本系列文章为看雪星星人为看雪安全爱好者创作的原创免费作品。
欢迎评论、交流、转载,转载请保留看雪星星人署名并勿用于商业盈利。
本人水平有限,错漏在所难免,欢迎批评指正。
微软在Windows的内核中提供了一套进行文件系统过滤驱动开发的标准接口。利用这套接口开发出来的驱动程序即为微过滤驱动(minifilter driver)。微过滤驱动是内核级的安全模块,能捕获正常的文件写入、文件改名等事件,正符合本篇开发模块执行防御的需求。
本书并不会详细介绍Windows驱动开发的环境准备和基础架构代码。有相关需要的读者建议阅读《Windows内核调试技术》,或是《Windows内核编程》,这两本书中都有配置环境和准备调试环境、微过滤驱动开发和调试的详细说明。
我们需要一个微过滤驱动的范例,在其基础上开发和改造来实现需要的功能。GitHub上有大量的微过滤驱动的范例,我建议选择微软提供的例子,这些例子是最可靠和权威的。
GitHub上微软的目录下有一个名为Windows-driver-samples的目录,在其下路径blob/main/filesys/miniFilter下可以找到许多微过滤驱动的例子。其中的passThrough是一个只过滤不做任何处理的例子,非常便于理解。
下面以写操作的过滤作为说明。但写操作过滤的详尽实现将会在3.2节中呈现。
根据本书2.3.1节中设计的规则2.2,在任何新的可执行文件创建时,我们应捕获事件并将文件路径加入到可执行列表中。但显然,文件的创建操作所携带的信息并不足以完成这个操作。因为文件创建的初期,我们并不知道被创建的文件是否是一个可执行文件。
因此实际需要被捕获的操作并不是文件的创建,而是文件内容的写入。这和2.3.1节中设计的规则2.3刚好可以合并处理:捕获对任何文件的写入事件。任何时候当一个可执行文件被写入之后依然是一个可执行文件,或者一个不可执行文件被写入之后变成可执行文件了,我们则将其路径加入到2.3.1节中所述过的可疑库中。
综上所述,我们需要捕获的是文件被写入的事件。捕获写入事件的相关完整的代码将在本节中介绍。有经验的读者可能会提前意识到本节代码中含有漏洞。事实上不存在漏洞的安全系统是不存在的。我会在2.3节“漏洞分析”中详细解释并予以部分弥补。
参考passThrough的代码,微过滤驱动中最重要的基础框架为一个类型为FLT_OPERATION_REGISTRATION的数据结构的数组(本书后面称之为过滤操作数组,上下文明确时简称数组),该数组中内含一组回调函数指针。
开发微过滤驱动的主要工作是编写这些回调函数,并将回调函数指针填入该数组中,然后使用函数FltRegisterFilter向Windows内核注册。其中passThrough中对过滤操作结构的初始化如图3-1所示。
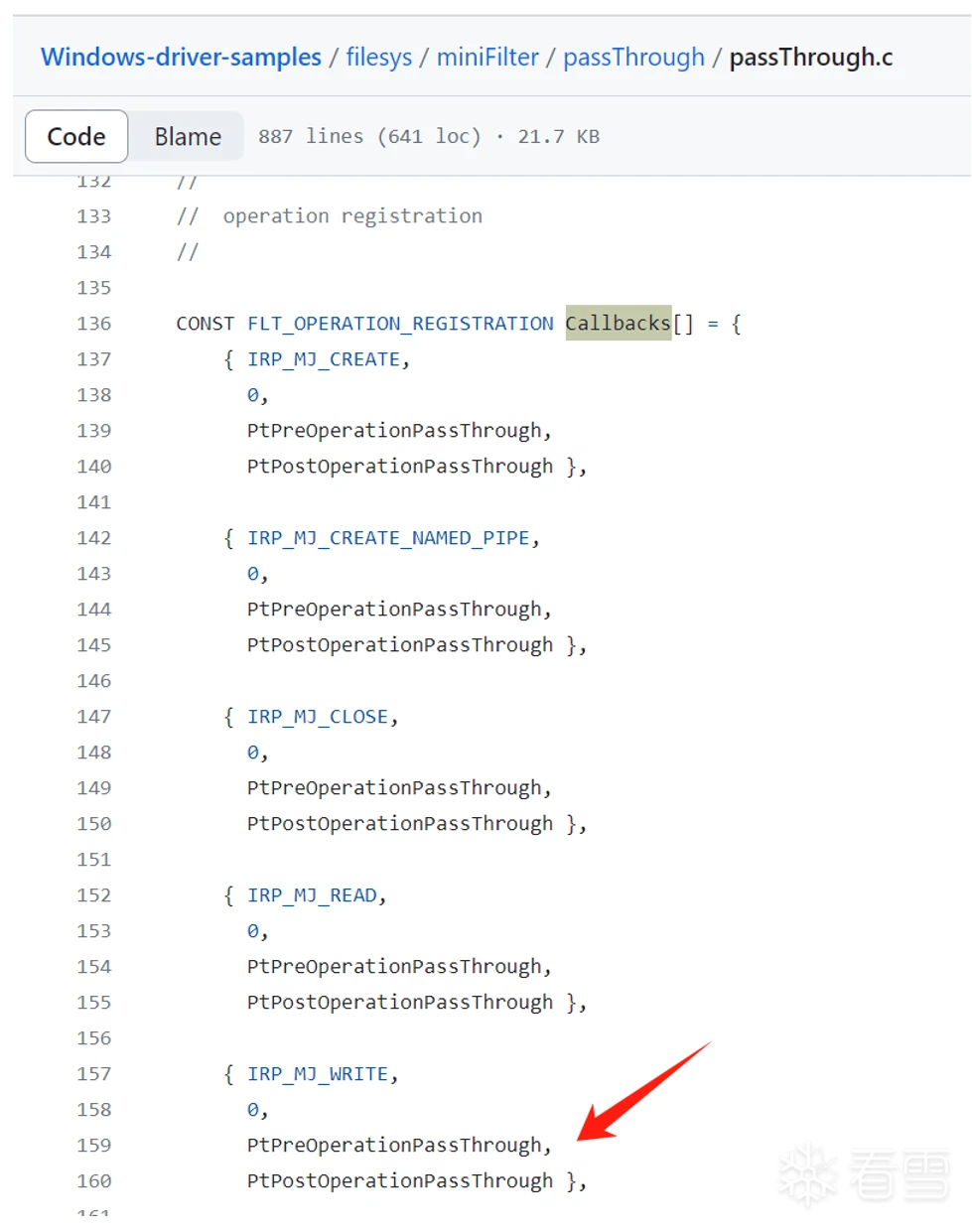
图3-1 passThrough中对过滤操作结构的初始化
图3-1中箭头所示可以看到数组中每个元素的初始化定义中有两个回调函数指针。其中之一以PtPre开头,而另一个以PtPost开头。Pre和Post分别表示前回调与后回调。前回调将被调用于请求完成之前,而后回调则会被调用于请求完成之后。
在回调函数指针之前的IRP_MJ_XXX系列的宏,则是发生的请求的主功能号。这个宏中的“IRP”前缀对应另一个数据结构IRP,全称为I/O Request Packet,即IO操作请求包,是Windows内核中用来处理诸如文件、磁盘读写这类IO操作的常用数据结构。后文我会将IRP简称为“请求”。
请求有多种,由主功能号进行分别。我们要处理的写操作,正是其中的请求之一。过滤操作数组的每个元素的意义为:如果发生了主功能号为IRP_MJ_XXX的请求,则先调用对应元素下的前回调函数指针(如果前回调函数中返回需要后回调,那么完成后还会再调用后回调函数)。
其中IRP_MJ_CREATE代表着文件的创建和打开请求,IRP_MJ_READ和IRP_MJ_WRITE分别为读和写请求,其他的请求依此类推。从上面这个数组初始化过程看所有请求都共用了前回调函数PtPreOperationPassThrough和后回调函数PtPostOperationPassThrough。当然,也可以为每个请求指定不同的回调函数指针。
因此,PassThrough在按微软相关文档提供的说明编译和安装在被测试机上的时候,一旦有文件被写入(出现IRP_MJ_WRITE请求),就会触发PtPreOperationPassThrough这个函数的调用。至于后回调是否被调用则取决于前回调的返回值。
从3.1.2节开始,我们的代码会注册一系列回调函数,其中包括写操作的前回调和后回调,并在其中处理写入内容可能导致文件变成可执行的情况。此事从原理上看颇为简单,但实际上我们很快会看到在操作系统内核中进行各种处理的艰难和复杂。
如果要捕获系统中所有文件被写入这一事件,理论上只要在图3-1中的PtPreOperationPassThrough函数中专门进行写请求的处理即可。但我对Callbacks相关代码进行了修改,在过滤操作数组中为需要处理的生成和写请求都指定了专门的处理函数,如代码3-1所示。
代码3-1 在过滤操作数组为需要处理的写请求指定专门的处理函数
// 文件过滤驱动需要过滤的回调
CONST FLT_OPERATION_REGISTRATION callbacks[] = {
…
{
IRP_MJ_CREATE,
0,
CreateIrpProcess,
CreateIrpPost
},
{
IRP_MJ_WRITE,
FLTFL_OPERATION_REGISTRATION_SKIP_PAGING_IO, (1)
WriteIrpProcess,
WriteIrpPost
},
…
{
IRP_MJ_OPERATION_END
}
};
代码3-1中需要注意的是(1)处,该标志表示不过滤分页(PAGING_IO)操作请求,直接跳过。这一处首次凸显了内核中文件系统处理的复杂性。
在用户态中,文件的“写入”操作非常单纯。只需要调用API[1](如WriteFile)将数据写入文件内容中,即为写操作,而无需关心内核中底层的实现。
但内核为了提升文件访问的性能,避免每一次读写文件都去转动磁盘,实际上将文件的部分内容保存在内存中,称之为文件缓存。只有文件缓存中找不到对应的内容,才会去真实磁盘中读取。
从用户态用API进行文件操作,看到的文件是文件缓存,而不是磁盘中的真实文件。API在内核中首先被转换为非分页请求,操作文件缓存。当文件缓存不能满足需求的时候,再使用分页请求操作真实文件内容。
一次用户态发起的写文件的操作实际完成过程如图3-2所示。
分页请求的过滤相当麻烦。原因在于分页请求发生时的中断级(即IRQL)相当高,也就是说,代码运行到这里时将无法被很多情况打断。
中断级时处理器运行时的一种状态,标志着当前运行的代码在何种情况下能够被打断。微软提供的内核函数都标示有明确的调用级要求,很多我们需要使用的函数调用级别要求很低,这意味着代码必须能够被打断。
举个简单的例子,假定我们调用函数IoCreateFile,该函数内部不可避免地可能调用分页(Paged)内存。分页内存的特性是不常使用时可能被回收,真实数据保存在磁盘上。当被用到时异常会打断当前代码,等待分页交互(即重新分配物理内存,并把数据从磁盘移动到内存中)的过程完成,才可以继续。因此调用IoCreateFile的时候当前中断级必须要能够接受被缺页异常打断,否则就无法调用此函数。

图3-2 一次用户态发起的写文件的操作实际完成过程
这只是一个例子,实际上关于中断级可能还有其他的要求。因此在MSDN[2]中查阅IoCreateFile的文档时,我们能看到MSDN中关于函数的中断级要求,如图3-3所示。

图3-3 MSDN中关于函数的中断级要求
因为有这样的麻烦存在,大多数情况下,我们并不推荐过滤分页请求。所以在代码3-1中,我们使用了特殊标记来跳过对分页请求的过滤,即FLTFL_OPERATION_REGISTRATION_SKIP_PAGING_IO。
从图3-2来看,因为从用户态发起的文件写操作只会被转换为非分页请求(此处实际有漏洞,会在第4章的缺陷分析中详述),而分页请求只是内核内部使用。因此,考虑到本防御系统的本意只是防范初次执行,这样刚好也足够了。
经过代码3-1的处理,我们似乎只需要编写其中的函数WriteIrpProcess即可实现对任何文件的写操作进行拦截。虽然实际上并非如此(在3.4节中会有相关漏洞分析),但我们已经可以开始尝试进行第一步了。
微过滤驱动中所有的请求前回调函数原型都是一样的。代码3-1中的WriteIrpProcess的实现将从一个基本模板开始。请求前回调函数编写的基本模板如代码3-2所示。
代码3-2 请求前回调函数编写的基本模板
FLT_PREOP_CALLBACK_STATUS
WriteIrpProcess(
PFLT_CALLBACK_DATA data,
PCFLT_RELATED_OBJECTS flt_obj,
PVOID* compl_context)
{
FLT_PREOP_CALLBACK_STATUS flt_status =
FLT_PREOP_SUCCESS_NO_CALLBACK; (1)
do {
[培训]Windows内核深度攻防:从Hook技术到Rootkit实战!
最后于 2024-5-7 07:21
被星星人编辑
,原因:





