下载地址
先在cmd执行nvidia-smi,查看驱动版本,下载对应的cuda版本
下载地址
安装的时候选择默认路劲,安装完成在cmd执行nvcc -V,能查到cuda版本证明安装成功
下载跟cuda版本对应的cdDNN版本
解压后,把三个文件夹直接复制到cuda的安装目录
创建python虚拟环境
激活虚拟环境
生成.condarc文件
配置源,把下面内容复制进去,保存
下载地址
选择对应cuda版本的PyTorch安装命令
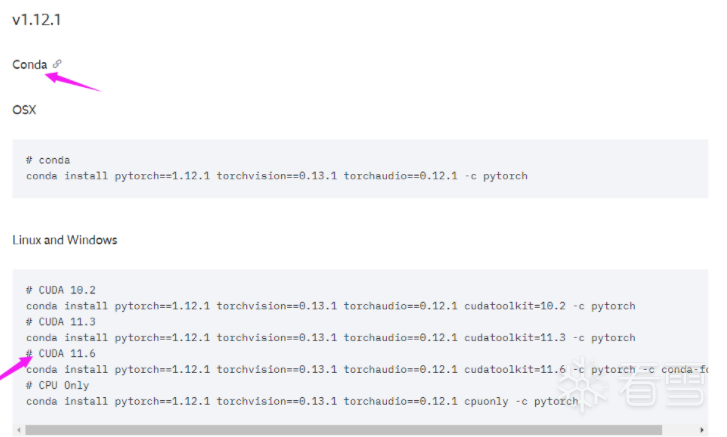
测试是否安装成功
下载yolov5
安装依赖包,先删掉这两行,因为PyTorch我们已经安装过了
然后安装
下载yolov5s.pt,放到根目录
运行命令
测试结果会保存在run目录下面

安装lableImg
labelImg常用快捷键
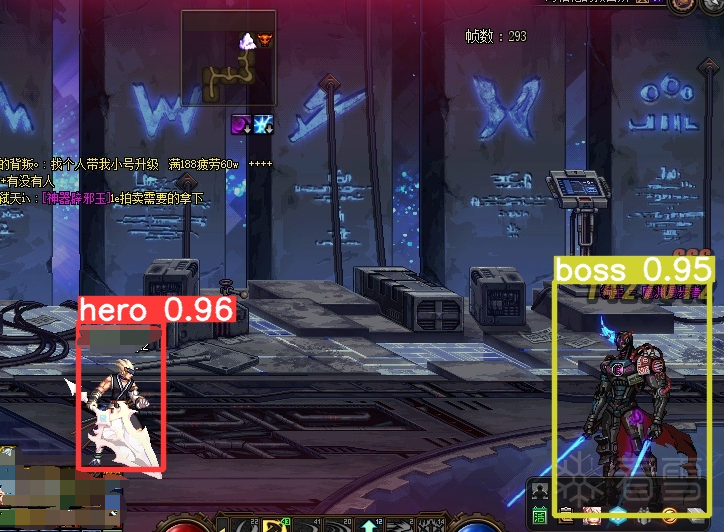
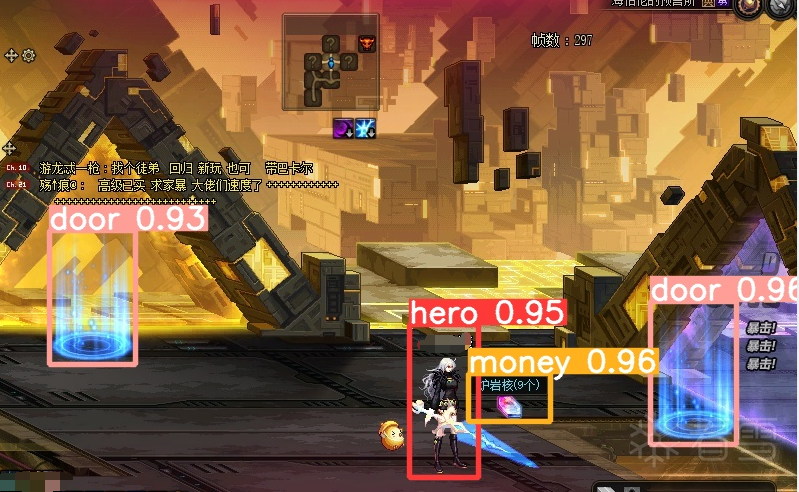
新建images和labels文件夹,把准备好的游戏截图放到images目录下,然后用labelimg开始标注(怎么标注,自己百度),总共标注5个类(hero,door,moster,money,boss)。
主要修改train的图片位置、类的个数和类的名字
只要修改nc的数量就可以
cache用disk或者ram都可以
如果内存不够,把work数再改小点
train完成后会在run/exp1/weights目录下会生产一个best.pt文件,用它来detect
经过yolov5训练后,最终识别准备率能达到0.9以上。

https://repo.anaconda.com/archive/
https://repo.anaconda.com/archive/
https://developer.nvidia.com/cuda-toolkit-archive
https://developer.nvidia.com/cuda-toolkit-archive
https://developer.nvidia.com/rdp/cudnn-download
https://developer.nvidia.com/rdp/cudnn-download
conda activate
conda create -n yolov5_test python=3.8
conda activate
conda create -n yolov5_test python=3.8
activate yolov5_test
conda config --set show_channel_urls yes
conda config --set show_channel_urls yes
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
https://pytorch.org/get-started/previous-versions/
https://pytorch.org/get-started/previous-versions/
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge
https://github.com/ultralytics/yolov5
https://github.com/ultralytics/yolov5
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2023-3-31 00:23
被zhang_derek编辑
,原因:







 pureGavin
pureGavin  改天我试试,不过强化学习这种估计要自定义GYM吧。Reward设计估计是精髓
改天我试试,不过强化学习这种估计要自定义GYM吧。Reward设计估计是精髓



