻址相关,x22看着像是跳转表地址
.text:00000000000FDB20 ADD X22, X22,
读取内存,和跳转相关
.text:00000000000FDB24 LDR X8, [X22,X8]
赋值,和条件选择语句不同条件相关
.text:00000000000FDB28 MOV W9,
.text:00000000000FDB2C MOV W10,
条件选择语句,和计算跳转地址相关
.text:00000000000FDB30 CSEL X9, X10, X9, EQ
计算 x8 = x8 - x9 和跳转寄存器相关
.text:00000000000FDB34 SUB X8, X8, X9
保存x27寄存器的值和跳转指令没有什么关系
.text:00000000000FDB38 STR X27, [SP,
下面是跳转指令
.text:00000000000FDB3C BR X8
from loguru import logger
from capstone import Cs, CS_ARCH_ARM64, CS_MODE_ARM
from keystone import Ks, KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN
from unicorn.arm64_const import UC_ARM64_REG_SP, UC_ARM64_REG_X27, UC_ARM64_REG_X8
from unicorn import Uc, UC_ARCH_ARM64, UC_MODE_ARM, UC_HOOK_CODE, UC_HOOK_MEM_READ_UNMAPPED, UC_HOOK_MEM_READ
mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
BASE_ADDR = 0x40000000
BASE_SIZE = 4 * 1024 * 1024
mu.mem_map(BASE_ADDR, BASE_SIZE)
STACK_ADDR = 0x10000000
STACK_SIZE = 0x00100000
mu.mem_map(STACK_ADDR, STACK_SIZE)
logger.debug(f"Memory map {hex(STACK_ADDR)} - {hex(STACK_ADDR + STACK_SIZE)}")
mu.reg_write(UC_ARM64_REG_SP, STACK_ADDR + STACK_SIZE)
ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN)
assembly_code = ';'.join([
'CMP X27, #0',
'MOV W8, #0x30',
'MOV W9, #0x310',
'ADRP X22, #0x212000',
'CSEL X8, X9, X8, EQ',
'ADD X22, X22, #0xB0',
'LDR X8, [X22,X8]',
'MOV W9, #0x433',
'MOV W10, #0x488F',
'CSEL X9, X10, X9, EQ',
'SUB X8, X8, X9',
])
encoding, count = ks.asm(assembly_code.strip())
logger.debug(f"Assembly code {bytes(encoding).hex()}, bytes count {count}")
mu.mem_write(BASE_ADDR, bytes(encoding))
def hook_code(uc: Uc, address: int, size: int, user_data):
inst = uc.mem_read(address, size)
md = Cs(CS_ARCH_ARM64, CS_MODE_ARM)
for i in md.disasm(inst, address):
logger.debug(f">>> {hex(i.address)}:\t{i.mnemonic}\t{i.op_str}")
mu.hook_add(UC_HOOK_CODE, hook_code)
def hook_mem_read(uc: Uc, access: int, address: int, size: int, value, user_data):
uc.mem_write(address, int.to_bytes(1046155, 8, byteorder='little'))
data = uc.mem_read(address, size)
logger.debug(f">>> Tracing memory read at {hex(address)}, size: {hex(size)}, data: {data.hex()}")
mu.hook_add(UC_HOOK_MEM_READ, hook_mem_read)
mu.reg_write(UC_ARM64_REG_X27, 1)
mu.emu_start(BASE_ADDR, BASE_ADDR + (4 * count))
x8_value = mu.reg_read(UC_ARM64_REG_X8)
logger.debug(f"x8 value: {hex(x8_value)}")
from loguru import logger
from capstone import Cs, CS_ARCH_ARM64, CS_MODE_ARM
from keystone import Ks, KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN
from unicorn.arm64_const import UC_ARM64_REG_SP, UC_ARM64_REG_X27, UC_ARM64_REG_X8
from unicorn import Uc, UC_ARCH_ARM64, UC_MODE_ARM, UC_HOOK_CODE, UC_HOOK_MEM_READ_UNMAPPED, UC_HOOK_MEM_READ
mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
BASE_ADDR = 0x40000000
BASE_SIZE = 4 * 1024 * 1024
mu.mem_map(BASE_ADDR, BASE_SIZE)
STACK_ADDR = 0x10000000
STACK_SIZE = 0x00100000
mu.mem_map(STACK_ADDR, STACK_SIZE)
logger.debug(f"Memory map {hex(STACK_ADDR)} - {hex(STACK_ADDR + STACK_SIZE)}")
mu.reg_write(UC_ARM64_REG_SP, STACK_ADDR + STACK_SIZE)
ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN)
assembly_code = ';'.join([
'CMP X27, #0',
'MOV W8, #0x30',
'MOV W9, #0x310',
'ADRP X22, #0x212000',
'CSEL X8, X9, X8, EQ',
'ADD X22, X22, #0xB0',
'LDR X8, [X22,X8]',
'MOV W9, #0x433',
'MOV W10, #0x488F',
'CSEL X9, X10, X9, EQ',
'SUB X8, X8, X9',
])
encoding, count = ks.asm(assembly_code.strip())
logger.debug(f"Assembly code {bytes(encoding).hex()}, bytes count {count}")
mu.mem_write(BASE_ADDR, bytes(encoding))
def hook_code(uc: Uc, address: int, size: int, user_data):
inst = uc.mem_read(address, size)
md = Cs(CS_ARCH_ARM64, CS_MODE_ARM)
for i in md.disasm(inst, address):
logger.debug(f">>> {hex(i.address)}:\t{i.mnemonic}\t{i.op_str}")
mu.hook_add(UC_HOOK_CODE, hook_code)
def hook_mem_read(uc: Uc, access: int, address: int, size: int, value, user_data):
uc.mem_write(address, int.to_bytes(1046155, 8, byteorder='little'))
data = uc.mem_read(address, size)
logger.debug(f">>> Tracing memory read at {hex(address)}, size: {hex(size)}, data: {data.hex()}")
mu.hook_add(UC_HOOK_MEM_READ, hook_mem_read)
mu.reg_write(UC_ARM64_REG_X27, 1)
mu.emu_start(BASE_ADDR, BASE_ADDR + (4 * count))
x8_value = mu.reg_read(UC_ARM64_REG_X8)
logger.debug(f"x8 value: {hex(x8_value)}")
def get_jump_table_addr(min_addr, max_addr):
cur_addr = min_addr
while True:
next_ea = idc.next_head(cur_addr, max_addr)
if next_ea == idc.BADADDR:
break
insn = idc.GetDisasm(next_ea)
if "X22" in insn or "W22" in insn:
tmp = insn.split()
if tmp[0] in ["STP", "ADD", "ADRP", "ADRL", "SUB"]:
print(f"{hex(next_ea)}: {insn}, function address: {hex(idc.get_func_attr(next_ea, idc.FUNCATTR_START))}")
if tmp[0] == "LDR":
print(f"[maybe] {hex(next_ea)}: {insn}")
cur_addr = next_ea
min_addr, max_addr = 0xfdaa4, idc.BADADDR
get_jump_table_addr(min_addr, max_addr)
def get_jump_table_addr(min_addr, max_addr):
cur_addr = min_addr
while True:
next_ea = idc.next_head(cur_addr, max_addr)
if next_ea == idc.BADADDR:
break
insn = idc.GetDisasm(next_ea)
if "X22" in insn or "W22" in insn:
tmp = insn.split()
if tmp[0] in ["STP", "ADD", "ADRP", "ADRL", "SUB"]:
print(f"{hex(next_ea)}: {insn}, function address: {hex(idc.get_func_attr(next_ea, idc.FUNCATTR_START))}")
if tmp[0] == "LDR":
print(f"[maybe] {hex(next_ea)}: {insn}")
cur_addr = next_ea
min_addr, max_addr = 0xfdaa4, idc.BADADDR
get_jump_table_addr(min_addr, max_addr)
def pattern_search_all(start_ea, end_ea, pattern_str):
image_base = idaapi.get_imagebase()
pattern = ida_bytes.compiled_binpat_vec_t()
err = ida_bytes.parse_binpat_str(pattern, image_base, pattern_str, 16)
if err:
print(f"Failed to parse pattern: {err}")
return
found_addrs = []
curr_addr = start_ea
while True:
curr_addr, _ = ida_bytes.bin_search(curr_addr, end_ea, pattern, ida_bytes.BIN_SEARCH_FORWARD)
if curr_addr == idc.BADADDR:
break
found_addrs.append(curr_addr)
curr_addr += 1
return found_addrs
br_addrs = []
pattern_str_1 = "00 01 1F D6"
pattern_str_2 = "20 01 1F D6"
tmp = pattern_search_all(min_addr, max_addr, pattern_str_1)
print(f"length of search result for x8: {len(tmp)}")
br_addrs.extend(tmp)
tmp = pattern_search_all(min_addr, max_addr, pattern_str_2)
print(f"length of search result for x9: {len(tmp)}")
br_addrs.extend(tmp)
def pattern_search_all(start_ea, end_ea, pattern_str):
image_base = idaapi.get_imagebase()
pattern = ida_bytes.compiled_binpat_vec_t()
err = ida_bytes.parse_binpat_str(pattern, image_base, pattern_str, 16)
if err:
print(f"Failed to parse pattern: {err}")
return
found_addrs = []
curr_addr = start_ea
while True:
curr_addr, _ = ida_bytes.bin_search(curr_addr, end_ea, pattern, ida_bytes.BIN_SEARCH_FORWARD)
if curr_addr == idc.BADADDR:
break
found_addrs.append(curr_addr)
curr_addr += 1
return found_addrs
br_addrs = []
pattern_str_1 = "00 01 1F D6"
pattern_str_2 = "20 01 1F D6"
tmp = pattern_search_all(min_addr, max_addr, pattern_str_1)
print(f"length of search result for x8: {len(tmp)}")
br_addrs.extend(tmp)
tmp = pattern_search_all(min_addr, max_addr, pattern_str_2)
print(f"length of search result for x9: {len(tmp)}")
br_addrs.extend(tmp)
def gather_critical_info(addr):
cur_addr = addr
infos = []
has_csel = False
has_csel_2 = False
csel_2_addr = None
insn = idc.GetDisasm(cur_addr)
jump_reg = insn.split()[1]
print(f"process {hex(cur_addr)}, jump register: {jump_reg}")
infos.append((cur_addr, insn))
for _ in range(5):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
if tmp[0] in ['SUB', 'ADD'] and jump_reg in tmp[1]:
cur_addr = prev_ea
offset_reg = tmp[3]
print(f"{hex(cur_addr)}: {insn}, offset register: {offset_reg}")
infos.append((cur_addr, insn))
break
cur_addr = prev_ea
for _ in range(5):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
if tmp[0] in ['MOV', 'CSEL'] and offset_reg in tmp[1]:
cur_addr = prev_ea
if tmp[0] == "CSEL":
has_csel = True
csel_t, csel_f = tmp[2].replace(',', ''), tmp[3].replace(',', '')
print(f"{hex(prev_ea)}: {insn}, csel true: {csel_t}, csel false: {csel_f}")
infos.append((prev_ea, insn))
break
cur_addr = prev_ea
for _ in range(8):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
if has_csel:
if tmp[0] == 'MOV' and (csel_t[1:] in tmp[1] or csel_f[1:] in tmp[1]):
print(f"[csel] {hex(prev_ea)}: {insn}")
infos.append((prev_ea, insn))
if tmp[0] == "LDR" and "X22" in tmp[2]:
print(f"{hex(prev_ea)}: {insn}")
infos.append((prev_ea, insn))
if not has_csel:
print("case 2 finished")
return infos, has_csel
return
if tmp[0] == "CSEL":
csel_2_addr = cur_addr
cur_addr = prev_ea
cur_addr = cur_addr if csel_2_addr is None else csel_2_addr
for _ in range(5):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
if tmp[0] == "CSEL":
cur_addr = prev_ea
csel_t, csel_f = tmp[2].replace(',', ''), tmp[3].replace(',', '')
print(f"{hex(prev_ea)}: {insn}, csel true: {csel_t}, csel false: {csel_f}")
infos.append((prev_ea, insn))
has_csel_2 = True
if has_csel_2:
if tmp[0] == 'MOV' and (csel_t[1:] in tmp[1] or csel_f[1:] in tmp[1]):
print(f"[csel] {hex(prev_ea)}: {insn}")
infos.append((prev_ea, insn))
cur_addr = prev_ea
for _ in range(5):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
print(tmp)
if tmp[0] == "MOV" and (csel_t[1:] in tmp[1] or csel_f[1:] in tmp[1]):
print(f"[csel] {hex(prev_ea)}: {insn}")
infos.append((prev_ea, insn))
cur_addr = prev_ea
return infos, has_csel
critical_infos = []
error_count = 0
for addr in br_addrs:
try:
info, has_csel = gather_critical_info(addr)
critical_infos.append({"address": addr, "info": info, "has_csel": has_csel})
except Exception as e:
error_count += 1
print(f"[gather] {hex(addr)} critical info error: {e}")
print(f"gather critical info error count: {error_count}")
def gather_critical_info(addr):
cur_addr = addr
infos = []
has_csel = False
has_csel_2 = False
csel_2_addr = None
insn = idc.GetDisasm(cur_addr)
jump_reg = insn.split()[1]
print(f"process {hex(cur_addr)}, jump register: {jump_reg}")
infos.append((cur_addr, insn))
for _ in range(5):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
if tmp[0] in ['SUB', 'ADD'] and jump_reg in tmp[1]:
cur_addr = prev_ea
offset_reg = tmp[3]
print(f"{hex(cur_addr)}: {insn}, offset register: {offset_reg}")
infos.append((cur_addr, insn))
break
cur_addr = prev_ea
for _ in range(5):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
if tmp[0] in ['MOV', 'CSEL'] and offset_reg in tmp[1]:
cur_addr = prev_ea
if tmp[0] == "CSEL":
has_csel = True
csel_t, csel_f = tmp[2].replace(',', ''), tmp[3].replace(',', '')
print(f"{hex(prev_ea)}: {insn}, csel true: {csel_t}, csel false: {csel_f}")
infos.append((prev_ea, insn))
break
cur_addr = prev_ea
for _ in range(8):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
if has_csel:
if tmp[0] == 'MOV' and (csel_t[1:] in tmp[1] or csel_f[1:] in tmp[1]):
print(f"[csel] {hex(prev_ea)}: {insn}")
infos.append((prev_ea, insn))
if tmp[0] == "LDR" and "X22" in tmp[2]:
print(f"{hex(prev_ea)}: {insn}")
infos.append((prev_ea, insn))
if not has_csel:
print("case 2 finished")
return infos, has_csel
return
if tmp[0] == "CSEL":
csel_2_addr = cur_addr
cur_addr = prev_ea
cur_addr = cur_addr if csel_2_addr is None else csel_2_addr
for _ in range(5):
prev_ea = idc.prev_head(cur_addr)
insn = idc.GetDisasm(prev_ea)
tmp = insn.split()
if tmp[0] == "CSEL":
cur_addr = prev_ea
csel_t, csel_f = tmp[2].replace(',', ''), tmp[3].replace(',', '')
print(f"{hex(prev_ea)}: {insn}, csel true: {csel_t}, csel false: {csel_f}")
infos.append((prev_ea, insn))
has_csel_2 = True
if has_csel_2:
if tmp[0] == 'MOV' and (csel_t[1:] in tmp[1] or csel_f[1:] in tmp[1]):
print(f"[csel] {hex(prev_ea)}: {insn}")
infos.append((prev_ea, insn))
cur_addr = prev_ea
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2025-1-7 11:06
被Tubbs编辑
,原因:







